
基于Jetson TK1的生物信息学平台
本文构建了基于NVIDIA Jetson TK1的生物信息学平台,实现了序列比对工具ClustalWtk和化合物比较工具MCCtk,并提供网页与移动服务界面。实验表明,该平台在低功耗下实现显著加速,性价比优于传统桌面GPU方案,适用于移动和嵌入式高性能计算场景。
基于NVIDIA Jetson TK1构建具有网络和移动服务的生物信息学平台
摘要
当前高端图形处理单元(简称GPU),如英伟达特斯拉、费米、开普勒系列显卡,每芯片可包含多达上千个核心,已广泛应用于高性能计算领域。这些GPU显卡(称为桌面GPU)需安装在配备桌面CPU的个人计算机/服务器中;此外,使用这些桌面CPU和GPU构建高性能计算平台的成本和功耗较高。英伟达发布了Tegra K1,即Jetson TK1,其包含4个ARM Cortex-A15 CPU和192个CUDA核心(开普勒GPU),是一款具有低成本、低功耗和高适用性优势的嵌入式板卡,适用于嵌入式应用。
NVIDIA Jetson TK1因此成为一个新的研究方向。本文基于NVIDIA Jetson TK1构建了一个生物信息学平台,并在该平台上分别设计了用于序列比对和化合物比较的ClustalWtk和MCCtk工具。同时,还为这两个工具提供了具有用户友好界面的网页和移动服务。实验结果表明,NVIDIA Jetson TK1的性价比高于Intel Xeon E5-2650 CPU和NVIDIA Tesla K20m GPU卡。
引言
当前高端图形处理单元(简称GPU)在高性能计算领域变得非常流行。这些GPU显卡,如英伟达特斯拉、费米、开普勒系列,每块芯片可包含多达上千个核心。例如,NVIDIA Tesla K20m GPU卡具有2496个CUDA核心。它们包含大规模多线程处理器,并且可以同时声明和执行数千个线程,以充分利用GPU的计算能力。然而,这些被称为桌面GPU的显卡必须安装在配备桌面CPU的个人计算机或服务器中。此外,使用这些桌面GPU显卡构建高性能计算平台的成本和功耗都很高。例如,一块英伟达特斯拉或费米GPU显卡可能需要花费数千美元,而一台个人计算机或服务器也可能需要花费数百到数千美元。该平台的总功耗可能高达一千瓦。此外,该平台难以满足即时性和移动性需求,即开发者需要通过远程控制来演示程序。
英伟达发布的Jetson TK1(也称为Tegra K1,http://elinux.org/Jetson_TK1)是一个面向嵌入式应用的全功能平台,包含192个CUDA核心(开普勒GPU)、4个ARM Cortex‐A15 CPU以及2个ISP核心。英伟达Jetson TK1还配备了用于移动应用的蓝牙和Wi‐Fi模块。一块英伟达Jetson TK1的成本低于三百美元,测试显示其功耗约为几十瓦(Paolucci 等,2014)。已有若干报告或文献分别将英伟达Jetson TK1与其他嵌入式平台、桌面CPU和桌面GPU进行比较。在英伟达Jetson TK1开发套件(http://www.nvidia.com/object/jetson‐tk1‐embedded‐dev‐kit.html)中显示,英伟达Jetson TK1的加速比和每瓦性能优于iPhone5中使用的苹果A7。詹姆斯·沃尔弗(沃尔弗,2015)从时间和加速比方面对英伟达Jetson TK1与树莓派型号进行了比较,结果表明单个英伟达Jetson TK1在这两项指标上均优于树莓派型号。P.S. Paolucci et al.(Paolucci 等,2014)还将英伟达Jetson TK1中的ARM Cortex‐A15 CPU与超微服务器中的英特尔至强E5620 CPU在每次突触事件的焦耳数、总能量、功耗和执行时间方面进行了比较。对于前两项,英伟达Jetson TK1的性能分别达到超微服务器的4.5倍和4.4倍;在功耗方面,英伟达Jetson TK1的性能达到超微服务器的14.4倍。然而,英伟达Jetson TK1的执行时间是超微服务器的3.3倍。S. Fu et al.(Fu 等,2015)对桌面级英特尔i7‐3770多核CPU、桌面级英伟达GTX 690显卡和英伟达Jetson TK1的性能、能效和成本效益进行了比较。结果证明,英伟达Jetson TK1的能效和成本效益均优于桌面级英特尔i7‐3770 CPU和桌面级英伟达GTX 690显卡;英伟达Jetson TK1的性能接近桌面级英特尔i7‐3770多核CPU,而桌面级英伟达GTX 690 GPU具有最佳性能。综上所述,与其它嵌入式板卡和桌面CPU相比,英伟达Jetson TK1是一款具备竞争力的嵌入式和移动板卡;此外,与桌面GPU显卡相比,英伟达Jetson TK1具有低成本和低功耗的优势。因此,在高性能计算领域研究英伟达Jetson TK1将成为一个新的研究方向。
