
人工智能专业-基于机器学习的中文文本分类算法
毕业设计-基于机器学习的中文文本分类算法:随着信息技术和互联网的快速发展和广泛应用,网络逐渐成为人们获取信息的重要渠道,各类信息数据数量呈爆炸式增长,人们逐渐从信息匮乏的时代走进信息过载的时代。全球范围内每一秒钟都会产生数以亿计的网络文本信息,互联网用户面对如此海量的文本信息,往往不能够快速有效获取自己需要的有价值的内容。为了快速获取有价值的文本信息,就需要对这些文本进行分类。新闻文本信息是人们接
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的中文文本分类算法
课题背景和意义
随着信息技术和互联网的快速发展和广泛应用,网络逐渐成为人们获取信息的重要渠道,各类信息数据数量呈爆炸式增长,人们逐渐从信息匮乏的时代走进信息过载的时代。全球范围内每一秒钟都会产生数以亿计的网络文本信息,互联网用户面对如此海量的文本信息,往往不能够快速有效获取自己需要的有价值的内容。为了快速获取有价值的文本信息,就需要对这些文本进行分类。新闻文本信息是人们接触较为广泛的文本信息形式,是人们了解社会动态、把握社会发展脉络的重要手段之一。在互联网日益发展壮大的今天,新闻文本信息不再受纸质媒体版面篇幅的限制,而是呈现出信息量庞大、种类繁多的特点。利用计算机对这些新闻信息进行有效筛选和分类,可以快速高效的获取有价值的信息内容,减少人力资源投入的同时也可以提升信息使用效率。文本分类技术可以提前对新闻信息进行过滤,将收集到的新闻进行分类,生成类别文章库,可以方便用户浏览感兴趣的类别信息,提升用户体验。总之,文本分类技术可以帮助人们对信息进行筛选、过滤,在现实生活中具有较为重要的研究意义。
实现技术思路
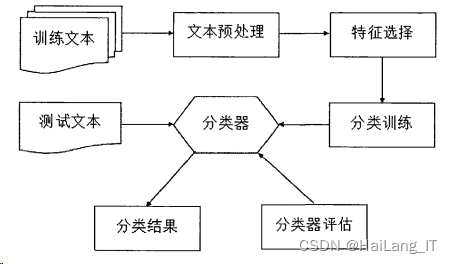
一、文本分类综述
文本分类从人工定义分类规则发展到今天的计算机自动分类,分类方法在不断改进,但由于中文文本自身的特殊性,文类的一般流程一直未曾有大的变化。文本分类的一般流程有以下几个:文本预处理、特征选择、分类器设计实现以及分类结果评价等四个主要步骤。
二、文本分类相关技术简
1、文本处理过程
中文文本分类相对于英文文本分类来说,句子结构较为复杂,需要进行一系列的文本处理过程之后才可以变为计算机可理解的语言,才能进行下一步的分类操作。
1)文本预处理
文本预处理过程是文本分类的基础环节,中文文本一句话的内部是连贯的、没有特殊分隔符的,标点符号只是句子间的分隔符号,而英文句子内部就有天然的空格符号作为每个单词之间的间隔符。
①中文分词
中文分词操作是是文本预处理过程中必不可少的环节,是中文文本分类研究的基础。
②去停用词
文档句子是由名词、动词、形容词、助词、叹词等成分构成,有些词如“导弹”“汽车”等可以很明显的表现出类别特征,而像“的”“地”“得”等词,虽然出现的频率很高,但对于分类没有任何意义,这些没有意义的字和词都是停用词。
文本表示
分词之后的中文文本是非结构化的字符数据,计算机不能直接识别语言。这时,需要将其转化为机器可以识别的、可进行计算的数据格式,这就是文本表示过程。
①布尔模型
布尔文本表示模型是一种简洁的表示模型,从名称可以看出它是一个二值模型,即:特征词出现在文档中,则定义值为1,否则定义值为0,因此这些特征词权重的值都具有二元性,如式:
![]()
②向量空间模型
向量空间文本表示模型是由 Salton 等人提出的,是被广泛应用的、效果不错的表示模型,在这个模型中,文档可表示为特征空间的高维特征向量。
③Word2vec 文本表示模型
Word2vec是谷歌研发的用于提取词向量的工具,目前已经在深度神经网络文本分类中发挥了不小的作用,有着浅层表示方法不可比拟的优势。
④模型比较
布尔模型是最简单的文本表示方法,功能有限。而向量空间模型和 Word2vec
模型从发展以来可以更为合理地表达文本信息,应用范围较广泛,实现灵活,比较受学者们的欢迎。

特征处理
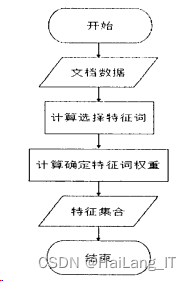
特征是用来表示文本内容的,在取得经过文本预处理过程的文档训练集后,利用一个特征选择计算函数对原始特征集进行评价;之后选择降序排列中分数较高的项作为特征词,对这些特征词进行权重计算,得到它们各自的贡献率。
1)特征选取
特征选取是一个降维的过程,在使用特征向量表征文档的时候,维度可能达到几千甚至几万维,在这种情况下,就需要使用特征降维方法对特征项进行过滤筛选,将维数降至一定范围之内。
①频率统计
频率统计是最简单的特征降维计算方法,简单易用,包括词频计算和文档频率计算。词频指的是特征项在训练集合中出现的频数,特征项出现的频率越高。
②信息增益
信息增益(Information gain)44的计算方法应用领域较为广泛,在文本分类中使用信息增益来计算,主要目的就是分析特征项可以为分类带来多少信息,自身所含有的信息越多,那么该特征项对于分类来说就越重要。
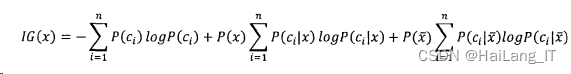
③互信息
互信息是信息论中非常有用的信息度量方式,它被看作是一个变量中含有关于另一个变量的信息量。
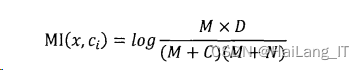
④CHI计算
CHI 计算是衡量特征项x与类别c;的关联程度的一种方式,也假设二者之间是符合x2分布的。如果特征项x与类别c的x2计算值越大,则代表二者之间的联系越紧密,对于分类越有意义。
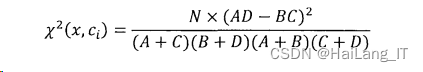
特征权重计算
在某种程度上,特征词的权重的作用有以下两点:是用来反映特征词对于文本表示的能力大小,二是可以帮助区分不同的文本内容。
(1)TF-IDF 权重计算方法
TF-IDF 权重计算是常见的权重计算方法,它是在词频的基础上增加了文档频率的因素,文档频率越高,则类别区分能力就越弱,相应的权重也应该减小。式显示了 TF-IDF 权重计算过程。
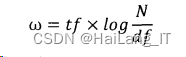
(2)TFC 权重计算方法
TFC权重计算方法在TF-IDF权重计算方法的基础上使用了文档长度进行了归一化,下式显示了这一正规化计算过程:
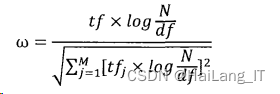
(3)LTC 权重计算方法
LTC 权重计算方法将 TFC 计算方法中的词频改为词频的对数来进行计算,降低了词频差异对于权重的影响,具体的计算过程如式:
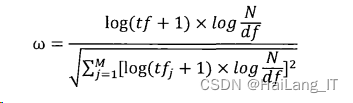
2、分类算法
朴素贝叶斯分类方法
