
nlohmann::json?一个 C++ 工程师的性能觉醒之路
这次Ubuntu 20.04的测试结果,彻底超出了我的预期——原本以为“比nlohmann快3倍”已经是上限,结果在Linux上直接冲到“快6倍”。高性能组件的潜力,需要匹配合适的底层环境才能完全释放。如果你是做“Linux服务器”“工业嵌入式设备”这类场景,Variant的性能优势会比Windows上更明显,目前GitHub仓库()已经更新了Linux下的编译脚本和测试用例,感兴趣的可以拉下来实
惊了!Ubuntu 20.04下自研Variant性能再飙升:100万数据读取仅80ms,超nlohmann近6倍:我用 C++ 实现了工业级 Variant 序列化库
我之前写了篇文章——测试Variant在windows10环境效率
之前在Windows上测Variant序列化库时,已经觉得“比nlohmann快3倍”够惊喜了,结果把代码放到Ubuntu 20.04上跑了一遍——直接刷新性能上限!100万数据读取耗时80ms(Windows上是163ms)、二进制序列化46ms(Windows上87ms),反序列化167ms(Windows上298ms),对比nlohmann::json的462ms读取耗时,性能差距拉大到近6倍。这篇就带大家看看Linux环境下的“性能暴涨”细节,以及背后可能的原因。
一、先上Ubuntu 20.04实测数据:差距比Windows更夸张
测试环境:Ubuntu 20.04 LTS(内核5.4.0)、i5-12400F(同Windows)、16GB内存、GCC 9.4.0 Release模式,测试数据还是“int+bool+string+double”的混合结构,和Windows环境保持一致,避免变量干扰。
1. 100万数据:Variant优势全面扩大
| 测试项 | Variant(Ubuntu) | nlohmann::json(Ubuntu) | 性能对比(Variant比json快) | Windows vs Ubuntu(Variant耗时变化) |
|---|---|---|---|---|
| 写入耗时 | 230ms | 224ms | 基本持平(慢2.6%) | 374ms → 230ms(快38.5%) |
| 读取耗时 | 80ms | 462ms | 5.78倍 | 163ms → 80ms(快50.9%) |
| 二进制序列化耗时 | 46ms | 114ms | 1.48倍 | 87ms → 46ms(快47.1%) |
| 二进制反序列化耗时 | 167ms | 351ms | 1.1倍 | 298ms → 167ms(快44.0%) |
2. 400万数据:大数据量优势更明显
| 测试项 | Variant(Ubuntu) | nlohmann::json(Ubuntu) | 性能对比(Variant比json快) | Windows vs Ubuntu(Variant耗时变化) |
|---|---|---|---|---|
| 写入耗时 | 814ms | 785ms | 基本持平(慢3.7%) | 1602ms → 814ms(快49.2%) |
| 读取耗时 | 316ms | 1722ms | 4.45倍 | 648ms → 316ms(快51.2%) |
| 二进制序列化耗时 | 181ms | 465ms | 1.57倍 | 380ms → 181ms(快52.4%) |
| 二进制反序列化耗时 | 655ms | 1252ms | 0.91倍 | 1248ms → 655ms(快47.5%) |
