
【嵌入式开发——Linux操作系统】6内存管理和进程地址空间
MMU、TLB、虚拟内存、段页式管理机制、页表、vm_area_struct、mm_struct
接下来,开始整理Linxu内存、进程相关的内容了(这也是绝大部分操作系统该处理的事情,即内存和任务),本节讲述Linux内存管理MM(Memory Management)的知识,参考链接:https://www.zhihu.com/people/crazyastone/posts
一、内存管理
0 背景知识
MMU(Memory Management Unit)内存管理单元,是一种负责处理CPU内存访问请求的计算机硬件,它的功能包括虚拟地址到物理地址的转换,内存保护,中央处理器高速缓存的控制;
TLB(Translation Lookaside Buffer):MMU的工作时查询页表的过程。如果把页表放在内存中查询的话开销太大,为了提高查找效率,专门用一小片访问更快的区域存放地址映射关系
MMU每次工作时都会遍历表里的关系,找到对应的映射,该过程叫table walk;
Cache:CPU与内存之间的缓存机制,用于提高访问速率,ARM-v8架构中Cache实际是L2 Cache;
CPU运行若干用户空间的进程和内核线程,为了加快性能,CPU中往往设计TLB和Cache这样的HW block。Cache是为了更快访问内存中的数据和指令,TLB是为了加快地址转换,将那些转换最频繁地址保存,无需从页表转换而是直接从高速缓存中获取地址数据。
1 虚拟内存
虚拟内存是内存管理的一种技术,使得应用程序认为它拥有一段连续的内存;操作系统为每个进程分配一套独立的虚拟地址,进程不直接访问物理地址(防止一些破坏性操作,保护操作系统),每个进程拥有4G的虚拟内存,用户程序可使用比实际物理内存更大的空间。
用户空间和内核空间使用的地址都是虚拟地址,当进程访问内存时,会由内核的【请求分页机制】和【缺页异常】调入物理内存页。
把虚拟地址转换成物理地址,需要MMU对虚拟地址进行上图所示的分段和分页(段页式)地址转换。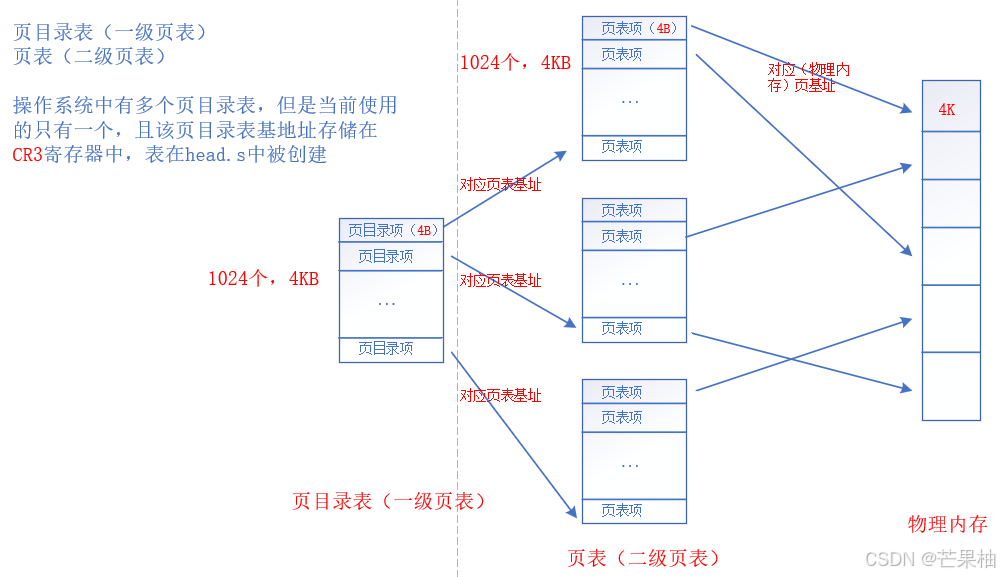
内存地址映射
MMU负责将虚拟地址转换为物理地址,对虚拟地址/逻辑地址进行分段,分页(段页式)地址转换。
逻辑地址—(分段)—线性地址—(分页)—物理地址
线性地址=段基址+逻辑地址,Linux中,省去了段映射(对x86段页式机制没买账)保留了页表机制,段基址为0,如此一来逻辑地址就是线性地址。
Linux的分页机制,通常采用三级页表:
全局页目录项PGD,Page Global Directory;中间页目录项PMD,Page Middle Directory;页表项PTE,Page Table Entry;
从CR3寄存器中读取页目录基址,结合线性地址的第一部分,获取全局页目录项;进一步结合线性地址第二部分,获取中间页目录项;进一步结合线性地址第三部分,获取页表项(也即物理页基址);最后结合线性地址的物理页内偏移量,得到最终实际物理地址。
Linux 操作系统,将虚拟内存划分为内核空间和用户空间。
2 用户空间和内核空间
用户空间:用户进程访问的空间,每个进程都有自己独立的用户空间,虚拟地址范围0x0000 0000-0xBFFF FFFF,总容量3G,用户进程只能访问用户控件的虚拟地址,只有通过系统调用,外设中断或异常才能访问内核空间;
分为以下区域:
text:存放编译好的二进制可执行代码;
data:存放已初始化的数据,包括静态变量,全局变量等;
bss:存放未初始化的数据,包括未初始化的静态变量;
heap堆:malloc分配的下偶爱内存在堆里(用户通过间接调用brk系统调用申请堆);
