
51c嵌入式~单片机~合集9
经过这几步后,程序下载工作就完成了,在以上的步骤中我们并没有选择要把程序下载到单片机的哪块内存中,即不需要设置地址。而对HEX文件而言,你看到的文件大小并不是实际的数据的大小。单片机程序编译之后,除了生成hex文件之外还生成了bin文件,实际它们都是单片机的下载文件,下文介绍它们的区别。烧写BIN文件的时候,用户是一定需要指定地址信息的。所以在下载bin文件时需要选择内存的起始地址和终止地址,即要
我自己的原文哦~ https://blog.51cto.com/whaosoft/13884964
一、单片机中hex、bin文件的区别
单片机程序编译之后,除了生成hex文件之外还生成了bin文件,实际它们都是单片机的下载文件,下文介绍它们的区别。
Hex
Hex文件包含地址信息。
在用ISP方式烧写程序时,有这样的经验:
- 选择单片机型号
- 选择串口号
- 设置波特率(或者默认)
- 选择下载的文件
- 点击下载按钮下载
在串口工具中,操作如下图红框所示。

经过这几步后,程序下载工作就完成了,在以上的步骤中我们并没有选择要把程序下载到单片机的哪块内存中,即不需要设置地址。因为HEX文件内部的信息已经包括了地址。
单片机一般是下载hex文件。
BIN
BIN文件格式只包括了数据本身,没有包含地址。烧写BIN文件的时候,用户是一定需要指定地址信息的。
所以在下载bin文件时需要选择内存的起始地址和终止地址,即要把bin文件下载到指定的内存空间。
通常需要指定程序内存地址的芯片为ARM芯片和DSP芯片。
文件大小 对于bin文件,通过右键属性查看到的文件的大小就是数据的实际大小。
而对HEX文件而言,你看到的文件大小并不是实际的数据的大小。一是因为HEX文件是用ASCII来表示数据,二是因为HEX文件本身还包括别的附加信息。
.
二、HEX文件的数据格式
Intel HEX文件是由一行行符合Intel HEX文件格式的文本所构成的ASCII文本文件。在Intel HEX文件中,每一行包含一个HEX记录。这些记录由对应机器语言码和/或常量数据的十六进制编码数字组成。Intel HEX文件通常用于传输将被存于ROM或者EPROM中的程序和数据。大多数EPROM编程器或模拟器使用Intel HEX文件。
~HEX记录格式
Intel HEX由任意数量的十六进制记录组成。每个记录包含5个域, 它们按以下格式排列[:LLAAAATT[DD…]CC]。每一组字母对应一个不同的域, 每一个字母对应一个十六进制编码的数字。每一个域由至少两个十六进制编码数字组成, 它们构成一个字节。
详细解释如下:
:每个Intel HEX记录都由冒号开头。
LL是数据长度域,它代表记录当中数据字节(dd)的数量。
AAAA是地址域,它代表记录当中数据的起始地址。
TT是代表HEX记录类型的域,它可能是以下数据当中的一个:
00 – 数据记录
01 – 文件结束记录
02 – 扩展段地址记录
04 – 扩展线性地址记录
DD 是数据域,它代表一个字节的数据。一个记录可以有许多数据字节,记录当中数据字节的数量必须和数据长度域LL中指定的数字相符。
CC是校验和域,它表示这个记录的校验和。校验和的计算是通过将记录当中所有十六进制编码数字对的值相加,以256为模进行以下补足。也就是说LLAAAATT[DD…]CC一共的校验和永远为0。
~数据记录格式
Intel HEX文件由任意数量以回车换行符结束的数据记录组成.
数据记录外观如下:
[:10246200464C5549442050524F46494C4500464C33]
其中:
10是这个记录当中数据字节的数量。
2462 是数据将被下载到存储器当中的地址。
00是记录类型(数据记录)。
464C…464C是数据。
33 是这个记录的校验和的补足码。
~扩展线性地址记录(HEX386)格式
扩展线性地址记录也叫作32位地址记录或HEX386记录。这些记录包含数据地址的高16位。扩展线性地址记录总是有两个数据字节。
外观如下:
[:02000004FFFFFC]
其中:
02是这个记录当中数据字节的数量。
0000是地址域,对于扩展线性地址记录,这个域总是0000。
04是记录类型 04(扩展线性地址记录)。
FFFF是地址的高16位。
FC是这个记录的校验和的补足码。
当一个扩展线性地址记录被读取,存储于数据域的扩展线性地址被保存,它被应用于从Intel HEX文件读取来的随后的记录。线性地址保持有效,直到它被另外一个扩展地址记录所改变。
通过把记录当中的地址域与被移位(16位)的来自扩展线性地址记录的地址数据相加获得数据记录的绝对存储器地址。以下的例子演示了这个过程:
来自数据记录地址域的地址 2462 扩展线性地址记录的数据域*10000H + FFFF0000 --------------------- 绝对存储器地址 FFFF2462
~扩展段地址记录(HEX86)
扩展段地址记录也叫HEX86记录,它包括4-19位数据地址段。扩展段地址记录总是有两个数据字节。
外观如下:
[:020000021200EA]
其中:
02 是记录当中数据字节的数量。
0000是地址域,对于扩展段地址记录,这个域总是0000。
02是记录类型 02(扩展段地址记录)。
1200是地址段。
EA是这个记录的校验和的补足码。
当一个扩展段地址记录被读取,存储于数据域的扩展段地址被保存,它被应用于从Intel HEX文件读取来的随后的记录。段地址保持有效,直到它被另外一个扩展地址记录所改变。
通过把记录当中的地址域与被移位(4位)的来自扩展段地址记录的地址数据相加获得数据记录的绝对存储器地址。以下的例子演示了这个过程:来自数据记录地址域的地址 2462
扩展段地址记录数据域*10H + 12000 ----------------- 绝对存储器地址 00014462
~文件结束(EOF)记录。
Intel HEX文件必须以文件结束(EOF)记录结束。这个记录的记录类型域的值必须是01。EOF记录外观总是如下
[:00000001FF]
其中:
00是记录当中数据字节的数量。
0000是数据被下载到存储器当中的地址。在文件结束记录当中地址是没有意义被忽略的。0000H是典型的地址。
01是记录类型01(文件结束记录)。
FF是这个记录的校验和的补足码。
~Intel HEX文件例子
下面是一个完整的Intel HEX文件的例子:
:10001300AC12AD13AE10AF1112002F8E0E8F0F2244
:10000300E50B250DF509E50A350CF5081200132259
:03000000020023D8
:0C002300787FE4F6D8FD7581130200031D
:10002F00EFF88DF0A4FFEDC5F0CEA42EFEEC88F016
:04003F00A42EFE22CB
:00000001FF看了这个例子,我自己也打开了之前写的51单片机的hex文件:
:2000000002000E75210675225B75230200267B007C00900090758140758901758CF1758A45
:2000200028D28C75A882758CF1758A280BBBFA157B00EC75F00A8485F020F5210CBC64027A
:200040007C00120051C0E0C0D0120051D0D0D0E032E52193F580D2A2C2A27580FED2A3C29C
:20006000A3120087E52093F580D2A2C2A27580FDD2A3C2A3120087227D327E287FF81151AA
:1A008000DFFEDEF8DDF4227E047FF8DFFEDEFA223F065B4F666D7D077F6FBC
:00000001FF~英文原文
QUESTION:What is the Intel HEX file format?
ANSWER:
8.1 The Intel HEX file is an ASCII text file with lines of text that follow theIntel HEX file format. Each line in an Intel HEX file contains one HEX record.These records are made up of hexadecimal numbers that represent machine language code and/or constant data. Intel HEX files are often used to transfer the program and data that would be stored in a ROM or EPROM. Most EPROM programmers or emulators can use Intel HEX files.
8.2 Record Format.
An Intel HEX file is composed of any number of HEX records. Each record is made up of five fields that are arranged in the following format:
:LLAAAATT[DD…]CC
Each group of letters corresponds to a different field, and each letter represents a single hexadecimal digit. Each field is composed of at least two hexadecimal digits-which make up a byte-as described below:
8.2.1 : is the colon that starts every Intel HEX record.
8.2.2 LL is the record-length field that represents the number of data bytes (dd) in the record.
8.2.3 AAAA is the address field that represents the starting address for subsequent data in the record.
8.2.4 TT is the field that represents the HEX record type, which may be one of the following:
8.2.4.1 00 - data record
8.2.4.2 01 - end-of-file record
8.2.4.3 02 - extended segment address record
8.2.4.4 04 - extended linear address record
8.2.5 DD is a data field that represents one byte of data. A record may have multiple data bytes. The number of data bytes in the record must match the number specified by the ll field.
8.2.6 CC is the checksum field that represents the checksum of the record. The checksum is calculated by summing the values of all hexadecimal digit pairs in the record modulo 256 and taking the two's complement.
8.3 Data Records.
The Intel HEX file is made up of any number of data records that are terminated with a carriage return and a linefeed. Data records appear as follows:
:10246200464C5549442050524F46494C4500464C33
where:
8.3.1 10 is the number of data bytes in the record.
8.3.2 2462 is the address where the data are to be located in memory.
8.3.3 00 is the record type 00 (a data record).
8.3.4 464C...464C is the data.
8.3.5 33 is the checksum of the record.
8.4 Extended Linear Address Records (HEX386).
Extended linear address records are also known as 32-bit address records and HEX386 records. These records contain the upper 16 bits (bits 16-31) of the data address. The extended linear address record always has two data bytes and appears as follows:
:02000004FFFFFC
where:
8.4.1 02 is the number of data bytes in the record.
8.4.2 0000 is the address field. For the extended linear address record, this field is always 0000.
8.4.3 04 is the record type 04 (an extended linear address record).
8.4.4 FFFF is the upper 16 bits of the address.
8.4.5 FC is the checksum of the record and is calculated as 01h + NOT(02h + 00h + 00h + 04h + FFh + FFh).
8.4.6 When an extended linear address record is read, the extended linear address stored in the data field is saved and is applied to subsequent records read from the Intel HEX file. The linear address remains effective until changed by another extended address record.
8.4.7 The absolute-memory address of a data record is obtained by adding the address field in the record to the shifted address data from the extended linear address record. The following example illustrates this process..
Address from the data record's address field 2462
Extended linear address record data field FFFF
-----------
Absolute-memory address FFFF2462
8.5 Extended Segment Address Records (HEX86).
Extended segment address records-also known as HEX86 records-contain bits 4-19
of the data address segment. The extended segment address record always has two
data bytes and appears as follows:
:020000021200EA
where:
8.5.1 02 is the number of data bytes in the record.
8.5.2 0000 is the address field. For the extended segment address record, this field is always 0000.
8.5.3 02 is the record type 02 (an extended segment address record).
8.5.4 1200 is the segment of the address.
8.5.5 EA is the checksum of the record and is calculated as 01h + NOT(02h + 00h + 00h + 02h + 12h + 00h).
8.5.6 When an extended segment address record is read, the extended segment addressstored in the data field is saved and is applied to subsequent records read from the Intel HEX file. The segment address remains effective until changed by another extended address record.
8.5.7 The absolute-memory address of a data record is obtained by adding the addressfield in the record to the shifted-address data from the extended segment address record. The following example illustrates this process.
Address from the data record's address field 2462
Extended segment address record data field 1200
--------
Absolute memory address 00014462
8.6 End-of-File (EOF) Records.
An Intel HEX file must end with an end-of-file (EOF) record. This record must have the value 01 in the record type field. An EOF record always appears as follows:
:00000001FF
where:
8.6.1 00 is the number of data bytes in the record.
8.6.2 0000 is the address where the data are to be located in memory. The address in end-of-file records is meaningless and is ignored. An address of 0000h is typical.
8.6.3 01 is the record type 01 (an end-of-file record).
8.6.4 FF is the checksum of the record and is calculated as 01h + NOT(00h + 00h + 00h + 01h).
8.7 Example Intel HEX File.
Following is an example of a complete Intel HEX file:
:10001300AC12AD13AE10AF1112002F8E0E8F0F2244
:10000300E50B250DF509E50A350CF5081200132259
:03000000020023D8
:0C002300787FE4F6D8FD7581130200031D
:10002F00EFF88DF0A4FFEDC5F0CEA42EFEEC88F016
:04003F00A42EFE22CB
:00000001FF...
三、SMT32的PWM波形输出配置
STM32之PWM波形输出配置总结。
1). TIMER分类:
STM32中一共有11个定时器,其中TIM6、TIM7是基本定时器;TIM2、TIM3、TIM4、TIM5是通用定时器;TIM1和TIM8是高级定时器,以及2个看门狗定时器和1个系统嘀嗒定时器。其中系统嘀嗒定时器是前文中所描述的SysTick。

