
人工智能大作业
设计估价函数(编程语言不限),以八数码为例演示A*算法的搜索过程,争取做到直观、清晰地演示算法,代码要适当加注释。八数码问题:在3×3方格棋盘上,分别放置了标有数字1, 2, 3, 4, 5, 6, 7, 8的八张牌,初始状态S0根据题目要求设定,使用的操作有: 空格上移,空格左移,空格右移,空格下移。试采用A*算法写程序实现这一搜索过程。
目录
大作业1:八数码问题的A*搜索算法实现
设计估价函数(编程语言不限),以八数码为例演示A*算法的搜索过程,争取做到直观、清晰地演示算法,代码要适当加注释。
八数码问题:在3×3方格棋盘上,分别放置了标有数字1, 2, 3, 4, 5, 6, 7, 8的八张牌,初始状态S0根据题目要求设定,使用的操作有: 空格上移,空格左移,空格右移,空格下移。试采用A*算法写程序实现这一搜索过程。
- 设置相同的初始状态和目标状态,针对不同的估价函数,求得问题的解,比较它们对搜索算法性能的影响,包括扩展节点数、生成节点数等,填入表1。
- 设置与上述1相同的初始状态和目标状态,用宽度优先搜索算法(即令估计代价h(n)=0的A*算法)求得问题的解,以及搜索过程中的扩展节点数、生成节点数,填入表1。
|
启发函数h(n) |
|||
|
不在位数 |
哈密顿距离 |
0 |
|
|
初始状态 |
283164705 |
283164705 |
283164705 |
|
目标状态 |
123804765 |
123804765 |
123804765 |
|
最优解 |
283164705 283014765 203184765 023184765 123084765 123804765 |
283164705 283104765 203184765 023184765 123084765 123804765 |
283164705 283104765 203184765 023184765 123084765 123804765 |
|
扩展节点数 (不包括叶子节点) |
6 |
5 |
5 |
|
生成节点数 (包含叶子节点) |
13 |
11 |
11 |
|
运行时间 (迭代次数) |
5 |
5 |
5 |
表1不同启发函数h(n)求解8数码问题的结果比较
运行情况
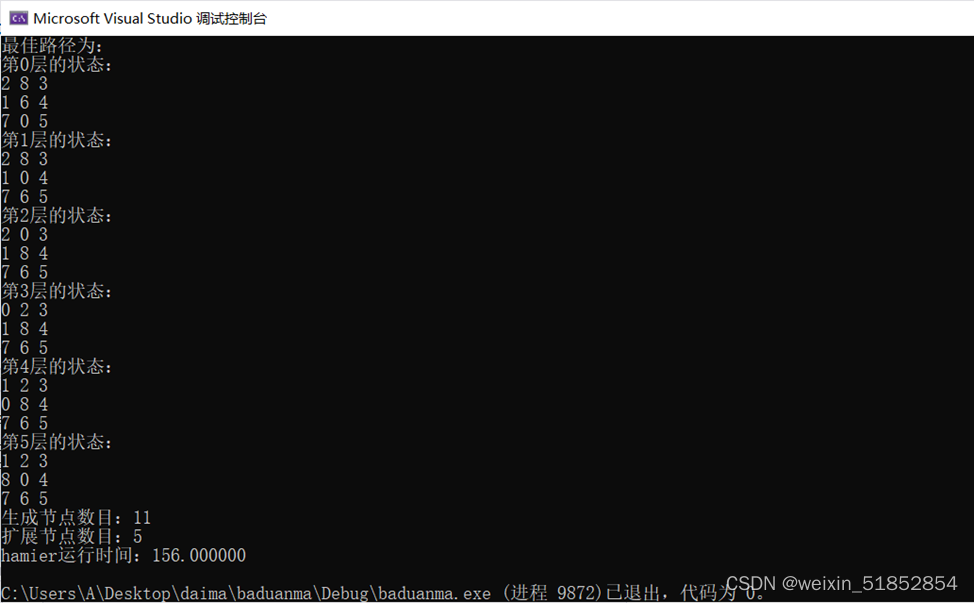
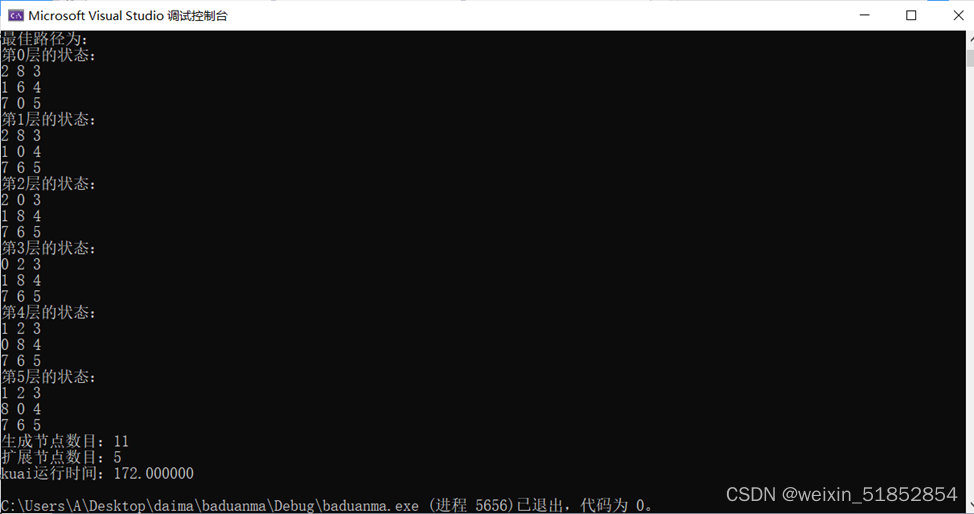
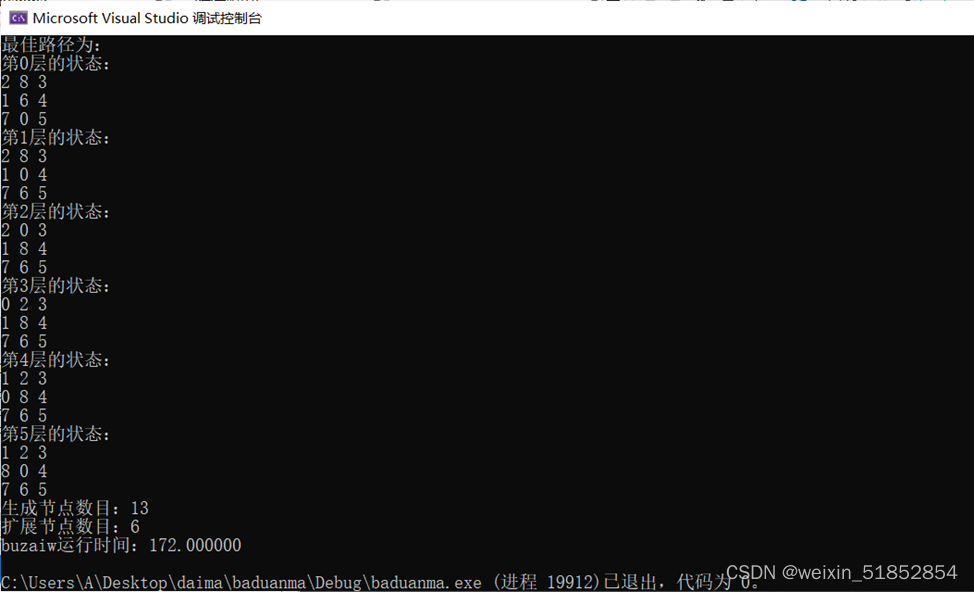
1. 画出[2, 8, 3], [1, 6, 4], [7, 0, 5]推导至[1, 2, 3], [8, 0, 4], [7, 6, 5]的图解。(拍照、截屏粘贴即可)
答:哈密顿算法:
宽度算法:
不在位算法:
算法影响
- 分析不同的估价函数对A*算法性能的影响。
答:
A*算法是一种在静态路网中求解最短路径的有效算法,通俗地讲,它不是像深度优先搜索算法和广度优先搜索算法一样的傻瓜式的埋头搜索,它是先对当前的情况进行分析,得到最有可能的一个分支,然后在该分支上进行扩展,然后将扩展的结果放在之前的大环境中进行比较,再选取最有可能的分支进行扩展,直到找到最终状态。A*算法的核心是估价函数的选取(通俗的说就是对当前情况的评价方式的选取,通过什么方式选取的分支才是最有可能离最终状态最近的分支)。所以搜索路径一般较短。
不在位数使用当前不在目标位置的数目作为代价函数,哈密顿使用当前位置与目标位置的距离和作为代价函数,两者都能有较短的搜索路径。
BFS:是一种宽度优先的算法,会把接下来所有节点搜索出来,对于解决最短或最少问题特别有效,而且寻找深度小,但缺点是内存耗费量大(需要开大量的数组单元用来存储状态)。
总的来说,宽度优先需要较高的算法性能,A*算法根据使用算法不同有所差异,但A*算法所需性能较低,运算较快。
- 根据宽度优先搜索算法和A*算法求解8数码问题的结果,分析启发式搜索的特点。
答:如果某一问题有解,那么利用A*搜索算法对该问题进行搜索则一定能搜索到解,并且一定能搜索到最优的解而结束。
具有可采纳性,信息性,单调性特点。
源程序
#include "iostream"
#include "stdlib.h"
#include "conio.h"
#include <math.h>
#include <windows.h>
#define size 3
using namespace std;
//定义二维数组来存储数据表示某一个特定状态
typedef int status[size][size];
struct SpringLink;
//定义状态图中的结点数据结构
typedef struct Node
{
status data;//结点所存储的状态 ,一个3*3矩阵
struct Node* parent;//指向结点的父亲结点
struct SpringLink* child;//指向结点的后继结点
struct Node* next;//指向open或者closed表中的后一个结点
int fvalue;//结点的总的路径
int gvalue;//结点的实际路径
int hvalue;//结点的到达目标的困难程度
}NNode, * PNode;
//定义存储指向结点后继结点的指针的地址
typedef struct SpringLink
{
struct Node* pointData;//指向结点的指针
struct SpringLink* next;//指向兄第结点
}SPLink, * PSPLink;
PNode open;
PNode closed;
//OPEN表保存所有已生成而未考察的节点,CLOSED表中记录已访问过的节点
//开始状态与目标状态
/*
status startt = {1,3,0,8,2,4,7,6,5};最佳路径为2
status startt = {1,3,0,2,8,4,7,6,5};迭代超过20000次,手动停止
status startt = {2,8,3,1,6,4,7,0,5};
status startt = {2,8,3,6,0,4,1,7,5}; //实验报告
*/
int t = 0; //迭代次数,相当于运行时间
int count_extendnode = 0;//扩展结点
int count_sumnode = 0; //生成节点
status startt = { 2,8,3,1,6,4,7,0,5 }; //实验报告
status target = { 1,2,3,8,0,4,7,6,5 };
//初始化一个空链表
void initLink(PNode& Head)
{
Head = (PNode)malloc(sizeof(NNode));
Head->next = NULL;
}
//判断链表是否为空
bool isEmpty(PNode Head)
{
if (Head->next == NULL)
return true;
else
return false;
}
//从链表中拿出一个数据
void popNode(PNode& Head, PNode& FNode)
{
if (isEmpty(Head))
{
FNode = NULL;
return;
}
FNode = Head->next;
Head->next = Head->next->next;
FNode->next = NULL;
}
//向结点的最终后继结点链表中添加新的子结点
void addSpringNode(PNode& Head, PNode newData)
{
PSPLink newNode = (PSPLink)malloc(sizeof(SPLink));
newNode->pointData = newData;
newNode->next = Head->child;
Head->child = newNode;
}
//释放状态图中存放结点后继结点地址的空间
void freeSpringLink(PSPLink& Head)
{
PSPLink tmm;
while (Head != NULL)
{
tmm = Head;
Head = Head->next;
free(tmm);
}
}
//释放open表与closed表中的资源
void freeLink(PNode& Head)
{
PNode tmn;
tmn = Head;
Head = Head->next;
free(tmn);
while (Head != NULL)
{
//首先释放存放结点后继结点地址的空间
freeSpringLink(Head->child);
tmn = Head;
Head = Head->next;
free(tmn);
}
}
//向普通链表中添加一个结点
void addNode(PNode& Head, PNode& newNode)
{
newNode->next = Head->next;
Head->next = newNode;
