
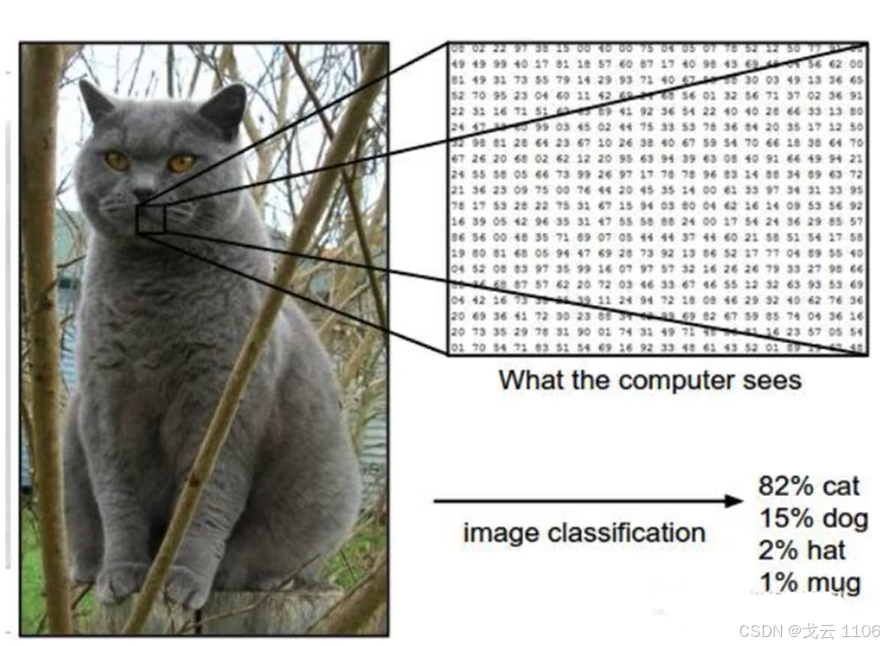
人工智能图像识别图像分类项目
微调预训练模型:在源领域上训练一个基础模型,再用目标领域的小样本数据对模型的部分层进行微调,使模型适应目标领域,像在大规模图像数据上预训练的卷积神经网络,在小样本的特定图像分类任务上微调。集成学习:训练多个不同的模型,例如使用不同的初始化参数训练多个卷积神经网络模型,然后将这些模型的预测结果进行融合,如采用投票法或平均法等。特征工程:手动提取图像的特征,像尺度不变特征变换(SIFT)、方向梯度直方
一、图像分类
· 将不同的图像,划分到不同的类别标签,实现最小的分类误差。
二、图像分类的三层境界
1、通用的多类别图像分类


2、子类细粒度图像分类


3、实例级图片分类


三、图像分类评估指标之混淆矩阵
TP(True positive,真正例)——将正类预测为正类数。
FP(False postive,假正例)——将反类预测为正类数。
TN(True negative,真反例)——将反类预测为反类数。
FN(False negative,假反例)——将正类预测为反类数。

