
周志华《机器学习导论》第11章 特征选择与稀疏学习
本文基于周志华院士《机器学习导论》第11章,系统综述特征选择与稀疏学习的主要方法。首先阐述特征子集的搜索策略与信息增益等评价准则;进而对比三类特征选择方法:过滤式(如Relief)、包裹式(如LVW)及嵌入式(如L1正则化);随后讨论稀疏表示与字典学习(K-SVD算法),说明如何通过字典构造获得数据的稀疏编码;最后介绍压缩感知理论,阐明如何利用信号稀疏性从欠采样数据中精确重构原信号,并关联至矩阵补
目录
2.1 过滤式选择 filter + Relief(不管学习器 先筛一下)
2.2 包裹式选择 wrapper + LVW(为学习器量身定做)
2.3 嵌入式选择 embedding + L1正则化(稀疏解相当于筛选)
1. 子集搜索与评价(怎么选特征子集 好子集的指标)
维度灾难 选择与当前学习任务比较相关的特征 进行训练
冗余特征:比如已知立方体的长宽高 底面积就是冗余特征 可以由其他特征得到
但可能会降低学习任务的难度 比如用表面积和高 能够更好的学习体积
如何选择特征子集(本身NP-hard),评价特征子集的好坏?
贪心式的双端“子集搜索” 从空集开始加 加入后使得总体效果最好的特征;也可以删最无关的特征
Beyond Greedy 可以使用启发式算法 如遗传算法。