其中TIM1和TIM8是能够产生3对PWM互补输出,常用于三相电机的驱动,时钟由APB2的输出产生。TIM2-TIM5是普通定时器,TIM6和TIM7是基本定时器,其时钟由APB1输出产生。
2)、PWM波形产生的原理:
通用定时器可以利用GPIO引脚进行脉冲输出,在配置为比较输出、PWM输出功能时,捕获/比较寄存器TIMx_CCR被用作比较功能,下面把它简称为比较寄存器。
这里直接举例说明定时器的PWM输出工作过程:若配置脉冲计数器TIMx_CNT为向上计数,而重载寄存器TIMx_ARR被配置为N,即TIMx_CNT的当前计数值数值X在TIMxCLK时钟源的驱动下不断累加,当TIMx_CNT的数值X大于N时,会重置TIMx_CNT数值为0重新计数。
而在TIMxCNT计数的同时,TIMxCNT的计数值X会与比较寄存器TIMx_CCR预先存储了的数值A进行比较,当脉冲计数器TIMx_CNT的数值X小于比较寄存器TIMx_CCR的值A时,输出高电平(或低电平),相反地,当脉冲计数器的数值X大于或等于比较寄存器的值A时,输出低电平(或高电平)。
如此循环,得到的输出脉冲周期就为重载寄存器TIMx_ARR存储的数值(N+1)乘以触发脉冲的时钟周期,其脉冲宽度则为比较寄存器TIMx_CCR的值A乘以触发脉冲的时钟周期,即输出PWM的占空比为 A/(N+1) 。
3)、STM32产生PWM的配置方法:
1、配置GPIO口:
配置IO口的时候无非就是开启时钟,然后选择引脚、模式、速率,最后就是用结构体初始化。不过在32上,不是每一个IO引脚都可以直接使用于PWM输出,因为在硬件上已经规定了用某些引脚来连接PWM的输出口。下面是定时器的引脚重映像,其实就是引脚的复用功能选择:
a.定时器1的引脚复用功能映像:

b.定时器2的引脚复用功能映像:

c.定时器3的引脚复用功能映像:

d.定时器4的引脚复用功能映像:

根据以上重映像表,我们使用定时器3的通道2作为PWM的输出引脚,所以需要对PB5引脚进行配置,对IO口操作代码:
GPIO_InitTypeDef GPIO_InitStructure;//定义结构体
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOB | RCC_APB2Periph_AFIO, ENABLE);//使能GPIO外设和AFIO复用功能模块时钟
GPIO_PinRemapConfig(GPIO_PartialRemap_TIM3, ENABLE); //选择Timer3部分重映像
//选择定时器3的通道2作为PWM的输出引脚TIM3_CH2->PB5 GPIOB.5
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_5; //TIM_CH2
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_AF_PP; //复用推挽功能
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOB, &GPIO_InitStructure);//初始化引脚2、初始化定时器:
TIM_TimeBaseInitTypeDef TIM_TimeBaseStructure;//定义初始化结构体
RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3, ENABLE); //使能定时器3时钟
//初始化TIM3
TIM_TimeBaseStructure.TIM_Period = arr; //自动重装载寄存器的值
TIM_TimeBaseStructure.TIM_Prescaler =psc; //TIMX预分频的值
TIM_TimeBaseStructure.TIM_ClockDivision = 0; //时钟分割
TIM_TimeBaseStructure.TIM_CounterMode = TIM_CounterMode_Up; //向上计数
TIM_TimeBaseInit(TIM3, &TIM_TimeBaseStructure); //根据以上功能对定时器进行初始化3、设置TIM3_CH2的PWM模式,使能TIM3的CH2输出:
TIM_OCInitTypeDef TIM_OCInitStructure;//定义结构体
TIM_OCInitStructure.TIM_OCMode = TIM_OCMode_PWM2;//选择定时器模式,TIM脉冲宽度调制模式2
TIM_OCInitStructure.TIM_OutputState = TIM_OutputState_Enable;//比较输出使能
TIM_OCInitStructure.TIM_OCPolarity = TIM_OCPolarity_Low;//输出比较极性低
TIM_OC2Init(TIM3, &TIM_OCInitStructure);//根据结构体信息进行初始化
TIM_OC2PreloadConfig(TIM3, TIM_OCPreload_Enable); //使能定时器TIM2在CCR2上的预装载值4、使能定时器3:
TIM_Cmd(TIM3, ENABLE); //使能定时器TIM3经过以上的操作,定时器3的第二通道已经可以正常工作并输出PWM波了,只是其占空比和频率都是固定的,我们可以通过改变TIM3_CCR2,则可以控制它的占空比。修改占空比的函数为:
TIM_SetCompare2(TIM3,n); //n不同,占空比不同。5、修改pwm波形的占空比:
编写一个函数:
void TIM3_PWM_Init(u16 arr,u16 psc);将以上所有的代码都加进来这个函数中,只要在main函数中调用该函数进行初始化,然后使用TIM_SetCompare2()函数修改PWM的占空比就可以在PB5脚得到需要的PWM波形了。关于频率以及占空比的计算方法有以下例子:
intmain(void)
{
TIM3_PWM_Init(9999,143);//频率为:72*10^6/(9999+1)/(143+1)=50Hz
TIM_SetCompare2(TIM3,4999);//得到占空比为50%的pwm波形
while(1);
}..
四、认识ARM:汇编、架构、异常级别和安全状态
01 ARM汇编指令
操作系统中硬件相关的部分集中体现在汇编指令和对寄存器的操作中,因此我们对ARM体系结构的介绍也围绕ARMv8-A的汇编指令和寄存器来展开。
处理器架构是处理器厂商为同一个系列的处理器规定的一个规范。ARM架构是一种精简指令集(RISC)架构,具有以下RISC架构特点:
- 较大的通用寄存器堆。
- load/store体系结构,其中数据处理操作仅对寄存器内容进行操作,而不是直接对内存内容。
- 简单寻址模式,所有load/store地址由寄存器内容和指令确定。该体系结构定义了处理单元与内存(包括缓存)的交互,并包括内存地址翻译系统。它还描述了多个处理单元如何相互作用。面积小、性能强和非常低的功耗是ARM体系结构的关键特性。本小节主要以ARMv8-A架构为例来介绍ARM体系结构的基本特性。ARMv8-A体系结构的一个重要特性是向后兼容,可以支持诸多标准和应用场景下的最优设计。ARMv8-A架构支持64bit的执行模式(AArch64)和32bit的执行模式(AArch32),这一模式兼容之前的ARM架构。两种执行状态都支持SIMD和浮点指令。
一、AMRv8架构概要
ARM体系结构自推出以来已经有了显著的发展,并且ARM还在继续开发它。到目前为止,已经有八个主要版本,由版本号1到8表示。其中前三个版本现在已经过时了。
通用名称AArch64和AArch32描述了64位和32位执行状态。AArch64是64位执行状态,意味着地址保存在64位寄存器中,并且基本指令集可以使用64位寄存器进行处理。AArch64支持A64指令集。AArch32是32位执行状态,这意味着地址保存在32位寄存器中,并且基本指令集使用32位寄存器进行处理。AArch32支持T32和A32指令集。
ARM支持三种架构配置:
- A系列,面向应用场景的架构(Application Profile)。该系列支持基于内存管理单元(MMU)的虚拟内存系统体系结构(VMSA)。它支持A64、A32和T32指令集。
- R系列,面向实时场景的架构配置。该系列支持基于内存保护单元(MPU)的受保护内存系统体系结构(PMSA)。它支持A32和T32指令集。
- M系列,面向微处理器的架构。该系列实现了一个为低延迟中断处理而设计的程序员模型(programmers’ model),该模型具有寄存器硬件堆栈和对中断处理程序的高级语言支持。它支持T32指令集的变种。
(注:内存保护单元(MPU)是ARM中配备的有效保护系统资源的一种硬件,提供了内存区域保护功能。)
二、ARMv8-A指令集
在ARMv8-A中,可能的指令集取决于执行状态:
- AArch64:AArch64 state只支持A64指令集。这是一个固定长度的指令集,使用32位指令编码。
- Arch32:AArch32 state支持以下指令集:
- A32:这是一个固定长度的指令集,使用32位指令编码。它是与ARMv7 ARM指令集兼容。
- T32:这是一个可变长度指令集,它同时使用16位和32位指令编码。它与ARMv7 Thumb®指令集兼容。
ARM指令的基本格式如下[2]:
<Opcode>{<Cond>}<S><Rd>,<Rn> {,<Opcode2>}
其中各个部分的含义为:
- Opcode:操作码,也就是助记符,说明指令需要执行的操作类型;
- Cond:指令执行条件码;
- S:条件码设置项,决定本次指令执行是否影响PSTATE寄存器相应状态位值;
- Rd/Xt:目标寄存器,A32指令可以选择R0-R14,T32指令大部分只能选择RO-R7,A64指令可以选择X0-X30;
- Rn/Xn:第一个操作数的寄存器,和Rd一样,不同指令有不同要求;
- Opcode2:第二个操作数,可以是立即数,寄存器Rm和寄存器移位方式(Rm,#shit);
ARMv8-A指令集的条件码如下图所示:

下面以A64指令集为例简要介绍ARMv8-A的指令体系。A64指令集中的指令主要分为控制指令、访存指令和计算指令。控制指令主要包括有条件分支指令、无条件分支指令、异常产生和返回指令、系统寄存器指令、系统指令、提示指令、同步指令和清除独占访问标志指令。访存指令主要有Load指令和Store指令,这两种指令有许多变种。计算指令包含算数指令、逻辑指令、MOVE指令、移位指令、位扩展指令和SIMD指令等等。以下列出了一些常用的控制指令的名称与用途。
1. 控制指令:
- 条件分支指令:

- 无条件分支指令:

- 使用寄存器的无条件分支指令:

- 异常产生指令:

- 异常返回指令:

- 系统寄存器指令:

- 同步指令和独占状态清除指令:

例如:

2. 访存指令:
ARMv8访存指令支持以下寻址模式:
- 基址加上无符号立即数的寻址和基址加上有符号立即数的寻址;
- 基址加上寄存器偏移值;
- 基址加上扩展的寄存器偏移;
- pre-index模式;
- post-index模式;
- PC相对寻址模式。
具体情形见下表:

其中对于A64指令集来说,64bit的基址来自通用寄存器X0-X30或来自栈指针SP,立即数或寄存器偏移值则是可选的,对寻址方式的解释如下:
- 寄存器偏移寻址是指来自64bit基址寄存器的地址加上一个偏移值;
- Pre-indexed模式是指寻址地址是64bit基址加上一个偏移值,这个计算和将会写入基址寄存器;
- Post-indexed模式是指寻址地址是64bit的基址,但之后基址和偏移值的和将会写入基址寄存器;由此可见pre-indexed和post-indexed的区别在于使用的地址是先加上偏移值再使用还是先使用再加上偏移值;
- PC相对寻址是指寻址地址是这条指令64bit的PC值加上一个19bit的有符号字偏移,这个地址在当前指令的PC值的 ±1MB范围内并且是4byte对齐的。使用PC相对寻址所load的数据大小至少为32bit并且只能用来预取指令,且PC值不能被其他寻址方式使用。
- 一个立即数偏移可以为有符号的,也可以为无符号的,可以为scaled也可以为unscaled。当一个立即数偏移是scaled的时候,它被编码为传输数据大小的整数倍。虽然汇编程序总是使用byte对齐的偏移,但汇编器或反汇编器会做必要的转换工作,因此可用的byte偏移值取决于load/store指令类型和数据传输的大小。
下面列出了一些load/store指令:

例如Load寄存器指令:



上表中指令的寻址方式有:
- 基址加上12bit无符号scaled立即数偏移寻址;
- 基址加上9bit有符号unscaled立即数偏移寻址;
- 基址加上64bit寄存器偏移,可选为scaled;
- 基址加上32bit可拓展寄存器偏移,可选为scaled;
- 有unscaled9bit有符号立即数偏移的pre-indexed模式;
- 有unscaled9bit有符号立即数偏移的post-indexed模式;
- Load至少32bit数据的PC相对寻址模式。
如果被load或store的指令的寻址模式会修改基址寄存器的内容,且被load/store寄存器恰好的是基址所在的寄存器,那么硬件的行为可能不确定。
3.计算指令:
在操作系统汇编语言中使用的计算指令主要是一些简单的算数计算指令,用于对寄存器的move操作和对地址的计算操作,一般计算指令既可以使用立即数作为操作数,也可以使用寄存器中的数作为操作数。下面简单列举了一些算数指令:
使用立即数的简单算数指令:

