
RT-Thread(一)
RT-Thread记录(二、RT-Thread内核启动流程 — 启动文件和源码分析)_RTT_矜辰所致_InfoQ写作社区Yaochenger/RT-Thread-Source-Notes: RT-Thread内核源码中文注释源码解读·RT-Thread操作系统的任务(上)_51CTO博客_rt-thread操作系统的特点【万字长文慎点】RT-Thread 内核要点,一网打尽_RT-Thread_
RT-Thread记录(二、RT-Thread内核启动流程 — 启动文件和源码分析)_RTT_矜辰所致_InfoQ写作社区
Yaochenger/RT-Thread-Source-Notes: RT-Thread内核源码中文注释
源码解读·RT-Thread操作系统的任务(上)_51CTO博客_rt-thread操作系统的特点
【万字长文慎点】RT-Thread 内核要点,一网打尽_RT-Thread_嵌入式操作系统论坛_MCU智学网 - Powered by Discuz! RT-Thread记录(十一、I/O 设备模型之UART设备 — 源码解析)-阿里云开发者社区
6. 线程的定义与线程切换的实现 — [野火]RT-Thread内核实现与应用开发实战——基于STM32 文档
RT-Thread移植到stm32 - 浇筑菜鸟 - 博客园
一、调用关系
以PIN设备为例。
这里说一下文件的关系:
![]()
drv_gpio.c是实际的设备驱动文件
dev_pin.c是设备驱动框架
device.c是提供给用户的接口即IO设备管理器
比如要设置pin的模式,有两种方式
第一种①:
通过rt_device_control()。这种通过IO设备管理器的方式只能调用固定的6钟函数。属于 通用设备模型接口(open/close/read/write/control)。
struct rt_device_ops
{
/* common device interface */
rt_err_t (*init) (rt_device_t dev);
rt_err_t (*open) (rt_device_t dev, rt_uint16_t oflag);
rt_err_t (*close) (rt_device_t dev);
rt_ssize_t (*read) (rt_device_t dev, rt_off_t pos, void *buffer, rt_size_t size);
rt_ssize_t (*write) (rt_device_t dev, rt_off_t pos, const void *buffer, rt_size_t size);
rt_err_t (*control)(rt_device_t dev, int cmd, void *args);
};整体的调用关系如下图所示:
注册从底层(驱动实现层)->上层(IO设备管理层),调用从上层到底层。
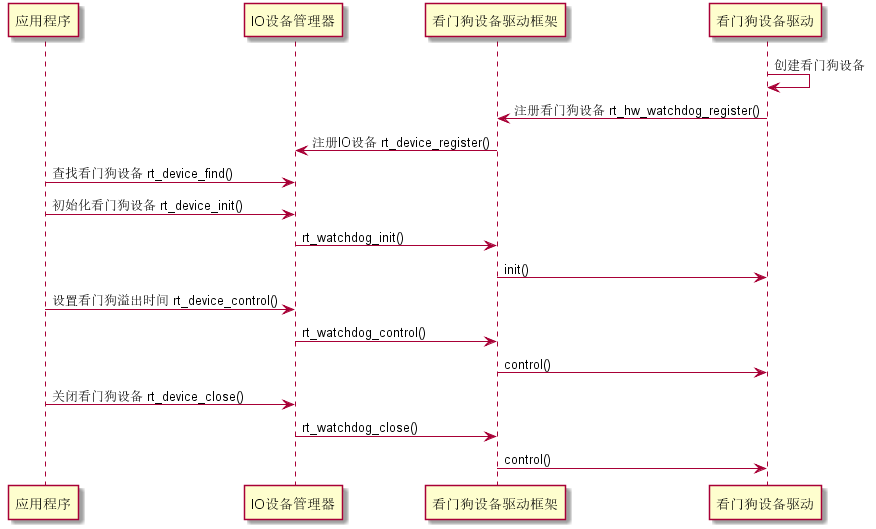
这种方式用户或系统通过 rt_device_control() 来调用,走的是 RT-Thread 设备管理层的统一接口。
-
特点:
-
能处理多种命令(不仅仅是
pin_mode)。 -
是设备管理层与驱动层之间的统一通道之一。
-
这第一种实际上是用了双层多态的方法。
rt_err_t rt_device_control(rt_device_t dev, int cmd, void *arg)
{
/* parameter check */
RT_ASSERT(dev != RT_NULL);
RT_ASSERT(rt_object_get_type(&dev->parent) == RT_Object_Class_Device);
/* call device_write interface */
if (device_control != RT_NULL)
{
return device_control(dev, cmd, arg);
}
return -RT_ENOSYS;
}
static rt_err_t _pin_control(rt_device_t dev, int cmd, void *args)
{
struct rt_device_pin_mode *mode;
struct rt_device_pin *pin = (struct rt_device_pin *)dev;
/* check parameters */
RT_ASSERT(pin != RT_NULL);
mode = (struct rt_device_pin_mode *)args;
if (mode == RT_NULL)
return -RT_ERROR;
pin->ops->pin_mode(dev, (rt_base_t)mode->pin, (rt_base_t)mode->mode);
return 0;
}第一层:通过不同的dev调用不同的control
dev->control = _pin_control;
rt_device_control(dev, cmd, args);
第二层:通过函数_pin_control调用不同的具体硬件实现。
pin->ops->pin_mode(...);
应用层 → rt_device_control() → _pin_control() → pin->ops->pin_mode() → 硬件函数
第二种②:
通过rt_pin_mode()调用,此时没有通过IO设备管理接口,所以可以调用除那6种类型之外的函数,。属于 PIN 设备类的特定接口,为了让用户方便调用 GPIO 中断,而不是让用户去操作 control() 或自己写复杂逻辑。
-
调用来源:
用户应用直接调用rt_pin_mode(pin, mode)来设置引脚模式。 -
特点:
-
不走
rt_device_control()这种通用接口,而是走 PIN 框架提供的专用快捷 API。 -
调用链更短,直接触发底层
pin_mode()。
-
| 方面 | _pin_control() |
rt_pin_mode() |
|---|---|---|
| 入口 | rt_device_control() 通用设备管理接口 |
专用 PIN API |
| 函数可见性 | static(仅驱动文件内部可见) |
对外公开 |
| 参数 | 通用设备指针 + 命令 + void* 参数 | 直接是 pin 编号 + 模式 |
| 调用链 | 设备管理层 → _pin_control() → ops->pin_mode() |
用户 API → _hw_pin.ops->pin_mode() |
| 灵活性 | 可扩展处理多种命令 | 仅用于设置模式 |
| 性能 | 调用链稍长(多一次命令解析和参数转换) | 调用链更短(直接调函数指针) |
用户应用
│
├── 调用 rt_pin_mode() → 直接调 ops->pin_mode()
│
└── 调用 rt_device_control() → _pin_control() → 调 ops->pin_mode()
二、object对象管理系统(object.c)
RT-Thread 采用内核对象管理系统来访问 / 管理所有内核对象,内核对象包含了内核中绝大部分设施,这些内核对象可以是静态分配的静态对象,也可以是从系统内存堆中分配的动态对象。
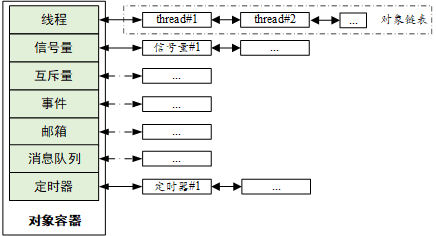
RT-Thread 的内核对象容器及链表如下图所示:
下图则显示了 RT-Thread 中各类内核对象的派生和继承关系。对于每一种具体内核对象和对象控制块,除了基本结构外,还有自己的扩展属性(私有属性),例如,对于线程控制块,在基类对象基础上进行扩展,增加了线程状态、优先级等属性。这些属性在基类对象的操作中不会用到,只有在与具体线程相关的操作中才会使用。因此从面向对象的观点,可以认为每一种具体对象是抽象对象的派生,继承了基本对象的属性并在此基础上扩展了与自己相关的属性。
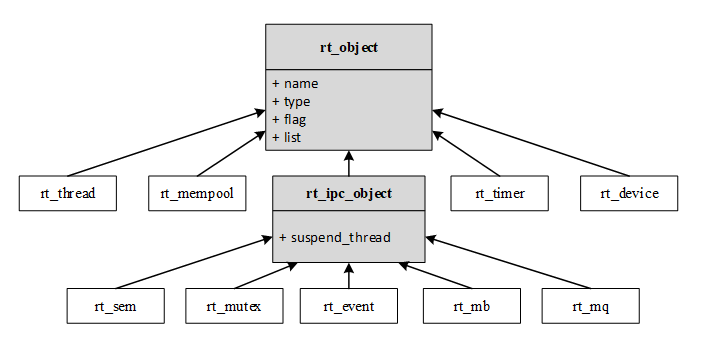
在对象管理模块中,定义了通用的数据结构,用来保存各种对象的共同属性,各种具体对象只需要在此基础上加上自己的某些特别的属性,就可以清楚的表示自己的特征。
这种设计方法的优点有:
(1)提高了系统的可重用性和扩展性,增加新的对象类别很容易,只需要继承通用对象的属性再加少量扩展即可。
(2)提供统一的对象操作方式,简化了各种具体对象的操作,提高了系统的可靠性。
上图中由对象控制块 rt_object 派生出来的有:线程对象、内存池对象、定时器对象、设备对象和 IPC 对象(IPC:Inter-Process Communication,进程间通信。在 RT-Thread 实时操作系统中,IPC 对象的作用是进行线程间同步与通信);由 IPC 对象派生出信号量、互斥量、事件、邮箱与消息队列、信号等对象。
enum rt_object_class_type
{
RT_Object_Class_Thread = 0, /* 对象为线程类型 */
#ifdef RT_USING_SEMAPHORE
RT_Object_Class_Semaphore, /* 对象为信号量类型 */
#endif
