
基于Python的强化学习的黑白棋人工智能实验
而黑白棋中,需要优先占到边界和角落,其中角落最为重要,自己努力占领角落的同时也要尽量不要让对方占领角落,因此角落旁的位置的分数可以设置得低一些。针对如何学习一个最优的策略,我们可以这样做:先随机初始化一个策略,计算该策略的值函数,并根据值函数来设置新的策略,然后一直反复迭代直到收敛。如果需要拿到完整的轨迹才能评估和更新策略,则效率较低,因此考虑模拟一段轨迹,每行动一步,就利用贝尔曼方程评估状态的价
目录
人工智能实验:强化学习实验报告 1
一、 基本原理 1
1.1 强化学习 1
1.2 Q学习方法 2
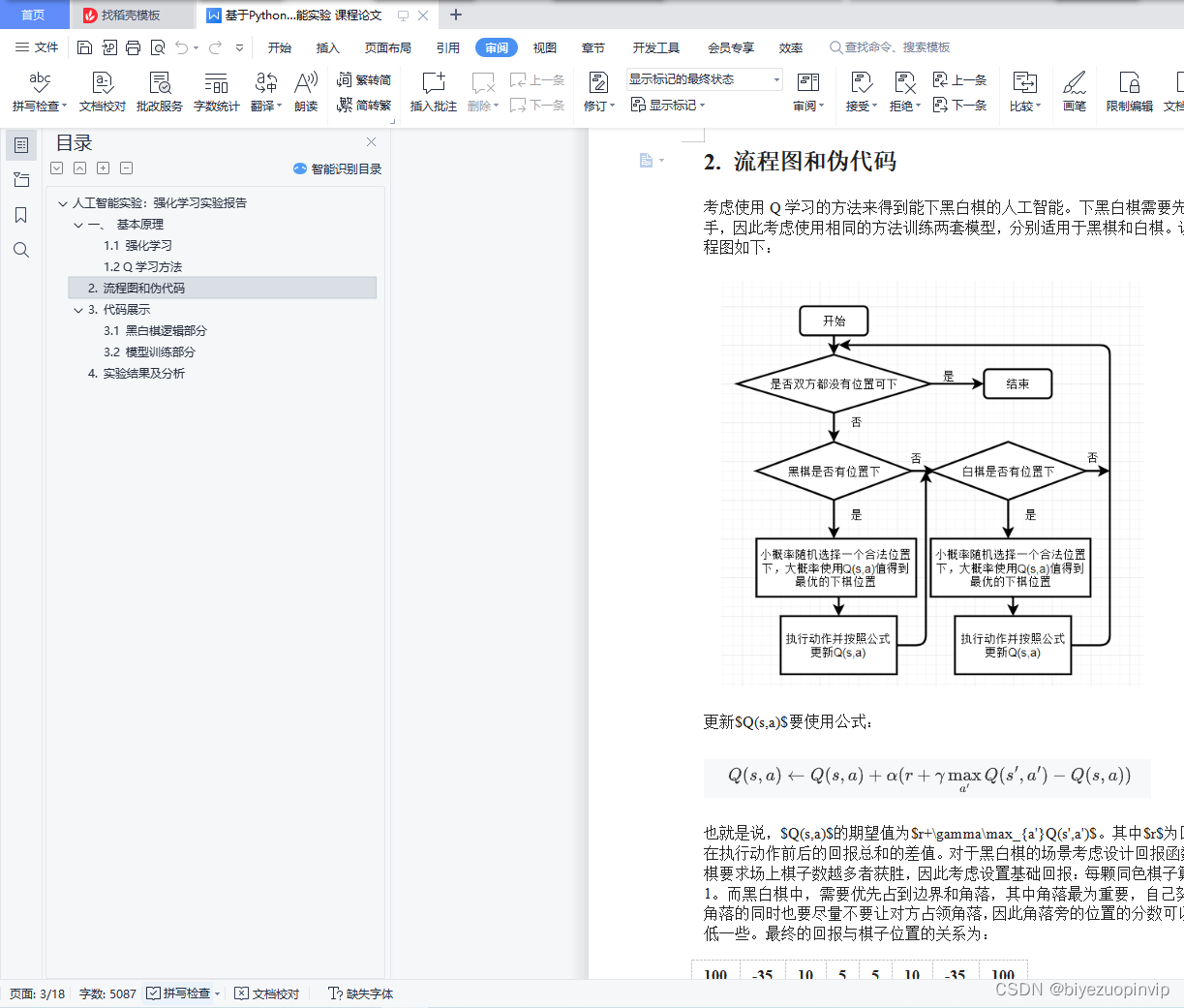
2. 流程图和伪代码 2
3. 代码展示 5
3.1 黑白棋逻辑部分 5
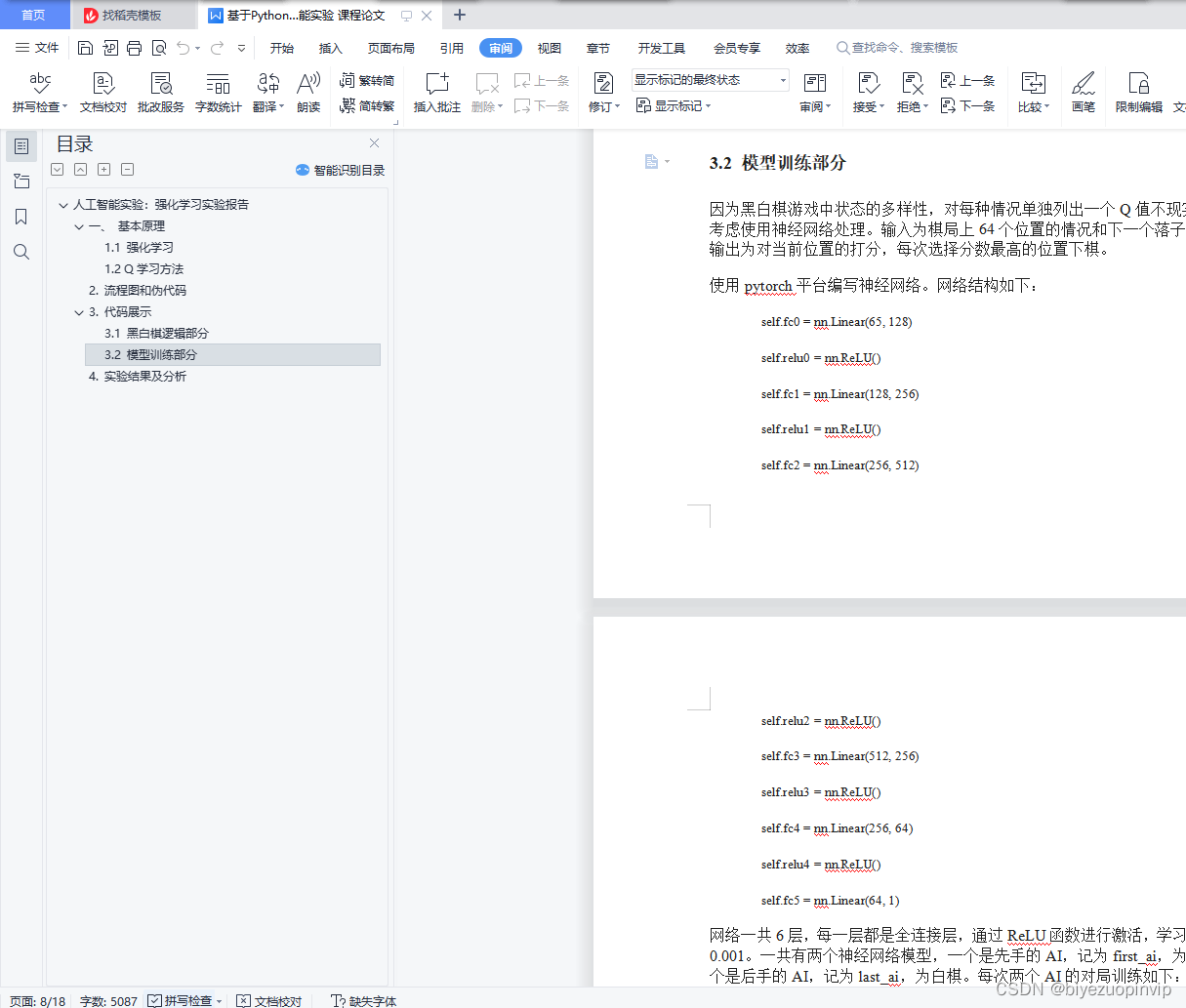
3.2 模型训练部分 8
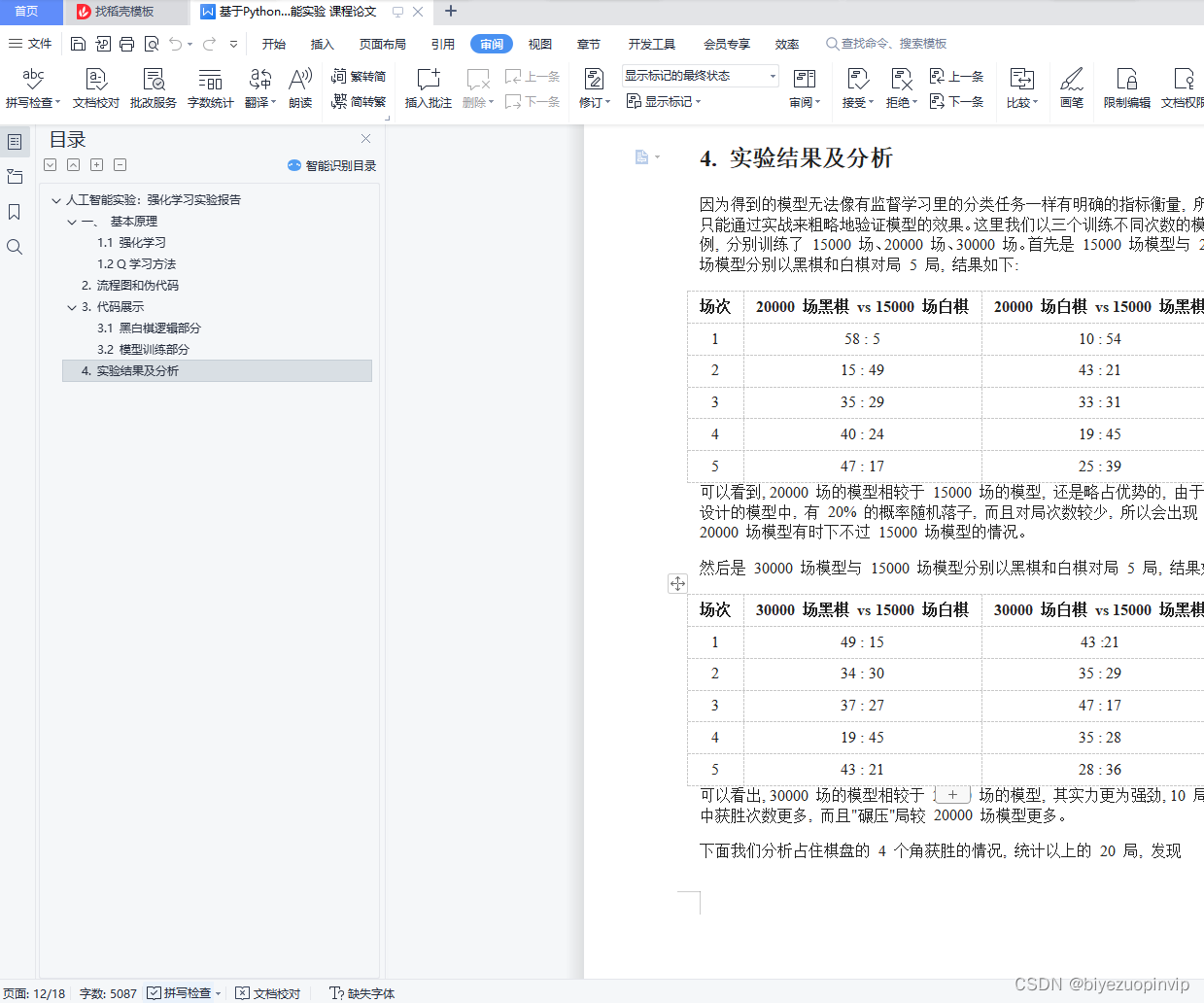
4. 实验结果及分析 12
1.2 Q学习方法
函数是对策略π\piπ的评估。如果策略π\piπ有限(即状态数和动作数都有限),可以对所有的策略进行评估并选出最优策略π∗\pi*π∗。但这种方式在实践中很难实现,通过迭代的方法不断优化策略,直到选出最优策略。 针对如何学习一个最优的策略,我们可以这样做:先随机初始化一个策略,计算该策略的值函数,并根据值函数来设置新的策略,然后一直反复迭代直到收敛。
