
小米数据平台大改造:一年省下巨额成本,性能提升6倍的秘密
小米技术团队最近公开了一个重磅改造项目:把原本乱七八糟的数据平台架构彻底重构了。效果有多夸张?**查询性能直接提升 6 倍,高并发场景下延迟最高降低 300%。**按小米的数据规模,光服务器成本一年就能省下千万级别。更关键的是,技术栈从原来的七八套系统简化到现在的两三套,运维同学终于不用半夜起来救火了。
小米技术团队最近公开了一个重磅改造项目:把原本乱七八糟的数据平台架构彻底重构了。
效果有多夸张?**查询性能直接提升 6 倍,高并发场景下延迟最高降低 300%。**按小米的数据规模,光服务器成本一年就能省下千万级别。
更关键的是,技术栈从原来的七八套系统简化到现在的两三套,运维同学终于不用半夜起来救火了。
小米之前有多痛苦
想象一下小米每天产生多少数据:几亿台手机在线上报,IoT 设备传感器数据不停涌入,米家商城的交易数据,还有汽车业务的车联网数据。这些数据加起来,每天都是 PB 级别的增长。
数据存了一遍又一遍
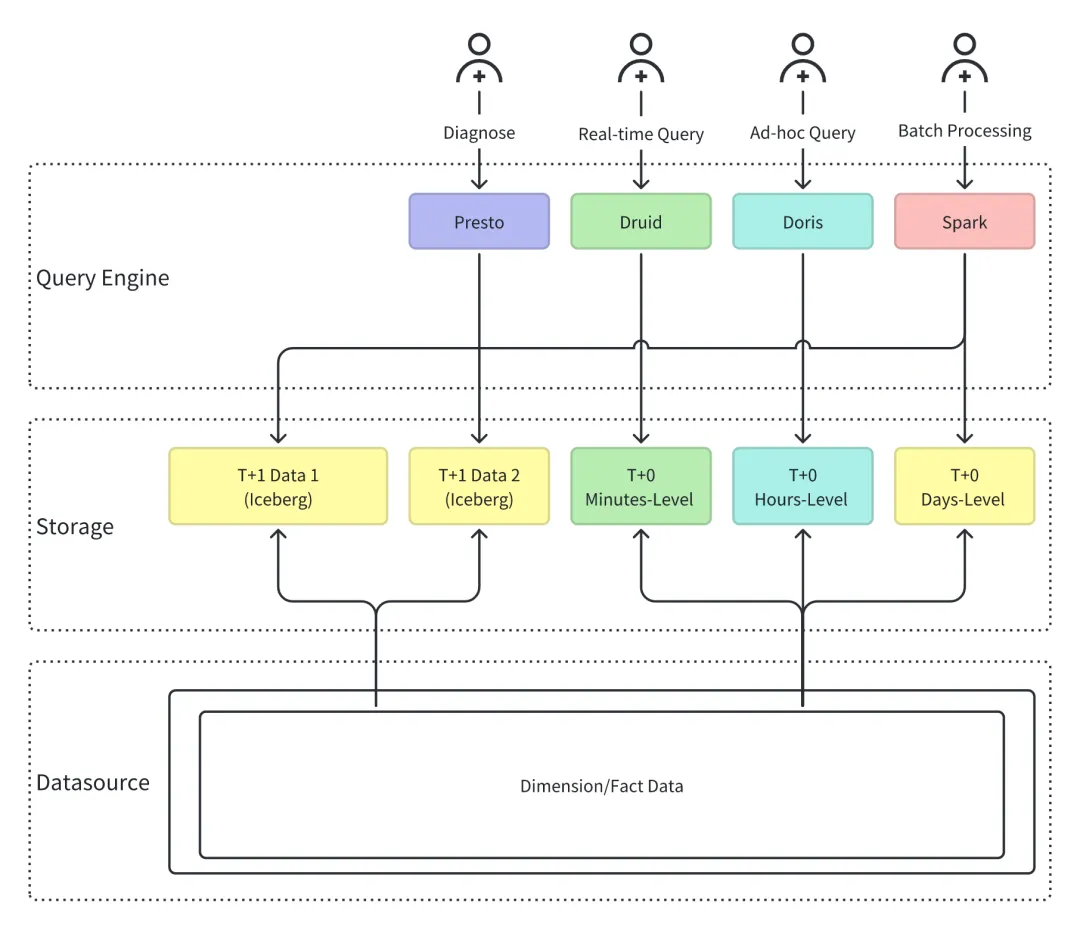
为了满足不同业务需求,小米不得不把同一份数据存储在多个系统里:
- Iceberg 放历史数据
- Paimon 做流批处理
- Druid 跑实时分析
- Doris 做交互查询
结果就是数据到处都是,一致性没法保证,存储成本飞涨。
引擎多到运维崩溃
计算引擎更是一大堆:Presto 负责离线查询,Druid 做实时 OLAP,Doris 搞交互分析,Spark 跑批处理。
每个引擎都有自己的监控体系、权限管理、数据建模逻辑。新人入职光是搞清楚什么场景用什么工具就要好几个月。
