
【智能控制1】 从生物大脑到人工智能:深度解密径向基函数(RBF)神经网络的奥秘
🔬 从生物神经元到人工神经元的演进历程🎯 径向基函数的直观理解与数学本质🏗️ RBF网络的三层架构与工作机制⚡ 快速学习算法与性能优势分析【附13个GitHub仓库链接】
📚 文章纲要
🌟 引言
神经网络在人工智能中的重要地位
RBF神经网络的独特价值与应用前景
📖 第一章:神经网络基础
1.1 生物启示 - 从大脑神经元到人工智能的灵感源泉
1.2 人工神经元模型 - 数学抽象与激活函数机制
1.3 网络层次结构 - 输入层、隐藏层、输出层的协同工作
🔍 第二章:径向基函数核心概念
2.1 径向基函数定义 - "距离决定影响"的数学表达
2.2 常见RBF类型 - 高斯函数、多二次函数等详解
2.3 直观理解 - "影响源"与"专家系统"的生动比喻
🏛️ 第三章:RBF网络架构解析
3.1 三层结构设计 - 输入、RBF隐藏层、线性输出层
3.2 工作原理机制 - 非线性变换与线性组合的两阶段处理
3.3 数学描述 - 函数逼近的完整数学框架
🎓 第四章:隐藏层的自主学习之道
4.1 中心点的智能发现 - 从随机到聚类的进化
4.2 宽度参数的自适应调节 - 让网络学会"专注"的范围
4.3 联合优化的协同智慧 - 多参数协调的艺术
🤖 第五章:机器人控制中的智能权重训练
5.1 线性回归的数学之美 - 最小二乘法的优雅解决方案
5.2 梯度下降的迭代智慧 - 让机器学会"试错学习"
5.3 机器人控制的自适应率技术 - 实时响应环境变化的关键
🔧 第六章:完整学习系统的工程实现
6.1 系统性学习框架 - 从数据到智能的完整流程
6.2 分阶段训练策略 - 化繁为简的工程智慧
6.3 实时监控与优化 - 让系统具备自我完善的能力
🔮 结论与展望
RBF网络的核心价值与技术优势
从生物启发到工程实现的完整闭环
人工智能与机器人控制融合发展的无限可能
引言
神经网络是人工智能领域中最重要的技术之一,它模仿人脑神经元的工作方式来处理信息。本文我们将从最基础的概念开始,一步步深入了解一种特殊而强大的神经网络——径向基函数(RBF)神经网络。它独特的"局部专家"理念和高效的学习机制,正在改变着机器人控制、模式识别和智能决策的格局。
第一章:什么是神经网络
1.1 从生物神经元谈起
我们的大脑由大约1000亿个神经元组成,每个神经元都像一个微小的信息处理器。生物神经元包含三个主要部分:树突(接收信息)、细胞体(处理信息)和轴突(传递信息)。当神经元接收到足够强的刺激时,它会"激活"并向其他神经元发送信号。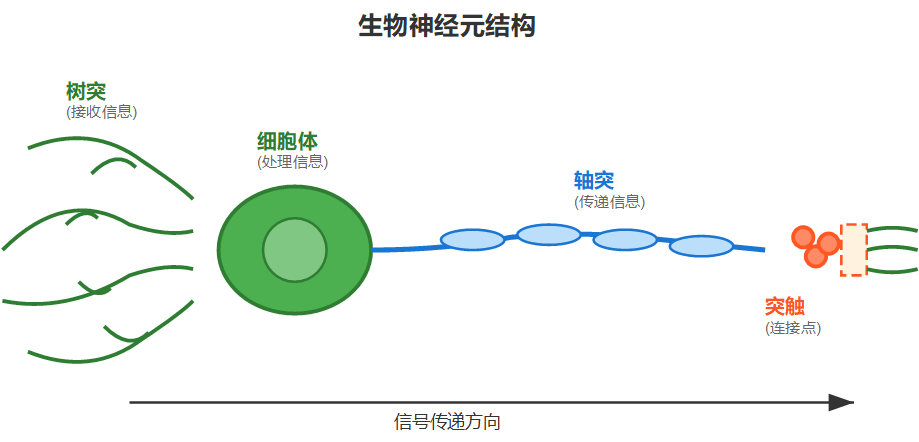
神经元之间通过突触连接,形成复杂的网络。这个网络能够学习、记忆和做出决策。人工神经网络正是受到这种生物机制的启发而诞生的。
1.2 人工神经元模型
人工神经元是对生物神经元的数学抽象。一个人工神经元接收多个输入信号 x1,x2,...,xnx_1, x_2, ..., x_nx1,x2,...,xn,每个输入都有对应的权重 w1,w2,...,wnw_1, w_2, ..., w_nw1,w2,...,wn,表示这个输入的重要程度。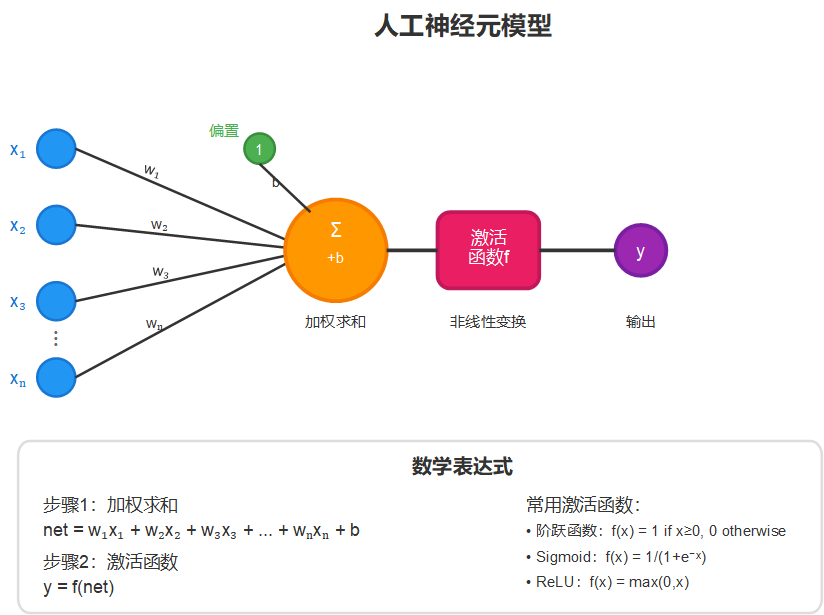
人工神经元的工作过程可以用数学公式表示:
y=f(∑i=1nwixi+b)y = f(\sum_{i=1}^{n} w_i x_i + b)y=f(i=1∑nwixi+b)
其中:
- xix_ixi 是第 iii 个输入
- wiw_iwi 是第 iii 个权重
- bbb 是偏置项(类似于阈值)
- fff 是激活函数
- yyy 是输出
激活函数的作用是决定神经元是否"激活"。常见的激活函数有阶跃函数、sigmoid函数等。当加权和超过某个阈值时,神经元就会输出信号。
1.3 神经网络的层次结构
单个神经元的能力有限,但当我们把许多神经元按层组织起来,就形成了神经网络。最简单的神经网络包含三层:
输入层:接收外部输入数据,不进行计算,只是传递信息。
隐藏层:进行信息处理和特征提取,可以有一层或多层。
输出层:产生最终的输出结果。
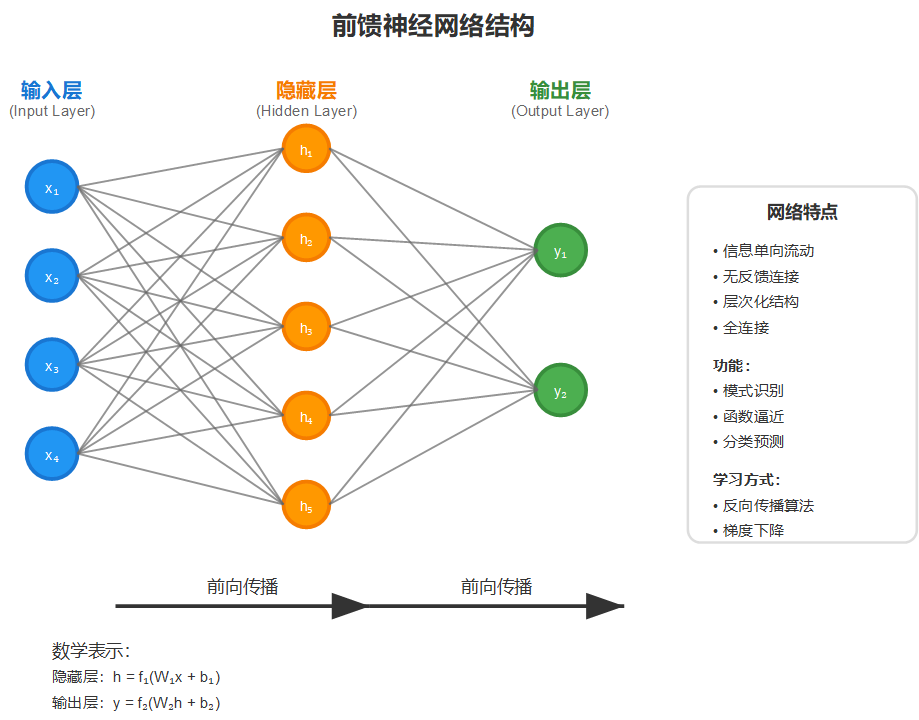
信息从输入层流向输出层,每一层的神经元都会对接收到的信息进行处理和变换。这种前馈的信息流动方式使得网络能够学习输入和输出之间的复杂关系。
第二章:RBF神经网络的基本概念
2.1 什么是径向基函数
径向基函数(Radial Basis Function,RBF)是一类特殊的函数,它的值只依赖于输入点到某个中心点的距离。用数学语言表达:
ϕ(x)=ϕ(∣∣x−c∣∣)\phi(\mathbf{x}) = \phi(||\mathbf{x} - \mathbf{c}||)ϕ(x)=ϕ(∣∣x−c∣∣)
其中:
- x\mathbf{x}x 是输入向量
- c\mathbf{c}c 是中心点向量
- ∣∣x−c∣∣||\mathbf{x} - \mathbf{c}||∣∣x−c∣∣ 是欧几里得距离
- ϕ\phiϕ 是径向基函数
这里的"径向"指的是函数值沿着从中心点向外的径向方向变化。可以想象成一个山峰,山顶是中心点,随着距离中心点越远,函数值会发生变化(通常是递减)。
2.2 常见的RBF函数类型
最常用的RBF函数是高斯函数:
ϕ(r)=exp(−r22σ2)\phi(r) = \exp(-\frac{r^2}{2\sigma^2})ϕ(r)=exp(−2σ2r2)
其中:
- r=∣∣x−c∣∣r = ||\mathbf{x} - \mathbf{c}||r=∣∣x−c∣∣ 是距离
- σ\sigmaσ 是宽度参数,控制函数的"胖瘦"
高斯函数就像一座优美的钟形山峰,山顶(中心点)处达到最高值1,然后随着距离的增加呈指数下降。参数 σ\sigmaσ 就像是控制这座山"胖瘦"的旋钮:。σ\sigmaσ 越小,函数越"尖锐",影响范围越小,就像激光一样集中;σ\sigmaσ 越大,函数越"平缓",影响范围越广,就像柔和的灯光。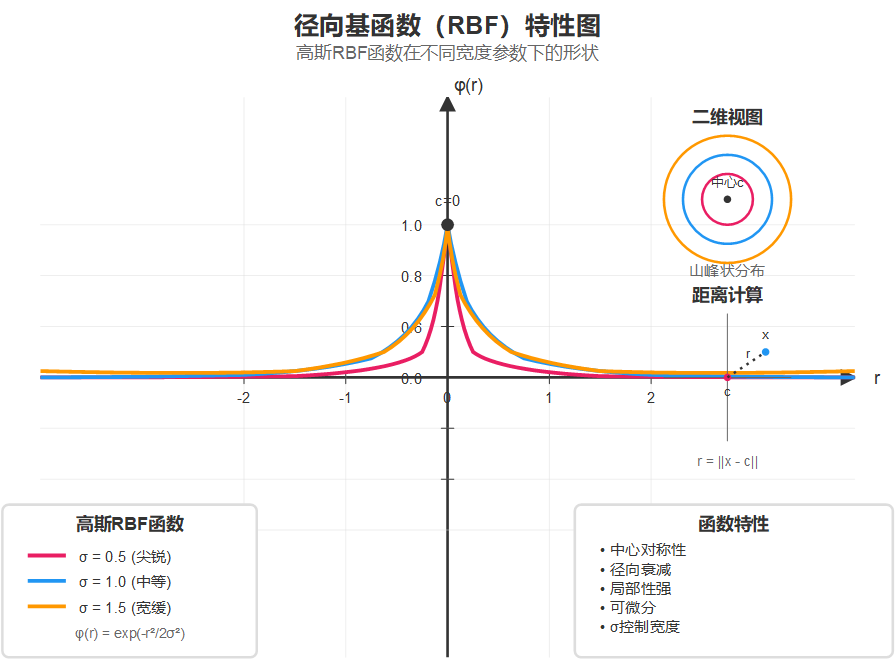
其他常见的RBF函数还包括:
多二次函数:ϕ(r)=r2+σ2\phi(r) = \sqrt{r^2 + \sigma^2}ϕ(r)=r2+σ2- 像一个倒置的漏斗,平缓上升
逆多二次函数:ϕ(r)=1r2+σ2\phi(r) = \frac{1}{\sqrt{r^2 + \sigma^2}}ϕ(r)=r2+σ21- 像一个倒置的钟,中心高,四周低
薄板样条函数:ϕ(r)=r2log(r)\phi(r) = r^2 \log(r)ϕ(r)=r2log(r)- 具有特殊的数学性质,常用于插值问题
2.3 RBF的直观理解
我们可以用一个生动的比喻来理解RBF函数:想象在一个平面上放置了多个影响源(如热源、光源),每个影响源都会对周围产生影响,影响的强度随距离而变化。RBF函数就是描述这种影响强度分布的数学工具。
在模式识别中,我们可以把每个RBF中心看作一个**“专家”**,它对某个特定区域的输入特别敏感。当输入接近这个专家的专长领域时,该专家就会给出较强的响应;当输入远离其专长领域时,响应就会减弱。
第三章:RBF神经网络的结构
