
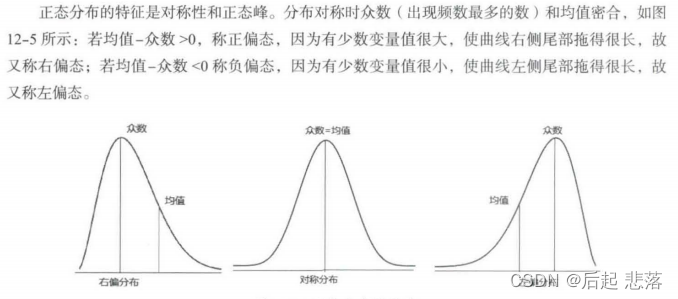
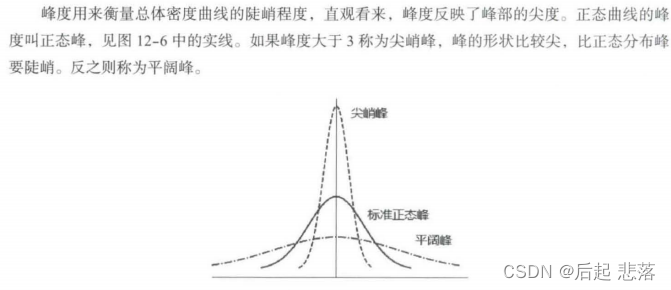
人工智能数学基础--应用篇
《人工智能数学基础》唐宇迪 ----学习笔记
1.假设检验
1.1基本思想
假设检验问题就是在原假设H。和与原假设对立的备择假设h中作出拒绝哪一个、接受哪一个的判断,是统计理论中基于“概率反证法”和“小概率原理”提出的假设检验方法。
(1)小概率原理
概率很小的事件一般在一次试验中不会发生,如果小概率事件在一次试验中竟然发生了,则事属反常,有理由怀疑原假设条件不成立。
(2)概率反证法
概率反证法的思想:首先对总体的参数或分布函数的表达式作出某种假设H,然后找出一个假设成立条件下出现可能性甚小的小概率事件A,如果在一次试验或抽样的结果中小概率事件发生了,这与小概率原理相违背,表明假设H。不成立,拒绝H,接受备择假设h。若小概率事件A没有发生,表明试验或抽样结果支持这个假设H,这时称假设H与实验结果是相容的,或者说,可以接受原假设H。
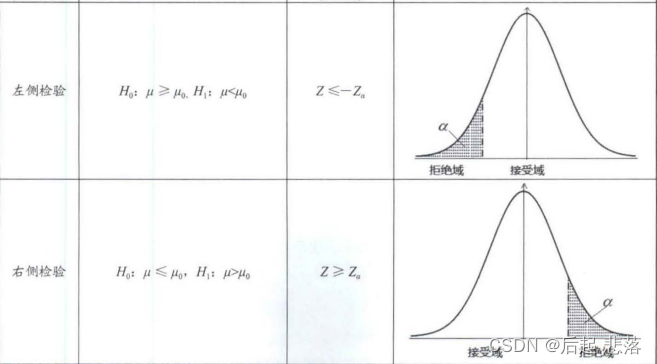
1.1.1左右侧检验与双侧检验
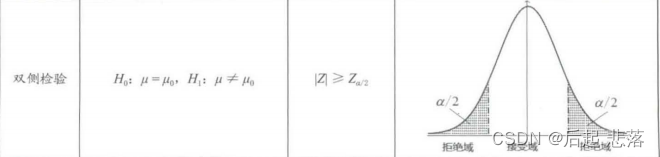
如果拒绝域在接受域的两侧,这类假设检验为双侧检验;如果拒绝域在接受域的一侧,这类假设检验为单侧检验。
(1)左右侧检验
(2)双侧检验
1.1.2 P值检验法
前面讨论的假设检验方法称为临界值法,此方法得到的结论较简单,如在给定的显著性水平下,两次抽样的结果都是拒绝原假设,样本信息中包含了反对原假设的证据,我们就需要衡量证据强度的差异,因此需要找到一个能够衡量样本所包含对原假设有利或不利信息强度的量。
如果P值<显著性水平α,样本统计量将落入拒绝域,那么在显著性水平α下拒绝H;如果Р值≥α,则在显著性水平α下接受H。图12-2中显示右侧检验时Р值<显著性水平α,落入拒绝域,所以拒绝原假设H,这种利用Р值检验假设的方法称为Р值检验法。
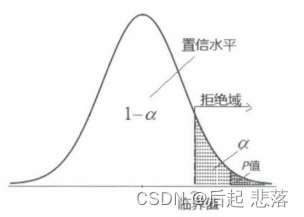
Р值是当H成立时,用样本统计量观察值所求得的概率,所以Р值是用样本检验统计量构造出H的拒绝域的最小实际显著性水平。Р值越小,H越不可能成立(更小概率的事件发生),说明样本信息中拒绝H。的证据更强、更充分,故Р值法的结论更加准确。
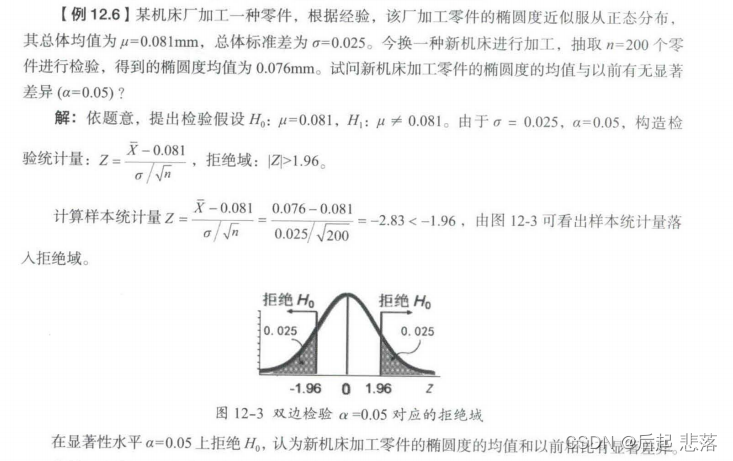
1.2 Z检验
Z检验(ZTest)是对总体均值的检验,常用于推断两组样本平均数的差异是否显著,或者已知标准差或大样本(即样本容量大于30)情况下,检验一个样本平均数与一个已知的总体平均数的差异是否显著。
Z检验公式:
显著性水平α一般取0.05,0.01,常用的Z检验的几个临界点包括:双侧Z=1.96,Z=2.58;单侧Z=1.645,Z=2.33。
1.3 t检验

(1)单总体检验:
单总体t检验又称单样本均数t检验(one sample t test)。当样本的总体标准差α未知且服从正态分布时,检验样本均值u与已知总体均值u是否存在显著性差异。总体均值一般是理论值或标准值,也可以是经大量观察得到的较稳定的指标值。
(2)配对t检验:
配对t检验(paired t test),又称非独立两样本均值t检验,可以检验两个配对样本所代表的总体均值差异是否显著,也可用来检验一组样本在某处理前后的均值有无差异。