“子集评价”选择与问题关系大 对分类帮助大的特征 用信息增益 可参考决策树那部分
信息增益Gain (A) 越大,意味着特征子集A 包含的有助于分类的信息越多
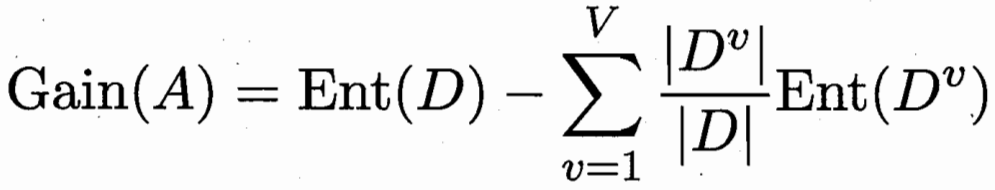
2. 三种特征选择方法
2.1 过滤式选择 filter + Relief(不管学习器 先筛一下)
先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关
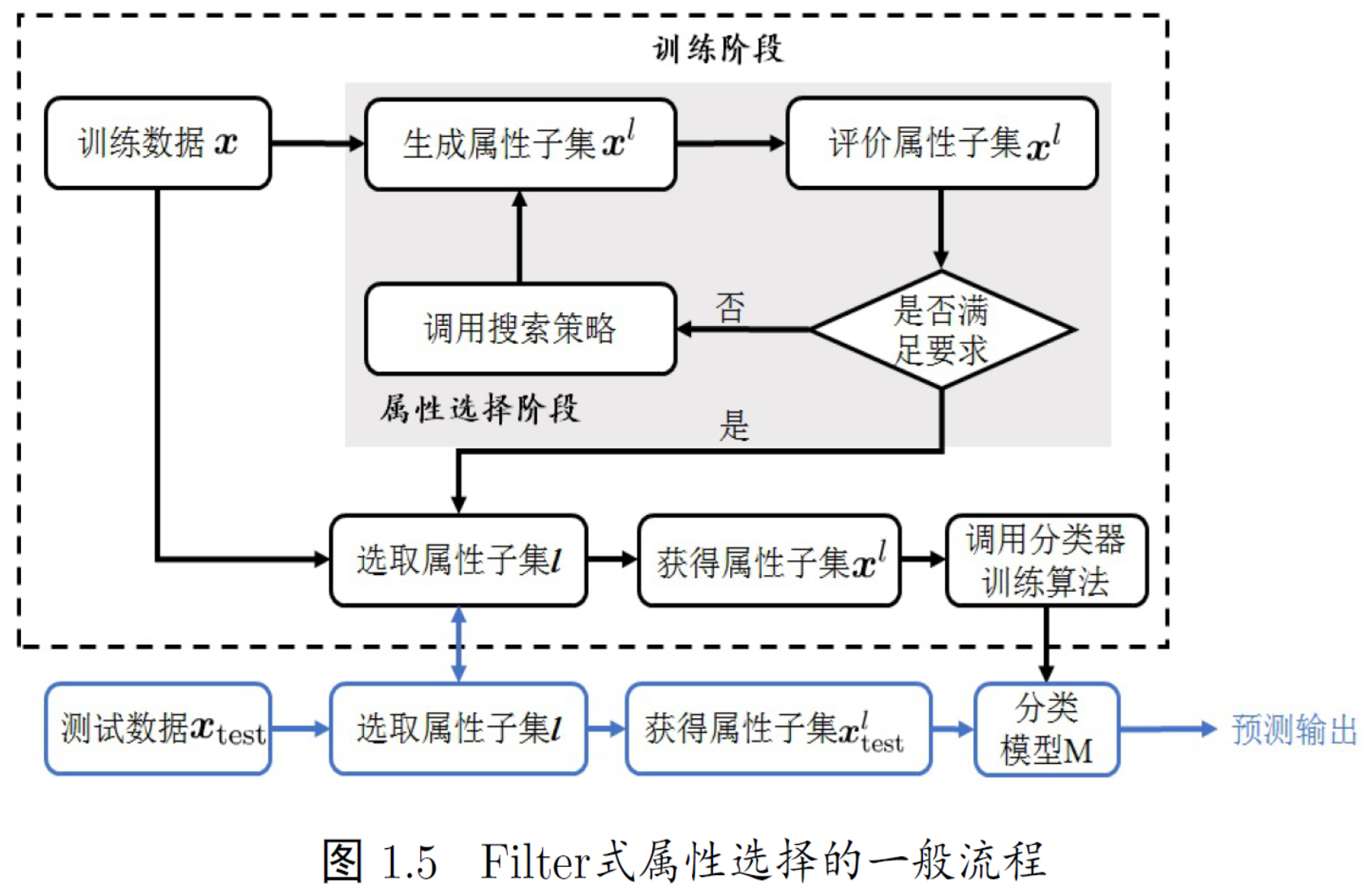
Relief (Relevant Features) 对每个特征计算相关统计量 选择值最大的几个
先在其同类样本中寻找最近邻 xi,nh,称为 “猜中近邻”(near-hit)
再在其异类样本中寻找最近邻 xi,nm,称为 “猜错近邻”(near-miss)
对于样本xi,属性j 的相关统计量(区分能力) 猜错间距 - 猜中间距

多分类问题变形为 Relief-F; 多种类 对每个类找猜错近邻 按种类样本数目权重放缩
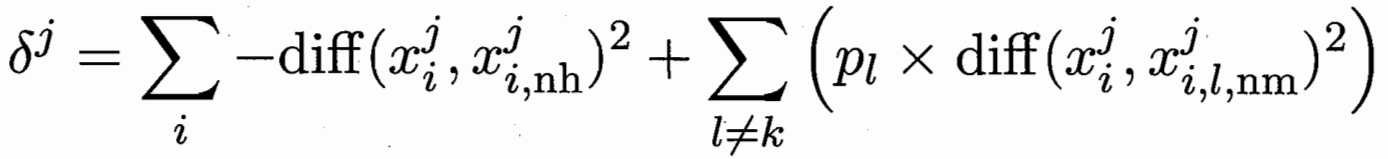
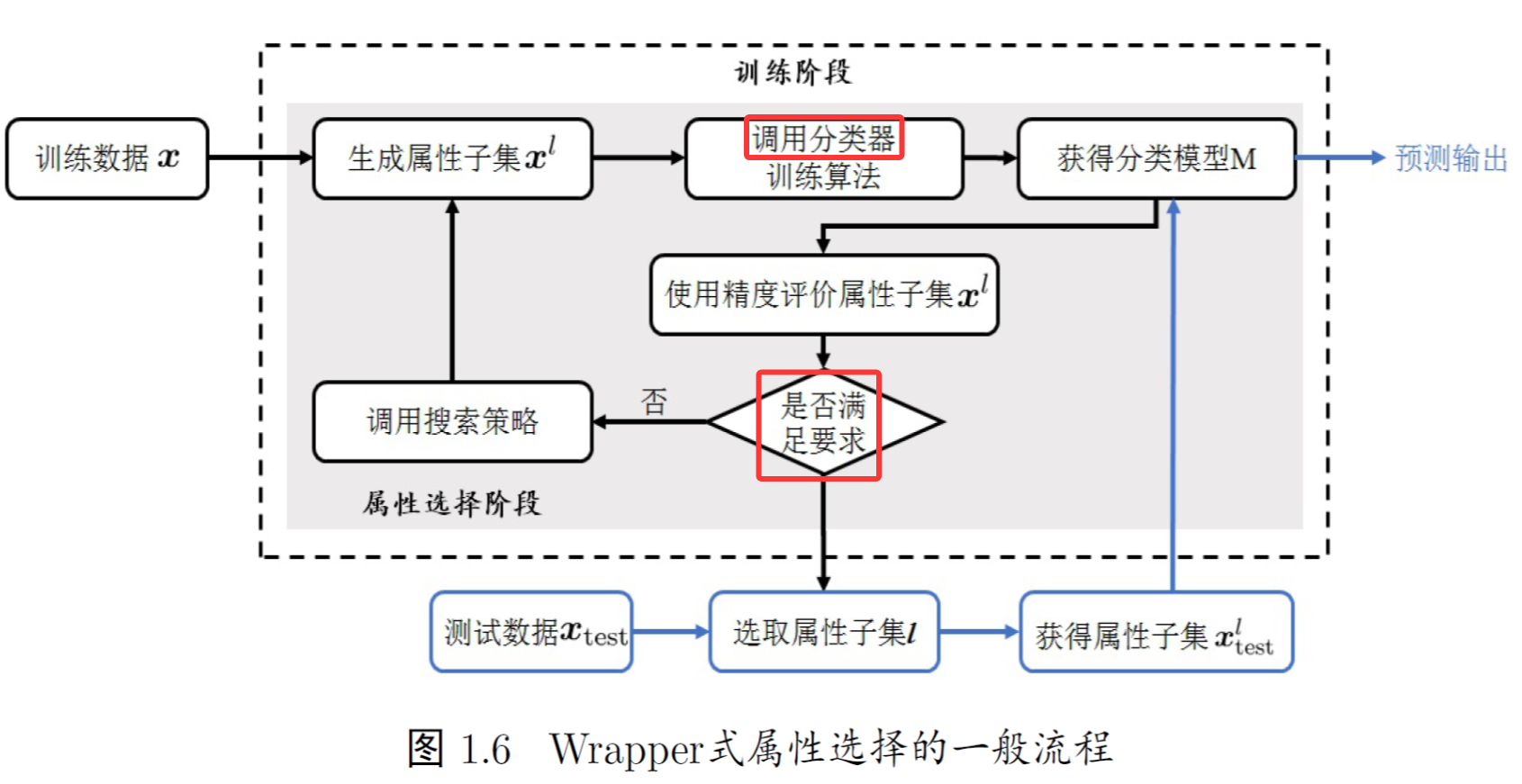
2.2 包裹式选择 wrapper + LVW(为学习器量身定做)