朴素贝叶斯是基于统计的分类方法,我们会选择高概率所对应的类别作为该点的类别,这是贝叶斯理论的核心,即选择高概率的决策。贝叶斯准则:
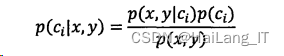
K 最近邻分类方法
最近邻分类是一种基于类比的学习算法,对于某个的待分类文本,通过计算其与其它训练集文本之间的距离,找到与之相近的k个训练集文本,待分类文本被分到k个训练集文本中最公共的类别中。
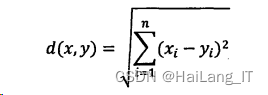
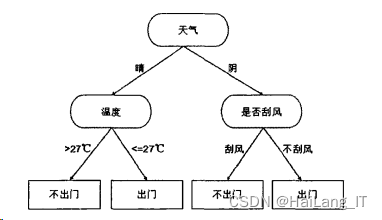
决策树分类方法
所谓决策树是一个与流程图相似的树形结构,分类流程分为三部分:一是对训练集进行训练构造判定树;二是决策树剪枝操作;三是分类规则的生成。
Fasttext 快速分类法
Fasttext是一个文本分类器,拥有简单且高效的文本分类与表征学习的算法,主要特点就是快。
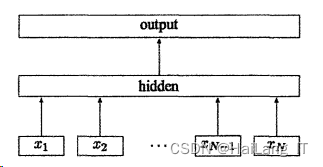
卷积神经网络分类方法
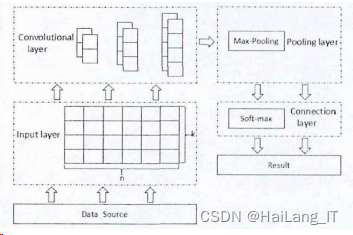
卷积神经网络(ConvolutionalNeuralNetworks,简称CNN)经常应用于图像分类。近些年,CNN等深度神经网络越来越多的被利用到文本分类上来,它可以省去人工特征提取步骤,利用网络对文本的特征进行提取,然后进行分类操作。CNN由输入(Input Layer)和输出层(Output Layer)以及多个隐藏层组成,隐藏层可分为卷积层(ConvolutionalLayer)、池化层(PoolingLayer)和全连接层(ConnectionLaver)。输入层接收数据,卷积层和池化层主要负责复杂的特征提取工作,全连接层负责进行文本分类操作,然后输出层展示分类结果。
3、分类算法评价方法
利用分类算法得到分类结果后,需要对结果进行评估,再对分类算法的设计进行评价,文本自动化分类的目的就是希望快速高效地得到较为正确的分类结果。
1、准确率
准确率(Precision)代表了分类结果中为正类的文档在实际情况下也是正类的比率,利用下式来计算:

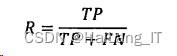
2、召回率
召回率(Recall)代表了待分类文档中所有正类在经过分类计算后依然是正类的比率,利用下式来计算;
3、F1值
F1 值是将准确率和召回率综合在一起考虑的一种评价指标,利用下式来计算:
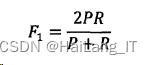
实现效果图样例
文本分类的应用十分广泛,可以将其应用在:
- 垃圾邮件的判定:是否为垃圾邮件
- 根据标题为图文视频打标签 :政治、体育、娱乐等
- 根据用户阅读内容建立画像标签:教育、医疗等
- 电商商品评论分析等等类似的应用:消极、积极
- 自动问答系统中的问句分类
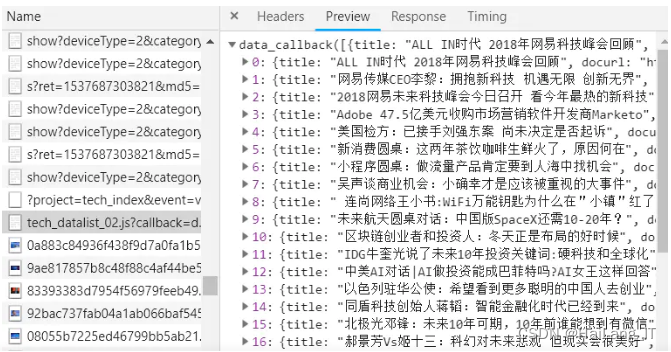
下图是新闻数据的请求:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 1
1 0
0- 0



 已为社区贡献133条内容
已为社区贡献133条内容

所有评论(0)