1 C语言
1.1 从源码到可执行文件的过程
- 预处理:去掉空格、注释,处理预处理指令(如
#include、#define),生成处理后的源代码文件。
- 编译:将预处理后的源代码翻译成汇编代码,生成汇编文件。
- 汇编:将汇编代码翻译成机器码,生成一个或多个目标文件(二进制文件)。
- 链接:合并目标文件、C标准库文件及其他库文件,生成最终可执行的二进制程序。
1.2 标识符及命名规范
- 定义:C语言中变量、函数、数组名、结构体等要素命名时使用的字符序列。
- 强制规范:
- 由小写/大写英文字母、0-9或
_组成。
- 不能以数字开头。
- 不可以是关键字(如
int、if)。
- 建议规范:见名知意,如
sum、userName;可采用下划线拼接(max_score)或小驼峰命名(maxScore)。
1.3 不同位数系统的地址字节数
- 32位系统:地址用4个字节表示。
- 64位系统:地址用8个字节表示。
2 变量
2.1 变量的声明和定义区别
| 类型 |
核心区别 |
示例 |
| 声明(Declaration) |
告知编译器变量存在及类型,不分配内存 |
extern int a; |
| 定义(Definition) |
为变量分配内存并初始化,形成完整实体 |
int a = 10; |
2.2 变量和常量的区别
- 值可改性:变量的值可修改,常量的值不可修改。
- 内存分配时机:变量通常在运行时分配内存,常量通常在编译时分配内存。
2.3 定义常量的方式及区别
| 方式 |
特点 |
示例 |
const关键字 |
C99新增,需指定数据类型,编译时类型检查,有作用域,更安全 |
const int MAX = 100; |
#define宏定义 |
预处理阶段文本替换,无类型检查,无作用域,更灵活 |
#define MAX 100 |
2.4 全局变量和局部变量的区别
| 对比维度 |
全局变量 |
局部变量 |
| 作用域 |
整个程序 |
定义它的函数或代码块内 |
| 生命周期 |
程序运行期间始终存在 |
函数调用/代码块执行期间 |
| 存储位置 |
全局静态区 |
栈区 |
| 默认初始化 |
未初始化时默认值为0/空 |
未初始化时值未定义(随机) |
2.5 num++和++num的区别
num++:先取值,再运算(值为num累加前的结果),如int b = num++;(先赋值b=num,再num=num+1)。++num:先运算,再取值(值为num累加后的结果),如int b = ++num;(先num=num+1,再赋值b=num)。
3 宏
3.1 常用预处理命令
#include(引入头文件)、#define(宏定义)、#if/#else/#elif/#endif(条件编译)、#undef(取消宏定义)、#ifdef/#ifndef(判断宏是否定义)。
3.2 取消宏定义
使用#undef命令,如#undef MAX(取消MAX的宏定义)。
3.3 条件编译及应用场景
- 定义:通过预处理指令,根据条件编译或排除代码,实现不同版本代码生成。
- 应用场景:
- 跨平台编程(为Windows/Linux编写不同代码)。
- 调试代码(开发时启用调试逻辑,发布时屏蔽)。
- 特性选择(根据宏定义启用/禁用功能模块)。
- 功能开关(通过编译选项控制代码是否生效)。
4 数据类型
4.1 C语言数据类型分类
- 整数类型:
char、short、int、long、long long。
- 浮点类型:
float(单精度)、double(双精度)、long double(长双精度)。
