
性能优化篇:整合RK3588异构计算+零拷贝实现YOLOv5推理
本文实现了一个基于V4L2接口的硬件加速图像处理流程,通过dmabuf实现ISP、RGA和NPU模块的零拷贝数据传输。系统首先使用V4L2控制ISP输出帧到dmabuf,然后经RGA进行预处理,最终送入NPU推理,结果映射到用户空间显示。整个流程均通过片上硬件资源处理,避免了CPU参与,显著降低了CPU占用率。文中详细阐述了V4L2驱动的8个关键步骤:设备打开、能力查询、格式枚举、格式设置、缓冲申
本文实现一个数据流,使用V4L2接口控制ISP出帧给dmabuf,再将dmabuf送给RGA模块做图像预处理,预处理输出依旧是dmabuf,然后再将该buf送给npu进行推理。推理结果映射到用户空间,并叠加到用户空间的mat图像上显示。
这样图像的相关操作全程经过片上硬件资源处理,实现硬件加速。同时硬件模块传递图像也是通过dmbuf,全程不经过Cpu,显著降低cpu占用率。
数据流程图如下: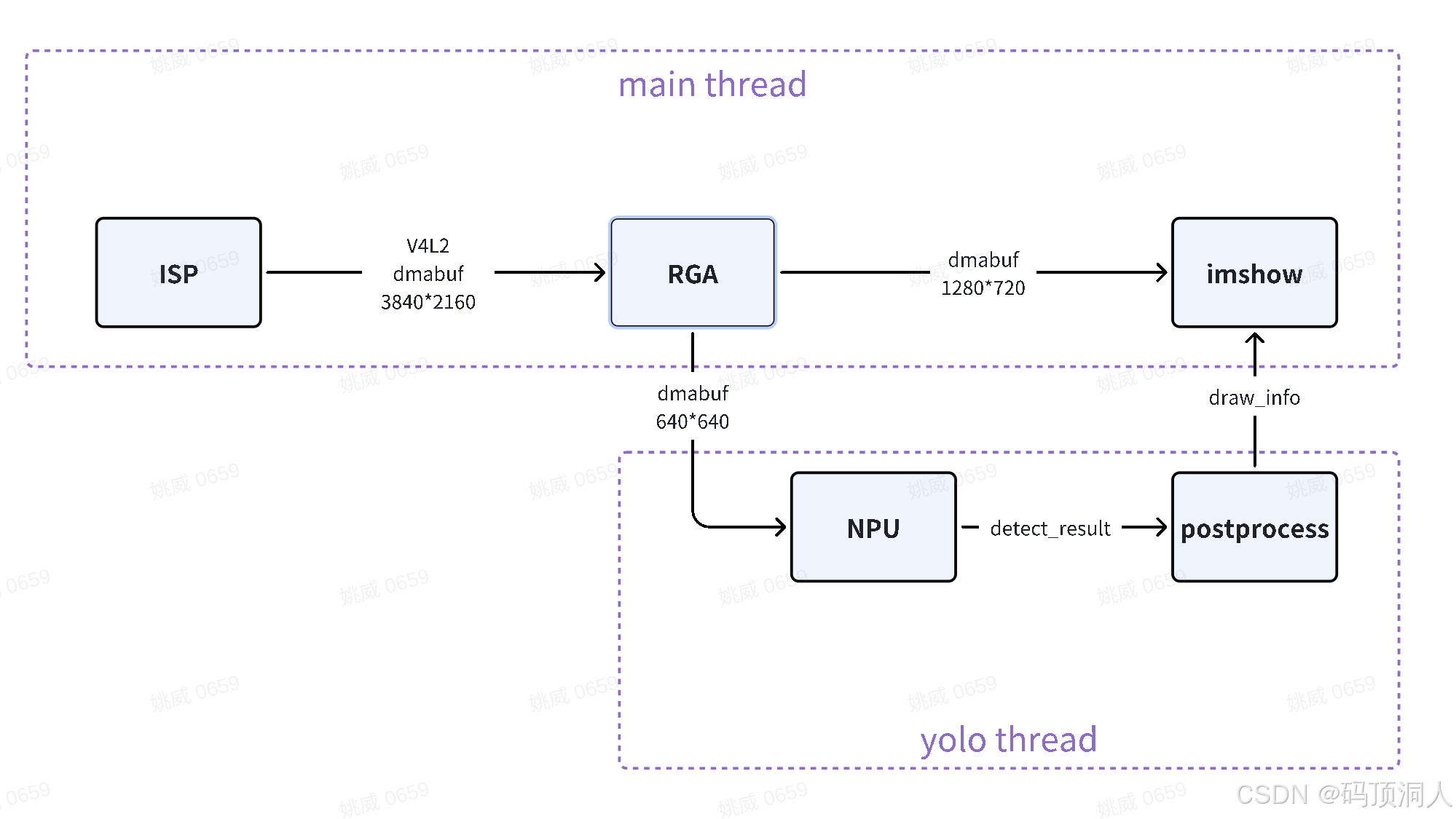
V4L2
step1(open)
/* 1. open /dev/video* */
cam_dev_fd = open(CAM_DEVICE, O_RDWR|O_NONBLOCK, 0);
if (cam_dev_fd < 0)
{
printf("can not open %s\n", CAM_DEVICE);
return -1;
}
step2(query capability)
/* 2. query capability */
struct v4l2_capability cap;
memset(&cap, 0, sizeof(struct v4l2_capability));
if (0 == ioctl(cam_dev_fd, VIDIOC_QUERYCAP, &cap))
{
if ((cap.capabilities & V4L2_CAP_VIDEO_CAPTURE_MPLANE) == 0)
{
fprintf(stderr, "Error opening device %s: video capture mplane not supported.\n", CAM_DEVICE);
return -1;
}
if(!(cap.capabilities & V4L2_CAP_STREAMING))
{
fprintf(stderr, "%s does not support streaming i/o\n", CAM_DEVICE);
return -1;
}
}
step3(enum formt)
struct v4l2_fmtdesc fmtdesc;
struct v4l2_frmsizeenum fsenum;
int fmt_index = 0;
int frame_index = 0;
while (1)
{
fmtdesc.index = fmt_index;
fmtdesc.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
if (0 != ioctl(cam_dev_fd, VIDIOC_ENUM_FMT, &fmtdesc))
{
printf("can not get format\n");
break;
}
printf("format %s:\n", fmtdesc.description);
frame_index = 0;
while (1)
{
memset(&fsenum, 0, sizeof(struct v4l2_frmsizeenum));
fsenum.pixel_format = fmtdesc.pixelformat;
fsenum.index = frame_index;
if (ioctl(cam_dev_fd, VIDIOC_ENUM_FRAMESIZES, &fsenum) == 0)
{
printf("\t%d: %d x %d\n", frame_index, fsenum.discrete.width, fsenum.discrete.height);
}
else
{
break;
}
frame_index++;
}
fmt_index++;
}
step4(set formt)
struct v4l2_format fmt;
memset(&fmt, 0, sizeof(struct v4l2_format));
fmt.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
fmt.fmt.pix.width = CAM_OUTPUT_WIDTH;
fmt.fmt.pix.height = CAM_OUTPUT_HEIGHT;
fmt.fmt.pix.pixelformat = FRAME_FMT;
fmt.fmt.pix.field = V4L2_FIELD_ANY;
if (0 == ioctl(cam_dev_fd, VIDIOC_S_FMT, &fmt))
{
num_planes = fmt.fmt.pix_mp.num_planes;
ret = ioctl(cam_dev_fd, VIDIOC_G_FMT, &fmt);
if(ret < 0)
{
printf("VIDIOC_G_FMT fail\n");
return -1;
}
printf("final fmt has been set: width:%d, height:%d, num_planes:%d, size:%d\n", fmt.fmt.pix.width, fmt.fmt.pix.height, num_planes, fmt.fmt.pix.sizeimage);
printf("\tpixelformat:\t%c%c%c%c\n", fmt.fmt.pix.pixelformat & 0xff,
(fmt.fmt.pix.pixelformat >> 8) & 0xff,
(fmt.fmt.pix.pixelformat >> 16) & 0xff,
(fmt.fmt.pix.pixelformat >> 24) & 0xff);
}
step5(req buffer)
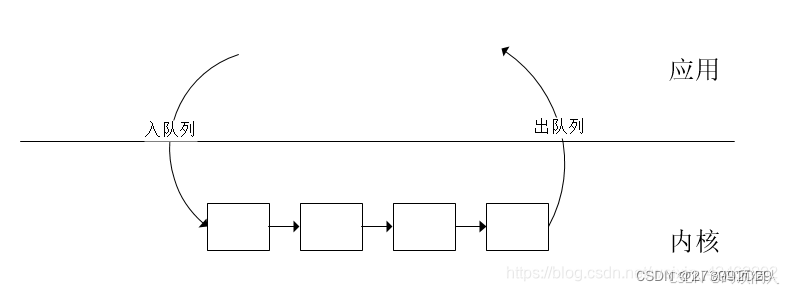
/* 5. 从驱动中申请dmabuf */
struct v4l2_requestbuffers req_buffer;
memset(&req_buffer, 0, sizeof(struct v4l2_requestbuffers));
req_buffer.count = REQBUF_NUM;
req_buffer.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
req_buffer.memory = V4L2_MEMORY_DMABUF;
if (ioctl(cam_dev_fd, VIDIOC_REQBUFS, &req_buffer) < 0)
{
printf("can not request buffers\n");
return -1;
}
for(int i = 0; i < REQBUF_NUM; i++)
{
ret = dma_buf_alloc(DMA_HEAP_PATH, fmt.fmt.pix.sizeimage, &dmabuf_fds[i], (void **)&dmabuf_maps[i]);
if (ret < 0)
{
printf("alloc raw dma_heap buffer failed!\n");
dma_buf_free(fmt.fmt.pix.sizeimage, &dmabuf_fds[i], dmabuf_maps[i]);
return -1;
}
printf("alloc dma_heap buffer. fd: %d, raw_buf: %p, size: %d \n", dmabuf_fds[i], dmabuf_maps[i], fmt.fmt.pix.sizeimage);
}
step6(queue buffer)
/* 6. queue buffer to driver queue*/
for(int i = 0; i < req_buffer.count; ++i)
{
struct v4l2_buffer buf;
struct v4l2_plane planes[num_planes];
memset(&buf, 0, sizeof(struct v4l2_buffer));