统一计算设备架构(简称CUDA,(尼克尔斯等人,2008年))能够访问GPU,并使超级计算普及化。过去,许多并行算法、CUDA程序和工具已基于这些桌面GPU显卡在多个高速计算领域开发,例如气象学、图像和视频处理、流体动力学模拟、地震分析等。例如,在计算生物学中,存在多种工具,如MUMmerGPU(Schatz等人,2007年)、CUDA‐MEME(Liu等人,2010年)、CUDA‐BLASTP(Liu、Schmidt、Mu¨ller‐Wittig,2011年)等。ClustalW(汤普森、希金斯、吉布森,1994年)是一种渐进式多序列比对工具,该方法通过反复比对序列对以及先前生成的比对结果,来实现一组序列的比对,是目前常用的比对方法。渐进式多序列比对的核心思想是根据基于每对序列计算出的相似性得分所构建的系统发育树中的顺序,逐步进行序列对的比对。在之前的研究中,我们提出了一种基于单GPU和多GPU的ClustalW v2.0.11的GPU版本,称为CUDA ClustalW v1.0(Hung等人,2015年),采用了任务内并行化(Liu、Maskell、Schmidt,2009年)的方法。基于桌面级英伟达特斯拉C2050 GPU卡的CUDA ClustalW v1.0,在整体执行时间上相较于基于2.67吉赫兹桌面级英特尔至强X5550中央处理器的ClustalW v2.0.11可实现超过33倍的加速。
计算机辅助药物设计(简称CADD)(John,2007年)已成为一个新兴的研究领域,有助于提高药物设计与开发的效率。通过CADD,可以找到针对靶基因或蛋白质的潜在抑制剂。之后,通常会将这些潜在抑制剂与化合物数据库(如ZINC)(Irwin和Shoichet,2005年)进行比较,以寻找具有相似结构的其他化合物。因此,化合物比较已成为计算化学中一项重要且常用的任务。过去已经提出了许多算法来进行化合物比较,例如LINGO方法(Vidal, Thormann, Pons, 2005)和指纹方法(Grant 等,2006)。然而,在与大量化合物进行比较时,这将非常耗时。在之前的工作中,我们提出了一种基于GPU的多重化合物比较并行算法,称为CUDA‐MCC(Lin等人,2014年),支持单GPU和多GPU。基于桌面端NVIDIA Tesla K20m GPU卡的CUDA‐MCC,相比基于2.0 GHz桌面Intel Xeon E5‐2650 CPU的版本,可实现45倍和391倍的加速。
因此,本文构建了一个基于NVIDIA Jetson TK1的生物信息学移动与加速计算平台。基于该平台,本文分别重新实现了CUDA ClustalW v1.0和CUDA‐MCC,称为ClustalWtk和MCCtk,并进行了测试。实验结果表明,与单个Intel Xeon E5‐2650 CPU或单个ARM Cortex‐A15 CPU上的CPU版本相比,这两种工具在单个NVIDIA Jetson TK1上均可分别实现3倍和4倍的加速比。此外,NVIDIA Jetson TK1的性价比高于台式机用NVIDIA Tesla K20m GPU卡。用户友好界面使用户能够方便地访问所提出工具的图形处理器计算能力;此外,NVIDIA Jetson TK1包含蓝牙和Wi‐Fi模块,适用于移动应用。因此,本工作还提供了具有用户友好界面的这两种工具的网页和移动服务。
本文其余部分组织如下。第2节介绍预备概念。第3节介绍在NVIDIA Jetson TK1上构建的生物信息学平台以及ClustalWtk和MCCtk工具的细节。实验结果见第4节。结论在第5节中给出。
2. 预备概念
2.1. CUDA和NVIDIA GPU架构
CUDA 是常用编程语言(如 C/C++)的扩展,用户可以使用它编写用于实际应用的多线程程序。CUDA程序分为两部分实现:由中央处理器执行的主机和由图形处理器执行的设备。该函数在设备端执行的函数称为内核,它以一组并发执行的线程形式被调用。这些线程被组织成一个层次化结构:线程块和网格。网格是一组线程块,而一个线程块包含多个线程。网格的大小是指每网格的线程块数,线程块的大小是指每个线程块的线程数。同一个线程块中的线程可以通过每个线程块的共享内存进行通信,并能相互同步。除了共享内存外,还有五种内存类型,包括每网格私有本地内存、所有线程块共享的全局内存、纹理内存、常量内存以及每个线程的私有寄存器。英伟达GPU架构中的基本处理单元称为流处理器或CUDA核心。多个流处理器在图形处理器上执行计算任务。根据不同的架构设计,若干个流处理器可集成到一个流式多处理器中,例如费米和开普勒架构每个流式多处理器分别包含32个和192个流处理器。纹理内存和常量内存的缓存限制为每个流式多处理器8KB。费米和开普勒架构为每个流式多处理器提供了真正的可配置L1缓存,并在所有流式多处理器之间共享统一的L2缓存。因此,全局内存可以访问L2缓存,而每个流式多处理器则可以使用其L1缓存和共享内存。当程序运行内核时,设备会将线程块调度到流式多处理器上执行。SIMT机制指的是线程以32个为一组的小组合形式在流式多处理器上运行,这一组称为线程束。线程束调度器同时调度并分发指令。CUDA程序的性能模式深受每个线程块的线程数和每网格的线程块数的影响。