(3)两独立样本t检验:
两独立样本t检验又称成组t检验,适用于完全随机设计的两样本均值的比较,其目的是检验两样本所来自的总体的均值是否相等。完全随机设计是将受试对象随机地分配到两组中,每组数据分别接受不同的处理后,对结果进行分析比较。
(4)正态性检验和两总体方差的齐次检验:
a.正态性检验

b.方差齐性检验:
通常方差是指数据的分布离散程度,例如方差分析(ANOVA)中,假定不同的样本数据虽然来自不同均值的抽样总体,但它们应该有相同的方差。方差齐性是指不同样本的方差大体相同,比较两个或两个以上样本均值时,例如双样本1检验时,如果方差有显著差异将会掩盖掉均值的差异信息并导致结论错误。
方差齐性检验的方法是以两方差中较大的方差为分子,较小的方差为分母,求二者的比值,称为F值,然后将求得的F值与临界值比较,看差异是否显著。

1.4 卡方检验
前面对总体参数的假设检验普遍要求是总体呈正态分布,但实际研究中,有时不能知道总体服从什么类型的分布,这些情况下,需要掌握一些非参数检验技术。非参数检验是在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态等进行推断的方法。由于非参数检验方法在推断过程中不涉及有关总体分布的参数,因此被称为“非参数”检验。其中最为常用的就是卡方检验。卡方检验是以卡方分布为基础的一种检验方法,只适合于大样本的情形,一般要求样本容量n≥50。
卡方检验是一种用途很广的假设检验方法,它主要用于检验两个或两个以上样本率或构成比之间差别的显著性。
卡方检验也可检验两个分类变量是否相关或是否相互独立。在许多实际应用中经常会遇到这样的问题,某个对象有两个指标X与Y,往往要分析这两个指标是否独立或是否互不相关。例如,地下水位的变化是否与地震有关、城市的大气污染是否与汽车尾气排放有关、慢性气管炎是否与吸烟有关、人的色盲是否与性别有关等。
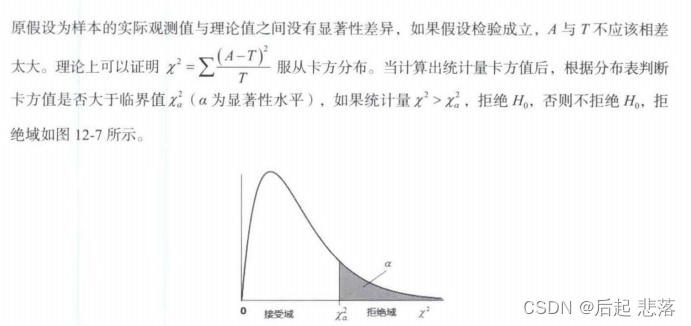
卡方检验法的基本思想:检验样本的实际观测值与理论推断值之间的偏离程度,统计量卡方值表示实际观测值与理论推断值之间的偏离程度,卡方值越大,偏差越大;卡方值越小,偏差越小,若两个值完全相等时,卡方值就为0,表明实际观测值和理论值完全符合。
卡方值计算公式:
1.5假设检验的两类错误

第一类错误“弃真”出现原因:从总体中抽取样本时,存在多个样本平均值,由于样本抽样的随机性,恰好抽到的样本均值把本来真实的原假设拒绝了,这就是“弃真”错误出现的原因。
第二类错误“取伪”出现原因:如果原假设H是错误的,随机抽取的样本有可能落入接受域,导致假设检验的结果是接受原假设H,造成“取伪”错误。
2.相关分析
事物和变量之间非确定性的关系,就是相关关系。研究事物之间的这种不确定性关系的数学方法,就称为相关分析。
在数学上,研究两个或两个以上处于同等地位的事物之间相关程度的强弱,并用适当的统计指标表示出来的过程,称为相关分析。根据相关分析,可以从不同角度对事物的相关性进行分类。
(1)按照相关程度可以分成完全相关、不完全相关和不相关。一个变量的数量变化由另一个变量的数量变化所确定,称为完全相关,即函数关系;两个变量的数量变化各自独立,称为不相关;介于完全相关与不相关之间的称不完全相关。
(2)按照相关的方向分为正相关和负相关。正相关指相关变量的数量变动方向一致,负相关指相关变量的数量变动方向相反。