mmap内存映射区:用于匿名映射中的swap区映射;文件映射;动态链接库。malloc分配的大块内存在mmap里;
stack栈:函数调用链以及函数运行期间产生的局部变量和调用参数,默认大小为8MB。
内核管理这些区域方法是,将这些内存区域抽象成vm_area_struct的内存管理对象,该结构体是描述进程地址空间的基本管理单元,一个进程需要多个vm_area_struct来描述其用户空间虚拟地址,并用【链表】和【红黑树】来组织多个vm_area_struct。
链表用于遍历全部节点用,红黑树适用于在地址空间中定位特定内存区域,内核为了各种操作都有高性能,所以同时使用这两种数据结构。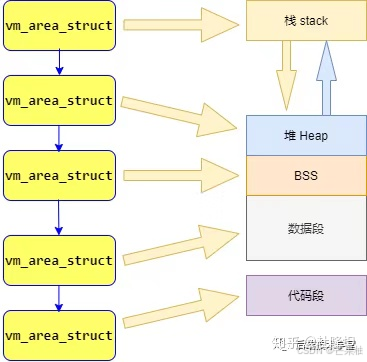
内核空间:LInux内核地址空间虚拟地址范围:0xC000 0000-0xFFFF FFFF,总容量1GB,包括内核镜像、物理页面表、驱动程序等;
分为以下区域:
直接映射区:从内核空间起始地址(0xC000 0000)地址开始,最大896MB内核空间直接映射,即该部分线性地址和分配的物理地址都是连续的。
高端内存线性地址空间:
内核空间线性地址896MB-1GB之间128MB的地址区间是高端内存线性空间,因为内核空间总大小才1GB,如果全部直接映射,那么最多只能寻址1GB大小的物理内存。所以内核后128MB地址区间进一步划分映射区,以达到对整个物理地址范围的寻址。
(1)动态内存映射区:vmalloc Region,该区域由内核函数vmalloc来分配,特点是:线性空间连续,但对应的物理地址空间不一定连续。vmalloc分配的线性地址所对应的物理内存可能处于低端内存,也可能处于高端内存。
每一块vmalloc分配的内核虚拟内存都对应一个vm_struct结构体,不同内核空间虚拟地址之间有4k大小的防越界空闲区间隔区。
(2)永久内存映射区:Persistent Kernel mapping Region,该区域访问高端内存,用过alloc_page分配高端内存页或kmap分配到的高端内存映射到该区域。
(3)固定映射区:Fixed Kernel Mapping Region,该区域和4GB顶端只有4k的隔离带,每个地址项都有特定的用途,如ACPI_BASE等。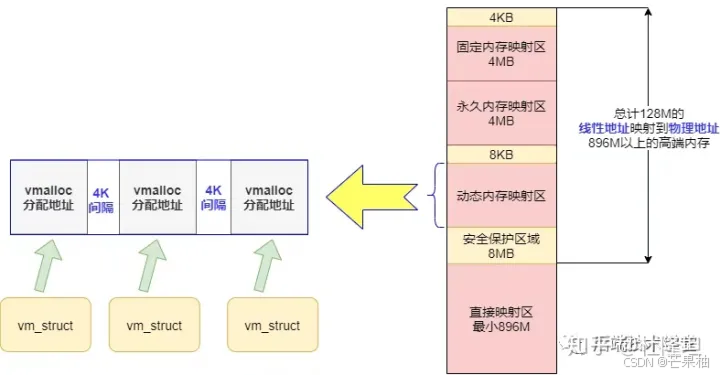
3 Linux内存分配方式
物理内存管理
Linux系统中把物理内存划分为4k大小的内存页Page(也称作页框Page Frame),物理内存的分配和回收都是基于内存页进行。
假如系统请求小块内存,可预先分配一页给它,避免反复申请和释放小块内存带来的频繁系统开销;假如系统请求大块内存,则可用多页拼凑,而不必要求大块连续内存。
面临问题
(1)外部碎片。频繁的分配和回收物理页,导致大量小块内存夹杂在已分配页面中间。
(2)内部碎片。当实际需要很小内存时,也会分配至少4k大小页面,这样会导致页框内部有很多未使用部分。
页面管理算法
(1)伙伴系统算法(Buddy System)
所有的空闲页框分组为11个页块链表,第一个链表有n1个页块,页块大小为1个页;第二个链表有n2个页块,页块大小为2个页;第三个链表有n3个页块,页块大小为4个页;…第十一个链表有n个页块,页块大小为1024个页。(因为任何正整数都可以由2^n的和组成,所以任何大小内存的系统,都可以找到合适的内存块分配方法,减少了外部碎片的产生。)
分配实例
申请4个页框,但是长度为4的连续页框链表中没有空闲页框块,Buddy System会从连续8个页框块的链表中取出一个,将其拆分为2个连续4页框块,其中一个返回给用户,另一个放入连续4页框的空闲链表中。