针对给定学习器选择最有利于其性能、 “量身定做”的特征子集。
LVW(Las Vegas Wrapper)利用拉斯维加斯框架 :利用随机性来做选择或进行尝试。
(1)随机产生特征子集
(2)使用交叉验证:如果新子集更好(误差小 或者误差同特征数少)则替换为最优解
(3)如果连续T次没有更新答案 就退出循环
与过滤式相比 最终学习器的性能更好; 但因为需多次训练学习器 计算开销会大很多
2.3 嵌入式选择 embedding + L1正则化(稀疏解相当于筛选)
特征选择过程与学习器训练过程同时完成。

正则化项: L2范数岭回归; 改善(减小)矩阵的条件数,确保了解的稳定性和唯一性。
将线性回归写成 ![]()
如果X^T X 条件数(最大奇异值 / 最小奇异值)大,矩阵病态,求解不稳定。
加上λ之后 使得矩阵 (X^T X + λI)的特征值变大λ 一定为正数。
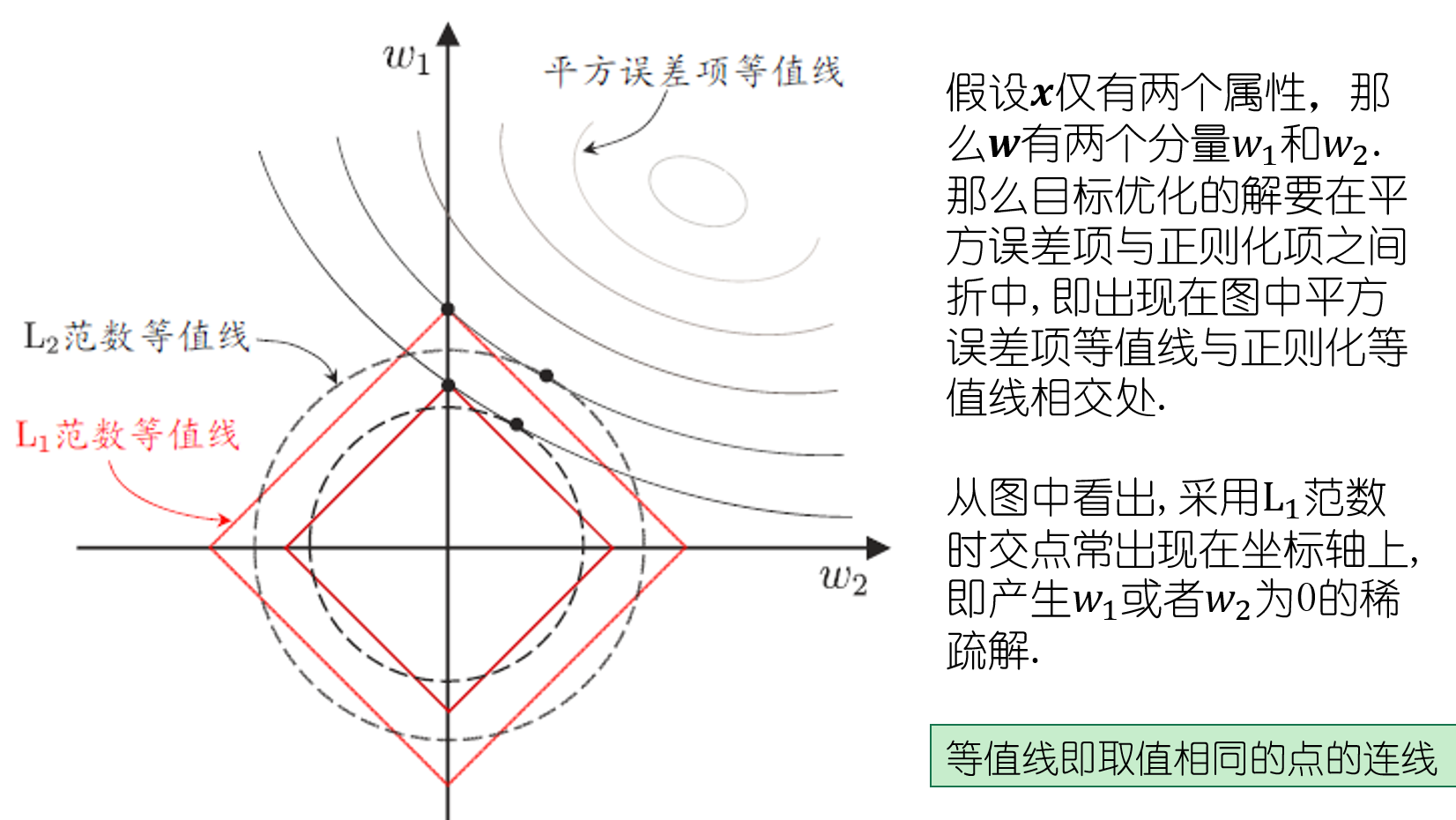
L1范数LASSO 更易于获得“稀疏”(sparse)解 w非零变量少。
w=0 对应的特征相当于被筛选掉了。
两股力量 范数往原点拉;误差往误差椭圆圆心拉;最优点即可看做椭圆和 圆/正方形的交点。
椭圆和正方形交点 落在正方形顶点位置概率大,即为稀疏解。
L1正则化问题的求解可使用近端梯度下降(PGD)迭代求解