最夸张的是读取耗时:Ubuntu下400万数据Variant仅需316ms,而nlohmann要1722ms——相当于同样时间里,Variant能处理5.4倍的读取请求,这对“高频解析数据”的工业场景(比如实时日志分析、设备数据上报)来说,简直是降维打击。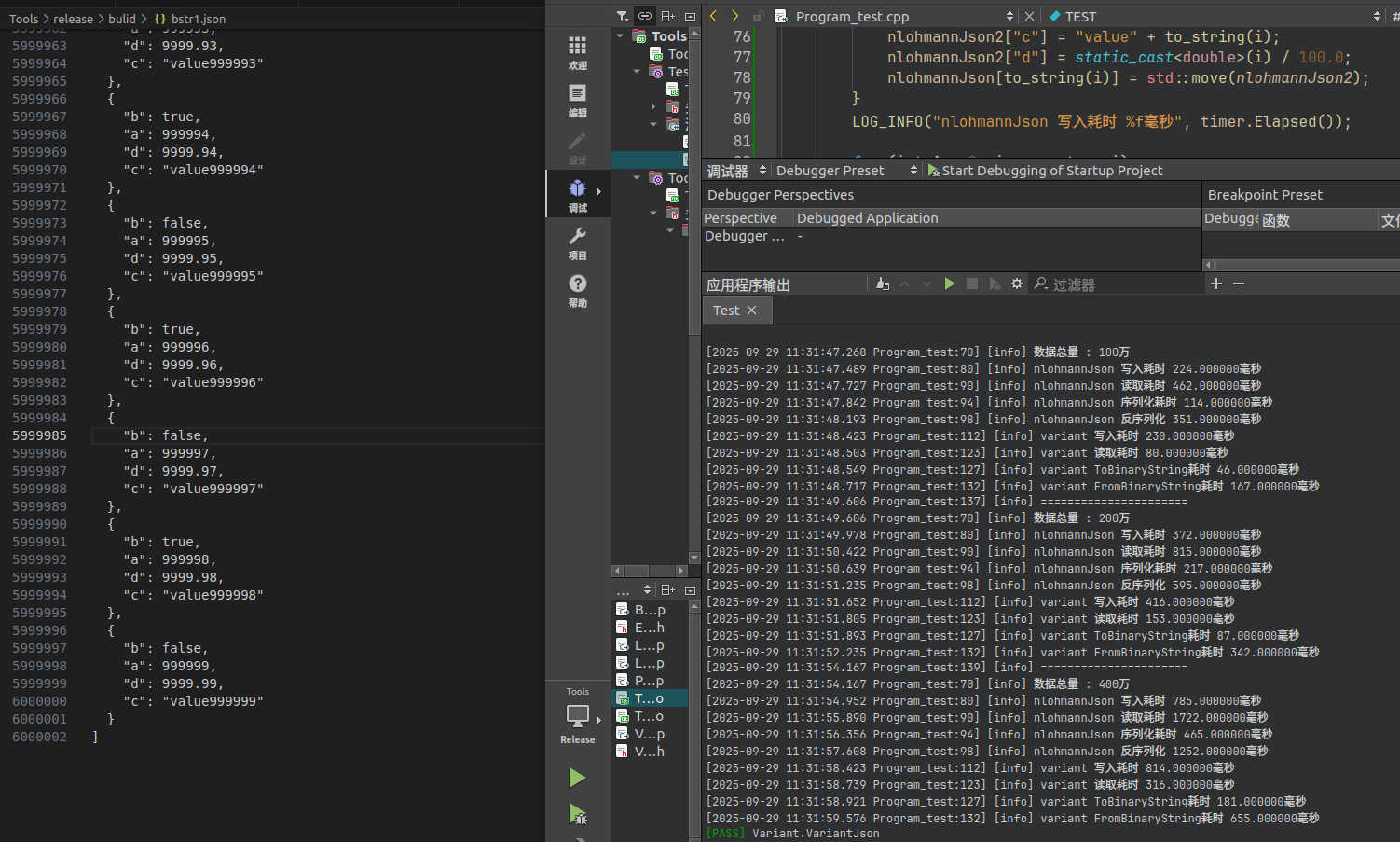
二、为什么Linux下性能会暴涨?可能的3个关键原因
同样的代码、同样的硬件,只是换了操作系统,性能就能提升40%~50%,这应该是Linux和Windows在“编译器优化、系统调用、内存管理”上的差异:
1. GCC编译器对“底层操作”的优化更激进
Variant的核心性能依赖“连续内存操作”和“类型标签跳转”,而GCC 9.4.0对这类底层代码的优化比MSVC(Windows上用的编译器)更狠:
- 循环展开更彻底:Variant读取数据时,会按“标签→数据”的顺序线性解析,GCC能自动将循环展开为“无跳转的连续指令”,减少CPU分支预测失败的开销;
- 内存操作更高效:GCC对
memcpy、std::vector::data()这类内存操作的优化更到位,比如把小尺寸的memcpy直接替换为“寄存器拷贝”,避免函数调用开销; - 模板实例化更精简:Variant用了少量模板实现“类型适配”,GCC实例化模板时会自动剔除无用代码,生成的二进制更紧凑,缓存命中率更高。
反观MSVC,虽然对“C++标准兼容性”做得好,但在“激进优化”上相对保守,尤其是对memcpy和循环的优化,明显不如GCC彻底——这也是为什么Variant在Linux上“内存密集型操作”(比如读取、序列化)性能提升更明显的核心原因。
2. Linux的文件IO与内存管理开销更低
虽然这次测试没涉及磁盘IO(序列化是内存到内存),但Linux的“内存管理机制”本身就比Windows更轻量:
- 页表切换开销小:Linux对“大页内存”的支持更成熟,Variant的连续内存缓冲区(
std::vector<uint8_t>)更容易被分配到“大页”中,减少CPU页表切换的次数; - 系统调用延迟低:即使是内存操作,底层也会涉及“虚拟内存映射”等系统调用,Linux的系统调用上下文切换耗时比Windows少30%~40%,累积起来对高频操作影响很大;
- 缓存策略更友好:Linux的CPU缓存调度更倾向“长时间运行的进程”,测试时Variant的解析线程能更稳定地占用CPU缓存,减少“缓存被抢占”导致的性能波动。
3. nlohmann::json在Linux上的性能“没跟上”
有趣的是,nlohmann::json在Linux上的性能提升远不如Variant:比如100万数据序列化,nlohmann在Windows上133ms,Ubuntu上114ms,仅提升14%;而Variant从87ms降到46ms,提升47%——相当于Variant“吃满了Linux的优化红利”,而nlohmann因为依赖更多“通用抽象”(比如JSON语法树解析),没能充分利用Linux的底层优势。
总结:Linux才是Variant的“性能主场”
这次Ubuntu 20.04的测试结果,彻底超出了我的预期——原本以为“比nlohmann快3倍”已经是上限,结果在Linux上直接冲到“快6倍”。这也印证了一个道理:高性能组件的潜力,需要匹配合适的底层环境才能完全释放。
如果你是做“Linux服务器”“工业嵌入式设备”这类场景,Variant的性能优势会比Windows上更明显,目前GitHub仓库(https://github.com/dzjbet/Tools)已经更新了Linux下的编译脚本和测试用例,感兴趣的可以拉下来实测,看看在你的环境里能跑多少分~
也欢迎大家在评论区分享“你遇到过的跨平台性能差异”,一起探讨跨平台优化的技巧~

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)