4.2 整数和浮点数的存储区别
- 整数:以二进制补码形式存储。
- 浮点数:按IEEE 754标准存储,包含符号位、指数位和尾数位(如
float占4字节,double占8字节)。
4.3 char类型的本质
长度为1字节(8位)的整数,实际存储字符对应的ASCII码值(如'a'的ASCII码为97,存储为0x61)。
4.4 数据类型自动转换原则
- 整数类型间:窄字节→宽字节(如
char→int),有符号→无符号。
- 浮点类型间:低精度→高精度(如
float→double)。
- 整数与浮点:整数→浮点数(如
int→float)。
4.5 枚举的应用场景
- 替代宏定义,提高代码可读性(如
enum Color {RED, GREEN, BLUE};)。
- 表示相关状态/选项(如设备状态
enum State {IDLE, RUNNING, ERROR};)。
- 表示错误代码(如
enum ErrorCode {SUCCESS=0, FILE_NOT_FOUND=1};)。
- 限制变量取值范围,增强程序健壮性。
4.6 typedef和#define的区别
| 对比维度 |
typedef |
#define |
| 本质 |
C语言关键字,创建类型别名 |
宏定义,预处理阶段文本替换 |
| 类型检查 |
编译时进行类型安全检查 |
无类型检查 |
| 作用域 |
有作用域(如局部typedef仅在函数内有效) |
无作用域,从定义到文件结束有效 |
4.7 switch的参数类型要求
参数必须是整数类型(如int、char、enum,不能是float、double或字符串)。
4.8 break和continue的区别
break:结束当前循环或switch语句,跳转到语句外继续执行。continue:跳过当前循环的剩余部分,直接开始下一次循环(不结束循环)。
5 数组
5.1 数组特点及长度计算
- 特点:
- 元素在内存中连续、有序排列。
- 初始化后长度固定,不可修改。
- 通过索引(下标)快速访问元素,时间复杂度O(1)。
- 长度计算:
数组长度 = sizeof(数组名) / sizeof(单个元素),如int arr[5];的长度为sizeof(arr)/sizeof(int) = 5。
5.2 字符串的本质
是字符数组,在内存中以空字符\0(ASCII值为0)作为结束标志(如"abc"实际存储为'a'、'b'、'c'、'\0')。
5.3 sizeof()和strlen()的区别
| 函数 |
计算范围 |
示例(char str[] = "abc";) |
sizeof() |
字符数组总字节数(含\0) |
sizeof(str) = 4(3个字符+1个\0) |
strlen() |
实际字符个数(不含\0) |
strlen(str) = 3 |
5.4 多维数组及内存存储
- 定义:元素为数组的数组(如
int arr[2][3];表示2个元素,每个元素是含3个int的数组)。
- 内存存储:连续存储,按行优先顺序(如
arr[0][0]→arr[0][1]→arr[0][2]→arr[1][0]…)。
6 指针
6.1 同类型指针相减的结果
得到两个指针之间元素的个数(非地址差值),如int arr[5], *p1=arr, *p2=arr+2;,则p2-p1=2(表示中间有2个int元素)。
注意:指针仅支持减法,不支持加法。
6.2 指针加减整数的结果
指针指向的内存地址移动,移动字节数=指针类型字节数×整数,如:
int *p:p+1向后移动4字节(int占4字节)。char *p:p-2向前移动2字节(char占1字节)。
6.3 指针能否比较大小
可以比较(如==、<、>),比较的是指针指向的内存地址大小(如p1 < p2表示p1指向的地址值小于p2)。
6.4 数组名与指向首元素指针的区别
| 对比维度 |
数组名 |
指向首元素的指针 |
| 类型 |
元素类型[](如int[5]) |
元素类型*(如int*) |
sizeof结果 |
整个数组大小(如int arr[5]的sizeof(arr)=20) |
指针本身大小(32位系统4字节,64位系统8字节) |
&取地址 |
首元素地址(&arr与arr值相同,但类型不同) |
指针变量自身的地址 |
+1结果 |
下一个元素地址(如arr+1指向arr[1]) |
下一个元素地址(与数组名+1效果相同) |
*取值 |
首元素的值(*arr = arr[0]) |
首元素的值(与数组名*效果相同) |
| 可变性 |
不可重新赋值(如arr = arr+1错误) |
可重新赋值(如p = p+1正确) |
6.5 指针数组和数组指针的区别
| 类型 |
定义 |
本质 |
示例 |
| 指针数组 |
元素类型 *数组名[长度] |
数组,每个元素是指针 |
int *p[3];(3个int*类型的指针组成的数组) |
| 数组指针 |
元素类型 (*指针名)[长度] |
指针,指向一个数组 |
int (*p)[3];(指向含3个int的数组的指针) |
6.6 指针函数和函数指针的区别
| 类型 |
定义 |
本质 |
示例 |
| 指针函数 |
返回类型 *函数名(参数列表) |
函数,返回值为指针 |
int *add(int a, int b);(返回int*类型的函数) |
| 函数指针 |
返回类型 (*指针名)(参数列表) |
指针,指向一个函数 |
int (*p)(int, int);(指向参数为2个int、返回int的函数) |
6.7 常量指针和指针常量的区别
| 类型 |
定义 |
核心限制 |
示例 |
| 常量指针 |
const 类型 *指针名 或 类型 const *指针名 |
指向的常量值不可修改,指针地址可修改 |
const int *p = &a; *p=10;(错误);p=&b;(正确) |
| 指针常量 |
类型 *const 指针名 |
指针地址不可修改,指向的值可修改 |
int *const p = &a; p=&b;(错误);*p=10;(正确) |
6.8 字符数组和字符指针的区别
| 对比维度 |
字符数组 |
字符指针 |
| 内存分配 |
局部数组存栈区,全局数组存全局区;连续内存 |
指针存栈区,字符串字面量存全局常量区 |
| 大小 |
定义时需指定大小(如char arr[10];) |
指针本身占4/8字节,无固定存储大小 |
| 修改字符 |
可直接修改元素(如arr[0] = 'A';) |
不可修改字符串字面量(如char *p="abc"; p[0]='A';错误) |
| 整体赋值 |
不可重新赋值(如arr = "def";错误) |
可重新指向新字符串(如p = "def";正确) |
6.9 空指针
- 定义:不指向任何有效内存地址的指针,用
NULL表示(本质是(void*)0)。
- 特点:可赋值给任何指针类型;声明指针时无确切地址,建议赋
NULL(如int *p = NULL;)。
6.10 悬空指针
- 定义:指向已释放内存地址的指针(如
free(p);后未置NULL,p成为悬空指针)。
