
嵌入式八股文总结C语言笔记
本文总结了嵌入式开发中C语言的关键知识点,主要内容包括: 关键字详解 const定义只读变量 static定义静态变量/函数 volatile防止编译器优化 typedef定义类型别名 内存管理 三种内存分配方式:静态存储区、栈、堆 内存泄漏原因及检测方法 野指针的危害与防范 核心概念对比 sizeof与strlen 结构体与联合体 指针数组与数组指针 指针函数与函数指针 底层原理 大端/小端模式
const关键字关键字const关键字的作用
有类型的只读的常变量或指针,作用域为类型后面的变量
关键字static的作用
静态变量或函数,程序杀死时变量或函数空间才消失,不能用extern在外部调用
关键字volatile的作用
禁用编译器优化,每一次读写都是有序进行,直接对内存进行操作,变化的快
编译器优化
问al
关键字 typedef的作用
在自己的作用域内给一个已经存在的类型一个别名
中断函数ISR要注意的
不能用返回值
快进快出,不推荐浮点数计算
不可重入函数,不能在ISR中使用
重入函数
重入函数(Reentrant Function)是可以在其执行过程中被中断,并在中断后再次被安全调用的函数。这类函数在多任务环境(如操作系统、中断处理、多线程编程)中至关重要,因为它们能保证在并发执行或嵌套调用时不会产生副作用或数据损坏。
C语言编译的四个步骤
预处理,展开宏和包含头文件,生成.i文件;
编译预处理后的源代码,生成.s文件;
转换为机器码,生成.o文件;
最终生成可执行文件。
隐式类型转换
无符号整型与有符号整型进行运算:
核心原则:向无符号类型转换
int 和 long 的运算规则,类型转换方向:
编译器会向更宽的数据类型转换(即能表示更大范围的类型)
day2
静态存储区分配、栈上分配、堆上分配
内存分配方式对比表
| 特性 | 静态存储区 | 栈上分配 | 堆上分配 |
|---|---|---|---|
| 分配位置 | 程序数据段(.data/.bss) | 函数调用栈 | 动态内存池 |
| 生命周期 | 整个程序运行期间 | 函数/作用域结束即释放 | 显式释放前一直存在 |
| 分配速度 | 极快(编译时确定) | 极快(单指令调整栈指针) | 较慢(需搜索合适内存块) |
| 释放方式 | 程序结束时自动释放 | 自动释放(栈指针回退) | 需手动释放(free/delete) |
| 大小限制 | 编译时固定 | 较小(通常几MB) | 较大(受系统内存限制) |
| 管理方式 | 编译器管理 | 编译器自动管理 | 程序员手动管理 |
| 碎片问题 | 无 | 无 | 可能产生内存碎片 |
| 典型应用 | 全局变量、静态变量、字符串常量 | 局部变量、函数参数 | 动态数据结构、大块内存 |
| 访问速度 | 快 | 最快(通常在CPU缓存中) | 较慢(可能触发缺页中断) |
| 初始化 | 自动初始化为0(BSS段)或指定值 | 未初始化时包含随机值 | 未初始化时包含随机值 |
| 风险 | 无释放风险 | 栈溢出(stack overflow) | 内存泄漏、悬空指针、双重释放 |
静态存储分配:内存在编译程序时就已经分配好了,这块内存在程序的整个运行期间都存在,比如全局变量、静态变量等;
栈上分配:在执行函数时,函数内局部变量的存储单元都可以在栈上创建,栈空间充足的话则正常分配,栈空间不足则提示栈溢出错误;函数执行结束时这些存储单元自动被释放;
从堆上分配:也叫做动态内存分配,程序运行时使用malloc()或new()函数申请的内存就是从堆上分配的,程序员可以自定义申请内存的大小,并且要自己负责在何时调用free()或者delete()函数释放内存,要注意内存泄露的问题。
sizeof 与 strlen 深度解析
核心区别对比表
| 特性 | sizeof 运算符 |
strlen 函数 |