#ifdef RT_USING_MUTEX
RT_Object_Class_Mutex, /* 对象为互斥量类型 */
#endif
#ifdef RT_USING_EVENT
RT_Object_Class_Event, /* 对象为事件类型 */
#endif
#ifdef RT_USING_MAILBOX
RT_Object_Class_MailBox, /* 对象为邮箱类型 */
#endif
#ifdef RT_USING_MESSAGEQUEUE
RT_Object_Class_MessageQueue, /* 对象为消息队列类型 */
#endif
#ifdef RT_USING_MEMPOOL
RT_Object_Class_MemPool, /* 对象为内存池类型 */
#endif
#ifdef RT_USING_DEVICE
RT_Object_Class_Device, /* 对象为设备类型 */
#endif
RT_Object_Class_Timer, /* 对象为定时器类型 */
#ifdef RT_USING_MODULE
RT_Object_Class_Module, /* 对象为模块 */
#endif
RT_Object_Class_Unknown, /* 对象类型未知 */
RT_Object_Class_Static = 0x80 /* 对象为静态对象 */
};
从上面的类型说明,我们可以看出,如果是静态对象(系统对象),那么对象类型的最高位将是 1(是 RT_Object_Class_Static 与其他对象类型的或操作),否则就是动态对象,系统最多能够容纳的对象类别数目是 127 个。
1.对象管理系统的整体框架
RT-Thread 的对象系统(线程、信号量、互斥量、设备等)都用一个全局对象信息表(struct rt_object_information)来管理,每种对象有一个链表 object_list 记录该类型所有已经注册的对象。
这里的链表结构可以看我其他的文章,有讲过,与linux内核使用的是一样的通用链表。
struct rt_object_information
{
enum rt_object_class_type type; /**< object class type */
rt_list_t object_list; /**< object list */
rt_size_t object_size; /**< object size */
struct rt_spinlock spinlock;
};这个链表是循环双向链表:
information->object_list // 链表头节点
↕ next/prev
[obj1] <-> [obj2] <-> ... <-> [head]
This function will return the specified type of object information.这个函数就是利用了container_of来返回特定类型的对象信息。
struct rt_object_information *
rt_object_get_information(enum rt_object_class_type type)
{
int index;
type = (enum rt_object_class_type)(type & ~RT_Object_Class_Static);
for (index = 0; index < RT_Object_Info_Unknown; index ++)
if (_object_container[index].type == type) return &_object_container[index];
return RT_NULL;
}可以看一下_object_container这个数组里存放的都是线程、信号量、设备等的全局信息表。
static struct rt_object_information _object_container[RT_Object_Info_Unknown] =
{
/* initialize object container - thread */
{RT_Object_Class_Thread, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Thread), sizeof(struct rt_thread), RT_SPINLOCK_INIT},
#ifdef RT_USING_SEMAPHORE
/* initialize object container - semaphore */
{RT_Object_Class_Semaphore, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Semaphore), sizeof(struct rt_semaphore), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_MUTEX
/* initialize object container - mutex */
{RT_Object_Class_Mutex, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Mutex), sizeof(struct rt_mutex), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_EVENT
/* initialize object container - event */
{RT_Object_Class_Event, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Event), sizeof(struct rt_event), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_MAILBOX
/* initialize object container - mailbox */
{RT_Object_Class_MailBox, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_MailBox), sizeof(struct rt_mailbox), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_MESSAGEQUEUE
/* initialize object container - message queue */
{RT_Object_Class_MessageQueue, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_MessageQueue), sizeof(struct rt_messagequeue), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_MEMHEAP
/* initialize object container - memory heap */
{RT_Object_Class_MemHeap, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_MemHeap), sizeof(struct rt_memheap), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_MEMPOOL
/* initialize object container - memory pool */
{RT_Object_Class_MemPool, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_MemPool), sizeof(struct rt_mempool), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_DEVICE
/* initialize object container - device */
{RT_Object_Class_Device, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Device), sizeof(struct rt_device), RT_SPINLOCK_INIT},
#endif
/* initialize object container - timer */
{RT_Object_Class_Timer, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Timer), sizeof(struct rt_timer), RT_SPINLOCK_INIT},
#ifdef RT_USING_MODULE
/* initialize object container - module */
{RT_Object_Class_Module, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Module), sizeof(struct rt_dlmodule), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_HEAP