memset(&planes, 0, sizeof(planes));
buf.index = i;
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
buf.memory = V4L2_MEMORY_DMABUF;
buf.m.planes = planes;
buf.length = num_planes;
buf.m.planes[0].m.fd = dmabuf_fds[i];
if (0 != ioctl(cam_dev_fd, VIDIOC_QBUF, &buf))
{
perror("Unable to queue buffer");
return -1;
}
}
step7(streaming on)
/* start camera */
if (0 != ioctl(cam_dev_fd, VIDIOC_STREAMON, &type))
{
printf("Unable to start capture\n");
return -1;
}
step8(dequeue buffer)
循环出队buffer,拿出来消费
/* dequeue buffer */
struct v4l2_buffer buf;
struct v4l2_plane planes[num_planes];
memset(&buf, 0, sizeof(struct v4l2_buffer));
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
buf.memory = V4L2_MEMORY_DMABUF;
buf.m.planes = planes;
buf.length = num_planes;
if (0 != ioctl(cam_dev_fd, VIDIOC_DQBUF, &buf))
{
printf("Unable to dequeue buffer\n");
break;
}
step9(queue buffer)
归还给内核
/* queue buffer, 此时raw_rga_buf对应的dmabuf_fds[buf.index]已经使用完,结果保存在新内存中。可以立即入队给内核 */
if (0 != ioctl(cam_dev_fd, VIDIOC_QBUF, &buf))
{
printf("Unable to queue buffer");
break;
}
step10(stream off、close)
/* close camera */
if (0 != ioctl(cam_dev_fd, VIDIOC_STREAMOFF, &type))
{
printf("Unable to stop capture\n");
return -1;
}
close(cam_dev_fd);
printf("close camera. \n");
/* free req dma buffer */
for(int i = 0; i < req_buffer.count; i++)
{
printf("free dma buffer. fd: %d, raw_buf: %p, size: %d \n", dmabuf_fds[i], dmabuf_maps[i], fmt.fmt.pix.sizeimage);
dma_buf_free(fmt.fmt.pix.sizeimage, &dmabuf_fds[i], dmabuf_maps[i]);
}
RGA
使用wrapbuffer_fd_t,包装ISP出的dmabuf,以便RGA使用
// convert raw image to npu input image
rga_buffer_t raw_rga_buf = wrapbuffer_fd_t(dmabuf_fds[buf.index], CAM_OUTPUT_WIDTH, CAM_OUTPUT_HEIGHT, CAM_OUTPUT_WIDTH, CAM_OUTPUT_HEIGHT, RK_FORMAT_YCrCb_420_SP);
ret = imresize(raw_rga_buf, resize_tonpu_rga_buf); // resize raw dmabuf to resize buf 640x640
if (ret != IM_STATUS_SUCCESS)
{
printf("resize_tonpu_rga_buf running failed, %s\n", imStrError((IM_STATUS)ret));
break;
}
ret = imcvtcolor(resize_tonpu_rga_buf, input_npu_buf, RK_FORMAT_YCrCb_420_SP, RK_FORMAT_RGB_888); // cvt color nv21 to rgb888
if (ret != IM_STATUS_SUCCESS)
{
printf("cvtcolor input_npu_buf running failed, %s\n", imStrError((IM_STATUS)ret));
break;
}
NPU
申请输入npu的dmabuf内存,并将其绑定到rga的输出dmabuf
/* alloc input tensor memory */
rknn_tensor_mem* input_mems[1];
input_attrs[0].type = RKNN_TENSOR_UINT8;
input_attrs[0].fmt = RKNN_TENSOR_NHWC;
input_mems[0] = rknn_create_mem(ctx, input_attrs[0].size_with_stride);
printf("rknn create input_mems[0].fd: %d, size: %d \n", input_mems[0]->fd, input_mems[0]->size);
input_npu_buf = wrapbuffer_fd_t(input_mems[0]->fd, NPU_INPUT_WIDTH, NPU_INPUT_HEIGHT, NPU_INPUT_WIDTH, NPU_INPUT_HEIGHT, RK_FORMAT_RGB_888);
/* Set input tensor memory */
ret = rknn_set_io_mem(ctx, input_mems[0], &input_attrs[0]);
if (ret < 0)
{
printf("rknn_set_io_mem fail! ret=%d\n", ret);
pthread_exit(NULL);
}
数据流总结
- 初始化阶段
硬件绑定:
主线程绑定到CPU核心7。
推理线程绑定到CPU核心6。
资源准备:
加载模型文件 yolov5s-640-640.rknn。
初始化NPU推理上下文。
创建DMA缓冲区(用于摄像头输入、缩放、颜色转换等)。
分配内存给输入输出张量(input_mems, output_mems)。
同步机制初始化:
使用互斥锁 (pthread_mutex) 和条件变量 (pthread_cond) 控制主线程与推理线程之间的通信。
使用信号量 (sem_result_ready) 通知主线程推理结果就绪。 - 摄像头采集流程
设备打开:通过 /dev/video11 打开摄像头设备。
格式设置:
设置分辨率为 3840x2160,像素格式为 NV21。
申请 DMA 缓冲区:
为摄像头帧分配多个 DMA 缓冲区(dmabuf_fds[i])。
启动视频流:
调用 VIDIOC_STREAMON 启动摄像头捕获。 - 主循环处理帧数据
主循环持续处理每一帧图像:
A. 图像预处理
去队列化帧数据:
使用 VIDIOC_DQBUF 获取摄像头帧。
图像缩放与格式转换:
将原始 NV21 图像缩放到 640x640(用于 NPU 输入)并转换为 RGB 格式。
另一路缩放到 1280x720 并转换为 BGR 格式(用于显示)。
B. 激活 NPU 推理
唤醒推理线程:
如果推理线程空闲,则发送条件信号,触发推理任务。
等待推理结果:
主线程使用 sem_wait 等待推理完成。
C. 显示处理结果
绘制检测框:
在 cv::Mat 图像上绘制检测框和标签。
OpenCV 显示:
使用 cv::imshow 展示最终图像。
D. 帧回收
重新入队:
处理完的帧通过 VIDIOC_QBUF 重新入队供摄像头继续使用。
4. 释放资源
关闭摄像头:
调用 VIDIOC_STREAMOFF 停止视频流。