}
//向非递减排列的链表中添加一个结点(已经按照权值进行排序)
void addAscNode(PNode& Head, PNode& newNode)
{
PNode P;
PNode Q;
P = Head->next;
Q = Head;
while (P != NULL && P->fvalue < newNode->fvalue)
{
Q = P;
P = P->next;
}
//上面判断好位置之后,下面就是简单的插入了
newNode->next = Q->next;
Q->next = newNode;
}
//计算结点的 h 值 f=g+h. 按照不在位的个数进行计算
int computeHValue(PNode theNode)
{
int num = 0;
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
if (theNode->data[i][j] != target[i][j])
num++;
}
}
return num;
}
/*
//计算结点的 h 值 f=g+h. 按照将牌不在位的距离和进行计算
int computeHValue(PNode theNode)
{
int num = 0;
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
if (theNode->data[i][j] != target[i][j] && theNode->data[i][j] != 0) {
for (int ii = 0; ii < 3; ii++) {
for (int jj = 0; jj < 3; jj++) {
if (theNode->data[i][j] == target[ii][jj]) {
num += abs(ii - i) + abs(jj - j);
break;
}
}
}
}
}
}
return num;
}
*/
//计算结点的f,g,h值
void computeAllValue(PNode& theNode, PNode parentNode)
{
if (parentNode == NULL)
theNode->gvalue = 0;
else
theNode->gvalue = parentNode->gvalue + 1;
theNode->hvalue = computeHValue(theNode);
//theNode->hvalue = 0;
theNode->fvalue = theNode->gvalue + theNode->hvalue;
}
//初始化函数,进行算法初始条件的设置
void initial()
{
//初始化open以及closed表
initLink(open);
initLink(closed);
//初始化起始结点,令初始结点的父节点为空结点
PNode NULLNode = NULL;
PNode Start = (PNode)malloc(sizeof(NNode));
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
Start->data[i][j] = startt[i][j];
}
}
Start->parent = NULL;
Start->child = NULL;
Start->next = NULL;
computeAllValue(Start, NULLNode);
//起始结点进入open表
addAscNode(open, Start);
}
//将B节点的状态赋值给A结点
void statusAEB(PNode& ANode, PNode BNode)
{
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
ANode->data[i][j] = BNode->data[i][j];
}
}
}
//两个结点是否有相同的状态
bool hasSameStatus(PNode ANode, PNode BNode)
{
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
if (ANode->data[i][j] != BNode->data[i][j])
return false;
}
}
return true;
}
//结点与其祖先结点是否有相同的状态
bool hasAnceSameStatus(PNode OrigiNode, PNode AnceNode)
{
while (AnceNode != NULL)
{
if (hasSameStatus(OrigiNode, AnceNode))
return true;
AnceNode = AnceNode->parent;
}
return false;
}
//取得方格中空的格子的位置
void getPosition(PNode theNode, int& row, int& col)
{
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
if (theNode->data[i][j] == 0)
{
row = i;
col = j;
return;
}
}
}
}
//交换两个数字的值
void changeAB(int& A, int& B)
{
int C;
C = B;
B = A;
A = C;
}
//检查相应的状态是否在某一个链表中
bool inLink(PNode spciNode, PNode theLink, PNode& theNodeLink, PNode& preNode)
{
preNode = theLink;
theLink = theLink->next;
while (theLink != NULL)
{
if (hasSameStatus(spciNode, theLink))
{
theNodeLink = theLink;
return true;
}
preNode = theLink;
theLink = theLink->next;
}
return false;
}
//产生结点的后继结点(与祖先状态不同)链表
void SpringLink(PNode theNode, PNode& spring)
{
int row;
int col;
getPosition(theNode, row, col);
//空的格子右边的格子向左移动
if (col != 2)
{
PNode rlNewNode = (PNode)malloc(sizeof(NNode));
statusAEB(rlNewNode, theNode);
changeAB(rlNewNode->data[row][col], rlNewNode->data[row][col + 1]);
if (hasAnceSameStatus(rlNewNode, theNode->parent))
{
free(rlNewNode);//与父辈相同,丢弃本结点
}
else
{
rlNewNode->parent = theNode;
rlNewNode->child = NULL;
rlNewNode->next = NULL;
computeAllValue(rlNewNode, theNode);
//将本结点加入后继结点链表
addNode(spring, rlNewNode);
}
}
//空的格子左边的格子向右移动
if (col != 0)
{
PNode lrNewNode = (PNode)malloc(sizeof(NNode));
statusAEB(lrNewNode, theNode);
changeAB(lrNewNode->data[row][col], lrNewNode->data[row][col - 1]);
if (hasAnceSameStatus(lrNewNode, theNode->parent))
{
free(lrNewNode);//与父辈相同,丢弃本结点
}
else
{
lrNewNode->parent = theNode;
lrNewNode->child = NULL;
lrNewNode->next = NULL;
computeAllValue(lrNewNode, theNode);
//将本结点加入后继结点链表
addNode(spring, lrNewNode);
}
}
//空的格子上边的格子向下移动
if (row != 0)
{
PNode udNewNode = (PNode)malloc(sizeof(NNode));
statusAEB(udNewNode, theNode);
changeAB(udNewNode->data[row][col], udNewNode->data[row - 1][col]);
