
RuleGo:Go语言的轻量级高性能嵌入式规则引擎实战指南
规则引擎作为IT系统中不可或缺的一部分,它通过将业务逻辑和程序代码分离,实现快速响应业务规则的变化,保证系统的灵活性和可维护性。RuleGo是一个轻量级的规则引擎,专为Go语言设计,它不仅提供了灵活的规则定义和管理,而且在并发处理和性能优化方面具有独特优势。在接下来的章节中,我们将深入探讨RuleGo的核心特性,包括规则定义的语法、内存和CPU优化技术、Go语言并发优势、嵌入式系统集成能力,以及A

简介:RuleGo是一个为Go语言开发的规则引擎,旨在简化应用程序中复杂业务逻辑的实现。它允许开发者将业务规则与核心代码分离,便于维护更新。RuleGo通过定义条件和动作来处理各种数据任务,并以轻量级和高性能的特点运行于资源受限环境。由于Go语言的并发优势,RuleGo能高效并行处理规则。嵌入式设计让RuleGo可以直接集成到应用程序中,减少外部依赖,增强系统响应速度和安全。API接口使规则管理更加灵活,支持非程序员参与。RuleGo的”rulego-main”文件提供了核心引擎和使用示例,方便开发者快速集成和应用。 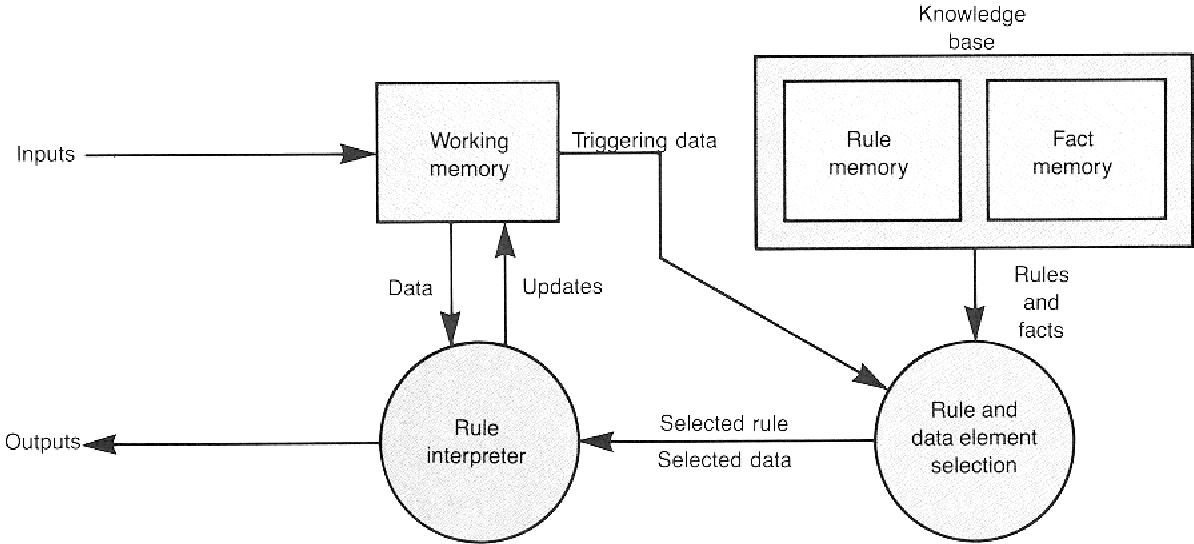
1. RuleGo规则引擎概述
规则引擎作为IT系统中不可或缺的一部分,它通过将业务逻辑和程序代码分离,实现快速响应业务规则的变化,保证系统的灵活性和可维护性。RuleGo是一个轻量级的规则引擎,专为Go语言设计,它不仅提供了灵活的规则定义和管理,而且在并发处理和性能优化方面具有独特优势。
在接下来的章节中,我们将深入探讨RuleGo的核心特性,包括规则定义的语法、内存和CPU优化技术、Go语言并发优势、嵌入式系统集成能力,以及API接口设计和规则管理的灵活性。通过这些内容,您将能够更全面地了解RuleGo,并在实际工作中有效地运用它来提升项目的开发效率和系统性能。
2. 条件和动作的规则定义
2.1 规则引擎的工作原理
2.1.1 规则引擎的定义和作用
规则引擎是一种软件系统,它按照预定的规则来执行业务逻辑。它被设计用于从一组给定的业务规则中分离和管理业务逻辑。规则引擎的作用包括业务策略的实现、业务逻辑的自动化处理以及复杂决策的简化。
规则引擎的定义可以概括为以下几个方面:
- 解耦业务逻辑: 通过将业务逻辑从核心应用中分离出来,规则引擎可以使得业务决策可以独立于应用而变化。
- 灵活的业务规则: 业务规则可以被非技术人员编辑和管理,提高了规则的灵活性。
- 提高业务可维护性: 规则的变更不需要修改和重新部署程序,降低了维护成本。
2.1.2 RuleGo引擎的工作流程
RuleGo引擎是基于Go语言实现的规则引擎,它的工作流程主要包含以下几个步骤:
- 加载规则: 将定义好的规则加载到引擎中,这通常包括条件规则和动作规则。
- 执行规则: 根据提供的输入数据,匹配规则条件,并执行相应的动作。
- 规则解析: 对于复杂的规则,可能需要解析引擎来处理和理解规则语言。
- 结果输出: 执行完匹配的规则后,将结果输出到相应的处理流程或存储系统中。
RuleGo的执行流程如图1所示:
graph LR
A[开始] --> B[加载规则]
B --> C[等待输入数据]
C --> D[匹配规则]
D --> |匹配成功| E[执行动作]
D --> |匹配失败| C
E --> F[输出结果]
F --> G[结束]
2.2 规则的分类和定义
2.2.1 条件规则的定义和语法
条件规则是规则引擎中用于决策的基础,它定义了触发动作规则的条件。通常,一个条件规则包括多个条件表达式,这些表达式使用逻辑运算符(如AND、OR)组合在一起。
在RuleGo中,条件规则的定义使用特定的语法,例如:
rule "example_condition_rule" when
