
OSDDY:基于嵌入式系统、借助深度YOLO算法的小型无人机目标监视检测系统
该结构采用上采样技术,将不需要的光谱图像改进为现有信号,并对特定位置的特征进行重新缩放,这显著增强了小目标的检测能力,实际提升了采样率。作为目标检测系统,其处理架构需将机器视觉算法与合作提示整合到两架多旋翼无人机的飞行测试中,该方法在复杂环境下的目标范围脆弱性检测中兼具精度与鲁棒性。)方法来检测多目标。指出,无人机在民用和军事领域的多种应用中,通过视觉摄像头实现合作目标的帧序列跟踪与检测(基于深度
点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
文章地址:https://link.springer.com/article/10.1186/s13640-021-00559-1
计算机视觉研究院专栏
Column of Computer Vision Institute
计算机视觉是用于目标检测的交叉学科领域。目标检测中继在辅助监控、车辆检测和姿态估计中是至关重要的部分。

PART/1
概述
在本研究中,我们提出了一种新颖的深度你只看一次(深度YOLOV3)方法来检测多目标。该方法在训练和测试阶段会关注整个帧图像,采用基于回归的技术,利用概率模型对目标进行定位。在此过程中,我们构建了106个卷积层,随后是2个全连接层,并使用812×812×3的输入尺寸来检测小型无人机。我们先以一半分辨率对卷积层进行分类预训练,然后将分辨率加倍用于检测。每层的滤波器数量设置为16,最后一个尺度层的滤波器数量超过16,以提升小目标检测性能。该结构采用上采样技术,将不需要的光谱图像改进为现有信号,并对特定位置的特征进行重新缩放,这显著增强了小目标的检测能力,实际提升了采样率。这种YOLO架构之所以被选用,是因为它相比更多滤波器,更注重减少内存资源和计算成本。所提出的系统经过设计和训练,仅针对单一类别“无人机”进行目标检测与跟踪,且基于嵌入式系统的深度YOLO实现了该功能。该YOLO方法能够以更高精度预测每个网格单元的多个边界框。我们使用大量小型无人机在不同场景(如开阔场地和具有复杂背景的海洋环境)中对模型进行了训练。
PART/2
背景
无人机在各个领域的应用日益增多,尤其是在军事和监控领域,用于在特定场景中执行精密任务。实时检测无人机对于安全保障至关重要。如今,在雨天、强光和夜间等各种环境中实现无人机的实时检测仍是一大挑战。深度学习在不同条件下的目标检测中发挥着关键作用。最近,计算机视觉与深度学习方法(如R-CNN、FasterR-CNN和Mask-RCNN)为目标检测提供了解决方案。目标检测与跟踪系统已广泛应用于军事、医疗领域以及配备自主机器人的安全监控场景。传统目标识别主要依赖边缘、切割和模板假设,其准确率较低且误差较大。此外,基于内容的图像检索(CBIR)采用多种特征提取方法,结合滤波技术对检测目标进行处理以确保识别。图像分类器中使用梯度直方图,局部二值模式则通过滑动窗口假设对目标图像进行扫描。机器学习技术借助手工特征(如PASCALVOC目标检测)提升图像精度,但所有这些机制在嵌入式系统的监控场景中进行目标跟踪时仍面临挑战。为克服这些问题,研究人员提出了多种深度学习模型以提高检测精度。R-CNN、FasterR-CNN和Mask-RCNN等深度学习模型不适用于快速检测小目标。本文提出一种新型深度YOLOV3算法用于小目标检测。该方法通过置信度评分、主干分类器和多尺度预测实现小型无人机目标的检测。深度YOLOV3在小型无人机检测中具备以下机制:
本文的贡献如下:
-
提出深度YOLOV3算法,以快速解决小目标检测问题。
-
基于条件概率计算置信度评分,用于检测目标物体的边界框。
-
利用主干分类器和多尺度预测实现目标的高精度分类,提升监控准确性。
-
所提深度YOLOV3模型对小型无人机的检测准确率达99.99%,且误差较低。
基于深度学习的目标检测已实现不同精度水平。SongHan等人指出,低成本航拍虽通过先进无人机获取高亮图像和视频,但易产生误差。他们提出一种基于嵌入式系统框架的深度无人机方案,重点研究无人机视觉与自动跟踪能力。在硬件层面,使用GPU(如NVIDIAGTX980)和嵌入式GPU(如NVIDIATegraK1、TegraX1)进行跟踪与检测,嵌入式配置下帧速率、精度评估和功耗分析显示跟踪速度为1.6fps。Redman等人提出YOLO检测器的新应用,将目标检测与分类转化为边界框回归问题及关联概率计算。有研究提出端到端神经网络用于概率分类分析,而FasterR-CNN则被广泛用于目标检测。
Krizhevsky等人发现深度神经网络在计算机视觉中广泛用于二分类和多图像分类分析,经典网络工具AlexNet包含8层和6000万连接,随后出现VGGNet。Szegedy等人提出GoogleNet,通过CNN支持不同尺度缩放,其卷积层采用1×1、3×3和5×5核级设计,通过多层交叉连接解决梯度问题。He等人提出ResNet提升图像识别精度,通过跨层连接增强绝对值;SqueezeNet应用于CNN,以50倍更少连接实现更高精度。
Henriques等人强调核化相关滤波器(基于DFT)用于图像分类检测,结合快速算法实现对角化变换,在NVIDIATK1套件上使跟踪器达到70帧/秒。SabirHossain等人指出,空中图像的目标检测与跟踪可通过智能传感器和无人机实现,提出基于深度学习的嵌入式框架(如JetsonTX或AGXXavier搭配Intel神经计算棒)。飞行无人机受覆盖范围限制,因此需基于GPU嵌入式计算能力,通过多目标检测算法提升精度。DeepSORT采用卡尔曼滤波假设跟踪,结合多旋翼无人机的关联度量。
RobertoOpromolla指出,无人机在民用和军事领域的多种应用中,通过视觉摄像头实现合作目标的帧序列跟踪与检测(基于深度学习)。YOLO作为目标检测系统,其处理架构需将机器视觉算法与合作提示整合到两架多旋翼无人机的飞行测试中,该方法在复杂环境下的目标范围脆弱性检测中兼具精度与鲁棒性。
ChristosKyrkou等人提出基于深度CNN的单阶段目标检测器权衡机制,无人机在特定环境中检测车辆,CNN为无人机部署提供整体优化方案。空中图像在低功耗嵌入式处理器上以6-19帧/秒运行,精度达95%。Tsung-YiLin等人指出,RetinaNet利用主干网络实现目标检测,支持分类与回归;主干网络结合输入图像的卷积特征,FasterR-CNN则使用特征金字塔网络(FPN),通过金字塔层级的C通道特征映射、A锚框和N目标类的ReLU激活计算目标存在概率。
