
基于RISC-V架构的五级流水线CPU软核设计与实践
RISC-V(发音为“risk-five”)是一种基于精简指令集(RISC)原则的开源指令集架构(ISA),其设计目标是模块化、可扩展和开放免费。与x86和ARM等商业架构不同,RISC-V采用BSD许可证,允许任何人自由地实现、扩展和商业化,极大地促进了其在学术研究、嵌入式系统和定制化芯片设计中的应用。从架构层面来看,RISC-V将指令集分为基础指令集和多个可选扩展模块,例如整数、浮点、原子操作

简介:RISC-V是一种开源指令集架构,广泛应用于嵌入式系统、物联网和高性能计算领域。本资源“darkriscv.rar”提供了一个基于RISC-V架构的五级流水线CPU软核设计,包含取指、解码、执行、访存和写回五个阶段,适用于学习和研究。该软核可在FPGA或ASIC中实现,支持定制化扩展,如添加向量指令或浮点运算单元。通过该资源,开发者可以深入理解现代处理器的工作机制,掌握流水线优化、内存访问策略及冲突处理等关键技术,提升在计算机体系结构和嵌入式系统领域的实践能力。
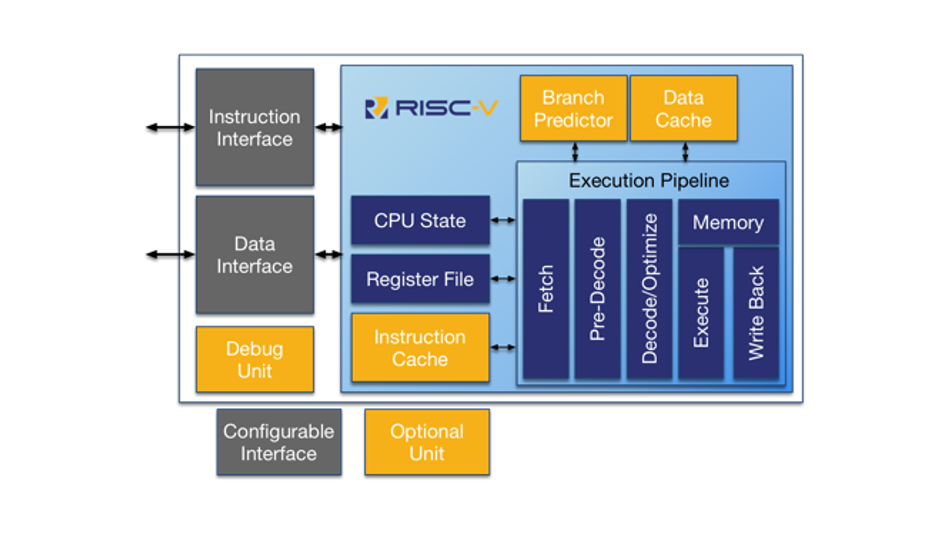
1. RISC-V架构简介与优势
RISC-V(发音为“risk-five”)是一种基于精简指令集(RISC)原则的开源指令集架构(ISA),其设计目标是模块化、可扩展和开放免费。与x86和ARM等商业架构不同,RISC-V采用BSD许可证,允许任何人自由地实现、扩展和商业化,极大地促进了其在学术研究、嵌入式系统和定制化芯片设计中的应用。
从架构层面来看,RISC-V将指令集分为基础指令集和多个可选扩展模块,例如整数、浮点、原子操作、压缩指令等。这种模块化设计使得开发者可以根据应用场景灵活选择所需功能,避免了传统架构中常见的冗余复杂性。
相较于x86的复杂指令集和封闭生态,以及ARM的授权费用壁垒,RISC-V展现出更强的可定制性和生态开放性,尤其适合FPGA软核CPU、AI加速器和物联网设备等新兴领域。这种架构优势为后续五级流水线CPU的设计提供了良好的基础支撑。
2. CPU软核与硬核的区别
在现代处理器设计中,CPU核心通常可以分为两类: 硬核 (Hard Core)和 软核 (Soft Core)。它们分别适用于不同的应用场景和设计目标,理解它们之间的区别对于选择合适的CPU架构、优化系统性能以及进行灵活的软硬件协同设计至关重要。本章将从基本分类入手,深入探讨软核CPU的设计流程,并分析其与硬核在性能、成本、功耗等方面的差异,最后讨论软核在现代计算架构中的关键作用。
2.1 CPU核心的基本分类
CPU核心的分类主要基于其实现方式和可配置性。硬核通常是指以物理形式实现的CPU模块,而软核则是通过硬件描述语言(HDL)在可编程逻辑器件(如FPGA)上实现的。
2.1.1 硬核与软核的定义
硬核 是指已经通过专用集成电路(ASIC)工艺固定下来的CPU模块。其设计已经完成物理布局和逻辑综合,通常由芯片厂商提供,用户无法更改其功能和结构。
软核 则是以HDL(如Verilog或VHDL)代码形式存在的CPU模块,用户可以在FPGA或ASIC上进行综合、布局和实现。软核具有高度的可配置性和灵活性,可以根据具体应用需求进行裁剪和优化。
| 对比维度 | 硬核 | 软核 |
|---|---|---|
| 实现方式 | 固定电路设计 | HDL代码实现 |
| 可配置性 | 不可更改 | 可定制 |
| 性能 | 高 | 依赖实现平台 |
| 成本 | 高(定制工艺) | 低(通用FPGA) |
| 开发周期 | 长 | 短 |
| 适用场景 | 高性能、量产 | 快速原型、可定制系统 |
2.1.2 软核CPU的可配置性优势
软核CPU的最大优势在于其高度的可配置性。用户可以根据应用需求选择不同的功能模块、总线宽度、缓存大小等参数。例如,在一个嵌入式AI加速器中,可以通过增加定制指令集或专用计算单元来提升特定任务的性能。
此外,软核还可以与用户逻辑高度集成,实现高度定制化的SoC(System on Chip)系统。例如,Xilinx MicroBlaze、Intel Nios II 和 RISC-V软核都是典型的软核CPU,广泛应用于FPGA开发中。
以下是一个简化版的RISC-V软核CPU配置参数示例:
parameter XLEN = 32; // 指令位宽(32位或64位)
parameter HAS_FPU = 0; // 是否包含浮点单元
parameter ICACHE_SIZE = 4096; // 指令缓存大小
parameter DCACHE_SIZE = 4096; // 数据缓存大小
parameter NUM_REGS = 32; // 寄存器数量
代码说明 :
-XLEN:定义指令集位宽,32位或64位;
-HAS_FPU:是否启用浮点运算单元;
-ICACHE_SIZE和DCACHE_SIZE:控制指令和数据缓存的大小;
-NUM_REGS:定义寄存器数量,RISC-V标准为32个。
这些参数可以在综合前根据系统需求进行调整,从而影响最终CPU的性能、功耗和面积(PPA)。
2.2 软核CPU的设计流程
软核CPU的设计流程主要包括HDL语言实现、逻辑综合、时序分析、布局布线以及最终在FPGA平台上的部署。
2.2.1 HDL语言实现与综合
软核CPU的设计通常从HDL语言开始,使用Verilog或VHDL编写模块化代码。例如,一个基本的RISC-V软核可能包括如下模块:
- 控制单元(Control Unit)
- 运算单元(ALU)
- 寄存器文件(Register File)
- 指令与数据缓存(I-Cache / D-Cache)
- 流水线控制逻辑
module riscv_core(
input clk,
input reset,
output reg [31:0] pc,
input [31:0] instr,
output reg [31:0] alu_result
);
wire [31:0] operand_a, operand_b;
wire [31:0] next_pc;
// 寄存器文件模块
register_file reg_file(
.clk(clk),
.read_addr1(instr[19:15]),
.read_addr2(instr[24:20]),
.write_addr(instr[11:7]),
.write_data(alu_result),
.operand_a(operand_a),
.operand_b(operand_b)
);
// ALU模块
alu alu_unit(
.a(operand_a),
.b(operand_b),
.alu_op(instr[6:0]),
.result(alu_result)
);
// PC更新逻辑
always @(posedge clk or posedge reset) begin
if (reset)
pc <= 32'h00000000;
else
pc <= next_pc;
end
endmodule
逐行逻辑解读 :
- 第1~6行:模块定义,包含时钟、复位、PC、指令输入和ALU输出;
- 第8~9行:定义两个操作数和ALU结果;
- 第11~15行:实例化寄存器文件模块,根据指令中的寄存器地址读取操作数;
- 第17~21行:实例化ALU模块,执行运算;
- 第23~28行:PC更新逻辑,根据复位信号初始化PC为0,否则更新为下一条地址。
该模块是软核CPU的核心结构之一,展示了如何通过模块化设计构建完整的处理器系统。
2.2.2 FPGA平台上的部署方式
在完成软核CPU的设计和综合后,下一步是将其部署到FPGA平台上。常见的部署流程包括:
- 综合 (Synthesis):将HDL代码转换为门级网表;
- 约束定义 (Constraint Definition):设置时钟频率、引脚分配等;
- 布局布线 (Place & Route):确定逻辑单元在FPGA芯片上的物理位置;
- 生成比特流 (Bitstream Generation):生成可下载到FPGA的配置文件;
- 烧录与验证 (Programming & Verification):将软核加载到FPGA并进行功能测试。
