
人工智能芯片开发——算子重构技术
本文介绍了Thinker架构中的两种可重构处理单元(PE):通用PE和超级PE。通用PE支持卷积层、全连接层和循环层的MAC运算,通过5bit控制字实现配置重构,包含数据流处理和状态机控制逻辑。超级PE在通用PE基础上扩展功能,新增池化、tanh、Sigmoid等5种操作,采用12bit控制字配置,通过重用乘法器和加法器提高资源利用率。两种PE均采用Verilog实现,支持灵活的算子重构以适应不同
目录
1.算子重构
在深入PE与片上存储前,需先明确算子重构的核心定位——它并非“重新设计算子”,而是根据硬件架构特性(PE 阵列、存储层次、互联方式)调整算子的实现方式,最终达成三大目标:
算力匹配:让算子的计算粒度(如卷积核大小、矩阵分块尺寸)与PE阵列的并行能力(如 PE 数量、运算精度)对齐,避免PE空闲;
能效优化:通过减少片外访存(DRAM访问功耗是SRAM的100倍以上),最大化片上数据复用;
灵活性平衡:在专用算力(适配特定算子)与通用能力(支持多模型算子)间找到最优解。
算子重构的核心维度包括:
计算拆解:将复杂算子(如3D卷积、多头注意力)拆分为 PE 可并行处理的子任务(如2D卷积块、单头注意力计算);
数据映射:定义输入数据(特征图、权重、QKV矩阵)如何分配到片上存储与PE中,最大化数据复用;
并行调度:规划PE的运算顺序(空间并行、时间并行、流水线)与数据流动路径,提升 PE 利用率。
Thinker的可重构异构阵列中PE分为两种类型:通用PE和超级PE。这两种类型的PE都支持算子重构。
2. 通用PE
通用PE支持卷积层、全连接层和循环层的MAC运算,并由5bit控制字(s1、s3、s6、s7、s11)进行配置重构。
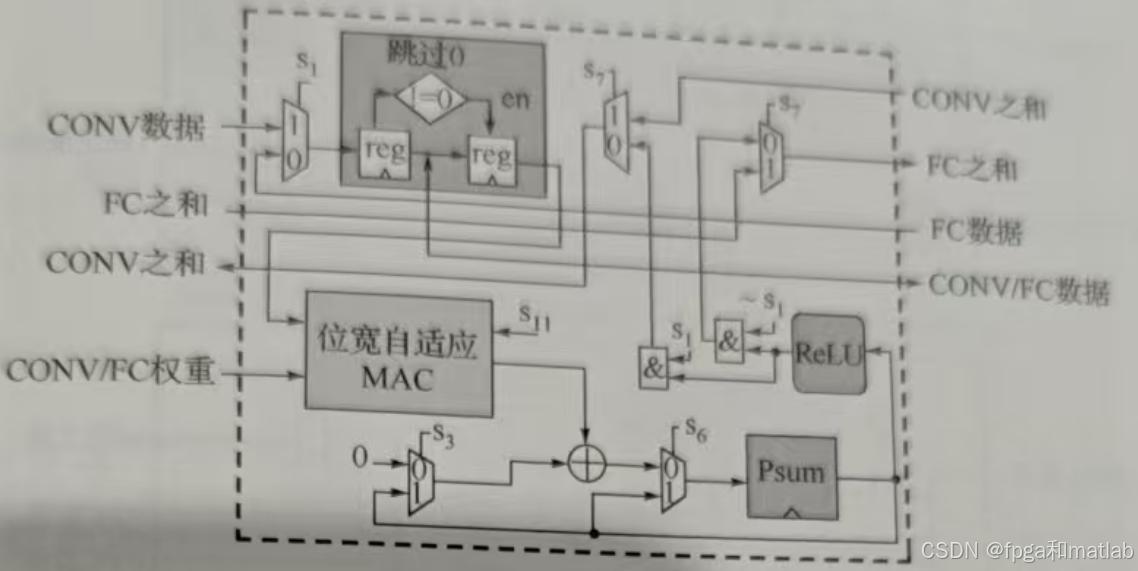
如上图所示,聚焦卷积(CONV)、全连接(FC)等基础运算的数据流转。输入有CONV数据、FC之和等,经“跳过 0”模块(处理无效数据)、位宽自适应MAC(乘加运算核心),结合控制字选通,输出CONV之和、FC数据等,构建基础神经网络运算通路,支撑卷积层、全连接层的MAC运算 。
通用PE,其Verilog实现方式如下:
module general_pe #(
parameter DATA_WIDTH = 16,
parameter WEIGHT_WIDTH = 16,
parameter OUTPUT_WIDTH = 32
)(
input wire clk,
input wire rst_n,
input wire [DATA_WIDTH-1:0] data_in,
input wire [WEIGHT_WIDTH-1:0] weight_in,
input wire [4:0] ctrl_word, // 5位控制字 s1, s3, s6, s7, s11
input wire enable,
output reg [OUTPUT_WIDTH-1:0] result_out,
output reg valid
);
// 控制位定义
localparam S1 = 4; // 假设控制字位顺序为s1, s3, s6, s7, s11
localparam S3 = 3;
localparam S6 = 2;
localparam S7 = 1;
localparam S11 = 0;
// 内部寄存器
reg [DATA_WIDTH-1:0] data_reg;
reg [WEIGHT_WIDTH-1:0] weight_reg;
reg [OUTPUT_WIDTH-1:0] mac_result;
reg [OUTPUT_WIDTH-1:0] accumulator;
// 乘法器和加法器
wire [DATA_WIDTH+WEIGHT_WIDTH-1:0] mult_result = data_reg * weight_reg;
// 状态机
localparam IDLE = 2'b00;
localparam COMPUTE = 2'b01;
localparam OUTPUT = 2'b10;
reg [1:0] current_state, next_state;
// 状态转换
always @(posedge clk or negedge rst_n) begin
if (!rst_n)
current_state <= IDLE;
else
current_state <= next_state;
end
// 下一个状态逻辑
always @(*) begin