/* initialize object container - small memory */
{RT_Object_Class_Memory, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Memory), sizeof(struct rt_memory), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_SMART
/* initialize object container - module */
{RT_Object_Class_Channel, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Channel), sizeof(struct rt_channel), RT_SPINLOCK_INIT},
{RT_Object_Class_ProcessGroup, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_ProcessGroup), sizeof(struct rt_processgroup), RT_SPINLOCK_INIT},
{RT_Object_Class_Session, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Session), sizeof(struct rt_session), RT_SPINLOCK_INIT},
#endif
#ifdef RT_USING_HEAP
{RT_Object_Class_Custom, _OBJ_CONTAINER_LIST_INIT(RT_Object_Info_Custom), sizeof(struct rt_custom_object), RT_SPINLOCK_INIT},
#endif
};以上总结:对象管理系统是用一个信息数组来维护,包括线程、信号量、设备等不同类型的对象。每个数组元素表示一个对象,每个元素中又维护一个循环双向链表来存储同类型的对象,且这个链表的第一个节点不存储数据,是一个哨兵节点。
2.主要函数讲解
只讲解需要注意的函数
①对象初始化函数
This function will initialize an object and add it to object system management.
初始化对象并加入到对象系统中。传进来的object可以是静态创建的,也可以是动态malloc的。
void rt_object_init(struct rt_object *object,
enum rt_object_class_type type,
const char *name)
{
rt_base_t level;
rt_size_t obj_name_len;
#ifdef RT_DEBUGING_ASSERT
struct rt_list_node *node = RT_NULL;
#endif /* RT_DEBUGING_ASSERT */
struct rt_object_information *information;
#ifdef RT_USING_MODULE
struct rt_dlmodule *module = dlmodule_self();
#endif /* RT_USING_MODULE */
/* get object information */
information = rt_object_get_information(type);
RT_ASSERT(information != RT_NULL);
#ifdef RT_DEBUGING_ASSERT
/* check object type to avoid re-initialization */
/* enter critical */
level = rt_spin_lock_irqsave(&(information->spinlock));
/* try to find object */
for (node = information->object_list.next;
node != &(information->object_list);
node = node->next)
{
struct rt_object *obj;
obj = rt_list_entry(node, struct rt_object, list);
RT_ASSERT(obj != object);
}
/* leave critical */
rt_spin_unlock_irqrestore(&(information->spinlock), level);
#endif /* RT_DEBUGING_ASSERT */
/* initialize object's parameters */
/* set object type to static */
object->type = type | RT_Object_Class_Static;
#if RT_NAME_MAX > 0
if (name)
{
obj_name_len = rt_strlen(name);
if(obj_name_len > RT_NAME_MAX - 1)
{
LOG_E("Object name %s exceeds RT_NAME_MAX=%d, consider increasing RT_NAME_MAX.", name, RT_NAME_MAX);
RT_ASSERT(obj_name_len <= RT_NAME_MAX - 1);
}
rt_memcpy(object->name, name, obj_name_len);
object->name[obj_name_len] = '\0';
}
else
{
object->name[0] = '\0';
}
#else
object->name = name;
#endif
RT_OBJECT_HOOK_CALL(rt_object_attach_hook, (object));
level = rt_spin_lock_irqsave(&(information->spinlock));
#ifdef RT_USING_MODULE
if (module)
{
rt_list_insert_after(&(module->object_list), &(object->list));
object->module_id = (void *)module;
}
else
#endif /* RT_USING_MODULE */
{
/* insert object into information object list */
rt_list_insert_after(&(information->object_list), &(object->list));
}
rt_spin_unlock_irqrestore(&(information->spinlock), level);
}具体的功能看源码就知道了,所以就不讲了。主要讲一下几个需要注意的点。
node = information->object_list.next;为什么不是node = information->object_list?
object_list 是一个链表头节点,而不是链表中实际的数据节点。它本身并不存放具体的 rt_object,只是用来标记链表的起点和终点。头节点本身 只是一个哨兵,不存数据。链表的实际元素是挂在 head.next 开始的。
for循环那段代码的作用是什么?
这段代码是 RT-Thread 对象系统的安全防护:它在对象初始化前,遍历当前类型的对象链表,确认待注册对象不在其中,防止重复插入导致系统崩溃。
防止同一对象被重复注册:
如果 object 已经在链表里,再次调用 rt_object_init() 就会在这里触发 RT_ASSERT(),程序直接报错(调试模式下会停住)。
保证链表一致性:
防止某个对象被插入两次,导致链表结构混乱(出现环路错误、内存覆盖等)。
rt_object_init()
↓
找到 object_list
↓
for 遍历链表
↓
if (obj == object) → 断言失败
↓
安全 → 插入链表
调试模式(宏定义)的设计
上面那段代码只有在开启调试断言模式时才会执行。断言触发导致程序中止(方便开发阶段定位错误)。
如果没有这个调试模式,那么rt_object_init() 会不做重复检查,直接初始化 object->type,然后把它插入到链表中(后续的 rt_list_insert_after)。
如果你真的传入了一个已经注册过的对象,可能会导致链表结构损坏(两个节点的 next / prev 链接乱掉),最终可能出现死循环、内存覆盖等问题。
这么设计主要是考虑性能问题:对象初始化是一个非常常用的操作(尤其在驱动和内核中);
每次初始化都去遍历整个链表会增加时间开销(O(n));在调试阶段加这个遍历检查是为了抓 bug;在发布阶段移除检查,换取性能。
②如何遍历内核对象?