如果需要拿到完整的轨迹才能评估和更新策略,则效率较低,因此考虑模拟一段轨迹,每行动一步,就利用贝尔曼方程评估状态的价值,即时序差分方法。下面考虑使用Q学习算法估计Q函数: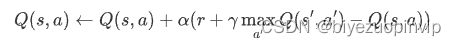
Q学习的算法不通过πεπ^επε来选择下一步动作a′a'a′,而直接选择最优Q函数,所以更新后的Q函数是关于策略π\piπ而非πϵ\pi^\epsilonπϵ的,因此是一种异策略算法。
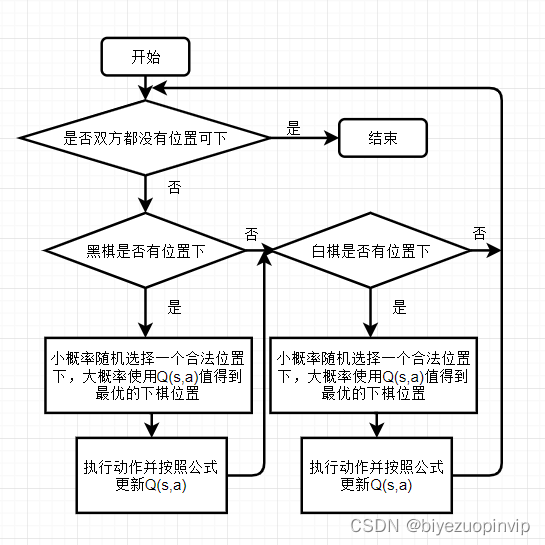
- 流程图和伪代码
考虑使用Q学习的方法来得到能下黑白棋的人工智能。下黑白棋需要先手和后手,因此考虑使用相同的方法训练两套模型,分别适用于黑棋和白棋。训练的流程图如下: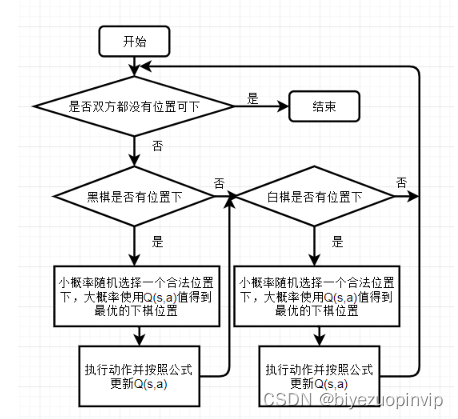
更新Q(s,a)Q(s,a)Q(s,a)要使用公式: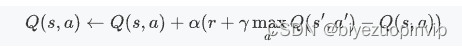
也就是说,Q(s,a)Q(s,a)Q(s,a)的期望值为r+γmaxa′Q(s′,a′)r+\gamma\max_{a'}Q(s',a')r+γmaxa′Q(s′,a′)。其中rrr为回报,是在执行动作前后的回报总和的差值。对于黑白棋的场景考虑设计回报函数:黑白棋要求场上棋子数越多者获胜,因此考虑设置基础回报:每颗同色棋子算回报为1。而黑白棋中,需要优先占到边界和角落,其中角落最为重要,自己努力占领角落的同时也要尽量不要让对方占领角落,因此角落旁的位置的分数可以设置得低一些。
from train import *
import time