2.2. ClustalW
ClustalW(汤普森、希金斯、吉布森,1994)是一种渐进式多序列比对工具;其流程可分为三个步骤:(1)距离矩阵计算,(2)引导树构建,以及(3)渐进比对。在大多数情况下,距离矩阵计算步骤的计算时间占据了ClustalW整体执行时间的大部分(李,2003)。在距离矩阵计算步骤中,通过使用双序列比对算法(如尼德曼‐翁施算法(尼德曼和翁施,1970))从每对生物序列中计算相似性得分。对于两条长度均为n的序列进行比对,使用尼德曼‐翁施算法的时间复杂度和空间复杂度均为O(n²)。对于使用ClustalW对k条长度为n的序列进行比对,需要进行k²/2次成对比对,总时间复杂度为O(k²n²)。在引导树构建步骤中,根据已计算的距离矩阵(步骤1中的相似性得分)使用系统发育树构建算法构建有根系统发育树。对于大多数系统发育树构建算法(如UPGMA(斯尼思和索卡尔,1973)),该步骤的时间复杂度为O(k³)。所构建的引导树可用于决定后续渐进比对步骤的顺序。在渐进比对步骤中,根据引导树中的顺序(在步骤2中创建)生成成对比对结果。尽管此步骤仍需使用双序列比对算法来获得成对对比结果,然后合并先前生成的比对,但此步骤中的成对比对次数通常远少于距离矩阵计算步骤中的次数。
2.3. 多重化合物比较 (MCC)
通常,分子(化合物)可以表示为指纹(Grant 等,2006)和 SMILES(Vidal, Thormann, Pons, 2005),因此化合物比较的工作可被视为字符串比较。Tanimoto系数是最常用的度量方法。两个分子之间进行化合物比较(称为一对一比较,O2O)的时间复杂度为O(n²),其中n是化合物的最大长度。通常情况下,化合物的长度较短(几十到几百),计算时间较小。然而,在与大量化合物进行比较时将会耗费较多时间。对于MCC问题,可以将一个化合物与一组化合物进行比较(称为一对所有比较,简写为O2A),或比较两组化合物(称为所有对所有比较,简写为A2A)。对于A2A,MCC问题的内在时间复杂度为O(k²n²),其中包含k个长度为n的化合物。LINGO方法(Vidal, Thormann, Pons, 2005)是将分子建模为SMILES表示的子串集合。因此,通过滑动窗口方案,将SMILES字符串分割成所有长度为q的子串。这些子串被存储为一组q‐Lingos。在进行O2O比较时,使用来自两个分子的两组q‐Lingos来查找相同的Lingos。然后利用相同Lingos的数量来计算Tanimoto系数。
3. 方法
3.1. 构建生物信息学平台
本文在NVIDIA Jetson TK1上构建了一个生物信息学平台,该平台可分为四个部分:系统设置、程序移植、性能调优和界面设计。对于系统设置,需要完成一些准备工作,例如刷新系统镜像、配置网络以及在目标计算平台上安装相关软件。对于程序移植,针对ClustalWtk和MCCtk,需分别调整和修改CUDA ClustalW v1.0与CUDA‐MCC的编译命令及程序代码。对于性能调优,由于NVIDIA Jetson TK1与桌面GPU显卡在线程块数量以及每个线程块的线程数方面存在差异,因此有必要进行性能调优;将分别通过不同的线程块数量和每个线程块的线程数对ClustalWtk和MCCtk在NVIDIA Jetson TK1上进行评估。对于界面设计,分别为ClustalWtk和MCCtk设计了基于Qt开发框架、网页和移动服务的多种接口。
3.1.1. 系统设置
本文中的所有工作均在适用于Tegra的Linux(简称L4T)R21.1上实现。系统镜像和设备驱动程序从NVIDIA开发者专区(https://developer.nvidia.com/linux‐tegra‐rel‐21)下载,该网站为英伟达提供了一些有用的开发工具。下载文件的解压路径非常重要,例如,设备驱动程序必须放置在系统镜像的子目录中,该目录命名为“rootfs”。然后通过在系统镜像的顶层目录执行“apply_binaries.sh”脚本来进一步编译。使用微型USB线缆将NVIDIA Jetson TK1与Linux主机PC连接。要使系统进入“强制USB恢复模式”,设备必须处于关机状态,而非挂起或睡眠状态。接着,在按住强制恢复按钮的同时按下重置按钮。
为了检查设备是否已进入“强制USB恢复模式”,可使用命令“lsusb”来查看是否存在“NVIDIA公司”。如果出现“NVIDIA公司”,则表示NVIDIA Jetson TK1已成功连接到Linux主机PC。为了刷写设备,执行命令“sudo ./flash.sh ‐S 14580MiB jetson‐tk1 mmcblk0p1”。完成此刷写操作后,使用默认账户和密码登录L4T系统。