3.1 RBF网络的三层架构
RBF神经网络具有典型的三层前馈结构:
输入层:简单地将输入信号传递给隐藏层,不进行任何变换。如果输入是 nnn 维向量 x=[x1,x2,...,xn]T\mathbf{x} = [x_1, x_2, ..., x_n]^Tx=[x1,x2,...,xn]T,那么输入层就有 nnn 个节点。
隐藏层(RBF层):这是RBF网络的核心,每个隐藏层神经元对应一个RBF函数。第 jjj 个隐藏层神经元的输出为:
ϕj(x)=exp(−∣∣x−cj∣∣22σj2)\phi_j(\mathbf{x}) = \exp(-\frac{||\mathbf{x} - \mathbf{c}_j||^2}{2\sigma_j^2})ϕj(x)=exp(−2σj2∣∣x−cj∣∣2)
其中 cj\mathbf{c}_jcj 是第 jjj 个RBF中心,σj\sigma_jσj 是对应的宽度参数。
输出层:对隐藏层的输出进行线性组合,得到最终输出:
yk=∑j=1mwjkϕj(x)+bky_k = \sum_{j=1}^{m} w_{jk} \phi_j(\mathbf{x}) + b_kyk=j=1∑mwjkϕj(x)+bk
其中:
- mmm 是隐藏层神经元个数
- wjkw_{jk}wjk 是从第 jjj 个隐藏层神经元到第 kkk 个输出神经元的权重
- bkb_kbk 是第 kkk 个输出神经元的偏置
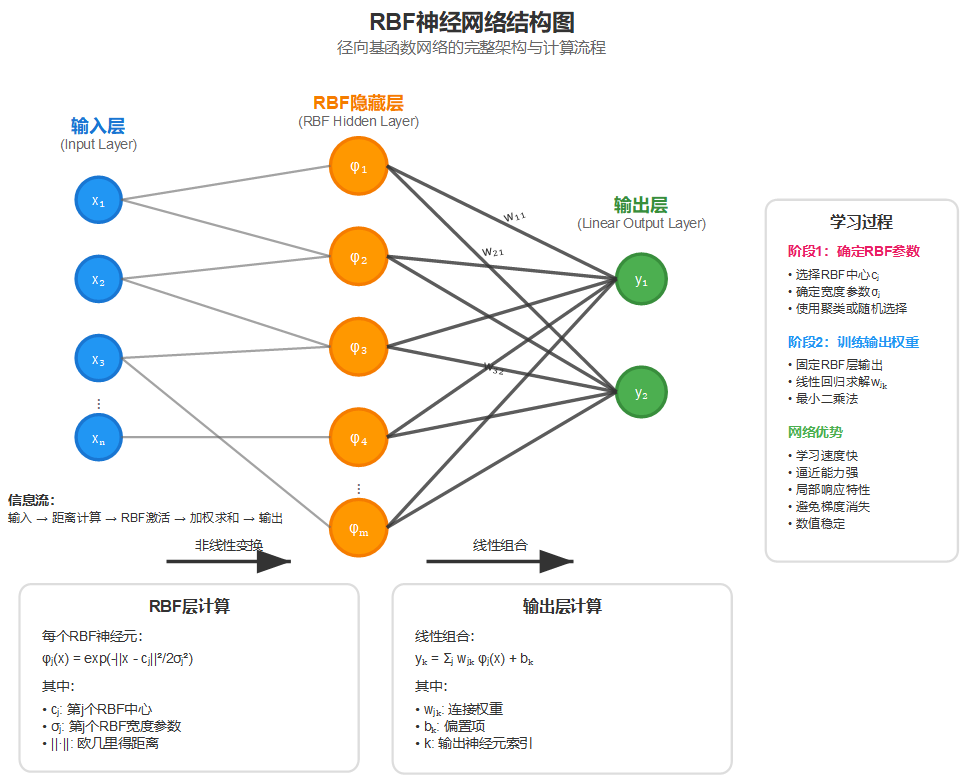
3.2 RBF网络的工作原理
RBF网络的工作可以分为两个阶段:
第一阶段:非线性变换
输入信号通过隐藏层的RBF函数进行非线性变换。每个RBF神经元计算输入与其中心的相似度,输出一个介于0和1之间的激活值。距离中心越近,激活值越大;距离越远,激活值越小。
第二阶段:线性组合
输出层将隐藏层的所有激活值进行加权线性组合,得到最终输出。这个过程是完全线性的,使得网络的学习过程更加简单高效。
3.3 RBF网络的数学描述
对于一个具有 nnn 个输入、mmm 个隐藏层神经元、ppp 个输出的RBF网络,其完整的数学表达式为:
f(x)=∑j=1mwjϕ(∣∣x−cj∣∣)+bf(\mathbf{x}) = \sum_{j=1}^{m} w_j \phi(||\mathbf{x} - \mathbf{c}_j||) + bf(x)=j=1∑mwjϕ(∣∣x−cj∣∣)+b
这个公式表明,RBF网络实际上是在进行函数逼近,用RBF函数的线性组合来逼近目标函数。
第四章:隐藏层中心和宽度的学习
4.1 RBF中心的确定方法
RBF网络隐藏层的学习主要涉及两个关键参数:中心位置 cj\mathbf{c}_jcj 和宽度参数 σj\sigma_jσj。这些参数的选择直接影响网络的性能和泛化能力。
4.1.1 随机选择法
最简单的方法是从训练样本中随机选择一部分作为RBF中心[1]:
cj=xij,j=1,2,...,m\mathbf{c}_j = \mathbf{x}_{i_j}, \quad j = 1,2,...,mcj=xij,j=1,2,...,m
其中 xij\mathbf{x}_{i_j}xij 是随机选择的第 iji_jij 个训练样本,mmm 是隐藏层神经元个数。
这种方法简单快速,但可能导致中心分布不均匀,影响网络性能。
4.1.2 K-means聚类法
更常用的是K-means聚类方法[2][3][4],它能够更好地反映数据的分布特性:
算法步骤:
- 初始化:随机选择 mmm 个点作为初始聚类中心
- 分配样本:将每个训练样本分配给距离最近的聚类中心
- 更新中心:重新计算每个聚类的质心
- 重复:重复步骤2-3直到收敛
数学表达为:
分配步骤:
c(t)(i)=argminj∣∣xi−cj(t)∣∣2c^{(t)}(i) = \arg\min_j ||\mathbf{x}_i - \mathbf{c}_j^{(t)}||^2c(t)(i)=argjmin∣∣xi−cj(t)∣∣2
更新步骤:
cj(t+1)=1∣Sj(t)∣∑i∈Sj(t)xi\mathbf{c}_j^{(t+1)} = \frac{1}{|S_j^{(t)}|} \sum_{i \in S_j^{(t)}} \mathbf{x}_icj(t+1)=∣Sj(t)∣1i∈Sj(t)∑xi
其中 Sj(t)S_j^{(t)}Sj(t) 是第 ttt 次迭代时分配给第 jjj 个聚类的样本集合。
4.1.3 自组织学习方法
竞争学习是一种更加智能的中心选择方法[5]:
对于每个输入样本 x\mathbf{x}x,找到距离最近的中心(获胜神经元):
j∗=argminj∣∣x−cj∣∣j^* = \arg\min_j ||\mathbf{x} - \mathbf{c}_j||j∗=argjmin∣∣x−cj∣∣
然后更新获胜神经元的中心:
cj∗=cj∗+η(x−cj∗)\mathbf{c}_{j^*} = \mathbf{c}_{j^*} + \eta(\mathbf{x} - \mathbf{c}_{j^*})cj∗=cj∗+η(x−cj∗)
其中 η\etaη 是学习率,通常随训练过程逐渐减小:
η(t)=η0exp(−t/τ)\eta(t) = \eta_0 \exp(-t/\tau)η(t)=η0exp(−t/τ)
4.2 宽度参数的确定
宽度参数 σj\sigma_jσj 控制着RBF函数的"影响范围",其选择对网络性能至关重要[6]。
4.2.1 固定宽度方法
最简单的方法是为所有RBF神经元设置相同的宽度[7]:
σ=dmax2m\sigma = \frac{d_{max}}{\sqrt{2m}}σ=2mdmax
其中 dmaxd_{max}dmax 是所有RBF中心之间的最大距离:
dmax=maxi,j∣∣ci−cj∣∣d_{max} = \max_{i,j} ||\mathbf{c}_i - \mathbf{c}_j||dmax=i,jmax∣∣ci−cj∣∣
4.2.2 近邻距离法
为每个RBF设置不同的宽度,基于其与邻近中心的距离[8]:
σj=1k∑i=1k∣∣cj−cni∣∣\sigma_j = \frac{1}{k} \sum_{i=1}^{k} ||\mathbf{c}_j - \mathbf{c}_{n_i}||σj=k1i=1∑k∣∣cj−cni∣∣
其中 cni\mathbf{c}_{n_i}cni 是距离 cj\mathbf{c}_jcj 最近的第 iii 个中心,kkk 通常取2或3。
4.2.3 自适应宽度学习
宽度参数也可以通过梯度下降法进行优化[9]。对于误差函数 EEE,宽度参数的更新规则为:
σj=σj−ησ∂E∂σj\sigma_j = \sigma_j - \eta_\sigma \frac{\partial E}{\partial \sigma_j}σj=σj−ησ∂σj∂E
其中:
∂E∂σj=∑k∑p(ypk−tpk)wjkϕj(xp)∣∣xp−cj∣∣2σj3\frac{\partial E}{\partial \sigma_j} = \sum_{k} \sum_{p} (y_{pk} - t_{pk}) w_{jk} \phi_j(\mathbf{x}_p) \frac{||\mathbf{x}_p - \mathbf{c}_j||^2}{\sigma_j^3}∂σj∂E=k∑p∑(ypk−tpk)wjkϕj(xp)σj3∣∣xp−cj∣∣2