context.Condition1 == true && context.Condition2 != false then
// 动作逻辑
end
2.2.2 动作规则的定义和语法
动作规则定义了当条件规则匹配成功时,应该执行的操作。动作规则可以是调用外部服务、更新数据、发送通知等。
在RuleGo中,动作规则的定义可以是这样的:
action "example_action_rule" {
// 动作逻辑
}
2.3 规则的编写与测试
2.3.1 规则编写实践
编写规则时,首先要确定业务场景和需求。以贷款审批为例,可能需要检查申请人的信用评分是否高于阈值,并且是否有未偿还的债务。
在RuleGo中编写规则的基本步骤包括:
- 定义条件规则: 基于业务逻辑定义条件表达式。
- 定义动作规则: 根据条件规则的匹配结果,指定要执行的动作。
- 使用语法检查: 利用RuleGo的IDE或编辑器插件,检查语法正确性。
2.3.2 规则测试方法和工具
规则测试是确保规则按照预期执行的关键步骤。RuleGo提供了多种测试方法和工具,包括单元测试、集成测试和规则的模拟执行。
测试工具应提供以下功能:
- 模拟输入数据: 快速设置测试用例,模拟真实世界的数据输入。
- 运行和调试: 执行规则并观察输出,进行调试。
- 结果验证: 检查规则执行结果是否符合预期。
// RuleGo测试代码示例
func TestExampleConditionRule(t *testing.T) {
// 初始化测试环境
// 设置输入数据 context
// 执行规则
// 验证输出结果
}
注意: 在上述代码中,我们假设有相应的测试辅助函数
initTestEnv,setData,executeRule, 和verifyResult。
规则的编写和测试是保证规则引擎能够正确执行业务逻辑的基础。通过这些实践,开发者可以确保每个业务场景下的规则都能得到正确的应用和执行。
3. 轻量级内存和CPU优化
3.1 内存管理优化技术
3.1.1 内存使用的监控和分析
在编写高效的应用程序时,合理管理内存资源至关重要。内存泄漏、过度分配、以及不当的内存访问都可能导致性能下降或程序崩溃。因此,监控和分析内存使用是性能优化的第一步。
在Go语言中,标准库提供了一些工具来帮助开发者监控内存使用情况。例如, runtime.ReadMemStats 函数可以用来读取内存统计信息。此外,pprof库是Go的性能分析工具,能够对程序进行采样分析,提供内存使用和CPU性能的详细报告。
使用pprof进行内存分析的基本步骤如下:
1. 导入pprof包并在程序中注册HTTP处理器。
2. 在需要分析的代码位置添加特定的pprof函数调用,或者在运行时动态地使用pprof的HTTP接口。
3. 启动pprof分析器,并指定输出文件或直接在浏览器中查看内存分析结果。
import _ "net/http/pprof"
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
在上述代码中,我们通过 http.ListenAndServe 启动了一个HTTP服务器,并注册了pprof的处理器。pprof将提供内存和CPU分析的端点。
3.1.2 优化内存使用的策略
内存使用优化需要根据内存使用分析报告来制定策略。以下是一些常见的内存使用优化策略:
- 避免内存泄漏 :确保所有的goroutine正常退出,并且所有的资源都被正确释放。
- 优化数据结构 :使用合适的数据结构可以减少内存占用。例如,使用
sync.Pool可以重用对象,减少临时对象的创建。 - 减少内存分配 :在循环或频繁调用的函数中避免使用
fmt包,因为它会隐式地进行内存分配。尽量使用bytes.Buffer或strings.Builder。 - 使用内存池 :对于需要频繁创建和销毁的对象,使用内存池可以显著减少内存分配。
