
人工智能发展简史9:GPT 系列——从GPT-1 到 GPT-5 的进化之路
GPT系列是由OpenAI开发的专注于语言生成的AI模型,基于Transformer解码器架构,采用单向预训练方法。从GPT-1(2018)确立"预训练+微调"范式,到GPT-2(2019)实现零样本学习,再到GPT-3(2020)展现1750亿参数的强大上下文学习能力。ChatGPT(2022)通过对话优化和人类反馈强化学习实现类人交互,GPT-4(2023)则突破多模态理解和复杂推理。最新的G
1.专注于语言生成的GPT系列
与 BERT 专注于语言理解不同,OpenAI 的 GPT 系列(Generative Pre-trained Transformer)则专注于语言生成。

图 1 OpenAI 的 GPT 系列
GPT的模型架构基于Transformer解码器,与BERT不同,GPT采用了单向Transformer的预训练方法,只能利用上文信息进行训练。
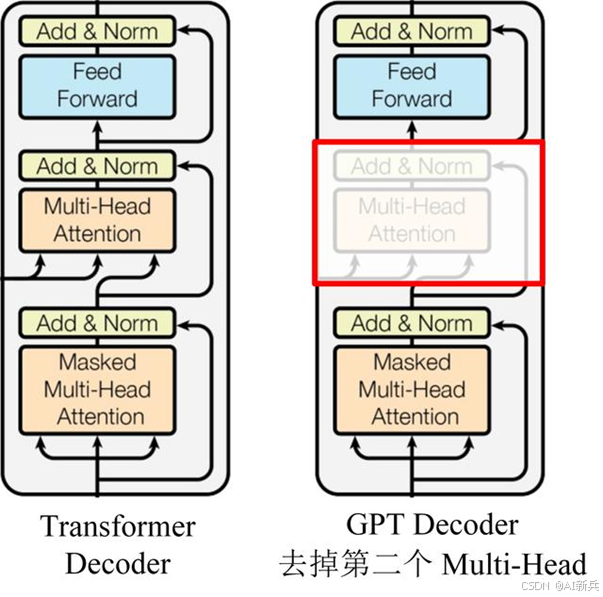
图 2 GPT Decoder架构与Transformer Decoder架构的对比
2.GPT发展历程
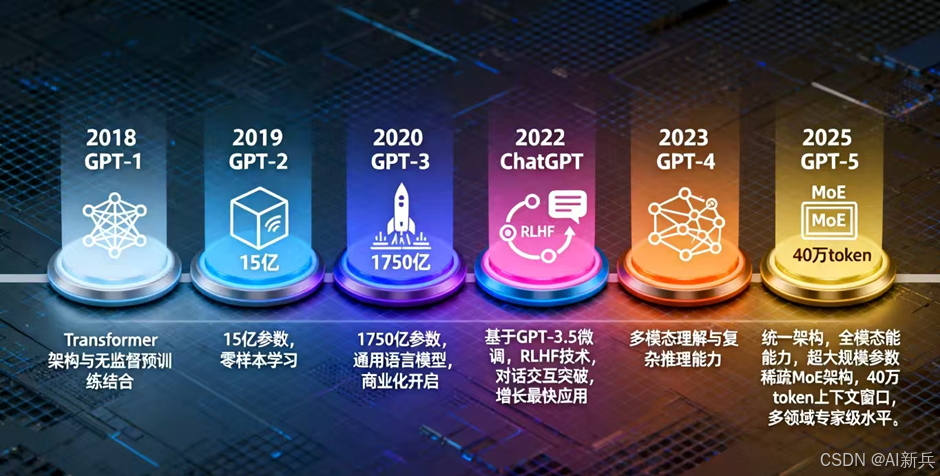
图 3 GPT发展历程
1)GPT-1(2018.06):“预训练 + 微调” 范式的奠基者
作为 OpenAI 发布的首个 GPT 模型,GPT-1 的核心贡献是确立了大模型训练的基础框架,而非单纯追求性能。
核心参数:12 层 Transformer 解码器架构,参数量 1.17 亿
关键创新:双阶段训练范式
预训练阶段:基于包含 7000 多本书籍的 BooksCorpus 数据集,通过 “预测下一个单词” 的自监督学习,让模型自主掌握语言语法、逻辑与常识规律;
微调阶段:利用有标签的任务数据(如文本分类、问答数据集)进行监督学习,使模型快速适配具体场景需求。
行业意义:彻底打破传统 NLP 模型 “一事一训”(一个任务需单独训练一个模型)的局限,为后续所有大模型的研发提供了 “通用预训练 + 任务微调” 的核心思路。
2)GPT-2(2019.02):零样本学习的 “文字魔法师”
GPT-2 通过规模提升与能力优化,首次让语言生成模型具备 “无训练即应用” 的灵活性。
核心参数:参数量从 1.17 亿跃升至 15 亿,训练数据量从 5GB 扩充至 40GB
关键创新:零样本学习(Zero-Shot Learning)
模型无需针对特定任务进行微调,仅通过自然语言提示(Prompt)即可直接处理新任务 —— 用户无需懂技术,只需用日常语言下达指令,模型就能生成对应结果。
能力价值:将语言生成模型从 “技术实验室” 推向 “初步实用化”,降低了 AI 生成文本的使用门槛。
3)GPT-3(2020.05):1750 亿参数的 “超级大脑”
GPT-3 以 “超大参数规模” 驱动能力质变,首次展现通用语言模型的全能潜力。
核心参数:参数量达 1750 亿(较 GPT-2 提升 11 倍),训练数据量 45TB(涵盖书籍、网页、文章等多元内容)
关键创新:上下文学习(In-Context Learning)
无需显式微调,只需在输入中提供少量示例(如 “例 1:苹果→红色;例 2:香蕉→黄色;问:橙子→?”),模型就能通过理解示例逻辑,完成同类新任务。