if (hasAnceSameStatus(udNewNode, theNode->parent))
{
free(udNewNode);//与父辈相同,丢弃本结点
}
else
{
udNewNode->parent = theNode;
udNewNode->child = NULL;
udNewNode->next = NULL;
computeAllValue(udNewNode, theNode);
//将本结点加入后继结点链表
addNode(spring, udNewNode);
}
}
//空的格子下边的格子向上移动
if (row != 2)
{
PNode duNewNode = (PNode)malloc(sizeof(NNode));
statusAEB(duNewNode, theNode);
changeAB(duNewNode->data[row][col], duNewNode->data[row + 1][col]);
if (hasAnceSameStatus(duNewNode, theNode->parent))
{
free(duNewNode);//与父辈相同,丢弃本结点
}
else
{
duNewNode->parent = theNode;
duNewNode->child = NULL;
duNewNode->next = NULL;
computeAllValue(duNewNode, theNode);
//将本结点加入后继结点链表
addNode(spring, duNewNode);
}
}
}
//输出给定结点的状态
void outputStatus(PNode stat)
{
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
cout << stat->data[i][j] << " ";
}
cout << endl;
}
}
//输出最佳的路径
void outputBestRoad(PNode goal)
{
int deepnum = goal->gvalue;
if (goal->parent != NULL)
{
outputBestRoad(goal->parent);
}
cout << "第" << deepnum-- << "层的状态:" << endl;
outputStatus(goal);
}
void AStar()
{
PNode tmpNode = NULL;//指向从open表中拿出并放到closed表中的结点的指针
PNode spring;//tmpNode的后继结点链
PNode tmpLNode;//tmpNode的某一个后继结点
PNode tmpChartNode;
PNode thePreNode;//指向将要从closed表中移到open表中的结点的前一个结点的指针
bool getGoal = false;//标识是否达到目标状态
long numcount = 1;//记录从open表中拿出结点的序号
initial();//对函数进行初始化
initLink(spring);//对后继链表的初始化
tmpChartNode = NULL;
//Target.data=target;
cout << "1" << endl;
PNode Target = (PNode)malloc(sizeof(NNode));
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
Target->data[i][j] = target[i][j];
}
}
cout << "1" << endl;
cout << "从open表中拿出的结点的状态及相应的值" << endl;
while (!isEmpty(open))
{
t++;
//从open表中拿出f值最小的元素,并将拿出的元素放入closed表中
popNode(open, tmpNode);
addNode(closed, tmpNode);
count_extendnode = count_extendnode + 1;
cout << "第" << numcount++ << "个状态是:" << endl;
outputStatus(tmpNode);
cout << "其f值为:" << tmpNode->fvalue << endl;
cout << "其g值为:" << tmpNode->gvalue << endl;
cout << "其h值为:" << tmpNode->hvalue << endl;
/* //如果拿出的元素是目标状态则跳出循环
if(computeHValue(tmpNode) == 0)
{ count_extendnode=count_extendnode-1;
getGoal = true;
break;
}*/
//如果拿出的元素是目标状态则跳出循环
if (hasSameStatus(tmpNode, Target) == true)
{
count_extendnode = count_extendnode - 1;
getGoal = true;
break;
}
//产生当前检测结点的后继(与祖先不同)结点列表,产生的后继结点的parent属性指向当前检测的结点
SpringLink(tmpNode, spring);
//遍历检测结点的后继结点链表
while (!isEmpty(spring))
{
popNode(spring, tmpLNode);
//状态在open表中已经存在,thePreNode参数在这里并不起作用
if (inLink(tmpLNode, open, tmpChartNode, thePreNode))
{
addSpringNode(tmpNode, tmpChartNode);
if (tmpLNode->gvalue < tmpChartNode->gvalue)
{
tmpChartNode->parent = tmpLNode->parent;
tmpChartNode->gvalue = tmpLNode->gvalue;
tmpChartNode->fvalue = tmpLNode->fvalue;
}
free(tmpLNode);
}
//状态在closed表中已经存在
else if (inLink(tmpLNode, closed, tmpChartNode, thePreNode))
{
addSpringNode(tmpNode, tmpChartNode);
if (tmpLNode->gvalue < tmpChartNode->gvalue)
{
PNode commu;
tmpChartNode->parent = tmpLNode->parent;
tmpChartNode->gvalue = tmpLNode->gvalue;
tmpChartNode->fvalue = tmpLNode->fvalue;
freeSpringLink(tmpChartNode->child);
tmpChartNode->child = NULL;
popNode(thePreNode, commu);
addAscNode(open, commu);
}
free(tmpLNode);
}
//新的状态即此状态既不在open表中也不在closed表中
else
{
addSpringNode(tmpNode, tmpLNode);
addAscNode(open, tmpLNode);
count_sumnode += 1;//生成节点
}
}
}
//目标可达的话,输出最佳的路径
if (getGoal)
{
cout << endl;
cout << "最佳路径长度为:" << tmpNode->gvalue << endl;
cout << "最佳路径为:" << endl;
outputBestRoad(tmpNode);
}
//释放结点所占的内存
freeLink(open);
freeLink(closed);
// getch();
}
int main()
{
double start = GetTickCount();
AStar();
printf("生成节点数目:%d\n", count_sumnode);
printf("扩展节点数目:%d\n", count_extendnode);
printf("buzaiw运行时间:%f\n", GetTickCount() - start);
return 0;
}八数码问题也称为九宫问题。在3×3的棋盘,摆有八个棋子,每个棋子上标有1至8的某一数字,不同棋子上标的数字不相同。棋盘上还有一个空格,与空格相邻的棋子可以移到空格中。要求解决的问题是:给出一个初始状态和一个目标状态,找出一种从初始转变成目标状态的移动棋子步数最少的移动步骤。
问题注意的关键在:
1.open是一个单向链表,存储的是可以由初始节点由若干步达到的可能节点(我们忽略节点Node中的previous),其是按照代价估计(f+g)从小 到大排序的。