而释放时候,会检查这几个页框前后页框是否空闲,能否组成下一级长度的块。
(2)slab分配器
一般来讲,内核对象的生命周期是:分配内存-初始化-释放内存,内核中有大量task_struct,file_struct等小对象,远用不到1页内存大小空间;slab分配器,【通过将内存按使用对象不同再进一步划分成不同大小空间】,形成每个数据对象(结构体)slab存储池,每当申请此类对象时,就会从slab列表中分配一个出去;当释放时,重新保存在该列表中,而不是返回给伙伴系统,从而避免内部碎片;同时也提高了内存分配性能。
优点:
slab内存管理基于内核小对象,不用每次分配1内存,充分利用内存空间,避免内部碎片;
slab对内核频繁创建和释放小对象做缓存,重复利用一些相同的对象,减少分配次数。
虚拟内存分配
Linux通过虚拟内存管理,假定每个程序都有4G的虚拟内存寻址空间,虚拟内存(包括用户空间和内核空间)一般没有映射到物理内存,只有当访问申请虚拟内存时,才会发生缺页异常,通过上述伙伴系统和slab分配器申请物理内存。
(1)用户空间内存分配
malloc用于申请用户空间虚拟内存,当申请小于128KB内存时,malloc使用sbrk或brk分配内存;当申请大于128KB内存时,使用mmap函数申请内存;
存在问题:brk/sbrk/mmap属于系统调用,每次申请内存会产生系统调用开销,影响性能,且堆是从低地址往高地址生长,低地址不释放的话,高地址内存不能回收,容易产生碎片。
解决办法:malloc采用内存池的实现方式,先申请一大块内存,再分成不同大小的内存,当用户申请时,直接从内存池中选择一块相近的内存块分配出去。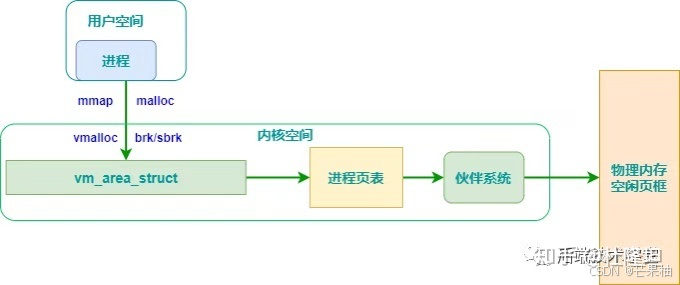
(2)内核空间内存分配
kmalloc和vmalloc分别用于分配不同映射区的虚拟内存。
kmalloc分配的虚拟地址范围在内核空间的【直接内存映射区】,kfree用于释放内存。kmalloc是基于slab分配器的,一般情况下驱动程序中调用该函数,其按字节单位分配虚拟内存,一般用于分配小块内存。
vmalloc分配的虚拟地址区间,位于vmalloc_start和vmalloc_end之间的【动态内存映射区】,一般用于分配大块内存,vfree用于释放,一般用在活动的交换区分配数据结构,为某些I/O驱动程序分配缓冲区,或为内核模块分配空间。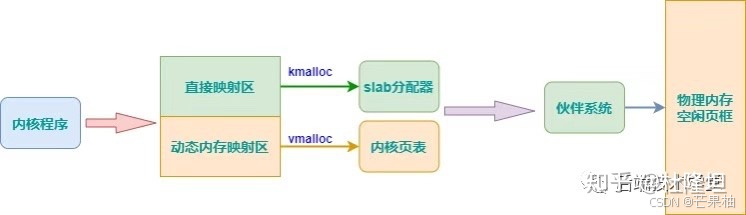
二、进程地址空间
内存是最基本的资源,除了一般数据定义时占据,在运行一个进程/任务时,也是必不可少的资源,接着介绍Linux系统中进程地址空间。
地址空间
进程地址空间由进程可寻址的虚拟内存组成,通过内核,进程可以给自己的地址空间动态地添加或减少内存区域。进程只能访问有效内存区域内的内存地址。每个区域也具有相关权限如对相关进程可读、可写、可执行属性。
内存区域包含各种内存对象,如:
代码段,数据段,bss段,堆,栈,内存映射区。
内存描述符
内核使用内存描述符结构体表示进程的地址空间,该结构体包含了和进程地址空间有关的全部信息,内存描述符由mm_struct结构体表示:
struct mm_struct {
struct vm_area_struct *mmap; /* 内存区域链表 */
struct rb_root mm_rb; /* VMA形成的红黑树 */
struct vm_area_struct *mmap_cache; /* 最近使用的内存区域 */
unsigned long free_area_cache; /* 地址空间第一个空洞 */
pgd_t *pgd; /* 页全局目录 */