四、图像分类评估指标
精确率(Accuracy):精确率是最常用的分类性能指标。可以用来表示模型的精度,即模型识别正确的个数/样本的总个数。一般情况下,模型的精度越高,说明模型的效果越好。
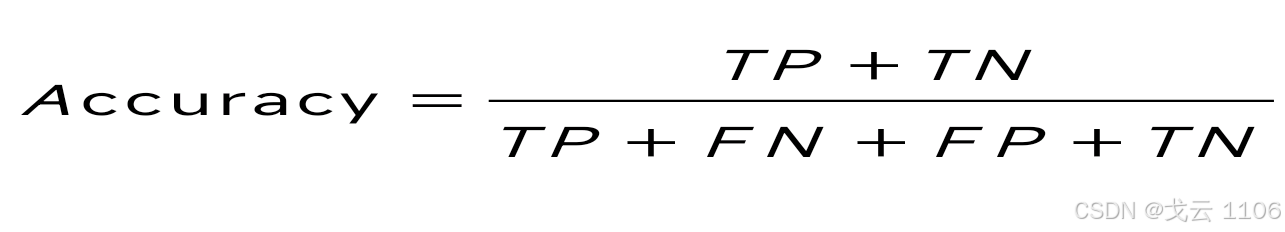
准确率(Precision):又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。
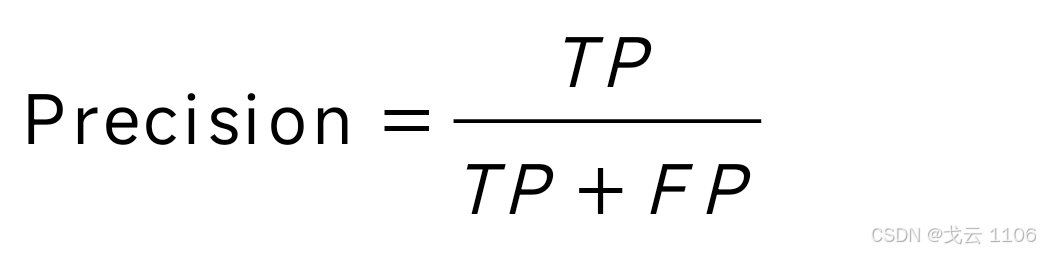
召回率(Recall):又称为查全率,表示模型正确识别出为正类的样本的数量占总的正类样本数量的比值。
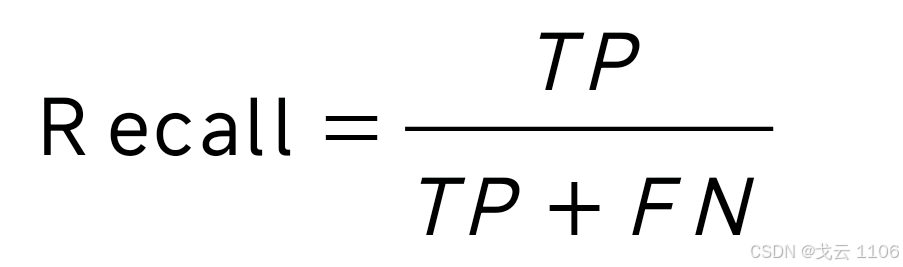
F1_Score:它被定义为正确率和召回率的调和平均数。
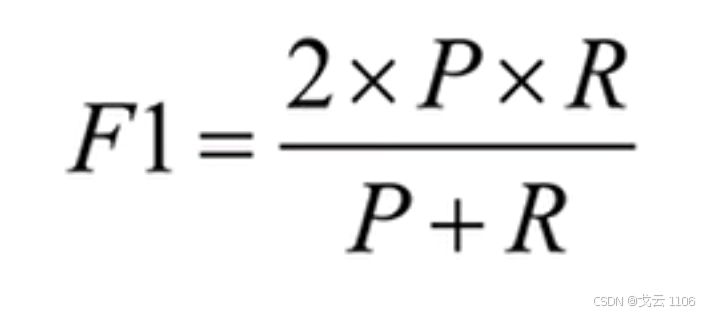
P-R曲线:
·召回率增加,精度下降。
·曲线和坐标轴面积越大,模型越好。
·对正负样本不均衡敏感。


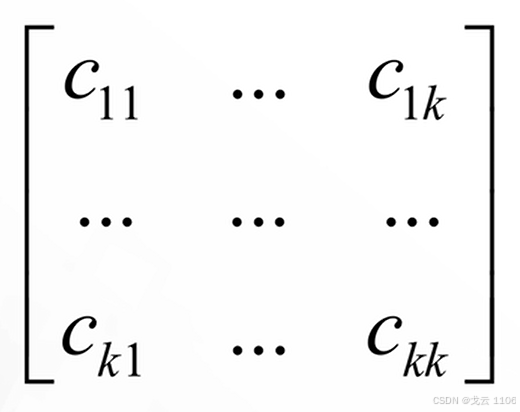
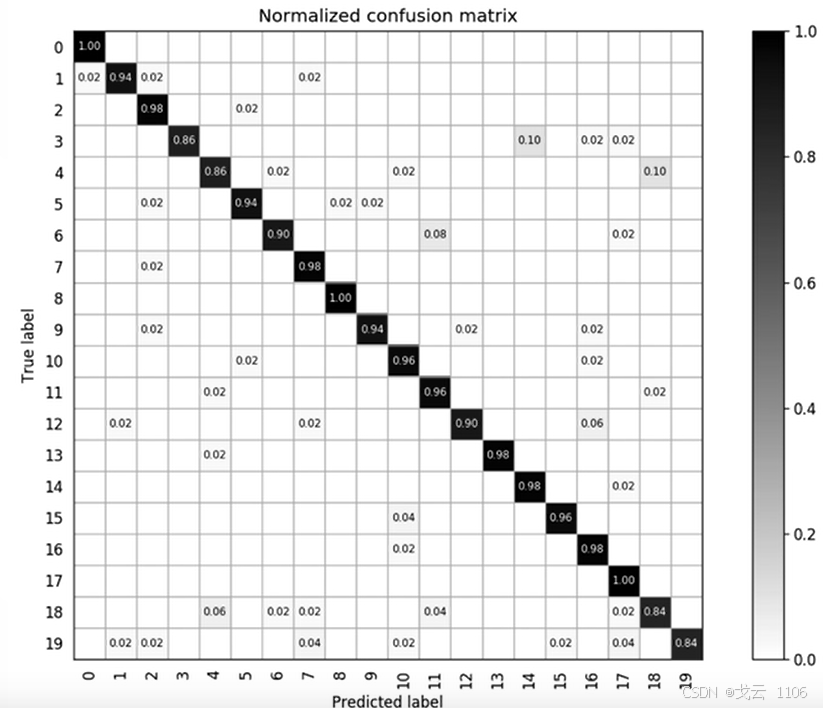
·多类别分类模型各个类别之间的分类情况对于k分类问题,混淆矩阵为k*k的矩阵,元素Cij表示第i类样本被分类器判定为第j类的数量。
主对角线的元素之和为正确分类的样本数,其余元素之和为错误分类的样本数。对角线的值越大,分类器准确率越高。
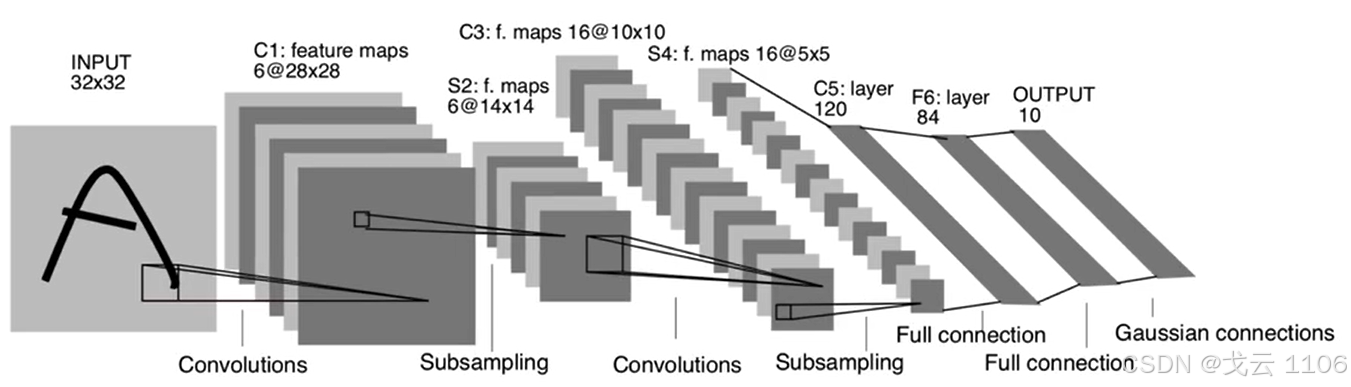
五、模型基本概念-网络的深度
深度学习最重要的属性,计算最长路径的卷积层+全连接层数量。LeNet网络,C1+C3+C5+F6+Output共5层。