import pygame
def draw(chesses):
space = 60 # 四周留下的边距
cross_size = 40 # 交叉点的间隔
cross_num = 9
# 绘制棋盘底色
screen.fill((150, 80, 0))
# 绘制网格
for x in range(0, cross_size * cross_num, cross_size):
pygame.draw.line(screen, (255, 255, 255), (x + space, 0 + space),
(x + space, cross_size * (cross_num - 1) + space), 1)
for y in range(0, cross_size * cross_num, cross_size):
pygame.draw.line(screen, (255, 255, 255), (0 + space, y + space),
(cross_size * (cross_num - 1) + space, y + space), 1)
# 绘制棋子
black = 0
white = 0
for x in range(cross_num-1):
for y in range(cross_num-1):
color = chesses[(x,y)]
if color != 0:
xi = space + (x + 0.5) * cross_size
yi = space + (y + 0.5) * cross_size
if color == 1:
white += 1
pygame.draw.circle(screen, (255, 255, 255), (xi, yi),15,0)
else:
black += 1
pygame.draw.circle(screen, (0, 0, 0), (xi, yi), 15, 0)
print('-------------')
print('black:',black)
print('white:', white)
pygame.display.update()
def aiPlay(ai, ai_color, chesses, _ai):
pos = getNextStepPos(chesses, ai_color)
if pos != []:
play(ai_color, pos, chesses, ai, _ai, False)
def endGame(chesses, ai_color):
black = 0
white = 0
for i in range(8):
for j in range(8):
if chesses[i][j] == 1:
white += 1
elif chesses[i][j] == -1:
black += 1
print('-------------')
print('black:',black)
print('white', white)
if black == white:
print('draw')
if black > white:
if ai_color == 1:
print('you win!')