释放所有 DMA 缓冲区:
包括原始帧、缩放、颜色转换等缓冲区。
销毁 NPU 上下文:
释放模型内存和推理相关资源。
退出线程:
等待推理线程结束,并销毁互斥锁和条件变量。
完整源码
#include <iostream>
#include <fstream>
#include <sstream>
#include <cstddef>
#include <cmath>
#include <stdlib.h>
#include <string.h>
#include <sys/time.h>
#include <unistd.h>
#include <sys/mman.h>
#include <string.h>
#include <vector>
#include <chrono>
#include <sched.h>
#include <poll.h>
#include <linux/types.h>
#include <linux/videodev2.h>
#include <linux/fb.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <pthread.h>
#include <semaphore.h>
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/core/core.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
#include "rga.h"
#include "RgaUtils.h"
#include "im2d.h"
#include "rknn_api.h"
#include "postprocess.h"
#include "dma_alloc.h"
constexpr int CAM_OUTPUT_WIDTH = 3840;
constexpr int CAM_OUTPUT_HEIGHT = 2160;
constexpr int CAM_SHOW_WIDTH = 3840/3;
constexpr int CAM_SHOW_HEIGHT = 2160/3;
constexpr int CAM_OUTPUT_FPS = 30;
#define FRAME_FMT V4L2_PIX_FMT_NV21
constexpr int NPU_INPUT_WIDTH = 640;
constexpr int NPU_INPUT_HEIGHT = 640;
constexpr const char* model_filename = "../model/yolov5s-640-640.rknn";
constexpr const char* labels_filename = "../model/coco_80_labels_list.txt";
char* labels[OBJ_CLASS_NUM];
constexpr int MAX_CORES = 8;
constexpr const char* FREQ_PATH = "/sys/devices/system/cpu/cpu%d/cpufreq/scaling_max_freq";
constexpr const char *CAM_DEVICE = "/dev/video11";
constexpr int REQBUF_NUM = 4;
void* rknn_thread_func(void* arg);
pthread_mutex_t rknn_mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t rknn_cond = PTHREAD_COND_INITIALIZER;
sem_t sem_result_ready;
volatile enum class RKNN_THREAD_STATUS
{
IDLE, // 0 空闲状态
READY, // 1 唤醒条件变量~推理线程推理之间
PROCESSING, // 2 推理中
DONE, // 3 结果已更新
EXIT // 4 退出
} rknn_thread_status;
int input_npu_channel = 3;
int input_npu_width = 0;
int input_npu_height = 0;
rknn_input_output_num io_num;
rknn_tensor_attr output_attrs[10] = {0};
rga_buffer_t input_npu_buf = {0};
detect_result_group_t detect_result_group = {0};
static void dump_tensor_attr(rknn_tensor_attr* attr)
{
std::string shape_str = attr->n_dims < 1 ? "" : std::to_string(attr->dims[0]);
for (int i = 1; i < attr->n_dims; ++i)
{
shape_str += ", " + std::to_string(attr->dims[i]);
}
printf(" index=%d, name=%s, n_dims=%d, dims=[%s], n_elems=%d, size=%d, w_stride = %d, size_with_stride=%d, fmt=%s, "
"type=%s, qnt_type=%s, "
"zp=%d, scale=%f\n",
attr->index, attr->name, attr->n_dims, shape_str.c_str(), attr->n_elems, attr->size, attr->w_stride,
attr->size_with_stride, get_format_string(attr->fmt), get_type_string(attr->type),
get_qnt_type_string(attr->qnt_type), attr->zp, attr->scale);
}
double __get_us(struct timeval t) { return (t.tv_sec * 1000000 + t.tv_usec); }
static unsigned char* load_data(FILE* fp, size_t ofst, size_t sz)
{
unsigned char* data;
int ret;
data = NULL;
if (NULL == fp)
{
return NULL;
}
ret = fseek(fp, ofst, SEEK_SET);
if (ret != 0)
{
printf("blob seek failure.\n");
return NULL;
}
data = (unsigned char*)malloc(sz);
if (data == NULL)
{
printf("buffer malloc failure.\n");
return NULL;
}
ret = fread(data, 1, sz, fp);
return data;
}
static unsigned char* load_model(const char* filename, int* model_size)
{
FILE* fp;
unsigned char* data;
fp = fopen(filename, "rb");
if (NULL == fp)
{
printf("Open file %s failed.\n", filename);
return NULL;
}
fseek(fp, 0, SEEK_END);
int size = ftell(fp);
data = load_data(fp, 0, size);
fclose(fp);
*model_size = size;
return data;
}
static int saveFloat(const char* file_name, float* output, int element_size)
{
FILE* fp;
fp = fopen(file_name, "w");
for (int i = 0; i < element_size; i++)
{
fprintf(fp, "%.6f\n", output[i]);
}
fclose(fp);
return 0;
}
int main(void)
{