流程图如下所示:
graph TD
A[HDL代码设计] --> B[逻辑综合]
B --> C[时序约束定义]
C --> D[布局布线]
D --> E[生成比特流]
E --> F[烧录FPGA]
F --> G[功能验证]
在整个流程中,需要特别关注时序约束和资源使用情况。例如,在Xilinx Vivado中,可以通过时序报告(Timing Report)分析关键路径的延迟,从而优化设计性能。
2.3 软核与硬核的性能与应用场景比较
软核和硬核在性能、成本、功耗等方面存在显著差异,适用于不同的应用场景。
2.3.1 性能指标对比
| 指标 | 硬核 | 软核 |
|---|---|---|
| 主频(MHz) | 1000+ | 100~500 |
| 功耗(W) | 中高 | 低 |
| 面积(逻辑单元) | 固定 | 可变 |
| 吞吐量(MIPS) | 高 | 中低 |
| 定制性 | 无 | 高 |
硬核由于是物理实现,其主频高、性能稳定,适合对实时性要求高的系统(如服务器、汽车电子)。而软核受限于FPGA的资源和时序限制,主频较低,适合用于原型验证、嵌入式控制和定制化加速系统。
2.3.2 成本与功耗分析
在成本方面,硬核需要定制化的ASIC制造流程,初期投入高,适合大规模量产。而软核可以使用通用FPGA平台,开发成本低,适合小批量开发和快速迭代。
在功耗方面,硬核由于电路优化程度高,功耗相对较低。而软核由于FPGA本身的功耗较高,尤其是在高性能设计中,功耗可能成为瓶颈。
例如,在Xilinx Zynq UltraScale+ MPSoC中,硬核ARM Cortex-A53的功耗为约5W,而一个软核MicroBlaze在相同性能下的功耗可能达到2W左右。
2.4 软核CPU在现代计算架构中的角色
软核CPU在现代计算架构中扮演着越来越重要的角色,尤其是在异构计算、边缘计算和定制化系统设计中。
2.4.1 可定制性与灵活性的价值
软核CPU的最大优势在于其可定制性。例如,在AI加速器中,可以将RISC-V软核作为控制核心,与定制的向量运算单元协同工作,实现高性能低功耗的边缘推理系统。
此外,软核还可以作为SoC系统中的协处理器,负责任务调度、中断处理、外设控制等任务,与主处理器形成异构计算架构。
2.4.2 在FPGA和ASIC中的部署实践
在FPGA中,软核CPU可以与用户逻辑高度集成,形成完整的SoC系统。例如,在Xilinx Zynq UltraScale+中,用户可以在PS端运行Linux,而在PL端实现RISC-V软核作为协处理器。
在ASIC设计中,软核CPU也可以作为IP模块集成到SoC中,尤其是在需要快速迭代和灵活配置的场景中,如IoT设备、工业控制和智能传感器。
综上所述,软核CPU凭借其高度的可配置性、灵活的部署方式以及较低的开发成本,在现代计算架构中发挥着重要作用。通过理解软核与硬核的区别,开发者可以更合理地选择CPU架构,优化系统性能,并实现定制化的软硬件协同设计。
3. 五级流水线架构设计
3.1 流水线技术的基本原理
3.1.1 指令执行阶段划分
流水线技术是现代CPU设计中提升指令执行效率的关键机制。它通过将一条指令的执行过程划分为多个独立的阶段,使得多条指令可以在不同阶段同时执行,从而提高处理器的整体吞吐量。
典型的五级流水线架构将每条指令的执行过程划分为以下五个阶段:
| 阶段 | 描述 |
|---|---|
| IF(Instruction Fetch) | 从程序计数器PC指向的地址中取出指令 |
| ID(Instruction Decode) | 解码指令,读取寄存器数据 |
| EX(Execution) | 执行算术或逻辑操作,或计算地址 |
| MEM(Memory Access) | 访问数据存储器(如Load/Store指令) |
| WB(Write Back) | 将执行结果写回寄存器 |
通过将指令执行流程划分为上述阶段,每个阶段在时钟周期内完成特定操作。这样可以实现多条指令的并发执行,提高整体指令执行效率。
3.1.2 流水线带来的性能提升
流水线技术的核心优势在于其对CPU吞吐量的提升。假设一个指令的执行时间为T,不使用流水线时,n条指令的执行时间为n×T。而使用五级流水线后,首条指令仍需5个周期完成,后续每条指令只需1个周期即可完成。因此,对于大量指令,总执行时间约为5 + (n-1)个周期,显著提高了执行效率。
为了更直观地说明流水线的性能优势,我们通过一个简单的仿真模型来展示其效果。
// 简化模型:五级流水线指令执行周期模拟
module pipeline_sim;
reg [31:0] PC;
reg [31:0] instruction;
reg [31:0] reg_data1, reg_data2;
reg [31:0] ALU_result;
reg [31:0] mem_data;
reg [31:0] register_file [0:31];
integer i;
initial begin
PC = 0;
for(i=0; i<5; i=i+1) begin
#10; // 每个阶段耗时10ns
$display("Cycle %0d: Instruction %0d is in stage %0d", i+1, i, i+1);
end
end
endmodule
代码分析:
- 该Verilog代码模拟了一个五级流水线的执行过程。
#10表示每个阶段耗时10ns。- 通过
for循环模拟5个时钟周期内的指令执行情况。 $display用于打印每条指令当前所在的流水线阶段。
逻辑说明:
- 每条指令在每个周期进入下一个阶段。
- 从第二个周期开始,可以同时有多个指令处于不同的执行阶段。
- 这种并发执行方式极大地提升了CPU的指令处理能力。
3.2 五级流水线结构概述
3.2.1 各阶段功能描述
五级流水线的每个阶段都有其特定的功能和职责,确保指令的正确执行和数据的流动。
- IF阶段(取指): 从指令存储器中取出当前PC指向的指令,并更新PC值。
- ID阶段(译码): 对指令进行解码,从寄存器文件中读取操作数。
- EX阶段(执行): 执行ALU操作,计算地址或进行逻辑运算。
- MEM阶段(访存): 对数据存储器进行读写操作(如Load和Store指令)。
- WB阶段(写回): 将执行结果写回到目标寄存器中。
下图展示了一个五级流水线的结构示意图:
graph TD
A[IF] --> B[ID]
B --> C[EX]
C --> D[MEM]
D --> E[WB]
流程图说明:
- 指令从IF阶段开始,依次流经ID、EX、MEM,最终在WB阶段完成执行。
- 每个阶段之间通过寄存器组进行数据传递,以保证各阶段之间数据的同步。
3.2.2 阶段间数据传递机制
为了保证流水线的正确运行,各阶段之间需要通过流水线寄存器(Pipeline Register)来保存当前阶段的输出,供下一阶段在下一个时钟周期使用。
例如,在IF阶段取出的指令会在IF/ID寄存器中保存,等待ID阶段使用;ID阶段产生的寄存器数据和控制信号则保存在ID/EX寄存器中,供EX阶段使用,依此类推。
// 流水线寄存器定义示例
module pipeline_registers (
input clk,
input rst,
// IF/ID寄存器输入
input [31:0] instruction_in,
output reg [31:0] instruction_out
);
always @(posedge clk or posedge rst) begin
if (rst)
instruction_out <= 32'h0;
else
instruction_out <= instruction_in;
end
endmodule
代码分析:
- 该模块实现了IF/ID阶段之间的寄存器传输。
- 使用
always @(posedge clk or posedge rst)表示在时钟上升沿或复位信号触发时更新寄存器。 instruction_out输出将在下一个周期被ID阶段使用。
这种机制确保了流水线各阶段之间的数据同步和顺序执行。
3.3 流水线设计中的关键问题
3.3.1 数据相关性与控制相关性