如果先不考虑正则化系数 仅有f(x) 找到二阶泰勒展开近似,配方后进行迭代解答


如果加上正则化系数 最小化目标为

![]() 因为每个分量独立(初中 带绝对值的一次函数) 可解得
因为每个分量独立(初中 带绝对值的一次函数) 可解得
 可代入迭代求解。
可代入迭代求解。
3. 稀疏表示与字典学习
若把数据集看做一个矩阵 每一行代表一个样本 每一列代表一个特征 特征选择即选择列。
稀疏表示可以去除无关列 降低学习难度与计算开销 提高模型的解释性。
字典学习的目标:提取事物/任务 最本质的特征(类似于字典当中的字或词语)
就像话语是通过字词的排列组合 可以用这个字典里的特征表示这一类的所有事物。
字典好不好:取决提取的特征是否稀疏 是否为任务的本质特征。

字典B的维度:k代表词汇量 控制字典大小;d为数据集中 数据x的维度。
解法:变量交替迭代 K-SVD算法。
(1)固定字典B 求到每个x 最好的α表示;
(2)固定α 求最好的字典B。Trick 在于每次更新B 只更新其中的一列
4. 压缩感知(压缩信号-> 稀疏表示-> 重构)
数字信号领域:数据传输中,能否利用接收到的压缩、丢包后的数字信号,精确重构出原信号?
奈奎斯特(Nyquist)采样定理,采样频率达到模拟信号最高频率的两倍,则采样后的数字信号就保留了模拟信号的全部信息。
假定有长度为m的离散信号x,采样得长度为n的采样后信号y(短了很多 n<<m)使用测量矩阵φ。
正过来压缩很容易![]() 如何实现已知y 反推x?
如何实现已知y 反推x?
有难度,因为从信息少的返回信息多的 可能对应很多信息多的解(欠定方程)
若有![]() 则
则![]()
若根据y 能恢复出稀疏的s 再用s恢复x。
k限定等距性 k-RIP

L0范数最小化 在一定条件下与 L1范数最小化问题共解,所以可以转化为LASSO形式。
应用:书籍推荐问题 矩阵补全
假设获得一些读者对于书的评价,矩阵补全问题:
没有书被所有人度过 也没有人读过所有书 所以相当于很多值是缺失的 需要恢复出完全的值。
压缩感知技术恢复欠采样信号的前提条件之一是 信号有稀疏表示
书籍的特征有 题材、作者等;题材数远小于书本数 所以满足稀疏性。
在刚注册一个软件的时候,会先问顾客爱看什么 获得顾客特征。
可写成找一个秩最小的矩阵X 并且矩阵X对应位置与A有效值位置上的数相同。


rank 秩 = 非零奇异值的个数 -> 凸松弛为 “核范数” = 奇异值之和
我们将原本NP难的秩最小化问题,松弛为一个可以高效求解的凸优化问题。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐

 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)