·每一个网络层的通道数,以卷积网络层计算。 LeNet网络,C1(6),C3(16)。
六、图像分类中样本量过少的问题
样本量极少:样本获取较难导致总体样本量过少。
集成学习:训练多个不同的模型,例如使用不同的初始化参数训练多个卷积神经网络模型,然后将这些模型的预测结果进行融合,如采用投票法或平均法等。这样能综合多个模型的优势,提升分类性能与稳定性。
特征工程:手动提取图像的特征,像尺度不变特征变换(SIFT)、方向梯度直方图(HOG)等特征,这些特征能突出图像关键信息,使模型基于更有效的信息进行分类,一定程度弥补样本量少的缺陷。
主动学习:主动选择最有价值的样本进行标注,逐步扩充数据集。比如使用不确定性采样策略,选择模型预测结果不确定性高的样本让人工标注,这样能用较少的标注工作量提升模型性能。

工业产品
医疗
样本量过少的解决方案
迁移学习:使用预训练模型。
ImageNet数据集具有通用性,使用它进行预训练可加速模型收敛。

基于实例的迁移学习:从源领域挑选出与目标领域数据分布最接近的样本,加入到目标领域的小样本数据集中,以此扩充有效样本数量。比如在图像识别中,若目标领域是医疗影像识别且样本少,可从相似的、样本丰富的通用图像数据里选相关度高的图像作为补充。
基于特征的迁移学习:
特征提取与映射:从源领域数据中提取出通用且有效的特征,通过合适的变换映射到目标领域,让目标领域能利用这些特征丰富自身表示。例如自然语言处理里,将在大规模文本上学到的词向量特征迁移到小样本的特定主题文本分类任务中。
微调预训练模型:在源领域上训练一个基础模型,再用目标领域的小样本数据对模型的部分层进行微调,使模型适应目标领域,像在大规模图像数据上预训练的卷积神经网络,在小样本的特定图像分类任务上微调。
基于模型的迁移学习:直接将在源领域训练好的模型整体或部分结构迁移到目标领域。若源领域和目标领域任务类似,可直接复用模型结构;若有差异,可修改模型输出层以适应目标领域的任务需求,如从语音识别的一个任务迁移到另一个相关任务。
2、样本量过少的解决方案2
数据增强(有监督方法与无监督方法)


有监督方法:平移、翻转、亮度、对比度、裁剪、缩放等。
无监督方法:通过GAN网络生成所需样本,然后再进行训练。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)