
嵌入式八股RTOS与Linux--内存管理篇
2026秋招嵌入式八股汇总--关于RTOS和Linux的
内存管理
基础
- 内存碎片是什么?如何避免
内存碎片是指已经分配的内存块之间出现未被利用的空间;内存碎片分为内部碎片和外部碎片,内部碎片的意思是:分配了10个字节,但实际只用2个字节;外部内存碎片是指夹在两个内存块中间的内存
- 使用内存对齐:比如分配内存块过小的时候,分配的size更大一些
- 内存池:预先定义好固定大小的内存池
- 避免内存泄漏
- 什么是内存泄漏?如何避免
内存泄漏是指程序动态分配的内存未释放,导致系统内存浪费,最终可能使程序崩溃(要么是忘了,要么是给这个指针分配其他值了)
- 良好的编程习惯
- 使用智能指针(C++)
- 使用内存检查工具:ccmalloc
- segmeationdefault是什么?如何调试
Segmentation fault(段错误)通常是由于程序访问了未分配或非法的内存地址引起的
- gdb调试
- 检查指针和数组是否越界,或者是不是局部变量占用空间过大导致栈溢出
- 非法指针 指针指向了一个无法访问的地址
- 使用相关的工具检测
- 堆/栈 的区别是什么
- 栈由程序自由分配/释放,堆由程序员手动释放
- 栈是从高地址向低地址增长,堆是从低地址向高地址增长
- 对于进程的多个线程,每个线程有自己的栈(进程调度篇讲过为啥)
- 对于进程的多个线程,共享堆内存
- 栈保存的是函数的局部变量 调用信息
- 堆保存的是动态分配的数据
- 堆/栈内存溢出的原因
堆内存溢出:可能是堆的尺寸设置得过小/动态申请的内存没有释放。
栈内存溢出:可能是栈的尺寸设置得过小/递归层次太深/函数调用层次过深/分配了过大的局部变量int a[1000000000000000]/数组越界
裸机的内存管理
-
为什么不建议使用裸机malloc
裸机的堆和栈的定义在startup.s中大小可以通过修改Heap_Size和Stack_Size来确定,这两块区域会由__main函数来分配和初始化
