
灾难性遗忘_深度学习2.0 | 持续学习:让人工智能不再“灾难性遗忘”!
点击上方蓝字关注“人工智能热点”全球最热门的人工智能前沿资讯平台全文共2802字,阅读时长需要9分钟人脑显然是人工智能追求的最高标准,这种可以在新的环境中不断吸收新的知识和根据不同的环境灵活调整自己行为的能力,也正是深度学习系统与人脑相差甚远的重要原因。想让传统深度学习系统获得连续学习能力,最重要的是克服人工神经网络会出现的“灾难性遗忘”问题,让神经网络在学习新知识的同时保留旧知识...
人脑显然是人工智能追求的最高标准,这种可以在新的环境中不断吸收新的知识和根据不同的环境灵活调整自己行为的能力,也正是深度学习系统与人脑相差甚远的重要原因。想让传统深度学习系统获得连续学习能力,最重要的是克服人工神经网络会出现的“灾难性遗忘”问题,让神经网络在学习新知识的同时保留旧知识。前段时间,ICLR2020中一篇名为《超网络的连续学习》(Continual learning with hypernetworks)的研究,提出了任务条件化的超网络(基于任务属性生成目标模型权重的网络),该方法能够有效克服灾难性的遗忘问题。
 BEGIN1如何做到持续学习(Continual Learning)?
BEGIN1如何做到持续学习(Continual Learning)?
深度学习领域一直以来都存在着“灾难性遗忘”(Catastrophic Forgetting)的难题,它指的是利用神经网络当学习一个新任务的时候,需要更新网络中的参数,但是上一个任务提取出来的知识也是储存在这些参数上的,于是每当学习新的任务就会把学习旧任务得到的知识给遗忘掉,做不到像人类那样在学习中可以利用先前学习过的经验和知识,快速地进行相似技能的学习。
当人工神经网络在多个任务上连续训练时,它们会遭受灾难性遗忘。为了克服这一问题,本文提出了一种基于任务条件超网络的新方法,即基于任务身份生成目标模型权重的网络。由于一个简单的关键特性,连续学习(CL)对于这类模型来说不那么困难:任务条件超网络不需要回忆所有先前看到的数据的输入-输出关系,而只需要排练特定于任务的权重实现,可以使用一个简单的正则化器将其保存在内存中。除了在标准的CL基准上达到最先进的性能外,对长任务序列的额外实验还表明,任务条件超网络显示出保留以前记忆的巨大容量。值得注意的是,当可训练超网络权值的数目与目标网络大小相当或小于目标网络大小时,在压缩状态下实现了很长的存储寿命。本文深入研究了低维任务嵌入空间(超网络的输入空间)的结构,并证明了任务条件超网络具有转移学习的能力。
2超网络(Hypernetworks)持续学习方法在苏黎世联邦理工学院以及苏黎世大学的这项工作中,最重要的是对超网络(Hypernetworks)的应用。在介绍超网络的连续学习之前,我们先对超网络做一下介绍。超网络是一个非常有名的网络,简单说就是用一个网络来生成另外一个网络的参数,工作原理是:用一个超网络输入训练集数据,然后输出对应模型的参数,最好的输出是这些参数能够使得在测试数据集上取得好的效果。简单来说超网络其实就是一个Meta network。传统的做法是用训练集直接训练这个模型,但是如果使用超网络则不用训练,抛弃反向传播与梯度下降,直接输出参数,这等价于超网络学会了如何学习图像识别。