else:
print('ai_wins!')
else:
if ai_color == 1:
print('ai wins!')
else:
print('you win!')
exit(0)
if __name__ == '__main__':
# 初始化图形界面
pygame.init()
space = 60 # 四周留下的边距
cross_size = 40 # 交叉点的间隔
cross_num = 9
grid_size = cross_size * (cross_num - 1) + space * 2 # 棋盘的大小
screencaption = pygame.display.set_caption('18340057-黑白棋') # 窗口标题
screen = pygame.display.set_mode((grid_size, grid_size)) # 设置窗口长宽
screen.fill((0, 0, 0))
pygame.draw.rect(screen, (255, 255, 255), ((grid_size / 2, 0), (grid_size / 2, grid_size)), 0)
pygame.display.update()
# 选择颜色
ai_color = player_color = 0
choose_color = True
while choose_color:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
exit()
if event.type == pygame.MOUSEBUTTONUP: # 松开鼠标
x, y = pygame.mouse.get_pos() # 获取鼠标位置
choose_color = False
if x < grid_size / 2:
ai_color = 1
player_color = -1
else:
ai_color = -1
player_color = 1
# 依据颜色选择ai
if ai_color == 1:
ai = torch.load('last_ai.pkl')
_ai = torch.load('first_ai.pkl')
else:
ai = torch.load('first_ai.pkl')
_ai = torch.load('last_ai.pkl')
# 初始化棋局
chesses = torch.FloatTensor(np.zeros((8, 8)))
chesses[3][3] = 1
chesses[3][4] = -1
chesses[4][3] = -1
chesses[4][4] = 1
# ai 先手
if ai_color == -1:
aiPlay(ai, ai_color, chesses, _ai)
draw(chesses)
while 1:
for event in pygame.event.get():
# 退出游戏
if event.type == pygame.QUIT:
pygame.quit()
exit()
# 获取鼠标点击位置
if event.type == pygame.MOUSEBUTTONUP: # 松开鼠标
x, y = pygame.mouse.get_pos() # 获取鼠标位置
x = round((x - space - 0.5 * cross_size) / cross_size) # 获取到x方向上取整的序号
y = round((y - space - 0.5 * cross_size) / cross_size) # 获取到y方向上取整的序号
# 如果玩家下的位置合法则可以落子
if x >= 0 and x < cross_num-1 and y >= 0 and y < cross_num-1 and \
chesses[(x, y)] == 0 and isValidPos(x , y, player_color, chesses):
chesses[(x, y)] = player_color # 将落子加入棋子列表
putChess(chesses, (x,y), player_color)
draw(chesses)
# 稍微等待一下,
time.sleep(0.5)
aiPlay(ai, ai_color, chesses, _ai)
draw(chesses)
# 人下不了则ai一直下
while getNextStepPos(chesses, player_color) == []:
time.sleep(0.5)
aiPlay(ai, ai_color, chesses, _ai)
# 都下不了则结束游戏
if getNextStepPos(chesses, ai_color) == [] and getNextStepPos(chesses, player_color) == []:
endGame(chesses, ai_color)
draw(chesses)






openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)