- 风险:访问悬空指针可能导致程序崩溃或数据错误。
6.11 野指针及避免方法
- 定义:指向不可知地址的指针(未初始化、悬空、越界访问均可能产生)。
- 避免方法:
- 指针声明时初始化(如
int *p = NULL;或int *p = &a;)。
- 释放内存后立即置
NULL(如free(p); p = NULL;)。
- 避免指针越界访问(如数组遍历不超过长度)。
6.12 指针和引用的区别
- 引用是C++特性,C语言无引用;引用本质是变量的别名,必须初始化且不可重新绑定,而指针可独立存在并修改指向。
7 结构体
7.1 结构体变量与结构体指针的访问区别
- 结构体变量:用**
.(点运算符)** 访问成员,如struct Student s; s.age = 20;。
- 结构体指针:用**
->(箭头运算符)** 访问成员,如struct Student *p = &s; p->age = 20;。
7.2 结构体长度计算(内存对齐)
- 核心规则(以8字节对齐为例):
- 第一个成员地址偏移量为0。
- 成员对齐:
- 成员类型<8字节:首地址为自身类型大小的整数倍(如
int成员首地址需是4的整数倍)。
- 成员类型≥8字节:首地址为8的整数倍。
- 内嵌结构体:首地址为内嵌结构体最大成员类型大小的整数倍。
- 整体补齐:结构体总大小为最大成员类型大小(或8,若最大成员≥8)的整数倍。
- 示例:
struct A {char c; int i;};,char占1字节,int需对齐到4字节,总大小为8字节(1+3(填充)+4=8)。
7.3 结构体和共用体的区别
| 对比维度 |
结构体(struct) |
共用体(union) |
| 内存使用 |
各成员拥有独立内存,总大小=成员大小之和+填充(内存对齐) |
所有成员共用一块内存,总大小=最大成员大小(需内存补齐) |
| 数据存储 |
各成员可同时存储有效数据,互不干扰 |
同一时间仅一个成员可使用内存,修改一个成员会覆盖其他成员数据 |
| 用途 |
存储不同类型的关联数据(如学生信息:姓名、年龄、成绩) |
节省内存,存储互斥的不同类型数据(如设备状态:整数码/字符串描述) |
8 函数
8.1 形参和实参的区别
| 类型 |
定义 |
特点 |
| 形参 |
函数定义中声明的参数(如void add(int a, int b)中的a、b) |
本质是局部变量,仅在函数内有效;函数调用时接收实参的值 |
| 实参 |
函数调用时传递的具体值/变量(如add(3, 5)中的3、5) |
需与形参类型匹配;传递时为“值传递”(普通参数)或“地址传递”(指针参数) |
8.2 主函数(main)的参数和返回值规则
- 参数:
- 无参数(最常用):
int main(void)。
- 带命令行参数:
int main(int argc, char *argv[]),其中argc是参数个数(至少为1,含程序名),argv是参数数组(argv[0]为程序名,argv[1]~argv[argc-1]为命令行参数)。
- 返回值:
int类型,return 0表示程序运行成功,非零值表示运行失败(操作系统可捕获该值)。
8.3 函数原型
即函数声明,包含函数名称、返回类型、参数列表(无函数体),用于告知编译器函数的接口信息,如int add(int a, int b);。通常放在头文件中,避免“未定义函数”错误。
8.4 常用C语言系统函数
- 输入输出:
printf()(格式化输出到控制台)、scanf()(格式化输入)。