( 3)按照相关的形式分成线性相关和非线性相关。将相关变量值作为直角坐标系的坐标,变量的不同取值如果呈直线分布,称为线性相关;如果呈曲线分布,称为非线性相关。
2.1.线性相关
线性相关的两个变量之间的相关程度可以通过一个量化的相关系数r来表示。相关系数有以下几个特点。
(1)r的数值范围是-1~+1。
(2)r的绝对值表示变量之间的密切程度(即强度)。绝对值越接近1,表示两个变量之间关系越密切;越接近0,表示两个变量之间关系越不密切。
(3) r的正负号表示变化方向。“+”号表示变化方向一致,即正相关;“-”号表示变化方向相反,即负相关。
(4)相关系数的值仅仅是一个比值。它不是由相等单位度量而来的(即不等距),也不是百分比,因此,不能直接进行算术运算。
(5)相关系数只能描述两个变量之间的变化方向及密切程度,并不能揭示两者之间的内在本质联系,即相关的两个变量不一定存在因果关系。
可以通过散点图来直观地观察随机变量之间的相关性。下面来看一下相关系数取不同值时对应的图形。
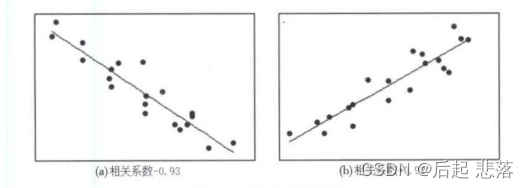
2.2皮尔森相关系数
皮尔森(Pearson)相关系数是用来度量两个连续型的随机正态变量之间的线性关系的一种随机变量特征量。皮尔森相关系数和随机变量的协方差关系比较密切。
协方差是反映两个随机变量相关程度的指标,下面是协方差的数学表示。
cov(X,Y)=E{[x-E(X)][Y-E(Y)]}= E(XY)-E(X)E( Y)
上式中X、Y是随机变量,E表示随机变量的期望值。当随机变量相互独立时,协方差cov为0;当随机变量相互不独立,即存在相关关系时,cov不为0; cov>0,表示两者正相关;cov<0,表示两者负相关。
协方差可以在一定程度上反映随机变量的相关性,但协方差受方差的影响较大,不同的相关变量的方差差异很大时,协方差数值很难建立不同组相关变量对的相关关系的对比。
为了更好地度量两个随机变量的相关程度,对协方差公式进行修正,可以在其基础上除以两个随机变量的标准差,这就是皮尔森相关系数,可以用以下公式表示:
上式中,X、Y是随机变量,p;是皮尔森相关系数,ox和o,是标准差,E是随机变量的期望值。皮尔森系数是一个介于-1~l的值,当两个变量的线性关系增强时,相关系数趋于1或-l;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
2.3相关系数的计算与假设检验
2.3.1相关系数的计算
使用Python代码计算二维数组中行数据之间的皮尔森相关系数和列数据之间的皮尔森相关系数。
#13-1.py
import numpy as np
tang =np. array([[10,10,8,9,7],
[4,5,4,3,3],
[3,3,1,1,1]])
print( 'data source')
print(tang)
print( ' corrcoef between rowdata')
print(np.corrcoef(tang))
print( " corrcoef between columndata")
print(np.corrcoef(tang,rowvar=0))
首先引入NumPy包,然后调用numpy.array 函数构造数据源;调用numpy.corrcoef 函数,传入数据源计算行数据相互之间的相关系数;调用numpy.corrcoef 函数时传入参数 rowvar=0,表示计算列数据之间的相关系数。