|---|---|---|
| 类型 | 编译时一元运算符 | 运行时库函数 (<string.h>/<cstring>) |
| 作用对象 | 任何数据类型(变量、类型、表达式) | 仅接受以 \0 结尾的字符串 (char*) |
| 返回值 | 对象或类型占用的内存字节数 (size_t) |
字符串中字符的个数(不包括 \0) |
| 计算时机 | 编译时(除变长数组外) | 运行时(扫描内存直到遇到 \0) |
| 参数求值 | 不求值(仅推导类型) | 必须求值(需要有效指针) |
| 处理数组 | 返回整个数组大小 | 返回字符串长度 |
| 处理指针 | 返回指针本身大小 | 需指向有效字符串 |
| 处理结构体 | 返回结构体总大小(含填充字节) | 不适用 |
| 示例 | sizeof(int) → 4 (32位系统) |
strlen("abc") → 3 |
结构体(struct)与联合体(union)
核心区别对比表
| 特性 | 结构体 (struct) | 联合体 (union) |
|---|---|---|
| 内存分配 | 所有成员独立分配内存 | 所有成员共享同一内存区域 |
| 内存大小 | ≥ 所有成员大小之和(含内存对齐填充) | = 最大成员的大小 |
| 成员访问 | 同时访问所有成员 | 同一时间只能有效访问一个成员 |
| 数据存储 | 存储多个独立值 | 存储多个可能值中的当前有效值 |
| 初始化 | 可初始化所有成员 | 只能初始化第一个成员 |
| 应用场景 | 数据聚合、对象表示 | 类型转换、节省内存、变体类型 |
| 安全特性 | 类型安全 | 需要程序员确保访问正确的成员 |
| 内存布局 | 顺序存储 | 所有成员从同一地址开始 |
day3
什么是内存泄漏,内存泄露的原因,如何判断内存泄漏
内存泄漏(Memory Leak)详解
一、内存泄漏的定义
内存泄漏指程序在动态分配内存后,未能正确释放不再使用的内存空间,导致系统可用内存持续减少的现象。如同"只借不还"的借款,这些内存会被程序永久占用,直到程序终止才被操作系统回收
内存泄漏的根本原因
1. 显式分配后未释放
void leak_example() {
int *ptr = (int*)malloc(10 * sizeof(int)); // 分配内存
// ... 使用ptr
// 忘记 free(ptr);
}2. 指针重定向导致丢失原地址
void redirect_leak() {
char *buffer = malloc(256);
buffer = "New string"; // 原内存块地址丢失!
}3. 异常路径未释放
void exception_leak() {
FILE *file = fopen("data.txt", "r");
if (some_error) return; // 提前返回未关闭文件
fclose(file);
}检测内存泄漏的方法
1. 运行时监控工具
| Visual Studio | Windows | 调试器自带内存诊断工具 |
2. 代码级检测技术
// 重载new/delete记录分配点(C++示例)
void* operator new(size_t size, const char* file, int line) {
void* ptr = malloc(size);
log_allocation(ptr, size, file, line); // 记录分配信息
return ptr;
}
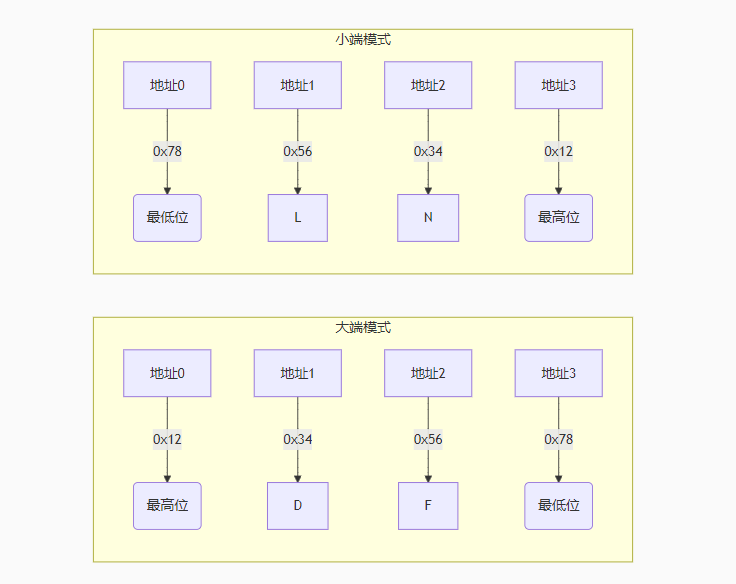
#define DEBUG_NEW new(__FILE__, __LINE__)大端模式与小端模式详解
1. 基本概念