2.close的结构比较特殊,如果从头到尾顺序看(忽略 节点Node中的previous)是一个单向链表,从尾向前看(忽略节点Node中的next),是一个倒向的树。(因为要输出最终的节点转移过程,所以必须要记录每一个节点是由哪一个节点扩展来的,虽然一个节点可以由很多节点扩展而来,但是别忘了我们之前说的,只记录从初始节点到当前节点最短的那条路径,update函数所做的事),虽然结构有点混乱,但是顺看的链表和倒看的倒树并不相互影响,链表只是为了方便节点的管理。
3.最后输出结果的过程弄乱了close的结构,只保留了我们要输出的这条路径线。
该代码段的缺点:
内存回收比较难,内存都是只申请不释放。
我们求得的只是较短的路径,但未必是最短的路径。
大作业2:产生式系统设计
实验目的
1. 熟悉知识的表示方法
2. 掌握产生式系统的运行机制
3. 产生式系统推理的基本方法
实验内容
设计并编程实现一个小型产生式系统(如分类、诊断等类型)。
实验要求
1. 具体应用领域自选,具体系统名称自定。
2. 用一阶谓词逻辑和产生式规则作为知识表示,利用产生式系统实验程序,建立知识库,分别运行正、反向推理。
实验报告
1. 系统设置,包括系统名称和系统谓词,给出谓词名及定义。
系统使用动物作为库存

2. 编辑知识库,通过输入规则或修改规则等,建立规则库。
相关推理规则

3. 建立事实库(综合数据库),输入多条事实或结论。
手动输入事实
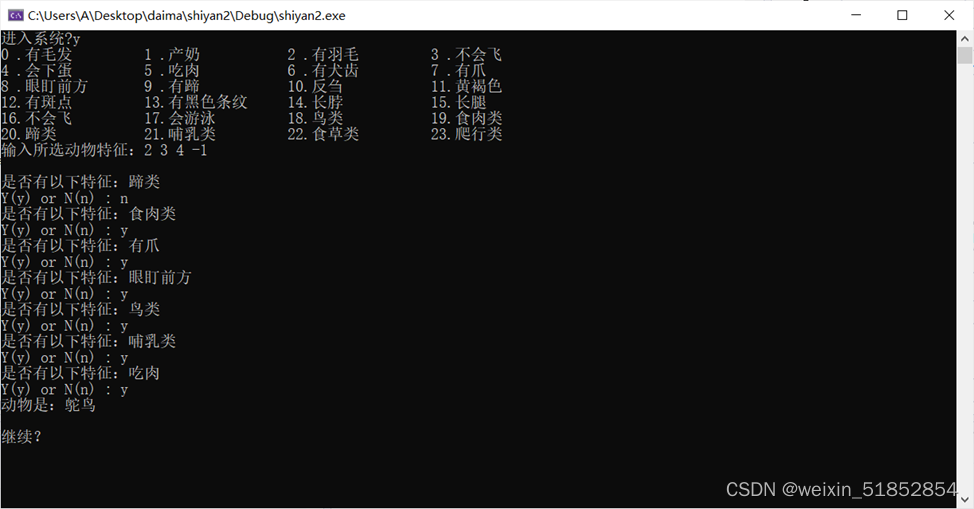
4. 运行推理,包括正向推理和反向推理,给出相应的推理过程、事实区和规则区。
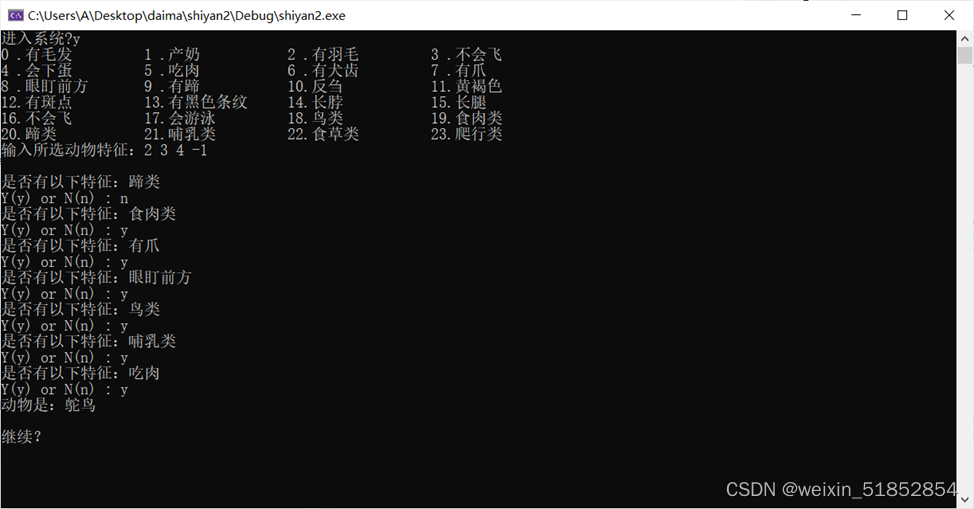
规则区见上图
五. 心得体会
设计步骤包括:
(1)创建数据库
系统的实现首先应该创建一个植物数据库,将个体特征信息拆分为以下三个部分再创建数据库,三个部分分别是:
1)实现将个体名称的信息导入数据库
2)实现个体特征的定义,并将信息导入数据库
3)将个体与个体特征结合起来,产生一个关于个体或其他信息的规则,将规则导入数据库
(2)编写系统运行时要用的算法
产生式系统的实现有三种方法:
1)正向推理:
2)逆向推理:
3)双向推理:
首先确定系统的实现方法为哪一种,进行算法的编写,再定义并构造系统所需要的其他函数,例如:计算置信度、重置置信度、排序算法等。
(3)设计流程及输入输出显示
系统的功能实现除了必备的数据库及核心算法等,还应该具备一个具有输入输出提示的界面,在输入特征时可以显示数据库的特征,提示使用者进行下一步的操作,以及其他功能,例如:停止输入、清屏等。
系统完成情况:
(1)基本功能实现
系统创建了数据库、规则库,并对一条规则的结束标志做出了规定。
该系统已经能基本满足对输入的特征给出相应的回答,通过双向推理的方法判断是否有该植物,并询问补充特征,完成对数据库的数据访问。
(2)用户操作实现
可以实现系统较为流畅的操作,用户可根据系统所给提示较好的完成特征输入,并根据提示补全特征以及进行继续操作或退出操作。
缺点:
本系统的规则库是静态的,不能很好的进行增删改操作,这使得在实际运用是不便于系统数据库的修改和维护,对于系统功能更方便地实现增加了一定难度。
大作业3:基于遗传算法的优化问题
遗传算法是一种通过模拟自然进化过程搜索最优解的方法,将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程。在求解较为复杂的组合优化问题时,相对一些常规的优化算法,通常能够较快地获得较好的优化结果。
随着网络购物的蓬勃发展,现代快递物流配送系统是一个城市提高其公共运输能力的关键。其中,车辆路径优化问题是城市配送系统(City Delivery System, CDS)的重要环节,通过对车辆行驶路径的优化管理可以有效地降低城市配送成本,同时可以提高城市交通效率,节省公共资源,无论对企业还是对社会,都具有重要的意义。本作业针对CDS的车辆路径规划问题,采用遗传算法(Genetic Algorithm, GA)作为优化方法,提出一种配送车辆路径规划的设计方案,以实现车辆路径选取的最优决策。
假设有一个无人配送物流车要送往N个快递站,它必须选择所要走的路径,路径的限制是每个快递站只能拜访一次,而且最后要回到原来出发的快递站(假设快递站之间的距离为坐标间的直线距离)。路径的选择目标是要求得的路径路程为所有路径之中的最小值。
用遗传算法求解不同规模(如10个快递站,20个快递站,50个快递站)的CDS问题,快递站坐标随机生成,不限制实现算法语言(可使用C++、Python、Matlab等),在报告内附关键代码以及详细注释。
画出遗传算法求解CDS问题的流程图。
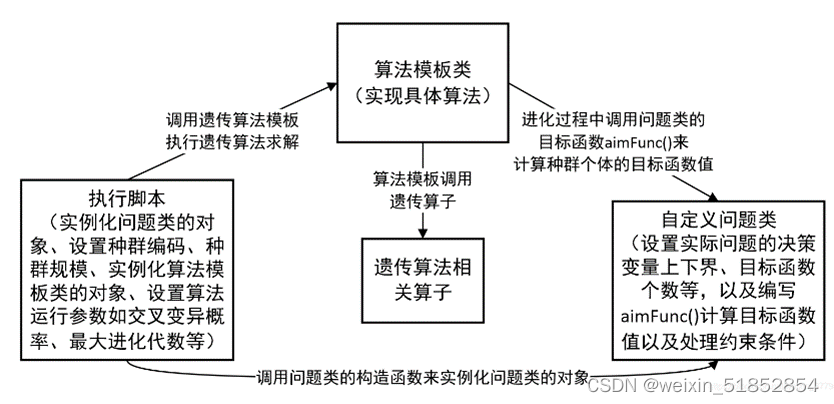
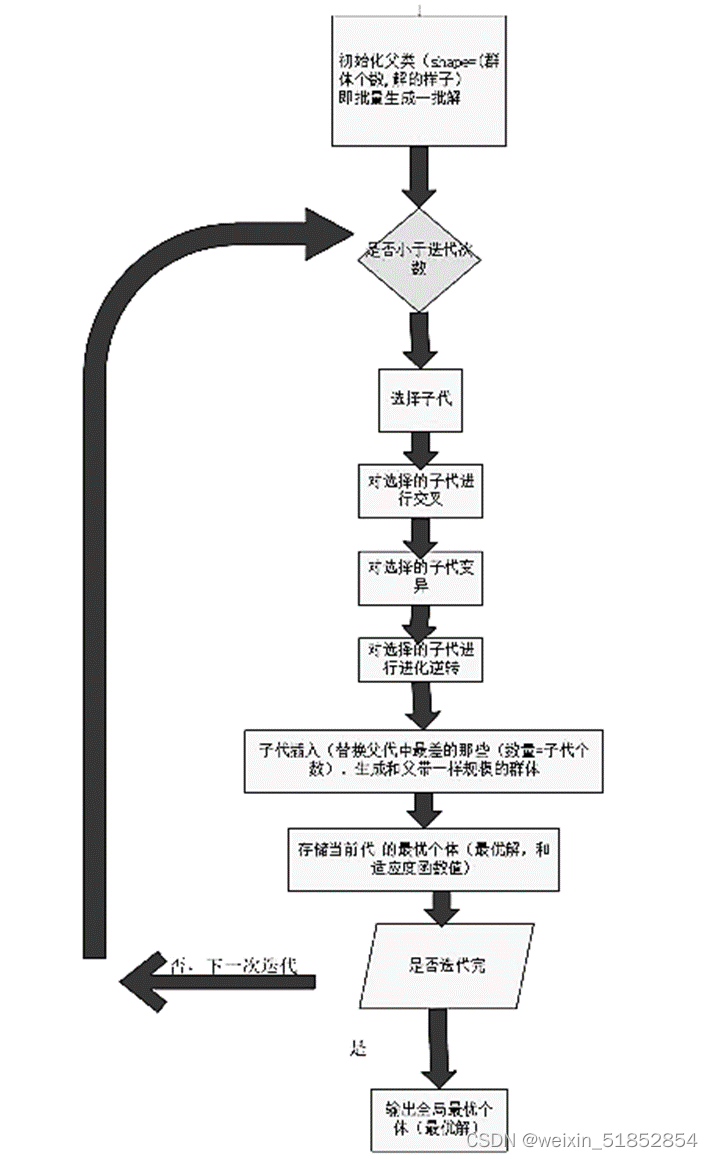
考虑10个城市的求解时间:
加载并使用cProfile模块
cProfile是python标准库中一个使用便捷、开销合理的 C 扩展,适用于分析长时间运行的程序。
在本次实验中使用改模块完成对程序的性能分析。
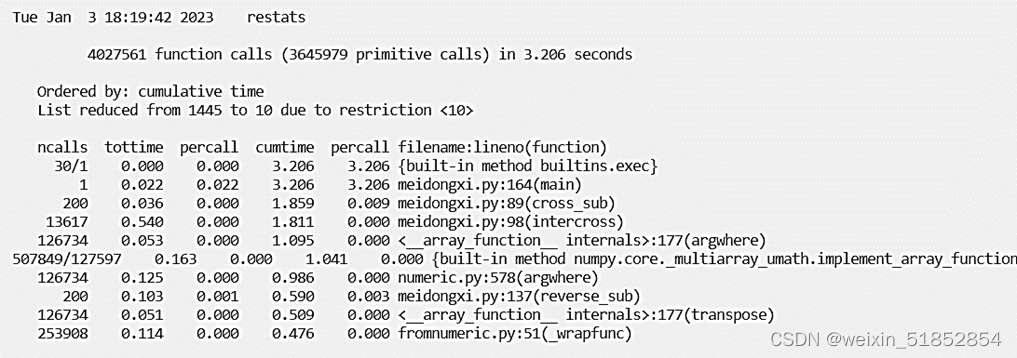
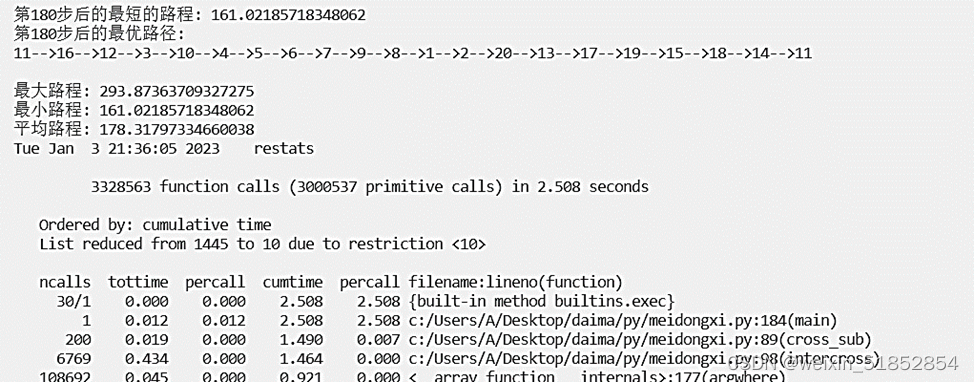
考虑20个城市的求解时间:
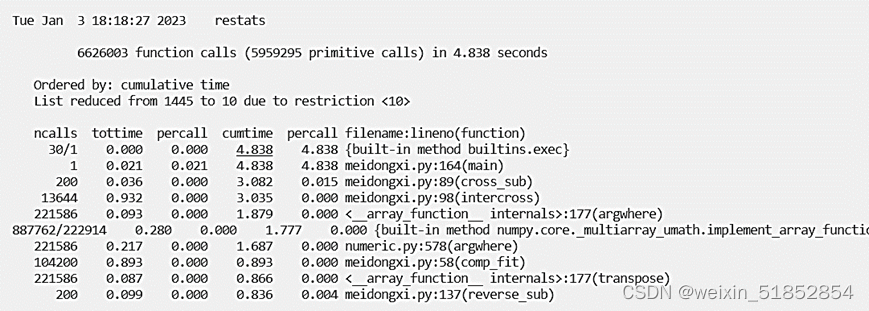
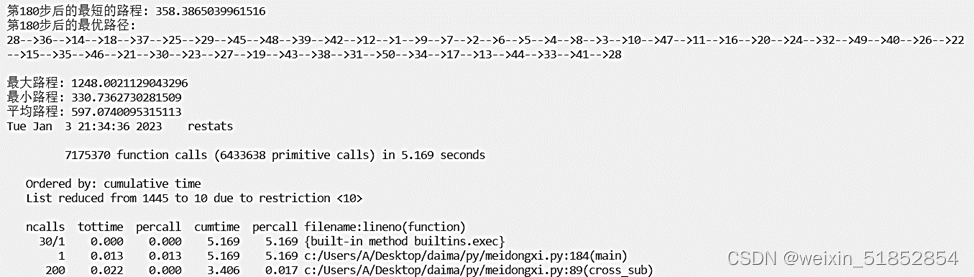
考虑50个城市的求解时间:
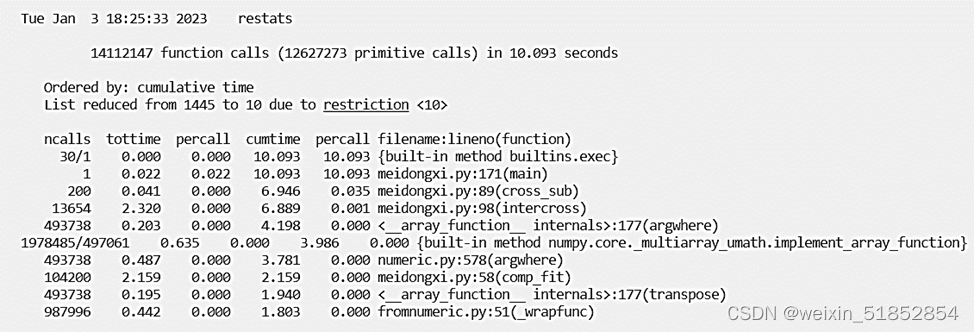
对于同一个CDS问题(快递站数量及对应坐标不变),对比分析种群规模、交叉概
率和变异概率对算法结果的影响。
配送体系规模:10
配送体系规模:20
配送体系规模50
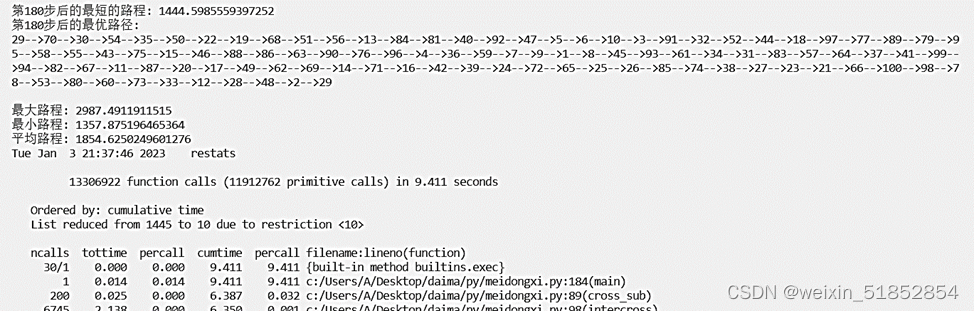
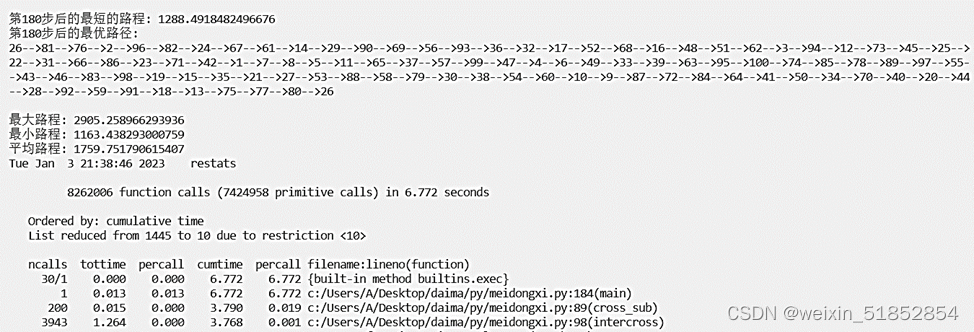
配送体系规模:100 交叉概率0,变异概率0.15
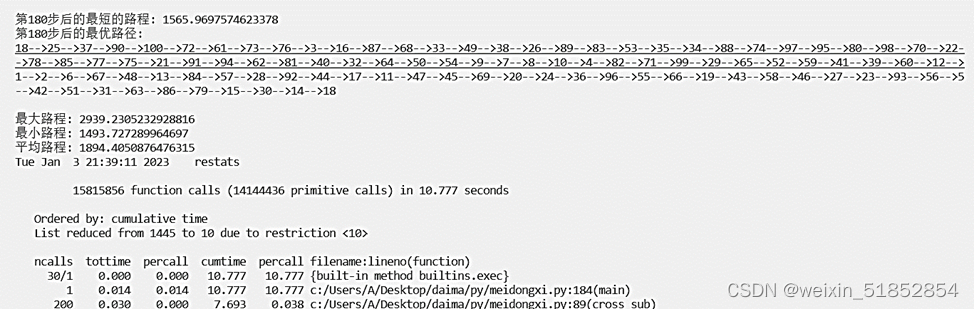
交叉概率0.5,变异概率0.15
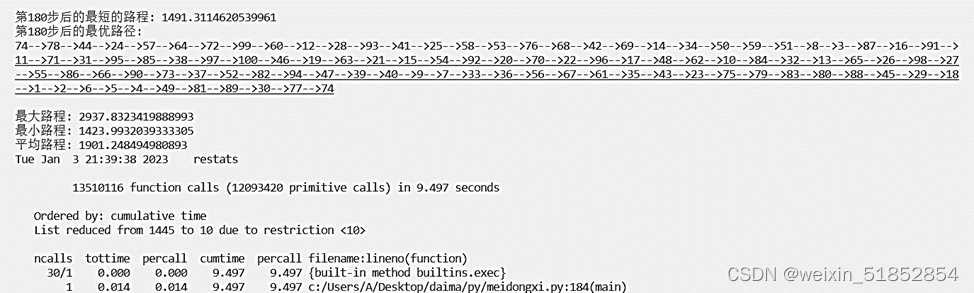
交叉概率1,变异概率0.15
交叉概率0.85,变异概率0
交叉概率0.85,变异概率0.5
交叉概率0.85,变异概率1
液压随动 扩张状态观测器
4. 心得体会。
|
配送体系规模 |
最好适应度 |
最差适应度 |
平均适应度 |
平均运行时间 |
|
10 |
0.044569238 |
0.033328 |
0.043873 |
1.684 |
|
20 |
0.006210332 |
0.003403 |
0.005608 |
2.508 |
|
50 |
0.00302356 |
0.000801 |
0.001675 |
5.169 |
表1 遗传算法求解不同规模的CDS问题的结果
|
种群规模 |
交叉概率 |
变异概率 |
最好适应度 |
最差适应度 |
平均适应度 |
平均运行时间 |
|
10 |
0.85 |
0.15 |
0.044569238 |
0.033328 |
0.043873 |
1.684 |
|
20 |
0.85 |
0.15 |
0.006210332 |
0.041887 |
5.61E-06 |
2.508 |
|
100 |
0.85 |
0.15 |
0.000736445 |
0.000335 |
0.000539 |
9.411 |
|
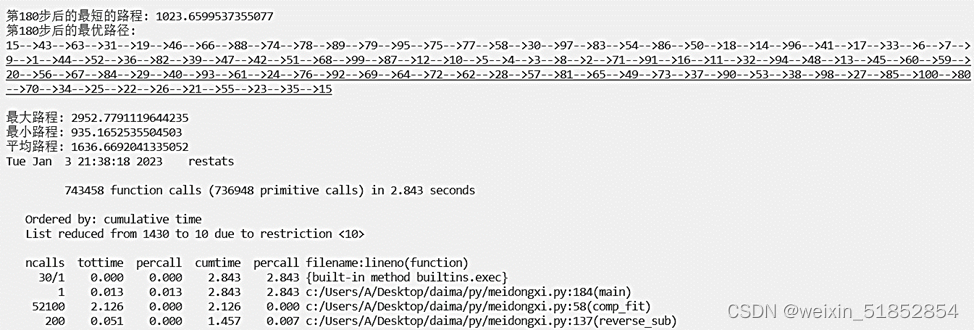
100 |
0 |
0.15 |
0.00106933 |
0.000339 |
0.000611 |
2.843 |
|
100 |
0.5 |
0.15 |
0.000859522 |
0.000344 |
0.000568 |
6.772 |
|
100 |
1 |
0.15 |
0.000669466 |
0.00034 |
0.000528 |
10.777 |
|
100 |
0.85 |
0 |
0.000702251 |
0.00034 |
0.000526 |
9.497 |
|
100 |
0.85 |
0.5 |
0.000633912 |
0.000342 |
0.000498 |
9.555 |
|
100 |
0.85 |
1 |
0.00068316 |
0.000336 |
0.000514 |
9.628 |
表2不同的种群规模、交叉概率和变异概率的求解结果
|
变异策略 |
个体选择概率分配 |
最好适应度 |
最差适应度 |
平均适应度 |
平均运行时间 |
|
两点互换 |
按适应度 |
0.000845717 |
0.000334 |
0.000608 |
7.436 |
|
翻转变异 |