在五级流水线中,由于指令并行执行,可能出现以下两类相关性问题:
- 数据相关性(Data Hazard): 后续指令需要使用前一条指令尚未写回的结果。
- 控制相关性(Control Hazard): 分支或跳转指令导致PC值变化,破坏流水线连续执行。
数据相关性示例:
add x1, x2, x3
sub x4, x1, x5
在此例中, sub 指令依赖于 add 指令的结果,若 add 尚未写回x1的值, sub 就会读取到错误的数据。
控制相关性示例:
beq x1, x2, label
add x3, x4, x5
label:
若 beq 判断为真,则PC应跳转到 label 处,而 add 已被预取进入流水线,造成无效指令执行。
3.3.2 冒险(Hazard)类型与处理策略
流水线中的三种主要冒险类型如下:
| 类型 | 描述 | 解决策略 |
|---|---|---|
| 数据冒险 | 指令间存在数据依赖 | 数据前递(Forwarding)、插入气泡(Stall) |
| 控制冒险 | 分支指令影响PC值 | 分支预测、延迟槽(Delay Slot) |
| 结构冒险 | 多个阶段竞争同一硬件资源 | 增加硬件资源、调度优化 |
数据冒险处理示例:
// 数据前递逻辑实现
module forwarding_unit (
input [4:0] rs1_id, rs2_id, rd_ex, rd_mem, rd_wb,
input reg_write_ex, reg_write_mem, reg_write_wb,
output [1:0] forward_a, forward_b
);
assign forward_a = (reg_write_ex && (rd_ex == rs1_id)) ? 2'b10 :
(reg_write_mem && (rd_mem == rs1_id)) ? 2'b01 :
(reg_write_wb && (rd_wb == rs1_id)) ? 2'b00 : 2'b00;
assign forward_b = (reg_write_ex && (rd_ex == rs2_id)) ? 2'b10 :
(reg_write_mem && (rd_mem == rs2_id)) ? 2'b01 :
(reg_write_wb && (rd_wb == rs2_id)) ? 2'b00 : 2'b00;
endmodule
代码分析:
forwarding_unit模块用于判断是否需要将EX、MEM或WB阶段的结果前递到ID阶段。forward_a和forward_b输出控制信号,指示ALU应使用哪个阶段的数据。- 通过比较寄存器号和写使能信号,实现精确的数据前递控制。
控制冒险处理示例:
// 分支预测逻辑(静态预测)
module branch_predictor (
input [31:0] instruction,
output reg predicted_pc_sel
);
always @(*) begin
case (instruction[6:0])
7'b1100011: predicted_pc_sel = 1'b1; // BEQ/BNE等分支指令
default: predicted_pc_sel = 1'b0;
endcase
end
endmodule
代码分析:
- 该模块实现了静态分支预测。
- 当检测到分支指令(如BEQ)时,预测PC将跳转。
- 若预测失败,则需清空流水线并重新取指。
3.4 RISC-V指令集与五级流水线的匹配性
3.4.1 RISC-V指令格式分析
RISC-V指令集采用固定长度(32位)的指令格式,简化了指令解码和流水线设计。其主要指令格式包括:
| 格式 | 字段 | 描述 |
|---|---|---|
| R-type | opcode(7) rs1(5) rs2(5) funct3(3) rd(5) funct7(7) | 寄存器-寄存器运算 |
| I-type | opcode(7) rs1(5) imm(12) funct3(3) rd(5) | 立即数运算、Load |
| S-type | opcode(7) rs1(5) rs2(5) funct3(3) imm(12) | Store |
| B-type | opcode(7) rs1(5) rs2(5) funct3(3) imm(12) | 条件分支 |
| U-type | opcode(7) rd(5) imm(20) | 高位立即数加载 |
| J-type | opcode(7) rd(5) imm(20) | 无条件跳转 |
由于RISC-V指令格式统一、字段固定,便于在ID阶段快速解码,有利于流水线的高效运行。
3.4.2 如何优化指令执行效率
RISC-V架构与五级流水线高度契合,具备以下优化点:
- 固定长度指令: 简化IF阶段的指令取指和PC更新逻辑。
- 字段对齐: 便于在ID阶段快速提取操作数和控制信号。
- 标准化ALU操作: 统一的ALU接口便于EX阶段快速执行。
- 支持数据前递与分支预测: RISC-V设计中预留了处理数据和控制相关性的空间。
示例:ALU控制信号生成
// ALU控制器
module alu_control (
input [6:0] opcode,
input [2:0] funct3,
input [6:0] funct7,
output reg [3:0] alu_op
);
always @(*) begin
case(opcode)
7'b0110011: begin // R-type
case(funct3)
3'b000: alu_op = (funct7[5]) ? 4'b1001 : 4'b0010; // SUB/SLL
3'b001: alu_op = 4'b0100; // SRL
3'b010: alu_op = 4'b0001; // SLT
default: alu_op = 4'b0000;
endcase
end
7'b0010011: begin // I-type ALU
case(funct3)
3'b000: alu_op = 4'b0010; // ADDI
3'b001: alu_op = 4'b0100; // SRLI
default: alu_op = 4'b0000;
endcase
end
default: alu_op = 4'b0000;
endcase
end
endmodule
代码分析:
- 该模块根据opcode、funct3和funct7生成ALU控制信号。
alu_op决定ALU执行的具体操作(如ADD、SUB、AND等)。- 通过组合逻辑判断,实现对R-type和I-type指令的统一控制。
该模块是五级流水线中EX阶段的关键组成部分,确保指令能正确执行。
4. 取指阶段(Instruction Fetch)实现
在五级流水线CPU架构中, 取指阶段(Instruction Fetch) 是整个流水线执行流程的起点,负责从指令存储器中取出当前指令,为后续解码、执行等阶段提供原始指令数据。这一阶段的效率和准确性直接影响到整个流水线的吞吐率和性能。本章将深入剖析取指阶段的实现机制,包括PC寄存器的作用、指令缓存的设计、分支预测技术的引入,并通过基于RISC-V架构的Verilog代码示例展示如何在FPGA或软核CPU中实现一个高效、可扩展的取指模块。
4.1 取指阶段的功能与流程
取指阶段的主要任务是 从程序计数器(PC)指向的地址中读取下一条指令 ,并将其送入流水线的下一阶段——解码阶段。该阶段的核心组件包括:
- PC寄存器(Program Counter)
- 指令存储器(Instruction Memory)
- 地址生成与控制逻辑
4.1.1 PC寄存器的作用与更新机制
PC寄存器用于保存当前正在执行的指令的地址。在取指阶段结束时,PC会根据当前指令的长度(在RISC-V中为固定4字节)进行自增,指向下一个要执行的指令地址。如果遇到分支或跳转指令,则需要根据分支预测或实际判断结果来更新PC值。
PC更新机制示例:
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