4.3 中心和宽度的联合优化
在一些高级应用中,中心和宽度可以同时进行优化[10]:
中心的梯度更新:
cj=cj−ηc∂E∂cj\mathbf{c}_j = \mathbf{c}_j - \eta_c \frac{\partial E}{\partial \mathbf{c}_j}cj=cj−ηc∂cj∂E
其中:
∂E∂cj=∑k∑p(ypk−tpk)wjkϕj(xp)(xp−cj)σj2\frac{\partial E}{\partial \mathbf{c}_j} = \sum_{k} \sum_{p} (y_{pk} - t_{pk}) w_{jk} \phi_j(\mathbf{x}_p) \frac{(\mathbf{x}_p - \mathbf{c}_j)}{\sigma_j^2}∂cj∂E=k∑p∑(ypk−tpk)wjkϕj(xp)σj2(xp−cj)
这种联合优化方法可以获得更好的网络性能,但计算复杂度也相应增加。
第五章:输出层权重的训练方法
5.1 线性回归方法(最小二乘法)
当RBF中心和宽度确定后,隐藏层输出矩阵 Φ\boldsymbol{\Phi}Φ 就固定了。此时输出层的学习变成了标准的线性回归问题[11]。
对于训练样本 {(xp,tp)}p=1N\{(\mathbf{x}_p, \mathbf{t}_p)\}_{p=1}^N{(xp,tp)}p=1N,我们希望最小化均方误差:
E=12∑p=1N∑k=1L(ypk−tpk)2E = \frac{1}{2} \sum_{p=1}^N \sum_{k=1}^{L} (y_{pk} - t_{pk})^2E=21p=1∑Nk=1∑L(ypk−tpk)2
其中 ypky_{pk}ypk 是网络对第 ppp 个样本第 kkk 个输出的预测值,tpkt_{pk}tpk 是对应的目标值。
解析解:
权重矩阵的最优解为:
W=(ΦTΦ)−1ΦTT\mathbf{W} = (\boldsymbol{\Phi}^T\boldsymbol{\Phi})^{-1}\boldsymbol{\Phi}^T\mathbf{T}W=(ΦTΦ)−1ΦTT
其中:
- Φ\boldsymbol{\Phi}Φ 是 N×mN \times mN×m 的隐藏层输出矩阵
- T\mathbf{T}T 是 N×LN \times LN×L 的目标矩阵
- W\mathbf{W}W 是 m×Lm \times Lm×L 的权重矩阵
5.2 梯度下降法
当数据量很大或者 ΦTΦ\boldsymbol{\Phi}^T\boldsymbol{\Phi}ΦTΦ 接近奇异时,可以使用梯度下降法进行迭代求解[12][13]。
5.2.1 批量梯度下降
权重更新规则为:
wjk(t+1)=wjk(t)−η∂E∂wjkw_{jk}^{(t+1)} = w_{jk}^{(t)} - \eta \frac{\partial E}{\partial w_{jk}}wjk(t+1)=wjk(t)−η∂wjk∂E
其中梯度为:
∂E∂wjk=∑p=1N(ypk−tpk)ϕj(xp)\frac{\partial E}{\partial w_{jk}} = \sum_{p=1}^N (y_{pk} - t_{pk}) \phi_j(\mathbf{x}_p)∂wjk∂E=p=1∑N(ypk−tpk)ϕj(xp)
5.2.2 随机梯度下降
对于每个训练样本,权重更新为:
wjk=wjk−η(ypk−tpk)ϕj(xp)w_{jk} = w_{jk} - \eta (y_{pk} - t_{pk}) \phi_j(\mathbf{x}_p)wjk=wjk−η(ypk−tpk)ϕj(xp)
这种方法收敛速度更快,但可能存在震荡现象。
5.2.3 小批量梯度下降
结合批量和随机梯度下降的优点,每次使用一小批样本(batch)进行更新[14]:
wjk=wjk−η1B∑b=1B(ybk−tbk)ϕj(xb)w_{jk} = w_{jk} - \eta \frac{1}{B} \sum_{b=1}^B (y_{bk} - t_{bk}) \phi_j(\mathbf{x}_b)wjk=wjk−ηB1b=1∑B(ybk−tbk)ϕj(xb)
其中 BBB 是批量大小。
5.3 机器人智能控制中的自适应率技术
在机器人智能控制系统中,自适应率技术是确保控制器能够实时响应环境变化和任务需求的关键技术[34][35][36]。与传统的固定学习率不同,自适应率技术能够根据机器人的运行状态、环境复杂性和任务优先级动态调整学习参数。
5.3.1 实时自适应学习率调节
在机器人控制中,实时自适应学习率调节是核心技术之一[37][38]。该技术基于机器人当前的性能指标和环境反馈来动态调整RBF网络的学习率。
基于误差的自适应调节:
η(t)=η0⋅sigmoid(α⋅E(t))\eta(t) = \eta_0 \cdot \text{sigmoid}(\alpha \cdot E(t))η(t)=η0⋅sigmoid(α⋅E(t))
其中:
- E(t)E(t)E(t) 是机器人在时刻 ttt 的控制误差
- α\alphaα 是敏感度参数
- η0\eta_0η0 是基础学习率
基于梯度变化的自适应调节[39]:
ηjk(t)={ηjk(t−1)⋅βinc,if ∂E∂wjk(t)⋅∂E∂wjk(t−1)>0ηjk(t−1)⋅βdec,if ∂E∂wjk(t)⋅∂E∂wjk(t−1)<0\eta_{jk}(t) = \begin{cases} \eta_{jk}(t-1) \cdot \beta_{inc}, & \text{if } \frac{\partial E}{\partial w_{jk}}(t) \cdot \frac{\partial E}{\partial w_{jk}}(t-1) > 0 \\ \eta_{jk}(t-1) \cdot \beta_{dec}, & \text{if } \frac{\partial E}{\partial w_{jk}}(t) \cdot \frac{\partial E}{\partial w_{jk}}(t-1) < 0 \end{cases}ηjk(t)={ηjk(t−1)⋅βinc,ηjk(t−1)⋅βdec,if ∂wjk∂E(t)⋅∂wjk∂E(t−1)>0if ∂wjk∂E(t)⋅∂wjk∂E(t−1)<0
其中 βinc>1\beta_{inc} > 1βinc>1 和 βdec<1\beta_{dec} < 1βdec<1 分别为增长和衰减因子。
5.3.2 任务导向的自适应率策略
机器人在执行不同任务时需要不同的控制精度和响应速度[40][41]。任务导向的自适应率策略能够根据当前任务的特性调整学习参数。
任务复杂度评估:
Ctask=w1⋅Ddof+w2⋅Venv+w3⋅TprecisionC_{task} = w_1 \cdot D_{dof} + w_2 \cdot V_{env} + w_3 \cdot T_{precision}Ctask=w1⋅Ddof+w2⋅Venv+w3⋅Tprecision