- 字符串处理:
strlen()(计算字符串长度)、strcat()(拼接字符串)、strcmp()(比较字符串)。
- 数学计算:
ceil()(向上取整)、floor()(向下取整)、round()(四舍五入)、sqrt()(平方根)。
- 内存操作:
malloc()(动态分配内存)、free()(释放内存)、memcpy()(内存拷贝)。
8.5 传递指针与传递值的区别
| 传递方式 |
核心逻辑 |
适用场景 |
| 传递值 |
实参的值复制到形参,函数内修改形参不影响实参 |
传递基本数据类型(int、float等),无需修改实参 |
| 传递指针 |
实参的地址传递到形参,函数可通过指针修改实参指向的数据 |
传递数组、结构体等大型数据(避免拷贝开销),或需修改实参值 |
8.6 回调函数
- 定义:作为参数传递给其他函数的函数,当满足特定条件时被调用。
- 实现方式:通过函数指针传递,如
void process(int (*callback)(int), int data),其中callback是函数指针,指向需回调的函数。
- 用途:实现事件驱动(如中断回调)、框架扩展(如排序函数中的比较回调)。
8.7 带参宏定义和函数的区别
| 对比维度 |
带参宏定义(如#define ADD(a,b) ((a)+(b))) |
函数(如int add(int a, int b) {return a+b;}) |
| 执行时机 |
预处理阶段文本替换,无函数调用开销 |
运行时执行,需保存现场、传递参数、跳转执行,有调用开销 |
| 类型检查 |
无类型检查,可能因参数类型不匹配导致错误(如ADD(3.5, 2)无问题,add(3.5, 2)编译报错) |
编译器进行类型检查,参数类型不匹配时编译报错 |
| 代码体积 |
多次调用会导致代码膨胀(每次替换生成新代码) |
多次调用仅执行同一段函数代码,代码体积小 |
| 调试 |
无法单步调试宏替换后的代码 |
可单步调试函数内部逻辑 |
8.8 printf()、sprintf()、fprintf()的区别
| 函数 |
功能 |
输出目标 |
示例 |
printf() |
格式化输出数据 |
标准输出设备(控制台) |
printf("age: %d\n", 20); |
sprintf() |
格式化输出数据到字符串 |
字符数组(内存) |
char buf[50]; sprintf(buf, "name: %s", "Tom"); |
fprintf() |
格式化输出数据到文件 |
指定文件流(如FILE *) |
FILE *fp = fopen("log.txt", "w"); fprintf(fp, "error: %d\n", 1); |
9 关键字
9.1 static关键字的作用
- 静态局部变量:
- 存储在全局静态区,函数调用结束后不销毁,生命周期贯穿程序运行期间。
- 仅在首次函数调用时初始化,后续调用使用上次的值(如
void count() {static int num=0; num++;},每次调用num自增1)。
- 静态全局变量:
- 作用域仅限于声明它的源文件,其他源文件无法通过
extern引用。
- 避免全局变量重名冲突(如
static int g_val;仅在当前.c文件中有效)。
- 静态函数:
- 作用域仅限于声明它的源文件,其他源文件无法调用。
- 减少函数名污染(如
static void func() {}仅在当前.c文件中可调用)。
9.2 extern关键字的作用