大端模式(Big-Endian)和小端模式(Little-Endian)是两种不同的字节序(Byte Order)存储方式,用于描述多字节数据(如整型、浮点型)在内存中的存储顺序:
| 模式 | 高位字节存储位置 | 低位字节存储位置 | 特点 |
|---|---|---|---|
| 大端模式 | 低内存地址 | 高内存地址 | 符合人类阅读习惯 |
| 小端模式 | 高内存地址 | 低内存地址 | 计算机处理更高效 |
2. 存储方式对比
以32位整数 0x12345678(十六进制)为例:
内存地址: 0x1000 0x1001 0x1002 0x1003
----------------------------
大端模式: | 0x12 | 0x34 | 0x56 | 0x78 |
----------------------------
小端模式: | 0x78 | 0x56 | 0x34 | 0x12 |
----------------------------
指针数组与数组指针详解
核心区别总结
| 特性 | 指针数组 | 数组指针 |
|---|---|---|
| 本质 | 数组(元素是指针) | 指针(指向数组) |
| 声明形式 | int *arr[5] |
int (*ptr)[5] |
| 内存占用 | 多个指针空间 | 单个指针空间 |
| 元素类型 | 指针类型 | 数组类型 |
| 访问方式 | arr[i] → 指针值 |
(*ptr)[i] → 数组元素 |
| 指针运算 | arr+1 → 下一个指针元素 |
ptr+1 → 下一个完整数组 |
| 典型应用 | 字符串数组、多级数据结构 | 二维数组操作、动态多维数组 |
一、指针数组(Array of Pointers)
1. 概念定义
指针数组本质是数组,其元素均为指针类型。每个数组元素存储一个内存地址。
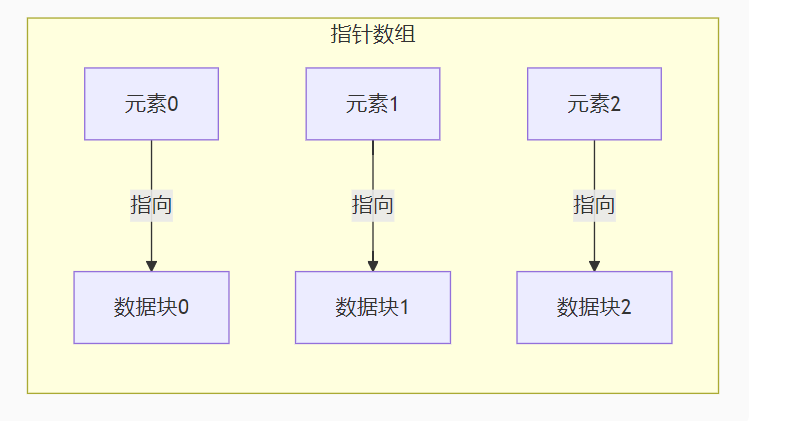
二、数组指针(Pointer to an Array)
1. 概念定义
数组指针本质是指针,它指向一个完整的数组(而非单个元素)。
指针函数与函数指针详解
核心区别总结
| 特性 | 指针函数 | 函数指针 |
|---|---|---|
| 本质 | 函数(返回指针类型) | 指针(指向函数) |
| 声明形式 | int *func(int a) |
int (*func_ptr)(int a) |
| 内存占用 | 函数代码段 | 指针大小(4/8字节) |
| 使用方式 | 直接调用:func() |
间接调用:func_ptr() |
| 主要用途 | 返回动态内存/数据地址 | 回调机制/多态实现 |
| 赋值操作 | 不可赋值 | 可指向不同函数 |
| 典型应用 | 内存分配函数 | 事件处理/策略模式 |
一、指针函数(Function Returning Pointer)
1. 概念定义
指针函数本质是函数,其返回值类型为指针类型。函数执行后返回一个内存地址。

二、函数指针(Pointer to Function)
1. 概念定义
函数指针本质是指针,它存储函数的入口地址。通过该指针可以间接调用函数。
数组与指针
一、本质区别对比
| 特性 | 数组 | 指针 |
|---|---|---|
| 本质 | 连续内存块的数据集合 | 存储内存地址的变量 |
| 内存分配 | 静态分配(编译时确定大小) | 动态分配(运行时确定) |
| 存储内容 | 实际数据值 | 内存地址 |
| 内存占用 | sizeof(元素类型)×元素个数 |
固定大小(4/8字节) |
| 可修改性 | 数组名不可重新赋值 | 指针值可修改 |
| 类型信息 | 包含元素类型和长度信息 | 仅含目标类型信息 |
| 地址操作 | &array 返回数组首地址 |
&ptr 返回指针变量地址 |
黄金法则:对待指针就像对待武器——永远知道它指向哪里,不用时安全存放(置空)!