例如:
![]()

使用寄存器的逻辑操作指令:

例如:


其中:

寄存器移位指令:

例如:

02 ARM架构寄存器
在处理器中,寄存器用于保存需要被快速访问的数据,在操作系统中需要特别注意的寄存器主要有栈指针寄存器(SP)、连接寄存器(LR)、程序计数器(PC)以及当前程序状态寄存器(CPSR)和保存程序状态寄存器(SPSR)。本小节主要以ARMv8-A为例介绍ARM架构的寄存器的基本情况。详情可参见文献[3],D1.6小节。
在这一小节中,我们主要介绍ARMv8架构中AArch64执行状态下的寄存器使用情况。ARM架构中的寄存器主要有两类,一类用于提供系统控制与状态报告;另一类用于指令运行和异常处理。我们主要讨论第二类。
通用寄存器主要用于基本指令集中的指令运行,通用寄存器共有31个,编号为R0-R31。这些通用寄存器可以被当成31个64bit的寄存器,编号为X0-X30;或者被作为31个32bit的寄存器,编号为W0-W30。
在AArch64执行状态下,除了通用寄存器外,每一个异常级别都会有一个栈指针寄存器(StackPointer Register, SP),栈指针寄存器为SPEL0和SPEL1。异常级别用于区分指令的执行权限,我们将在本章的第四期介绍。如果处理器实现中包含EL2,那么还有SPEL2。如果处理器实现中包含EL3,那么还有SPEL3。详情可参考链接[5]。
SIMD和浮点寄存器共用一系列寄存器,这些寄存器会用于浮点操作、向量操作和其它SIMD有关的标量操作。SIMD指令是能够复制多个操作数、并把它们打包在大型寄存器的一组指令集[3]。以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。浮点寄存器和SIMD寄存器共包含32个128bit位宽的寄存器,V0-V31。这些寄存器可以作为:
- 32个双字(64bit)寄存器,D0-D31。
- 32个单字(32bit)寄存器,S0-S31。
- 32个半字(16bit)寄存器,H0-H31。
- 32个单字(8bit)寄存器,B0-B31。
程序状态寄存器(Current Program Status Register,CPSR) 在用户级编程时用于存储条件码。CPSR包含条件码标志,中断禁止位,当前处理器模式以及其他状态和控制信息。
保存程序状态寄存器(SPSR,Saved Program StatusRegister)用于保存CPSR的状态,以便异常返回后恢复异常发生时的工作状态。在A64中,不再使用单一的CPSR寄存器,来保存当前处理器状态,而是用PSTATE来保存处理器状态,而在A32中依然使用CPSR。有关PSTATE和CPSR的详细信息可参考链接[4]。A64中SPSR 格式的示意图如下图所示:

其中N、Z、C、V均为条件码标志位。它们的内容可被算术或逻辑运算的结果所改变,并且可以用于决定某条指令是否被执行,其含义如下表所示[8]:
|
标志位 |
含义 |
|
N |
当两个有符号整数运算时:N=1表示运算的结果为负数;N=0表示运算的结果为正数或零。 |
|
Z |
Z=1表示运算的结果为零,Z=0表示运算的结果非零。 |
|
C |
可以有4种方法设置C的值:
|
|
V |
对于加减运算指令,当操作数和运算结果为二进制的补码表示的带符号数时,V=1表示符号为溢出,通常其他指令不影响V位。 |
M[3:0]则用来确定异常级别和SP:

有关SPSR中各个位的详细信息可以参考文献[1] 1.6.4小节。
连接寄存器LR(R14)的主要作用有两个:
1. 保存子程序返回地址,用MOVE指令或BX指令可以用于实现返回,如MOV PC、LR或BXLR。若子程序中还需要调用子程序,则可以写为:

第一条指令将LR中的内容入栈,最后一条将栈中保存的LR寄存器的内容存入PC中用于返回。
2. 当异常发生时,异常模式的LR用于保存异常返回地址,将LR内容入栈可以处理嵌套中断。
PC是程序计数器,其中保存的是正在被加载的指令,而不是正在被执行的指令。例如,若指令长度为4byte,则PC指向当前正在被执行的指令的地址+8byte的地址。关于LR和PC的详细内容可参考文献[6]和[7]。
以下是异常级别EL3中使用的寄存器的例图:

ARM架构中处理器有不同的运行模式,因此同一个功能的寄存器在不同的运行模式下可能对应不同的物理寄存器,这些寄存器被称为备份寄存器。如SPSR_svc表示svc模式下使用的SPSR寄存器。ARM架构中常用的运行模式如下表所示[9]:
|
处理器模式 |
描述 |
|
用户模式(User, usr) |
正常程序执行的模式 |
|
快速中断模式(FIQ, fiq) |
用于高速数据传输和通道处理 |
|
外部中断模式(IRQ, irq) |
用于通常的中断处理 |
|
特权模式(Supervisor, svc) |
供操作系统使用的一种保护模式 |
|
数据访问中止模式(Abort, abt) |
当数据或指令预取中止时进入该模式,用于虚拟存储及存储保护 |
|
未定义指令中止模式(Undefined, und) |
当执行未定义指令时进入该模式,用于支持通过软件仿真硬件的协处理器 |
|
系统模式(System, sys) |
用于运行特权级的操作系统任务 |
ARMv8-A架构还有Monitor(mon)工作模式,用于处理器安全状态与非安全状态的切换,Hypervisor(hyp)模式则用于对虚拟化有关功能的支持。有关安全状态的详细内容在后续的文章中会介绍。
03 ARM架构中的执行状态
ARMv8-A有两种执行模式,一种是AArch64执行模式,另一种是AArch32执行模式。执行状态定义处理单元(Processing Element, PE)的执行环境,包括以下内容:
- 支持的寄存器宽度
- 支持的指令集
- 异常模型
- 虚拟存储系统(Virtual Memory System Architecture, VMSA)架构
- 程序员模型
AArch64为64位执行状态。对应上述内容,此执行状态:
- 提供31个64位通用寄存器,其中X30用作过程链接寄存器(ProcedureLink Register)。
- 提供64位程序计数器(PC)、堆栈指针(SP)和异常链接寄存器(ELRs)。
- 提供32个128位寄存器以支持SIMD矢量和标量浮点运算。
- 提供单一指令集A64。
- 定义ARMv8异常模型,该模型最多有四个异常级别EL0-EL3,它们提供执行权限层次结构。
- 支持64位虚拟寻址。
- 定义一系列与PSTATE相关的寄存器。A64指令集包括能直接操作各种PSTATE寄存器的指令。
- 使用后缀命名每个系统寄存器,该后缀指示可以访问寄存器的最低异常级别。
AArch32为32位执行状态。对应上述内容,此执行状态:
- 提供13个32位通用寄存器和一个32位PC、一个32位SP寄存器和一个32位链接寄存器(Link Register,LR)。链接寄存器用作异常链接寄存器和过程链接寄存器。其中一些寄存器有多个备份寄存器,用于不同的处理器工作模式。我们在上一期提到过,同一个功能的寄存器在不同的处理器运行模式下可能对应不同的物理寄存器,这些寄存器被称为备份寄存器。
- 为从Hyp(hypervisor)模式返回的异常提供一个异常链接寄存器。
- 提供32个64位寄存器,用于对高级SIMD矢量和标量浮点计算的支持。
- 提供两个指令集,A32和T32。
- 支持基于处理器工作模式的ARMv7-A异常模型,并将其映射到基于异常级别的ARMv8异常模型。
- 使用32位虚拟地址。
- 使用单个当前程序状态寄存器(CPSR)保存处理器状态。
- 在AArch64和AArch32执行状态之间进行转换称为内部处理(interprocessing)。
04 ARMv8-A架构的异常级别和安全状态
ARMv8-A有四个异常级别,从EL0到EL3。对于异常级别ELn,整数n增加表示软件执行的特权权限变大了。EL0级别下的执行叫非特权执行(unprivileged execution)。EL1主要用于运行操作系统内核。EL2可以支持非安全操作的虚拟化。EL3则支持安全状态和非安全状态之间的转换。安全状态与ARM TrustZone技术有关[2]。安全状态可以运行可信执行环境(TEE, Trusted Execution Environment)及安全应用,用于保障隐私数据和程序运行环境的安全性。
ARMv8-A架构并未直接指定哪些软件应该运行在哪些异常级别,但是在通常情况下,有如异常级别的使用模型:
1.应用程序运行在EL0;
2.操作系统内核和相关功能运行在EL1;
3.Hypervisor[3]运行在EL2;
4.安全世界状态和正常世界状态的切换在EL3完成。
下图反映了ARM-v8A架构中的执行状态、安全状态和异常级别之间关系[1]:

