
水果识别分类-人工智能毕设
基于深度学习的水果识别分类项目,包含9种模型实现(7种CNN架构和2种Transformer架构),通过CBAM注意力机制优化模型性能。该项目针对水果产业全链条痛点,可实现对多种水果的精准识别,准确率超98%,单图识别耗时不足0.5秒。项目包含完整的代码实现、多模型对比实验(混淆矩阵、ROC曲线等)、Django演示系统,配套4-6小时的详细讲解视频,涵盖基础知识、环境配置、代码使用等内容,适合计
大家好,我是B站的UP主:我喜欢吃小熊饼干。我在CSDN会写一些文章介绍我做的项目,这些项目我都录制了详细的讲解视频(约4-6个小时的内容量),讲解基础知识,环境配置,代码使用等内容。
详细了解请移步:
详细讲解视频-我喜欢吃小熊饼干的个人主页-哔哩哔哩视频![]() https://space.bilibili.com/284801305
https://space.bilibili.com/284801305
几分钟快速预览项目效果的演示视频:
【计算机毕设】基于深度学习的水果识别分类【水果分类】【CNN】【Transformer】【卷积神经网络】

详细的讲解视频合集:
- 合集第一集:主要讲对整个教程的介绍,深度学习项目的基本做法和基本概念。然后介绍具体该项目的基本做法。如何去扩张项目,增加更多的内容。(这里不会涉及到代码,纯从项目的做法的角度,以PPT讲解的方式带大家入门,建立深度学习的基本概念)