野指针
一、野指针的定义与本质
野指针(Dangling Pointer) 是指向无效内存地址的指针变量。这种指针具有以下特征:
-
指向已被释放的内存(最常见情况)
-
指向未初始化的随机地址
-
指向超出作用域的局部变量
-
指针算术运算后指向非法地址
int *wild_pointer; // 未初始化的指针 → 野指针
void create_dangling_pointer() {
int local = 42;
int *ptr = &local;
} // 函数结束,local被销毁 → ptr成为野指针
int *create_leaked_pointer() {
int *p = malloc(sizeof(int));
*p = 100;
return p; // 返回后p被正确使用不是野指针
}
void misuse_pointer() {
int *p = create_leaked_pointer();
free(p);
// p现在成为野指针
*p = 200; // 危险操作!
}二、野指针的五大产生原因
1. 未初始化的指针
int *ptr; // 未初始化
printf("%d", *ptr); // 访问随机内存 → 段错误2. 释放后未置空
int *data = malloc(100 * sizeof(int));
// 使用data...
free(data); // 释放内存
// 未置空 → data成为野指针
data[0] = 10; // 危险操作!3. 返回局部变量地址
int *dangerous_func() {
int local_var = 42;
return &local_var; // 返回栈内存地址
}
int *ptr = dangerous_func(); // ptr成为野指针4. 多指针指向同块内存
int *p1 = malloc(sizeof(int));
int *p2 = p1; // 两个指针指向同一内存
free(p1); // 释放内存
// p2现在成为野指针5. 指针越界访问
int arr[5] = {0};
int *ptr = arr;
for(int i=0; i<10; i++) { // 越界访问
*ptr++ = i;
} // 循环结束后ptr可能指向非法地址三、野指针的严重危害
| 危害类型 | 具体表现 | 后果等级 |
|---|---|---|
| 程序崩溃 | 访问未映射内存触发段错误(Segmentation Fault) | ★★★★★ |
| 数据损坏 | 覆盖有效内存区域导致其他变量值异常 | ★★★★☆ |
| 安全漏洞 | 可能被利用进行任意代码执行(如通过函数指针覆盖) | ★★★★★ |
| 内存泄漏 | 误操作导致内存管理混乱 | ★★★☆☆ |
| 调试困难 | 随机出现的崩溃,难以复现和定位 | ★★★★☆ |
典型案例:2014年苹果iOS系统"goto fail"漏洞(CVE-2014-1266)部分源于指针操作不当
野指针与空指针的区别
| 特性 | 野指针 | 空指针 |
|---|---|---|
| 定义 | 指向无效内存地址 | 显式指向NULL (0x0) |
| 产生原因 | 释放后未置空/越界访问 | 显式赋值ptr = NULL |