- 用于声明外部链接的变量或函数,告知编译器该变量/函数在其他源文件中定义,当前文件可直接引用(无需重新定义)。
- 示例:在
a.c中定义int g_val = 10;,在b.c中通过extern int g_val;声明后,即可使用g_val。
9.3 volatile关键字的作用
- 核心作用:防止编译器优化,强制编译器每次使用变量时都从内存重新读取(而非使用寄存器中的备份)。
- 适用场景:
- 并行设备的硬件寄存器(如状态寄存器,值可能被硬件修改)。
- 中断服务子程序中访问的非自动变量(如
volatile int flag;,中断中修改flag,主程序需实时读取)。
- 多线程共享变量(避免线程间因编译器优化导致的数据不一致)。
10 内存
10.1 C语言内存模型
| 内存区域 |
存储内容 |
特点 |
| 栈区(stack) |
函数参数、局部变量、函数返回地址 |
由操作系统自动分配/释放,生长方向为低地址→高地址,大小固定(栈溢出会导致程序崩溃) |
| 堆区(heap) |
动态分配的内存(malloc/calloc/realloc申请) |
由程序员手动分配/释放(free),生长方向为高地址→低地址,大小灵活(需避免内存泄漏) |
| 全局(静态)区(static) |
全局变量、静态变量(static修饰)、字符串常量 |
程序启动时分配,结束时释放;全局变量和静态变量未初始化时默认值为0 |
| 程序代码区 |
函数体的二进制代码、只读数据(如const修饰的全局变量) |
只读属性,防止程序意外修改代码 |
10.2 1G内存计算机能否malloc(1.2G)
有可能。因为malloc申请的是虚拟地址空间的内存,与物理内存大小无直接关联;操作系统通过虚拟内存技术(如页交换),可将部分硬盘空间模拟为内存,满足大内存申请需求(实际使用时若物理内存不足,会触发页交换)。
10.3 内存泄漏
- 定义:程序中动态分配的堆内存(
malloc/calloc等申请)未释放或无法释放,导致系统内存浪费,长期运行可能使程序变慢甚至崩溃。
- 分类:
- 常发性内存泄漏:泄漏代码被多次执行(如循环中未释放内存)。
- 偶发性内存泄漏:仅在特定环境/操作下发生(如异常分支中未释放内存)。
- 一次性内存泄漏:泄漏代码仅执行一次(如程序启动时申请内存未释放)。
- 隐式内存泄漏:程序运行中持续分配内存,仅在结束时释放(如服务器长期运行会耗尽内存)。
10.4 内存溢出
- 定义:程序使用的内存超过系统可提供的最大内存(或进程允许的内存上限),导致程序无法运行(如提示“Out Of Memory”并崩溃)。
- 原因:
- 内存泄漏堆积:长期未释放的内存累积,最终耗尽可用内存。
- 超大对象加载:单个对象(如大数组、大结构体)大小超过剩余可用内存。
10.5 堆和栈的区别
| 对比维度 |
栈 |
堆 |
| 申请/释放方式 |
操作系统自动分配/释放(函数调用时分配,返回时释放) |
程序员手动申请(malloc)/释放(free) |
| 申请大小限制 |
栈大小固定(通常几MB),超过会触发栈溢出 |
堆大小灵活(受虚拟内存限制),可申请较大内存 |
| 生长方向 |
低地址→高地址 |
高地址→低地址 |
| 效率 |
效率高(使用一级缓存,无需复杂分配算法) |
效率低(使用二级缓存,需遍历空闲内存链表) |
| 内存碎片 |
无碎片(连续分配、释放) |
频繁申请/释放会产生碎片(小块空闲内存无法利用) |
10.6 堆栈溢出的原因
- 栈溢出:
- 栈大小设置过小(如局部数组过大:
int arr[100000];)。