以遍历所有互斥量为例子
rt_mutex_t mutex = RT_NULL;
struct rt_list_node *node = RT_NULL;
struct rt_object_information *information = RT_NULL;
information = rt_object_get_information(RT_Object_Class_Mutex);
rt_list_for_each(node, &(information->object_list))
{
mutex = (rt_mutex_t)rt_list_entry(node, struct rt_object, list);
/* 比如打印所有mutex的名字 */
rt_kprintf("name:%s\n", mutex->parent.parent.name);
}
三、设备管理函数讲解(device.c)
只讲解需要注意的函数
①设备打开函数(与设备关闭函数成对出现)
rt_err_t rt_device_open(rt_device_t dev, rt_uint16_t oflag)
{
rt_err_t result = RT_EOK;
/* parameter check */
RT_ASSERT(dev != RT_NULL);
RT_ASSERT(rt_object_get_type(&dev->parent) == RT_Object_Class_Device);
/* if device is not initialized, initialize it. */
if (!(dev->flag & RT_DEVICE_FLAG_ACTIVATED))
{
if (device_init != RT_NULL)
{
result = device_init(dev);
if (result != RT_EOK)
{
LOG_E("To initialize device:%.*s failed. The error code is %d",
RT_NAME_MAX, dev->parent.name, result);
return result;
}
}
dev->flag |= RT_DEVICE_FLAG_ACTIVATED;
}
/* device is a stand alone device and opened */
if ((dev->flag & RT_DEVICE_FLAG_STANDALONE) &&
(dev->open_flag & RT_DEVICE_OFLAG_OPEN))
{
return -RT_EBUSY;
}
/* device is not opened or opened by other oflag, call device_open interface */
if (!(dev->open_flag & RT_DEVICE_OFLAG_OPEN) ||
((dev->open_flag & RT_DEVICE_OFLAG_MASK) != ((oflag & RT_DEVICE_OFLAG_MASK) | RT_DEVICE_OFLAG_OPEN)))
{
if (device_open != RT_NULL)
{
result = device_open(dev, oflag);
}
else
{
/* set open flag */
dev->open_flag = (oflag & RT_DEVICE_OFLAG_MASK);
}
}
/* set open flag */
if (result == RT_EOK || result == -RT_ENOSYS)
{
dev->open_flag |= RT_DEVICE_OFLAG_OPEN;
dev->ref_count++;
/* don't let bad things happen silently. If you are bitten by this assert,
* please set the ref_count to a bigger type. */
RT_ASSERT(dev->ref_count != 0);
}
return result;
}主要功能就是一开始检查是否初始化了,如果没有初始化那就先初始化,然后如果是独立设备stand alone那么就不能多次打开。
下面的条件判断就要仔细看一下了。
/* device is not opened or opened by other oflag, call device_open interface */
if (!(dev->open_flag & RT_DEVICE_OFLAG_OPEN) ||
((dev->open_flag & RT_DEVICE_OFLAG_MASK) != ((oflag & RT_DEVICE_OFLAG_MASK) | RT_DEVICE_OFLAG_OPEN)))
{
if (device_open != RT_NULL)
{
result = device_open(dev, oflag);
}
else
{
/* set open flag */
dev->open_flag = (oflag & RT_DEVICE_OFLAG_MASK);
}
}第一个条件很简单:就是设备还没打开。RT_DEVICE_OFLAG_OPEN 是 RT-Thread 用来标记设备已打开的位。如果没打开,必须调用 device_open() 做初始化。
第二个条件:已经打开了但打开模式与这次请求不一样,那么需要执行 device_open()。
步骤拆解:
1.RT_DEVICE_OFLAG_MASK
用来屏蔽掉 open_flag 中与打开模式无关的位
只保留读写模式位(READ_ONLY / WRITE_ONLY / READ_WRITE)
2.(dev->open_flag & RT_DEVICE_OFLAG_MASK)
取出当前设备的打开模式
3.(oflag & RT_DEVICE_OFLAG_MASK)
取出本次请求打开的模式
4.| RT_DEVICE_OFLAG_OPEN
给本次请求的模式加上“已打开”标志
5.!=
如果当前模式与这次请求的模式不同,就返回真
然后下面的else表示:如果设备没有提供专门的 device_open() 函数,就直接把打开模式标记到 open_flag 里,而不去做硬件层面的初始化动作。
②RT_DEVICE_OFLAG_RDONLY与RT_DEVICE_FLAG_RDONLY有何区别,dev->flag和dev->oflag有何区别
RT_DEVICE_OFLAG_RDONLY与RT_DEVICE_FLAG_RDONLY的区别
RT_DEVICE_OFLAG_xxx
-
O 代表 Open
-
是打开设备时的请求模式
-
由调用
rt_device_open()的上层代码传入 -
临时性的,只代表这一次打开的模式
-
可以同一设备多次以不同模式打开(如果支持)
RT_DEVICE_FLAG_xxx
-
F 代表 Feature/Flag
-
是设备本身的能力特性
-
由驱动作者在
rt_device_register()时设置 -
长期存在,反映硬件功能
-
决定了上层能不能用某种模式打开设备
总结
-
FLAG:设备的“说明书” → 我这台机器支持什么 -
OFLAG:你现在打开这台机器时选了什么模式
dev->flag 和 dev->open_flag 的区别
-
dev->flag-
存储设备的能力标志(RT_DEVICE_FLAG_xxx)
-
由驱动在注册时设置,不会因为
open()而变 -
决定能否用某种
OFLAG打开设备
-
-
dev->open_flag-
存储设备当前的打开模式(RT_DEVICE_OFLAG_xxx)
-
在
rt_device_open()时被修改 -
打开后会一直保持到
rt_device_close()时清除
-
所以,下面的例子就会导致冲突。
dev->flag = RT_DEVICE_FLAG_RDONLY; // 注册时设置,只读
rt_device_open(dev, RT_DEVICE_OFLAG_WRONLY); 读写打开
那rt-thread中肯定会做是否冲突的判断,核心逻辑其实就是 用 dev->flag(硬件能力)去对比用户传进来的 oflag(打开请求模式)。但我在device_open函数中没有看到这部分代码,应该是分布在宏里或者放到驱动的 device_open() 实现里,但逻辑一样:用设备能力去限制打开模式。
四、环形缓冲区
1、缓冲区强制写入
rt_size_t rt_ringbuffer_put_force(struct rt_ringbuffer *rb,
const rt_uint8_t *ptr,
rt_uint32_t length)
{
rt_uint32_t space_length;
RT_ASSERT(rb != RT_NULL);
space_length = rt_ringbuffer_space_len(rb);
if (length > rb->buffer_size)
{
ptr = &ptr[length - rb->buffer_size];
length = rb->buffer_size;
}
//从写索引处到缓冲区尾部有足够的空间写入length个数据,不需要修改mirro镜像
if (rb->buffer_size - rb->write_index > length)
{
/* read_index - write_index = empty space */
rt_memcpy(&rb->buffer_ptr[rb->write_index], ptr, length);
/* this should not cause overflow because there is enough space for
* length of data in current mirror */
rb->write_index += length;
if (length > space_length)
rb->read_index = rb->write_index;
return length;
}
rt_memcpy(&rb->buffer_ptr[rb->write_index],
&ptr[0],
rb->buffer_size - rb->write_index);
rt_memcpy(&rb->buffer_ptr[0],
&ptr[rb->buffer_size - rb->write_index],
length - (rb->buffer_size - rb->write_index));
/* we are going into the other side of the mirror */
rb->write_mirror = ~rb->write_mirror;
rb->write_index = length - (rb->buffer_size - rb->write_index);
if (length > space_length)
{
if (rb->write_index <= rb->read_index)
rb->read_mirror = ~rb->read_mirror;
rb->read_index = rb->write_index;
}
return length;
}
mirror镜像对应msb最高位,当读索引或者写索引到达缓冲区尾部重新循环时,取反。
为什么w指针在小于等于r指针时,r指针的镜像才需要取反呢?