作者使用 Hypernetwork 生成 RNN 的权重,发现能为 LSTM 生成非共享权重,并在字符级语言建模、手写字符生成和神经机器翻译等序列建模任务上实现最先进的结果。超网络采用一组包含有关权重结构的信息的输入,并生成该层的权重,如下图所示。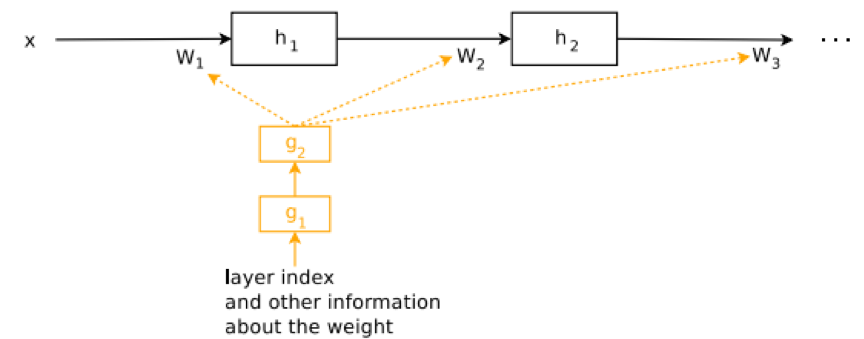 超网络生成前馈网络的权重:黑色连接和参数与主网络相关联,而橙色连接和参数与超网络相关联。超网络的连续学习模型在整个工作中,首先假设输入的数据{X(1),......X(T)}是可以被储存的,并能够使用输入的数据计算Θ(T 1)。另外,可以将未使用的数据和已经使用过数据进行混合来避免遗忘。假设F(X,Θ)是模型,那么混合后的数据集为{(X(1),Y(1)),。。。,(X(T1),Y(T1)),(X(T),Y(T))},其中其中Y(T)是由模型f(.,Θ(t1))生成的一组合成目标。然而存储数据显然违背了连续学习的原则,所以在论文中作者提出了一种新的元模型fh(e(t),Θh)做为解决方案,新的解决方案能够将关注点从单个的数据输入输出转向参数集{Θ(T)},并实现非储存的要求。这个元模型称为任务条件超网络,主要思想是建立任务e(t)和权重Θ的映射关系,能够降维处理数据集的存储,大大节省内存。模型主要有三个部分:模型的第一部分:任务条件超网络。首先,超网络会将目标模型参数化,即不是直接学习特定模型的参数,而是学习元模型的参数,从而元模型会输出超网络的权重,也就是说超网络只是权重生成器。
超网络生成前馈网络的权重:黑色连接和参数与主网络相关联,而橙色连接和参数与超网络相关联。超网络的连续学习模型在整个工作中,首先假设输入的数据{X(1),......X(T)}是可以被储存的,并能够使用输入的数据计算Θ(T 1)。另外,可以将未使用的数据和已经使用过数据进行混合来避免遗忘。假设F(X,Θ)是模型,那么混合后的数据集为{(X(1),Y(1)),。。。,(X(T1),Y(T1)),(X(T),Y(T))},其中其中Y(T)是由模型f(.,Θ(t1))生成的一组合成目标。然而存储数据显然违背了连续学习的原则,所以在论文中作者提出了一种新的元模型fh(e(t),Θh)做为解决方案,新的解决方案能够将关注点从单个的数据输入输出转向参数集{Θ(T)},并实现非储存的要求。这个元模型称为任务条件超网络,主要思想是建立任务e(t)和权重Θ的映射关系,能够降维处理数据集的存储,大大节省内存。模型主要有三个部分:模型的第一部分:任务条件超网络。首先,超网络会将目标模型参数化,即不是直接学习特定模型的参数,而是学习元模型的参数,从而元模型会输出超网络的权重,也就是说超网络只是权重生成器。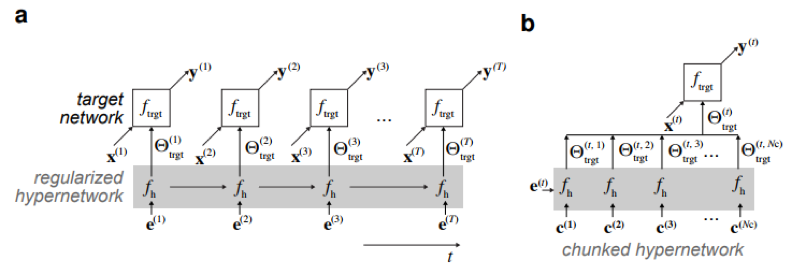 a:正则化后的超网络生成目标网络权重参数;b:迭代地使用较小的组块超网络产生目标网络权重。然后利用带有超网络的连续学习输出正则化。在论文中,作者使用两步优化过程来引入记忆保持型超网络输出约束。首先,计算Θh(Θh的计算原则基于优化器的选择,本文中作者使用Adam),即找到能够最小化损失函数的参数。注:Θ h是模型学习之前的超网络的参数; 模型的第二部分:用分块的超网络进行模型压缩。超网络产生目标神经网络的整个权重集。然而,超网络可以迭代调用,在每一步只需分块填充目标模型中的一部分。这表明允许应用较小的可重复使用的超网络。有趣的是,利用分块超网络可以在压缩状态下解决任务,其中学习参数(超网络的那些)的数量实际上小于目标网络参数的数量。