| 检测难度 | 困难(随机崩溃) | 容易(if(ptr)检查) |
| 访问后果 | 未定义行为(崩溃/数据损坏) | 可预测崩溃(段错误) |
| 安全风险 | 高危(可能被利用) | 低危(立即暴露问题) |
头文件中定义静态变量
一、核心结论:技术上可行,但需谨慎使用
在C/C++中,头文件中可以定义静态变量,但这是一种需要特别谨慎的做法,因为会导致多个编译单元拥有各自的变量副本。
二、静态变量的行为特性
1. 文件作用域静态变量(头文件中定义)
| 特性 | 说明 |
|---|---|
| 存储位置 | 数据段(全局/静态存储区) |
| 链接属性 | 内部链接(internal linkage) |
| 作用域 | 当前编译单元(每个包含该头文件的源文件) |
| 生命周期 | 程序运行期间(从程序启动到结束) |
| 初始化时机 | 在main()函数执行前初始化 |
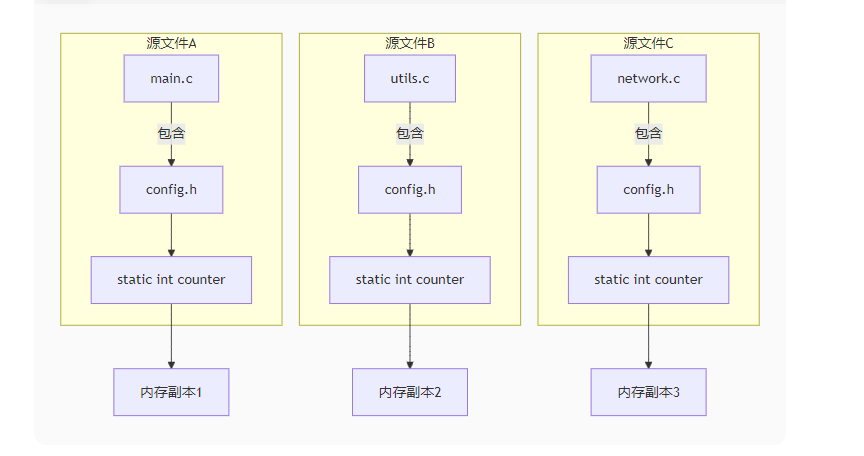
头文件静态变量的风险
1. 内存浪费
2. 状态不一致
3. 初始化顺序问题
4. 线程安全问题
最佳实践指南
-
黄金法则:头文件中只做声明,不做定义
// 正确做法 extern int globalVar; // 声明 void function(); // 函数声明
day4
一、核心原则:从右向左的参数入栈顺序
在函数调用过程中,参数的入栈顺序遵循从右向左的原则(right-to-left)。这是C/C++默认调用约定(cdecl)的标准行为。
示例分析
void example(int a, int b, int c);
example(1, 2, 3);对应的汇编代码:
push 3 ; 最右侧参数c先入栈
push 2 ; 参数b入栈
push 1 ; 最左侧参数a最后入栈
call example二、完整的函数调用栈帧构建过程
调用者操作序列
-
参数入栈:从右向左依次压入参数
-
返回地址入栈:执行call指令时自动完成
-
控制权转
总结与最佳实践
函数调用黄金法则
-
参数顺序:从右向左入栈(cdecl/stdcall)
-
栈帧构建:
-
清理责任:
-
cdecl:调用者清理
-
stdcall:被调用者清理
-
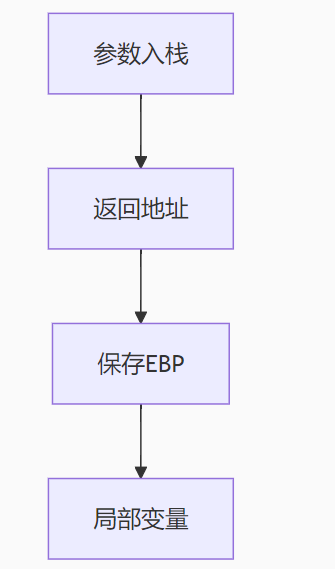
程序内存分段
一、程序内存核心分段
程序在内存中通常分为以下5个核心段,每个段有特定的功能和特性:
| 段名 | 别名 | 存储内容 | 权限 | 生命周期 | 增长方向 |
|---|---|---|---|---|---|
| 代码段(Text) | 文本段(Text) | 机器指令、常量字符串 | R-X (读执行) | 程序整个运行期 | - |
| 数据段(Data) | 初始化数据段(Data) | 显式初始化的全局/静态变量 | RW- (读写) | 程序整个运行期 | - |
| BSS段 | 未初始化数据段 | 零初始化的全局/静态变量 | RW- (读写) | 程序整个运行期 | - |
| 堆(Heap) | 动态内存区 | 动态分配的内存(malloc/new) | RW- (读写) | 手动管理 | 向上增长↑ |
| 栈(Stack) | 调用栈 | 局部变量、函数参数、返回地址 | RW- (读写) | 函数调用周期 | 向下增长↓ |