YiLiu等人强调无人机在电力传输设备检测中的应用,深度学习算法需关注无人机传输控制。MaskR-CNN通过边缘检测、孔洞填充和霍夫变换处理传输设备组件(应用于无线通信),基于无人机传输参数的模型实现100%检测精度。
LIY等人提出多块单阶段多框检测器(SSD)用于无人机铁路轨道监控的小目标检测,将输入图像分割为补丁,通过两阶段子层检测处理截断目标(包含子层抑制和训练样本过滤)。对于主层未检测到的边界框,通过改进SSD显著提升检测率;该深度学习模型还用于滑坡标注及雨天关键通信场景。
Jun-IchiroWatanabe等人将YOLO应用于海洋环境塑料(微塑料与宏塑料)保护,通过卫星遥感技术结合海面目标跟踪器实现全球环境监测。自主机器人用于海洋环境目标观测控制,水下生态系统研究采用深度网络学习算法,YOLOv3应用精度达77.2%。Kaliappan等人提出聚类和遗传算法等机器学习技术实现负载均衡;Vimal等人提出基于机器学习的马尔可夫模型用于认知无线电网络能量优化;Aybora等人模拟YOLOv3目标检测的标注误差,分析训练与测试阶段的错误标注;Sabir等人设计基于GPU的嵌入式飞行机器人,利用深度学习算法实现空中图像的实时多目标检测与跟踪。
PART/3
新算法框架解析
所提模型的目标是通过一种新型YOLOV3模型分析实时环境中的目标检测,并利用边界坐标内的边界框进行运动决策。YOLOv3采用Darknet与残差网络等混合方法,相比YOLOv2具有更优的特征提取能力。图像在边界框层级坐标内完成捕获与分割,在新型YOLOV3模型中,这些坐标以每秒帧间隔映射到框内。该模型应用深度卷积神经网络(DCNN)以实现高精度预测,通过32、64、128、256和1024等不同滤波器尺寸结合步长与填充操作,对帧内像素进行逐像素处理。不同卷积层采用多种尺寸的核化相关滤波器(KCF)方案,通常KCF在视频处理中运行速度极快。CNN层将图像分割为多个区域,基于所有分割区域的置信度分数预测精确的边界框。所提YOLOv3在戴尔EMC工作站上训练,该工作站配置包括:两颗英特尔至强金牌511812核处理器、六通道256GB2666MHzDDR4ECC内存、2×NVIDIAQuadroGV100GPU、4×1TBNVMe40级SSD及1TBSATAHDD。
研究方案
本研究提出一种新型YOLOV3深度学习嵌入式模型,用于实时系统中的小目标检测。YOLO可在单实例中处理整幅图像以预测边界框坐标,并计算所有边界框的类别概率。YOLO每秒可处理45帧图像,本研究采用深度卷积神经网络(DCNN)实现高精度预测。
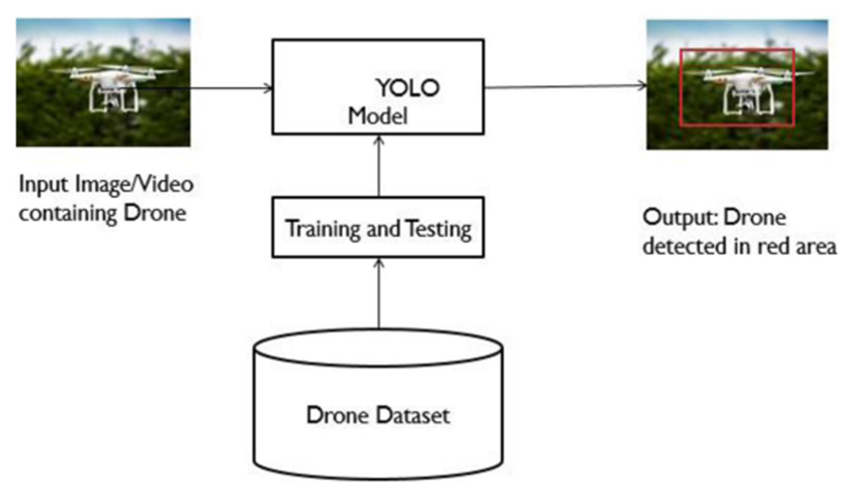
上图展示了用于预测无人机的深度YOLOV3预测模型,标记的输入图像经过45,000轮训练。每个区域为7×7网格,可预测5个边界框,该模型同时可检测无人机目标。所提嵌入式YOLO算法通过回归机制,对单轮处理中的整幅图像预测目标类别及边界框坐标,实现特定目标位置的检测。