如果发现程序出现了栈溢出,就增大Stack_Size的内存
这块内存是在是太小了,很容易出现碎片化,而且你也不确定这个malloc背后的实现到底咋样 -
实现自己的mymalloc
如果真的想用malloc的话 在裸机上用的更多的是内存池的操作,虽然会浪费内存但是可以有效防止外部内存碎片化
比如我们可以预先定义一个全局数组 然后通过算法去管理对这个数组的访问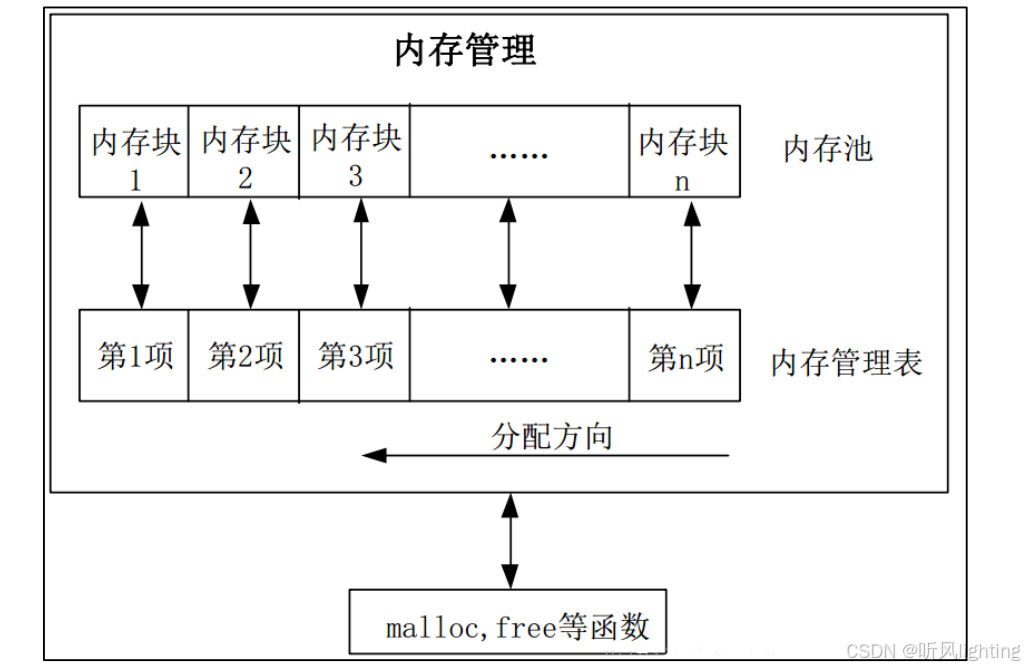
FreeRTOS的内存管理算法
heap1-heap5
- heap4算法
- 把所有的空闲块组合成一个链表 每次需要新的内存块就遍历链表寻找
- firstFit思想:第一个大于等于需要Size + 结构体 大小的空闲块会被取出 如果过大会被分割
- 释放内存块时会尝试合并链表中的空闲内存
- 缺点是分配时间不确定
TLSF算法–O(1)复杂度
