
FreeRTOS 入门(六):栈的局部变量分配与任务独立栈核心原因
本文通过分析ARM架构下局部变量的存储机制和FreeRTOS任务切换机制,深入探讨了栈在嵌入式系统中的关键作用。第一部分通过反汇编验证了volatile修饰符强制变量入栈的特性,分析了寄存器与栈分配的优先级;第二部分阐述了RTOS中每个任务需要独立栈的原因,解释了任务切换时上下文保存与恢复的完整流程。文章指出栈不仅是存储局部变量的空间,更是实现多任务并发的核心机制,为后续分析FreeRTOS源码奠
目录
- 一、前言
- 二、栈的局部变量分配:volatile 与寄存器 / 栈的关系
- 2.1 基础案例:局部变量的存储差异(寄存器 vs 栈)
- 2.2 变量增多时的栈分配逻辑(寄存器不足场景)
- 三、RTOS 任务为何需要独立栈?(结合任务切换机制)
- 3.1 任务切换的核心需求:现场保存与恢复
- 3.2 独立栈的作用:避免任务上下文混淆
- 四、下一篇预告
- 五、结尾
一、前言
大家好,我是 Hello_Embed。上一篇我们通过函数嵌套调用的反汇编,解决了 “LR/PC 覆盖” 的问题,摸清了栈在函数调用中的基础作用。这一篇,我们聚焦上遗留的两个核心问题:栈到底如何分配局部变量?为什么 FreeRTOS 的每个任务都必须有自己的独立栈?
这两个问题是理解 RTOS 任务管理的关键 —— 局部变量的存储逻辑关系到栈的空间规划,而任务独立栈则是多任务并发执行的 “根基”。我们依然通过 “代码 + 反汇编” 的实证方式,从现象到本质拆解,确保每个结论都有底层依据。
二、栈的局部变量分配:volatile 与寄存器 / 栈的关系
局部变量的存储位置(寄存器或栈),由编译器优化和变量修饰符(如volatile)共同决定。volatile的核心作用是 “禁止编译器优化”,强制变量的读写操作直接作用于内存(栈),而非寄存器 —— 这为我们观察栈的分配逻辑提供了便利。
2.1 基础案例:局部变量的存储差异(寄存器 vs 栈)
先看main函数的代码与对应反汇编对比,直观感受局部变量的存储差异:

代码与反汇编对应分析:
main函数中定义了三个变量:ch=65(无volatile)、i=99(有volatile)、buf=my_malloc(100)(无volatile),反汇编逻辑如下:
- 栈空间初始化:函数入口通过
PUSH {r4-r6, lr}保存寄存器,同时划分出栈空间(保存寄存器的过程本质是占用栈内存); - 无 volatile 变量(ch、buf)→ 存储在寄存器:
ch=65:汇编中直接将 0x41(65)存入寄存器 R5,未操作栈;buf=my_malloc(100):my_malloc返回值存入 R0,随后赋值给 R4(推测 R4 代表 buf),同样未入栈;- 原因:编译器优化策略 —— 寄存器读写速度远快于栈,无
volatile修饰时,优先用寄存器存储变量以提升效率;
- 有 volatile 变量(i)→ 强制存储在栈:
i=99:先将 0x63(99)存入 R0,再通过STR r0, [sp, #0]将 R0 的值写入栈地址sp+0,明确入栈;- 原因:
volatile要求变量的每次读写都对应实际内存操作,避免编译器将其优化到寄存器中(常用于硬件寄存器、多任务共享变量)。