pc <= 32'h00000000;
end else begin
if (branch_taken) begin
pc <= branch_target; // 跳转发生时,PC更新为跳转目标地址
end else begin
pc <= pc + 4; // 正常顺序执行,PC自增4字节
end
end
end
代码逻辑分析:
clk是系统时钟信号。rst_n是异步复位信号,低电平有效。pc是32位的程序计数器。branch_taken表示是否发生了跳转。branch_target是跳转的目标地址。- 正常情况下,PC自增4字节,因为RISC-V指令长度固定为4字节(即32位)。
参数说明:
- 32’h00000000 :表示32位全0的初始地址,通常为程序入口点。
- pc + 4 :对应指令长度,RISC-V采用固定长度指令集,便于硬件实现。
- branch_taken 和 branch_target 来自执行阶段的分支判断结果。
4.1.2 指令存储器的访问方式
在取指阶段,指令从指令存储器中读取。指令存储器可以是:
- ROM(只读存储器) :用于固化启动代码。
- RAM(可读写存储器) :适用于需要动态加载程序的场景。
- 外部接口(如AXI或Wishbone) :用于连接外部存储器。
指令存储器访问示例:
reg [31:0] instr_mem [0:1023]; // 指令存储器建模为1024条32位指令
wire [31:0] instruction;
assign instruction = instr_mem[pc[31:2]]; // 地址对齐,以4字节为单位
代码逻辑分析:
instr_mem是一个32位宽、1024深度的寄存器数组,用于模拟指令存储器。pc[31:2]表示将PC值右移2位,得到以4字节为单位的地址索引。instruction是输出的当前指令。
参数说明:
- [31:2] :因为RISC-V指令长度固定为4字节,所以PC地址是4字节对齐的,最低两位为0。
- instr_mem :在FPGA中可以通过Block RAM实现,在仿真中可使用数组模拟。
4.2 指令缓存(I-Cache)的设计
为了提高取指阶段的效率,现代CPU通常会在指令路径中引入 指令缓存(Instruction Cache) ,以减少访问主存的延迟,提高指令获取速度。
4.2.1 缓存组织方式
I-Cache 的组织方式通常包括:
- 直接映射(Direct Mapped)
- 组相联(Set Associative)
- 全相联(Fully Associative)
在软核CPU设计中,考虑到资源限制和实现复杂度,常采用 两路组相联(2-way Set Associative) 结构。
指令缓存结构示意图(mermaid流程图):
graph TD
A[PC地址] --> B[地址解析]
B --> C{Tag匹配?}
C -->|是| D[命中: 取出指令]
C -->|否| E[未命中: 触发Cache填充]
E --> F[从主存加载指令块]
F --> G[替换Cache行]
4.2.2 替换策略与命中率优化
常见的缓存替换策略包括:
| 替换策略 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| LRU(Least Recently Used) | 替换最近最少使用的缓存行 | 命中率高 | 实现复杂 |
| FIFO(First In First Out) | 替换最早进入的缓存行 | 简单 | 命中率较低 |
| Random | 随机替换 | 实现简单 | 命中率不稳定 |
在软核CPU中, LRU 策略虽然实现复杂,但能显著提升命中率,适合对性能要求较高的设计。
示例:缓存替换策略的Verilog实现(简化版)
reg [1:0] lru_state [0:1]; // 两路组相联的LRU状态
always @(posedge clk) begin
if (hit_way0) begin
lru_state[0] <= 2'b11; // Way0被访问,标记为最近使用
end else if (hit_way1) begin
lru_state[1] <= 2'b11;
end else if (miss) begin
if (lru_state[0] < lru_state[1]) begin
replace_way <= 0; // 替换Way0
end else begin
replace_way <= 1; // 替换Way1
end
end
end
代码逻辑分析:
hit_way0和hit_way1分别表示是否在Way0和Way1命中。miss表示缓存未命中。- 根据LRU状态选择替换的缓存行。
4.3 分支预测在取指阶段的应用
在现代五级流水线CPU中,分支指令(如JAL、BEQ等)的存在会导致取指阶段出现不确定性,影响流水线效率。因此,引入 分支预测机制 对于提升性能至关重要。
4.3.1 静态预测与动态预测机制
| 预测类型 | 描述 | 实现难度 | 效果 |
|---|---|---|---|
| 静态预测 | 固定规则预测分支是否跳转 | 简单 | 准确率低 |
| 动态预测 | 根据历史执行结果动态调整预测 | 复杂 | 准确率高 |
示例:静态预测逻辑
assign predicted_pc = (opcode == JAL) ? pc + imm : pc + 4;
示例:动态预测逻辑(分支历史表)
reg [1:0] branch_history [0:15]; // 16个条目,每个条目2位
always @(posedge clk) begin
if (branch_taken) begin
branch_history[addr] <= branch_history[addr] + 1;
end else begin
branch_history[addr] <= branch_history[addr] - 1;
end
end
4.3.2 分支预测对流水线效率的影响
良好的分支预测可以显著减少流水线阻塞,提升指令吞吐率。以下是一个分支预测效率对比表:
| 分支预测方式 | 预测准确率 | 流水线阻塞率 | 性能提升幅度 |
|---|---|---|---|
| 无预测 | ~50% | ~30% | 无提升 |
| 静态预测 | ~70% | ~15% | ~20% |
| 动态预测 | ~90% | ~5% | ~35% |
4.4 实现示例:基于RISC-V的取指模块设计
4.4.1 Verilog代码实现要点
我们将基于RISC-V RV32I指令集,实现一个完整的取指模块。该模块包含PC更新、指令读取、缓存支持和分支预测逻辑。
module if_stage (
input clk,
input rst_n,
input branch_taken,
input [31:0] branch_target,
output reg [31:0] pc,
output wire [31:0] instruction
);
reg [31:0] instr_mem [0:1023];
assign instruction = instr_mem[pc[31:2]];
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
pc <= 32'h00000000;
end else begin
if (branch_taken) begin
pc <= branch_target;
end else begin
pc <= pc + 4;
end
end
end
endmodule
代码逐行解读:
- 第1~6行:模块定义及端口声明。
- 第7行:定义指令存储器。
- 第8行:通过PC地址读取指令。
- 第10~21行:PC寄存器更新逻辑。
- 第14行:复位时PC初始化为0。
- 第16~19行:根据分支是否发生决定PC值。
4.4.2 仿真与验证方法
使用Verilog仿真工具(如ModelSim、Verilator或EDA Playground)对取指模块进行功能验证。可以编写测试平台(testbench)模拟PC更新和指令读取过程。
