
【毕业设计】基于卷积神经网络的鞋子识别 人工智能 深度学习 Python 目标检测
毕业设计选题:鞋子识别数据集旨在支持深度学习项目,尤其是基于YOLO(You Only Look Once)模型的目标检测应用。数据集包含三大类:物体、鞋子和拖鞋。通过收集各种风格、颜色和材质的鞋子图像,我们确保了数据的多样性和代表性,为模型训练提供了丰富的样本。在数据集制作过程中,首先进行了全面的数据采集,确保涵盖不同品牌和款式的鞋子。随后,使用LabelImg等工具对图像进行精确标注,以便于模
一、背景意义
随着电子商务和在线购物的快速发展,鞋类产品的市场需求日益增加。消费者对鞋子的选择不仅仅局限于品牌和价格,更加关注鞋子的款式、颜色和舒适度。因此,如何快速、准确地识别和分类各种鞋子成为了一个重要的研究课题。通过自动化的鞋子识别技术,可以为消费者提供个性化推荐,提升在线购物的便捷性和满意度。例如,用户可以通过上传图片快速找到相似款式的鞋子,从而节省搜索时间。通过对鞋子款式和流行趋势的分析,相关企业可以更好地把握市场动态,进行精准营销和产品设计。
二、数据集
2.1数据采集
首先,需要大量的鞋类图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:选择可靠的数据来源,包括公共数据集、在线购物网站、社交媒体平台等。可以通过网络爬虫技术抓取图片,或者通过开放的API获取相关数据。
-
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。根据预设的分类(物体、鞋子、拖鞋),收集尽可能多的高质量图像。确保图片涵盖不同的款式、颜色、角度和背景,以增强模型的泛化能力。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示鞋类特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
使用LabelImg标注鞋子数据集的过程虽然高效,但面临着复杂性和大量的工作量。数据集包含三大类:物体、鞋子和拖鞋。标注者需要仔细绘制每张图像中目标物体的边界框,以确保准确识别各种鞋子和其他物品。由于图像多样性,标注者需具备专业知识,确保标注一致性,避免因理解差异导致的标注不准确。此外,标注工作量庞大,数千张图像的标注可能耗时数周,并且还需进行复核和修正,以确保数据集质量。这一过程对于后续模型训练的效果至关重要,直接影响鞋子识别的准确性和效率。数据集中包含以下几种类别
- 物品:泛指各种物品或物体,可能包括鞋类物品在内。
- 鞋类:指各种类型的鞋子,包括运动鞋、皮鞋、靴子等不同款式的鞋类物品。
- 拖鞋:一种轻便、舒适的室内穿着鞋,通常用于家居或休闲场合。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 图像格式转换:将收集到的图像转换为统一的格式(如JPEG或PNG),并调整为相同的尺寸,以便于批处理和模型输入。
- 数据增强:通过旋转、缩放、翻转、裁剪等方式对图像进行数据增强,以增加数据集的样本量,提升模型的鲁棒性。
- 归一化处理:对图像像素值进行归一化处理,将其缩放到0到1之间,以加速模型训练过程。
- 划分数据集:将数据集划分为训练集、验证集和测试集,确保每个集的样本能够代表整体数据分布。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)的思想最早由Lecun等人在1998年提出,用于手写字符识别。该网络由多个相互连接的卷积层和全连接层组成,卷积层通过卷积操作和非线性变换处理输入,而全连接层则类似于传统人工神经网络。当时的网络层数仅为5层,但在手写字符识别任务中已取得显著成果。近年来,卷积神经网络迅速发展,在多种图像处理任务中表现出色,同时网络层数也不断增加。

基于卷积神经网络的内容图像检索方法,采用多个卷积层、全连接层及其他优化层构建网络模型。该方法主要包括三个模块:首先,预训练网络模型并对鞋类图像进行微调;其次,建立鞋类图像检索所需的特征库;最后,输入查询鞋子图像进行检索。这一方法为图像检索提供了新的思路和实现路径。
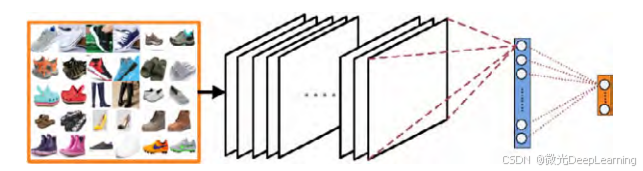
第一步是训练网络模型并通过鞋类图像进行微调,以确保模型能够有效识别相关特征。在获得训练好的模型后,第二步利用该模型提取检索库中图像的特征,从而建立鞋类检索图像的特征库。特征可以视为图像的一种编码方式,近年来的研究表明,卷积神经网络中除输入层和输出层以外的各层能够学习到丰富的图像特征。理论上,网络层数越高,所表示的特征越抽象,能够更好地表征图像内容。因此,选择Inception网络输出层前一层的全连接(FC)层作为图像特征表示。
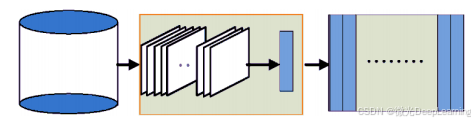
最后,用户可以输入需要查询的鞋子图像,通过训练好的网络提取该图像的特征,实现高效的图像检索。在这一过程中,提取图像特征的方法与建立特征索引库时所采用的方法一致,确保检索的准确性和效率。通过这种方式,系统能够快速匹配查询图像与特征库中的鞋类图像,提高检索的效率与准确性。
3.2模型训练
1. 环境配置