- 合集第二集:毕设选题指导,毕设服务等内容
- 合集第三集:从代码使用和演示的角度,介绍项目的内容。科普深度学习环境配置的知识,如何配置项目,如何使用项目,更换数据集训练,完成特定的课题。
- 合集第四集:讲解文档相关的内容,开题报告、开题ppt、开题答辩,论文写作,论文答辩等

第一集和第三集比较重要,可以整体看下这两个视频。
下面我用文字介绍一下项目的内容
项目的背景意义:
水果作为全球消费规模最大的农产品品类之一,在我国年总产量超 3 亿吨,涵盖苹果、柑橘、葡萄、猕猴桃等百余种品类,既是保障居民膳食营养的核心食材,也是推动乡村振兴的重要经济作物。然而,在水果产业 “种植 - 采收 - 流通 - 消费” 全链条中,传统人工识别模式已难以适配规模化、智能化发展需求,暴露出诸多痛点:在种植端,农户需凭经验区分果树品种、判断果实成熟度,易因误判导致采收时机不当,如柑橘过早采摘会降低甜度,过晚则易腐烂,直接影响收益;在流通端,水果分拣依赖人工分级,不仅效率低(单人日均分拣量不足 2 吨),还易因主观标准差异导致品质参差不齐,增加物流损耗(我国水果流通损耗率约 15%,远超发达国家 5% 的水平);在消费端,消费者难以精准辨别水果品种与新鲜度,既可能误将普通苹果当作高端品种购买,也可能因无法识别霉变早期迹象误食变质水果,损害健康权益。此外,在水果科研与资源保护领域,传统人工记录品种特征的方式耗时耗力,难以满足珍稀品种快速建档与动态监测的需求。