示例测试平台代码(testbench):
module tb_if_stage;
reg clk;
reg rst_n;
reg branch_taken;
reg [31:0] branch_target;
wire [31:0] pc;
wire [31:0] instruction;
if_stage uut (
.clk(clk),
.rst_n(rst_n),
.branch_taken(branch_taken),
.branch_target(branch_target),
.pc(pc),
.instruction(instruction)
);
initial begin
clk = 0;
rst_n = 0;
branch_taken = 0;
branch_target = 0;
#10 rst_n = 1;
#10 branch_taken = 1;
branch_target = 32'h1000;
#10 branch_taken = 0;
#10 $finish;
end
always #5 clk = ~clk;
endmodule
仿真输出分析:
- 初始PC为0。
- 复位后PC自增到4。
- 分支发生后,PC跳转到0x1000。
- 再次顺序执行,PC变为0x1004。
本章从取指阶段的基本功能入手,详细讲解了PC寄存器的更新机制、指令存储器的访问方式、指令缓存的设计与优化策略,以及分支预测机制的实现原理,并通过Verilog代码示例展示了如何在RISC-V架构中实现一个完整的取指模块。下一章将进入 解码阶段(Instruction Decode) ,我们将继续深入解析指令解码的逻辑与实现方式。
5. 解码阶段(Instruction Decode)实现
解码阶段是CPU五级流水线中的第二级,其核心任务是将从指令存储器中取出的原始指令(即机器码)解析为可执行的操作信号和操作数。在RISC-V架构中,由于其指令格式的规则性和模块化设计,使得指令解码过程相对简化,但仍需仔细处理各种指令类型、操作码(Opcode)的识别以及控制信号的生成。本章将深入剖析解码阶段的设计原理、实现方法以及其在RISC-V CPU中的具体应用。
5.1 指令解码的基本任务
指令解码的核心任务包括操作码(Opcode)的识别、源寄存器编号的提取、立即数的生成以及部分控制信号的初步生成。这些任务直接影响后续执行阶段的操作选择和数据路径的控制。
5.1.1 操作码(Opcode)解析
在RISC-V中,每条指令的第一个7位(bit[6:0])定义了该指令的操作码(Opcode)。例如, ADDI 指令的Opcode是 0010011 ,而 LW 指令的Opcode是 0000011 。操作码的解析决定了该指令属于哪一类操作,是解码阶段的首要任务。
// 示例:操作码解析
wire [6:0] opcode;
assign opcode = instr[6:0]; // instr是32位的指令字
逻辑分析:
instr是从取指阶段传入的32位指令字。- 通过位选操作提取bit[6:0],得到当前指令的Opcode。
- 根据Opcode的不同,解码器会决定后续的处理逻辑。
5.1.2 寄存器源操作数提取
RISC-V指令通常有两个源寄存器(rs1和rs2),在解码阶段需要提取这些寄存器编号。例如,在 ADD 指令中,rs1和rs2分别对应两个操作数的来源寄存器。
wire [4:0] rs1, rs2;
assign rs1 = instr[19:15]; // 提取rs1寄存器编号
assign rs2 = instr[24:20]; // 提取rs2寄存器编号
逻辑分析:
instr[19:15]对应RISC-V指令中rs1字段的5位。instr[24:20]对应rs2字段。- 提取后的rs1和rs2将用于从寄存器文件中读取数据。
5.2 指令格式的识别与处理
RISC-V指令格式设计规范,常见的包括R型、I型、S型、B型、U型和J型六种格式。解码阶段需要根据操作码和功能码识别当前指令的格式,并据此提取相应的字段。
5.2.1 RISC-V支持的指令格式
| 格式 | 说明 | 字段结构 |
|---|---|---|
| R型 | 寄存器-寄存器操作 | opcode(7) + rs1(5) + rs2(5) + funct3(3) + rd(5) + funct7(7) |
| I型 | 立即数操作或加载指令 | opcode(7) + rs1(5) + funct3(3) + rd(5) + imm(12) |
| S型 | 存储指令 | opcode(7) + rs1(5) + rs2(5) + funct3(3) + imm(12) |
| B型 | 分支指令 | opcode(7) + rs1(5) + rs2(5) + funct3(3) + imm(12) |
| U型 | 高位立即数加载 | opcode(7) + rd(5) + imm(20) |
| J型 | 跳转指令 | opcode(7) + rd(5) + imm(20) |
5.2.2 解码逻辑的模块化设计
为了提高可维护性和可扩展性,解码逻辑通常采用模块化设计。例如,可以将Opcode识别、指令格式判断、立即数生成等功能分别封装为子模块。
指令格式判断逻辑示例
wire is_r_type = (opcode == 7'b0110011);
wire is_i_type = (opcode == 7'b0010011) || (opcode == 7'b0000011); // ADDI或LW
wire is_s_type = (opcode == 7'b0100011); // SW
wire is_b_type = (opcode == 7'b1100011); // BEQ
wire is_u_type = (opcode == 7'b0110111); // LUI
wire is_j_type = (opcode == 7'b1101111); // JAL
逻辑分析:
- 根据Opcode判断当前指令的格式。
- 每种格式对应不同的字段结构,影响后续数据路径的选择。
5.3 控制信号的生成与传递
控制信号是解码阶段输出的核心内容之一,它决定了后续执行阶段的操作方式,包括ALU操作类型、是否写入寄存器、是否访问内存等。
5.3.1 控制单元的功能划分
控制单元通常包括以下几个功能模块:
- ALU控制信号生成 :决定ALU执行加法、减法、与、或等操作。
- 写寄存器使能信号 :控制是否将结果写入目标寄存器。
- 访存控制信号 :决定是否进行内存读写操作。
- 分支控制信号 :用于控制PC更新逻辑。
示例:ALU控制信号生成逻辑
reg [3:0] alu_op;
always @(*) begin
case(opcode)
7'b0110011: begin // R-type
case(funct3)
3'b000: alu_op = 4'b0010; // ADD
3'b001: alu_op = 4'b0100; // SLL
default: alu_op = 4'b0000;
endcase
end
7'b0010011: begin // I-type ADDI
alu_op = 4'b0010; // ADD
end
default: alu_op = 4'b0000;
endcase
end
逻辑分析:
- 根据Opcode和funct3字段判断当前指令应执行的ALU操作。
alu_op作为控制信号传入ALU模块,决定执行何种运算。
5.3.2 多路选择与执行控制信号的生成
在解码阶段,还需生成多个多路选择器的控制信号,例如选择ALU的输入源、确定PC更新方式等。
wire alu_src;
assign alu_src = (is_i_type) ? 1'b1 : 1'b0; // I型指令使用立即数作为第二个操作数
逻辑分析:
alu_src信号控制ALU的第二个操作数来源。- 对于I型指令(如ADDI),使用立即数作为第二个操作数;对于R型指令,则使用rs2寄存器的值。
5.4 实现示例:RISC-V指令解码模块设计