- 延迟初始化 :对于那些不是立即需要的对象,可以延迟到实际使用时再进行初始化,避免在程序启动时就分配大量内存。
var pool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
}
// 使用内存池
data := pool.Get().([]byte)
defer pool.Put(data)
在上述代码中,我们创建了一个 sync.Pool 类型的内存池,用于复用 []byte 类型的对象。在实际使用时,从池中获取对象进行操作,并在操作完成后将对象返回池中。
3.2 CPU性能优化策略
3.2.1 CPU资源监控和分析
与内存监控类似,了解程序对CPU资源的消耗也是优化性能的关键。Go语言提供了多种工具来监控和分析CPU资源的使用情况。其中包括pprof工具和trace工具,它们能够提供关于CPU使用情况的深入分析。
- pprof :除了内存分析外,pprof还提供了CPU性能分析的功能。通过pprof,我们可以得知程序中哪些函数消耗了较多的CPU资源。
- trace :Go的trace工具可以提供程序运行的详细时间线,帮助我们识别程序中的性能瓶颈。
使用pprof进行CPU性能分析的步骤类似于内存分析,但通常需要将分析结果保存到文件中,然后使用pprof的图形化工具或命令行工具来查看分析结果。
import _ "net/http/pprof"
// 在程序中启动pprof HTTP服务器
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
3.2.2 提升CPU效率的方法
为了提高CPU的使用效率,可以考虑以下策略:
- 避免不必要的计算 :对于一些可以通过预先计算或缓存结果来避免的计算,应当尽可能避免。
- 减少锁竞争 :在并发程序中,避免多个goroutine频繁竞争同一个锁,可以使用更细粒度的锁或无锁编程技术。
- 减少上下文切换 :上下文切换会消耗CPU资源,因此应该减少goroutine的数量,并使用通信来替代锁。
- 利用并发优势 :合理地利用Go的并发模型,将任务分解为可以并行处理的部分,以充分利用多核CPU的优势。
- 算法优化 :选择更高效的算法和数据结构,例如使用快速排序代替冒泡排序。
3.3 案例分析:性能优化实例
3.3.1 实际应用中的优化案例
在实际的应用场景中,内存和CPU优化往往需要结合具体的业务逻辑。以下是一个假设的优化案例:
假设我们有一个Web服务器处理来自客户端的请求,最初我们发现该服务器在高并发情况下响应时间变得非常缓慢。通过pprof工具分析,我们定位到问题在于大量重复创建和销毁goroutine以及频繁的内存分配。
针对这些问题,我们采取了以下优化措施:
- 引入工作池 :我们将请求处理逻辑放入工作池中,复用goroutine,避免了频繁创建和销毁goroutine带来的开销。
- 对象池化 :对于频繁使用的临时对象,比如缓冲区,使用了
sync.Pool来减少内存分配和垃圾回收的压力。 - 代码优化 :对一些关键函数进行了代码层面的优化,例如,在循环中重用局部变量而不是每次迭代都创建新变量。
3.3.2 案例总结和经验分享
通过上述优化,服务器的性能得到了显著提升。从这个案例中我们可以学到以下几点经验:
- 监控和分析的重要性 :在进行性能优化之前,充分的监控和分析是必不可少的。
- 针对具体问题采取具体措施 :每个性能瓶颈都有其特定原因,需要根据实际情况采取相应的优化策略。
- 基准测试 :在优化前后进行基准测试,以便量化优化的效果。
- 持续优化 :性能优化是一个持续的过程,随着系统的变化,可能需要不断地调整和优化策略。
通过这个案例分析,我们可以看到优化内存和CPU使用不仅仅是技术上的挑战,更是对系统整体设计和实现的考量。
4. Go语言并发优势利用