NVIDIA Jetson TK1 可以通过两种方式访问:直接访问 和 远程访问。第一种方式是使用键盘、鼠标和HDMI显示器直接访问NVIDIA Jetson TK1在“图形用户界面模式”下使用TK1。另一种方式是通过以太网端口以“远程模式”访问开发板(NVIDIA Jetson TK1)。由于动态主机配置协议和SSH默认均为开启状态,因此可以通过SSH在“远程控制模式”下访问NVIDIA Jetson TK1。当NVIDIA Jetson TK1连接到路由器时,IP地址由DHCP服务器分配。如果升级系统,在L4T R19中需要告知高级包管理工具不要覆盖libglx.so文件。此问题似乎在L4T R21中已修复。libglx.so文件是英伟达图形驱动中的特定文件,可能会被ubuntu提供的错误版本替换,导致用户无法进入图形环境。因此,在将NVIDIA Jetson TK1连接到互联网或执行更新之前,应先执行sudo apt‐mark hold xserver‐xorg‐core命令。
CUDA 6.5 版本已安装在 NVIDIA Jetson TK1 上。同时,从 NVIDIA开发者专区 下载了适用于 L4T 的 CUDA工具包 的 .deb文件格式 文件。为了安装 CUDA 仓库元数据,执行了 sudo dpkg ‐i命令 cuda‐repo‐l4t‐r21.1‐6‐5‐prod_6.5‐14_armhf.deb(该文件已手动下载并用于 L4T)。接着执行 sudo apt‐get update命令,以从 NVIDIA 下载并安装包含 OpenGL工具包 在内的实际 CUDA工具包。然后执行 “sudo apt‐get install cuda‐toolkit‐6‐5” 来安装软件包,并且需要将账户添加到 video 组,以允许访问 图形处理器。此外,还需将 “export PATH=/usr/local/cuda/bin:$PATH” 和 “export LD_LIBRARY_PATH=/usr/local/cuda/lib:$LD_LIBRARY_PATH” 添加到 bashrc 文件 中,然后使用 source命令 加载该文件。
其他开发工具也需要安装。Gcc和G++是构建OpenMPI和Qt所必需的;Apache和PHP对于应用程序接口设计至关重要;Gcc、G++、Apache、PHP、邮件服务器和Qt4均可通过apt包管理器直接安装,只需在终端执行“sudo apt‐get install gcc g++ apache2 php5 libapache2‐mod‐php5 mailutils qt4‐dev‐tools libqt4‐dev libqt4‐core libqt4‐gui libqt4‐opengl”命令即可(Qt:https://devtalk.nvidia.com/default/ topic/752892/qt‐anyone‐/;mailutils:http://askubuntu.com/questions/12917/how‐to‐send‐mail‐from‐the‐command‐line;Apache:https://www.digitalocean.com/community/tutorials/how‐to‐install‐linux‐apache‐mysql‐php‐lamp‐stack‐on‐ubuntu)。OpenMPI可从OpenMPI官方网站(http:// www.open‐mpi.org/)下载为“.tar.gz压缩格式”文件。解压OpenMPI源代码文件后,使用构建路径 “—prefix=/usr/local/openmpi”进行Configure。在“make all”和“sudo make install”完成后,应将“export OPENMPI=/usr/local/openmpi”、“export LD_LIBRARY_PATH=$OPENMPI/lib”以及“export PATH=$OPENMPI/bin:$PATH”添加到“bashrc文件”中,并执行source命令使其生效。
在NVIDIA Jetson TK1上安装了Wi‐Fi模块(Intel 7260 mini PCIE),但系统内核似乎不支持该模块。已尝试多种方法(https://github.com/jetsonhacks/ install7260LT4211)来解决此问题。针对NVIDIA Jetson TK1在LT4 R21.1下为Intel 7260 mini‐PCIE卡编译的设备驱动程序可从GitHub网站(https://github.com/)获取。为避免崩溃,在操作前先备份“/etc/rc.local”以及“cfg80211.ko”和“mac80211.ko”文件。执行“install7260Driver.sh”后,Wi‐Fi模块安装成功。
3.1.2. 程序移植