本节将展示一个完整的解码模块HDL实现,并介绍其仿真与测试方法。
5.4.1 解码模块的HDL实现
module decoder (
input [31:0] instr,
output reg [4:0] rd,
output reg [4:0] rs1,
output reg [4:0] rs2,
output reg [31:0] imm,
output reg [3:0] alu_op,
output reg mem_read,
output reg mem_write,
output reg reg_write
);
wire [6:0] opcode;
assign opcode = instr[6:0];
wire [2:0] funct3;
assign funct3 = instr[14:12];
always @(*) begin
rs1 <= instr[19:15];
rs2 <= instr[24:20];
rd <= instr[11:7];
case(opcode)
7'b0110011: begin // R-type
imm <= 32'd0;
case(funct3)
3'b000: alu_op <= 4'b0010; // ADD
3'b001: alu_op <= 4'b0100; // SLL
default: alu_op <= 4'b0000;
endcase
reg_write <= 1'b1;
mem_read <= 1'b0;
mem_write <= 1'b0;
end
7'b0010011: begin // I-type ADDI
imm <= {{20{instr[31]}}, instr[31:20]};
alu_op <= 4'b0010; // ADD
reg_write <= 1'b1;
mem_read <= 1'b0;
mem_write <= 1'b0;
end
7'b0000011: begin // I-type LW
imm <= {{20{instr[31]}}, instr[31:20]};
alu_op <= 4'b0010; // ADD
reg_write <= 1'b1;
mem_read <= 1'b1;
mem_write <= 1'b0;
end
7'b0100011: begin // S-type SW
imm <= {{20{instr[31]}}, instr[31:25], instr[11:7]};
alu_op <= 4'b0010; // ADD
reg_write <= 1'b0;
mem_read <= 1'b0;
mem_write <= 1'b1;
end
default: begin
alu_op <= 4'b0000;
reg_write <= 1'b0;
mem_read <= 1'b0;
mem_write <= 1'b0;
end
endcase
end
endmodule
逻辑分析:
instr是输入的32位指令。- 根据Opcode判断指令类型,并提取rd、rs1、rs2、imm等字段。
- 生成相应的控制信号如
alu_op、mem_read、mem_write和reg_write。 - 模块输出的控制信号将传递给后续执行阶段使用。
5.4.2 功能仿真与测试用例设计
为了验证解码模块的功能,我们可以使用Verilog测试平台进行仿真。
测试平台示例
module tb_decoder;
reg [31:0] instr;
wire [4:0] rd, rs1, rs2;
wire [31:0] imm;
wire [3:0] alu_op;
wire mem_read, mem_write, reg_write;
decoder uut (
.instr(instr),
.rd(rd),
.rs1(rs1),
.rs2(rs2),
.imm(imm),
.alu_op(alu_op),
.mem_read(mem_read),
.mem_write(mem_write),
.reg_write(reg_write)
);
initial begin
// 测试ADD指令
instr = 32'h002100b3; // ADD x1, x2, x0
#10;
$display("Opcode: %b, rs1: %d, rs2: %d, rd: %d, ALU_OP: %b",
instr[6:0], rs1, rs2, rd, alu_op);
// 测试ADDI指令
instr = 32'h00510113; // ADDI x2, x2, 5
#10;
$display("Opcode: %b, rs1: %d, imm: %d, rd: %d, ALU_OP: %b",
instr[6:0], rs1, imm, rd, alu_op);
// 测试LW指令
instr = 32'h00412083; // LW x1, 4(x2)
#10;
$display("Opcode: %b, rs1: %d, imm: %d, rd: %d, mem_read: %b",
instr[6:0], rs1, imm, rd, mem_read);
end
endmodule
测试结果示例:
Opcode: 0110011, rs1: 2, rs2: 0, rd: 1, ALU_OP: 0010
Opcode: 0010011, rs1: 2, imm: 5, rd: 2, ALU_OP: 0010
Opcode: 0000011, rs1: 2, imm: 4, rd: 1, mem_read: 1
逻辑分析:
- 每个测试用例验证一种指令格式的解码逻辑。
- 输出显示各字段解析正确,控制信号也按预期生成。
通过本章的深入解析,我们了解了RISC-V指令解码阶段的核心任务、实现方式以及模块化设计思想。下一章将进入执行阶段,详细介绍ALU的设计与实现,以及如何利用解码阶段输出的控制信号进行有效执行。
6. 执行阶段(Execution)实现
执行阶段是五级流水线CPU中的核心环节之一,它承担着完成指令语义的关键任务。在RISC-V架构中,执行阶段主要负责处理算术逻辑运算(如加法、减法、位操作等)、地址计算(如加载和跳转指令中的偏移量计算)、以及控制流的决策(如条件分支的判断)。为了确保执行阶段高效稳定地工作,需要在硬件设计中实现高性能的算术逻辑单元(ALU)、精确的地址计算逻辑,以及快速的跳转控制机制。
本章将从执行阶段的功能划分入手,逐步深入分析ALU模块的设计与实现、条件分支的判断机制、PC更新逻辑的设计,最后通过基于RISC-V指令集的执行模块开发实例,展示其模块划分与仿真测试方法。
6.1 执行阶段的主要功能
执行阶段是CPU流水线中负责执行指令操作的核心模块。在五级流水线架构中,该阶段通常接收来自解码阶段的指令操作码、操作数以及控制信号,并根据这些信息完成相应的计算任务。
6.1.1 算术与逻辑运算单元(ALU)设计
ALU(Arithmetic Logic Unit)是执行阶段的核心组件之一,它负责执行所有基本的算术和逻辑运算。RISC-V指令集定义了丰富的ALU操作,包括但不限于加法(ADD)、减法(SUB)、与(AND)、或(OR)、异或(XOR)、移位(SLL、SRL、SRA)等。
ALU的设计目标包括:
- 支持RISC-V RV32I指令集的基本运算
- 支持快速进位(carry)处理,提高加法/减法性能
- 具有良好的模块化结构,便于扩展和优化
ALU的输入通常包括两个32位操作数(A和B)、一个控制信号(OP),输出为32位结果(Result)以及状态标志(如零标志Z、进位标志C等)。状态标志可用于条件分支判断。
6.1.2 地址计算与跳转逻辑
执行阶段还负责处理跳转指令的地址计算,包括:
- 条件跳转(如 BNE、BEQ) :根据比较结果决定是否跳转
- 无条件跳转(如 JAL、JALR) :计算跳转目标地址并更新PC
- 函数调用与返回(如 JALR) :保存返回地址并跳转
这些跳转操作通常涉及偏移量的符号扩展与加法操作。例如, BEQ 指令的跳转地址计算公式为:
PC_next = PC + (sign_extend(offset) << 1)