从图中我们可以看出,Hypervisor相关的支持特性主要是在EL2的非安全状态实现的。Hypervisor可以支持虚拟机之间的切换,而虚拟机主要被包含在EL1的非安全状态和EL0的非安全状态中。一些Guest OS可以运行在EL1状态里,每一个Guest OS可以运行在一个虚拟机上。而应用则运行在EL0的非安全状态中,同时也运行在Guest OS上。
.
..
五、单片机的一键开关机控制电路
用一个按键开关控制单片机,也就是说一键开关机,从哪里入手?
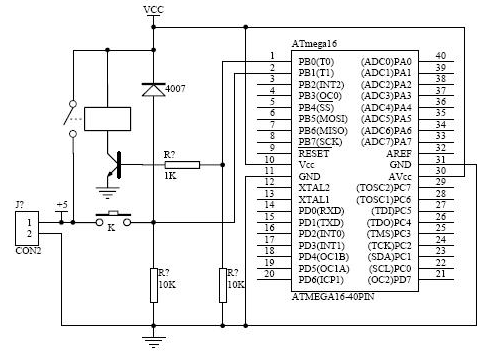
- 按下K,电源通过4007为整个系统供电,AVR开始工作。此时PB1为高电平。注意,电源来源是连接器旁边的+5V。
- AVR检测PB1,连续2秒为高(反之干扰和和误按K),PB0输出高电平,继电器工作。
- AVR等待PB1为低,然后进入正式工作。
- 此时K已经释放,整个系统有电,保持工作,但PB1为低电平(因为4007隔离)。
- 如果AVR再次检测到PB1为高时(连续2秒),AVR的PB0输出低电平,然后什么也不做了。
- 释放K后,系统电源关闭。
继电器可以使用电子开关代替,但电子开关会漏电。仅供参考。
另外,再放一个仪器仪表中比较常见的单键开关电路。
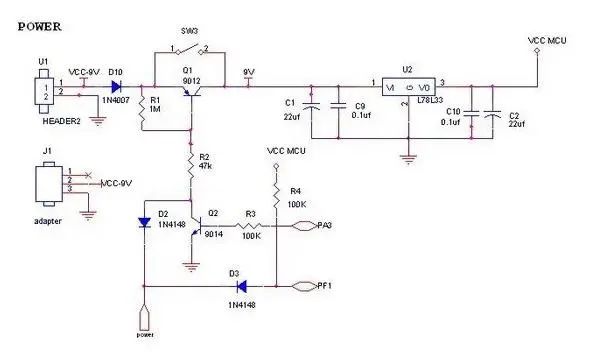
这里使用了普通的9014 9012三极管,其实不好,可以换用MOS管。
..
六、信号反射问题与相关电路设计技巧
信号反射现象
信号传输过程中感受到阻抗的变化,就会发生信号的反射。这个信号可能是驱动端发出的信号,也可能是远端反射回来的反射信号。根据反射系数的公式,当信号感受到阻抗变小,就会发生负反射,反射的负电压会使信号产生下冲。信号在驱动端和远端负载之间多次反射,其结果就是信号振铃。大多数芯片的输出阻抗都很低,如果输出阻抗小于PCB走线的特性阻抗,那么在没有源端端接的情况下,必然产生信号振铃。
什么是过冲(overshoot):过冲就是第一个峰值或谷值超过设定电压——对于上升沿是指最高电压而对于下降沿是指最低电压。
什么是下冲(undershoot):下冲是指下一个谷值或峰值。过分的过冲能够引起保护二极管工作,导致过早地失效。过分的下冲能够引起假的时钟或数据错误(误作)。
延庆川北小区45孙老师 东屯 收卖废品垃圾破烂炒股 废品孙
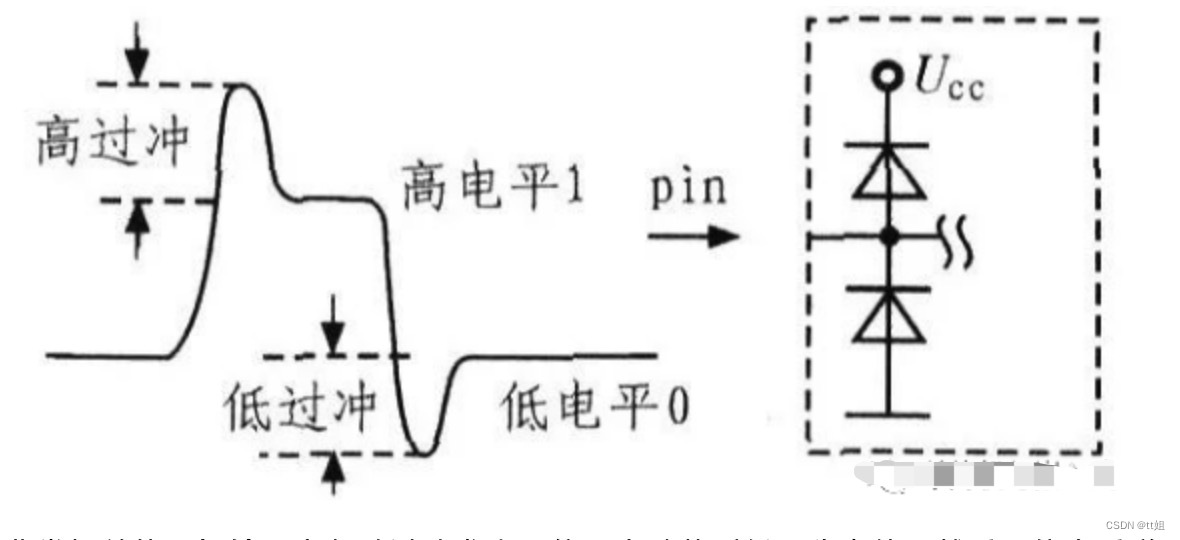
过冲非常相关的是振铃,它紧随过冲发生,信号会跌落到低于稳态值,然后可能会反弹到高于稳态,这个过程可能持续一段时间,直到稳定接近于稳态。振铃持续的时间也叫做安定时间。振荡(ringing)和环绕振荡(rounding)的现象是反复出现过冲和下冲。
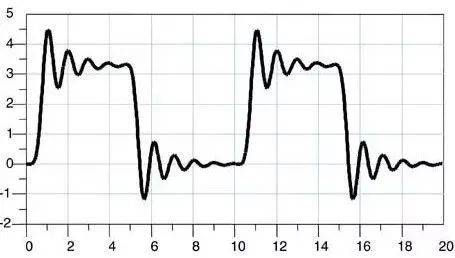
抑制信号反射等电路设计技巧
如果时钟信号链路比较长,为了解决信号反射问题,会在时钟输出信号上串接一个比如22或者33欧姆的小电阻。相x关文章推荐:认识传输线的三个特性,特性阻抗、反射、阻抗匹配。
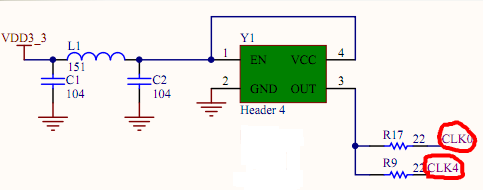
而且随着电阻的加大,振铃会消失,然而信号上升沿不再那么陡峭了,串联电阻是为了减小反射波,避免反射波叠加引起过冲。
这个解决方法叫阻抗匹配,阻抗在信号完整性问题中占据着极其重要的地位。
..
七、电容、电感产生的相位差
对于正弦信号,流过一个元器件的电流和其两端的电压,它们的相位不一定是相同的。这种相位差是如何产生的呢?这种知识非常重要,因为不仅放大器、自激振荡器的反馈信号要考虑相位,而且在构造一个电路时也需要充分了解、利用或避免这种相位差。下面探讨这个问题。
首先,要了解一下一些元件是如何构建出来的;其次,要了解电路元器件的基本工作原理;第三,据此找到理解相位差产生的原因;第四,利用元件的相位差特性构造一些基本电路。
电阻、电感、电容的诞生过程
科学家经过长期的观察、试验,弄清楚了一些道理,也经常出现了一些预料之外的偶然发现,如伦琴发现X射线、居里夫人发现镭的辐射现象,这些偶然的发现居然成了伟大的科学成就。电子学领域也是如此。
科学家让电流流过导线的时候,偶然发现了导线发热、电磁感应现象,进而发明了电阻、电感。科学家还从摩擦起电现象得到灵感,发明了电容。发现整流现象而创造出二极管也是偶然。
元器件的基本工作原理
电阻——电能→热能
电感——电能→磁场能,&磁场能→电能
电容——电势能→电场能,&电场能→电流
由此可见,电阻、电感、电容就是能源转换的元件。电阻、电感实现不同种类能量间的转换,电容则实现电势能与电场能的转换。
电阻
电阻的原理是:电势能→电流→热能。
电源正负两端贮藏有电势能(正负电荷),当电势加在电阻两端,电荷在电势差作用下流动——形成了电流,其流动速度远比无电势差时的乱序自由运动快,在电阻或导体内碰撞产生的热量也就更多。
正电荷从电势高的一端进入电阻,负电荷从电势低的一端进入电阻,二者在电阻内部进行中和作用。中和作用使得正电荷数量在电阻内部呈现从高电势端到低电势端的梯度分布,负电荷数量在电阻内部呈现从低电势端到高电势端的梯度分布,从而在电阻两端产生了电势差,这就是电阻的电压降。同样电流下,电阻对中和作用的阻力越大,其两端电压降也越大。
因此,用R=V/I来衡量线性电阻(电压降与通过的电流成正比)的阻力大小。
对交流信号则表达为R=v(t)/i(t)。
注意,也有非线性电阻的概念,其非线性有电压影响型、电流影响型等。
电感
电感的原理:电感——电势能→电流→磁场能,&磁场能→电势能(若有负载,则→电流)。
当电源电势加在电感线圈两端,电荷在电势差作用下流动——形成了电流,电流转变磁场,这称为“充磁”过程。若被充磁电感线圈两端的电源电势差撤销,且电感线圈外接有负载,则磁场能在衰减的过程中转换为电能(如负载为电容,则为电场能;若负载为电阻,则为电流),这称为“去磁”过程。
衡量电感线圈充磁多少的单位是磁链——Ψ。电流越大,电感线圈被冲磁链就越多,即磁链与电流成正比,即Ψ=L*I。对一个指定电感线圈,L是常量。
因此,用L=Ψ/I表达电感线圈的电磁转换能力,称L为电感量。电感量的微分表达式为:L=dΨ(t)/di(t)。
根据电磁感应原理,磁链变化产生感应电压,磁链变化越大则感应电压越高,即v(t)=d dΨ(t)/dt。
综合上面两公式得到:v(t)=L*di(t)/dt,即电感的感应电压与电流的变化率(对时间的导数)成正比,电流变化越快则感应电压越高。
电容
电容的原理:电势能→电流→电场能,电场能→电流。
当电源电势加在电容的两个金属极板上,正负电荷在电势差作用下分别向电容两个极板聚集而形成电场,这称为“充电”过程。若被充电电容两端的电源电势差撤销,且电容外接有负载,则电容两端的电荷在其电势差下向外流走,这称为“放电”过程。电荷在向电容聚集和从电容两个极板向外流走的过程中,电荷的流动就形成了电流。
要特别注意,电容上的电流并不是电荷真的流过电容两个极板间的绝缘介质,而只是充电过程中电荷从外部向电容两个极板聚集形成的流动,以及放电过程中电荷从电容两个极板向外流走而形成的流动。也就是说,电容的电流其实是外部电流,而非内部电流,这与电阻、电感都不一样。
衡量电容充电多少的单位是电荷数——Q。电容极板间电势差越大,说明电容极板被冲电荷越多,即电荷数与电势差(电压)成正比,即Q=C*V。对指定电容,C是常量。
因此,用C=Q/V表达电容极板贮存电荷的能力,称C为电容量。
电容量的微分表达式为:C=dQ(t)/dv(t)。
因为电流等于单位时间内电荷数的变化量,即i(t)=dQ(t)/dt,综合上面两个公式得到:i(t)=C*dv(t)/dt,即电容电流与其上电压的变化率(对时间的导数)成正比,电压变化越快则电流越大。
小结:v(t)=L*di(t)/dt
表明电流变化形成了电感的感应电压(电流不变则没有感应电压形成)。
i(t)=C*dv(t)/dt表明电压变化形成了电容的外部电流(实际是电荷量变化。电压不变则没有电容的外部电流形成)。
元件对信号相位的改变
首先要提醒,相位的概念是针对正弦信号而言的,直流信号、非周期变化信号等都没有相位的概念。
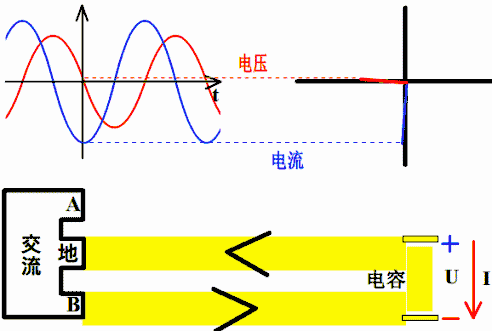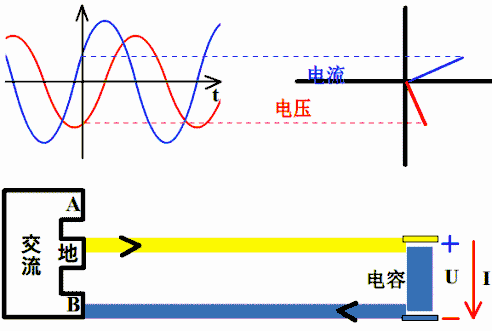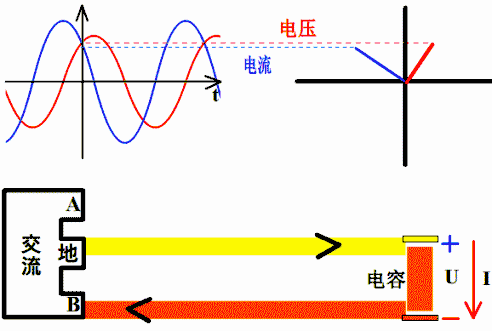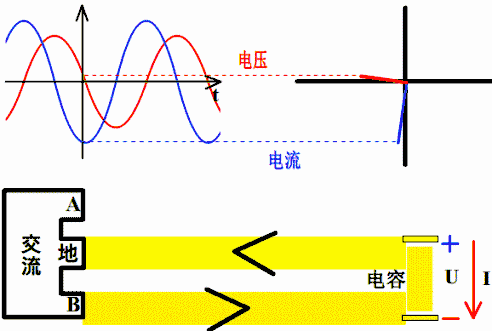
电阻上的电压电流同相位
因为电阻上电压v(t)=R*i(t),若i(t)=sin(ωt+θ),则v(t)=R* sin(ωt+θ)。所以,电阻上电压与电流同相位。
电感上的电流落后电压90°相位
因为电感上感应电压v(t)=L*di(t)/dt,若i(t)=sin(ωt+θ),则v(t)=L*cos(ωt+θ)。 所以,电感上电流落后感应电压90°相位,或者说感应电压超前电流90°相位。
直观理解:设想一个电感与电阻串联充磁。从充磁过程看,充磁电流的变化引起磁链的变化,而磁链的变化又产生感应电动势和感应电流。根据楞次定律,感应电流方向与充磁电流相反,延缓了充磁电流的变化,使得充磁电流相位落后于感应电压。
电容上的电流超前电压90°相位
因为电容上电流i(t)=C*dv(t)/dt,若v(t)=sin(ωt+θ),则i(t)=L*cos(ωt+θ)。
所以,电容上电流超前电压90°相位,或者说电压落后电流90°相位。
直观理解:设想一个电容与电阻串联充电。从充电过程看,总是先有流动电荷(即电流)的积累才有电容上的电压变化,即电流总是超前于电压,或者说电压总是落后于电流。
下面的积分方程能体现这种直观性:
v(t)=(1/C)*∫i(t)*dt=(1/C)*∫dQ(t),即电荷变化的积累形成了电压,故dQ(t)相位超前v(t);而电荷积累的过程就是电流同步变化的过程,即i(t)与dQ(t)同相。因此i(t)相位超前于v(t)。
元件相位差的应用
RC文氏桥、LC谐振过程的理解
无论RC文氏桥,还是LC的串联谐振、并联谐振,都是由电容或/和电感容元件的电压、电流相位差引起的,相x关文章:还没搞懂电压、电流的超前与滞后?就像机械共振的节拍一样。
当两个频率相同、相位相位的正弦波叠加时,叠加波的幅度达到最大值,这就是共振现象,在电路里称为谐振。
两个频率相同、相位相反的正弦波叠加,叠加波的幅度会降到最低,甚至为零。这就是减小或吸收振动的原理,如降噪设备。
当一个系统中有多个频率信号混合时,如果有两个同频信号产生了共振,那么这个系统中其它振动频率的能量就被这两个同频、同相的信号所吸收,从而起到了对其它频率的过滤作用。这就是电路中谐振过滤的原理。
谐振需要同时满足频率相同和相位相同两个条件。电路如何通过幅度-频率特性选择频率的方法以前在RC文氏桥中讲过,LC串并联的思路与RC相同,这里不再赘述。
下面我们来看看电路谐振中相位补偿的粗略估计(更精确的相位偏移则要计算)
RC文氏桥的谐振(图1)
若没有C2,正弦信号Uo的电流由C1→R1→R2,通过R2上压降形成Uf输出电压。由于支路电流被电容C1移相超前Uo 90°,这超前相位的电流流过R2(电阻不产生相移!),使得输出电压Uf电压超前于Uo 90°。
在R2上并联C2,C2从R2取得电压,由于电容对电压的滞后作用,使得R2上电压也被强制滞后。(但不一定有90°,因为还有C1→R1→C2电流对C2上电压即Uf的影响,但在RC特征频率上,并联C2后Uf输出相位与Uo相同。)
小结:并联电容使得电压信号相位滞后,称为电压相位的并联补偿。