在本部分中,ClustalWtk和MCCtk的程序代码是从为桌面GPU显卡设计的CUDA ClustalW v1.0和CUDA‐MCC修改而来,并分别在NVIDIA Jetson TK1上进行编译。ClustalWtk和MCCtk的详细信息分别在第3.2节和第3.3节中描述。编译器报告了一些错误,例如:“无法找到库。必须修复Configure和Makefile”。在这种情况下,应强制CUDA库路径使用x86路径,并将设备计算能力设置为3.2。对于包含OpenMP的程序,在编译命令中添加“‐Xcompiler ‐fopenmp”。同时附加“‐O3”参数以获得更好的性能模式。
然而,当输入数据较大时,在NVIDIA Jetson TK1上运行时间不正确。大量实验表明,当运行时间超过两千秒时,设备会返回极小或负数的运行时间。这种情况在桌面端中央处理器上并未出现。运行时间通过clock()函数计算,并存储在clock_t类型中。根据“time.h”文件中的定义,clock_t类型为long类型。NVIDIA Jetson TK1上的long类型最大值为2147483647,而在桌面端中央处理器(如Intel Xeon E5‐2650)上为9223372036854775807。NVIDIA Jetson TK1上long类型的最大值除以CLOCKS_PER_SEC(1000000)约为2147,与上述情况相符。由于clock()函数会导致溢出,因此“ftime()”函数和“timeb”结构体是更好的选择。“timeb”结构体包含time_t类型的time和unsigned short类型的millitm,将运行时间分为两部分进行存储,从而可计算更长时间的运行时间。
3.1.3. 性能调优
对于 ClustalWtk 和 MCCtk,性能调优 进一步分为两部分:线程块数量/每个线程块的线程数 和 硬件控制。在第一部分中,当线程块数量和每个线程块的线程数分别设置为 128 和 64 时,ClustalWtk 或 MCCtk 可达到最佳性能。这些为 ClustalWtk 和 MCCtk 设置的数值与 CUDA ClustalW v1.0 和 CUDA‐MCC 的不同。在第二部分中,使用“cat /sys/devices/ system/cpu/online”来检查 CPU 的状态。由于 NVIDIA Jetson TK1 默认只开启一个 CPU 核心,其他 CPU需要手动开启。例如,通过“echo 1>/sys/devices/system/cpu/cpu2/online”开启 CPU2。根据电池(电源)消耗情况,CPU 模式分为三种类型:“quiet”、“normal”和“performance”。为了获得最佳能效,默认的“quiet”模式被关闭并进入“performance”模式。“echo 0>/sys/devices/system/cpu/cpuquiet/tegra_cpuquiet/enable”用于关闭“quiet”模式。“echo performance >/sys/devices/system/cpu/cpu2/cpufreq/scaling_governor”用于将频率保持静态而非动态范围。可通过写入以下命令设置 CPU 频率:“echo <频率>>/ sys/devices/system/cpu/cpu0/cpufreq/scaling_setspeed”。如果设备运行在“quiet”模式下,可用的频率(Hz)如下:51000、102000、204000、312000、564000、696000、828000、960000、1092000;如果设备运行在“performance”模式下,可用的频率(Hz)如下:204000、312000、564000、696000、828000、960000、1092000、1122000、1224000、1326000、1428000、1530000、1632000、1734000、1836000、1938000、2014500、2116500、2218500、2320500。要手动控制 GPU 的时钟频率(Hz),首先应通过“cat /sys/ker‐ nel/debug/clock/gbus/possible_rates”确定支持的速率。然后通过“echo 852000000>/ sys/kernel/debug/clock/override.gbus/rate”和“echo 1>/ sys/kernel/debug/clock/override. gbus/state”设置速率(例如 852000 kHz)。最后通过“cat / sys/kernel/debug/clock/gbus/rate”验证该速率。
3.1.4. 界面设计
用户友好界面分别通过Qt和网页为ClustalWtk和MCCtk设计。Qt通过SSH和X11转发访问,仅在PC主机上可用。网页通过IP地址访问,具有更高的设备兼容性。