运维同学更惨,半夜经常被不同系统的告警吵醒。修好了 Presto,Druid 又出问题;搞定了 Druid,Doris 又开始报警。
业务同学也很无奈
数据分析师想做个简单的用户行为分析,得先搞清楚:
- 实时数据在 Druid 里
- 历史数据要用 Presto 查
- 复杂计算得上 Spark
- 临时查询找 Doris
学会这套组合拳,起码要半年时间。很多业务需求因为工具复杂度高,最后都不了了之。
破局思路:让专业的干专业的事
小米团队经过深度调研,发现了一个关键洞察:数据湖和数据库其实不冲突,完全可以优势互补。
Apache Paimon 这个数据湖的优势很明显:存储便宜、格式开放、流批一体、事务支持。但查询性能确实不如专门的分析数据库。
Apache Doris 查询性能强悍,毫秒级响应,高并发支持好,但存储成本高,扩展性有限。
小米的想法很简单:让 Paimon 负责存储,Doris 负责计算,两者深度融合。
新架构长这样
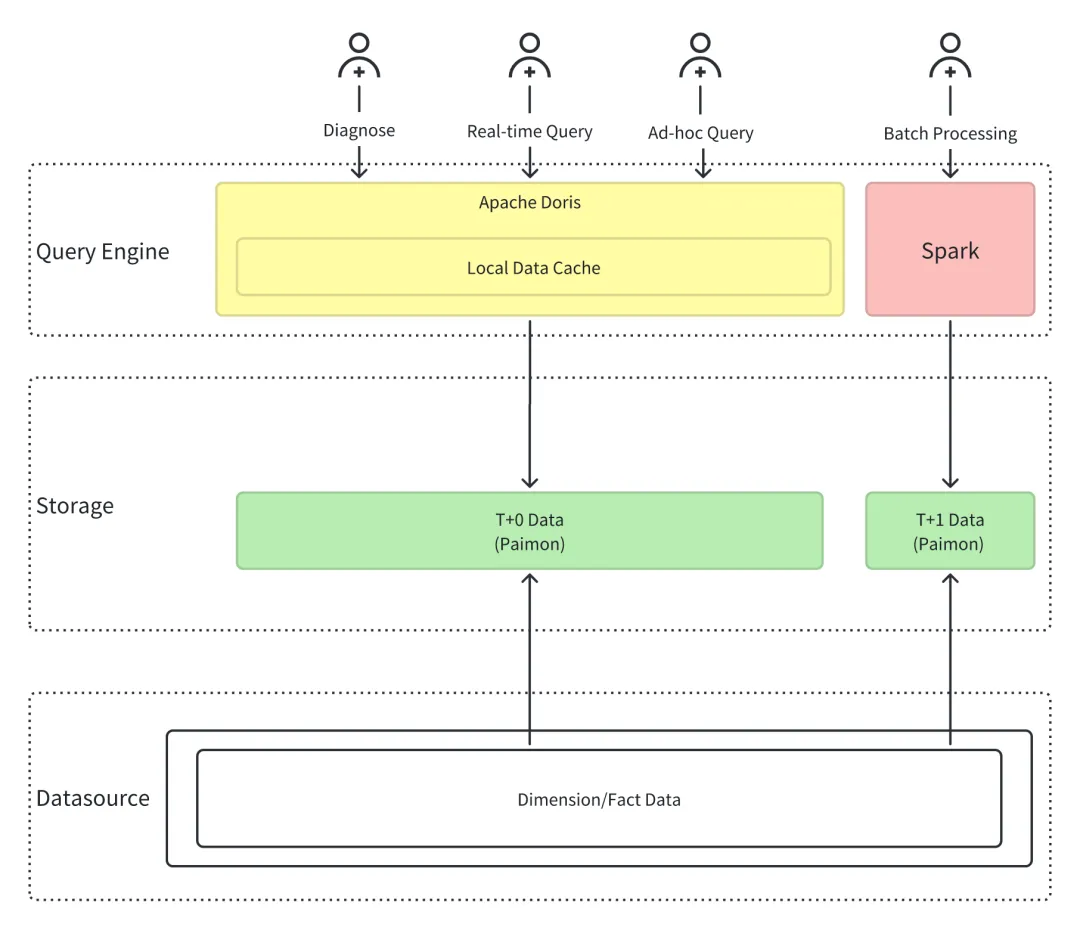
存储层统一:
所有数据都存在 Paimon 里,流批数据统一管理,开放格式保证兼容性。
计算层分工:
- Doris 负责实时查询和交互分析,性能要求高的场景
- Spark 负责离线批处理,复杂 ETL 作业
- 两者都直接读取 Paimon 数据,不用数据搬运
加速机制:
热点数据通过 Doris 物化视图缓存,用户查询自动路由到最快的数据源。
三个技术突破解决核心痛点
突破一:C++ 引擎直接读取 Paimon