LC并联谐振(图2)
若没有电容C,正弦信号u通过L感应到次级输出Uf,Uf电压超前于u 90°;在L初级并联电容C,由于电容对电压的滞后作用,使得L上电压也被强制滞后90°。因此,并联C后Uf输出相位与u相同。
LC串联谐振(图3)
对于输入正弦信号u,电容C使得串联回路中负载R上的电流相位超前于u 90°,电感L则使得同一串联回路中的电流相位再滞后90°二者相位偏移刚好抵消。因此,输出Uf与输入u同相。
总结
注意,相位影响不一定都是90°,与其它部分相关,具体则要计算。
- 串联电容使得串联支路电流相位超前,从而影响输出电压相位。
- 并联电容使得并联支路电压相位滞后,从而影响输出电压相位。
- 串联电感使得串联支路电流相位滞后,从而影响输出电压相位。
- 并联电感使得并联支路支路电压超前,从而影响输出电压相位。
更简洁的记忆:
在元件上的电流或电压,电容使电流相位超前,电感使电压相位超前。
..
八、电压、电流的超前与滞后
电压电流的超前与滞后这个概念是相对于电流和电压之间的关系而说的。也就是说,比如是容性负载(电容器),那么他会导致最终电流超前90度,如果是电感则产生最终电流超前-90度(即滞后90度) 反过来说,在平面直角坐标系中,假设电压为X轴水平方向,则是否超前则为Y轴垂直方向,当为容性负载时为Y正半轴部分,感性负载为Y负半轴部分 无论是正超前还是负超前(滞后)都会导致功率因数下降,而纯阻性负载其超前角是0度,这个时候功率因数为1 正因为容性和感性具有这种相反的性质,那么当使用电动机等感性负载时,会导致严重的负超前,这个时候就应当使用足够的电容器进行补偿,使其无限逼近0度,保证功率因数无限的逼近1。总之,功率因数下降,无论是正超前还是负超前都回导致下降,只有为0时才是最高的,而感性负载一应用就肯定是负的了。所以就要用电容补偿让他接近0。
如下图,由于Sin[ωt]在求导或积分后会出现Sin[ωt±90°],所以对于接上了正弦波的电感、电容,横坐标为ωt时可以观察到波形超前滞后的现象,直接从静态的函数图上看不太容易理解,还是做成动画比较好。用红色表示电压,蓝色表示电流。如果接上理想的直流电压表、直流电流表,可以观察到电压的变化超前于电流,电流的变化滞后于电压。时间增加时,纵坐标轴及时间原点会随着波形一起往左移动。
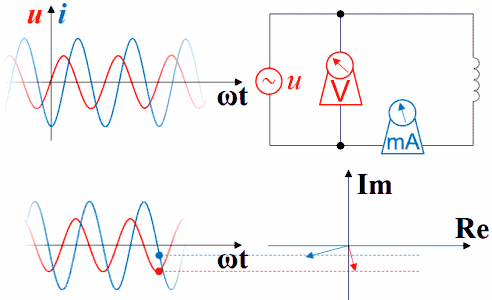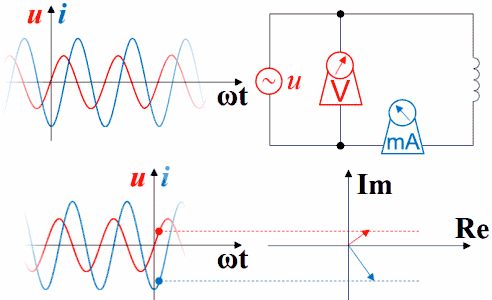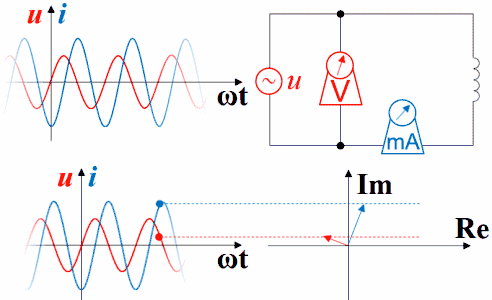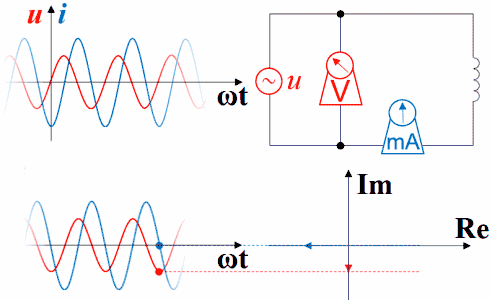
如果把波形画在矢量图右方,就是下面这种动画,但横坐标右方是过去存在的波形,指向过去,是-ωt。虽然波形反过来了,但电压的变化仍然超前于电流,电流的变化仍然滞后于电压。时间原点一直随着波形往右方移动,函数图中的纵坐标轴并未与横坐标交于原点,交点所代表的时间一直在增加。如果不注意,超前滞后的判断很容易出错。
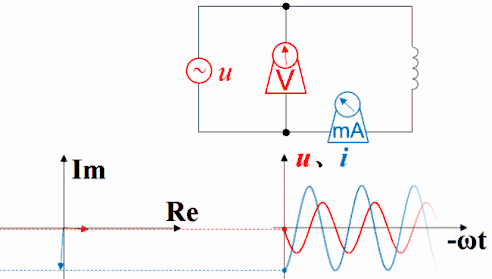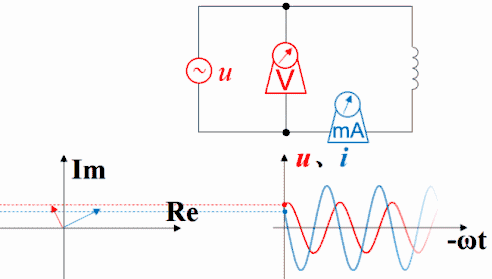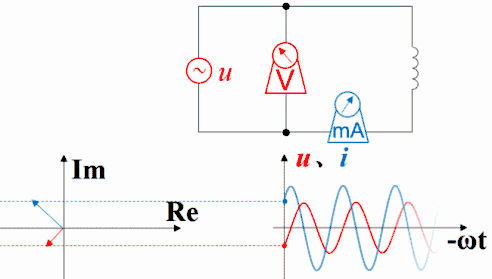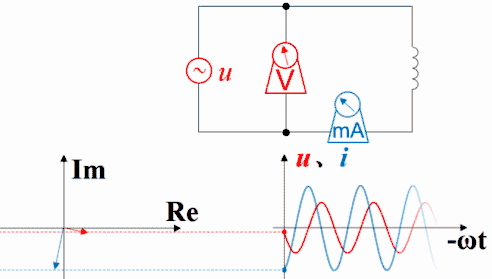
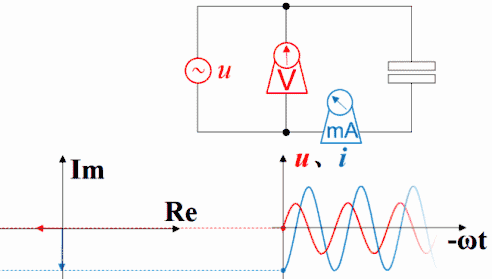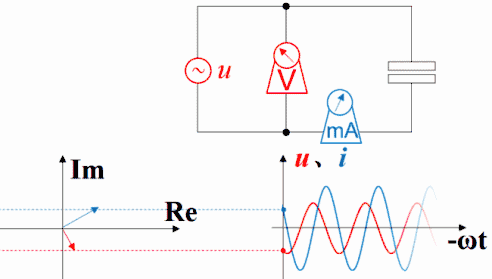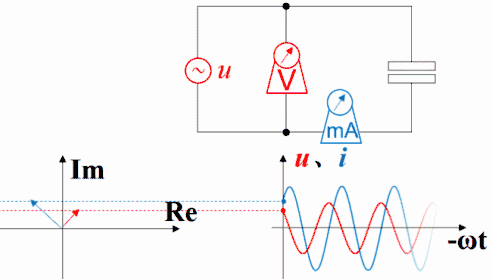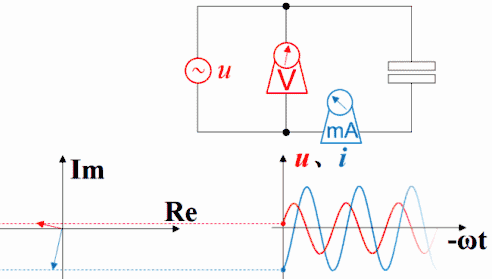
理解超前滞后这一概念用相量图是最好的,从测量数据来观察或者从静态波形上观察都不太直观而且容易出错。下图是电容的。电压的变化滞后于电流,电流的变化超前于电压。坐标系右方是未来,左方是过去。
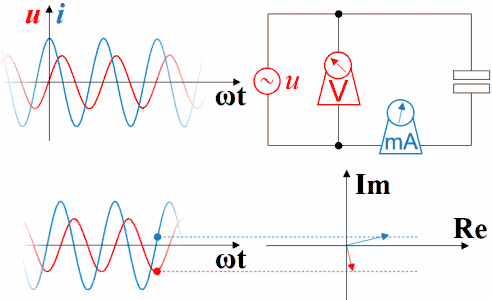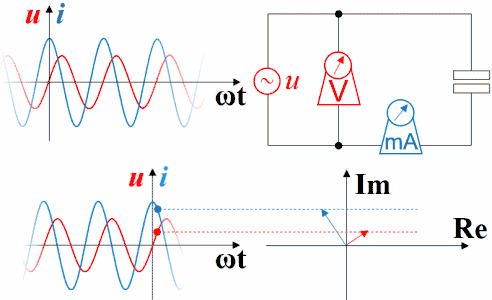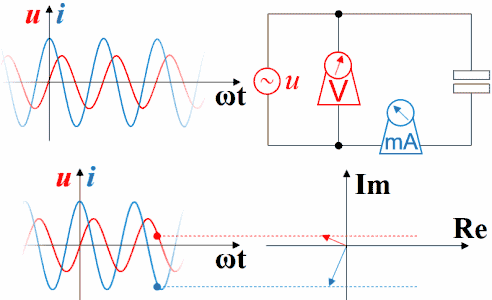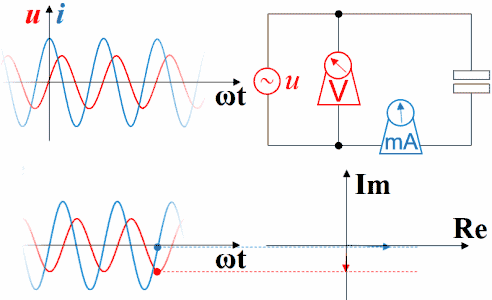
横坐标是-ωt时,电容的电压的变化仍然滞后于电流,电流的变化仍然超前于电压。因为此坐标系左方是未来,而右方是过去。
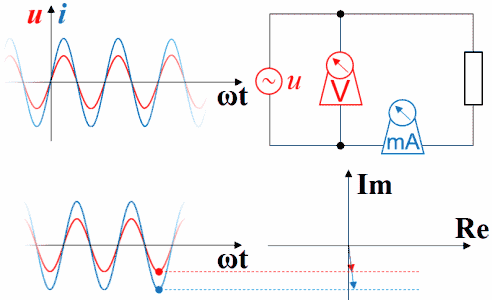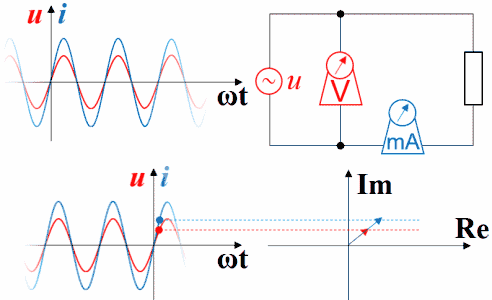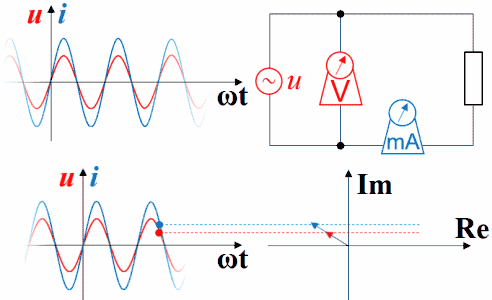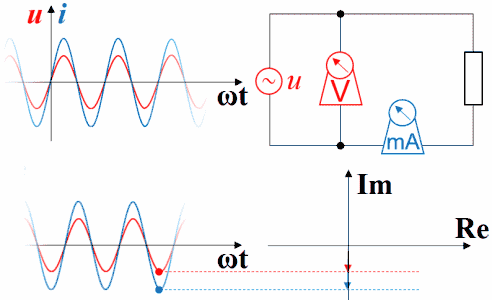
下图是电阻的。电压函数电流函数同相。
下图是三者串联的情况,没画相量图和波形图。但从指针的变化可以判断:电流相同时,电感和电容的电压函数反相。
没画总电压,因为总电压有可能超前于总电流,也有可能滞后于总电流,也有可能两者同相,同相时为谐振状态。
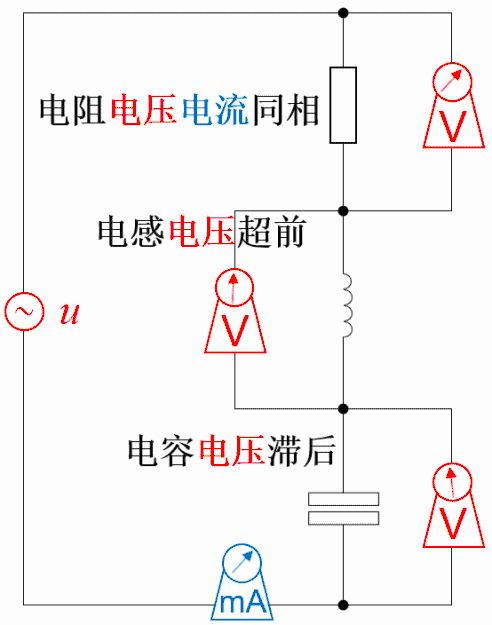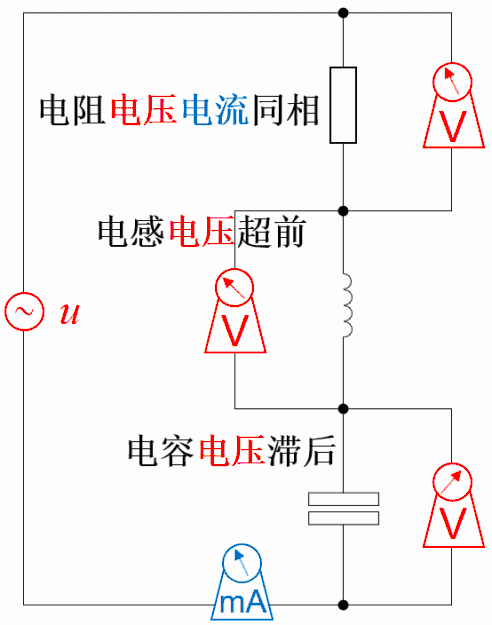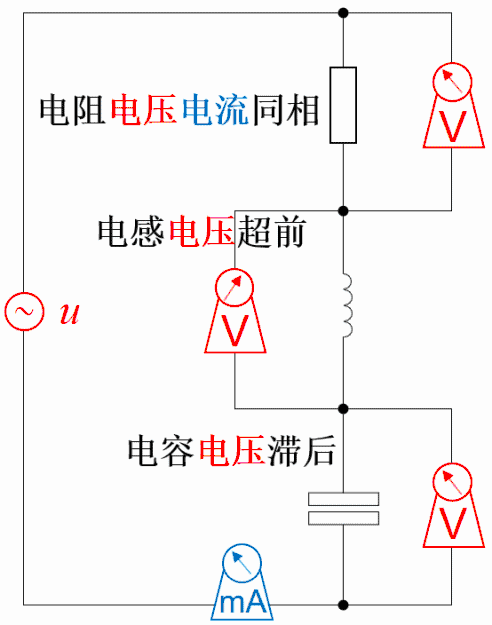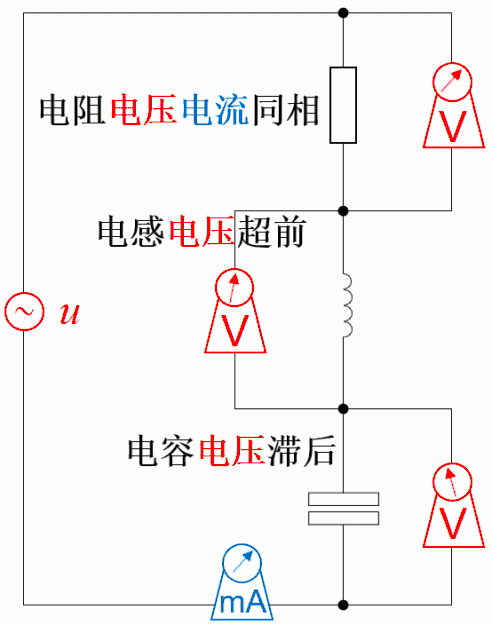
以前还做过这种,元件右边标的是电压电流的参考方向。用不同的颜色描述电压的大小,蓝色>黄色>红色;用不同的粗细和箭头描述电流的大小和方向,而且把电感、电容充能的效果也做进去了,电流最大时电感磁场能最大,电容电场能最小。
但是,就解释超前滞后这一概念的话,指针表的动画更直观。
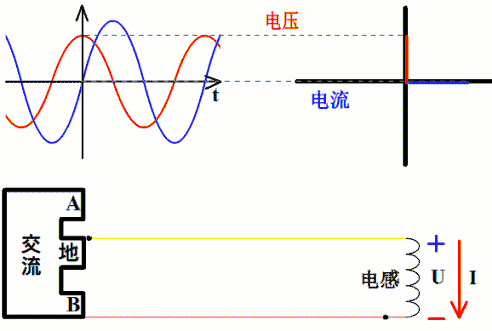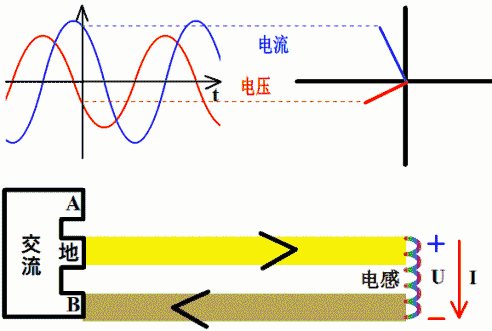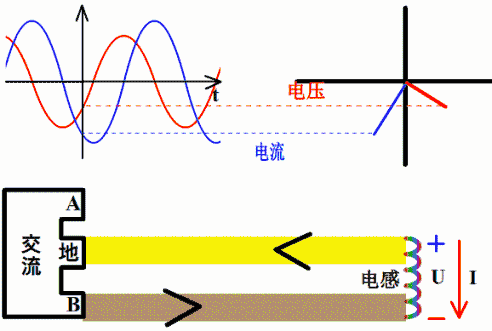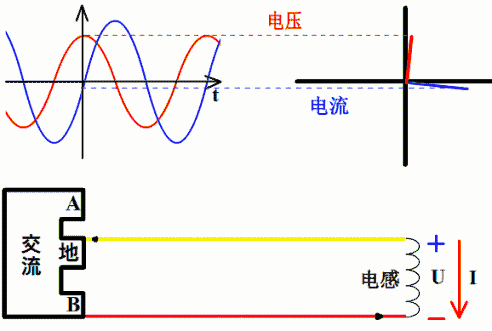
..
九、MCU那些开眼的用法
单片机是一个控制器件,除了控制外设还能有哪些不按常理的用法?看知乎大神的分享。知乎上,有一个非常火的问题——“MCU都有什么高级用法?”
知乎:
都说MCU本身不算什么高级东西,在MCU开发过程中,需要按照一定的标准化来执行,比如对变量,函数的定义,要确定他的生命周期,调用范围,访问条件等;常用的通信协议读写的协议往往应该抽象化,规定固定的输入输出,方便产品移植。
但实际上,很多时候,针对同一个需求其实有多种实现方案,但总有一个最优解。所以在这个过程中,总会有一些“脑洞大开”的操作,为人提供很多思路,今天就举几个例子给大家作为参考。
那些很惊艳的用法
当需要通过串口接收一串不定长数据时,可以使用串口空闲中断;这样就可以避免每接收到一个字符就需要进入中断进行处理,可以减少程序进入中断次数从而提高效率。
当需要测量一个波形的频率时,很多人会选择外部中断,其实通过定时器的外部时钟输入计数波形边沿,然后定时读取计数指计算频率的方式可以大大减少中断触发频率,提高程序执行效率。
在处理复杂的多任务场景时,可以利用实时操作系统(RTOS)来管理任务调度,提高系统的响应性和资源利用率。
对于需要低功耗运行的场景,可以采用动态电压频率调整(DVFS)技术,根据系统负载实时调整 MCU 的工作电压和频率,以降低功耗。
在进行数据存储时,采用闪存的磨损均衡算法,延长闪存的使用寿命。
利用硬件加密模块(如 AES 加密引擎)来保障数据的安全性和保密性,而不是通过软件实现加密,提高加密效率和安全性。
对于传感器数据的处理,采用数字滤波算法(如卡尔曼滤波),提高数据的准确性和稳定性。
当需要与多个设备进行通信时,采用总线仲裁机制和优先级设置,确保通信的高效和稳定。
在进行电源管理时,通过监测电源电压和电流,实现智能的电源管理策略,例如在低电量时进入低功耗模式。
对于实时性要求极高的控制任务,采用硬件直接触发中断,而不是通过软件轮询,减少响应延迟。
在单片机上跑的任何非线性系统的动态控制,都是高级用法。
用单片机去实现某种特殊的运动控制,赚很多钱,就是高级用法。
GPIO模拟一切
名为ShiinaKaze的网友,就非常“勇”,做了一个很折磨的事。
他用STM32F1利用GPIO模拟摄像头接口驱动OV2640摄像头模块。他表示,这是一个很折磨人的过程,我最多优化到了 1.5 FPSQ,所以选型一定要选好,不要折磨自己。设备采用STM32F103C8T6,OV2640,实现效果如下:

OV2640实际时序图:

这个项目难点在于:1.SCCB 模拟:SCCB 是12C-bus 的改版,主要是 OV2640 模块没有上拉电阻,无法进行通信,花了好长时间才发现这个问题;2.并行接口的模拟:如果使用 IO 模拟的话,只能达到1FPS,但是使用了 Timer 和 DMA,就可以达到 1.5~2 FPS。
关于 image sensor 的数据接收和处理的问题背景:现有 ov2640 image sensor,接口为 DCMI(并行接口)问题:现有 STM32H7 想获取 OV2640 的 mjpeg 流数据,并通过传输数据到 PC 软件1.采用 USART 还是 USB?2.接收数据选择哪种中断,Line interrupt 还是 Frame interrupt ?3.DCMI 通过 DMA 将数据转到 RAM 中的 Buffer,那么 Buffer 该如何设计,是设置一块大的连续 buffer?还是需要做一个 ring buffer,避免数据覆盖和数据顺乱?4.触发中断后,是否关闭 DCMI 和 DMA ?
嵌入式软件架构挺重要的,特别是大型项目。这是 STM32 的软件架构,不知道各位还有没有其他架构。
有网友吐槽,你要是在学校,我敬你是条汉子,你要是在工作岗位上干这鸟事,那你们的架构也太坏了。而他也表示——“我错了,再也不模拟了。”