case (current_state)
IDLE: next_state = enable ? COMPUTE : IDLE;
COMPUTE: next_state = OUTPUT;
OUTPUT: next_state = IDLE;
default: next_state = IDLE;
endcase
end
// 数据处理
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
data_reg <= 0;
weight_reg <= 0;
mac_result <= 0;
accumulator <= 0;
result_out <= 0;
valid <= 1'b0;
end else begin
case (current_state)
IDLE: begin
valid <= 1'b0;
if (enable) begin
data_reg <= data_in;
weight_reg <= weight_in;
end
end
COMPUTE: begin
// 根据控制字配置MAC操作
case ({ctrl_word[S1], ctrl_word[S3]})
// 卷积操作
2'b00: mac_result <= mult_result + (ctrl_word[S6] ? accumulator : 0);
// 全连接操作
2'b01: mac_result <= mult_result + (ctrl_word[S7] ? accumulator : 0);
// 循环层操作
2'b10: mac_result <= mult_result + (ctrl_word[S11] ? accumulator : 0);
default: mac_result <= mult_result;
endcase
// 更新累加器(如果需要)
if (ctrl_word[S6] || ctrl_word[S7] || ctrl_word[S11])
accumulator <= mac_result;
else
accumulator <= 0;
end
OUTPUT: begin
result_out <= mac_result;
valid <= 1'b1;
end
endcase
end
end
endmodule
3. 超级PE
超级PE由通用PE扩展而成,除了上述三种网络层的MAC运算以外,还支持另外5种类型的操作——池化、tanh、Sigmoid、标量乘法和加法以及 RNN 门控操作,由12bit控制字(s0~s11)进行配置重构。为了减小可重构阵列中不同类型操作部件的平均未使用 PE 面积,提高资源利用率,除了超级PE中的Pooling、Sigmoid和tanh外,乘法器和加法器在几乎所有类型操作中都被重用。图 显示了超级PE所支持的四种主要操作类型的数据通路。
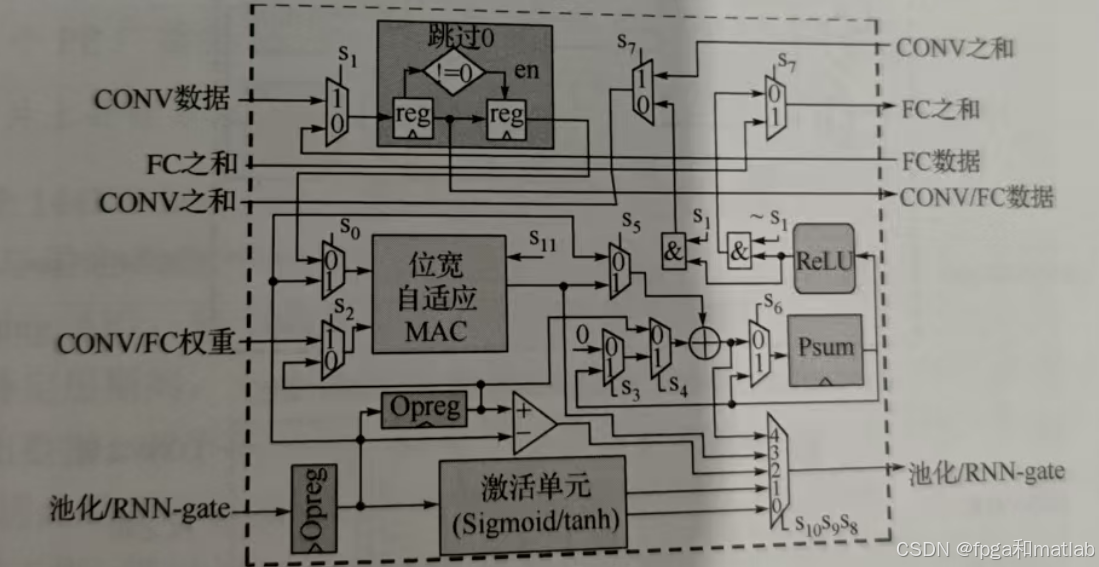
如上图所示,在通用PE基础上扩展功能。新增激活单元(Sigmoid/tanh)、Opreg(操作寄存器)等,可处理池化、RNN门控,以及更复杂激活函数运算。数据通路更丰富,能适配卷积、全连接、循环层(RNN-gate)等多场景,通过控制字灵活切换运算逻辑,实现算子重构适配不同网络层需求 。
超级PE,其Verilog实现方式如下:
module super_pe #(
parameter DATA_WIDTH = 16,
parameter WEIGHT_WIDTH = 16,
parameter OUTPUT_WIDTH = 32
)(
input wire clk,
input wire rst_n,
input wire [DATA_WIDTH-1:0] data_in,
input wire [WEIGHT_WIDTH-1:0] weight_in,
input wire [DATA_WIDTH-1:0] scalar_in, // 标量输入,用于标量运算
input wire [11:0] ctrl_word, // 12位控制字 s0~s11
input wire enable,
output reg [OUTPUT_WIDTH-1:0] result_out,
output reg valid
);
// 控制位定义
localparam S0 = 11;
localparam S1 = 10;
localparam S2 = 9;
localparam S3 = 8;