原来 Doris 读取 Paimon 数据要通过 Java SDK,这个 SDK 是单线程处理文件合并,性能瓶颈很明显。
小米团队直接绕过了 SDK,用 Doris 自己的 C++ Parquet Reader 读取数据文件,然后用分布式并行引擎做合并计算。
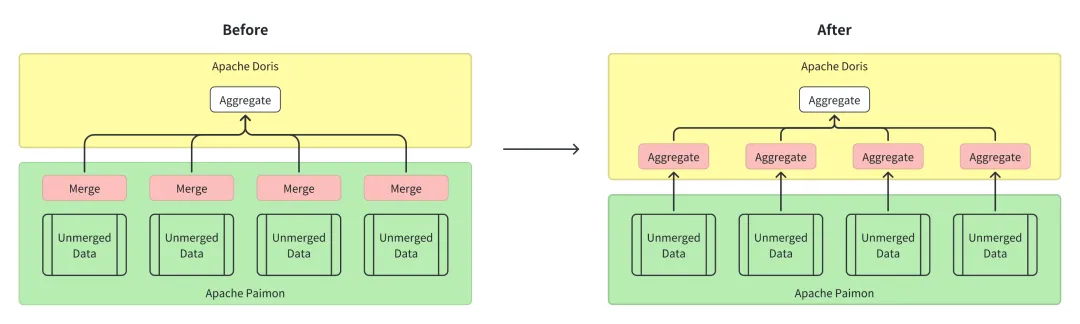
这个改动让聚合查询从 40 秒缩短到 8 秒,性能提升了 5 倍。
突破二:基于快照的增量物化视图
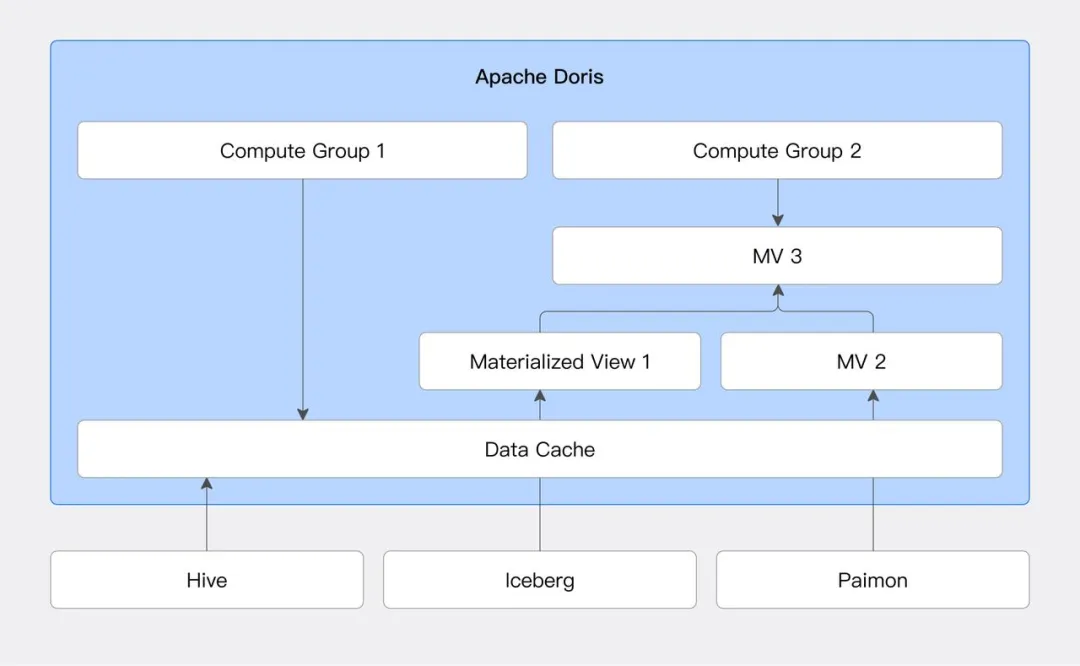
传统物化视图更新是按分区来的,对大分区或非分区表效率很低。小米开发了基于快照的增量读取:
SELECT * FROM paimon_table@incr('startSnapshotId'='0', 'endSnapshotId'='5')
这样就能精确读取两个快照之间的增量数据,然后增量更新物化视图。数据时效性大幅提升,更新成本显著降低。
突破三:HDFS 长尾延迟优化
HDFS 默认 60 秒超时在网络不稳定时会让查询延迟暴增。小米把超时时间调到 100 毫秒,启用快速重试,再加上本地缓存机制。
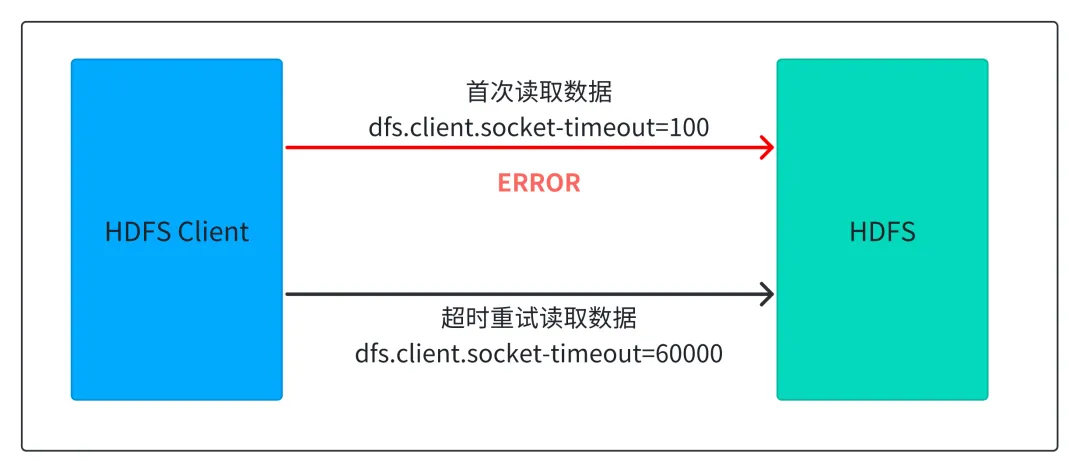
结果是 P99 延迟提升 1 倍,高并发场景延迟降低最高 300%。
改造成果超出预期
- 性能数据
查询平均延迟从 60 秒降到 10 秒,整体并发能力达到 Presto 的 5 倍。这个提升幅度在业界都算很少见的。
- 成本控制
技术栈简化后,服务器资源需求明显减少。数据去重存储,空间利用率提升。运维人力成本大幅下降。
按小米的体量估算,这套新架构一年能节省数千万成本。