其中:
- DdofD_{dof}Ddof 是任务所需的自由度数量
- VenvV_{env}Venv 是环境复杂度(障碍物密度、动态元素等)
- TprecisionT_{precision}Tprecision 是任务精度要求
- w1,w2,w3w_1, w_2, w_3w1,w2,w3 是权重系数
自适应学习率调整:
ηadaptive=ηbase⋅(1+Ctask−CnominalCmax)\eta_{adaptive} = \eta_{base} \cdot \left(1 + \frac{C_{task} - C_{nominal}}{C_{max}}\right)ηadaptive=ηbase⋅(1+CmaxCtask−Cnominal)
5.3.3 多层次自适应控制架构
现代机器人控制系统通常采用多层次自适应控制架构[42][43],将自适应率技术应用于不同的控制层次。
高层任务规划自适应率:
负责任务序列规划和目标设定,使用较慢的自适应率:
ηhigh=ηbase⋅(1−e−λht)\eta_{high} = \eta_{base} \cdot (1 - e^{-\lambda_h t})ηhigh=ηbase⋅(1−e−λht)
中层路径规划自适应率:
负责轨迹生成和避障规划,使用中等速度的自适应率:
ηmid=ηbase⋅sin2(ωmt)⋅e−γ∣epath∣\eta_{mid} = \eta_{base} \cdot \sin^2(\omega_m t) \cdot e^{-\gamma |e_{path}|}ηmid=ηbase⋅sin2(ωmt)⋅e−γ∣epath∣
底层运动控制自适应率:
负责关节控制和力控制,使用快速响应的自适应率[44]:
ηlow(t)=ηbase⋅(1+Kp∣epos(t)∣+Kd∣e˙pos(t)∣)\eta_{low}(t) = \eta_{base} \cdot \left(1 + K_p |e_{pos}(t)| + K_d |\dot{e}_{pos}(t)|\right)ηlow(t)=ηbase⋅(1+Kp∣epos(t)∣+Kd∣e˙pos(t)∣)
5.3.4 环境感知自适应率调节
机器人在复杂环境中工作时,环境的动态变化会影响控制性能[45][46]。环境感知自适应率调节技术能够根据传感器反馈实时调整学习参数。
传感器融合权重自适应:
ηsensor=∑i=1Nwi(t)⋅ηi,base\eta_{sensor} = \sum_{i=1}^{N} w_i(t) \cdot \eta_{i,base}ηsensor=i=1∑Nwi(t)⋅ηi,base
其中权重根据传感器可靠性动态调整:
wi(t)=reliabilityi(t)∑j=1Nreliabilityj(t)w_i(t) = \frac{\text{reliability}_i(t)}{\sum_{j=1}^{N} \text{reliability}_j(t)}wi(t)=∑j=1Nreliabilityj(t)reliabilityi(t)
环境不确定性补偿[47]:
ηuncertainty=ηnominal⋅(1+σenv2(t))\eta_{uncertainty} = \eta_{nominal} \cdot \left(1 + \sigma_{env}^2(t)\right)ηuncertainty=ηnominal⋅(1+σenv2(t))
其中 σenv2(t)\sigma_{env}^2(t)σenv2(t) 是环境不确定性的方差估计。
5.3.5 强化学习驱动的自适应率优化
现代机器人系统越来越多地采用强化学习驱动的自适应率优化技术[48][49][50],让机器人在与环境交互中学习最优的学习率策略。
Q-学习自适应率选择:
Q(s,η)=Q(s,η)+α[R+γmaxη′Q(s′,η′)−Q(s,η)]Q(s, \eta) = Q(s, \eta) + \alpha \left[R + \gamma \max_{\eta'} Q(s', \eta') - Q(s, \eta)\right]Q(s,η)=Q(s,η)+α[R+γη′maxQ(s′,η′)−Q(s,η)]
其中状态 sss 包括当前控制误差、任务类型和环境特征。
Actor-Critic自适应率调节[51]:
Actor网络: π(η|s) → 学习率分布
Critic网络: V(s) → 状态价值估计
更新规则:
∇θ_π J ≈ E[∇θ_π log π(η|s) · A(s,η)]
∇θ_V L ≈ E[(R + γV(s') - V(s))²]
5.3.6 安全约束下的自适应率控制
机器人安全是首要考虑因素,自适应率技术必须在安全约束下运行[52][53]。
控制屏障函数约束:
ηsafe=argminη∣∣η−ηdesired∣∣2\eta_{safe} = \arg\min_{\eta} ||\eta - \eta_{desired}||^2ηsafe=argηmin∣∣η−ηdesired∣∣2
subject to: h˙(x)+γh(x)≥0\text{subject to: } \dot{h}(x) + \gamma h(x) \geq 0subject to: h˙(x)+γh(x)≥0
其中 h(x)h(x)h(x) 是安全屏障函数。
风险感知自适应调节:
ηrisk=ηnominal⋅exp(−β⋅Risk(x,u))\eta_{risk} = \eta_{nominal} \cdot \exp(-\beta \cdot \text{Risk}(x, u))ηrisk=ηnominal⋅exp(−β⋅Risk(x,u))
其中风险函数考虑碰撞概率、关节限制和动力学约束。
5.3.7 分布式多机器人自适应协调
在多机器人系统中,分布式自适应率协调确保系统整体性能优化[54][55]。
一致性驱动的自适应率:
ηi(t+1)=ηi(t)+ϵ∑j∈Ni(ηj(t)−ηi(t))+μ∇ηiJi\eta_i(t+1) = \eta_i(t) + \epsilon \sum_{j \in N_i} (\eta_j(t) - \eta_i(t)) + \mu \nabla_{\eta_i} J_iηi(t+1)=ηi(t)+ϵj∈Ni∑(ηj(t)−ηi(t))+μ∇ηiJi
其中 NiN_iNi 是机器人 iii 的邻居集合,JiJ_iJi 是个体性能指标。
负载均衡自适应调节:
ηi=ηbase⋅LoadavgLoadi+ϵ\eta_i = \eta_{base} \cdot \frac{\text{Load}_{avg}}{\text{Load}_i + \epsilon}ηi=ηbase⋅Loadi+ϵLoadavg
确保计算资源在多机器人间的合理分配。
这些自适应率技术的应用使得RBF神经网络能够在复杂的机器人控制任务中表现出卓越的性能,包括实时响应、鲁棒性和学习效率。通过合理选择和调节这些参数,可以显著提升机器人系统在动态环境中的适应能力和控制精度。
第六章:RBF网络的完整学习过程
6.1 整体学习框架
RBF网络的学习是一个系统性的过程,需要协调隐藏层参数和输出层权重的优化[26]。完整的学习框架包括以下几个阶段:
6.1.1 数据预处理阶段
数据标准化:
xnorm=x−μσ\mathbf{x}_{norm} = \frac{\mathbf{x} - \boldsymbol{\mu}}{\boldsymbol{\sigma}}xnorm=σx−μ
其中 μ\boldsymbol{\mu}μ 和 σ\boldsymbol{\sigma}σ 分别是训练数据的均值和标准差向量。
数据集划分:将数据分为训练集(70%)、验证集(15%)和测试集(15%)。
6.1.2 网络结构设计阶段
隐藏层神经元数量选择[27]:
- 启发式方法:m=N×Lm = \sqrt{N \times L}m=N×L,其中 NNN 是训练样本数,LLL 是输出维数
- 交叉验证方法:尝试不同的 mmm 值,选择验证误差最小的
- 逐步增长方法:从小的 mmm 开始,逐渐增加直到性能饱和
6.2 分阶段学习策略
6.2.1 第一阶段:无监督学习隐藏层参数
这个阶段只使用输入数据 {xp}p=1N\{\mathbf{x}_p\}_{p=1}^N{xp}p=1N,不考虑输出目标[28]。
步骤1:使用K-means聚类确定RBF中心
初始化: 随机选择m个中心点
repeat:
for each 训练样本 x_p:
分配到最近的聚类中心
for each 聚类中心 c_j:
更新为分配样本的均值
until 中心位置收敛
步骤2:计算宽度参数
使用近邻距离法或固定宽度法确定每个RBF的宽度。
6.2.2 第二阶段:监督学习输出层权重
使用输入-输出对 {(xp,tp)}p=1N\{(\mathbf{x}_p, \mathbf{t}_p)\}_{p=1}^N{(xp,tp)}p=1N 训练输出层权重[29]。
方法选择:
- 小数据集:直接使用最小二乘法求解析解
- 大数据集:使用小批量梯度下降或Adam优化器
6.3 联合优化策略
对于更高的性能要求,可以采用联合优化策略,同时调整隐藏层参数和输出层权重[30]。
6.3.1 交替优化
算法框架:
初始化: 使用分阶段方法获得初始参数
repeat:
固定输出层权重,优化RBF中心和宽度
固定RBF参数,优化输出层权重
until 整体误差收敛
6.3.2 完全联合优化
使用梯度下降法同时优化所有参数:
参数更新顺序:
- 更新RBF中心:cj=cj−ηc∂E∂cj\mathbf{c}_j = \mathbf{c}_j - \eta_c \frac{\partial E}{\partial \mathbf{c}_j}cj=cj−ηc∂cj∂E
- 更新RBF宽度:σj=σj−ησ∂E∂σj\sigma_j = \sigma_j - \eta_\sigma \frac{\partial E}{\partial \sigma_j}σj=σj−ησ∂σj∂E
- 更新输出权重:wjk=wjk−ηw∂E∂wjkw_{jk} = w_{jk} - \eta_w \frac{\partial E}{\partial w_{jk}}wjk=wjk−ηw∂wjk∂E
不同类型参数通常需要不同的学习率:ηc<ησ<ηw\eta_c < \eta_\sigma < \eta_wηc<ησ<ηw。
6.4 学习过程的监控和调优
6.4.1 学习曲线监控
绘制训练误差和验证误差随训练轮数的变化[31]:
- 欠拟合:训练和验证误差都很高
- 过拟合:训练误差低但验证误差高
- 良好拟合:两个误差都较低且接近
6.4.2 早停法
当验证误差不再下降时提前停止训练[32]:
best_val_error = infinity
patience_counter = 0
patience = 10
for epoch in training_epochs:
train_one_epoch()
val_error = validate()
if val_error < best_val_error:
best_val_error = val_error
save_best_model()
patience_counter = 0
else:
patience_counter += 1
if patience_counter >= patience:
break
6.4.3 超参数优化
网格搜索:在预定义的参数空间中搜索最优组合
随机搜索:随机采样参数组合进行评估
贝叶斯优化:使用贝叶斯方法指导参数搜索[33]
6.5 完整算法总结
RBF网络完整学习算法:
输入: 训练数据 {(x_p, t_p)}, p=1...N
隐藏层神经元数量 m
学习参数 η, λ等
步骤1: 数据预处理
标准化输入数据
划分训练/验证/测试集
步骤2: 初始化隐藏层参数
使用K-means确定RBF中心 {c_j}
计算宽度参数 {σ_j}
步骤3: 计算隐藏层输出矩阵Φ
for p = 1 to N:
for j = 1 to m:
Φ[p,j] = exp(-||x_p - c_j||²/(2σ_j²))
步骤4: 训练输出层权重
if 小数据集:
W = (Φ^T Φ)^(-1) Φ^T T
else:
使用梯度下降法优化W
步骤5: 模型评估和调优
在验证集上评估性能
根据需要调整网络结构或参数
使用早停法防止过拟合
步骤6: 最终测试
在测试集上评估最终性能
输出: 训练好的RBF网络模型
这个完整的学习过程体现了RBF网络"局部学习,全局优化"的核心思想,通过合理的分阶段策略和联合优化,能够获得良好的网络性能和泛化能力。
结论
RBF神经网络作为一种重要的前馈神经网络,以其独特的径向基函数和简洁的三层结构,在函数逼近、模式识别、机器人控制等领域展现出了强大的能力。通过理解其基本原理和学习算法,我们可以更好地运用这一工具解决实际问题。
RBF网络的核心思想——局部逼近与全局优化的结合,不仅体现了生物神经系统的智慧,也为我们提供了一种高效的机器学习方法。
参考文献
[1] Oarriaga. (2024). “Minimal implementation of a radial basis function network.” GitHub. https://github.com/oarriaga/RBF-Network
[2] Raaaouf. (2024). “RBF neural network python implementation for classification problem.” GitHub. https://github.com/raaaouf/RBF_neural_network_python
[3] Analytics Vidhya. (2024). “What are the Radial Basis Functions Neural Networks?” https://www.analyticsvidhya.com/blog/2024/07/radial-basis-functions-neural-networks/
[4] GeeksforGeeks. (2024). “What are radial basis function neural networks?” https://www.geeksforgeeks.org/what-are-radial-basis-function-neural-networks/