关于MCU不一样的观点
虽然如此,很多人还是认为,MCU不高级,使用单片机也不高级。高级的内容都是可以发论文的,使用单片机发不了论文。但使用单片机解决指定的任务,这很高级。
尤其是上面所说的一些例子,确实是MCU外设的一些高端玩法。只不过,这些机制可能只是一种标准用法。名为lion187的网友就表示,毕竟许多硬件机制有实际需求后才添加进来的,比如接收不定长数据,最初没有超时中断的情况下只能软件实现,极大的浪费了CPU的效率,所以才设计了超时中断来减少软件工作量,进而形成了一种标准使用方法。
当然,这也是芯片设计和制造工艺的提升带来的红利,早期芯片设计和工艺无法满足复杂外设电路时,谁也不敢会去想用硬件来实现这么复杂的功能,任何产品的开发,都离不开具体业务需求,MCU也不例外,对产品来说,MCU外设的驱动只是完成开发的基本要素,更多的工作是围绕着业务逻辑展开的应用程序的开发。这时候数据结构与算法,各种控制算法和数值计算方法,设计模式,软件工程和设计理念成了高级的东西。
比如说,Linux 内核中的各驱动子系统的设计,设备对象和驱动对象这些沿用了 C++ 面向对象编程的思路,其实也可以沿用到 MCU的开发中,将设备与驱动分离,就可以使用同一套驱动算法来实现同类设备的不同驱动方法,比如:同一个 UART 驱动可以根据配置的不同来驱动 UARTO,也可以驱动 UART1,而且波特率也可以不同(只要为 UART 类创建不同的实例对象就可以了,用 C 语言就行),这就是 C++ 中方法与属性分离带来的好处。
同样在业务应用部分,单件模式、工厂模式等设计模式,状态机模型的使用也会给开发带来很多便利,使系统结构清晰,有效减少Bug数量,且易于维护和扩展。
当然,也有人认为,论高级还得是FPGA。就比如AMD(赛灵思)的ZYNQ,当你需要通过串口接收一串不定长数据时,可以直接用Programmable Logic部分写一个专用的,最终结果放到DRAM里,发个信号通知ARM处理器来读就好了;当你需要测量一个波形的频率时,可以直接用Programmable Logic部分写一个专用的,实时不间断测量。这就很高级。