int ret = 0;
sem_init(&sem_result_ready, 0, 0);
/* Bind to core 7 */
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(7, &cpuset);
ret = sched_setaffinity(0, sizeof(cpuset), &cpuset);
if(ret < 0)
{
printf("sched_setaffinity fail! ret=%d\n", ret);
return -1;
}
printf("main thread running on CPU %d\n", sched_getcpu());
/* 1. open /dev/video* */
int cam_dev_fd;
int type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
struct pollfd fds[1];
int num_planes;
int dmabuf_fds[REQBUF_NUM] = {0};
void *dmabuf_maps[REQBUF_NUM] = {0};
cam_dev_fd = open(CAM_DEVICE, O_RDWR|O_NONBLOCK, 0);
if (cam_dev_fd < 0)
{
printf("can not open %s\n", CAM_DEVICE);
return -1;
}
/* 2. query capability */
struct v4l2_capability cap;
memset(&cap, 0, sizeof(struct v4l2_capability));
if (0 == ioctl(cam_dev_fd, VIDIOC_QUERYCAP, &cap))
{
if ((cap.capabilities & V4L2_CAP_VIDEO_CAPTURE_MPLANE) == 0)
{
fprintf(stderr, "Error opening device %s: video capture mplane not supported.\n", CAM_DEVICE);
return -1;
}
if(!(cap.capabilities & V4L2_CAP_STREAMING))
{
fprintf(stderr, "%s does not support streaming i/o\n", CAM_DEVICE);
return -1;
}
}
else
{
printf("can not get capability\n");
return -1;
}
/* 3. enum formt */
struct v4l2_fmtdesc fmtdesc;
struct v4l2_frmsizeenum fsenum;
int fmt_index = 0;
int frame_index = 0;
while (1)
{
fmtdesc.index = fmt_index;
fmtdesc.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
if (0 != ioctl(cam_dev_fd, VIDIOC_ENUM_FMT, &fmtdesc))
{
printf("can not get format\n");
break;
}
printf("format %s:\n", fmtdesc.description);
frame_index = 0;
while (1)
{
memset(&fsenum, 0, sizeof(struct v4l2_frmsizeenum));
fsenum.pixel_format = fmtdesc.pixelformat;
fsenum.index = frame_index;
if (ioctl(cam_dev_fd, VIDIOC_ENUM_FRAMESIZES, &fsenum) == 0)
{
printf("\t%d: %d x %d\n", frame_index, fsenum.discrete.width, fsenum.discrete.height);
}
else
{
break;
}
frame_index++;
}
fmt_index++;
}
/* 4. set formt */
struct v4l2_format fmt;
memset(&fmt, 0, sizeof(struct v4l2_format));
fmt.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
fmt.fmt.pix.width = CAM_OUTPUT_WIDTH;
fmt.fmt.pix.height = CAM_OUTPUT_HEIGHT;
fmt.fmt.pix.pixelformat = FRAME_FMT;
fmt.fmt.pix.field = V4L2_FIELD_ANY;
if (0 == ioctl(cam_dev_fd, VIDIOC_S_FMT, &fmt))
{
num_planes = fmt.fmt.pix_mp.num_planes;
ret = ioctl(cam_dev_fd, VIDIOC_G_FMT, &fmt);
if(ret < 0)
{
printf("VIDIOC_G_FMT fail\n");
return -1;
}
printf("final fmt has been set: width:%d, height:%d, num_planes:%d, size:%d\n", fmt.fmt.pix.width, fmt.fmt.pix.height, num_planes, fmt.fmt.pix.sizeimage);
printf("\tpixelformat:\t%c%c%c%c\n", fmt.fmt.pix.pixelformat & 0xff,
(fmt.fmt.pix.pixelformat >> 8) & 0xff,
(fmt.fmt.pix.pixelformat >> 16) & 0xff,
(fmt.fmt.pix.pixelformat >> 24) & 0xff);
}
else
{
printf("can not set format\n");
return -1;
}
/* 5. 从驱动中申请dmabuf */
struct v4l2_requestbuffers req_buffer;
memset(&req_buffer, 0, sizeof(struct v4l2_requestbuffers));
req_buffer.count = REQBUF_NUM;
req_buffer.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
req_buffer.memory = V4L2_MEMORY_DMABUF;
if (ioctl(cam_dev_fd, VIDIOC_REQBUFS, &req_buffer) < 0)
{
printf("can not request buffers\n");
return -1;
}
for(int i = 0; i < REQBUF_NUM; i++)
{
ret = dma_buf_alloc(DMA_HEAP_PATH, fmt.fmt.pix.sizeimage, &dmabuf_fds[i], (void **)&dmabuf_maps[i]);
if (ret < 0)
{
printf("alloc raw dma_heap buffer failed!\n");
dma_buf_free(fmt.fmt.pix.sizeimage, &dmabuf_fds[i], dmabuf_maps[i]);
return -1;
}
printf("alloc dma_heap buffer. fd: %d, raw_buf: %p, size: %d \n", dmabuf_fds[i], dmabuf_maps[i], fmt.fmt.pix.sizeimage);
}
/* 6. queue buffer to driver queue*/
for(int i = 0; i < req_buffer.count; ++i)
{
struct v4l2_buffer buf;
struct v4l2_plane planes[num_planes];