strcpy vs memcpy
在C/C++中,strcpy和memcpy都是内存复制函数,但它们的设计目的、行为特征和使用场景有显著区别。以下是全面对比分析:
核心区别对比表
| 特性 | strcpy (字符串复制) |
memcpy (内存块复制) |
|---|---|---|
| 头文件 | <string.h> |
<string.h> |
| 原型 | char* strcpy(char* dest, const char* src) |
void* memcpy(void* dest, const void* src, size_t n) |
| 终止条件 | 遇到\0停止 |
复制指定字节数 |
| 安全性 | 低(不检查目标缓冲区大小) | 中(需手动指定长度) |
| 性能 | 通常更快(可提前终止) | 需要完整复制 |
| 处理空字符 | 自动添加\0 |
不添加\0 |
数据包含\0 |
会在\0处停止 |
完全复制所有字节 |
| 返回值 | 目标指针 | 目标指针 |
| 重叠处理 | 未定义行为 | 未定义行为(需用memmove) |
| 主要用途 | 字符串操作 | 二进制数据复制 |
day5
计算机中的浮点数通常不能表示所有数,存储的通常是实际的的近似值,比如1.0可能被存储为0.99999。无论是float还是double类型的变量,都不能保证可以精确的存储一个小数,只是近似值
绝对地址操作与执行跳转
一、核心概念与技术原理
1. 绝对地址操作的本质
在底层编程中,直接操作绝对地址涉及以下关键概念:
-
物理地址:内存芯片上的实际硬件位置
-
虚拟地址:操作系统提供的抽象地址空间
-
内存映射:硬件寄存器或设备的内存映射区域
二、绝对地址赋值技术实现
1. C语言指针操作
// 定义内存映射寄存器地址
#define HW_REGISTER ((volatile uint32_t *)0xFFFF0000)
void write_to_register(uint32_t value) {
// 直接向绝对地址写入
*HW_REGISTER = value;
// 内存屏障确保写入完成
__sync_synchronize();
}三、跳转到绝对地址执行
1. 函数指针跳转
typedef void (*entry_point)(void);
void jump_to_address(uintptr_t address) {
// 转换为函数指针
entry_point func = (entry_point)address;
// 设置栈指针(可选)
asm volatile("mov sp, %0" : : "r" (0x20001000));
// 执行跳转
func();
}数据在内存中的存储形式:原码、反码与补码详解
一、数据在内存中的存储形式
1. 基本存储单位
| 单位 | 大小 | 表示范围 | 说明 |
|---|---|---|---|
| 位(bit) | 1位 | 0或1 | 最小存储单元 |
| 字节(byte) | 8位 | 0-255 | 基本寻址单位 |
| 字(word) | 16位(2字节) | 0-65,535 | 早期系统基本单位 |