稳定版本 Qt 4.8 在互联网或书店中有更多的参考资料。通过 SSH 和 X11 转发,Qt 应用程序可以访问运行 CUDA 程序的设备。X11 转发在 NVIDIA Jetson TK1 出厂时默认开启。“ssh ‐X ”可用于在 Linux 或 Mac 上连接开启 X11 转发的设备,而 Microsoft Windows 用户可使用“Xming”和“Putty”应用程序实现相同功能。“QFile”用于在 NVIDIA Jetson TK1 上读写文件,“QProcess”用于启动外部程序并与之通信。该 CUDA程序由“start()”函数执行。“Connect()”函数用于报告CUDA程序完成后的状态。在 “start()”函数中,bash命令无效,因为系统环境在其中无法工作,因此使用程序的绝对路径,而不是“$HOME”变量或相对路径。最后,在“system()”函数中添加了bash命令“mail ‐s ‐A ”,以将结果数据发送给用户。如果账户(ubuntu)已添加到“video”组,则不会出现权限问题。
Bootstrap被用作网站框架,广泛应用于在网页上开发响应式、移动优先的项目。它可以帮助应用于手机、平板和PC。HTML允许用户设置输入文件和参数,并通过AJAX技术将其发送到PHP脚本。根据用户的选择,PHP脚本执行CUDA程序的CPU或GPU版本。
CUDA程序(如ClustalWtk或MCCtk)的运行时间平均超过30秒,主要取决于输入数据和算法。由于PHP脚本的默认运行时间限制为30秒,因此有必要在运行前设置最大执行时间。“set_time_limit(0)”被添加到PHP脚本中,其中零表示无限制。使用“shell_exec()”函数在PHP脚本中执行CUDA程序。当PHP运行CUDA程序时会报告“cuda device not found”。主要原因是apache账户(ubuntu/L4T中的www‐data)没有权限访问GPU。因此,将“www‐data”添加到“video”组后即可正常工作。
3.2. ClustalWtk
在ClustalWtk中,距离矩阵计算步骤在图形处理器上实现,并设计了多种优化方法以提升ClustalWtk的性能模式。在距离矩阵计算步骤中,通过使用双序列比对算法从每对序列中计算相似性得分。对于k条序列,ClustalWtk采用任务内并行化将每个成对比对分配给一个线程块,其中每个成对比对由同步对角多线程(SDMT)类型(Lin 和 Lin,2014)实现。ClustalWtk中使用的双序列比对算法包含三条路径:前向路径、反向路径和分治路径。为了同时在前向数组和反向数组中进行计算,线程块中的线程被分为两部分,一部分用于前向数组,另一部分用于反向数组。然后仅使用线程块中的一个线程来合并前向数组和反向数组最后一行的得分,以找到断点,并将原始二维数组划分为两个子数组。分治路径通过循环函数完成。此外,在ClustalWtk中,针对距离矩阵计算步骤设计了以下几种优化方法:
- 负载均衡策略 :使用任务内并行化,一个成对比对被分配给一个线程块。尽管NVIDIA Jetson TK1中只有一个流式多处理器,但该流式多处理器可以处理一个或多个线程块。对于ClustalWtk中的k个序列,一个核函数仅处理固定数量的、序列长度相似的成对比对。根据第3.1.3节,ClustalWtk中每线程块的线程数和每网格的线程块数分别为64和128。
- 内存分配 :对于成对比对,输入是两个序列和一个替换矩阵。这两个序列存储在共享内存中,而替换矩阵存储在纹理内存中。所有序列和距离矩阵都存储在2GB内存中;
- 无符号字符数据类型 :由于每对序列都存储在共享内存中,共享内存的使用会影响流式多处理器的占用率。为了减少共享内存的使用并提高占用率,这些序列使用无符号字符数据类型而非整型进行存储;
- 精度调整 :由于CUDA中的单精度浮点运算未按照 IEEE‐754 标准设计。在 ClustalWtk 中,使用 _fdiv_rn() 函数来替代内置的除法运算符。
3.3. MCCtk
在MCCtk中,目标首先是将列出的两组化合物(A2A)进行比较,即查询集(Query)和数据库(Database),然后找出数据库中与查询集中每个化合物的Tanimoto系数大于0.85的化合物。MCCtk包含三个阶段:preprocessing、comparison和output。在preprocessing阶段,查询集和数据库中的化合物分别以二维字符串数组的形式存储(表示为SMILES编码),分别为Q和Db。随后,每个SMILES编码(一个化合物)通过偏移量1的滑动窗口方案被分割成一组4‐Lingos(作为子字符串)。对于每个4‐Lingo,会根据ASCII编码表将其转换为一个32位整数(称为LINGO分数)。LINGO长度、LINGO数量和LINGO幅值分别根据4‐Lingo的数量、每个4‐Lingo在SMILES编码中出现的次数以及不重复的4‐Lingo数量进行计算。在comparison阶段,当执行一次内核函数时,查询集中的一个化合物将由所有线程(任务间并行化)与数据库中的所有化合物进行比较。在线程块中,每个线程用于将查询集中的一个化合物与数据库中的一个化合物进行比较。因此,为了实现高性能,线程块中每个线程的计算工作负载应相等。可以通过考虑LINGO分数、LINGO长度、LINGO数量和LINGO幅值,在NVIDIA Jetson TK1上采用负载均衡策略以加速计算速度。在comparison phase之后,在output阶段,针对查询集中的每个化合物,报告数据库中Tanimoto系数大于0.85的化合物。