memset(&buf, 0, sizeof(struct v4l2_buffer));
memset(&planes, 0, sizeof(planes));
buf.index = i;
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
buf.memory = V4L2_MEMORY_DMABUF;
buf.m.planes = planes;
buf.length = num_planes;
buf.m.planes[0].m.fd = dmabuf_fds[i];
if (0 != ioctl(cam_dev_fd, VIDIOC_QBUF, &buf))
{
perror("Unable to queue buffer");
return -1;
}
}
/* start camera */
if (0 != ioctl(cam_dev_fd, VIDIOC_STREAMON, &type))
{
printf("Unable to start capture\n");
return -1;
}
/* create window */
cv::namedWindow("img", /*flags=WINDOW_AUTOSIZE*/ 1);
/* alloc resize tonpu dma buffer */
char *resize_tonpu_buf = nullptr;
int resize_tonpu_dma_fd = 0;
int resize_tonpu_frame_size = NPU_INPUT_WIDTH * NPU_INPUT_HEIGHT * 3;
ret = dma_buf_alloc(DMA_HEAP_PATH, resize_tonpu_frame_size, &resize_tonpu_dma_fd, (void **)&resize_tonpu_buf);
if (ret < 0)
{
printf("alloc resize to npu dma_heap buffer failed! \n");
dma_buf_free(resize_tonpu_frame_size, &resize_tonpu_dma_fd, resize_tonpu_buf);
return -1;
}
printf("alloc dma_heap buffer. fd: %d, resize_tonpu_buf: %p, size: %d \n", resize_tonpu_dma_fd, resize_tonpu_buf, resize_tonpu_frame_size);
rga_buffer_t resize_tonpu_rga_buf = wrapbuffer_fd_t(resize_tonpu_dma_fd, NPU_INPUT_WIDTH, NPU_INPUT_HEIGHT, NPU_INPUT_WIDTH, NPU_INPUT_HEIGHT, RK_FORMAT_YCrCb_420_SP);
/* alloc resize to show dma buffer */
char *resize_toshow_buf = nullptr;
int resize_toshow_dma_fd = 0;
int resize_toshow_frame_size = CAM_SHOW_WIDTH * CAM_SHOW_HEIGHT * 3;
ret = dma_buf_alloc(DMA_HEAP_PATH, resize_toshow_frame_size, &resize_toshow_dma_fd, (void **)&resize_toshow_buf);
if (ret < 0)
{
printf("alloc resize to show dma_heap buffer failed! \n");
dma_buf_free(resize_toshow_frame_size, &resize_toshow_dma_fd, resize_toshow_buf);
return -1;
}
printf("alloc dma_heap buffer. fd: %d, resize_toshow_buf: %p, size: %d \n", resize_toshow_dma_fd, resize_toshow_buf, resize_toshow_frame_size);
rga_buffer_t resize_toshow_rga_buf = wrapbuffer_fd_t(resize_toshow_dma_fd, CAM_SHOW_WIDTH, CAM_SHOW_HEIGHT, CAM_SHOW_WIDTH, CAM_SHOW_HEIGHT, RK_FORMAT_YCrCb_420_SP);
/* alloc cvtcolor show dma buffer */
char *cvtcolor_toshow_buf = nullptr;
int cvtcolor_toshow_dma_fd = 0;
int cvtcolor_toshow_frame_size = CAM_SHOW_WIDTH * CAM_SHOW_HEIGHT * 3;
ret = dma_buf_alloc(DMA_HEAP_PATH, cvtcolor_toshow_frame_size, &cvtcolor_toshow_dma_fd, (void **)&cvtcolor_toshow_buf);
if (ret < 0)
{
printf("alloc cvtcolor to show dma_heap buffer failed! \n");
dma_buf_free(cvtcolor_toshow_frame_size, &cvtcolor_toshow_dma_fd, cvtcolor_toshow_buf);
return -1;
}
printf("alloc dma_heap buffer. fd: %d, cvtcolor_toshow_buf: %p, size: %d \n", cvtcolor_toshow_dma_fd, cvtcolor_toshow_buf, cvtcolor_toshow_frame_size);
rga_buffer_t cvtcolor_toshow_rga_buf = wrapbuffer_fd_t(cvtcolor_toshow_dma_fd, CAM_SHOW_WIDTH, CAM_SHOW_HEIGHT, CAM_SHOW_WIDTH, CAM_SHOW_HEIGHT, RK_FORMAT_BGR_888);
/* create rknn thread */
pthread_t rknn_thread;
ret = pthread_create(&rknn_thread, NULL, rknn_thread_func, NULL);
if (ret < 0)
{
printf("create rknn thread failed! \n");
return -1;
}
pthread_setname_np(rknn_thread, "rknn_thread");
// pthread_detach(rknn_thread);
char rknn_thread_name[16] = {0};
pthread_getname_np(rknn_thread, rknn_thread_name, sizeof(rknn_thread_name));
printf("rknn_thread tid:%ld, name: %s \n",rknn_thread, rknn_thread_name);
struct sched_param sched_param;
sched_param.sched_priority = sched_get_priority_max(SCHED_FIFO);
pthread_setschedparam(rknn_thread, SCHED_FIFO, &sched_param);
/* loop process frame */
printf("process running... \n");
bool grab_frames = true;
memset(fds, 0, sizeof(fds));
fds[0].fd = cam_dev_fd;
fds[0].events = POLLIN;
std::chrono::high_resolution_clock::time_point times[10];