行业影响:标志大模型技术进入 “参数规模驱动能力突破” 的新阶段,让业界意识到 “超大模型” 可具备跨领域通用能力。
4) ChatGPT(2022.11):对话式 AI 的革命
ChatGPT 基于 GPT-3.5 与 InstructGPT 优化,聚焦 “多轮对话场景”,首次让 AI 交互具备 “类人连贯性”。
关键创新:
对话聚焦微调:在海量真实对话数据集上训练,模型能精准记忆上下文(如用户前序提到 “孩子 3 岁”,后续对话中无需重复说明,模型可直接关联),避免 “答非所问”;
基于人类反馈的强化学习(RLHF):通过人类培训师对模型响应的 “质量排名”(如 “回答 A 更准确、更友好”),反向优化模型,让生成内容兼具 “有用、诚实、无害” 三大特性。
市场热度:发布后 5 天内用户量突破 100 万,引发全球范围的 AI 关注热潮,成为 “对话式 AI 从实验走向实用” 的标志性产品。
5)GPT-4(2023):多模态与复杂推理的突破
GPT-4 在 “能力广度” 与 “结果可靠性” 上全面升级,首次实现多模态理解与深度推理的结合。
核心进步:
更长上下文窗口:支持处理数万字的长文本(如完整报告、小说章节),可连贯理解复杂文档;
多模态理解:除文本外,还能解析图像信息(如识别图片中的图表数据、判断设计图的问题);
思维链(Chain of Thought)技术:面对复杂问题(如数学证明、逻辑分析),模型会先拆解 “中间步骤”(如 “第一步:明确已知条件;第二步:推导公式;第三步:代入计算”),再给出最终答案,大幅提升推理准确性;
更高事实性:通过优化训练数据与验证机制,显著减少 “模型幻觉”(即生成虚假信息)。
领域突破:在数学推理、代码生成(支持 Python、Java 等数十种语言)、多语言翻译(覆盖小语种)等领域的基准测试中排名第一,成为当时最先进的通用语言模型。
6) GPT-5(2025.08):迄今为止最强大的大模型
GPT-5 被描述为 OpenAI “迄今为止最强大的大模型”,核心突破在于 “自主进化能力” 与 “任务自主性”。
核心创新:
递归式数据生成机制:首次实现 “模型生成高质量数据→用该数据训练模型→模型生成更高质量数据” 的循环,大幅提升训练数据的质量与多样性;
“速度 - 深度” 兼容:解决此前模型 “快速响应则推理浅、深度推理则响应慢” 的矛盾,可根据用户需求动态调整;
任务自主完成能力:无需用户拆解步骤,可独立承接复杂全流程任务(如 “从零开发一个电商小程序,包含用户注册、商品管理、支付接口”);
极致可靠性:通过多轮事实校验与交叉验证,成为 OpenAI 历来 “最无幻觉、最具事实性” 的模型。
性能表现:
软件工程基准 SweeBench:刷新最高分,可修复复杂代码漏洞;
AdderPolyglot 评估:在 C++、Rust 等多编程语言中实现高效算法;
图像推理 MMMU 测试:得分超过人类专家,可精准解析复杂图像逻辑;
美国数学奥林匹克选拔考试(AMY 2025):可解答高难度竞赛题。
行业意义:标志大模型技术从 “追求性能参数” 转向 “优化用户体验与实用价值”,被视为推动 AI 在医疗、教育、工业等领域 “深度落地” 的核心载体。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)