| 双字(dword) | 32位(4字节) | 0-4,294,967,295 | 现代系统常用 |
2. 数值类型存储方式
整数类型
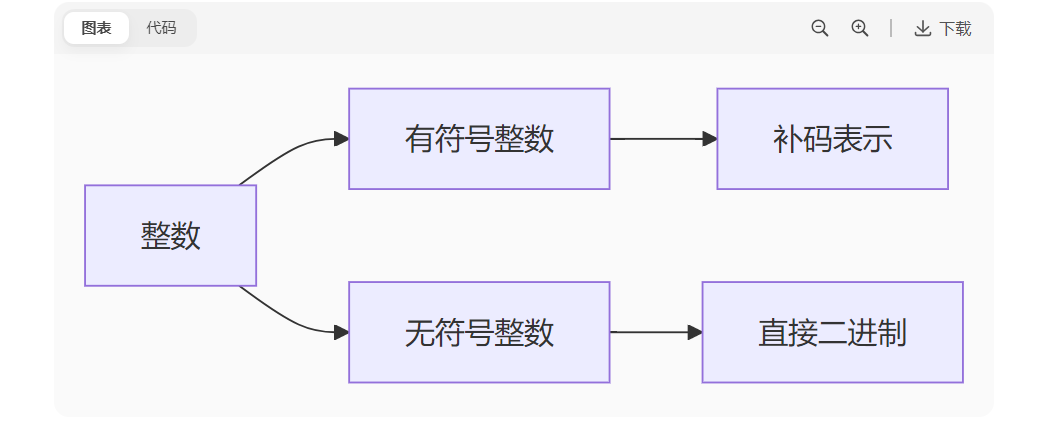
浮点数类型(IEEE 754标准)
| 类型 | 总位数 | 符号位 | 指数位 | 尾数位 | 范围 |
|---|---|---|---|---|---|
| float | 32位 | 1位 | 8位 | 23位 | ±3.4e38 |
| double | 64位 | 1位 | 11位 | 52位 | ±1.8e308 |
3. 字符与文本存储
| 编码 | 存储方式 | 特点 | 应用场景 |
|---|---|---|---|
| ASCII | 1字节/字符 | 仅支持英文 | 基础系统 |
| UTF-8 | 1-4字节/字符 | 变长编码 | 现代Web应用 |
| UTF-16 | 2或4字节/字符 | 定长/变长 | Windows系统 |
| GBK | 2字节/中文字符 | 中文专用 | 中文环境 |
4. 内存布局示例
int num = -42; // 补码存储: 0xFFFFFFD6
float pi = 3.14159f; // IEEE 754: 0x40490FDA
char str[] = "Hello"; // 连续字节: 48 65 6C 6C 6F 00二、原码、反码、补码详解
1. 核心概念对比
| 表示法 | 正数 | 负数 | 0的表示 | 加减运算 |
|---|---|---|---|---|
| 原码 | 符号位0+真值 | 符号位1+真值 | +0(0000), -0(1000) | 复杂 |
| 反码 | 同原码 | 符号位不变,数值位取反 | +0(0000), -0(1111) | 较复杂 |
| 补码 | 同原码 | 反码+1 | 唯一表示(0000) | 简单高效 |
2. 转换方法详解
原码 → 反码 → 补码 转换流程
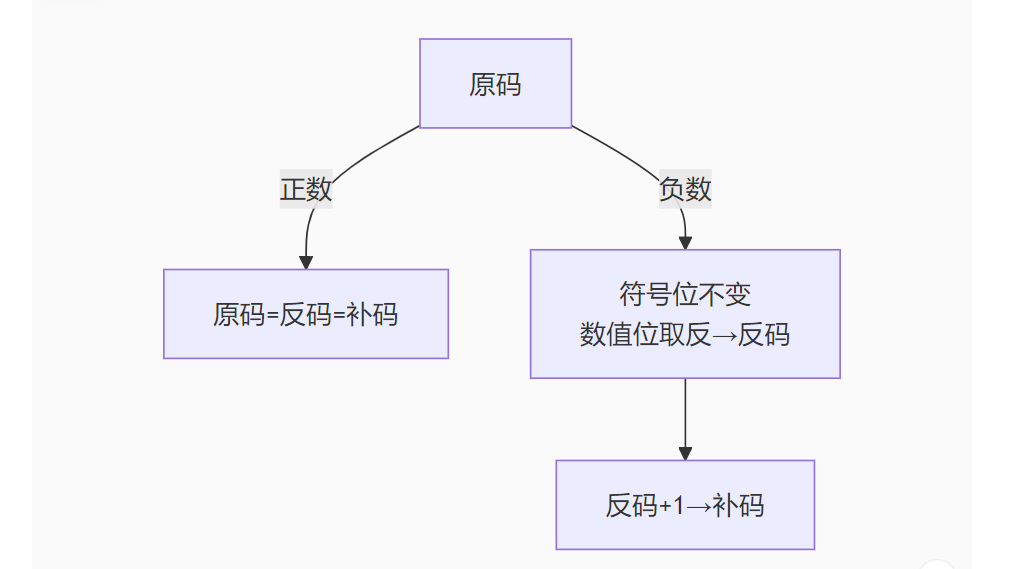
3. 补码的数学原理
补码表示基于模运算概念:
负数X的补码 = 模 - |X|
对于8位系统:模=256
-5的补码 = 256 - 5 = 251 = 11111011₂4. 补码运算优势
// 补码加法示例:5 + (-3)
0000 0101 (5)
+ 1111 1101 (-3的补码)
---------------
0000 0010 = 2 (结果正确)
// 原码加法需要额外处理符号位
0000 0101 (5)
+ 1000 0011 (-3原码) → 无法直接相加寄存器变量详解:概念、作用与现代应用
一、寄存器变量核心概念
1. 基本定义
寄存器变量是通过 register 关键字声明的变量,它向编译器建议将此变量存储在CPU寄存器而非内存中:
register int counter; // 声明寄存器变量2. 底层原理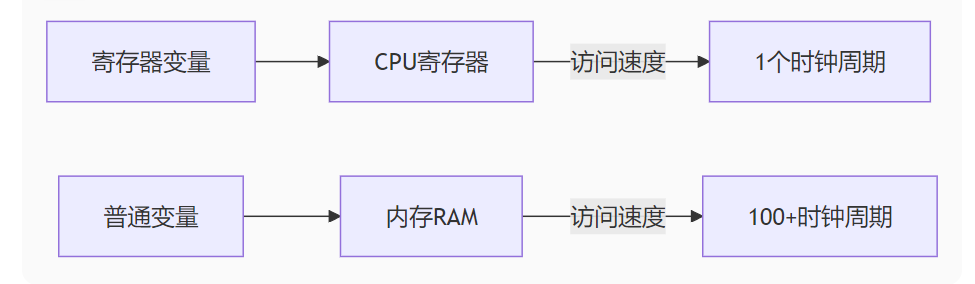
二、寄存器变量的核心作用
1. 性能加速(主要目的)
| 访问方式 | 速度 | 延迟 | 吞吐量 |
|---|---|---|---|
| 寄存器访问 | 0.3 ns | 1周期 | 1指令/周期 |