std::chrono::steady_clock::time_point last_time = std::chrono::steady_clock::now();
while (grab_frames)
{
if (1 != poll(fds, 1, 10000))
{
std::cout << "Ignore empty frames from camera." << std::endl;
break;
}
auto current_time = std::chrono::steady_clock::now();
std::chrono::duration<double> elapsed_seconds = current_time - last_time;
last_time = current_time;
float fps = 1.0 / elapsed_seconds.count();
printf("show fps: %.2f \n",fps);
/* dequeue buffer */
struct v4l2_buffer buf;
struct v4l2_plane planes[num_planes];
memset(&buf, 0, sizeof(struct v4l2_buffer));
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
buf.memory = V4L2_MEMORY_DMABUF;
buf.m.planes = planes;
buf.length = num_planes;
if (0 != ioctl(cam_dev_fd, VIDIOC_DQBUF, &buf))
{
printf("Unable to dequeue buffer\n");
break;
}
// convert raw image to npu input image
rga_buffer_t raw_rga_buf = wrapbuffer_fd_t(dmabuf_fds[buf.index], CAM_OUTPUT_WIDTH, CAM_OUTPUT_HEIGHT, CAM_OUTPUT_WIDTH, CAM_OUTPUT_HEIGHT, RK_FORMAT_YCrCb_420_SP);
ret = imresize(raw_rga_buf, resize_tonpu_rga_buf); // resize raw dmabuf to resize buf 640x640
if (ret != IM_STATUS_SUCCESS)
{
printf("resize_tonpu_rga_buf running failed, %s\n", imStrError((IM_STATUS)ret));
break;
}
ret = imcvtcolor(resize_tonpu_rga_buf, input_npu_buf, RK_FORMAT_YCrCb_420_SP, RK_FORMAT_RGB_888); // cvt color nv21 to rgb888
if (ret != IM_STATUS_SUCCESS)
{
printf("cvtcolor input_npu_buf running failed, %s\n", imStrError((IM_STATUS)ret));
break;
}
// 输入NPU图像准备好后,唤醒推理线程
pthread_mutex_lock(&rknn_mutex);
if(rknn_thread_status == RKNN_THREAD_STATUS::IDLE)
{
pthread_cond_signal(&rknn_cond);
rknn_thread_status = RKNN_THREAD_STATUS::READY;
}
pthread_mutex_unlock(&rknn_mutex);
// convert raw image to show image
ret = imresize(raw_rga_buf, resize_toshow_rga_buf); // resize raw dmabuf to resize buf 1280x720
if (ret != IM_STATUS_SUCCESS)
{
printf("resize_toshow_rga_buf running failed, %s\n", imStrError((IM_STATUS)ret));
break;
}
ret = imcvtcolor(resize_toshow_rga_buf, cvtcolor_toshow_rga_buf, RK_FORMAT_YCrCb_420_SP, RK_FORMAT_BGR_888); // cvt color nv21 to BGR888
if (ret != IM_STATUS_SUCCESS)
{
printf("cvtcolor_toshow_rga_buf running failed, %s\n", imStrError((IM_STATUS)ret));
break;
}
/* queue buffer, 此时raw_rga_buf对应的dmabuf_fds[buf.index]已经使用完,结果保存在新内存中。可以立即入队给内核 */
if (0 != ioctl(cam_dev_fd, VIDIOC_QBUF, &buf))
{
printf("Unable to queue buffer");
break;
}
dma_sync_device_to_cpu(cvtcolor_toshow_dma_fd);
cv::Mat show_frame_mat(CAM_SHOW_HEIGHT, CAM_SHOW_WIDTH, CV_8UC3, cvtcolor_toshow_buf);
// Draw Objects
sem_wait(&sem_result_ready);
rknn_thread_status = RKNN_THREAD_STATUS::IDLE; // rknn推理完后,可以立即再次推理,状态置为空闲
char text[256];
for (int i = 0; i < detect_result_group.count; i++)
{
detect_result_t* det_result = &(detect_result_group.results[i]);
sprintf(text, "%s %.1f%%", det_result->name, det_result->prop * 100);
// printf("%s @ (%d %d %d %d) %f\n", det_result->name, det_result->box.left, det_result->box.top, det_result->box.right, det_result->box.bottom, det_result->prop);
int x1 = det_result->box.left;
int y1 = det_result->box.top;
int x2 = det_result->box.right;
int y2 = det_result->box.bottom;
rectangle(show_frame_mat, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(255, 0, 0, 255), 3);
putText(show_frame_mat, text, cv::Point(x1, y1 + 12), cv::FONT_HERSHEY_SIMPLEX, 0.6, cv::Scalar(0, 0, 255), 2);
}
// show img
cv::imshow("img", show_frame_mat);
const int pressed_key = cv::waitKey(1);
if (pressed_key >= 0 && pressed_key != 255)
{
grab_frames = false;
}
}
/* close camera */
if (0 != ioctl(cam_dev_fd, VIDIOC_STREAMOFF, &type))
{
printf("Unable to stop capture\n");
return -1;
}
close(cam_dev_fd);
printf("close camera. \n");
/* free req dma buffer */
for(int i = 0; i < req_buffer.count; i++)
{