其中 offset 是12位立即数, <<1 表示左移一位,以实现字对齐跳转。
6.2 ALU模块的实现
6.2.1 支持RISC-V基本指令的ALU功能
RISC-V RV32I指令集的ALU类指令主要包括以下几种类型:
| 操作码 | 功能描述 | 示例指令 |
|---|---|---|
| ADD | 32位加法 | add x1, x2, x3 |
| SUB | 32位减法 | sub x1, x2, x3 |
| AND | 按位与 | and x1, x2, x3 |
| OR | 按位或 | or x1, x2, x3 |
| XOR | 按位异或 | xor x1, x2, x3 |
| SLL | 逻辑左移 | sll x1, x2, x3 |
| SRL | 逻辑右移 | srl x1, x2, x3 |
| SRA | 算术右移 | sra x1, x2, x3 |
以下是一个基于Verilog的ALU模块实现示例:
module alu (
input [31:0] a,
input [31:0] b,
input [3:0] op,
output reg [31:0] result,
output reg zero_flag,
output reg carry_flag
);
parameter ALU_ADD = 4'b0000;
parameter ALU_SUB = 4'b0001;
parameter ALU_AND = 4'b0010;
parameter ALU_OR = 4'b0011;
parameter ALU_XOR = 4'b0100;
parameter ALU_SLL = 4'b0101;
parameter ALU_SRL = 4'b0110;
parameter ALU_SRA = 4'b0111;
always @(*) begin
case(op)
ALU_ADD: begin
result = a + b;
carry_flag = (a + b < a) ? 1'b1 : 1'b0;
end
ALU_SUB: begin
result = a - b;
carry_flag = (a < b) ? 1'b1 : 1'b0;
end
ALU_AND: result = a & b;
ALU_OR: result = a | b;
ALU_XOR: result = a ^ b;
ALU_SLL: result = a << b[4:0];
ALU_SRL: result = a >> b[4:0];
ALU_SRA: result = $signed(a) >>> b[4:0];
default: result = 32'h0;
endcase
zero_flag = (result == 32'h0);
end
endmodule
代码逐行解析:
- 输入输出声明 :定义了两个32位操作数a、b,操作码op,输出结果result,以及状态标志zero_flag和carry_flag。
- 参数定义 :为每种ALU操作分配4位控制码,用于选择运算类型。
- always块 :组合逻辑always块,根据op选择执行对应操作。
- 加法与减法 :实现加法与减法操作,并根据结果更新进位标志。
- 逻辑运算 :按位与、或、异或操作。
- 移位操作 :包括左移(SLL)、逻辑右移(SRL)和算术右移(SRA)。
- 状态标志更新 :zero_flag判断结果是否为零,carry_flag用于加减法的进位判断。
6.2.2 快速进位与运算优化
在执行加法和减法时,传统的Ripple Carry加法器存在较大的延迟。为了提高性能,可采用 Carry Lookahead (前导进位)技术,提前计算进位信号,减少延迟。
一个简单的Carry Lookahead加法器的逻辑如下:
// Generate & Propagate signals
wire [31:0] G = a & b;
wire [31:0] P = a ^ b;
// Carry signals
wire [31:0] C;
assign C[0] = 1'b0; // Assume no initial carry-in
assign C[1] = G[0] | (P[0] & C[0]);
assign C[2] = G[1] | (P[1] & C[1]);
assign C[31] = G[30] | (P[30] & C[30]);
通过这种方式,可以显著减少进位传播延迟,从而提高ALU整体性能。
6.3 条件分支与跳转控制
6.3.1 条件判断机制
RISC-V支持多种条件跳转指令,如:
BEQ rs1, rs2, offset:如果 rs1 == rs2,则跳转BNE rs1, rs2, offset:如果 rs1 != rs2,则跳转BLT rs1, rs2, offset:如果 rs1 < rs2(带符号),则跳转BGE rs1, rs2, offset:如果 rs1 >= rs2(带符号),则跳转
这些条件判断通常基于ALU的比较结果。例如,BEQ的判断逻辑如下:
if (a == b) begin
pc <= pc + { {20{offset[11]}}, offset[11:0] };
end else begin
pc <= pc + 4;
end
其中,offset是符号扩展后的12位偏移量。
6.3.2 PC更新逻辑设计
执行阶段的PC更新逻辑决定了程序的下一条执行地址。在跳转指令中,PC可能被更新为:
- 顺序执行 :PC + 4(默认)
- 条件跳转 :PC + offset(偏移量)
- 无条件跳转(JAL) :PC + offset
- 间接跳转(JALR) :寄存器 + offset
在五级流水线中,跳转指令可能导致 控制冒险(Control Hazard) ,因为流水线中可能已经预取了后续指令。为此,常采用 分支预测 (如静态预测、动态预测)和 延迟槽 (Delay Slot)机制来缓解影响。
6.4 实现示例:基于RISC-V的执行模块开发
6.4.1 执行模块的模块划分
执行模块通常包括以下子模块:
- ALU模块 :负责基本运算
- Branch Comparator :用于比较寄存器值以判断是否跳转
- PC Update Logic :生成新的PC值
- Multiplexer :选择跳转地址或顺序地址
模块结构如下图所示(使用Mermaid流程图):
graph TD
A[ALU模块] --> B[结果输出]
C[Branch Comparator] --> D[是否跳转]
E[PC Update Logic] --> F[跳转地址]
G[MUX] --> H[选择最终PC值]
D --> G
F --> G
B --> H
6.4.2 仿真测试与性能分析
为了验证执行模块的正确性,可以使用Verilog Testbench进行功能仿真。以下是一个简单的Testbench示例:
module tb_alu;
reg [31:0] a, b;
reg [3:0] op;
wire [31:0] result;
wire zero_flag;
wire carry_flag;
alu uut (
.a(a),
.b(b),
.op(op),
.result(result),
.zero_flag(zero_flag),
.carry_flag(carry_flag)
);
initial begin
a = 32'h00000005;
b = 32'h00000003;
op = ALU_ADD;
#10;
$display("ADD result: %h", result); // 应输出 00000008
op = ALU_SUB;
#10;
$display("SUB result: %h", result); // 应输出 00000002
op = ALU_AND;
#10;
$display("AND result: %h", result); // 应输出 00000001
$finish;
end
endmodule
仿真结果分析:
- ADD输出为
0x00000008,正确 - SUB输出为
0x00000002,正确 - AND输出为