- TLSF通过两级位图(Two-Level Bitmap)和分级空闲块链表(Segregated Free List)的数据结构,确保内存分配和释放的时间复杂度均为O(1),适合实时性要求高的场景
- 由于采用四字节对齐至少size > 4,所以size的低2位被赋予了不同的含义
- good-fit思想: 假设一块所需内存 125byte 不会去120 - 128区间搜索 会直接在129-137这个区间找
Linux的内存管理
Linux的内存管理相当庞大 这里就大概讲一讲
为什么要引入虚拟内存?
- 简化内存管理:此时写代码的只要考虑虚拟地址空间(一片连续的内存)就好,而操作系统要考虑的就多了
- 实现内存隔离与安全性: 防止有进程恶意访问/修改某些地址的内容
- 更好的支持多任务并发: RTOS是直接指定了任务用多大的栈,但是一般都会有浪费
为了方便管理 内存的基本单位为一页(4KB) 无论是虚拟内存管理还是物理内存管理 都是以页为基本单位的
虚拟内存管理
对于64位操作系统 进程的虚拟地址空间是非常巨大的,一般会把整个地址空间划分一下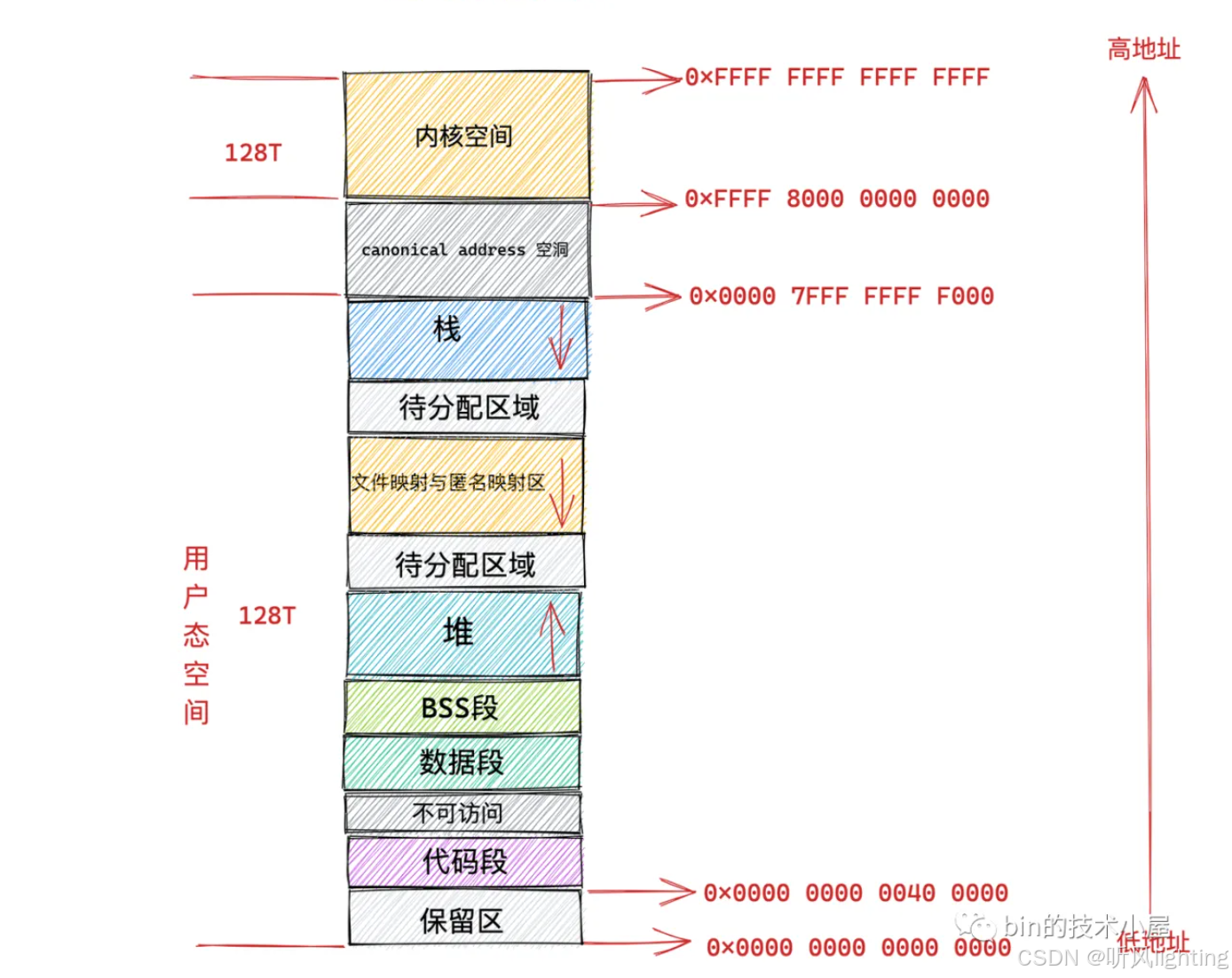
通过 mm_struct来管理整个进程,mm_struct记录了每个区的开始地址和结束地址
通过 vm_area_structs对于每个区进行管理 包括这个区的大小 可读/写权限等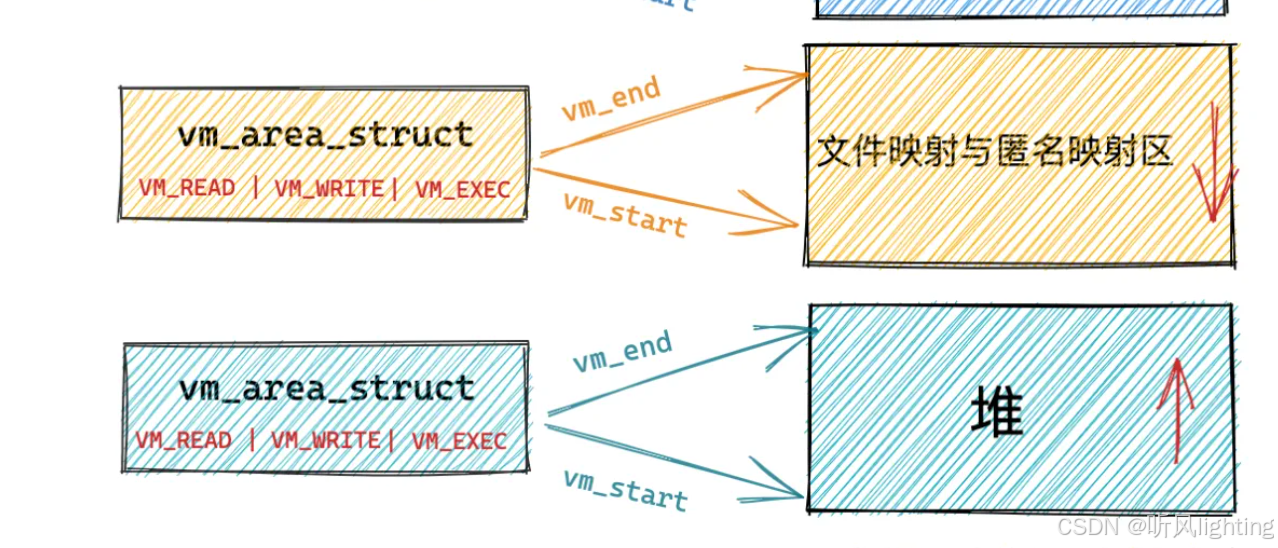
内核态虚拟内存空间是所有进程共享的,不同进程进入内核态之后看到的虚拟内存空间全部是一样的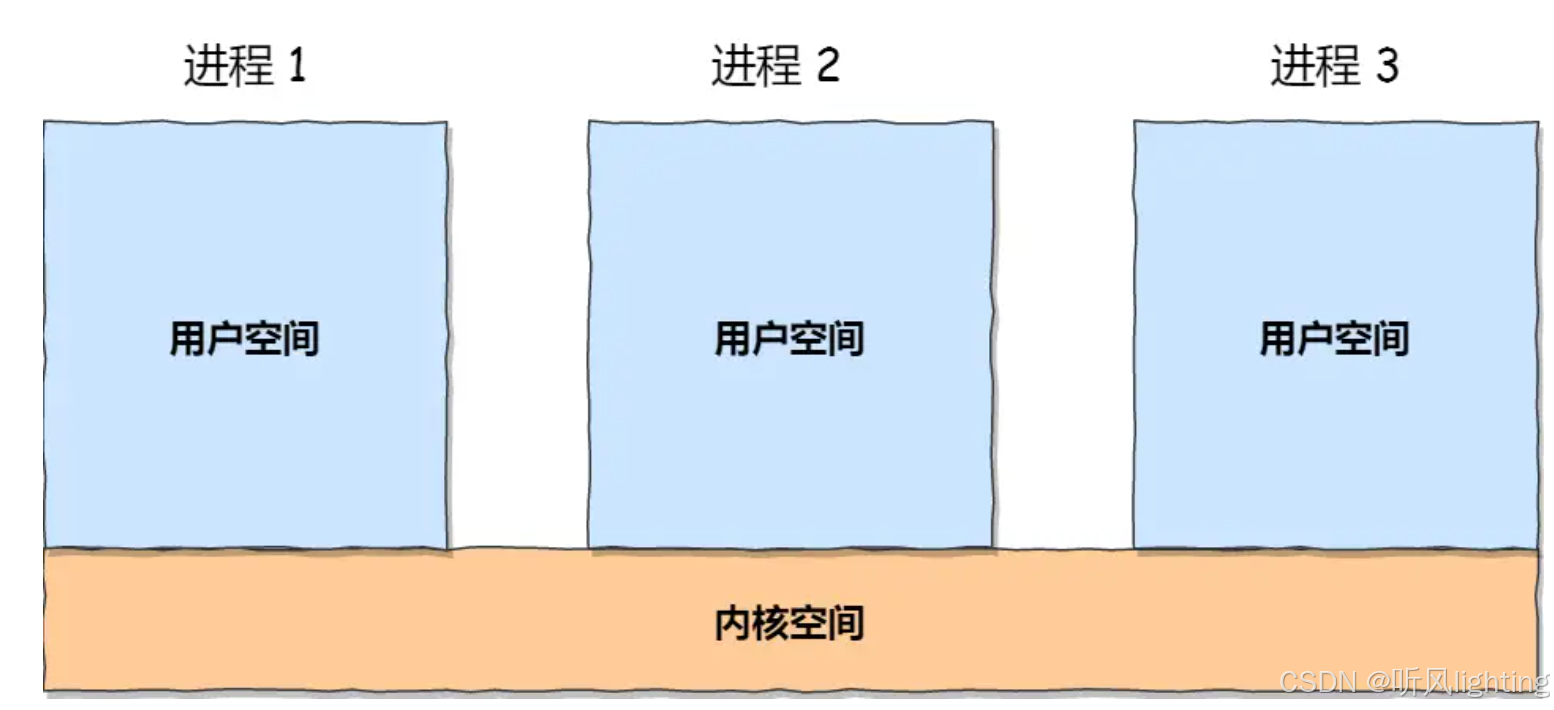
物理内存管理
虚拟内存地址转物理内存地址是通过一个叫做MMU的单元来实现的,为了加快转换速度会有一个TLB来进行缓存
-
段映射与页映射