- 递归层次过深(如无终止条件的递归函数)。
- 函数调用层次过深(如嵌套调用过多函数)。
- 堆溢出:
- 堆大小设置过小(嵌入式系统中常见)。
- 动态内存未释放(内存泄漏堆积)。
- 单次申请内存超过堆剩余空间(如
malloc(100MB)时堆仅剩余50MB)。
10.7 动态内存分配函数及注意事项
- 常用函数:
malloc(size_t size):分配size字节的未初始化内存,返回指向内存的指针(失败返回NULL)。calloc(size_t nmemb, size_t size):分配nmemb个大小为size的内存块,初始化为0,返回指针(失败返回NULL)。realloc(void *ptr, size_t size):调整ptr指向的内存大小为size字节,返回新内存指针(失败返回NULL,原内存不变)。free(void *ptr):释放ptr指向的堆内存(ptr必须是malloc/calloc/realloc返回的指针,不可重复释放或释放NULL)。
- 注意事项:
- 避免分配大量小内存块(增加系统开销,易产生碎片)。
- 内存使用后及时释放(避免内存泄漏),释放后将指针置
NULL(避免悬空指针)。
- 检查分配结果(如
if ((p = malloc(100)) == NULL) { /* 处理分配失败 */ })。
- 不越界访问动态内存(如
int *p = malloc(5*sizeof(int)); p[5] = 10;会破坏相邻内存)。
11 C语言库的使用
常用标准库及用途:
stdio.h:输入输出函数(printf、scanf、fopen等)。math.h:数学计算函数(sqrt、sin、ceil等)。stdlib.h:内存分配、随机数、类型转换等函数(malloc、free、rand等)。string.h:字符串处理函数(strlen、strcat、memcpy等)。time.h:时间相关函数(time、localtime等)。
12 数据结构和算法
12.1 数组和链表的区别
| 对比维度 |
数组 |
链表 |
| 内存存储 |
连续内存空间 |
非连续内存空间(节点含数据域和指针域) |
| 访问效率 |
索引访问(O(1)),效率高 |
遍历访问(O(n)),效率低 |
| 插入/删除效率 |
中间插入/删除需移动元素(O(n)),效率低 |
中间插入/删除仅需修改指针(O(1)),效率高 |
| 内存开销 |
无额外开销(仅存储数据) |
有额外开销(每个节点需存储指针) |
| 长度灵活性 |
初始化后长度固定,不可动态扩展 |
长度灵活,可动态添加/删除节点 |
12.2 栈和队列的区别
| 对比维度 |
栈(Stack) |
队列(Queue) |
| 核心原则 |
先进后出(LIFO,Last In First Out) |
先进先出(FIFO,First In First Out) |
| 操作位置 |
仅在栈顶(Top)进行插入(Push)和删除(Pop) |
队尾(Rear)插入(Enqueue),队头(Front)删除(Dequeue) |
| 适用场景 |
函数调用栈、表达式求值、括号匹配检查 |
任务调度(如进程队列)、消息队列、缓冲区处理 |
| 实现方式 |
数组栈(连续内存)、链表栈(非连续内存) |
数组队列(需循环队列避免假溢出)、链表队列 |
12.3 快慢指针在链表中的应用

- 判断链表是否有环:
- 快慢指针同时从表头出发,慢指针每次走1步,快指针每次走2步;若快指针追上慢指针,链表有环;若快指针走到