if (length > space_length)
{
if (rb->write_index <= rb->read_index)
rb->read_mirror = ~rb->read_mirror;
rb->read_index = rb->write_index;
}这段代码的前提(第一个条件)是要写入的数据大于缓冲区当前剩余的空位。第二个条件为什么要小于等于呢?
首先这段代码中的写索引是已经跨过缓冲区尾部并且写入之后更新过的数据,可以分情况来讨论。
没写入之前缓冲区的读写指针有三种情况。
① w > r
r' w
| ↓ ↓ |
| ———————————————————— |
| ↑ ↑ |
r w'这种情况下,从w后到r之前都是空的,而前提条件是要写入的数据大于剩余的空位并且要跨缓冲区尾部且不能超过缓冲区的总大小,所以在写入数据之后,新w’指针必然在r之后在原w之前。
而这时r需要更新成r’,r'需要等于w',而r往后移动到r'没有跨越尾部,所以不需要取反。
② w < r
r' r
| ↓ ↓ |
| ———————————————————— |
| ↑ ↑ |
w' w这种情况下,只有w指针到r指针之间的部分是空的。而前提条件是要写入的数据大于剩余的空位并且要跨缓冲区尾部且不能超过缓冲区的总大小,所以在写入数据之后,新w‘在缓冲区起始处到原w之间。
这时r需要更新成r’,r'需要等于w',而r往后移动到r'跨越了尾部,所以需要取反。
③ w = r
r' r
| ↓ ↓ |
| ———————————————————— |
| ↑ ↑ |
w' w此时没有空位,其余与第二种情况类似。
五、工作队列
1.RT-Thread中的工作队列的作用是什么?
在 RT-Thread 里,workqueue(工作队列)是一种 延迟/异步任务调度机制,主要作用是:
把一些耗时或不能在中断里完成的工作,放到线程上下文中去执行。
在嵌入式系统里,有些事情不适合在中断里直接做:
-
例如 I2C 读写、Flash 写入、网络数据处理,时间长,容易阻塞中断;
-
但你又希望中断发生时能触发这些操作。
这时可以在中断里仅仅“提交一个工作项(work)”,然后由 workqueue 线程在后台去完成真正的任务。
workqueue 本质是一个 线程 + 队列。
-
内部有一个
rt_thread不停轮询队列里的任务。 -
如果有新任务(work)被加入,就调度执行。
RT-Thread 的 workqueue 就像 Linux 的工作队列(workqueue)机制:
-
把中断上下文、延迟任务交给后台线程处理;
-
避免中断里做复杂逻辑;
-
也能定时执行任务(
rt_delayed_work)。
2.工作队列与DMA有何区别?
DMA 和工作队列并不是一个层面的东西,它们不能直接替代,但在某些场景下 DMA 的确能让你避免使用工作队列。
①RT-Thread 中的工作队列(workqueue)
-
本质:一个线程 + 一个任务队列。
-
用途:把不能在 中断上下文 做的耗时操作,延迟到 线程上下文 来执行。
-
典型场景:
-
中断里来了数据,先丢到缓冲区 → 提交一个工作到工作队列 → 工作队列线程里处理。
-
I²C/SPI/UART 收发完成后,数据解析、协议栈处理等比较重的逻辑。
-
②DMA(Direct Memory Access)
-
本质:硬件加速器,直接把外设和内存之间的数据搬运交给 DMA 控制器,不需要CPU一次次搬数据。
-
优势:
-
省 CPU,CPU 可以去干别的事。
-
速度快,因为是硬件搬运。
-
-
典型场景:
-
UART 接收数据:配置 DMA → DMA 自动搬到内存 → 触发中断。
-
SPI/LCD:DMA 批量传输像素数据。
-
| 特性 | DMA | 工作队列 |
|---|---|---|
| 本质 | 硬件外设 | 软件机制(线程+队列) |
| 处理内容 | 数据搬运(内存 <-> 外设) | 数据处理/业务逻辑(耗时任务) |
| 中断作用 | 传输完成时发中断 | 中断里提交任务到队列 |
| 耗时任务 | 不能做 | 可以做 |
| CPU 卸载 | 大幅度降低 CPU 开销 | 本质上还是 CPU 做,只是延迟到线程上下文 |
③DMA能代替worqueue吗?
-
DMA 能减少对工作队列的依赖:
举个例子,UART 接收 1KB 数据,如果没有 DMA,UART 中断会触发上千次 → 你可能需要工作队列来集中处理数据。
但用了 DMA,就变成:DMA 自动收 1KB → 一次中断 → 用户只要在 ISR 里唤醒线程处理即可,不需要工作队列来“搬运数据”。 -
DMA 不能替代工作队列的业务逻辑:
例如:-
协议解析(Modbus、MQTT)
-
JSON/XML 解析
-
文件系统读写
这些 DMA 干不了,还是需要工作队列(或者直接在应用线程里做)。
-
总结:
DMA = 硬件帮 CPU 搬数据。工作队列 = 软件机制帮你延迟处理耗时逻辑。
④linux中可以一次性从串口的fd中读多字节数据到用户缓冲区中,工作机制是怎样的?