import numpy as np
import scipy.stats as stats
tang = np.array([[74,71,72,68,76,73,67,70,65,74],
[76,75,71,70,76,79,65,77,62,72]])
print(tang[0])
print(tang[1])
cor, pv=stats.pearsonr(tang[0],tang[1])
print(cor)
print(pv)
在上述代码中,首先引入NumPy和 scipy.stats包,通过NumPy 的amay函数构建数据集,调用Stats 的 pearsonr函数求数据集的皮尔森相关系数r和 t检验显著性水平p-value。
输出结果:
[74 71 72 68 76 73 67 70 65 74]
[76 75 71 70 76 79 65 77 62 72]
0.7802972005173807
0.007744294734007285从输出结果中看到,首先显示了初一数学成绩和初二数学成绩构成的数据集,然后是皮尔森相关系数和拒绝H。的显著性水平。相关系数四舍五入为0.7803,与上文中 NumPy的计算相等;显著性水平0.0077,低于上文中给定的显著性水平0.01,与上文结果一致。由此可见,从统计意义上,总体的成绩相关性不为0,即初一数学成绩和初二数学成绩的总体存在相关性。
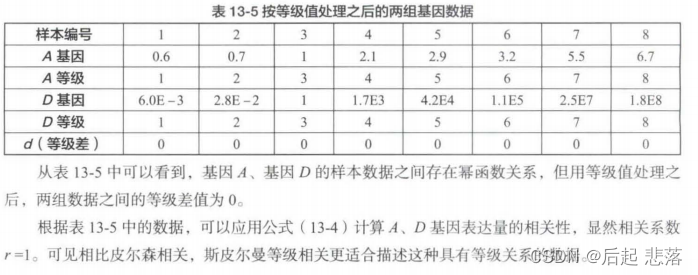
2.4斯皮尔曼等级相关
皮尔森相关是一种积差相关,主要用来度量两组连续型随机变量之间的相关关系(随机变量需符合正态分布)。当测量得到的数据不是等距或等比数据,而是具有等级顺序的数据,或者得到的数据是等距或等比数据,但其总体分布不是正态的,这时应用皮尔森相关来度量数据的相关关系可能就不一定准确了。
实际上,皮尔森相关系数是一种线性相关系数,对于非线性关系(例如A、D的幂函数关系)相关性的检测功效会下降。描述非线性相关关系时,可以考虑另外一个相关系数,即斯皮尔曼等级相关。
2.4.1斯皮尔曼等级相关系数
斯皮尔曼等级相关(Spearman's Correlation Coefficient for Ranked Data)主要用于解决名称数据和顺序数据相关的问题。当两个变量值以等级次序排列或以等级次序表示时,两个相应的总体并不一定呈正态分布,样本容量也不一定大于30,这种情况下可以用斯皮尔曼等级相关来描述两个变量之间的相关关系。
斯皮尔曼等级相关由英国统计学家斯皮尔曼根据积差相关的概念推导而来,用公式可以表示为:
从公式可以看出,斯皮尔曼等级相关简单而言,就是无论两个变量的数据如何变化,符合什么样的分布,我们只关心每个数值在变量内的排列顺序。如果两个变量的对应值在各组内的排序顺位是相同或类似的,则这两个变量具有显著的相关性。
严格来说,公式主要用于同一变量无相同等级时斯皮尔曼等级相关系数的计算;当同一变量有相同等级时,也可用它进行近似计算。
应用:
import numpy as np
import scipy.stats as stats
x=[10.35,6.24,3.18,8.46,3.21,7.65,4.32,8.66,9.12,10.31]
y =[5.13,3.15,1.67,4.33, 1.76,4.11,2.11,4.88,4.99,5.12]
correlation, pvalue = stats.spearmanr(x,y)