atomic_t mm_users; /* 使用地址空间的用户数 */
atomic_t mm_count; /* 主使用计数器 */
int map_count; /* 内存区域个数 */
struct rw_semaphore mmap_sem; /* 内存区域信号量 */
spinlock_t page_table_lock; /* 页表锁 */
struct list_head mmlist; /* 所有mm_struct形成的链表 */
unsigned long start_code; /* 代码段的开始地址 */
unsigned long end_code; /* 代码段的结束地址 */
unsigned long start_data; /* 数据段首地址 */
unsigned long end_data; /* 数据段尾地址 */
unsigned long start_brk; /* 堆首地址 */
unsigned long brk; /* 堆尾地址 */
unsigned long start_stack; /* 栈首地址 */
unsigned long arg_start; /* 命令行参数首地址 */
unsigned long arg_end; /* 命令行参数尾地址 */
unsigned long env_start; /* 环境变量首地址 */
unsigned long env_end; /* 环境变量尾地址 */
unsigned long rss; /* 所分配的物理页 */
unsigned long total_vm; /* 全部页面数 */
unsigned long locked_vm; /* 上锁的页面数 */
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* 保存的auxv */
cpumask_t cpu_vm_mask; /* 懒惰TLB交换掩码 */
mm_context_t context; /* 体系结构特殊数据 */
unsigned long flags; /* 状态标志 */
int core_waiters; /* 内核转储等待线程 */
struct core_state *core_state; /* 内核转储的状态 */
spinlock_t ioctx_lock; /* AIO I/O链表锁 */
struct hlist_head ioctx_list; /* AIO I/O链表 */
};
mmap和mm_rb这两个不同的数据结构体描述的对象是相同的:该地址空间中的全部内存区域。前者以链表形式存放而后者以红黑树形式存放。链表利于简单、高效地遍历所有元素;红黑树更适合搜索指定元素。
所有的mm_struct结构体通过自身的mmlist连接在一个双向链表中,该链表首元素是init_mm内存描述符,它代表init进程的地址空间。
在进程描述符task_struct里,mm成员就是该进程的内存描述符,所以current->mm便指向当前进程的内存描述符。fork()利用copy_mm()复制父进程内存描述符,而子进程中mm_struct实际通过allocate_mm()宏从mm_cache_slab缓存中分配得到。如果希望父进程和子进程共享地址空间,则clone()时,设置CLONE_VM标志,这样这一组父子进程称作线程。共享地址空间几乎是进程和Linux中所谓线程的唯一区别,对Linux来说并不区别对待它们,线程对内核来说只是一个共享特定资源的进程而已。
内核线程没有进程地址空间,即内核线程对应进程描述符中的mm域为空。
虚拟内存区域