Linux 串口内核驱动(tty/serial)通常有一个环形缓冲区(RX buffer)。数据从 UART 硬件接收 → 放入 RX buffer。用户态 read() 就是把 RX buffer 里的数据拷贝到用户态内存。
-
内核态已经在中断里把数据缓存好了。
-
用户态调用
read(fd, buf, count)时,内核直接把缓冲区里 连续的有效数据 拷贝出来。 -
也就是说,
read()并不是直接访问硬件,而是访问 内核缓冲区,所以一次性可以读多字节。
问:那Linux 串口内核驱动(tty/serial)通常有一个环形缓冲区(RX buffer)。数据从 UART 硬件接收 → 放入 RX buffer。 是用DMA吗?
不一定,要看具体的 UART 硬件和驱动实现:
中断模式(最常见)
-
UART 接收一个字节 → 触发 中断 → 内核中断处理函数把字节存入 环形缓冲区(RX buffer)
-
这种模式下 没有 DMA,每个字节都通过 CPU 中断拷贝。
-
优点:简单、硬件支持广;
-
缺点:CPU 频繁中断,数据量大时效率低。
DMA 模式
-
UART 支持 接收 DMA(Direct Memory Access)时,硬件可以直接把一段数据写入内核缓冲区,不需要 CPU 每接收一个字节中断。
-
驱动会设置 DMA 描述符 → 硬件自动把数据放到环形缓冲区 → 驱动只在缓冲区满或达到阈值时才触发一次中断。
-
优点:高效,减少 CPU 占用;
-
缺点:驱动实现复杂,需要硬件支持 DMA。
tty/serial 框架本身是兼容两种模式的,但驱动层决定是否启用 DMA。
问:中断模式(最常见)这个模式下,如果数据发送速度太快,uart的数据寄存器的数据不会被覆盖吗?导致传入到内核环形缓冲区中的数据不正确吗?
完全有可能,但 Linux 内核和硬件通常都有机制来尽量避免这个问题。
数据流(中断模式)
-
UART 硬件接收一个字节,存入 接收寄存器(RDR/DR)
-
硬件触发 RX 中断
-
内核中断处理函数(ISR)把 RDR 的字节 拷贝到 RX 环形缓冲区
可能发生覆盖的情况
-
如果 字节到达太快,比 ISR 处理速度还快:
-
硬件接收寄存器可能被新字节覆盖
-
内核 ISR 还没来得及把前一个字节读走
-
-
这种情况叫 接收溢出(Overrun)
-
UART 硬件通常会有 OVERRUN 标志位,内核可以检测到数据丢失
Linux 内核缓解方法
-
硬件 FIFO
大部分 UART 都有几字节到几十字节的 FIFO,减轻 ISR 频繁触发 -
环形缓冲区足够大
RX buffer 较大时,即使 CPU 延迟调度,暂时也不会溢出 -
中断优先级/加快 ISR
内核 ISR 尽量短,快速把数据搬到环形缓冲区 -
高速应用使用 DMA
DMA 可以直接批量写 RX buffer,避免单字节中断延迟导致丢数据
总结
-
理论上,如果数据发送速度太快且环形缓冲区满,会丢字节 → 数据错误
-
实践中:
-
硬件 FIFO + 内核 RX buffer + ISR 处理速度一般能满足常规串口速率(比如 115200 bps)
-
高速率、大数据量时,DMA 是更可靠的选择
-
3.工作队列在linux中的应用:
我们首先要搞清楚,linux的中断处理函数在哪里设置?
①用户态
在用户空间里,不能直接设置硬件中断处理函数(这一点与裸机或者RTOS不同)。
原因:
-
硬件中断是由 CPU 触发 → 内核响应 → 调用驱动中的中断服务程序(ISR)。
-
用户态没有权限直接访问中断控制器(如 APIC、GIC),也不能修改 IDT/IVT。
在用户态,你能接触到的只是 信号(signal)/事件(event),它们是内核把某些事件转化后发给用户态的机制。比如:
②内核态
在内核里写驱动时,可以注册硬件中断处理函数。
然后,用户态间接响应硬件中断。虽然用户态不能直接写 ISR,但可以通过内核驱动“转发事件”:
-
驱动里注册的硬件中断函数,ISR 里通过
poll/select/epoll、read()或ioctl()向用户态报告事件。 -
用户态程序再去处理。
比如 GPIO 中断,Linux 提供/sys/class/gpio/,用户程序可以poll()来等待 GPIO 中断。
总结:用户态要处理中断事件,通常写一个驱动 → 驱动注册 ISR → 驱动通过文件/事件机制通知用户态。内核态的中断一般处理方式是给用户态发出通知,具体的如何操作还是在用户态实现
硬件触发中断 → 内核 ISR 被调用
-
ISR(Interrupt Service Routine)必须尽量短小,不做耗时操作。
-
ISR 的任务一般是:
-
读取必要的硬件寄存器,清中断标志。
-
缓存数据到内核缓冲区(比如环形缓冲区)。
-
通知用户态或唤醒线程做后续处理。
-
通知用户态方式
内核可以通过多种方式让用户态感知事件:
-
文件接口
-
驱动创建字符设备
/dev/mydev。 -
用户态
read()/poll()/select()等阻塞等待。
-
-
信号(signal)
-
驱动通过
kill_pid()给指定用户进程发送SIGIO信号。
-
-
netlink/socket
-
内核和用户态通过 netlink 套接字通信。
-
-
wait queue / completion / eventfd
-
内核 ISR 设置状态 → 用户态线程通过阻塞等待事件。
-
用户态处理逻辑
-
用户态程序收到通知后,去读内核缓冲区的数据,或者执行具体业务逻辑。
-
优点:
-
ISR 快速返回,不阻塞硬件中断。
-
用户态可以自由使用阻塞/耗时操作。
-
扩展:
io的读事件或者写事件在没有利用内核提供的真正异步处理函数时,都不算是真正的异步工作,比如读事件,epoll/poll监听的fd有数据到来,这时需要把数据从内河缓冲区读到用户缓冲区,这个过程实际是会阻塞当前线程的,会影响当前线程后续的工作的,又或者是要对这些数据进行的处理很费时(数据解析,协议处理等)。
那么利用工作队列可以在linux中实现真正的异步工作,只把耗时的工作函数放入到工作队列中,然后后台线程(工作队列线程)处理异步任务。但如果再优化一下可以加入优先级使用大顶堆 小顶堆数据结构。
注:这只是在没有用内核提供的异步工作函数的情况下,用户态实现的模拟异步工作方式。因为内核提供的异步函数我没用过。
4.主要函数讲解
①主要结构体介绍
struct rt_workqueue
{
rt_list_t work_list;
rt_list_t delayed_list;
struct rt_work *work_current; /* current work */
struct rt_semaphore sem;
rt_thread_t work_thread;
};
list就是工作队列里的工作链表表头。delayed list是延迟工作链表表头。
struct rt_work
{
rt_list_t list;
void (*work_func)(struct rt_work *work, void *work_data);
void *work_data;
rt_uint16_t flags;
rt_uint16_t type;
struct rt_timer timer;
struct rt_workqueue *workqueue;
};
list是工作项链表表头(哨兵节点)。
②工作项提交函数
static rt_err_t _workqueue_submit_work(struct rt_workqueue *queue,
struct rt_work *work, rt_tick_t ticks)
{
rt_base_t level;
rt_err_t err = RT_EOK;
struct rt_work *work_tmp;
rt_list_t *list_tmp;
level = rt_spin_lock_irqsave(&(queue->spinlock));