按适应度比例分配 |
0.000851847 |
0.000345 |
0.000553 |
9.422 |
表3 不同的变异策略和个体选择概率分配策略的求解结果
代码:
#import geatpy as ea
#print(ea.__version__)
#print('hello')
from math import floor
import numpy as np
import matplotlib.pyplot as plt # 导入所需要的库
import cProfile
import pstats
from pstats import SortKey
class Gena_TSP(object):
def __init__(self ,data ,maxgen=200 ,size_pop=100 ,cross_prob=0.85 ,pmuta_prob=0.15 ,select_prob=0.8):
self.maxgen = maxgen # 最大迭代次数
self.size_pop = size_pop # 群体个数
self.cross_prob = cross_prob # 交叉概率
#self.pmuta_prob = pmuta_prob # 变异概率
self.select_prob = select_prob # 选择概率
self.data = data # 城市的左边数据
self.num =len(data) # 城市个数 对应染色体长度
# 距离矩阵n*n, 第[i,j]个元素表示城市i到j距离matrix_dis函数见下文
self.matrix_distance = self.matrix_dis()
# 通过选择概率确定子代的选择个数
self.select_num = max(floor(self.size_pop * self.select_prob + 0.5), 2)
# 父代和子代群体的初始化(不直接用np.zeros是为了保证单个染色体的编码为整数,np.zeros对应的数据类型为浮点型)
self.chrom = np.array([0] * self.size_pop * self.num).reshape(self.size_pop, self.num)#父 print(chrom.shape)(200, 14)
self.sub_sel = np.array([0] * self.select_num * self.num).reshape(self.select_num, self.num)#子 (160, 14)
# 存储群体中每个染色体的路径总长度,对应单个染色体的适应度就是其倒数 #print(fitness.shape)#(200,)
self.fitness = np.zeros(self.size_pop)
self.best_fit = []##最优距离
self.best_path = []#最优路径
# 计算城市间的距离函数 n*n, 第[i,j]个元素表示城市i到j距离
def matrix_dis(self):
res = np.zeros((self.num, self.num))
for i in range(self.num):
for j in range(i + 1, self.num):
res[i, j] = np.linalg.norm(self.data[i, :] - self.data[j, :])#求二阶范数 就是距离公式
res[j, i] = res[i, j]
return res
# 随机产生初始化群体函数
def rand_chrom(self):
rand_ch = np.array(range(self.num)) ## num 城市个数 对应染色体长度 =14
for i in range(self.size_pop):#size_pop # 群体个数 200
np.random.shuffle(rand_ch)#打乱城市染色体编码
self.chrom[i, :] = rand_ch
self.fitness[i] = self.comp_fit(rand_ch)
# 计算单个染色体的路径距离值,可利用该函数更新fittness
def comp_fit(self, one_path):
res = 0
for i in range(self.num - 1):
res += self.matrix_distance[one_path[i], one_path[i + 1]] #matrix_distance n*n, 第[i,j]个元素表示城市i到j距离
res += self.matrix_distance[one_path[-1], one_path[0]]#最后一个城市 到起点距离
return res
# 路径可视化函数
def out_path(self, one_path):
res = str(one_path[0] + 1) + '-->'
for i in range(1, self.num):
res += str(one_path[i] + 1) + '-->'
res += str(one_path[0] + 1) + '\n'
print(res)
# 子代选取,根据选中概率与对应的适应度函数,采用随机遍历选择方法
def select_sub(self):
fit = 1. / (self.fitness) # 适应度函数
cumsum_fit = np.cumsum(fit)#累积求和 a = np.array([1,2,3]) b = np.cumsum(a) b=1 3 6
pick = cumsum_fit[-1] / self.select_num * (np.random.rand() + np.array(range(self.select_num)))#select_num 为子代选择个数 160
i, j = 0, 0
index = []
while i < self.size_pop and j < self.select_num:
if cumsum_fit[i] >= pick[j]:
index.append(i)
j += 1
else:
i += 1
self.sub_sel = self.chrom[index, :]#chrom 父
# 交叉,依概率对子代个体进行交叉操作
def cross_sub(self):
if self.select_num % 2 == 0:#select_num160
num = range(0, self.select_num, 2)
else:
num = range(0, self.select_num - 1, 2)
for i in num:
if self.cross_prob >= np.random.rand():
self.sub_sel[i, :], self.sub_sel[i + 1, :] = self.intercross(self.sub_sel[i, :], self.sub_sel[i + 1, :])
def intercross(self, ind_a, ind_b):#ind_a,ind_b 父代染色体 shape=(1,14) 14=14个城市
r1 = np.random.randint(self.num)#在num内随机生成一个整数 ,num=14.即随机生成一个小于14的数
r2 = np.random.randint(self.num)
while r2 == r1:#如果r1==r2
r2 = np.random.randint(self.num)#r2重新生成
left, right = min(r1, r2), max(r1, r2)#left 为r1,r2小值 ,r2为大值
ind_a1 = ind_a.copy()#父亲
ind_b1 = ind_b.copy()# 母亲
for i in range(left, right + 1):
ind_a2 = ind_a.copy()
ind_b2 = ind_b.copy()
ind_a[i] = ind_b1[i]#交叉 (即ind_a (1,14) 中有个元素 和ind_b互换
ind_b[i] = ind_a1[i]
x = np.argwhere(ind_a == ind_a[i])
y = np.argwhere(ind_b == ind_b[i])
"""
下面的代码意思是 假如 两个父辈的染色体编码为【1234】,【4321】
交叉后为【1334】,【4221】
交叉后的结果是不满足条件的,重复个数为2个
需要修改为【1234】【4321】即修改会来
"""
if len(x) == 2:
ind_a[x[x != i]] = ind_a2[i]#查找ind_a 中元素=- ind_a[i] 的索引
if len(y) == 2:
ind_b[y[y != i]] = ind_b2[i]
return ind_a, ind_b