NULL,链表无环。
- 找出链表的中间节点:
- 快慢指针同时从表头出发,慢指针每次走1步,快指针每次走2步;当快指针走到表尾时,慢指针指向中间节点(偶数长度时指向中间偏左节点)。
- 删除链表倒数第n个节点:
- 快指针先出发走n步,随后快慢指针同时走1步;当快指针走到表尾时,慢指针指向倒数第n个节点的前驱节点,此时可删除目标节点。
- 删除排序链表中的重复项:
- 慢指针从表头出发,快指针从表头.next出发;若快慢指针值相同,删除快指针节点并后移快指针;若值不同,快慢指针同时后移,直至快指针走到
NULL。
12.4 满二叉树、完全二叉树、平衡二叉树的定义
- 满二叉树:每一层的结点个数都达到最大时的树,即第k层(从1开始计数)有2^(k-1)个结点,所有叶子结点均位于同一层。
- 完全二叉树:除最后一层外,其他每一层的结点数都达到最大,且最后一层的叶子结点均靠左排列的树;满二叉树是完全二叉树的特殊形式。
- 平衡二叉树:树上任意一个结点的两个子树的高度差不超过1,且该结点的两个子树也均为平衡二叉树的树。
12.5 算法
12.5.1 时间换空间与空间换时间的例子
| 策略 |
例子 |
时间复杂度 |
空间复杂度 |
| 时间换空间 |
冒泡排序 |
O(n²) |
O(1) |
| 空间换时间 |
快速排序 |
O(nlogn) |
O(nlogn) |
12.5.2 常见查找算法
- 顺序查找(线性查找)
- 原理:逐个遍历数据集合,对比每个元素与目标元素,直到找到目标或遍历结束。
- 平均时间复杂度:O(n),适用于无序或小规模数据集合。
- 二分查找
- 原理:仅适用于有序数据集合,从集合中间元素开始对比;若中间元素为目标,则查找结束;若目标小于中间元素,在左半部分继续查找,反之在右半部分查找,重复此过程直至找到目标或集合为空。
- 平均时间复杂度:O(logn),效率高于顺序查找。
- 分块查找
- 原理:结合顺序查找与二分查找,先将数据“按块有序”划分为m块(块内元素无序,块间元素有序),用二分查找确定目标所在块,再用顺序查找遍历块内元素。
12.5.3 常见排序算法
-
冒泡排序
- 原理:通过相邻元素两两对比,若顺序错误则交换位置,每一轮遍历将最大(或最小)元素“冒泡”到集合末尾,重复此过程直至集合有序。
- 平均时间复杂度:O(n²),属于稳定排序(相等元素相对位置不变)。
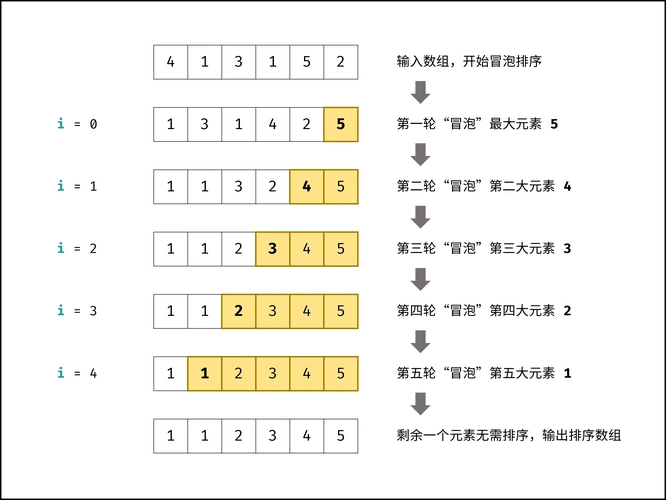
-
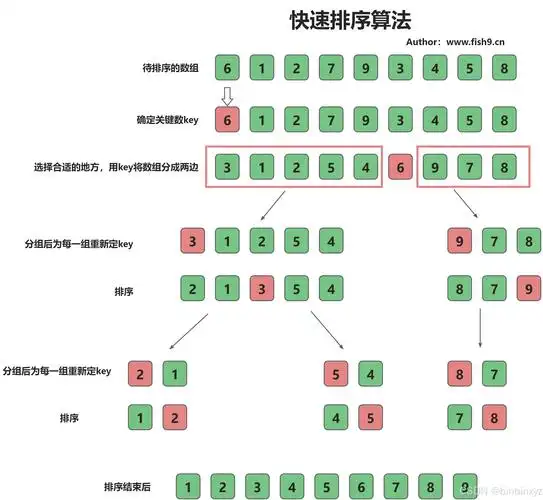
快速排序
- 原理:选择一个基准元素,将集合划分为两部分,左部分元素均小于基准,右部分元素均大于基准;再递归对左右两部分执行相同操作,直至所有子集合有序。
- 平均时间复杂度:O(nlogn),属于不稳定排序。
-
-
选择排序
- 原理:每次从待排序部分选择最小(或最大)元素,将其放到已排序部分的末尾,重复此过程直至集合有序。
- 平均时间复杂度:O(n²),属于不稳定排序。
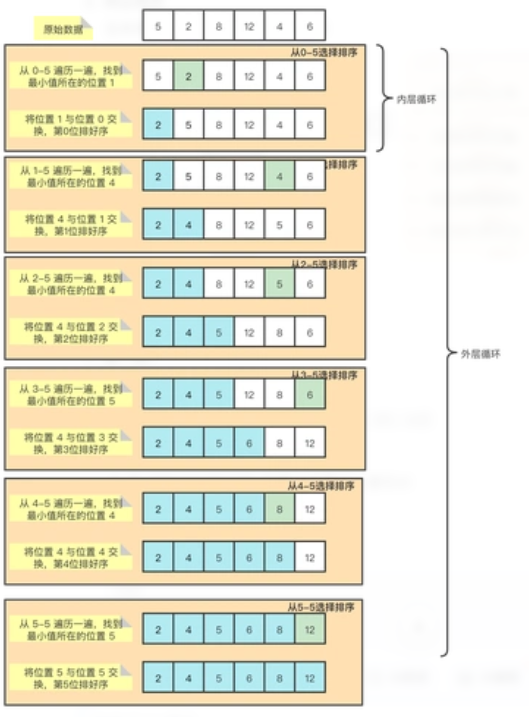
-
插入排序
- 原理:将待排序部分的元素逐个插入到已排序部分的合适位置,使已排序部分始终有序,重复此过程直至集合有序。
- 平均时间复杂度:O(n²),属于稳定排序。
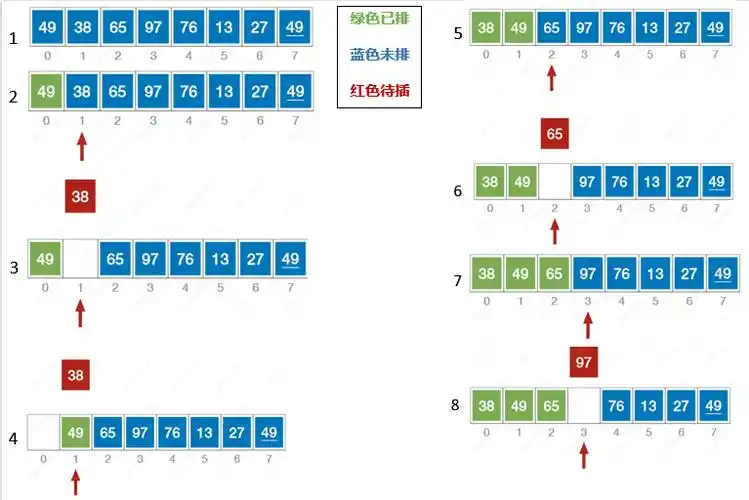



 25
25 0
0


 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)