4. 实验结果
在本研究中,ClustalWtk和MCCtk通过C+CUDA在单个NVIDIA Jetson TK1上实现。为了评估这两个工具,实验测试中使用了一台机器和一个NVIDIA Jetson TK1。该机器配备有八个Intel Xeon CPU核心、四块GPU显卡和128GB内存。每个Intel Xeon CPU核心由4个2.0 GHz的Intel Xeon E5‐2650处理器组成,每块GPU显卡为具有4.8GB内存和13个流式多处理器的NVIDIA Tesla K20m,每个流式多处理器包含192个0.706 GHz的CUDA核心。NVIDIA Jetson TK1包含1个ARM Cortex CPU核心、1个Tegra K1 SoC和2GB内存。该ARM Cortex CPU核心由4个2.32GHz的Cortex‐A15处理器组成,而Tegra K1采用的是具有1个流式多处理器的NVIDIA Kepler GK20a,该流式多处理器包含192个0.852 GHz的CUDA核心。ClustalW v2.0.11和MCC分别基于该机器中的Intel Xeon E5‐2650 CPU和NVIDIA Jetson TK1中的ARM Cortex‐A15 CPU运行;CUDA ClustalW v1.0和CUDA‐MCC基于该机器中的NVIDIA Tesla K20m GPU卡运行;ClustalWtk和MCCtk基于NVIDIA Jetson TK1中的NVIDIA Kepler GK20a运行。
为了评估ClustalW v2.0.11、CUDA ClustalW v1.0和ClustalWtk,测试用的蛋白质序列(Hung等人,2015年)从NCBI网站(www.ncbi.nlm.nih.gov/),这些序列可分为八个测试集:(c1) 100条长度为97的序列,(c2) 100条长度为498的序列,(c3) 100条长度为1002的序列,(c4) 100条长度为1523的序列,(c5) 1000条长度为97的序列,(c6) 1000条长度为498的序列,(c7) 1000条长度为1002的序列,(c8) 1000条长度为1523的序列。在对MCC、CUDA‐MCC和MCCtk的评估中,测试化合物从ZINC数据库[14]中随机选取,然后将这些化合物划分为查询集和数据库集。以下实验测试中使用了三个测试集:(m1) 查询集和数据库集各包含4096个化合物,(m2) 查询集和数据库集各包含8192个化合物,(m3) 查询集和数据库集各包含16384个化合物。
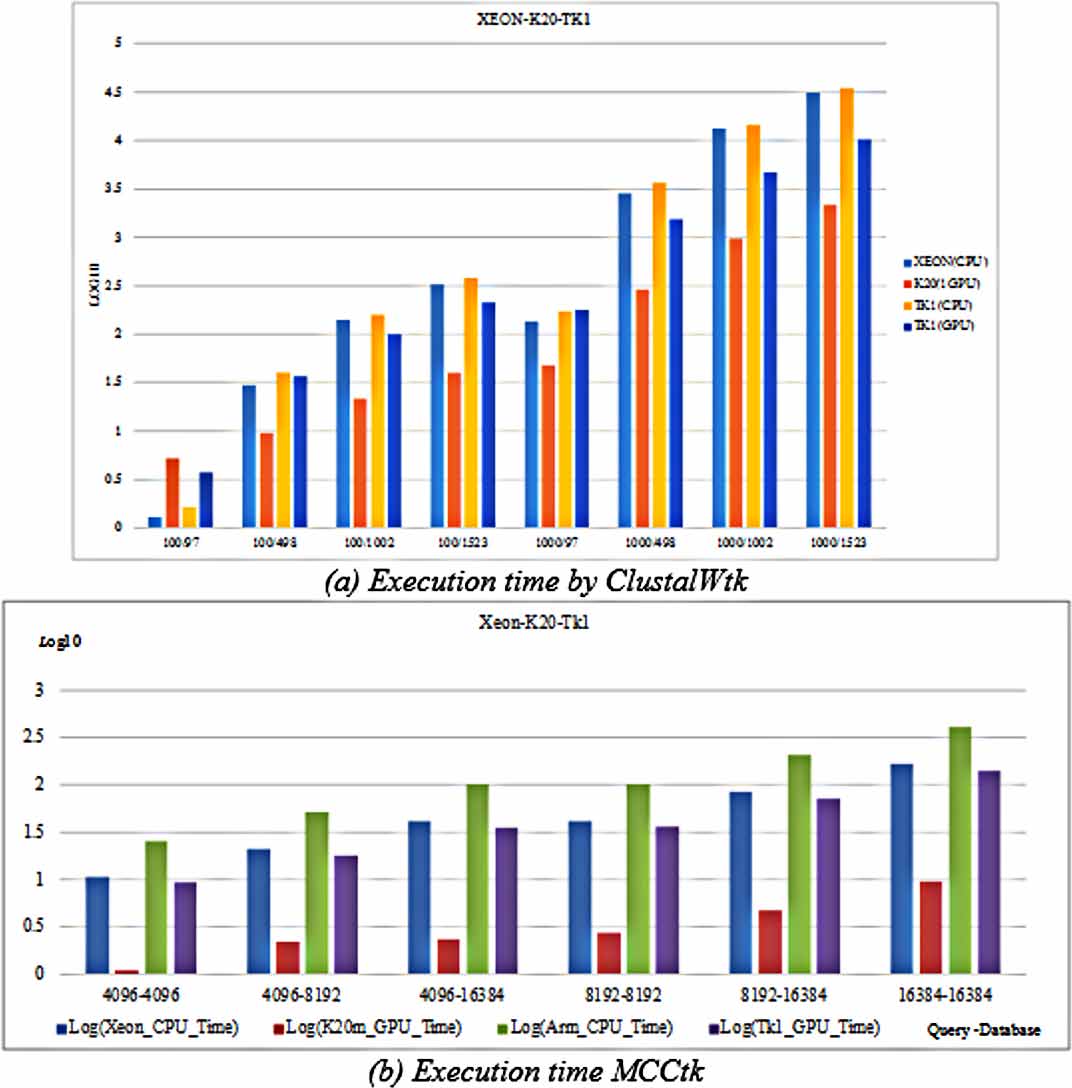
第一个测试是在机器和单个NVIDIA Jetson TK1上分别评估ClustalW v2.0.11、CUDA ClustalW v1.0和ClustalWtk在这八个测试集上的表现。图1(a)显示了执行时间(单位:秒),分别用log10表示ClustalW v2.0.11、CUDA ClustalW v1.0和ClustalWtk在不同测试集上的执行时间。从图1(a)可以看出,使用单个NVIDIA Tesla K20m GPU卡运行CUDA ClustalW v1.0 的执行时间,以及使用单个NVIDIA Jetson TK1运行ClustalWtk的执行时间,均分别小于在单个Intel XEON E5‐2650 CPU和ARM Cortex‐A15 CPU上运行ClustalW v2.0.11的执行时间。通过将单个NVIDIA Jetson TK1上ClustalWtk的执行时间与单个Intel XEON E5‐2650 CPU上ClustalW v2.0.11的执行时间进行比较,ClustalWtk可实现3倍的加速比。通过将单个NVIDIA Jetson TK1上ClustalWtk的执行时间与单个ARM Cortex‐A15 CPU上ClustalW v2.0.11的执行时间进行比较,ClustalWtk可实现4倍的加速比。在单个NVIDIA Tesla K20m GPU卡上运行CUDA ClustalW v1.0的执行时间少于在单个NVIDIA Jetson TK1上运行ClustalWtk的执行时间。其原因是单个NVIDIA Tesla K20m GPU卡上的CUDA核心数量是单个NVIDIA Jetson TK1的13倍。然而,在单个NVIDIA Jetson TK1上运行ClustalWtk的执行时间仅是单个NVIDIA Tesla K20m GPU卡上运行CUDA ClustalW v1.0执行时间的5倍。因此,在ClustalWtk中,NVIDIA Jetson TK1的性价比优于NVIDIA Tesla K20m GPU卡。