| L1缓存访问 | 0.9 ns | 3-4周期 | 有限 |
| 内存访问 | 100 ns | 100+周期 | 低 |
三、寄存器变量的技术特性
1. 关键限制
register int *ptr = &var; // 错误!不能取寄存器变量地址-
无法获取地址(寄存器无内存地址)
-
数量有限:x86架构仅有16个通用寄存器
-
大小限制:寄存器大小固定(通常≤64位)
黄金法则:优先改进算法和数据结构,寄存器优化应是最后手段。在编译器无法有效优化的特殊场景(如实时系统中断处理)才考虑手动控制寄存器使用。
字符串定义方式详解:C语言中的实现与区别
一、字符串定义的三种核心方式
1. 字符数组方式
char str1[] = "Hello"; // 栈分配
char str2[10] = "World"; // 显式大小
char str3[] = {'H', 'e', 'l', 'l', 'o', '\0'}; // 手动添加结束符2. 字符指针方式
char *ptr1 = "Hello"; // 指向字符串常量
char *ptr2 = malloc(10); // 堆分配
strcpy(ptr2, "World");
3. 动态内存分配方式
char *dyn_str = malloc(20 * sizeof(char));
strcpy(dyn_str, "Dynamic String");二、内存布局对比
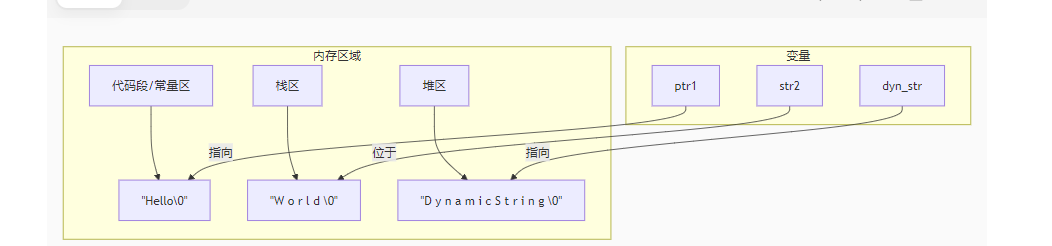
三、核心特性对比
| 特性 | 字符数组 | 字符指针(常量) | 字符指针(动态) |
|---|---|---|---|
| 内存位置 | 栈区/全局数据区 | 代码段(常量区) | 堆区 |
| 可修改性 | 可修改内容 | 不可修改内容 | 可修改内容 |
| 大小灵活性 | 编译时固定 | 编译时固定 | 运行时动态调整 |
| 内存管理 | 自动回收 | 无需管理 | 需手动free |
| sizeof结果 | 数组实际大小 | 指针大小(4/8字节) | 指针大小(4/8字节) |
| 初始化方式 | 直接赋值或列表初始化 | 直接指向字符串字面量 | 需malloc+strcpy |
| 生命周期 | 作用域内(栈)/程序周期(全局) | 整个程序周期 | 直到调用free |
| 赋值操作 | 不可整体赋值(需strcpy) | 可重新指向新地址 | 可重新指向新地址 |
| 使用风险 | 栈溢出风险 | 试图修改导致段错误 | 内存泄漏风险 |
****************************************************************************************************************************************************************************************************************************这个是学习倔强吧!青铜的嵌入式八股文总结(C语言篇)的自己的学习笔记,感谢大佬

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)