.
十、STM32单片机中Hex、Bin
STM32、51等单片机程序经过编译后,生成的hex文件、bin文件,它们都是单片机烧写文件,本文介绍它们的区别与应用。
Hex文件
Keil5中生成hex文件的配置
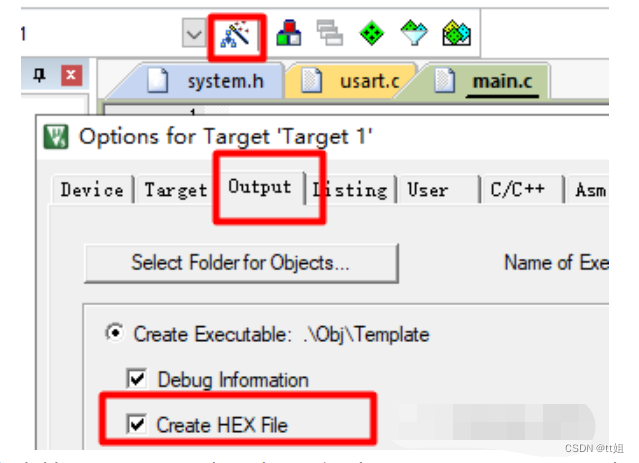
如上图,分别点击“魔术棒”-“Output选项卡”,勾选“Create HEX File”选项,确认即可。
STM32CubeIDE中生成hex文件的配置
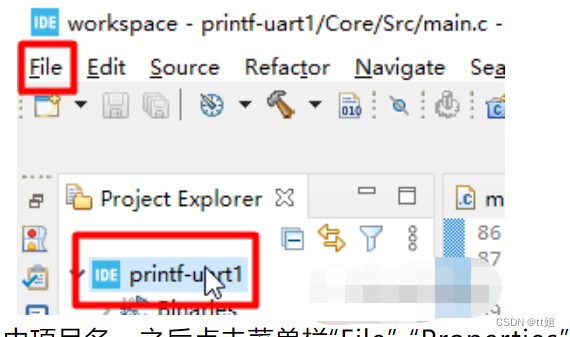
如上图,先用鼠标点击选中项目名,之后点击菜单栏“File”-“Properties”。
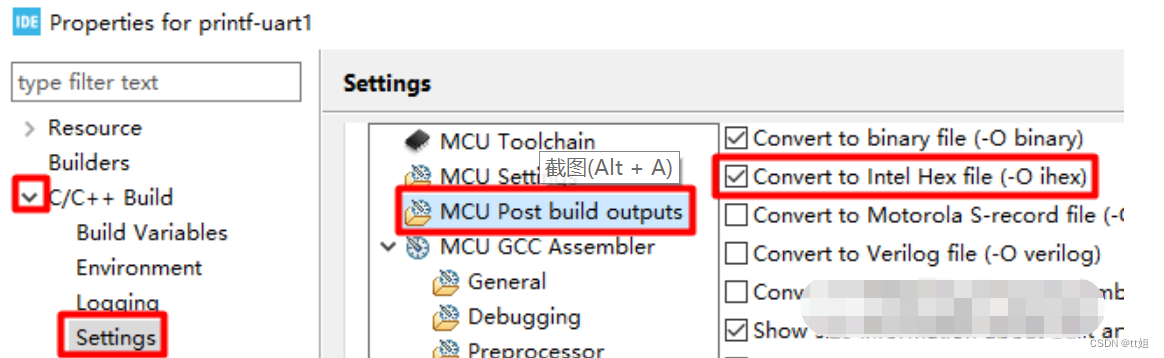
如上图红框处,依次点击“C/C++ Build”-“MCU Post build outputs”,勾选“Convert to Intel Hex file”,应用并关闭窗口。
hex烧写
用ISP方式烧写程序,首先找来ISP烧写软件,之后进行如下步骤:
- 选择芯片型号
- 选择串口号
- 设置波特率,可以默认为115200
- “打开文件”,选择要下载的hex文件
- 点击“程序下载”,开始烧写程序
带ISP下载功能的串口工具如下图所示。
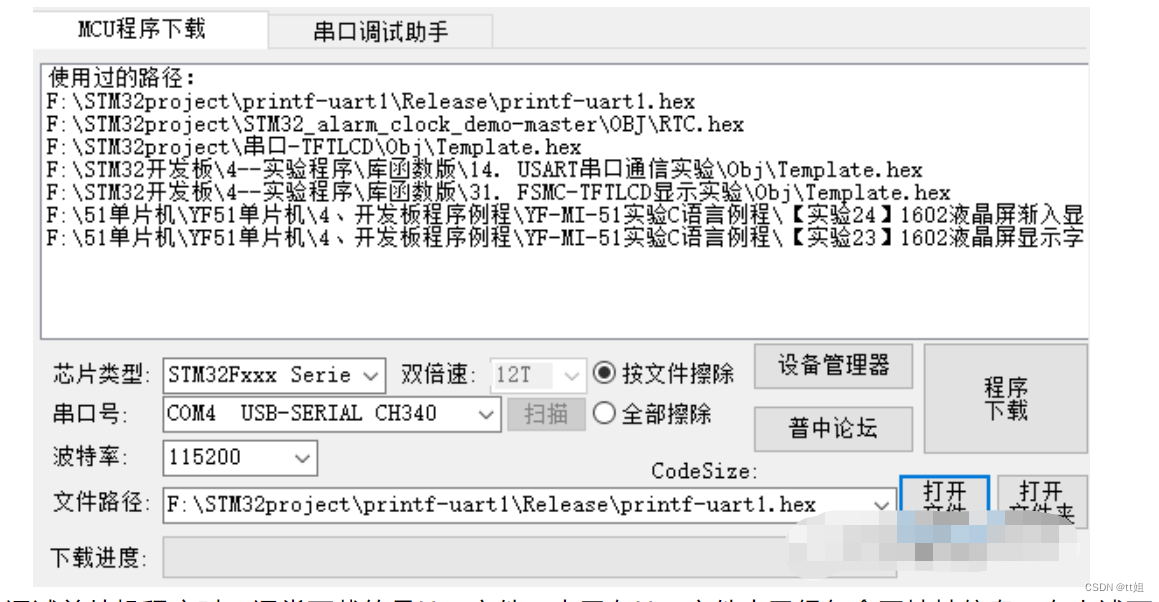
调试单片机程序时,通常下载的是Hex文件。由于在Hex文件中已经包含了地址信息,在上述下载步骤中不需要设置内存地址。
BIN文件
Keil5中生成Bin文件配置
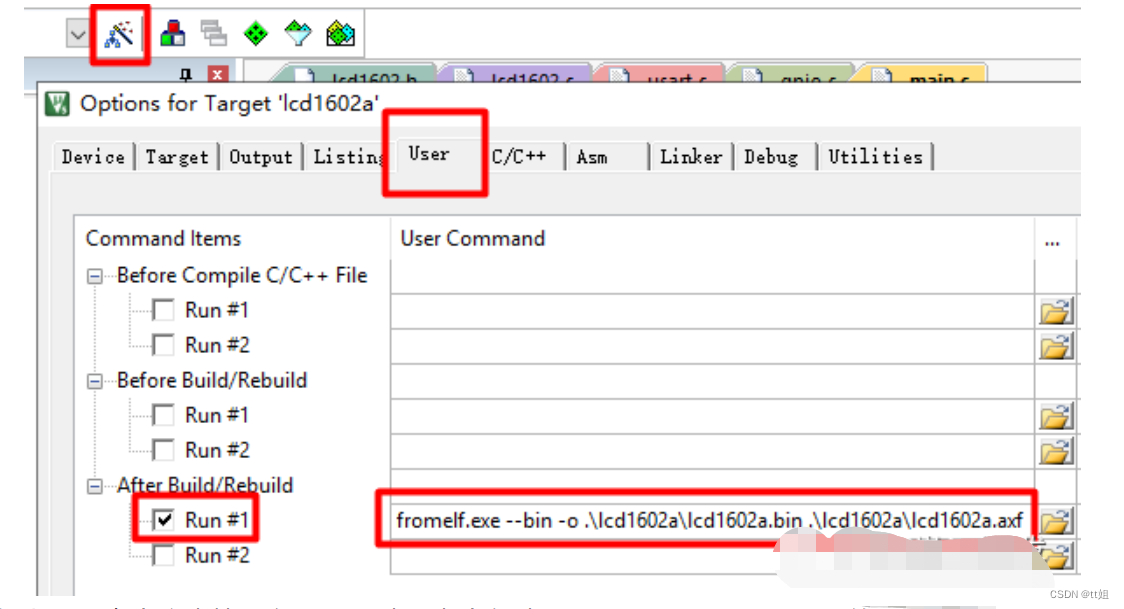
如上图,点击魔术棒,在“User”选项卡中勾选“After Build/Rebuild”下的“Run #1”。
在后面“User Command”一栏中填写如下用户自定义命令:
fromelf.exe --bin -o .\lcd1602a\lcd1602a.bin .\lcd1602a\lcd1602a.axf
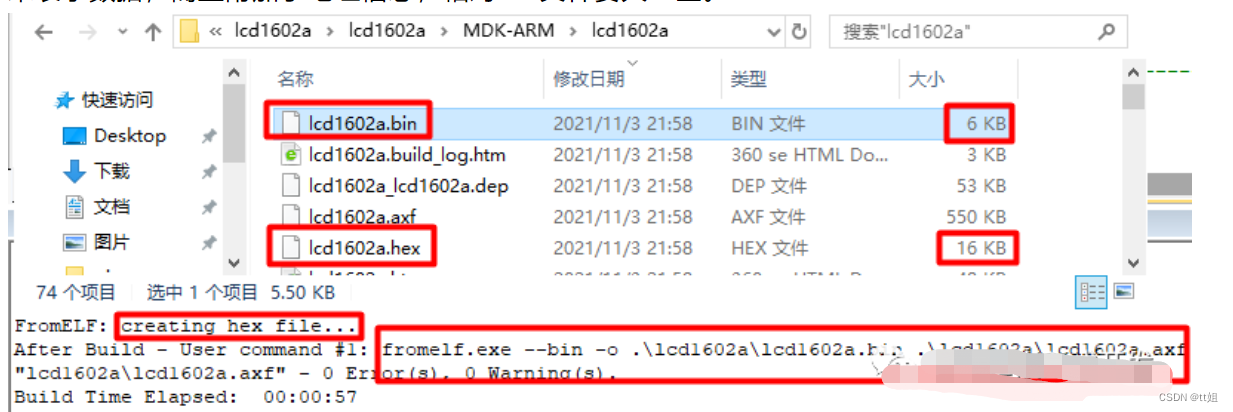
这个自定义命令在编译生成Hex文件之后执行,通过“formelf.exe”工具生成基于.axf文件的.bin文件。如下图,按修改时间排序也可以知道.bin文件是在.axf文件之后生成的。Hex文件是用ASCII来表示数据,而且附加了地址信息,相对Bin文件要大一些。
STM32CubeIDE中生成Bin的配置
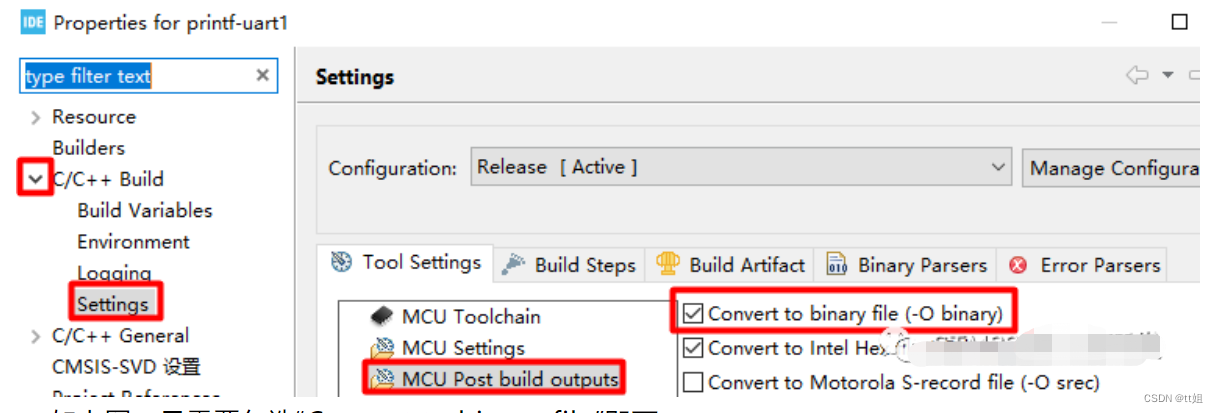
如上图,只需要勾选“Convert to binary file”即可。
延庆川北小区45孙老师 东屯 收卖废品破烂垃圾炒股 废品孙
二、设计单片机的通信协议
通信设计中考虑协议的灵活性,经常把协议设计成“不定长度”。
一个实例如下图:锐米LoRa终端的通信协议帧。
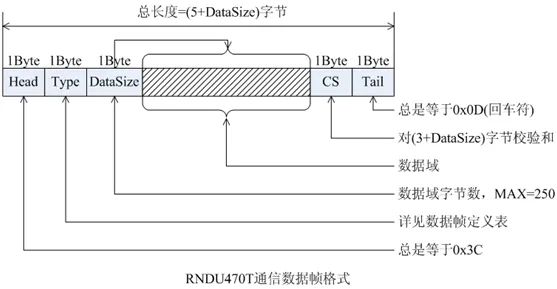
如果一个系统接收上述“不定长度”的协议帧,将会有一个挑战--如何高效接收与解析。
为简化系统设计,我们强烈建议您采用“状态机”来解析UART数据帧,并且把解析工作放在ISR(中断服务程序)完成,仅当接收到最后一个字节(0x0D)时,再将整个数据帧提交给进程处理。
该解析状态机的原理如下图所示:
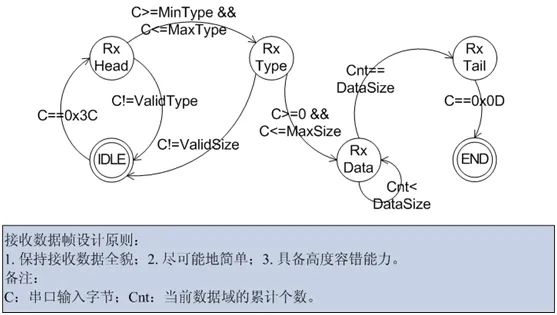
那么ISR处理这个状态机来得及吗?答案是:so easy!因为它只有3个动作,运算量十分小:
比较接收数据 -> 更新状态变量 -> 存储接收数据,C语言仅3条语句,翻译成机器指令也不超过10条。
代码清单如下:
/**
* @brief Status of received communication frame
*/
typedef enum
{
STATUS_IDLE = (uint8_t)0,
STATUS_HEAD, /* Rx Head=0x3C */
STATUS_TYPE, /* Rx Type */
STATUS_DATA, /* Data filed */
STATUS_TAIL, /* Tail=0x0D */
STATUS_END, /* End of this frame */
} COMM_TRM_STATUS_TypeDef;
/**
* @brief Data object for received communication frame
*/
typedef struct
{
uint8_t byCnt; /* Count of 1 field */
uint8_t byDataLen; /* Length of data field */
uint8_t byFrameLen; /* Length of frame */
COMM_TRM_STATUS_TypeDef eRxStatus;
uint8_t a_byRxBuf[MAX_LEN_COMM_TRM_DATA];
} COMM_TRM_DATA;
/**
* @brief Data object for received communication frame.
* @note Prevent race condition that accessed by both ISR and process.
*/
static COMM_TRM_DATA s_stComm2TrmData;
/**
* @brief Put a data that received by UART into buffer.
* @note Prevent race condition this called by ISR.
* @param uint8_t byData: the data received by UART.
* @retval None
*/
void comm2trm_RxUartData(uint8_t byData)
{
/* Update status according to the received data */
switch (s_stComm2TrmData.eRxStatus)
{
case STATUS_IDLE:
if (COMM_TRM_HEAD == byData) /* Is Head */
{
s_stComm2TrmData.eRxStatus = STATUS_HEAD;
}
else
{
goto rx_exception;
}
break;
case STATUS_HEAD:
if (TYPE_INVALID_MIN < byData && byData < TYPE_INVALID_MAX) /* Valid type */
{
s_stComm2TrmData.eRxStatus = STATUS_TYPE;
}
else
{
goto rx_exception;
}
break;
case STATUS_TYPE:
if (byData <= MAX_LEN_UART_FRAME_DATA) /* Valid data size */
{
s_stComm2TrmData.eRxStatus = STATUS_DATA;
s_stComm2TrmData.byDataLen = byData;
}
else
{
goto rx_exception;
}
break;
case STATUS_DATA:
if (s_stComm2TrmData.byCnt < s_stComm2TrmData.byDataLen)
{
++s_stComm2TrmData.byCnt;
}
else
{
s_stComm2TrmData.eRxStatus = STATUS_TAIL;
}
break;
case STATUS_TAIL:
if (COMM_TRM_TAIL == byData)
{
/* We received a frame of data, now tell process to deal with it! */
process_poll(&Comm2TrmProcess);
}
else
{
goto rx_exception;
}
break;
default:
ASSERT(!"Error: Bad status of comm2trm_RxUartData().\r\n");
break;
}
/* Save the received data */
s_stComm2TrmData.a_byRxBuf[s_stComm2TrmData.byFrameLen++] = byData;
return;
rx_exception:
ClearCommFrame();
return;
}..
十一、让代码中包含最新的编译时间信息
如何保证发布出去的bin文件是最终测试通过的版本?
一般的来讲,代码到了测试后期,master分支就不会频繁的提交了,并且提交也会更加谨慎。
但是人为操作总会出现纰漏,希望只要代码被重新编译过,那么bin文件就包含新的时间信息,而这个信息是可以从外部通信或printf来查看的。
在嵌入式开发中,版本号一般的都是一个int变量或字符串变量。但是若修改了代码而没有改version变量或宏定义,那么从version上就看不出来文件的变化。
那么最终编译的版本到底是哪个版本,是否与测试的版本完全一致,这个问题尤为突出。
目标文件中带有编译时间可以防止代码被改动过,只要代码被重新编译,那么就生成新的时间信息。
git能够记录文件修改信息,但是调试信息或工程配置等,很多文件都是ignore的,这些信息代表着最终的bin文件的运行环境。
某些复杂bug情况下,只有运行环境一致,仿真器才能attach到目标文件。
如何获取时间信息
这两个宏是日期和时间,格式如下。如果把这两个宏加入到代码,那么就得到了时间的字符串信息。
// Example of __DATE__ string: "Dec 27 2017"
// Example of __TIME__ string: "15:06:19"
const char *BuildInfo = "Version: " VERSION " " __DATE__ " " __TIME__;代码实现获取日期和时间的方法很多,比如:
unsigned int mk_Build_Date(void)
{
int year = 0, month = 0, day = 0;
int hour = 0, minute = 0, seconds = 0;
char m[4] = {0};
sscanf(__DATE__, "%3s %2d %4d", m, &day, &year);
for (month = 0; month < 12; month++)
{
if (strcmp(m, short_char_months[month]) == 0)
{
break;
}
}
sscanf(__TIME__, "%2d:%2d:%2d", &hour, &minute, &seconds);
#ifdef SHORT_DATA_CHAR__
printf("[null] ** Build at:\t%04u-%02u-%02us %02u:%02u:%02u\n",
year, month, day,
hour, minute,seconds);
#else
printf("[null] ** Build at:\t%04u-%02u-%02u %02u:%02u:%02u\n",
year, month, day,
hour, minute,seconds);
#endif
DEBUG("buildDate: %s %s\n", __DATE__, __TIME__);
return0;
}把上面的函数加入到代码中,就能获取工程编译的时间。
但是如果该代码所在的文件没有被修改,在非build-all情况下,编译器不会再次编译此文件,所以时间信息也就不会被更新。
如果每次都使用re-build all,一来繁琐,二来也不能保证每次都会记得点击build all按钮,靠技术手段来保证每次build都更新时间信息才是正道。
如何保证每次编译都更新时间信息
使用预编译指令,每次更新包含时间宏的文件或对应的链接文件。
在IAR环境下,官方已经给出了解决的方法(Using pre-build actions for time stamping)。
https://www.iar.com/support/tech-notes/ide/build-actions-pre-build-and-post-build/
方法1:修改文件的时间,引起编译器对文件进行重新编译。
cmd /c "touch /cygdrive/d/test.c"方法虽好,可惜IAR用户大多数是Windows用户,包括我在内,touch是linux命令,必须Cywin环境。如果安装过这个环境的话,那就大功告成了。
Cygwin touch command
You can enter "cygwin-application.exe" on the pre- and post-build command lines, if the environment variable PATH includes the directory where the "cygwin-application.exe" is located.
You can run the Cygwin command"touch" on the pre-build command line, but if you add a file path, for example "touch d:/test.c", the file path is not accepted by Cygwin.
Cygwin expects the POSIX path /cygdrive/d/test.c so the resulting command line would be "touch /cygdrive/d/test.c", however this command cannot be executed directly on the pre- and post-build command. Instead you have to run indirectly using:
cmd /c "touch /cygdrive/d/test.c"
The .bat file (located in project directory) alternative would look like:
Pre-build command line:
$PROJ_DIR$\pre-build.bat
File pre-build.bat:
touch /cygdrive/d/test.c方法2:修改文件对应的链接文件,触发编译器重新编译该文件,生成新的链接文件,那么就会生成新的带有时间信息的目标文件。
An alternative to the "touch"command is to have a pre-build action that deletes the object file, for example the Pre-build command line:
cmd /c "del "$OBJ_DIR$\test.o""在pre-build中加入上面的命令,就会在编译前删除test.o文件。
在这种模式下,工程代码只要任何位置发生变化,代码重新编译,就会触发删除test.o,然后链接过程发现没有test.o文件,那么就会重新编译一次test.c,那么新的时间信息就会记录下来了。
虽有些曲线救国的味道,但还是很顺利的实现了目标。
只要工程的任何地方有改动,生成新的目标文件,那么目标文件中就会带有最新的编译时间。
方法3:直接告诉编译器每次重新编译某个文件更直接,MDK支持此功能。
实际上,如果对工具多一些了解,万万是不会用上面的方法的,当然上面的方法也是通用想法,是通用型知识点,容易想到,也能达到目标。
新的方法,不需要写任何脚本,如果想让代码每次都编译更新DATA 和 TIME两个宏,那么让这个文件每次都编译一次就可以了,不需要删除它的obj文件然后让编译器找不到文件而触发重新编一次,其实直接告诉编译器每次重新编译更直接,MDK支持此功能。

下面是测试的效果:

其它资料:
...
十二、xx

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 24
24 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)