Go语言从诞生起就被设计成可以充分利用现代多核处理器的编程语言,其并发模型简洁而高效。这一章节将深入探讨Go语言并发模型的核心原理,并通过实践案例来展示如何利用Go语言的并发特性来优化RuleGo规则引擎的性能。
4.1 Go语言并发模型解析
Go语言通过轻量级线程称为Goroutine的并发机制,允许开发者以极低的性能开销创建成千上万的并发任务。这使得Go语言非常适合于高并发场景。
4.1.1 Goroutine和通道的工作机制
Goroutine是Go语言并发的核心,其背后是由Go运行时(runtime)来管理的。一个Goroutine可以被看作是一个函数的并发执行实例。当一个函数启动时,Go运行时会自动为它创建一个新的Goroutine,这个Goroutine会在一个系统线程上执行。
func hello() {
fmt.Println("Hello world")
}
func main() {
go hello() // 启动一个新的Goroutine
fmt.Println("Hello main")
}
上述代码中, go hello() 启动了一个新的Goroutine。主线程和新启动的Goroutine并发执行,这样就实现了并行处理。
通道(Channel)是Go语言中的一个核心类型,它提供了一种数据结构来连接并发执行的Goroutine。通过通道,可以安全地进行数据交换,避免了传统的多线程编程中的数据竞争和条件竞争问题。
4.1.2 并发控制和同步工具
Go语言提供了多种同步工具,包括互斥锁(Mutex)、读写锁(RWMutex)、条件变量(Cond)、WaitGroup等,它们可以帮助开发者控制并发访问共享资源的时机和顺序。
var count int
var mutex sync.Mutex
func increment() {
mutex.Lock()
count++
mutex.Unlock()
}
func main() {
for i := 0; i < 1000; i++ {
go increment() // 启动多个Goroutine来增加计数
}
time.Sleep(time.Second) // 等待所有Goroutine完成
fmt.Println("Count:", count) // 输出最终计数结果
}
上述代码中, mutex 用于保证在多个Goroutine中对 count 变量的增加操作是线程安全的。
4.2 并发编程实践
实际的规则引擎工作往往涉及到复杂的并发场景,如何在并发环境下高效且正确地处理规则至关重要。
4.2.1 并发场景下的规则处理
规则处理涉及到对数据的读取、处理和输出,每个步骤都可能需要并发执行。例如,在RuleGo中,可能同时需要处理上千条规则,这时候就需要利用Goroutine来并行处理这些规则。
func processRule(rule Rule) {
// 处理规则逻辑
}
func main() {
rules := getRules() // 假设这个函数可以获取到所有的规则
var wg sync.WaitGroup
for _, rule := range rules {
wg.Add(1) // 每个任务开始前,增加WaitGroup计数
go func(r Rule) {
defer wg.Done() // 任务完成时减少WaitGroup计数
processRule(r)
}(rule)
}
wg.Wait() // 等待所有任务完成
fmt.Println("所有规则处理完毕")
}
上述代码使用WaitGroup来等待所有Goroutine完成,并行处理规则。
4.2.2 性能测试和分析
为了确保并发程序的性能符合预期,性能测试和分析是不可或缺的步骤。Go语言的 testing 包和 pprof 包可以帮助我们完成这一任务。