print ('correlation' ,correlation)
print ( 'pvalue',pvalue)
correlation 0.9999999999999999
pvalue 6.646897422032013e-64上述结果显示,该数据集的斯皮尔曼相关系数近似等于l,显著性水平接近于0。
import numpy as np
import scipy.stats as stats
X=[10.35,6.24,3.18,8.46,3.21,7.65,4.32,8.66,9.12,10.31]
y=[5.13,3.15,1.67,4.33,1.76,4.11,2.11,4.88,4.99,5.12]
x=stats.rankdata(X)
y =stats.rankdata(y)
print (x)
print (y)
correlation,pvalue = stats.spearmanr(x,y)
print ('correlation' ,correlation)
print ('pvalue ' ,pvalue)
[10. 4. 1. 6. 2. 5. 3. 7. 8. 9.]
[10. 4. 1. 6. 2. 5. 3. 7. 8. 9.]
correlation 0.9999999999999999
pvalue 6.646897422032013e-64在上述代码中,首先调用Stats的 rankdata函数将原始数据转换成等级数据,然后调用Stats的spearmanr函数进行相关系数和显著性水平计算。rankdata 函数在进行等级数据转换时,会首先对原始数据进行排序,将其序号作为等级值,如果多个数据具有相同值,会根据rankdata函数的参数设置取多个相关值的最小、最大或平均等级作为等级值。
从结果可以看出,转换成等级数据之后,上述数据集中,两组数据的等级数据相同,用等级数据计算得到的斯皮尔曼相关系数和显著性水平与原始数据计算得到的数据相同。
2.5肯德尔系数
肯德尔(Kandall )相关系数(即和谐系数)是用来描述多个(即两个以上)等级变量之间的一致性程度的量。通常为K个评分者评N个对象,或者也可以是同一个人先后K次评N个对象,通过肯德尔系数描述K个评分者对N个对象评价的一致性。肯德尔系数按照同一评价者有无相同等级评定,可以分成以下两种情况。

import scipy.stats as stats
x1 =[10,9,8,7,6]
x2 =[10,8,9,6,7]
tau,p_value = stats.kendalltau(x1,x2)
print ( 'tau',tau)
print('p_value',p_value)
输出结果显示,等级数据x和x的肯德尔相关系数为0.6,其显著性水平约为0.233,即二者具有较弱的一致性。
2.6 质量相关分析
质量相关分析也是研究两个变量之间的相关关系的分析方法,其中,一个变量描述事物的总体性质或特点,如男与女、优与劣、及格与不及格等,一般是离散的形式;另一个变量以数量形式描述事物的具体性质,如智商、学科分数、身高、体重等。这两个变量之间的相关关系就是质量相关。质与量的相关主要包括二列相关和点二列相关等。
2.6.1二列相关
当两个变量都是正态连续变量,其中一个变量被人为地划分成二分变量(如按一定标准将属于正态连续变量的考试分数划分为及格与不及格、录取与未录取,把某一体育项目测验结果划分为通过与未通过、达标与未达标,把健康状况划分为好与差等),这个正态连续变量与二分变量之间的相关关系称为二列相关。二列相关可以用如下数学公式表示:
式中p表示二分变量中某一类别频率的比率q表示二分变量中另一类别频率的比率,X,表示与二分变量中p类别相对应的连续变量的平均数,x表示与二分变量中q类别相对应的连续变量平均数,o表示连续变量的标准差,Y表示正态曲线中与累积概率p相对应的概率密度函数值。
根据二列相关定义,二列相关的使用条件如下:
(1)两个变量都是连续变量,且总体呈正态分布或接近正态分布,至少是单峰对称分布。 (2)两个变量之间是线性关系。
(3)二分变量是人为划分的,其分界点应尽量靠近中值。 (4)样本容量应大于80。
2.6.2点二列相关
有两个随机变量,其中一个是正态连续变量,另一个是真正的二分名义变量(例如,男与女、已婚和未婚、色盲与非色盲、生与死等),这两个变量之间的相关关系称为点二列相关。点二列相关关系可以用以下公式表示:
import scipy.stats as stats
x=[1,0,0,0,0,0,0,1,1,1,1,0,1,1,1,1,1,0,0,0]
y =[84,82,76,60,72,74,76,84,88,90,78,80,92,94,96,88,90,78,76,74]
coef,pvalue=stats.pointbiserialr(x,y)
print( 'pointbiserialcorrcoef',coef)
print('pvalue' ,pvalue)
在输出结果中,可以看到点二列相关系数约为0.785,这与上文通过公式计算得到的相关系数一致;输出的显著性水平的值很小,表示相关系数具有统计学意义。
2.7 品质相关分析
如果两个变量都用来描述事物的综合性质且都是划分成几种类别来表示,则称这两个变量之间的相关关系为品质相关。例如,一个变量按性别分成男与女,另一个变量按学科成绩分成及格与不及格;又如,一个变量按学校类别分成重点及非重点,另一个变量按学科成绩分成优、良、中、差。在品质相关中,变量可以是二分的,也可以是多分的,不同的变量类型有不同的统计方法。下面来看两种不同的品质相关:列联相关和p相关。
2.7.1列联相关系数

2.7.2  相关
相关
当两个变量都是二分变量,无论是真正的二分变量还是人为的二分变量,这两个变量之间的相关系数称为p相关系数(Phi-Coefficient )。如性别与体育成绩是否达标的相关关系,城镇户口与农村户口和创新能力强弱之间的相关关系等。下面看一下o相关系数的数学定义。
如果变量A和变量B都是二分变量,变量A有两个取值A、A,变量B有两个取值B、B;,变量A和B的相关关系实际就是2×2列联相关。对某组样本数据,A、B变量取不同值的频数分别用a、b、c、d表示,具体的数据结构如下所示: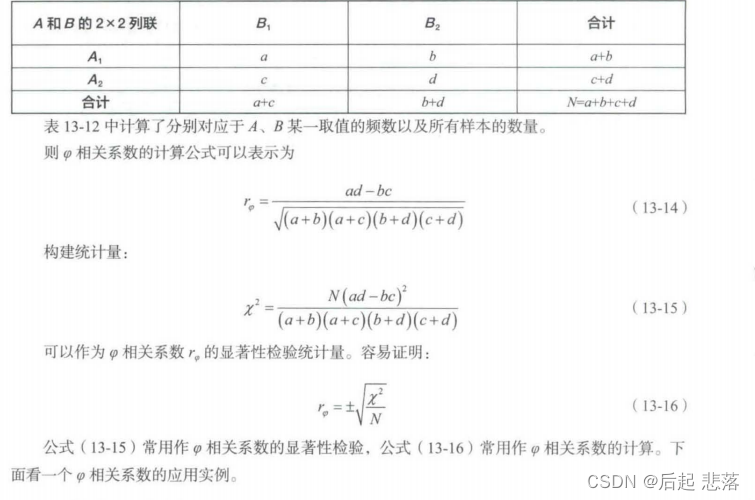
2.8偏相关与负相关
2.8.1 偏相关


2.8.2复相关

对于复相关系数,有以下几个性质。
(1)反映几个要素与某一个要素之间的复相关程度。复相关系数介于0~1。
(2)复相关系数越大,则表明要素(变量)之间的相关程度越密切。复相关系数为1,表示完全相关;复相关系数为0,表示完全无关。
(3)复相关系数必大于或至少等于单相关系数的绝对值。
(4)复相关系数必大于或至少等于同一系列数据所求得的偏相关系数的绝对值

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)