2.2 变量增多时的栈分配逻辑(寄存器不足场景)
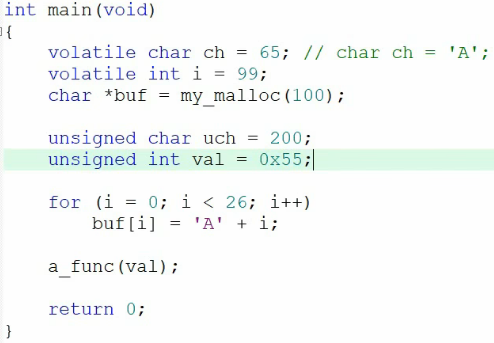
当局部变量数量超过可用寄存器时,即使无volatile修饰,多余变量也会被分配到栈中。我们修改代码:给ch加volatile,新增变量val=0x55,观察反汇编变化。
修改后代码:
对应反汇编代码:

关键变化分析:
- 栈空间扩大:入口指令变为
PUSH {r2-r6, lr},相比之前多保存了 R2 寄存器 —— 意味着栈占用空间增加,为更多局部变量腾出位置; - volatile 变量(ch、i)→ 均入栈:
ch=65:0x41 存入 R0 后,通过STR r0, [sp, #4]写入栈地址sp+4;i=99:0x63 存入 R0 后,通过STR r0, [sp, #0]写入栈地址sp+0;
- 新增变量 val→ 暂存寄存器:
- 反汇编中未直接体现 val 入栈,因其在调用
a_func时作为参数传递 ——ARM 架构下函数前 4 个参数通过 R0~R3 传递,val 被暂存在 R5 中,待调用时传入; - 若后续新增更多变量,R0~R7 寄存器耗尽后,多余变量会自动分配到栈中。
- 反汇编中未直接体现 val 入栈,因其在调用
栈空间分配示意图:
结合反汇编,此时栈中变量的存储位置如下(SP 为栈顶指针,栈从高地址向低地址生长):
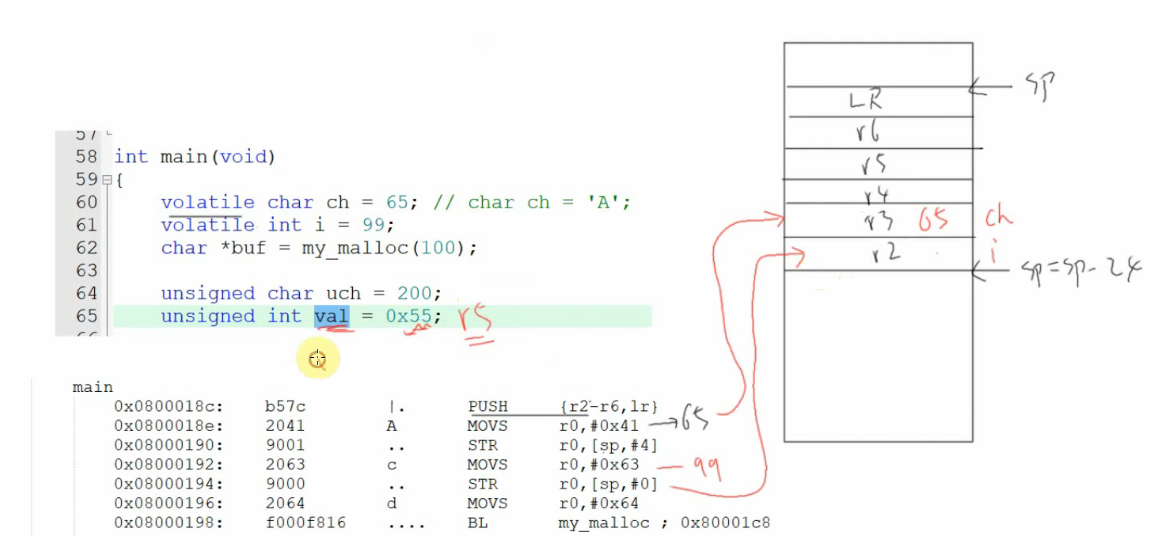
核心结论:
- 局部变量的存储优先级:寄存器(速度快)→ 栈(寄存器不足或有
volatile修饰时); volatile是 “强制入栈” 的开关,用于确保变量与内存的实时同步;- 栈通过
SP指针的偏移(sp+0、sp+4等)管理不同局部变量的存储地址,每个变量占 4 字节(32 位 MCU)。
三、RTOS 任务为何需要独立栈?(结合任务切换机制)
在裸机程序中,所有函数共用一个栈(系统栈),但 FreeRTOS 中每个任务都必须有独立的栈 —— 核心原因是多任务切换时需要保存 / 恢复专属上下文,避免任务间的变量和执行状态相互干扰。
3.1 任务切换的核心需求:现场保存与恢复
我们设计两个结构相似的任务,通过它们的切换逻辑理解独立栈的必要性:
基础函数与任务代码:
// 通用累加函数:接收参数a,加2后返回
int b_func(volatile int a)
{
a += 2;
return a;
}
// 任务A:cnt从0开始,循环调用b_func累加
Task_A()
{
int cnt = 0; // 任务A的局部变量cnt
while(1)
{
cnt = b_func(cnt); // 累加后更新cnt
}
}
// 任务B:cnt从100开始,循环调用b_func累加
Task_B()
{
int cnt = 100; // 任务B的局部变量cnt
while(1)
{
cnt = b_func(cnt); // 累加后更新cnt
}
}
任务切换的核心问题:
FreeRTOS 通过 “定时器中断” 触发任务切换 —— 当任务 A 运行到中途被中断,切换到任务 B 时,必须解决两个问题:
- 任务 A 的执行状态(如
cnt的值、当前执行到的指令地址)如何保存? - 切换回任务 A 时,如何精准恢复这些状态,让 A 从断点继续执行?