func BenchmarkProcessRules(b *testing.B) {
for i := 0; i < b.N; i++ {
processRules()
}
}
可以通过 go test -bench=. -benchmem 命令来运行基准测试,获取性能指标。
4.3 并发优势在RuleGo中的体现
利用Go语言的并发优势,RuleGo能够提供更高的性能和更好的扩展性。
4.3.1 实际应用的并发设计
在实际的RuleGo规则引擎中,可以设计一个并发执行器,它负责接收规则任务,并将它们分配给多个Goroutine来处理。这种设计模式可以极大地提升处理规则的效率,特别是在规则数量庞大时。
4.3.2 并发优势带来的性能提升
由于Goroutine的开销极低,相比于传统的线程模型,Go语言的并发处理能够显著减少资源消耗。这在处理大量规则时,可以带来显著的性能提升,因为能够充分利用现代CPU的多核优势。
在本章节中,我们深入了解了Go语言的并发模型,并展示了如何将这些并发特性应用到RuleGo规则引擎中,来实现更优的性能和更高的并发能力。通过理论和实践相结合的方式,我们可以看到Go语言并发优势在实际应用中的巨大潜力和价值。
5. 嵌入式设计带来的集成便利
5.1 嵌入式系统的概念和特点
5.1.1 嵌入式系统的定义
嵌入式系统是专用于控制、监视或辅助机械和设备运行的计算机系统。它不同于通用计算机系统,因为嵌入式系统通常被设计成具有特定的功能,而且它们的硬件和软件通常紧密集成在一起,以满足特定应用的需求。嵌入式系统在工业控制、家用电器、汽车电子、医疗设备、航空航天等领域得到了广泛的应用。
5.1.2 嵌入式系统的设计原则
设计嵌入式系统时需要考虑的关键原则包括硬件和软件的集成、资源优化、实时性能、可扩展性和可靠性。嵌入式设计师通常需要在有限的内存和处理能力约束下,实现高效和稳定的系统。此外,嵌入式系统还需要考虑低功耗和对环境的适应性。
5.2 RuleGo的嵌入式设计
5.2.1 RuleGo的嵌入式特性解析
RuleGo是一个专为嵌入式系统设计的规则引擎,它特别注重轻量级和高效率。RuleGo的嵌入式特性包括但不限于:
- 资源占用小 :在内存和CPU使用上进行优化,使其能够在资源有限的嵌入式设备上运行。
- 模块化设计 :易于集成到现有的嵌入式系统中,支持快速开发和定制化。
- 实时性能 :为实时或接近实时的规则处理进行了优化。
5.2.2 RuleGo与不同平台的兼容性
RuleGo支持跨平台运行,这意味着它可以部署在多种不同架构的嵌入式设备上。例如,它可以运行在ARM架构的微控制器,以及x86或MIPS架构的嵌入式系统。RuleGo的可移植性得益于其使用了Golang这种跨平台的语言,并且通过抽象层来隔离平台相关的依赖。
5.3 嵌入式集成案例分析
5.3.1 集成场景和案例介绍
一个典型的集成案例是智能家居控制系统。在这个场景中,RuleGo可以作为一个决策引擎来管理家中的智能设备。例如,它可以触发基于时间的灯光自动化,响应温度传感器的读数来调整HVAC系统的设置,或者在检测到门窗开启时发送通知。
5.3.2 案例中集成的优势分析
将RuleGo集成到智能家居系统中具有以下优势:
- 灵活性 :通过规则引擎,用户可以轻松地创建和修改自动化任务,无需重新编程。
- 效率提升 :实时监控和决策能够确保设备在最合适的时机运行,优化能源使用。
- 可扩展性 :随着更多智能设备的加入,RuleGo可以无缝扩展以支持新的规则和自动化流程。
代码块示例
// 一个简单的Goroutine示例,用于展示并发执行
func simpleGoroutine() {
// 使用Go关键字启动一个新的goroutine
go func() {
fmt.Println("This is a concurrent execution.")