内存区域都有一致的属性,如访问权限,相应操作等也一致。这样,**内存区域可以用vm_area_struct(虚拟内存区域)**描述:
struct vm_area_struct {
struct mm_struct *vm_mm; /* 相关的mm_struct结构体 */
unsigned long vm_start; /* 区间首地址 */
unsigned long vm_end; /* 区间尾地址 */
struct vm_area_struct *vm_next; /* VMA链表 */
pgprot_t vm_page_prot; /* 访问控制权限 */
unsigned long vm_flags; /* 标志 */
struct rb_node vm_rb; /* 树上VMA的节点 */
union {
struct{
struct list_head list;
void *parent;
struct vm_area_struct *head;
} vm_set;
struct prio_tree_node prio_tree_node;
} shared;
struct list_head anon_vma_node; /* anon_vma项 */
struct anon_vma *anon_vma; /* 匿名VMA对象 */
struct vm_operations_struct *vm_ops; /* 相关的操作表 */
unsigned long vm_pgoff; /* 文件中的偏移量 */
struct file *vm_file; /* 被映射的文件(如果存在)*/
void *vm_private_data; /* 私有数据 */
};
vm_flags标志内存区域的访问权限和行为信息等,如读写执行权限,区域向上/下增长等。
vm_start指向区间首地址,vm_end指向区间尾地址,vm_end-vm_start的大小就是内存区间的长度,同一进程地址空间的不同内存区间不能重叠。
vm_next域被插入链表,地址按增长方向排序。
内存区域操作
find_vma():给定一个内存地址查找属于哪个区域,该函数在指定地址空间中搜索第一个vm_end大于addr的内存区域,其通过红黑树搜索。
find_vma_prev():和find_vma()工作方式相同,但它返回第一个小于addr的VMA;
find_vma_intersection():返回第一个和指定地址区间相交的VMA。
mmap()和do_mmap()创建地址区间
内核使用do_mmap()创建一个新的线性地址区间,用户空间通过mmap()系统调用获取内核函数do_mmap()的功能。
mummap()和do_mummap()删除地址区间
do_mummap()从特定进程地址空间中删除指定地址区间,用户空间通过mummap()系统调用获取do_mummap()的功能。
页表
应用程序操作的对象时虚拟内存,而处理器直接操作的是物理内存,所以程序访问一个虚拟地址时,需先将虚拟地址转换为物理地址,然后处理器才能解析地址访问请求。地址转换需要硬件MMU查询页表才能完成,由于每次对虚拟内存中的页面访问必须先解析,所以页表性能非常关键。为了加快搜索,多数体系结构都实现一个翻译后备缓冲器(Translate looaside buffer, TLB),TLB是虚拟地址映射物理地址的缓存,当程序访问虚拟地址时,先检查TLB是否缓存了该虚拟地址到物理地址的映射,如果命中,物理地址直接返回,否则就需要接着查询页表搜索物理地址。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)