[5] Najeebuddinm98. (2024). “Design and implementation of a simple RBF Neural Network from scratch.” GitHub. https://github.com/najeebuddinm98/rbfnn_fromscratch
[6] HackerEarth. (2021). “Radial Basis Function Network.” https://www.hackerearth.com/blog/developers/radial-basis-function-network/
[7] Li, X., et al. (2022). “An RBF Neural Network Clustering Algorithm Based on K‐Nearest Neighbor.” Mathematical Problems in Engineering, Wiley Online Library. https://onlinelibrary.wiley.com/doi/10.1155/2022/1083961
[8] ResearchGate. (2016). “Any one help to understand small issue in RBF neural network?” https://www.researchgate.net/post/Any_one_help_to_understand_small_issue_in_RBF_neural_network
[9] Mrthetkhine. (2024). “RBF(Radial Basis Function) Neural Network Implementation in Python.” GitHub. https://github.com/mrthetkhine/RBFNeuralNetwork
[10] MDPI. (2024). “Learning in Deep Radial Basis Function Networks.” Entropy, 26(5), 368. https://www.mdpi.com/1099-4300/26/5/368
[11] AmirmohammadRostami. (2024). “Simple RBF and EBF neural network implementation with tensorflow.” GitHub. https://github.com/AmirmohammadRostami/BFNeuralNetwork
[12] Ruder, S. (2020). “An overview of gradient descent optimization algorithms.” https://www.ruder.io/optimizing-gradient-descent/
[13] Medium - Om Pramod. (2024). “Mastering Gradient Descent: Optimizing Neural Networks with Precision.” https://medium.com/@ompramod9921/mastering-gradient-descent-optimizing-neural-networks-with-precision-749e24c483f4
[14] Blog at the Bottom of the Sea. (2024). “Gradient Descent With Adam in Plain C++.” https://blog.demofox.org/2024/02/11/gradient-descent-with-adam-in-plain-c/
[15] MachineLearningMastery. (2021). “Gentle Introduction to the Adam Optimization Algorithm for Deep Learning.” https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/
[16] Built In. (2023). “Complete Guide to the Adam Optimization Algorithm.” https://builtin.com/machine-learning/adam-optimization
[17] Analytics Vidhya. (2025). “Optimizers in Deep Learning: A Detailed Guide.” https://www.analyticsvidhya.com/blog/2021/10/a-comprehensive-guide-on-deep-learning-optimizers/
[18] Shiksha Online. (2024). “Adam Optimizer for Stochastic Gradient Descent.” https://www.shiksha.com/online-courses/articles/adam-optimizer-for-stochastic-gradient-descent/
[19] Medium - Dagang Wei. (2024). “Demystifying the Adam Optimizer in Machine Learning.” https://medium.com/@weidagang/demystifying-the-adam-optimizer-in-machine-learning-4401d162cb9e
[20] GeeksforGeeks. (2020). “What is Adam Optimizer?” https://www.geeksforgeeks.org/adam-optimizer/
[21] Medium - C Uwatwembi. (2024). “Understanding Regularization in Deep Learning: L1, L2, Dropout, Data Augmentation, and Early Stopping Explained for Everyone.” https://medium.com/@c.uwatwembi/understanding-regularization-in-deep-learning-l1-l2-dropout-data-augmentation-and-early-5a5a24ac5954
[22] E2E Networks. (2022). “Regularization in Deep Learning: L1, L2 & Dropout.” https://www.e2enetworks.com/blog/regularization-in-deep-learning-l1-l2-dropout
[23] GeeksforGeeks. (2024). “Dropout Regularization in Deep Learning.” https://www.geeksforgeeks.org/dropout-regularization-in-deep-learning/