在开始开发YOLO项目之前,首先需要配置合适的开发环境。这通常涉及创建一个新的虚拟环境,以便于管理项目依赖。可以使用Python的venv模块创建虚拟环境,并安装所需的库,例如PyTorch或TensorFlow、OpenCV和其他数据处理库。这一步骤确保了项目的可移植性和依赖关系的清晰,使得后续的开发工作更加高效。
# 创建一个新的虚拟环境
python -m venv yolo_env
source yolo_env/bin/activate # Linux/Mac
# yolo_env\Scripts\activate # Windows
# 安装必要的库
pip install torch torchvision
pip install opencv-python
pip install matplotlib
pip install pandas
pip install tqdm2. 模型训练
环境配置完成后,下一步是使用准备好的数据集进行模型训练。此过程包括选择适当的YOLO模型(如YOLOv5),配置训练参数(如学习率、批量大小和训练轮数),并指定数据集的路径和格式。通过调用训练函数,模型会在数据集上进行多轮训练,不断调整其参数,以提高在特定任务(如鞋子识别)上的性能。训练过程中,模型的损失值和准确率会被持续监控,以评估训练的进展。
import torch
from yolov5 import train
# 设置训练参数
train.run(
data='data.yaml', # 数据集配置文件
imgsz=640, # 输入图像大小
batch=16, # 每批次的图像数量
epochs=50, # 训练的轮数
weights='yolov5s.pt', # 预训练模型
workers=4 # 数据加载线程数
)3. 模型评估
训练完成后,需要对模型的性能进行评估。这通常通过在验证集上测试模型的准确率、召回率和F1分数等指标来实现。评估过程可以帮助识别模型在不同类别上的检测能力,揭示潜在的过拟合问题,从而为后续的模型优化提供依据。此外,使用可视化工具分析模型在测试集上的表现,可以为进一步的改进提供直观的反馈。
from yolov5 import val
# 评估模型
val.run(
weights='runs/train/exp/weights/best.pt', # 最佳模型权重
data='data.yaml', # 数据集配置文件
imgsz=640, # 输入图像大小
conf_thres=0.25, # 置信度阈值
iou_thres=0.45 # IOU阈值
)4. 推理和结果展示
一旦模型经过训练和评估,接下来是使用训练好的模型进行推理,即对新图像进行检测。在这一阶段,加载模型并将其应用于待检测图像,模型会返回检测到的目标及其边界框。通过可视化工具,可以将检测结果在原图上展示出来,直观地显示模型的识别能力。这一步骤不仅有助于验证模型的实际效果,还能为用户提供友好的交互体验。
import cv2
import torch
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/best.pt')
# 读取图像
img = cv2.imread('test_image.jpg')
results = model(img)
# 显示结果
results.show() # 显示检测结果
results.save('output') # 保存结果到output文件夹5. 模型导出与部署
最后一步是将训练好的模型导出为适合实际应用的格式,以便在不同环境中使用。YOLO模型可以导出为多种格式,如ONNX、TorchScript或TensorFlow格式。这一步骤确保模型可以在生产环境中高效运行,支持实时检测或集成到更复杂的应用系统中。导出后的模型可以被部署到服务器、移动设备或边缘计算设备,满足不同场景下的需求。
# 导出模型为ONNX格式
model.export(format='onnx') # 可以导出为其他格式,如TensorFlow等
# 或者保存为TorchScript格式
torchscript_model = torch.jit.trace(model, torch.randn(1, 3, 640, 640)) # 示例输入
torchscript_model.save('yolo_model.pt')
四、总结
鞋子识别系统的开发利用了深度学习技术,特别是YOLO模型,旨在实现高效的鞋类产品检测和分类。数据集的构建是该项目的核心,包含三个主要分类:物体、鞋子和拖鞋。通过对各种风格、颜色和材质的鞋子进行全面的数据采集,我们确保了数据的多样性,为模型训练提供了充分的样本。在数据集制作过程中,使用LabelImg进行精确标注,确保每个图像的标记清晰且一致,提升了数据的质量。这一过程虽然复杂且耗时,但对模型的训练效果至关重要。经过严格的预处理,包括图像格式转换和数据增强,数据集为后续的模型训练奠定了坚实基础。通过该鞋子识别系统,开发者可以实现精准的鞋类检测,提升在线购物的用户体验,助力商家进行更有效的库存管理和市场分析。总之,鞋子识别不仅推动了智能零售的发展,也为时尚行业的创新提供了强有力的技术支持。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 28
28 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)