随着消费升级与智慧农业发展,市场对水果识别的精准性、效率性、便捷性提出更高要求。一方面,消费者对水果品质、安全性的关注度持续提升,据调研,超 70% 的消费者愿为 “可溯源、品质可控” 的水果支付溢价;另一方面,水果种植户与企业亟需智能化工具降低成本、提升效益,如规模化果园需快速统计不同品种挂果量,连锁超市需高效完成水果分拣与货架补货。传统人工识别不仅无法满足这些需求,还会因人为误差造成经济损失 —— 据行业估算,我国每年因水果识别不当导致的直接损失超百亿元。
水果识别图像分类项目依托计算机视觉、深度学习技术,通过采集水果的外观特征(颜色、形状、纹理)、结构特征(果径、果形指数)及局部细节(果皮纹路、果斑分布),可实现对 50 种以上常见水果的品种识别、成熟度分级、新鲜度检测,甚至能精准区分外观相似的品类(如沃柑与茂谷柑、巨峰葡萄与夏黑葡萄),识别准确率超 98%,且单张图像识别耗时不足 0.5 秒。这一技术突破不仅能破解产业全链条痛点:在种植端,帮助农户快速判断果实成熟度、统计品种产量,优化采收计划,降低损耗;在流通端,嵌入智能分拣设备可将分拣效率提升 3-5 倍,统一分级标准,推动水果品质标准化;在消费端,通过载体,消费者拍摄水果即可获取品种、产地、营养成分及新鲜度评估,实现 “明明白白消费”;在科研端,能快速完成水果品种特征数字化建档,助力珍稀品种保护与遗传资源研究。