[24] EITCA Academy. (2024). “How do regularization techniques like dropout, L2 regularization, and early stopping help mitigate overfitting in neural networks?” https://eitca.org/artificial-intelligence/eitc-ai-adl-advanced-deep-learning/neural-networks/neural-networks-foundations/examination-review-neural-networks-foundations/how-do-regularization-techniques-like-dropout-l2-regularization-and-early-stopping-help-mitigate-overfitting-in-neural-networks/
[25] LUNARTECH. “Mastering L1 and L2 Regularization: The Ultimate Guide to Preventing Overfitting in Neural Networks.” https://www.lunartech.ai/blog/mastering-l1-and-l2-regularization-the-ultimate-guide-to-preventing-overfitting-in-neural-networks
[26] Medium - TechwithJulles. (2024). “Model Validation and Optimization — Regularization Techniques (L1, L2, Dropout).” https://medium.com/@techwithjulles/model-validation-and-optimization-regularization-techniques-l1-l2-dropout-182cb4375ecd
[27] Pickl.ai. (2024). “What is Dropout Regularization in Deep Learning?” https://www.pickl.ai/blog/what-is-dropout-regularization-in-deep-learning/
[28] Data Science Stack Exchange. “When should one use L1, L2 regularization instead of dropout layer, given that both serve same purpose of reducing overfitting?” https://datascience.stackexchange.com/questions/37362/when-should-one-use-l1-l2-regularization-instead-of-dropout-layer-given-that-b
[29] Analytics Vidhya. (2025). “Regularization in Deep Learning with Python code.” https://www.analyticsvidhya.com/blog/2018/04/fundamentals-deep-learning-regularization-techniques/
[30] Cross Validated. “Deep Learning: Use L2 and Dropout Regularization Simultaneously?” https://stats.stackexchange.com/questions/241001/deep-learning-use-l2-and-dropout-regularization-simultaneously
[31] ArmaghanSarvar. (2024). “Training RBF Neural network using ES algorithm.” GitHub. https://github.com/ArmaghanSarvar/Training-RBF-Neural-network
[32] Aliizadi. (2024). “Evolving RBF Neural Network implementation.” GitHub. https://github.com/aliizadi/Evolving-RBF-Neural-Network
[33] Medium - İlyurek Kılıç. (2024). “Optimizers: A Deep Dive into Gradient Descent, Adam, and Beyond.” https://medium.com/@ilyurek/optimizers-a-deep-dive-into-gradient-descent-adam-and-beyond-e6a1d00bc9b0
[34] Dumitrache, I., & Caramihai, S. (2015). “Mobile Robots Adaptive Control Using Neural Networks.” arXiv preprint arXiv:1512.03345. https://arxiv.org/abs/1512.03345
[35] Chen, S., et al. (2024). “Adaptive neural network control for robotic manipulators with guaranteed finite-time convergence.” Neurocomputing. https://www.sciencedirect.com/science/article/abs/pii/S0925231219300906
[36] Zhang, H., et al. (2024). “Dynamic neural networks based adaptive optimal impedance control for redundant manipulators under physical constraints.” Neurocomputing. https://www.sciencedirect.com/science/article/abs/pii/S0925231221017021
[37] Zhou, J., et al. (2024). “Adaptive Neural Network Tracking Control of Robotic Manipulators Based on Disturbance Observer.” Processes, 12(3), 499. https://www.mdpi.com/2227-9717/12/3/499