- 用户反馈
业务同学反馈最多的是:终于不用学那么多工具了,一个 SQL 接口就能搞定大部分需求。
开发效率也明显提升,新功能上线速度更快,数据建模更统一。
技术贡献回馈开源
小米把所有技术成果都贡献给了 Apache Doris 社区:
快照级增量读取:现在所有用户都能用这个功能
物化视图增强:支持更细粒度的增量更新
HDFS 优化:读取性能优化策略
Paimon 深度集成:各种读取和缓存优化
这就是开源的魅力,一家公司的创新能让整个生态受益。
对其他公司的启发
- 架构选型要务实
小米的经验告诉我们,技术选型不能只看单点能力,要看整体架构的协调性。
数据湖和数据库不是非此即彼的关系,完全可以优势互补。关键是要找到合适的融合点。
- 开源技术已经足够成熟
Apache Doris 和 Apache Paimon 的组合在小米这样的大规模场景下表现优异,说明开源技术已经具备了替代商业产品的能力。
对很多公司来说,这是降本增效的好机会。
- 渐进式改造风险更低
小米没有一次性推倒重建,而是逐步优化改造。这种方式风险可控,业务影响最小。
湖仓一体的未来
从小米的实践看,湖仓一体已经不是概念,而是实实在在能落地的技术方案。
未来的数据架构会更加专业化:存储、计算、缓存、调度等组件都会更专注于自己的领域,但通过标准化接口实现深度协作。
对技术团队来说,系统性的架构设计能力比单点技术更重要。小米的成功不只是选对了技术,更重要的是找到了最佳的组合方式。
数据时代的竞争,拼的不是单项技术,而是整体架构的协调性和演进能力。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)