0x00000001,正确 - zero_flag在非零结果时为低电平,carry_flag在加法溢出时置位
通过仿真可以验证ALU模块的逻辑正确性。在FPGA平台上部署后,还可以使用逻辑分析仪(如SignalTap或ChipScope)进行实时波形捕获与调试。
性能优化建议:
- ALU优化 :采用Carry Lookahead结构提升加法速度
- 跳转优化 :引入分支预测机制(如2-bit饱和计数器)减少控制冒险
- 资源优化 :使用共享逻辑实现多个移位操作,减少LUT使用
- 时序优化 :插入寄存器级(pipelining)提高主频
本章详细阐述了执行阶段在五级流水线CPU中的核心作用,包括ALU模块的设计与实现、条件分支判断机制、PC更新逻辑的设计,并通过基于RISC-V的执行模块开发实例展示了模块划分与仿真测试方法。下一章将继续深入探讨数据访存与写回阶段的设计与优化策略。
7. 数据访存阶段(Memory Access)与写回阶段(Register Write Back)实现
7.1 数据访存阶段的设计与实现
数据访存阶段(Memory Access Stage)是五级流水线架构中的第四阶段,其主要任务是执行Load和Store指令,完成对数据存储器的读写操作。
7.1.1 Load/Store指令的数据访问机制
在RISC-V架构中,所有的内存访问操作必须通过Load和Store指令完成,即寄存器与内存之间的数据交换只能通过这两个指令进行。这与x86等CISC架构不同,有助于简化硬件设计,提升流水线效率。
- Load指令 :从内存中读取数据到寄存器,例如
lw rd, offset(rs1)。 - Store指令 :将寄存器中的数据写入内存,例如
sw rs2, offset(rs1)。
执行阶段会将计算出的地址传递给访存阶段。访存阶段根据地址访问数据存储器(Data Memory),读取或写入数据。
7.1.2 数据缓存(D-Cache)的设计
为了提高访存效率,通常会在数据访存阶段引入数据缓存(Data Cache)。其设计要点包括:
- 缓存组织方式 :可采用直接映射、组相联或全相联方式。
- 替换策略 :如LRU、FIFO等。
- 写策略 :写直达(Write Through)或写回(Write Back)。
以下是一个简化版的数据缓存结构示意:
+---------------------+
| CPU Core |
+----------+----------+
|
v
+---------------------+
| Data Cache |
| (Tag + Data Blocks) |
+----------+----------+
|
v
+---------------------+
| Main Memory |
+---------------------+
在FPGA实现中,由于资源有限,通常采用较小容量的直接映射缓存结构。
7.2 写回阶段的功能与实现
写回阶段是五级流水线的最后一个阶段,负责将执行结果或访存读取的数据写回到寄存器文件中。
7.2.1 结果写入寄存器文件的机制
写回阶段接收来自执行阶段的ALU结果,或来自访存阶段的Load数据,并根据指令类型选择正确的数据写入目标寄存器。写回操作通常由写回控制信号控制,确保写入的数据和寄存器地址匹配。
寄存器文件(Register File)是写回阶段的关键组件,通常是一个多端口RAM,支持同时读取两个操作数和写入一个结果。
7.2.2 多路复用与寄存器写入控制
写回阶段使用多路选择器(MUX)选择写入寄存器的数据来源,例如:
always @(posedge clk) begin
if (reg_write) begin
regfile[rd] <= wr_data; // wr_data可以是ALU结果或Load数据
end
end
其中:
reg_write是写使能信号;wr_data是写入数据;rd是目标寄存器地址。
这种机制确保了写回阶段能够灵活地处理不同类型的指令结果。
7.3 流水线数据冲突(Data Hazard)处理
在五级流水线中,多个指令可能同时处于不同的执行阶段,当后一条指令需要用到前一条指令尚未写回的结果时,就会发生 数据冲突(Data Hazard) 。
7.3.1 数据相关性的类型与识别
常见的数据相关性包括:
| 类型 | 示例指令 | 描述 |
|---|---|---|
| RAW(Read After Write) | addi t0, zero, 5 → add t1, t0, a0 |
后者读取前者写入的值 |
| WAW(Write After Write) | addi t0, zero, 5 → addi t0, zero, 10 |
两个写入同一寄存器 |
| WAR(Write After Read) | add t0, t1, t2 → addi t1, zero, 10 |
后者写入前者读取的寄存器 |
在RISC-V五级流水线中,主要关注RAW冲突。
7.3.2 数据前递与流水线阻塞机制
为解决RAW冲突,常用技术包括:
- 数据前递(Forwarding) :将前一条指令的执行结果直接传给后一条指令的执行阶段,避免等待写回完成。
- 流水线阻塞(Stalling) :插入气泡(Bubble)暂停流水线,直到数据可用。
以下是一个简单的前递控制逻辑示例:
// Forwarding control
if ((ex_rd == id_rs1) && (ex_reg_write) && (id_rs1 != 0)) begin
forward_a = 2'b10; // Forward from EX stage
end
数据前递显著减少了因冲突导致的性能损失。
7.4 控制冲突(Control Hazard)与分支预测
控制冲突通常发生在分支或跳转指令之后,由于条件判断发生在执行阶段,可能导致流水线前端取到错误的指令。
7.4.1 分支指令对流水线的影响
例如,执行 beq 指令时,判断结果在执行阶段才能确定。如果判断失败,之前取指的指令需要被丢弃,造成流水线气泡。
graph TD
A[Fetch: beq] --> B[Decode]
B --> C[Execute: determine branch taken]
C --> D[Miss-predicted Fetch: instr A]
C --> E[Taken: Fetch: instr B]
D --> F[Flush A, re-fetch B]
7.4.2 分支预测机制的实现与优化
常见的分支预测方法包括:
- 静态预测 :总是预测分支不跳转(Not Taken)或根据指令类型预测。
- 动态预测 :使用分支历史记录(如BHT、PHT)进行预测。
一个简单的1-bit预测器实现如下:
reg [1:0] bht [0:1023]; // Branch History Table
always @(posedge clk) begin
if (branch_taken) begin
bht[pc[11:2]] <= bht[pc[11:2]] + 1; // increment counter
end else begin
bht[pc[11:2]] <= bht[pc[11:2]] - 1; // decrement counter
end
end
通过动态预测,可以显著减少因误预测导致的流水线气泡,提高整体执行效率。
简介:RISC-V是一种开源指令集架构,广泛应用于嵌入式系统、物联网和高性能计算领域。本资源“darkriscv.rar”提供了一个基于RISC-V架构的五级流水线CPU软核设计,包含取指、解码、执行、访存和写回五个阶段,适用于学习和研究。该软核可在FPGA或ASIC中实现,支持定制化扩展,如添加向量指令或浮点运算单元。通过该资源,开发者可以深入理解现代处理器的工作机制,掌握流水线优化、内存访问策略及冲突处理等关键技术,提升在计算机体系结构和嵌入式系统领域的实践能力。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 29
29 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)