localparam S4 = 7;
localparam S5 = 6;
localparam S6 = 5;
localparam S7 = 4;
localparam S8 = 3;
localparam S9 = 2;
localparam S10 = 1;
localparam S11 = 0;
// 操作模式定义
localparam OP_CONV = 3'b000;
localparam OP_FC = 3'b001;
localparam OP_RNN = 3'b010;
localparam OP_POOL = 3'b011;
localparam OP_TANH = 3'b100;
localparam OP_SIGMOID = 3'b101;
localparam OP_SCALAR_MUL = 3'b110;
localparam OP_SCALAR_ADD = 3'b111;
// 内部信号
wire [OUTPUT_WIDTH-1:0] general_pe_out;
wire general_pe_valid;
reg [DATA_WIDTH-1:0] data_in_to_pe;
reg [WEIGHT_WIDTH-1:0] weight_in_to_pe;
reg [4:0] general_pe_ctrl; // 通用PE的5位控制字
reg [OUTPUT_WIDTH-1:0] post_process_data;
reg [OUTPUT_WIDTH-1:0] max_pool_reg;
reg [OUTPUT_WIDTH-1:0] avg_pool_reg;
reg [1:0] pool_count;
// 实例化通用PE作为基础
general_pe #(
.DATA_WIDTH(DATA_WIDTH),
.WEIGHT_WIDTH(WEIGHT_WIDTH),
.OUTPUT_WIDTH(OUTPUT_WIDTH)
) general_pe_inst (
.clk(clk),
.rst_n(rst_n),
.data_in(data_in_to_pe),
.weight_in(weight_in_to_pe),
.ctrl_word(general_pe_ctrl),
.enable(enable),
.result_out(general_pe_out),
.valid(general_pe_valid)
);
// 状态机
localparam IDLE = 3'b000;
localparam CONFIG = 3'b001;
localparam COMPUTE = 3'b010;
localparam POST_PROCESS = 3'b011;
localparam OUTPUT = 3'b100;
reg [2:0] current_state, next_state;
// 状态转换
always @(posedge clk or negedge rst_n) begin
if (!rst_n)
current_state <= IDLE;
else
current_state <= next_state;
end
// 下一个状态逻辑
always @(*) begin
case (current_state)
IDLE: next_state = enable ? CONFIG : IDLE;
CONFIG: next_state = COMPUTE;
COMPUTE: next_state = general_pe_valid ? POST_PROCESS : COMPUTE;
POST_PROCESS: next_state = OUTPUT;
OUTPUT: next_state = IDLE;
default: next_state = IDLE;
endcase
end
// 配置通用PE控制字
always @(*) begin
general_pe_ctrl = {ctrl_word[S1], ctrl_word[S3], ctrl_word[S6],
ctrl_word[S7], ctrl_word[S11]};
end
// 数据通路选择
always @(*) begin
case (ctrl_word[11:9]) // 使用高3位选择操作模式
OP_CONV, OP_FC, OP_RNN: begin
data_in_to_pe = data_in;
weight_in_to_pe = weight_in;
end