此外,该项目成果还可拓展至更多场景:在水果电商领域,结合图像识别的溯源系统能提升消费者信任度,推动销量增长;在智慧厨房场景,可联动家电实现 “水果自动削皮、榨汁” 等智能化操作;在海关检疫领域,能快速识别外来水果品种,防范生物入侵风险。从长远来看,水果识别图像分类技术不仅能推动水果产业从 “经验驱动” 向 “数据驱动” 转型,提升全链条效率与价值,还能为农产品智能化识别提供技术范式,助力我国农业向高质量发展迈进,兼具显著的经济价值、社会价值与技术示范价值。
项目的技术路线图
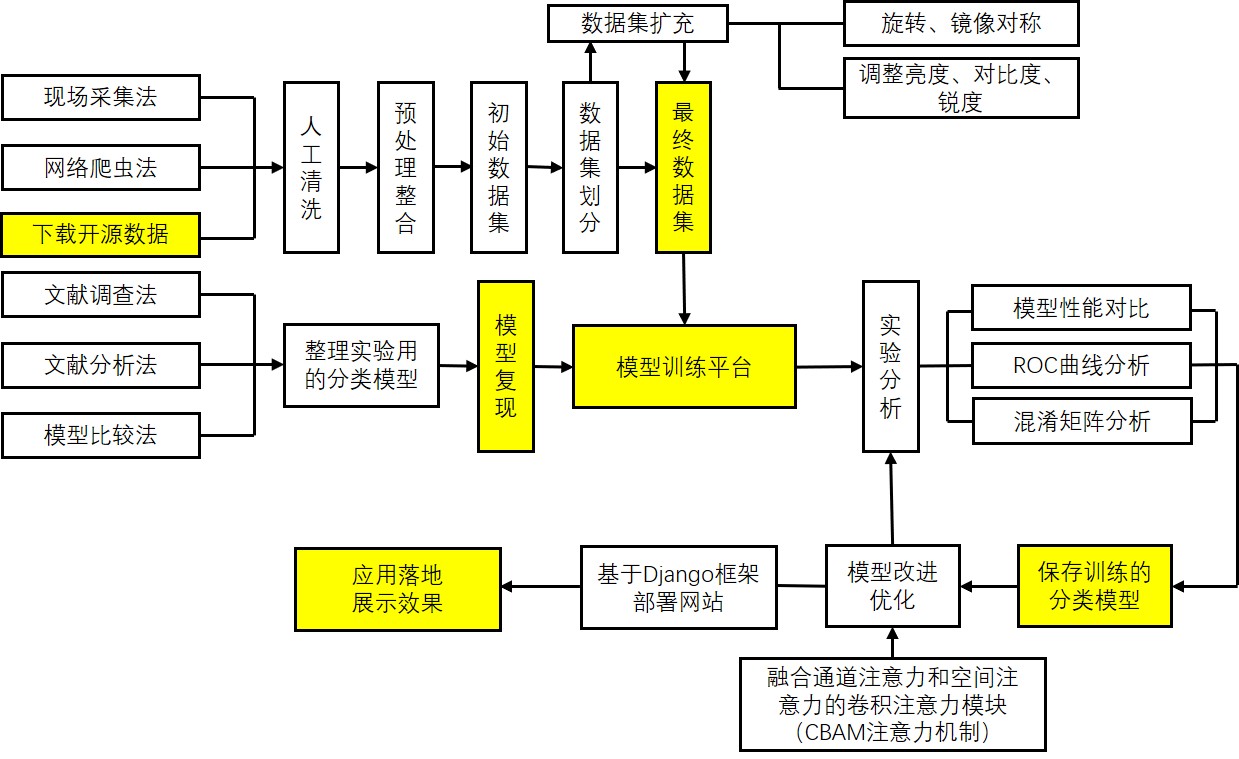
项目的数据集信息如下:
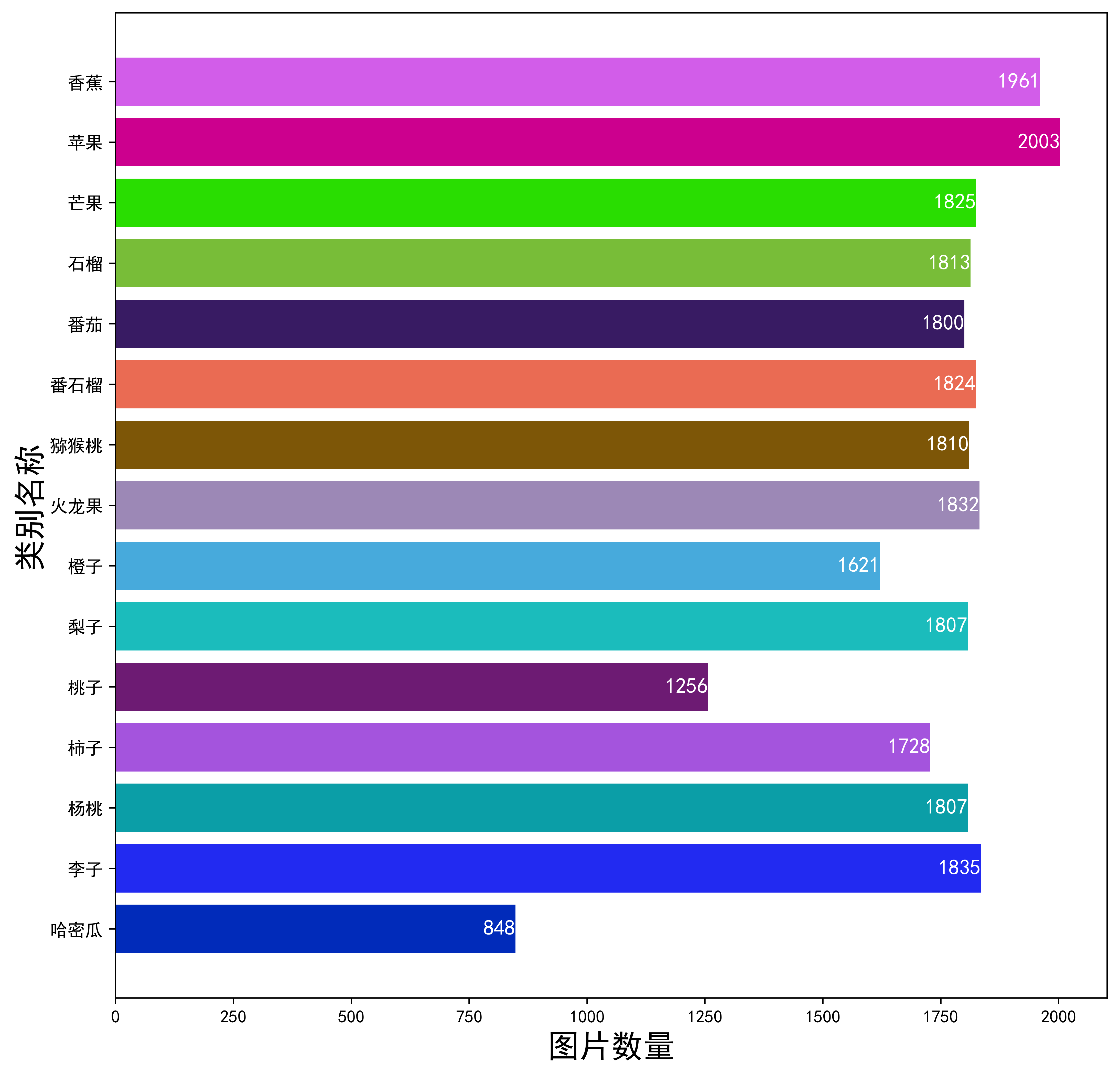

项目里实现了9种常见的模型,包括:
CNN架构的模型:
1.AlexNet
2.VGG
3.ResNet
4.MobileNet
5.DenseNet
6.ConvNeXt
7.ShuffleNet
Transformer架构的模型:
8. Swin_Transformer
9. VIT
在我的设计的项目里,一般结构如下:
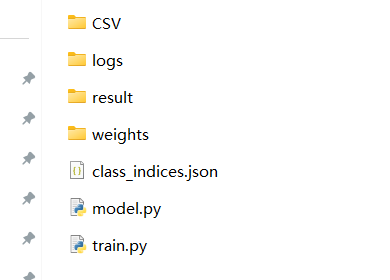
model.py: 定义模型结构
train.py:训练模型
csv文件夹里是每次训练模型生成的日志文件
logs文件夹里是TensorBoard的日志文件
weights文件夹里存储最终训练得到的模型。
举例子,ResNet模型的核心代码如下(其他模型类似,不在赘述):
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x并且项目对模型进行了优化改进,改进的内容是增加CBAM注意力机制,项目里可以实现对以上任意一种模型增加CBAM注意力机制。
常见的做法是先选择2-4种候选模型(9种模型都用有点多,推荐选部分你喜欢的模型)做对比实验,选出性能最好的模型,在最优的模型的基础上,进一步增加cbam注意力机制,进行优化改进。如果老师要求高,可以在进一步做消融实验(即模型改进优化前后的对比实验)。
CBAM机制的核心代码如下:
# CBAM 注意力模块实现 (可复用)
class CBAM(nn.Module):
def __init__(self, channels: int, reduction_ratio: int = 16, kernel_size: int = 7):
super(CBAM, self).__init__()