最开始时是段映射,比如在虚拟地址中的各个段,记录这些段在真实物理内存的起始地址,这样对于段中变量通过偏移量就能找到物理内存了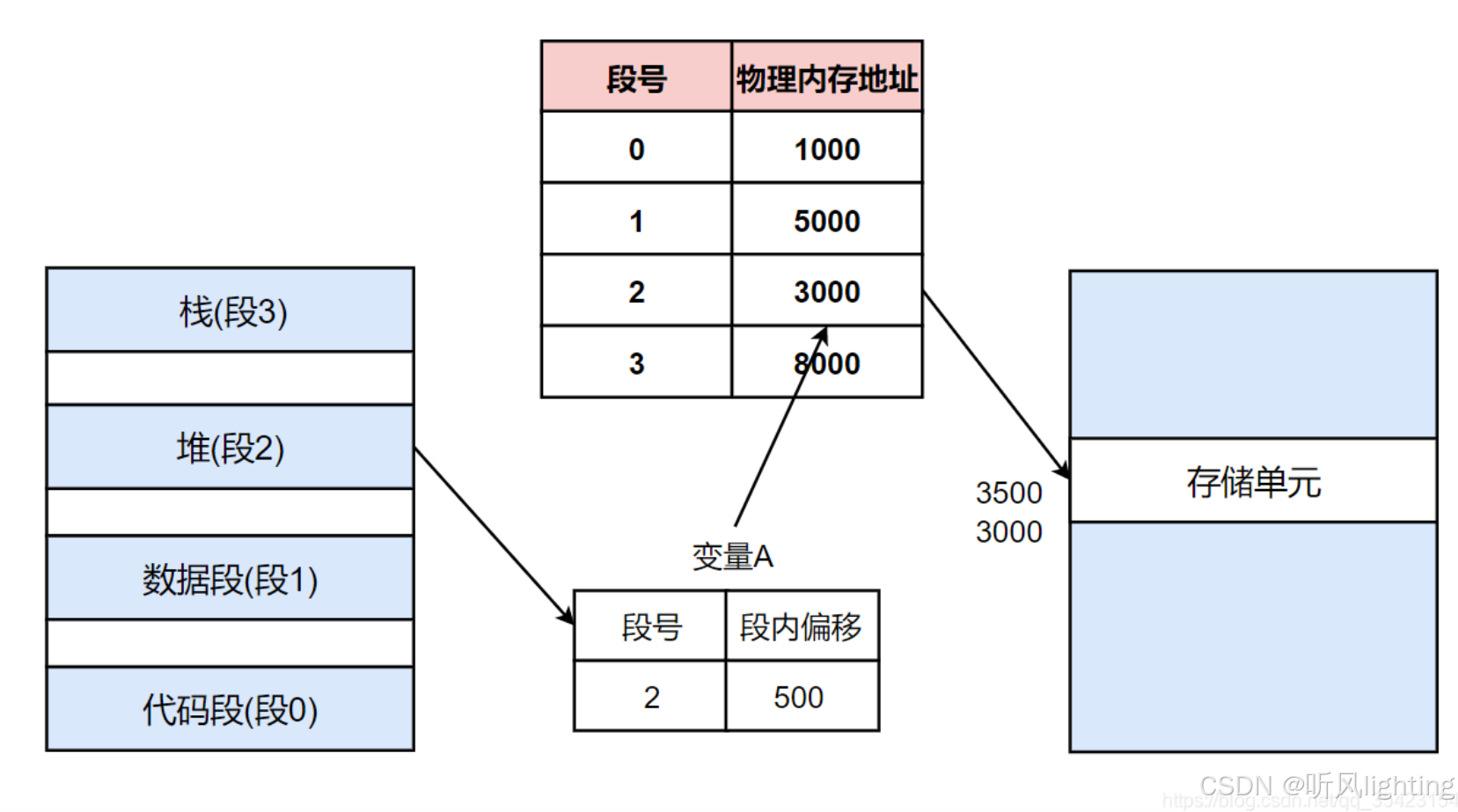
缺点:管理不够细致,容易产生内存碎片;因为是基于偏移量转换的 这意味着必须每段必须对应一块连续的物理内存;此时就很容易产生内存碎片了
所以引入了页映射,此时对于内存的管理更加精确更加细致,哪怕是程序中的段也不一定得使用连续物理内存了
缺点:页表的记录需要消耗很多物理内存,引入了多级页表与TLB(TLB实际上就是一个缓存)- 虚拟内存与物理内存的映射
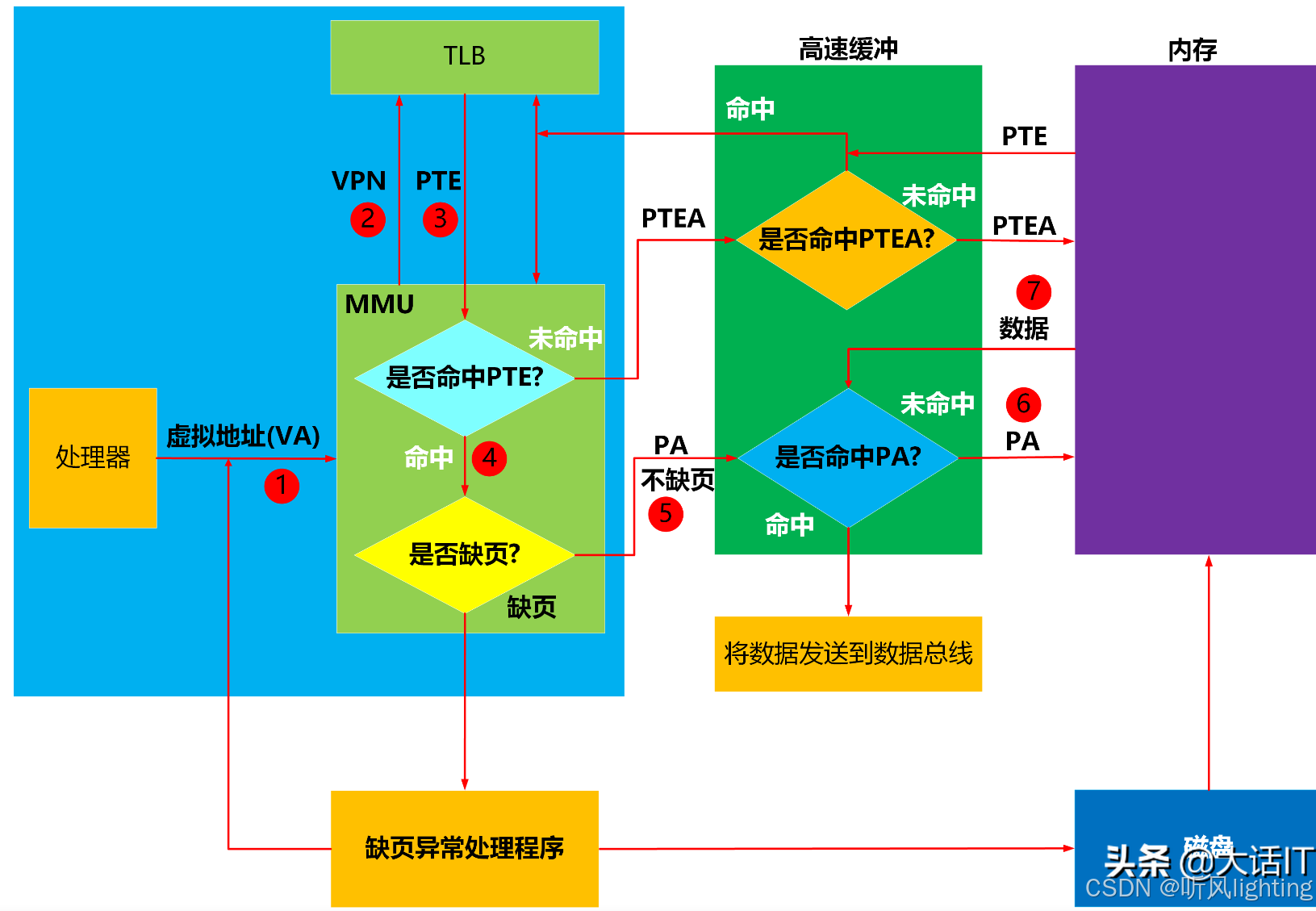
- 虚拟内存与物理内存的映射
-
缺页中断 pagefault
- 如何触发
程序访问虚拟内存一个页时,如果当前页面不在物理内存中 就会触发page fault - 是谁的动作
硬件上: MMU 发现了访问内存物理页不存在或者访问权限不够 就会触发这个异常,此时操作系统就会处理