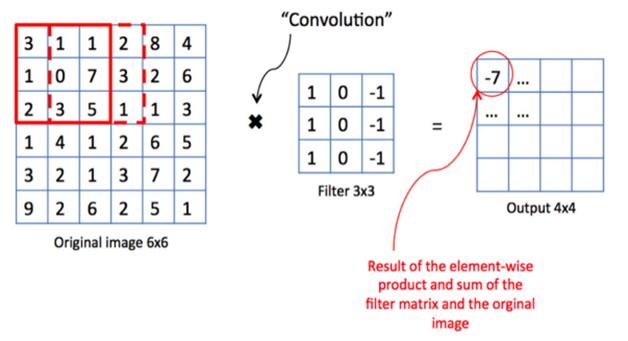
本文设计的深度卷积神经网络(DCNN)包含106个卷积层,集成卷积层、池化层和具备分类功能的全连接层。通过沿输入图像滑动滤波器计算特征图,最终生成二维矩阵。下图展示了卷积层中计算的样本特征图。
PART/4
实验及可视化
本文从Kaggle数据集和谷歌下载了约2GB的3000张无人机图像。在提出的YOLOv3模型中,对无人机数据集进行了45,000轮训练,以实现高准确率和敏感性。图3展示了用于训练和测试的无人机样本图像。本研究采用预训练的YOLOv3模型进行训练,并在基于GPU的工作站上实现了YOLOv3算法。
输入图像通过含106个卷积层的预训练YOLOv3模型进行训练,训练阶段耗时超过8小时构建模型。该训练后的YOLO模型可接收图像或视频输入,在无人机图像/视频检测中达到99.99%的准确率。
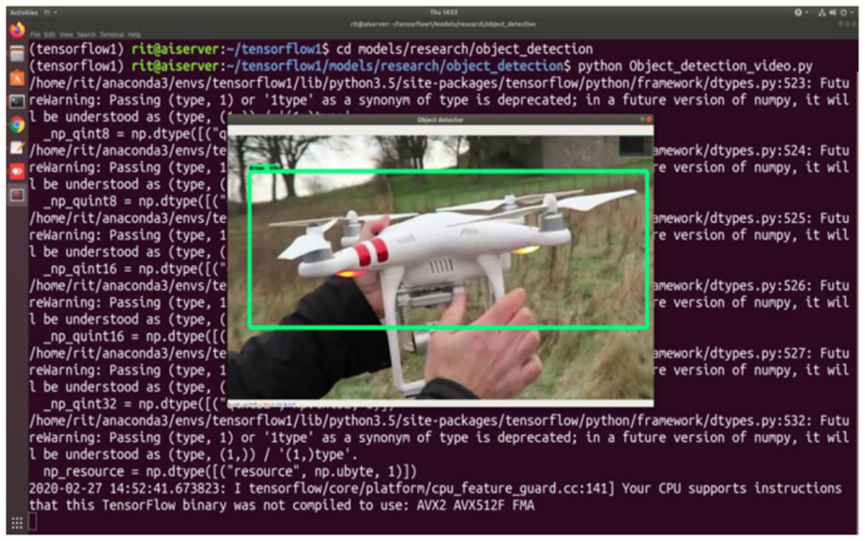
上图展示了测试阶段对无人机视频的检测效果。表1对比了YOLO、YOLOv2和YOLOv3三种模型的准确率:YOLO和YOLOv2适合快速检测大型目标,而本研究提出的YOLOv3架构因采用混合网络结构,更适用于小型目标检测。
所提出的深度YOLOV3模型在训练和测试阶段实现了99.99%的准确率,这得益于其106个卷积层和不同尺寸特征图的设计。研究同时使用YOLOv2模型进行训练和测试,其准确率为98.27%,该模型仅依赖残差网络进行目标检测。此外,YOLOV3模型还基于条件概率设计了置信度评分机制,以有效预测目标物体。
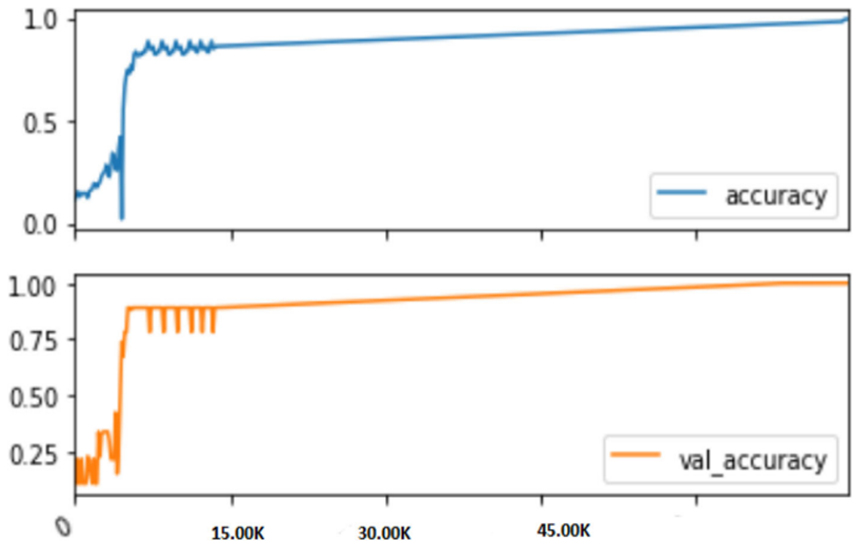
上图显示,该模型在训练周期结束时达到了极高的准确率。所提出的方法还采用主干分类器(backboneclassifier)实现了目标的精准分类。
结论
本研究提出一种新型深度YOLOV3模型用于小目标检测,项目采用预训练YOLOV3结合无人机图像对模型进行训练。仿真结果表明,所提深度YOLOV3模型适用于计算机视觉处理。该模型设计106个卷积层与多尺度特征图,以学习小型无人机目标特征。YOLOv3通过结合Darknet与残差网络实现更优的特征提取能力,经45,000轮训练后达到高检测精度。
该方案利用交并比(IOU)同步预测边界框与网格单元的置信度分数,采用逻辑分类器与二元交叉熵损失函数优化小目标检测。深度YOLOV3通过多尺度预测与主干分类器实现99.99%的检测准确率,各类损失分析表明模型基于条件概率构建了可靠的置信度评分机制,确保目标边界框的精准预测。与YOLO、YOLOv2等旧版本相比,YOLOv3对大型目标的检测适应性较弱。
未来研究可拓展算法,在复杂可见条件与偏远区域场景中,针对海量小型无人机数据进行训练。
有相关需求的你可以联系我们!


END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
往期推荐
🔗

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)