a:正则化后的超网络生成目标网络权重参数;b:迭代地使用较小的组块超网络产生目标网络权重。然后利用带有超网络的连续学习输出正则化。在论文中,作者使用两步优化过程来引入记忆保持型超网络输出约束。首先,计算Θh(Θh的计算原则基于优化器的选择,本文中作者使用Adam),即找到能够最小化损失函数的参数。注:Θ h是模型学习之前的超网络的参数; 模型的第二部分:用分块的超网络进行模型压缩。超网络产生目标神经网络的整个权重集。然而,超网络可以迭代调用,在每一步只需分块填充目标模型中的一部分。这表明允许应用较小的可重复使用的超网络。有趣的是,利用分块超网络可以在压缩状态下解决任务,其中学习参数(超网络的那些)的数量实际上小于目标网络参数的数量。
模型的第三部分:上下文无关推理,未知任务标识(context-free inference: unknown task identity)。从输入数据的角度确定要解决的任务。超网络需要任务嵌入输入来生成目标模型权重。在某些连续学习的应用中,由于任务标识是明确的,或者可以容易地从上下文线索中推断,因此可以立即选择合适的嵌入。在其他情况下,选择合适的嵌入则不是那么容易。
3实验结果基准测试作者使用MNIST、CIFAR10和CIFAR-100公共数据集对论文中的方法进行了评估。评估主要在两个方面:(1)研究任务条件超网络在三种连续学习环境下的记忆保持能力,(2)研究顺序学习任务之间的信息传递。具体的在评估实验中,作者根据任务标识是否明确出了三种连续学习场景:CL1,任务标识明确;CL2,任务标识不明确,并不需明确推断;CL3,任务标识可以明确推断出来。另外作者在MNIST数据集上构建了一个全连通的网络。在CIFAR实验中选择了ResNet-32作为目标神经网络。为了进一步说明论文中的方法,作者考虑了四个连续学习分类问题中的基准测试:非线性回归,Permuted MNIST,Split-MNIST,Split CIFAR-10/100。非线性回归的结果如下:
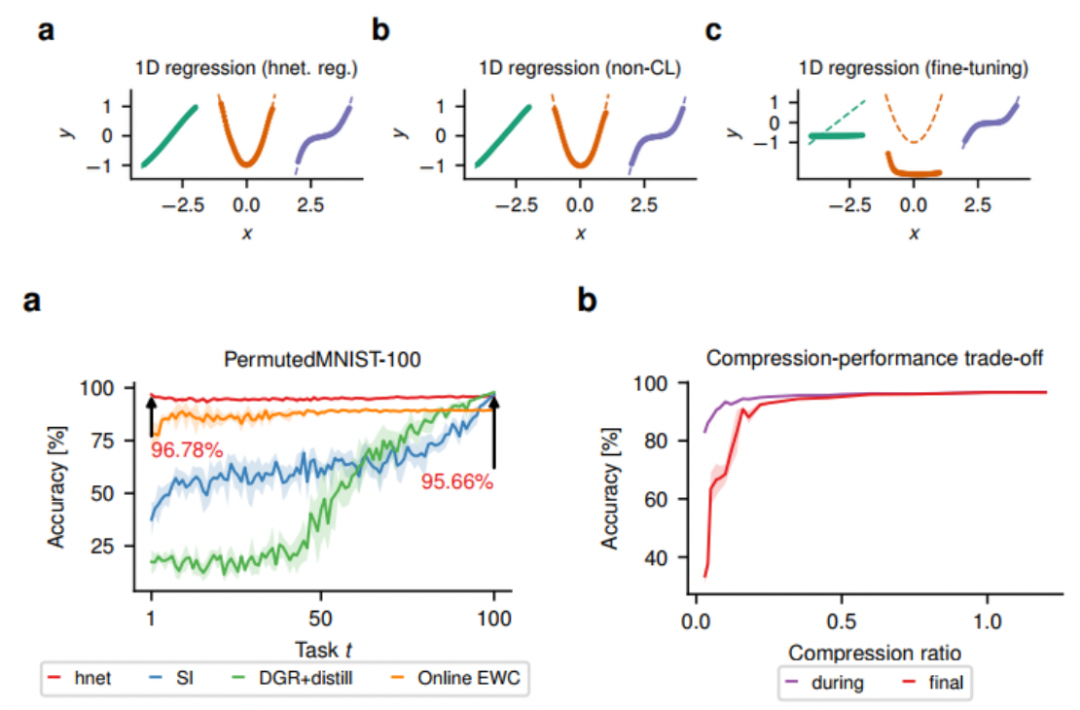 a:即使在低维度空间下仍然有着高分类性能,同时没有发生遗忘;b:即使最后一个任务占据着高性能区域,并在远离嵌入向量的情况下退化情况仍然可接受,其性能仍然较高。
a:即使在低维度空间下仍然有着高分类性能,同时没有发生遗忘;b:即使最后一个任务占据着高性能区域,并在远离嵌入向量的情况下退化情况仍然可接受,其性能仍然较高。
在CIFAR实验中,作者选择了ResNet-32作为目标神经网络,在实验过程中,作者发现运用任务条件超网络基本完全消除了遗忘,另外还会发生前向信息反馈,这也就是说与从初始条件单独学习每个任务相比,来自以前任务的知识可以让网络表现更好。
总结本篇论文提出了一种新的神经网络模型---超网络,它非常适合于持续学习问题。该方法具有可扩展性和通用性,可作为独立的持续方法或与生成重放方法结合使用。研究结果表明任务条件下的超网络可以实现长的记忆寿命以及将信息传输到未来的任务,这是持续学习者的两个基本特征。作为深度学习2.0中的一个重要方向,持续学习如果能够让模型具有了像人一样的联想记忆能力,真正的“人工智能”距离我们将不再遥远了。参考文献:
https://3g.163.com/all/article/F2QO2Q350511DPVD.html
https://www.researchgate.net/publication/333600619_Continual_learning_with_hypernetworks


喜欢本篇内容请给我们点个在看哟


openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)