# 变异模块 在变异概率的控制下,对单个染色体随机交换两个点的位置。
def mutation_sub(self):
for i in range(self.select_num):#遍历每一个 选择的子代
if np.random.rand() <= self.cross_prob:#如果随机数小于变异概率
r1 = np.random.randint(self.num)#随机生成小于num==14 的数
r2 = np.random.randint(self.num)
while r2 == r1:#如果相同
r2 = np.random.randint(self.num)#r2再生成一次
self.sub_sel[i, [r1, r2]] = self.sub_sel[i, [r2, r1]]#随机交换两个点的位置。
# 进化逆转 将选择的染色体随机选择两个位置r1:r2 ,将 r1:r2 的元素翻转为 r2:r1 ,如果翻转后的适应度更高,则替换原染色体,否则不变
def reverse_sub(self):
for i in range(self.select_num):#遍历每一个 选择的子代
r1 = np.random.randint(self.num)#随机生成小于num==14 的数
r2 = np.random.randint(self.num)
while r2 == r1:#如果相同
r2 = np.random.randint(self.num)#r2再生成一次
left, right = min(r1, r2), max(r1, r2)#left取r1 r2中小值,r2取大值
sel = self.sub_sel[i, :].copy()#sel 为父辈染色体 shape=(1,14)
sel[left:right + 1] = self.sub_sel[i, left:right + 1][::-1]#将染色体中(r1:r2)片段 翻转为(r2:r1)
if self.comp_fit(sel) < self.comp_fit(self.sub_sel[i, :]):#如果翻转后的适应度小于原染色体,则不变
self.sub_sel[i, :] = sel
# 子代插入父代,得到相同规模的新群体
def reins(self):
index = np.argsort(self.fitness)[::-1]#替换最差的(倒序)
self.chrom[index[:self.select_num], :] = self.sub_sel
#路径坐标
data = np.array([16.47,96.10,16.47,94.44,20.09,92.54,
22.39,93.37,25.23,97.24,22.00,96.05,20.47,97.02,
17.20,96.29,19.41,97.13,20.09,92.55,26.87,80.51,#11个
23.51,86.23,15.21,65.84,23.51,64.23,27.65,25.41,#15
# 25.51,81.23,17.21,64.84,22.51,64.24,27.61,25.41,#19
# 14.52,75.24,17.56,24.47,22.75,45.74,27.75,25.74,#23个
# 14.28,75.47,17.21,57.21,22.24,42.24,27.24,25.22,#27
# 14.82,74.21,17.85,64.45,22.78,12.24,27.42,25.41,#31
# 14.74,72.85,17.25,67.52,22.56,47.24,27.32,25.77,#35
# 14.71,73.25,17.74,62.24,22.14,12.24,27.74,74.41,#39
# 14.28,71.74,17.82,62.74,22.75,78.24,27.87,23.41,#43
# 14.14,71.14,17.27,61.66,22.15,24.24,27.45,78.41,#47
# 14.87,74.25,17.54,68.65,22.45,45.24,27.74,78.78,#51
# 17.44,72.85,14.25,25.52,27.56,49.24,22.32,23.77,#55
# 17.71,73.25,17.74,62.24,22.14,2.4,27.74,74.41,#59
# 71.52,71.74,17.82,62.74,22.75,78.24,27.87,23.41,#63
# 12.74,71.14,17.27,61.66,22.15,24.24,15.15,78.41,#67
# 25.25,74.25,17.54,68.65,22.45,45.24,27.4,78.78,#71
# 4.17,72.85,17.25,67.52,2.56,7.24,27.32,5.77,#75
# 1.25,73.25,17.74,2.24,2.14,12.24,27.74,4.41,#79
# 14.14,21.74,7.82,62.74,22.75,78.24,27.87,23.27,#83
# 4.45,71.14,7.27,1.66,22.15,24.24,27.45,78.74,#87
# 14.26,25.12,7.54,8.65,2.45,45.24,27.47,78.25,#91
# 14.28,71.74,17.82,62.74,22.75,78.24,27.87,13.25,#95
# 4.14,71.14,7.27,1.66,22.15,24.24,27.45,78.25,#99
# 14.87,12.15#100
]).reshape(15,2)
def main(data):
Path_short = Gena_TSP(data) # 根据位置坐标,生成一个遗传算法类
Path_short.rand_chrom() # 初始化父类
## 绘制初始化的路径图
fig, ax = plt.subplots()
x = data[:, 0]
y = data[:, 1]
ax.scatter(x, y, linewidths=0.1)
for i, txt in enumerate(range(1, len(data) + 1)):
ax.annotate(txt, (x[i], y[i]))
res0 = Path_short.chrom[0]
x0 = x[res0]
y0 = y[res0]
for i in range(len(data) - 1):
plt.quiver(x0[i], y0[i], x0[i + 1] - x0[i], y0[i + 1] - y0[i], color='r', width=0.005, angles='xy', scale=1,
scale_units='xy')
plt.quiver(x0[-1], y0[-1], x0[0] - x0[-1], y0[0] - y0[-1], color='r', width=0.005, angles='xy', scale=1,
scale_units='xy')
plt.show()
print('初始染色体的路程: ' + str(Path_short.fitness[0]))
# 循环迭代遗传过程
for i in range(Path_short.maxgen):
Path_short.select_sub() # 选择子代
Path_short.cross_sub() # 交叉
Path_short.mutation_sub() # 变异
Path_short.reverse_sub() # 进化逆转
Path_short.reins() # 子代插入
# 重新计算新群体的距离值
for j in range(Path_short.size_pop):
Path_short.fitness[j] = Path_short.comp_fit(Path_short.chrom[j, :])
# 每隔三十步显示当前群体的最优路径
index = Path_short.fitness.argmin()
if (i + 1) % 30 == 0:
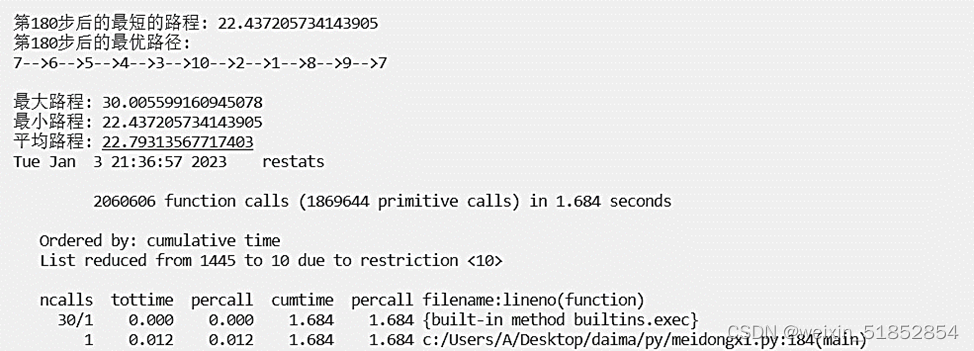
print('第' + str(i + 1) + '步后的最短的路程: ' + str(Path_short.fitness[index]))
print('第' + str(i + 1) + '步后的最优路径:')
Path_short.out_path(Path_short.chrom[index, :]) # 显示每一步的最优路径
# 存储每一步的最优路径及距离
Path_short.best_fit.append(Path_short.fitness[index])
Path_short.best_path.append(Path_short.chrom[index, :])
res1 = Path_short.chrom[0]