/* remove list */
rt_list_remove(&(work->list)); //把当前work工作项从工作项链表中移除。
work->flags = 0;
if (ticks == 0)
{
rt_list_insert_after(queue->work_list.prev, &(work->list)); //尾插法(双向的所以是prev)
work->flags |= RT_WORK_STATE_PENDING;
work->workqueue = queue;
rt_completion_done(&(queue->wakeup_completion));
err = RT_EOK;
}
else if (ticks < RT_TICK_MAX / 2)
{
/* insert delay work list */
work->flags |= RT_WORK_STATE_SUBMITTING;
work->workqueue = queue;
work->timeout_tick = rt_tick_get() + ticks;
//queue->delayed_list 是一个 延时任务链表头(环形链表)。注意实际节点是第二个
list_tmp = &(queue->delayed_list);
for (work_tmp = rt_list_entry(list_tmp->next, struct rt_work, list);
&work_tmp->list != list_tmp;
work_tmp = rt_list_entry(work_tmp->list.next, struct rt_work, list))
{
if ((work_tmp->timeout_tick - work->timeout_tick) < RT_TICK_MAX / 2)
{
list_tmp = &(work_tmp->list);
break;
}
}
rt_list_insert_before(list_tmp, &(work->list));
rt_completion_done(&(queue->wakeup_completion));
err = RT_EOK;
}
else
{
err = -RT_ERROR;
}
rt_spin_unlock_irqrestore(&(queue->spinlock), level);
return err;
}该函数根据是否是延时任务项来执行。
该函数的主要作用是把一个新的 work 插入到队列的延时链表里,并保证链表按超时时间升序排列。
work_tmp是延时链表里的工作项,work是要提交的工作项。
rt_list_insert_after(queue->work_list.prev, &(work->list));这里有两个对象:
-
queue->work_list→ 是链表头(类型是struct rt_list,RT-Thread 的链表实现,和 Linux 的list_head类似,就是表头)。 -
work->list→ 是某个struct rt_work里的链表节点成员。
也就是说,你只是把 work 结构体的 list 节点 插入到 queue->work_list 的链表里。
利用通用链表的统一管理相同结构体里的链表节点。
-
混用不同结构体:指的是一个链表里同时放
struct student和struct teacher,需要额外标识来区分。 -
这里的情况:一个链表里全是
struct rt_work节点,链表节点的类型统一,取回时用rt_list_entry(pos, struct rt_work, list)就能正确解析。
所以这只是“同一类型对象的链表管理”,而不是混用。
if ((work_tmp->timeout_tick - work->timeout_tick) < RT_TICK_MAX / 2)
-
这里是 关键排序逻辑。
-
timeout_tick表示该任务应该超时的时刻(系统 tick 计数)。 -
因为
rt_tick_t是无符号数,tick 计数会溢出,所以不能直接比较大小。 -
通常做法是:
A 在 B 前触发当(A - B) < (MAX_TICK / 2)。 -
这样能正确处理 tick 溢出的问题。
++这里讲一下为什么要这么做
这个是 处理无符号 tick 计数溢出时序比较 的经典技巧。
在 RTOS(RT-Thread / FreeRTOS / Linux 内核 jiffies)里,系统时钟 tick 计数通常是一个 无符号整数(比如 32 位 rt_tick_t)。
-
tick 一直自增,到达最大值时溢出回 0。
-
所以 tick 值不是单调无限递增的,而是一个环形的。
例如,假设 MAX = 2^32 - 1 = 0xFFFFFFFF:
假设有两个点:
-
A = 0xFFFFFFFE
-
B = 0x00000005
从逻辑上看:
B 在 A 之后触发(B 是溢出之后的时间点)。
但如果直接用大小比较:
A (0xFFFFFFFE) > B (0x00000005)
会误判,错误地认为 A 在 B 后面。
解决办法L:推导过程放在最后的附录。
用差值 (A - B) 来比较,并结合 半个最大值 (MAX/2) 的判断。
如果 (A - B) < MAX/2 ,说明 B比 A 早。或者说A更晚
如果 (A - B) > MAX/2 ,说明 A比 B 早。或者说A更早
(X - Y) == MAX/2 → 模棱两可,因为环形距离刚好是半圈,无法确定谁先谁后。
那么此时是不是 X,Y的最大值就是MAX/2,不能超过这个值
else if (ticks < RT_TICK_MAX / 2)是的,合法比较时,差值不能超过 MAX/2,所以ticks不能超过MAX/2。
{
list_tmp = &(work_tmp->list);
break;
}-
找到第一个比
work超时时间更大的work_tmp。 -
把
list_tmp更新为它的位置,准备把新work插到它前面。 -
break跳出循环,插入操作在循环外完成。
③ 工作队列线程函
static void _workqueue_thread_entry(void *parameter)主要作用:把到期的延时 work 从 delayed_list 转移到就绪队列 work_list,若有就绪 work 就取出执行;若没有就绪 work,则带超时地睡眠等待下一件事发生(到期或被唤醒)。
current_tick = rt_tick_get();
delay_tick = RT_WAITING_FOREVER;
while (!rt_list_isempty(&(queue->delayed_list)))
{
work = rt_list_entry(queue->delayed_list.next, struct rt_work, list);
if ((current_tick - work->timeout_tick) < RT_TICK_MAX / 2)
{
rt_list_remove(&(work->list));
rt_list_insert_after(queue->work_list.prev, &(work->list)); // 入就绪队列尾部
work->flags &= ~RT_WORK_STATE_SUBMITTING;
work->flags |= RT_WORK_STATE_PENDING;
}
else
{
delay_tick = work->timeout_tick - current_tick;
break;
}
}
把“已到期”的延时 work 移到就绪队列
delayed_list 是按到期时间排序的,因此只需要看链表头(delayed_list.next)。
-
到期则:
-
从
delayed_list删除该 work; -