}()
// 主goroutine需要等待上面的goroutine完成,或者可以使用sync.WaitGroup
// 来等待多个goroutine完成。
time.Sleep(1 * time.Second)
}
逻辑分析和参数说明
在上述代码中,我们定义了一个匿名函数(即没有命名的函数),并在一个新创建的goroutine中执行它。Goroutines是Go语言并发模型的核心,允许同时执行多个函数调用。在这个例子中, simpleGoroutine 函数启动了一个并发执行的goroutine,而主goroutine继续执行 time.Sleep ,这是为了确保在程序退出前,goroutine有足够的时间执行。
这个简单示例演示了Go语言的并发特性,它是基于CSP(Communicating Sequential Processes)模型的。goroutine之间的通信依赖于通道(channels)进行数据交换,但在此例中,我们没有展示数据交换的机制。
表格示例
| 特性 | 描述 |
|---|---|
| 轻量级 | 低内存占用,快速启动 |
| 可配置 | 可通过配置文件灵活设置规则 |
| 实时性 | 高效规则引擎,快速响应事件 |
| 易集成 | 可以嵌入到多种嵌入式系统 |
表格说明
上表总结了RuleGo在嵌入式设计中的主要特性,包括轻量级设计、可配置性、实时性以及易于集成的特点。这些特性为嵌入式系统提供了强大的规则处理能力,同时保持了对系统资源的高效利用。
在设计和选择嵌入式系统组件时,特别是用于实时任务的系统,这些特性显得尤为重要。例如,在工业自动化控制系统中,系统可能需要响应数十到数百个传感器信号,并根据复杂的业务逻辑进行实时决策。RuleGo作为嵌入式规则引擎,能够在这样的环境中发挥作用,提供可靠的规则处理能力。
mermaid格式流程图示例
graph LR
A[开始] --> B{检测条件}
B -->|是| C[执行动作]
B -->|否| D[继续监控]
C --> E[等待下一次条件检测]
E --> B
D --> E
流程图说明
上述mermaid流程图展示了使用RuleGo规则引擎的简单决策过程:
- 开始 :启动规则引擎。
- 检测条件 :RuleGo监控相关条件是否满足。
- 执行动作 :如果条件满足,执行预定义的动作。
- 等待下一次条件检测 :动作执行完毕后,继续监控条件或者等待下一次条件的检查。
这个流程可以应用在各种实时监控场景中,如安全系统、健康监测等。RuleGo的灵活性使得它能够很容易地适应不同的业务逻辑,提供即时反应的规则处理能力。
通过嵌入式设计,RuleGo可以无缝集成到现有的系统中,同时提供高效的资源管理和运行时表现。本章节分析了嵌入式系统设计原则和RuleGo的特性,以及在具体案例中的应用优势,通过代码块、表格和流程图的方式,加深了对嵌入式集成便利性的理解。
6. API接口及规则管理灵活性
规则引擎的灵活性和集成能力在很大程度上取决于它的API设计和规则管理机制。本章节将深入探讨RuleGo规则引擎的API接口设计原则、功能以及如何实现规则的动态管理,进而提升整个系统的灵活性和可靠性。
6.1 RuleGo的API设计
6.1.1 API设计的原则和框架
在设计API时,我们需要确保接口的清晰性、一致性和可用性。RuleGo遵循RESTful设计原则,这意味着它的API是无状态的、可以缓存的,并且使用统一的资源命名约定。此外,为了提高易用性,RuleGo还提供了命令行工具(CLI)和图形用户界面(GUI)以供用户轻松管理规则。
接口的框架主要基于以下几部分:
- 资源表示 :每个API调用都是对规则引擎中一个具体资源的操作。
- HTTP方法 :使用GET、POST、PUT、DELETE等标准方法来表示读取、创建、更新和删除操作。
- 状态码 :返回标准的HTTP状态码,以便客户端可以轻松识别请求的结果。
下面是一个简单的API设计例子,用于列出所有规则:
GET /rules
6.1.2 API接口的功能和用法
RuleGo提供了一系列API接口来支持规则的创建、查询、更新和删除。以下是一个创建新规则的API示例:
POST /rules
Content-Type: application/json
{
"name": "sample_rule",
"condition": "user.status == 'active'",
"action": "send_notification('User is active')"
}
执行上述请求后,RuleGo会返回新创建的规则标识符或任何错误信息。这种API设计使得开发者可以轻松地通过编程方式与RuleGo引擎交互,实现规则的自动化管理。
6.2 规则管理的灵活性
6.2.1 规则的动态加载和卸载
在RuleGo中,规则的动态管理是核心功能之一。开发者可以不必重启引擎,直接通过API动态加载新的规则或卸载不再需要的规则。这使得规则的更新和维护变得无缝且高效。
例如,以下代码展示了如何动态加载一条规则:
PUT /rules/load
Content-Type: application/json
{
"content": "new_rule.go"
}
这条API将指定的规则文件 new_rule.go 加载到引擎中。规则文件应该遵循RuleGo的语法规则。
6.2.2 规则版本控制和回滚机制
为了保证规则更新的可靠性,RuleGo提供了版本控制机制。每次规则的更新都会生成新的版本号,开发者可以查询历史版本并根据需要回滚到之前的版本。
GET /rules/versions
此API会返回规则的所有版本信息,开发者可以使用以下API来回滚到特定版本:
POST /rules/rollback
Content-Type: application/json
{
"version": "1.0.2"
}
6.3 规则管理实践
6.3.1 规则管理的实现方法
RuleGo的规则管理功能主要通过一组API接口实现,这些API可以由开发者通过编程方式调用,也可以通过内置的CLI或GUI进行交互。开发者可以创建专门的脚本或应用程序来自动化规则的管理任务。
一个典型的自动化脚本示例如下:
#!/bin/bash
# 创建新规则
curl -X POST http://localhost:8080/rules -d @new_rule.json
# 列出所有规则
curl http://localhost:8080/rules
# 删除规则
curl -X DELETE http://localhost:8080/rules/sample_rule
6.3.2 实践中的问题解决和优化
在实践过程中,开发者可能会遇到规则冲突、性能瓶颈或系统稳定性的挑战。RuleGo设计时考虑到了这些问题,并提供了相应的机制来解决。
例如,为了避免规则间的冲突,RuleGo提供了优先级设置,规则可以根据业务需求设定优先级,确保正确执行。对于性能问题,RuleGo提供了性能分析工具,可帮助开发者识别并优化低效的规则。此外,RuleGo的集群模式支持在多节点间分布式执行规则,进一步提高了系统的可靠性和扩展性。
在此基础上,我们可以通过持续集成和持续部署(CI/CD)流程来整合这些规则管理实践,使得整个系统的维护和更新更加高效和自动化。通过这种方式,RuleGo可以帮助企业构建一个高度灵活和可维护的规则驱动系统。
简介:RuleGo是一个为Go语言开发的规则引擎,旨在简化应用程序中复杂业务逻辑的实现。它允许开发者将业务规则与核心代码分离,便于维护更新。RuleGo通过定义条件和动作来处理各种数据任务,并以轻量级和高性能的特点运行于资源受限环境。由于Go语言的并发优势,RuleGo能高效并行处理规则。嵌入式设计让RuleGo可以直接集成到应用程序中,减少外部依赖,增强系统响应速度和安全。API接口使规则管理更加灵活,支持非程序员参与。RuleGo的”rulego-main”文件提供了核心引擎和使用示例,方便开发者快速集成和应用。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 27
27 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)