OP_SCALAR_MUL, OP_SCALAR_ADD: begin
data_in_to_pe = data_in;
weight_in_to_pe = scalar_in; // 标量作为权重输入
end
default: begin
data_in_to_pe = data_in;
weight_in_to_pe = weight_in;
end
endcase
end
// 主处理逻辑
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
result_out <= 0;
valid <= 1'b0;
post_process_data <= 0;
max_pool_reg <= 0;
avg_pool_reg <= 0;
pool_count <= 0;
end else begin
case (current_state)
IDLE: begin
valid <= 1'b0;
pool_count <= 0;
avg_pool_reg <= 0;
end
CONFIG: begin
// 初始化池化寄存器
if (ctrl_word[11:9] == OP_POOL) begin
if (ctrl_word[S0]) // 最大池化
max_pool_reg <= 0;
else // 平均池化
avg_pool_reg <= 0;
end
end
COMPUTE: begin
// 池化操作积累
if (ctrl_word[11:9] == OP_POOL && enable) begin
if (ctrl_word[S0]) begin // 最大池化
max_pool_reg <= (data_in > max_pool_reg) ? data_in : max_pool_reg;
end else begin // 平均池化
avg_pool_reg <= avg_pool_reg + data_in;
pool_count <= pool_count + 1'b1;
end
end
end
POST_PROCESS: begin
case (ctrl_word[11:9])
OP_CONV, OP_FC, OP_RNN: begin
post_process_data <= general_pe_out;
end
OP_POOL: begin
if (ctrl_word[S0]) // 最大池化
post_process_data <= max_pool_reg;
else // 平均池化
post_process_data <= avg_pool_reg / (pool_count + 1'b1);
end
OP_TANH: begin
// Tanh近似实现: tanh(x) ≈ x * (27 + x²) / (27 + 3*x²)
reg [OUTPUT_WIDTH-1:0] x_squared;
x_squared = general_pe_out * general_pe_out;
post_process_data <= (general_pe_out * (27 + x_squared)) / (27 + 3 * x_squared);
end
OP_SIGMOID: begin
// Sigmoid近似实现: sigmoid(x) ≈ 1 / (1 + exp(-x))
// 简化实现使用查找表或多项式近似
reg [OUTPUT_WIDTH-1:0] exp_val;
exp_val = (general_pe_out < 0) ? (1 << (DATA_WIDTH-1)) : 0;
post_process_data <= (1 << (DATA_WIDTH-1)) / ( (1 << (DATA_WIDTH-1)) + exp_val );
end
OP_SCALAR_MUL: begin
post_process_data <= general_pe_out; // 复用通用PE的乘法
end
OP_SCALAR_ADD: begin
post_process_data <= data_in + scalar_in; // 标量加法
end
endcase
end
OUTPUT: begin
result_out <= post_process_data;
valid <= 1'b1;
end
endcase
end
end
endmodule

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)