# 通道注意力
self.channel_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, channels // reduction_ratio, kernel_size=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channels // reduction_ratio, channels, kernel_size=1, bias=False),
nn.Sigmoid()
)
# 空间注意力
self.spatial_att = nn.Sequential(
nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2, bias=False),
nn.Sigmoid()
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 通道注意力
channel_att = self.channel_att(x)
x_channel = x * channel_att
# 空间注意力
max_pool = torch.max(x_channel, dim=1, keepdim=True)[0]
avg_pool = torch.mean(x_channel, dim=1, keepdim=True)
spatial_att = self.spatial_att(torch.cat([max_pool, avg_pool], dim=1))
x_out = x_channel * spatial_att
return x_out
CBAM结构的示意图如下:

CBAM注意力机制是一种用于前馈卷积神经网络的简单而有效的注意力模块。 给定一个中间特征图,CBAM模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将注意力图与输入特征图相乘以进行自适应特征优化。 由于CBAM是轻量级的通用模块,因此可以忽略的该模块的开销而将其无缝集成到任何CNN架构中,并且可以与基础CNN一起进行端到端训练。
首先,输入是一个中间特征图,将特征图输入至Channel Attention Module 获取通道注意力,然后将注意力权重作用于中间特征图。
然后,将施加通道注意力的特征图输入至Spatial Attention Module 获取空间注意力,然后将注意力权重作用到特征图上。
最终,经过这两个注意力模块的串行操作,最初的特征图就经过了通道和空间两个注意力机制的处理,自适应细化特征。

训练完模型可以做对比实验,通过写代码可以制作对比曲线图和柱状图,项目的最终实验效果如下:
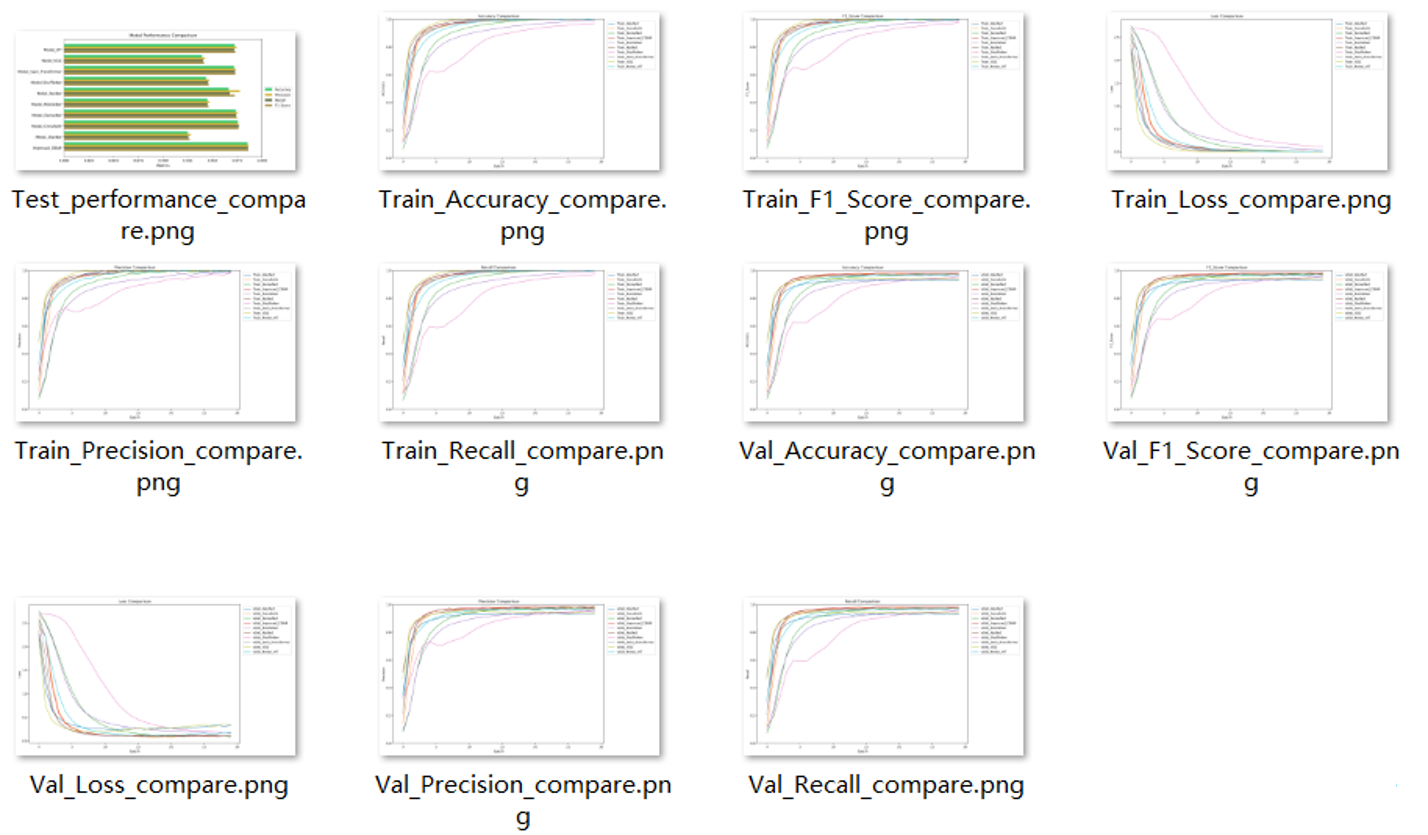
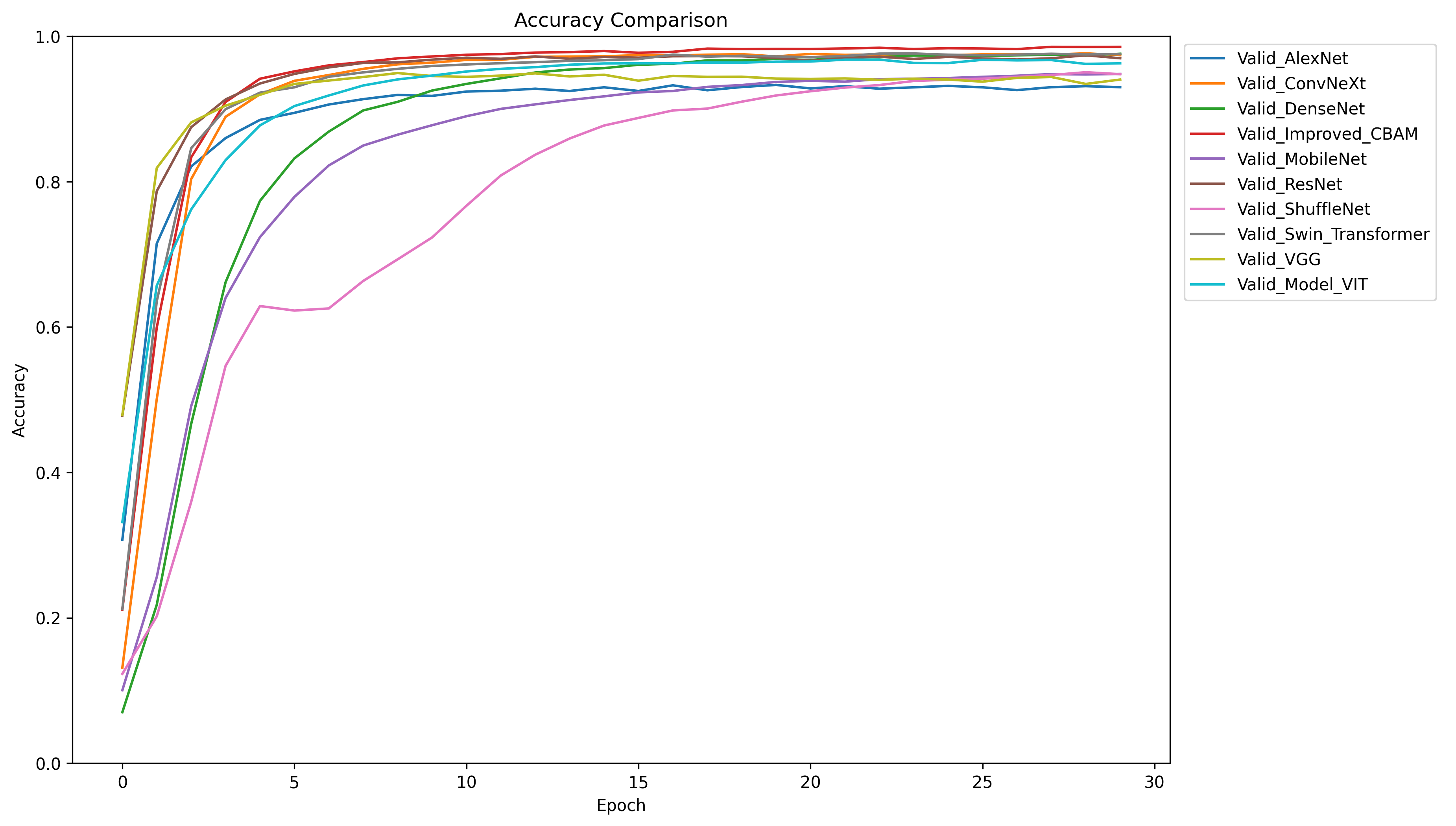
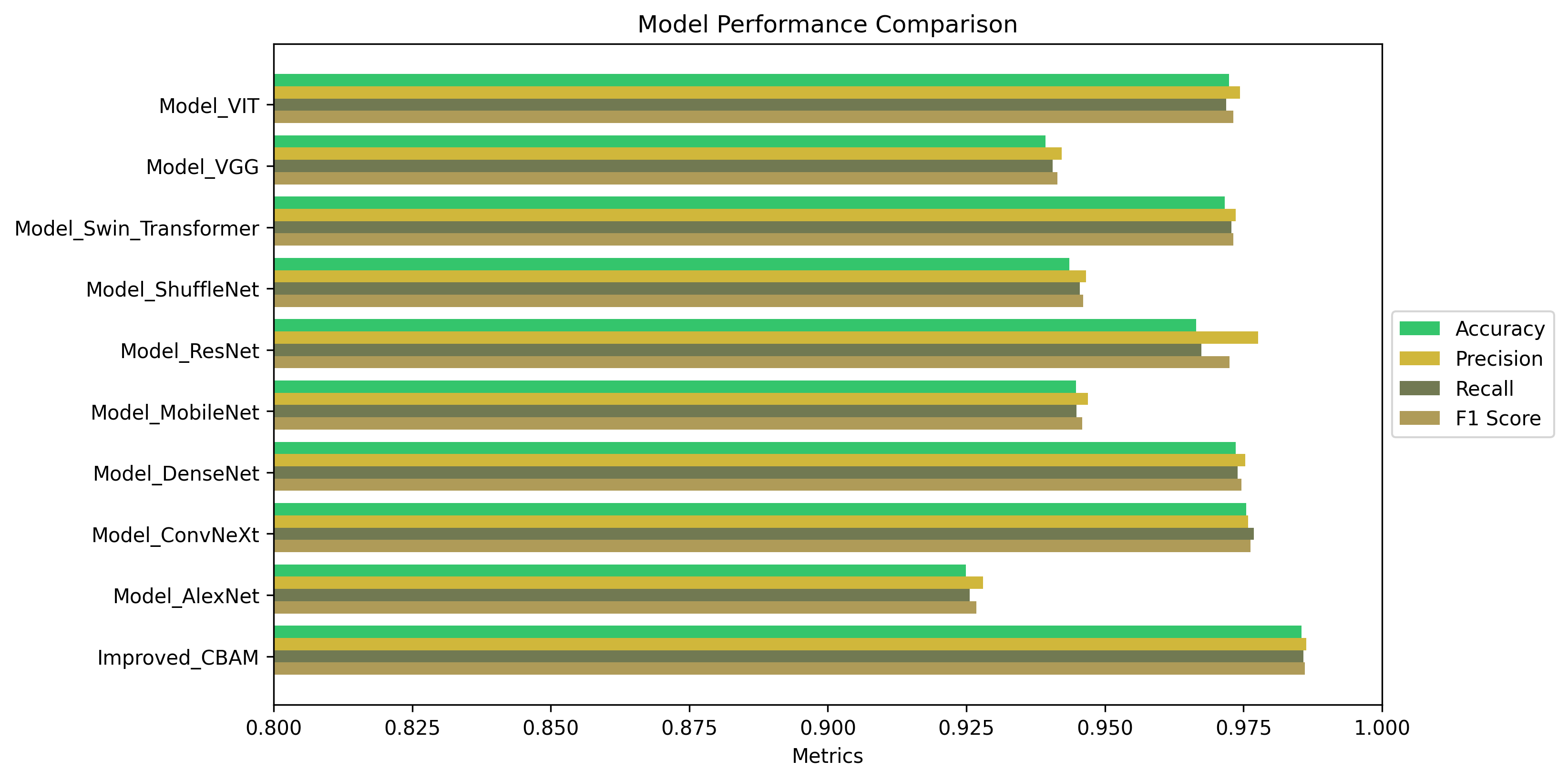
模型最终能达到97%以上
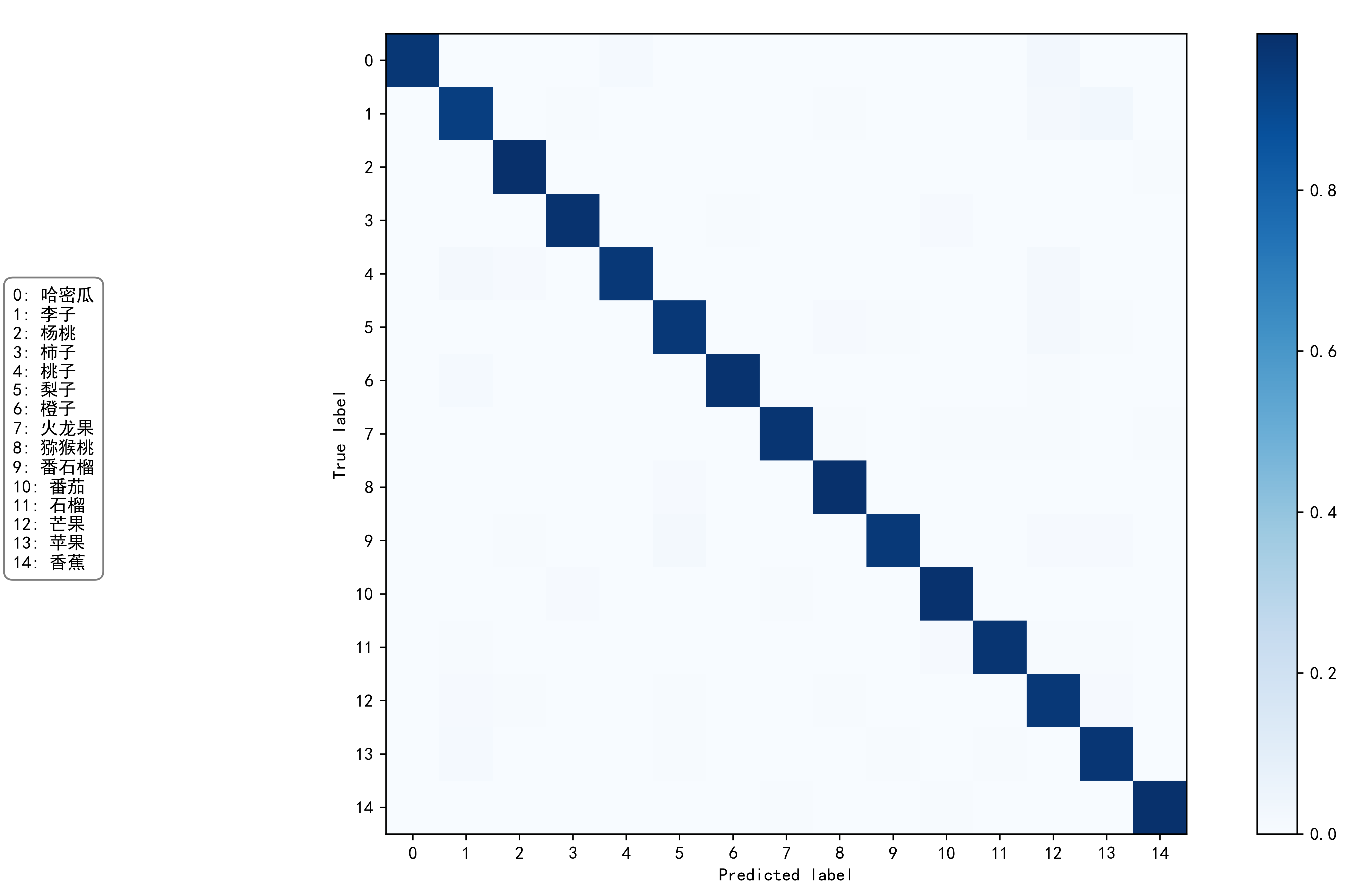
除了对比实验之外,还可以进一步分析模型的性能,其中
混淆矩阵实验图如下:
ROC曲线实验图如下:
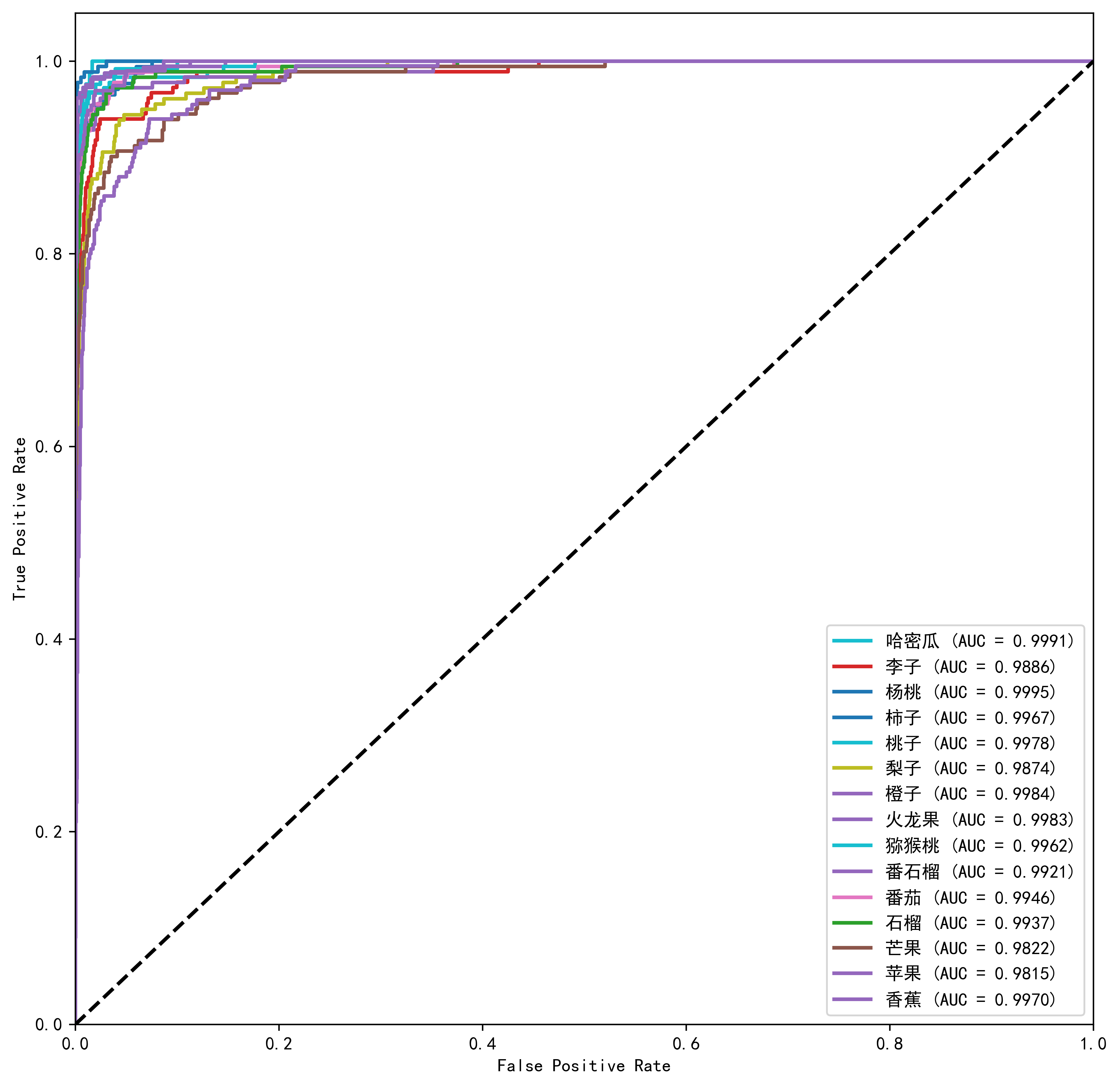
以上是实验的内容。
最后基于Python的Django框架,制作最终的演示系统,最终结果预览如下:
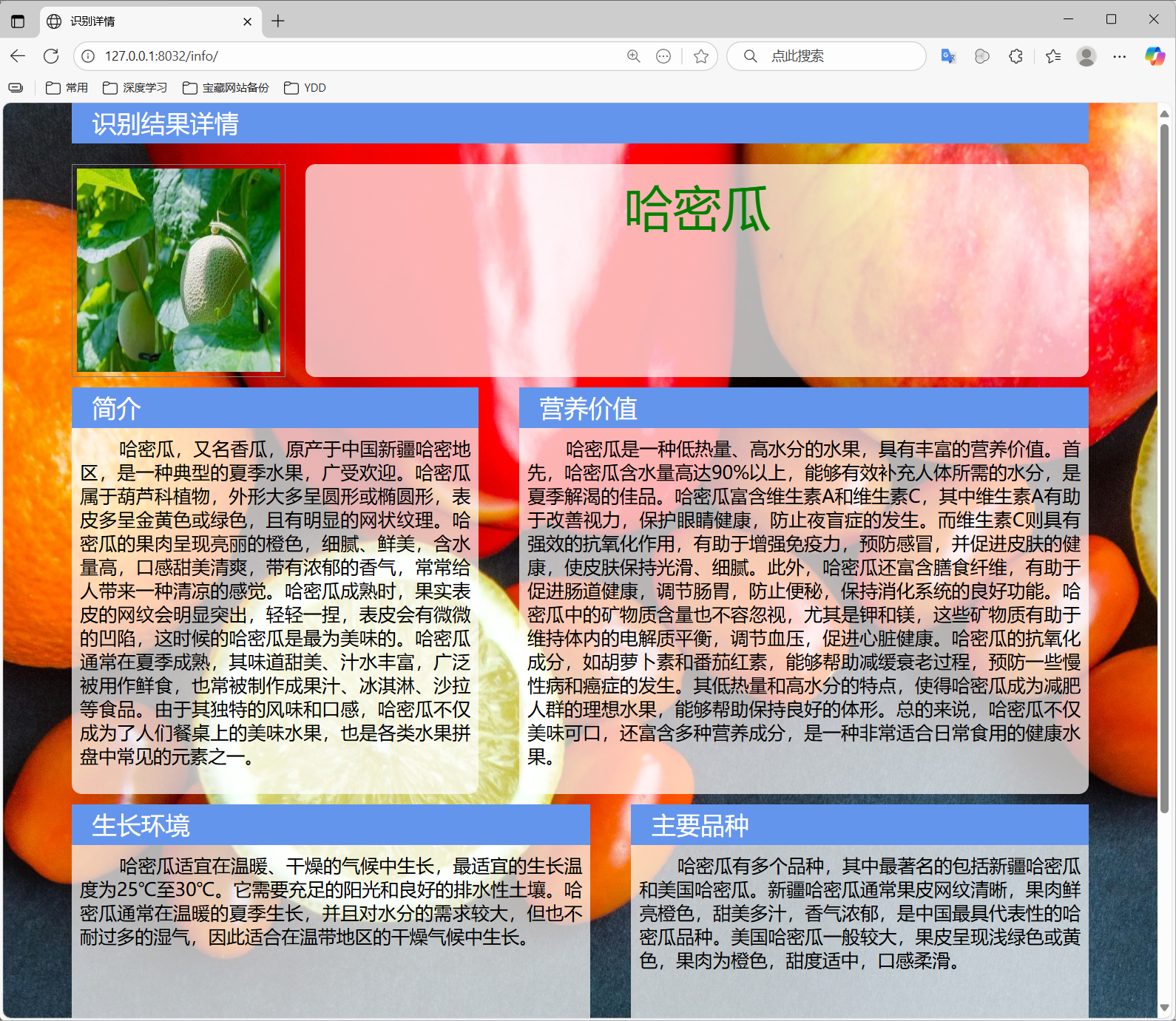
本项目包含:
1.多模型的对比实验和图表,丰富了项目的内容。
2. 模型的优化改进,实现项目的重新。
3. 混淆矩阵和ROC等实验分析,拓展的项目的深度和内容量
4.实现了最终的演示系统,实现了项目的落地和应用。


openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐

 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)