x0 = x[res1]
y0 = y[res1]
for i in range(len(data) - 1):
plt.quiver(x0[i], y0[i], x0[i + 1] - x0[i], y0[i + 1] - y0[i], color='r', width=0.005, angles='xy', scale=1,
scale_units='xy')
plt.quiver(x0[-1], y0[-1], x0[0] - x0[-1], y0[0] - y0[-1], color='r', width=0.005, angles='xy', scale=1,
scale_units='xy')
plt.show()
# print(Path_short.best_fit)
a=max(Path_short.best_fit)
b=min(Path_short.best_fit)
c=sum(Path_short.best_fit)/200
print('最大路程: ' +str(a))
print('最小路程: ' +str(b))
print('平均路程: ' +str(c))
return Path_short # 返回遗传算法结果类
# Path_short=main(data)
# print(Path_short.best_fit)
cProfile.run('main(data)','restats')
# 加载保存到restats文件中的性能数据
p = pstats.Stats('restats')
# # 打印所有统计信息
# p.strip_dirs().sort_stats(-1).print_stats()
# 打印累计耗时最多的10个函数
p.sort_stats(SortKey.CUMULATIVE).print_stats(10)
# # 打印内部耗时最多的10个函数(不包含子函数)
# p.sort_stats(SortKey.TIME).print_stats(10)大作业4:基于人工神经网络的图像识别
随着BP神经网络和卷积神经网络的快速发展,基于人工神经网络的图像识别技术赋予了人工智能设备“看”的能力。本课程为培养学生以人工智能相关技术基础从事相关应用研究的能力,例如使用MATLAB深度学习工具箱或Pytorch深度学习框架等深度学习工具训练一个图像识别网络,用于物体分类识别(已提供垃圾分类、猫狗识别、食物识别等数据集至课程群)学生的考核以大作业的形式进行。
本次大作业共分以下三个模块:
1. 基于人工神经网络的图像识别领域前沿技术发展现状(不少于500字)。
2. 复现已有资料的实验或完成一个基于人工神经网络的图像识别的应用课题。
要求:①介绍所完成大作业的基本内容②对所使用算法的工作原理进行分析③介绍所使用的神经网络的结构参数④有实验结果分析与讨论。
3. 心得体会(不少于300字)。
参考资料:
一.基于人工神经网络的图像识别领域前沿技术现状
摘要: 卷积神经网络(CNN)在计算机视觉领域已经取得了前所未有的巨大成功,目前众多传统计算机视觉算法已经被深度学习所替代。由于其巨大的商业落地价值,导致深度学习以及卷积神经网络成为研究的热点,大量优秀的工作不断地涌现。图像识别是计算机视觉领域最核心同时也是最基本的问题,其他的任务如目标检测,图像分割,图像生成,视频理解等都高度依赖于图像识别中的特征表达能力。卷积神经网络在图像识别中的最新进展能够直接影响所有基于深度学习的计算机视觉任务的表现,因此深度了解该进展显得尤其重要。本文首先介绍卷积神经网络的基本模块,接着简要介绍这几年涌现出来的里程碑工作以及他们各自的特点,最后对这些工作进行总结以及给出自己的若干思考。
前言
2016 年 3 月,“人工智能”一词被写入中国“十三五”规划纲要, 2016 年 10 月美国政府发布《美国国家人工智能研究与发展战略规划》文件。Google 、Microsoft、 Facebook、 百度、腾讯、阿里巴巴等各大互联网公司也纷纷加大对人工智能的投入,成立了相应的人工智能实验室。各类人工智能创业公司层出不穷, 各种人工智能应用逐渐改变人类的生活。 深度学习是目前人工智能的重点研究领域之一,应用于人工智能的众多领域,包括语音、计算机视觉、自然语言处理等。
深度学习其实是机器学习的一部分,机器学习经历了从浅层机器学习到深度学习两次浪潮。深度学习模型与浅层机器学习模型之间存在重要区别。 浅层机 器 学习模型不使用分布式表示(distributed representations),而且需要人为提取特征。模型本身只是根据特征进行分类或预测,因此人为提取的特征好坏很大程度上决定了整个系统的好坏。特征提取及特征工程不仅需要专业的领域知识,而且需要花费大量人力物力。深度学习模型是一种表示学习 (representation learning),能够学到数据更高层次的抽象表示,能够自动从数据中提取特征。 另外,深度学习的模型能力会随着深度的增加而呈指数增长。
图像分类,就是对于一个给定的图像,预测它属于哪个类别签。图像是3维数组,数组元素是取值范围从0到255的整数。数组的尺寸是宽度x高度x3,其中这个3代表的是红、绿和蓝3个颜色通道。如图1
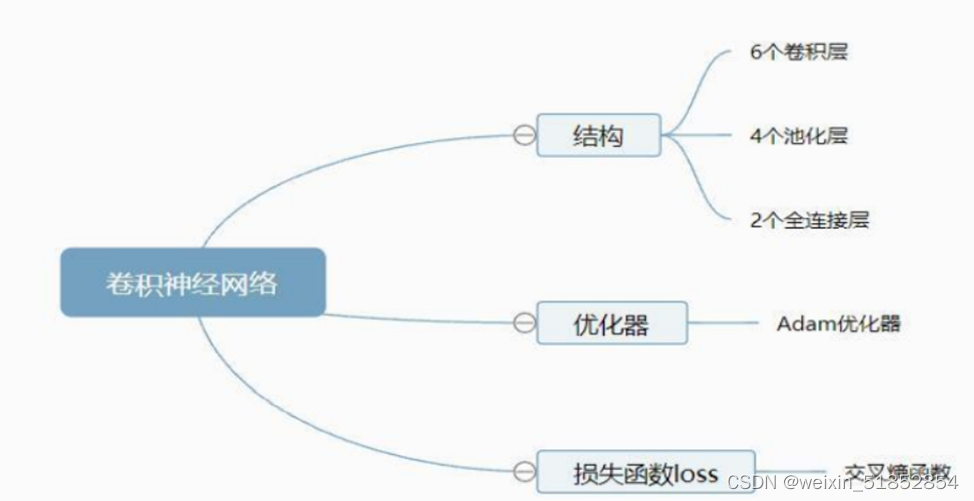
一个简单的卷积神经网络是由各种层按照顺序排列组成,网络中的每个层使用一个可微分的函数将数据从一层传递到下一层。卷积神经网络主要由三种类型的层构成:卷积层,池化层和全连接层。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。如图:
(1)卷积层
卷积层可以说是卷积神经架构中最重要的步骤之一,涉及到特征表达的好坏,同时也是占据我整个网络95%以上的计算量。卷积是一种线性的、平移不变性的运算。
(2)非线性激活单元
非线性激活单元受启发于人类大脑的神经元模型。在神经元模型中,树突将信号传递到细胞体,信号在细胞体中组合相加。如果最终之和高于某个阈值,那么神经元将会激活,向其轴突输出一个峰值信号传递至下一个神经元。
引入非线性激活函数的主要目的是增加神经网络的非线性性。因为如果没有非线性激活函数的话,每一层输出都是上层输入的线性函数,因此,无论神经网络有多少层,得到的输出都是线性函数,这就是原始的感知机模型,这种线性性不利于发挥神经网络的优势。
目前比较常用的有ReLu和LReLu,Logistic(Sigmoid)单元由于其饱和区特性导致整个网络梯度消失而逐渐退出历史舞台。
(3)池化层
通常,在连续的卷积层之间会周期性地插入一个池化层。它的作用是逐渐降低数据体的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。池化层通常使用MAX操作,对输入数据体的每一个切片独立进行操作,改变它的空间尺寸。最常见的形式是使用尺寸2x2的滤波器,以步长为2来对每个深度切片进行降采样,将其中75%的激活信息都丢掉。每个MAX操作是从4个数字中取最大值(也就是在深度切片中某个2x2的区域)。注意在池化的过程中,数据体的通道数保持不变。
(4)全链接层
所谓全链接层即是传统的神经网络,每一个神经单元都和上一层所有的神经单元密集连接。如今,全连接层由于其巨大的参数量易过拟合以及不符合人类对图像的局部感知原理,一般不参与图像的特征提取(已由卷积层替代),只用于最后的线性分类, 相当于在提取的高层特征向量上进行线性组合并且输出最后的预测结果。
- 电力信息化
对于电力系统来说,定期检测电力设备,能够确保系统的正常运转。电力企业通过使用具有智能效果的图像识别技术,可以自动检测电力设备的运转情况,能够保证电力设备的正常运行,在一定程度上能够降低安全事故的出现概率。除此以外,图像识别技术还能够进一步加强电力设备检测系统的自动化管理和智能化管理,可以实时监控电力系统存在的隐蔽型问题,相关工作人员即能够及时解决问题,从而防止出现过多的电力安全事故[1]。
由于图像识别技术的使用过程比较复杂,各个步骤的实施情况,将会直接影响电力设备检测的效率,其可以对准备处理的图像内容实施预先采集工作,在利用数字摄影设备采集图像的过程,图像质量会受到一定的影响,若是技术人员并未实施预处理,会减少图像识别内容的精准性。工作人员在进行预处理时,通常会使用灰度处理,能够有效提高图像的整体质量。
与此同时,工作人员还需要进一步优化图像的识别方式和计算方式,从而加快图像识别的速度。图像识别期间会占据计算机的一部分内存,若是图像识别的总数量过多,甚至会减慢计算机识别的速度,因此工作人员应该不断优化完善计算机的使用性能,并需要不断優化识别算法,能够为提升电力设备检测工作的时效性提供基本保障。
过程包括:图像预处理,选取二值化阈值,识别电力设备,故障分析和判断等。
(2)交通运输领域
图像识别技术在ITS中的应用领域非常广阔,包括道路识别、障碍物检测、车辆检测、车牌识别和车型识别等领域。