printf("free dma buffer. fd: %d, raw_buf: %p, size: %d \n", dmabuf_fds[i], dmabuf_maps[i], fmt.fmt.pix.sizeimage);
dma_buf_free(fmt.fmt.pix.sizeimage, &dmabuf_fds[i], dmabuf_maps[i]);
}
// free dma buffer
printf("free resize_tonpu_dma_buf. fd: %d, raw_buf: %p, size: %d \n", resize_tonpu_dma_fd, resize_tonpu_buf, resize_tonpu_frame_size);
dma_buf_free(resize_tonpu_frame_size, &resize_tonpu_dma_fd, resize_tonpu_buf);
printf("free resize_toshow_dma_buf. fd: %d, raw_buf: %p, size: %d \n", resize_toshow_dma_fd, resize_toshow_buf, resize_toshow_frame_size);
dma_buf_free(resize_toshow_frame_size, &resize_toshow_dma_fd, resize_toshow_buf);
printf("free cvtcolor_toshow_dma_buf. fd: %d, raw_buf: %p, size: %d \n", cvtcolor_toshow_dma_fd, cvtcolor_toshow_buf, cvtcolor_toshow_frame_size);
dma_buf_free(cvtcolor_toshow_frame_size, &cvtcolor_toshow_dma_fd, cvtcolor_toshow_buf);
// destroy rknn thread
pthread_mutex_lock(&rknn_mutex);
rknn_thread_status = RKNN_THREAD_STATUS::EXIT;
pthread_cond_signal(&rknn_cond); // 唤醒线程退出
pthread_mutex_unlock(&rknn_mutex);
pthread_join(rknn_thread, NULL); // 确保推理线程完全退出
printf("destroy rknn thread. \n");
pthread_mutex_destroy(&rknn_mutex);
pthread_cond_destroy(&rknn_cond);
sem_destroy(&sem_result_ready);
printf("process end... \n");
return 0;
}
/*============= 推理线程函数 =============*/
void* rknn_thread_func(void* arg)
{
// if(arg == nullptr)
// {
// printf("rknn_thread_func arg is nullptr. \n");
// pthread_exit(NULL);
// }
/* Create the neural network */
printf("Loading mode...\n");
rknn_context ctx;
int model_data_size = 0;
unsigned char* model_data = load_model(model_filename, &model_data_size);
int ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);
if (ret < 0)
{
printf("rknn_init error ret=%d\n", ret);
pthread_exit(NULL);
}
loadLabelName(labels_filename, labels);
/* Query rknn info */
rknn_sdk_version version;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version));
if (ret < 0)
{
printf("rknn_init error ret=%d\n", ret);
pthread_exit(NULL);
}
printf("sdk version: %s driver version: %s\n", version.api_version, version.drv_version);
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret < 0)
{
printf("rknn_init error ret=%d\n", ret);
pthread_exit(NULL);
}
printf("model input num: %d, output num: %d\n", io_num.n_input, io_num.n_output);
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++)
{
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
if (ret < 0)
{
printf("rknn_init error ret=%d\n", ret);
pthread_exit(NULL);
}
dump_tensor_attr(&(input_attrs[i]));
}
for (int i = 0; i < io_num.n_output; i++)
{
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
dump_tensor_attr(&(output_attrs[i]));
}
input_npu_channel = 3;
input_npu_width = 0;
input_npu_height = 0;
if (input_attrs[0].fmt == RKNN_TENSOR_NCHW)
{
printf("model is NCHW input fmt\n");
input_npu_channel = input_attrs[0].dims[1];
input_npu_height = input_attrs[0].dims[2];
input_npu_width = input_attrs[0].dims[3];
}
else
{
printf("model is NHWC input fmt\n");
input_npu_height = input_attrs[0].dims[1];
input_npu_width = input_attrs[0].dims[2];
input_npu_channel = input_attrs[0].dims[3];
}
printf("model input height=%d, width=%d, channel=%d\n", input_npu_height, input_npu_width, input_npu_channel);
/* alloc input tensor memory */
rknn_tensor_mem* input_mems[1];
input_attrs[0].type = RKNN_TENSOR_UINT8;
input_attrs[0].fmt = RKNN_TENSOR_NHWC;
input_mems[0] = rknn_create_mem(ctx, input_attrs[0].size_with_stride);
printf("rknn create input_mems[0].fd: %d, size: %d \n", input_mems[0]->fd, input_mems[0]->size);
input_npu_buf = wrapbuffer_fd_t(input_mems[0]->fd, NPU_INPUT_WIDTH, NPU_INPUT_HEIGHT, NPU_INPUT_WIDTH, NPU_INPUT_HEIGHT, RK_FORMAT_RGB_888);
/* alloc output tensor memory */