rt_list_insert_after(queue->work_list.prev, &work->list):插到 就绪队列尾(prev是尾结点,等价于list_add_tail),保持 FIFO 执行顺序; -
更新标志:从 SUBMITTING 变为 PENDING。
-
-
未到期:
-
由于链表按时间升序,后面的也一定更晚,所以计算这个最早的剩余等待时间:
-
delay_tick = work->timeout_tick - current_tick;
-
-
然后
break;,不再检查后续。
-
小提示:
这里能“连续搬运”多条到期 work,因为while会继续检查表头,直到遇到一个未到期的 work 为止。
if (rt_list_isempty(&(queue->work_list)))
{
rt_spin_unlock_irqrestore(&(queue->spinlock), level);
rt_completion_wait(&(queue->wakeup_completion), delay_tick);
continue;
}
若没有就绪 work,则带超时地睡眠等待。
-
如果此刻
work_list为空:-
释放锁;
-
rt_completion_wait(..., delay_tick)进入阻塞:-
delay_tick == FOREVER:表示没有任何延时 work,纯粹等别人“唤醒我”(有新 work 提交时会 complete)。 -
delay_tick > 0:表示最早的延时 work 还有这么多 tick 到期;到期或被外部新提交唤醒都会返回。
-
-
-
continue;回到主循环,重新处理(可能是到期了、也可能被唤醒了)。
work = rt_list_entry(queue->work_list.next, struct rt_work, list); // 取头
rt_list_remove(&(work->list)); // 出队
queue->work_current = work; // 标记当前正在执行的 work
work->flags &= ~RT_WORK_STATE_PENDING;
work->workqueue = RT_NULL; // 解除归属(便于后续再次提交)
work_func = work->work_func; // 提前取出回调与数据
work_data = work->work_data;
rt_spin_unlock_irqrestore(&(queue->spinlock), level);
-
取头执行:保持 FIFO。
-
抢占式设计:在执行回调之前先把锁放掉,这样执行期间其他 CPU/中断可以继续提交 work、移动 work,不会阻塞队列管理。
-
work->workqueue = RT_NULL;:很多实现用这个字段判断一个 work 是否“已在某个队列中/被占用”,置空意味着现在它“脱离队列”,回调里如果愿意,可以把自己再次提交(重新入队)。
work_func(work, work_data); // 真正做事
queue->work_current = RT_NULL;
_workqueue_work_completion(queue); // 通知:有 work 完成了
-
执行用户提供的处理函数。
-
清空
work_current,表明 worker 空闲了。 -
_workqueue_work_completion(queue):通常会rt_completion_done(&queue->wakeup_completion),用于:-
唤醒可能等待“队列空闲”的提交者;
-
或者作为“有事件发生”的通用唤醒点。
-
5.workqueue在RT-Thread中的应用
附录:
用差值 (A - B) 来比较,并结合 半个最大值 (MAX/2) 的判断。
如果 (A - B) < MAX/2 ,说明 B比 A 早。或者说A更晚
如果 (A - B) > MAX/2 ,说明 A比 B 早。或者说A更早
为什么如此(严格推导 + 直观解释)
把 tick 环看成一个环(0 → MAX → 0)。对于两个时间点 A 与 B,考虑无符号差 A - B(这是模运算,自动处理溢出)。
-
A - B表示从B沿“正向”(递增方向)走到A的“距离”(以 tick 单位,模RT_TICK_MAX+1)。 -
如果这个“正向距离”小于一圈的一半(
< RT_TICK_MAX/2),说明 从 B 沿正向很快就能到达 A,换句话说 A 位于 B 的“未来半圈”内,也就是 A 在时间线上晚于 B(A 比 B 更靠后)。 -
如果
A - B很大(> 半圈),说明从 B 沿正向到 A 要绕过很大一段(接近整圈),这意味着 A 实际上位于 B 的“过去半圈”——即 A 比 B 更早。
用具体数字验证
设 RT_TICK_MAX = 100(为方便举例,真实是 2^N-1):
-
不发生溢出、A 在 B 之后:
-
B = 50, A = 80
-
A - B = 30 < 50 → 表示 A 在 B 之后(更晚)。符合直观。
-
-
不发生溢出、A 在 B 之前:
-
B = 50, A = 20
-
A - B = (20 - 50) mod 101 = 71 > 50 → 表示 A 在 B 之前(更早)。
-
-
发生溢出(A 很大、B 很小),实际 A 在 B 之后:
-
A = 98, B = 5 (时间上 A 比 B 晚,A 在溢出前)
-
A - B = 93 > 50 → 表示 A 在 B 之前(看起来像“早”) —— 注意这是相对 B 的判断:从 B 向前到 A 要绕大圈,说明 A 实际是在 B 的过去(即 A 比 B 早)。(这例子是为说明规则一致性)
-
更直观的说法:
-
(X - Y) < half→ 从 Y 前进到 X 路程短 → X 在 Y 的“未来” → X 更晚。 -
(X - Y) > half→ 从 Y 前进到 X 路程长(要绕一大圈) → X 在 Y 的“过去” → X 更早。
为什么会有 MAX/2 的概念
tick 计数是 无符号数(比如 uint32_t),范围是 0 ~ MAX(MAX=2^32-1)。
当你做差值 (X - Y) 时,这是 模运算(overflow 自动回环)。
为了判断 X 在 Y 的“过去”还是“未来”,我们要比较 模差值。
因为 tick 是个“环”,如果不限制范围,就会有二义性。
举个例子:
-
MAX = 100(方便演示),那么MAX/2 = 50。 -
Y = 20, X = 80。-
你说
X比Y晚吗? -
如果看“直线”,X=80 > Y=20 → 晚。
-
但在环上,差值
(X - Y) = 60,这比MAX/2=50大,意味着“绕大圈”才到 X → 所以判断规则认为 X 其实在 Y 的过去。
-
这就是为什么要限制在 MAX/2:
我们规定:时间差的“合法范围”只能落在
[-MAX/2, +MAX/2]之间。
这样就保证比较是唯一且无二义性的。
那么差值的最大值是不是 MAX/2?
是的,合法比较时,差值不会超过 MAX/2。
超过 MAX/2 的差值就会被解释成“绕大圈”,也就是“相反方向”。
-
(X - Y) < MAX/2→ X 在 Y 的未来(X 更晚) -
(X - Y) > MAX/2→ X 在 Y 的过去(X 更早) -
(X - Y) == MAX/2→ 模棱两可,因为环形距离刚好是半圈,无法确定谁先谁后。
通常有两种处理方法:
-
约定一方优先:比如认为差值等于半圈时,“A 不晚于 B”。
-
避免设计这种场景:实际上 tick 一般是毫秒级,
MAX/2的跨度是几十年(32bit tick 大约 49 天;64bit tick 根本够不到),所以根本不会出现== MAX/2的情况,直接不用管。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)