软件上: 操作系统执行对应的handler 把页面从磁盘或者swap空间加载到物理内存。/也有可能别的进程用了这块东西已经在物理内存了,那就建立映射就行
- 如何触发
堆区内存管理
malloc()/free()函数的底层实现,其实就是通过系统调用brk向内核的内存管理系统申请内;malloc申请的内存大于128KB的时候 就会使用mmap映射了 可以通过打印地址来分析在哪里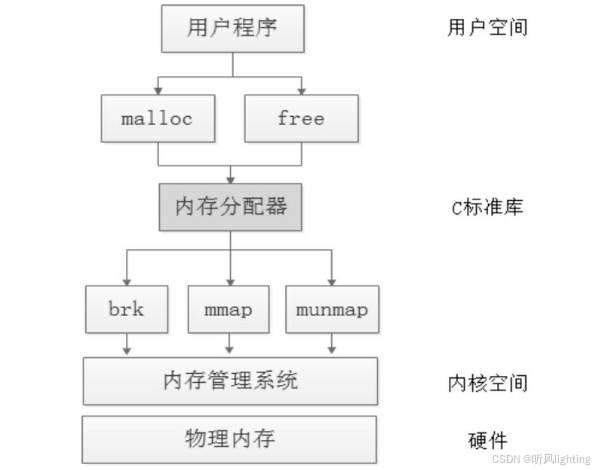
因为反复的系统调用开销是很大的,所以我们会使用ptmalloc来管理已经申请/释放的内存
感兴趣可以搜索了解
大概流程:
malloc–>系统调用brk()–>内核更新vm_area_struct–>发现需要触发Page Fault–>调用对应Handler–>完成物理内存分配和映射–>返回

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)