答案就是每个任务的独立栈—— 栈是保存任务 “现场(上下文)” 的唯一载体。
3.2 独立栈的作用:避免任务上下文混淆
任务的 “上下文” 包括:所有寄存器的值(R0~R15)、局部变量、函数调用的返回地址(LR)。这些信息都存储在任务的独立栈中,切换流程如下:
1. 任务 A 切换到任务 B:保存 A 的现场
- 定时器中断触发后,CPU 自动进入中断服务函数;
- FreeRTOS 的调度器会执行 “保存现场” 操作:将任务 A 的所有寄存器值(R0~R15、xPSR)通过
PUSH指令存入任务 A 的专属栈; - 记录任务 A 当前的栈顶指针 SP 的值,存入任务 A 的控制结构体(TCB)中;
- 至此,任务 A 的所有状态都被 “冻结” 在自己的栈中,不会被后续操作修改。
2. 恢复任务 B 的现场并执行
- 调度器从任务 B 的 TCB 中取出之前保存的 SP 值,将其赋值给 CPU 的 SP 寄存器;
- 通过
POP指令,从任务 B 的栈中取出所有寄存器值,恢复到 CPU 中; - 其中,PC 寄存器的值被恢复为任务 B 被中断时的指令地址,CPU 继续执行任务 B;
- 任务 B 的局部变量(如
cnt=100)存储在自己的栈中,与任务 A 的栈完全隔离,不会混淆。
3. 再次切换回任务 A:重复 “恢复 - 保存” 流程
- 当任务 B 被中断,调度器会先保存 B 的现场到 B 的栈,再从 A 的 TCB 中取出 SP,恢复 A 的栈内容到 CPU;
- 任务 A 的
cnt值、执行断点等状态完全恢复,就像从未被中断过一样。
核心优势:
- 局部变量隔离:任务 A 和 B 的
cnt都存在各自的栈中,即使变量名和调用的函数相同,也不会相互覆盖; - 执行状态独立:每个任务的上下文保存在专属栈中,切换时通过 SP 精准定位,确保执行流程不中断。
四、下一篇预告
本次我们彻底解答了栈的两个核心问题,搞懂了局部变量的存储逻辑和任务独立栈的必要性 —— 这些都是理解 FreeRTOS 源码的基础。下一篇,我们将正式进入源码层面:
- FreeRTOS 的核心数据结构(任务控制块 TCB 的关键字段);
- 任务创建函数
xTaskCreate的底层实现(如何为任务分配栈和 TCB); - 任务调度器的基本工作原理(如何切换任务上下文)。
五、结尾
本篇笔记的核心,是从 “局部变量存储” 和 “多任务切换” 两个维度,揭开了栈在 RTOS 中的核心价值:它不仅是存储局部变量的 “临时仓库”,更是保存任务上下文的 “状态保险箱”。
理解栈的这些逻辑后,很多 RTOS 开发中的问题会迎刃而解 —— 比如 “任务栈大小设多少合适?”(需覆盖函数嵌套深度 + 局部变量总大小 + 上下文保存所需空间);“任务崩溃可能的原因?”(栈溢出导致上下文被破坏)。
从 ARM 架构基础到堆、栈原理,我们已经为 FreeRTOS 源码学习铺垫了足够的底层知识。接下来,我们将从 “用 RTOS” 过渡到 “懂 RTOS”,深入源码拆解核心机制。我是 Hello_Embed,下一篇源码解析不见不散,一起攻克 FreeRTOS 的核心难点!

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐
 47
47 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)