第二个测试用于评估MCC、CUDA‐MCC和MCCtk在单个NVIDIA Jetson TK1上的这三组测试集的执行情况。图1(b)显示了执行时间(单位:秒),该时间由MCC、CUDA‐MCC和MCCtk在不同测试集上以log10表示。从图1(b)可以看出,使用单个NVIDIA Tesla K20m GPU卡运行CUDA‐MCC的执行时间以及使用单个NVIDIA Jetson TK1运行MCCtk的执行时间,分别少于使用单个Intel Xeon E5‐2650 CPU和ARM Cortex‐A15 CPU运行MCC的执行时间。通过将单个NVIDIA Jetson TK1上的执行时间与MCC在单个Intel Xeon E5‐2650 CPU上的执行时间进行比较,MCCtk可实现3倍的加速比。通过将单个NVIDIA Jetson TK1上的执行时间与MCC在单个ARM Cortex‐A15 CPU上的执行时间进行比较,MCCtk可实现4倍的加速比。在图1(b)中,对于NVIDIA Tesla K20m GPU卡和NVIDIA Jetson TK1的比较,我们从图1(a)得到了相同的观察结果。在MCCtk中,NVIDIA Jetson TK1的性价比也优于NVIDIA Tesla K20m GPU卡。
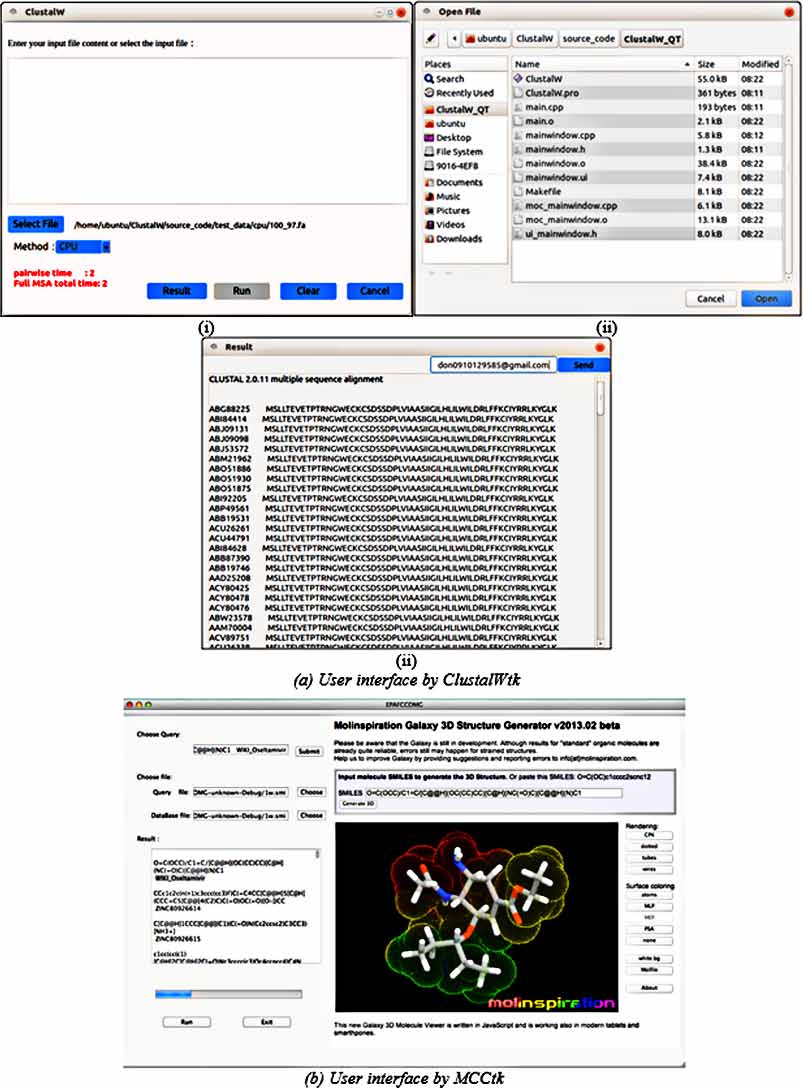
使用Qt为ClustalWtk和MCCtk设计的用户友好界面分别如图2(a)和图2(b)所示。对于ClustalWtk,图2(a‐i)是ClustalWtk的初始界面,输入的“生物序列”可以粘贴到该界面上;输入也可以从目录中选择,如图2(a‐ii)所示;用户可以选择两种工具之一——在桌面CPU上运行的ClustalW或在NVIDIA Jetson TK1上运行的ClustalWtk,以获得比对结果,如图2(a‐i)所示;ClustalW或ClustalWtk的执行时间可以在界面中列出,如图2(a‐i)所示;输出的“多序列比对结果”可以在界面中显示,如图2(a‐iii)所示。对于图2(b)左侧的MCCtk,查询和数据库文件可以从目录中选择;查询中的化合物也可以在界面中指定;MCCtk会计算具有相似结构的其他化合物,并显示这些化合物的信息。所选化合物的3D结构可视化可在图2(b)的右侧显示。
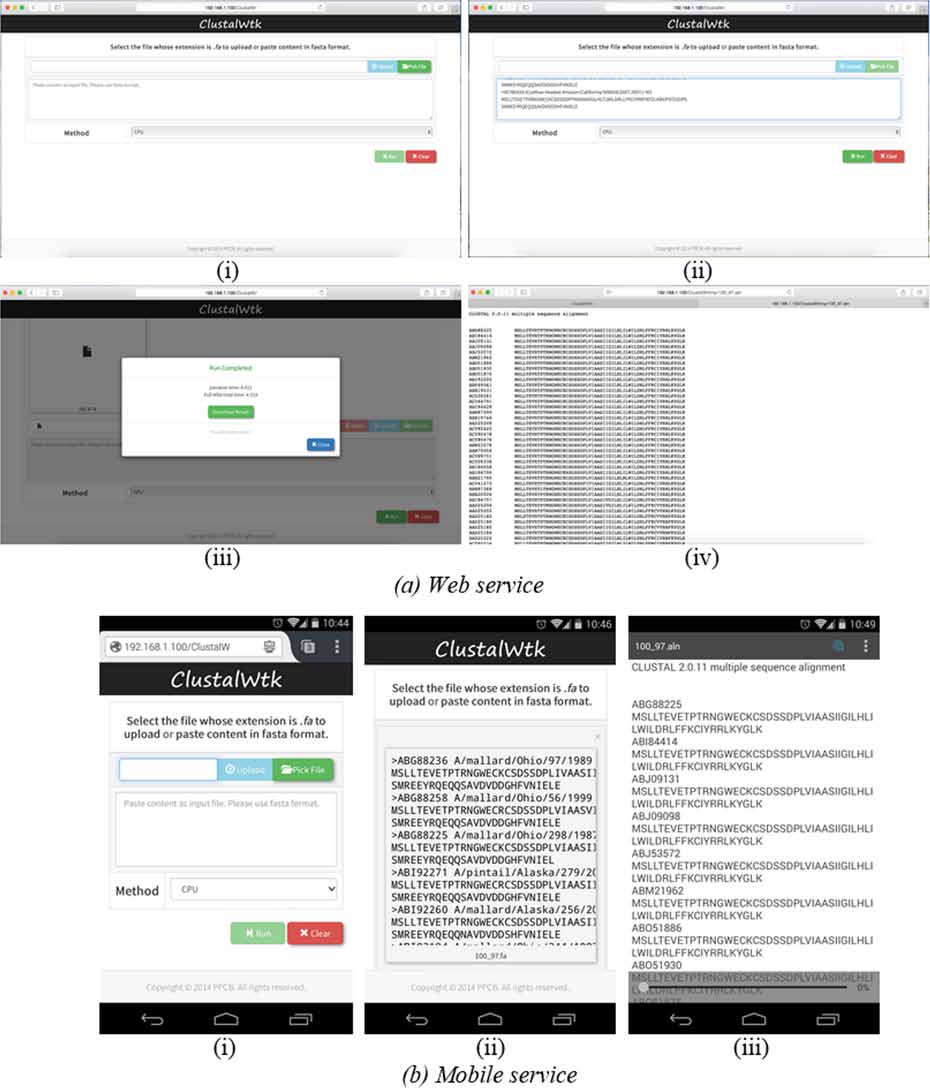
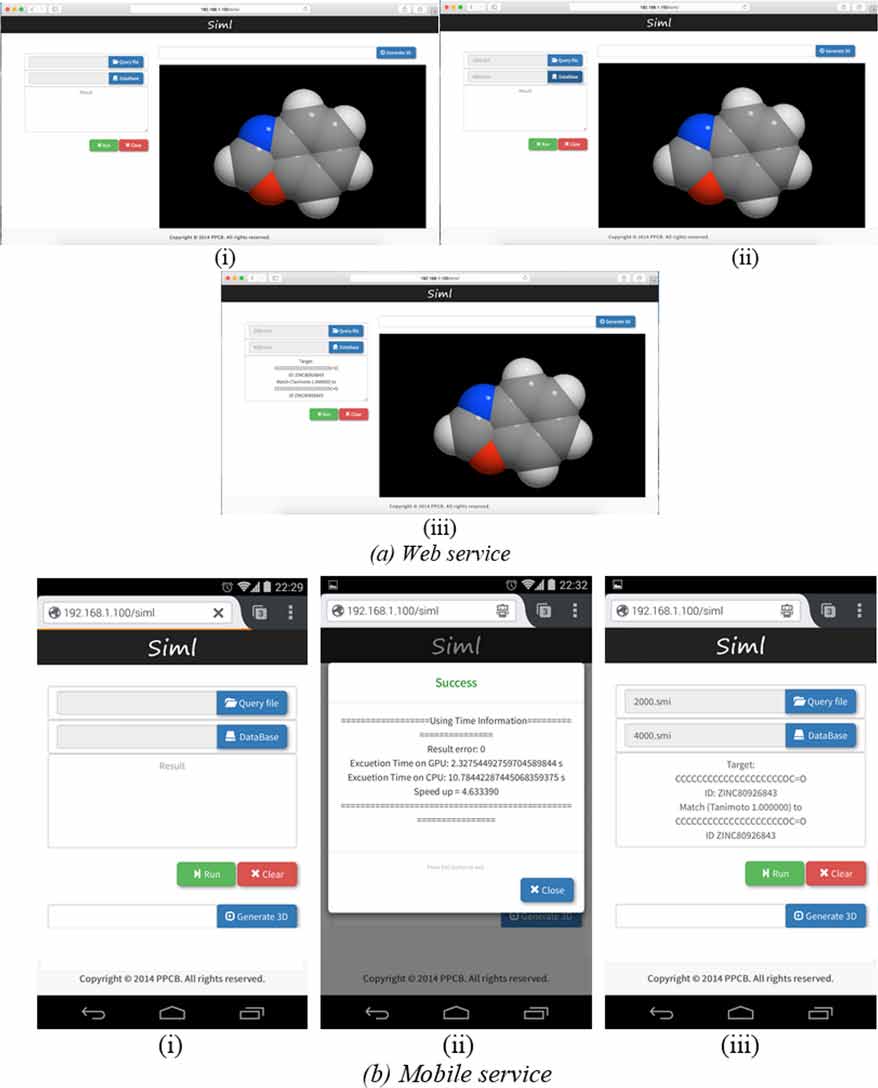
网页和移动服务也可以通过以太网和Wi‐Fi模块在NVIDIA Jetson TK1上设计。ClustalWtk和MCCtk提供的网页和移动服务接口分别如图3和图4所示。对于ClustalWtk,图3(a‐i)是网页服务的初始界面;输入序列可以选择或粘贴到网页上,如图3(a‐ii)所示;可以在两个工具ClustalW和ClustalWtk中选择其一,以获得多序列比对的结果,如图3(a‐ii)所示;ClustalW或ClustalWtk的执行时间可在图3(a‐iii)中显示;结果如图3(a‐iv)所示。图3(b‐i)是移动服务的初始界面;输入序列可以选择并上传至NVIDIA Jetson TK1,如图3(b‐ii)所示;输出结果显示在图3(b‐iii)中。对于MCCtk,图4(a‐i)是网页服务的初始界面;查询和数据库文件作为输入项可在网页上选择,如图4(a‐ii)所示;具有相似结构的化合物的信息列于图4(a‐iii)中。图4(b‐i)是初始移动服务界面上的接口;MCCtk的执行时间如图4(b‐ii)所示;所得化合物的信息列于图4(b‐iii)中。
5. 结论
本文构建了一种基于NVIDIA Jetson TK1的生物信息学移动与加速计算平台,并在此平台上设计了ClustalWtk和MCCtk。根据实验结果,对ClustalWtk和MCCtk得出两点观察结论:(1)与单个Intel XEON E5‐2650 CPU上的ClustalW v2.0.11和单个ARM Cortex‐A15 CPU上的MCC相比,两者在单个NVIDIA Jetson TK1上分别实现了3倍和4倍的加速比。(2)其性价比通过NVIDIA Jetson TK1的性能优于NVIDIA Tesla K20m GPU卡。分别为ClustalWtk和MCCtk设计了基于Qt开发框架、网页和移动服务的用户友好界面。
未来,将考虑把一些并行技术(如线程级并行(Wu 等,2014)和多GPU通信(Playne, Hawick, 2015))应用于所提出的平台和工具中。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)