[38] Mathworks. (2024). “Incremental Learning: Adaptive and real-time machine learning.” https://blogs.mathworks.com/deep-learning/2024/03/04/incremental-learning-adaptive-and-real-time-machine-learning/
[39] Stanford CS231n. “Neural Networks 3: Learning and Evaluation.” https://cs231n.github.io/neural-networks-3/
[40] Hu, J., et al. (2024). “FLaRe: Achieving Masterful and Adaptive Robot Policies with Large-Scale Reinforcement Learning Fine-Tuning.” arXiv preprint arXiv:2409.16578. https://arxiv.org/abs/2409.16578
[41] Chen, L., et al. (2022). “Continual Learning for Real-World Autonomous Systems: Algorithms, Challenges and Frameworks.” Journal of Intelligent & Robotic Systems. https://link.springer.com/article/10.1007/s10846-022-01603-6
[42] Shafiullah, N., et al. (2024). “Supervised Policy Learning for Real Robots.” RSS 2024 Tutorial. https://supervised-robot-learning.github.io/
[43] MIT Annual Reviews. (2024). “Deep Reinforcement Learning for Robotics: A Survey of Real-World Successes.” https://www.annualreviews.org/content/journals/10.1146/annurev-control-030323-022510
[44] Wu, Z., et al. (2020). “Real-Time Adaptive Machine-Learning-Based Predictive Control of Nonlinear Processes.” Industrial & Engineering Chemistry Research. https://pubs.acs.org/doi/10.1021/acs.iecr.9b03055
[45] Wang, Y., et al. (2024). “Adaptive neural network control of manipulators with uncertain kinematics and dynamics.” Engineering Applications of Artificial Intelligence. https://www.sciencedirect.com/science/article/abs/pii/S0952197624000939
[46] Dixon, W. E., et al. (2024). “Nonlinear Controls and Robotics.” University of Florida Publications. https://ncr.mae.ufl.edu/index.php?id=publications
[47] Khlaifiabilel. (2024). “Deep Reinforcement Learning in Robotics for NVIDIA Jetson.” GitHub. https://github.com/khlaifiabilel/Deep-Reinforcement-Learning-in-Robotics
[48] Yang, Y., et al. (2024). “Reinforcement Learning Papers Collection.” GitHub. https://github.com/yingchengyang/Reinforcement-Learning-Papers
[49] Ivanov, S., et al. (2024). “Adaptive Reinforcement Learning for Robot Control.” arXiv preprint. https://arxiv.org/html/2404.18713v1
[50] Neptune.ai. (2025). “10 Real-Life Applications of Reinforcement Learning.” https://neptune.ai/blog/reinforcement-learning-applications
[51] Google Research. (2024). “Tensor2Robot: Distributed machine learning infrastructure for large-scale robotics research.” GitHub. https://github.com/google-research/tensor2robot
[52] Zhang, C., et al. (2024). “Mode-Adaptive Neural Networks for Quadraped Motion Control.” GitHub. https://github.com/cghezhang/MANN
[53] Lamarr Institute. (2025). “Introduction to Reinforcement Learning – A Robotics Perspective.” https://lamarr-institute.org/blog/reinforcement-learning-and-robotics/
[54] Ze, Y. (2024). “Paper List: Robotics, Learning, Vision.” GitHub. https://github.com/YanjieZe/Paper-List
[55] Choi, C. (2024). “SNN-Daily-Arxiv: Synaptic motor adaptation for adaptive robotic control.” GitHub. https://github.com/conscious-choi/SNN-Daily-Arxiv

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)