道路识别是智能车辆导航中一个具有挑战性的课题,是车辆导航的基础。由于道路情况非常复杂,为使问题简化,研究者们提出了许多关于道路模型的假设,包括道路曲线形状假设,道路宽度及边界平行假设,道路路面平坦假设,路面特征一致假设。目前主要采取下述方法:
(1) 基于区域的道路识别方法;
(2) 基于边缘的道路识别方法;
(3) 基于模板的道路识别方法;
(4) 基于图像滤波的道路识别方法。
技术难点
识别主要面临以下技术上的难点:
1. 由于自然环境下的路面情况比较复杂,导致采集到的车牌图像背景复杂车体本身的干扰,如车辆生产厂家的标志、车体广告、个性车主在车体上的涂鸦等都给图像造成了干扰,都可能会对处理造成影响。
2. 由于采集误差、噪声和光线的影响,使得图像质量较差,而且运动又不同程度地造成了图像的恶化,透视产生了儿何变形,给图像预处理造成了一定的困难。汽车牌照上目标的大小不同,距离不等,目标尺寸不规范,都存在着一定程度的图像仿射变形和模糊大量的随机噪声的干扰,光线、光照角度的不同,造成车牌区域明暗灰度的无规律变化。汽车速度往往也会对车牌识别有较大的影响,汽车速度超过70公里/小时,拍摄的汽车图像会产生模糊、扭曲、变形。
3. 中国的车辆牌照一般由三种字符组成:汉字、英文字符、阿拉伯数字,所以中国的车辆牌照识别远远难于国外的车辆牌照识别。另一方面,车牌具有不同的颜色,主要分为黄底黑字、蓝底白字、黑底白字等三种,字符与车牌背景的灰度比也不一致。所识别的车辆种类繁多、车型、颜色变化多端,这些因素均给车牌识别增加了难度。
4. 为了达到应用的水平,必须要求能够实时地对过往车辆的车牌进行识别,因此算法不能过于复杂。而大多数的传统方法计算量都偏大,根本无法达到实时的要求。这就要求要另辟蹊径,寻求一种快速精确的定位和识别的方法。
5. 在实际情况下由于各类车型不同,大小不同,同一车型的车牌位置不同,加上车身纹理线条复杂,所以在非车牌区域可能形成同车牌区域类似的色彩和纹理,可能导致定位时出现误差。快速准确的找到车牌的位置是一个难题。
6. 字符的粘连处理,字符断裂时的合并,是字符分割的难点。
7. 车牌识别时虽然车牌字符的字符数比较少,字体规范,但也可能导致标准的车牌字符与实际拍摄的车牌字符之间存在较大差距,致使模板的选取存在较大困难。
(3) 医疗
在医疗上进行人工智能的诸多尝试上,能够率先改变现有医疗格局并商业化的莫过于人工智能在医疗影像识别中的使用,其中最主要的两个原因是
1.图像识别本身的算法门槛较低,研究充分,且在许多其他领域有所运用,可以较为方便地迁移到医疗影像的处理上;
2.医疗影像产生了大量的图片数据,数据结构简单,便于用作机器学习的素材。
根据研究,目前医疗影像市场中采用人工智能方法的公司有五十家左右,其中接近一半是近两年成立的,并且有超过三分之一的公司是在美国成立。大部分的投资都在两百万到五百万美元之间,而2016年全年的投资在五千六百万美元左右。这些公司中大约一半的研究方向是全身多区域的影像处理,另一半则集中在特定区域,诸如乳腺,心血管等。
(4)农业
据中国统计年鉴,2016年,我国农业生产总值达5.93万亿元,占GDP的8%,但由农业病害等灾害造成的直接损失达0.503万亿元,占农业生产总值的8.48%。
在农业生产中,农药使用也在急剧增加,农药残留不仅会引发社会问题,还会加剧对环境的污染。因此,对农作物进行准确的病害识别并推荐合适的防治措施,创造出能为植物看病的“医生”,可以挽救农作物的生命,减少农药使用量,保证农作物的产量。
AI与农业病虫害做结合,首先是要建立病虫害的数据集,其次需要机器学习和图像识别系统技术的配合,并且要确保农民使用智能手机的普及率,这样才可以使技术快速有效地传达。
AI监测病虫害主要指利用机器学习、计算机视觉等技术,采用特定的计算机算法和模型,对农业病虫害发生的光谱或图像信号进行挖掘,获得有效的数据特征,实现对病虫害情况的实时识别和鉴定的过程。
农作物病害检测竞赛的发起方、创新工场人工智能工程院执行院长王咏刚认为,目前AI在图像识别领域已非常成熟,并有了相应的数据,将其应用到农业病虫害检测中难度不大。
AI农作物病害检测仅是AI在农业应用的很小一个方面,它的应用领域是非常广泛的。比如农业专家系统,也可以叫农业智能系统,是一个具有大量农业专业知识与经验的计算机系统。应用AI技术可依据一个或多个农业专家提供的特殊领域知识、经验进行推理和判断,模拟农业专家就某一复杂农业问题进行决策。
以上,通过简要介绍了深度学习在图像识别的不断进展和重要工作,可以看到,目前神经网络的设计思路基本上朝着更深,更宽等多个方向同时发展。目前。由于深度学习在图像识别的任务已经超过人类,可见能够很好地从输入映射到隐层地特征表达,并且能够层级式地提取特征并通过最后通过内嵌的分类网络完成分类任务。并且卷积神经网络通过轻量话网络或者模型压缩能够在嵌入式或者移动端运行,已慢慢从实验室走向更多的商业化应用,走进寻常百姓家。
如今,由于最新的神经网络在某个程度上解决了计算机视觉领域特征表达的问题,神经网开始在诸多研究方向如目标检测,图像分割,实例分割,图像生成,人脸识别,车辆识别,人体姿态估计等大方光彩,取得的研究成果也是远超传统算法令人振奋。深度学习或者说卷积神经网络通过刷脸支付,交通天眼系统,无人驾驶等商业应用正在悄悄的改变着我们的生活。
二.基于人工神经网络的图像识别的应用课题相关内容
目的: 实现图像分类,需传入相应的训练集进行训练,保存为另一个模型,然后进行调用使用。
配置环境: pycharm(python3.7),导入pytotch库
知识预备: 需要了解卷积神经网络的基本原理与结构,熟悉pytorch的使用
(1) 收集数据集,利用 python 的 requests 库和 bs4 进行网络爬虫,下载数据集
(2) 搭建卷积神经网络
(3)对卷积神经网络进行训练
(4) 改进训练集与测试集,并扩大数据集
(5) 保存模型
(6) 调用模型进行测试

训练函数:
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device).float().unsqueeze(1)
optimizer.zero_grad()
output = model(data)
# print(output)
loss = F.binary_cross_entropy(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 1 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))验证函数
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device).float().unsqueeze(1)
# print(target)
output = model(data)
# print(output)
test_loss += F.binary_cross_entropy(output, target, reduction='mean').item()
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).to(device)
correct += pred.eq(target.long()).sum().item()
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
实验结果分析与讨论

- 总结
本次实验我学会了:
- 如何在Anaconda虚拟环境下,安装机器学习框架pytorch。
- 如何在pytorch中读入文件夹中的图片数据。并且利用文件夹的名称,给图片打上标记。
- 如何在TuriCreate中训练深度神经网络,以分辨图片。
- 卷积神经网络(Convolutional Neural Network, CNN)的基本构成和工作原理。
但是仍存在问题:
- 不能自行搭建一个神经网络框架,对模型的层次参数完全掌握。
- Pytorch的使用生疏,不了解大致内容。
- 图片识别能力不够,难以进一步优化。
- 心得体会
第四个实验是难度较大的实验,难点主要在两个地方,一是对实验原理的理解,虽然我花费了大量时间,但本次实验只能对实验原理有浅显的理解,还需要实例去应用结合着理解实验。二是实验环境的配置Anaconda虚拟环境的配置花了我较长的时间,并且实验环境之间的逻辑关系也是我未曾接触的,但总归是实现了实验的再现,达到了课程目标。
最后,忠心感谢老师,学长为我们实验的无私付出和帮助我的同学们!
评 语
|
对课程大作业的评语: 总结上述实验,本次大作业比较好的结合了书本知识,将课堂上相当抽象的知识转变为实际的问题,在此要感谢老师们精心挑选的课程任务与课程资料! 我第一次对人工智能的实践有了客观的认识,这也增加了我对人工智能这项技术的兴趣,以后还有很长的路要走,还需学习! |
|
大作业成绩: |
评阅人签名: |
注:1、无评阅人签名成绩无效;
2、必须用钢笔或圆珠笔批阅,用铅笔阅卷无效。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)