rknn_tensor_mem* output_mems[10] = {0};
for (uint32_t i = 0; i < io_num.n_output; ++i)
{
int output_size = output_attrs[i].n_elems * sizeof(int8_t);
output_mems[i] = rknn_create_mem(ctx, output_size);
printf("rknn create output_mems[%d].fd: %d, size: %d \n", i, output_mems[i]->fd, output_mems[i]->size);
}
/* Set input tensor memory */
ret = rknn_set_io_mem(ctx, input_mems[0], &input_attrs[0]);
if (ret < 0)
{
printf("rknn_set_io_mem fail! ret=%d\n", ret);
pthread_exit(NULL);
}
/* Set output tensor memory */
for (uint32_t i = 0; i < io_num.n_output; ++i)
{
ret = rknn_set_io_mem(ctx, output_mems[i], &output_attrs[i]);
if (ret < 0)
{
printf("rknn_set_io_mem fail! ret=%d\n", ret);
pthread_exit(NULL);
}
}
/* 线程绑定到第6个核上 */
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(6, &cpuset);
ret = sched_setaffinity(0, sizeof(cpuset), &cpuset);
if(ret < 0)
{
printf("sched_setaffinity fail! ret=%d\n", ret);
pthread_exit(NULL);
}
printf("rknn_thread running on CPU %d\n", sched_getcpu());
std::chrono::steady_clock::time_point last_time = std::chrono::steady_clock::now();
while(true)
{
auto current_time = std::chrono::steady_clock::now();
std::chrono::duration<double> elapsed_seconds = current_time - last_time;
last_time = current_time;
float fps = 1.0 / elapsed_seconds.count();
// printf("rknn fps: %.2f \n",fps);
pthread_mutex_lock(&rknn_mutex);
while(rknn_thread_status != RKNN_THREAD_STATUS::READY && rknn_thread_status != RKNN_THREAD_STATUS::EXIT)
{
pthread_cond_wait(&rknn_cond, &rknn_mutex); // 1.调用该函数时会自动释放锁并进入阻塞状态,2.条件变量被唤醒时,重新获得锁,并继续向下执行
}
if (rknn_thread_status == RKNN_THREAD_STATUS::EXIT)
{
printf("rknn_thread exit... \n");
break;
}
// run rknn
rknn_thread_status = RKNN_THREAD_STATUS::PROCESSING;
pthread_mutex_unlock(&rknn_mutex);
ret = rknn_run(ctx, NULL);
if (ret < 0)
{
printf("rknn_run error! ret=%d\n", ret);
pthread_exit(NULL);
}
// post process
float scale_w = (float)input_npu_width / CAM_SHOW_WIDTH;
float scale_h = (float)input_npu_height / CAM_SHOW_HEIGHT;
const float nms_threshold = NMS_THRESH;
const float box_conf_threshold = BOX_THRESH;
std::vector<float> out_scales;
std::vector<int32_t> out_zps;
for (int i = 0; i < io_num.n_output; ++i)
{
out_scales.push_back(output_attrs[i].scale);
out_zps.push_back(output_attrs[i].zp);
}
post_process((int8_t*)output_mems[0]->virt_addr, (int8_t*)output_mems[1]->virt_addr, (int8_t*)output_mems[2]->virt_addr, input_npu_height, input_npu_width,
box_conf_threshold, nms_threshold, scale_w, scale_h, out_zps, out_scales, &detect_result_group, labels);
pthread_mutex_lock(&rknn_mutex);
rknn_thread_status = RKNN_THREAD_STATUS::DONE; // 标记结果已更新
sem_post(&sem_result_ready); // 发送结果就绪信号
pthread_mutex_unlock(&rknn_mutex);
}
// free rknn tensor input and output mem
ret = rknn_destroy_mem(ctx, input_mems[0]);
if (ret < 0)
{
printf("rknn_destroy input_mems fail! ret=%d\n", ret);
}
printf("rknn_destroy input_mems, fd: %d, size: %d \n", input_mems[0]->fd, input_mems[0]->size);
for (uint32_t i = 0; i < io_num.n_output; ++i)
{
ret = rknn_destroy_mem(ctx, output_mems[i]);
if (ret < 0)
{
printf("rknn_destroy output_mems[%d] fail! ret=%d\n", i, ret);
continue;
}
printf("rknn_destroy output_mems[%d],fd: %d, size: %d \n", i, output_mems[i]->fd, output_mems[i]->size);
}
// release rknn
ret = rknn_destroy(ctx);
if (ret < 0)
{
printf("rknn_destroy fail! ret=%d\n", ret);
}
printf("rknn_destroyed. \n");
// free model data and labels
if (model_data)
{
free(model_data);
model_data = nullptr;
printf("free model_data. \n");
}
for (int i = 0; i < OBJ_CLASS_NUM; i++)
{
if (labels[i] != nullptr)
{
free(labels[i]);
labels[i] = nullptr;
}
}
printf("free labels \n");
pthread_exit(NULL);
}```

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)