
CompileX:从 GCC 到 STM32 的编译与内存映射全解析
在现代计算机系统中,从C 源代码到可执行文件的过程并非一条简单的黑箱流水线,而是一段充满逻辑与体系的工程旅程。GCC 作为 Linux 与嵌入式开发中最广泛使用的编译器,不仅承担着代码翻译的使命,更深刻地影响着内存布局、符号链接、执行效率与跨平台兼容性。本实验以“GCC 编译与 STM32 存储映射对比分析”为核心,通过在与C 程序中全局变量、静态变量、局部变量、堆、栈的存储分配差异;GCC 编译
文章目录
前言
在现代计算机系统中,从 C 源代码到可执行文件 的过程并非一条简单的黑箱流水线,而是一段充满逻辑与体系的工程旅程。
GCC 作为 Linux 与嵌入式开发中最广泛使用的编译器,不仅承担着代码翻译的使命,更深刻地影响着 内存布局、符号链接、执行效率与跨平台兼容性。
本实验以 “GCC 编译与 STM32 存储映射对比分析” 为核心,通过在 Ubuntu (x86) 与 STM32 (Cortex-M3) 平台上分别编写、编译与运行 C 程序,深入理解以下关键概念:
- C 程序中 全局变量、静态变量、局部变量、堆、栈 的存储分配差异;
- GCC 编译流程(预处理 → 编译 → 汇编 → 链接)的工作机制;
- ELF 文件结构 与 Linux 下可执行程序的内存映射方式;
- ARM Cortex-M / STM32F10x 存储器映射 与 Flash、SRAM、外设空间的关系;
- 通过 串口输出变量地址,验证嵌入式系统中实际物理地址分布。
实验的目标不仅是“让程序能跑起来”,更重要的是让开发者清楚地知道 代码的每一段存放在哪里、为什么这样设计、系统如何加载与运行它。
从而搭建起对 编译系统与存储体系的整体认知框架 —— 为后续学习操作系统、嵌入式底层、RTOS 内核打下扎实基础。
一、Linux GCC 常用命令
1. GCC简介
GCC 的原意是 GNU C Compiler(GNU C 编译器)。
经过多年发展,GCC 已不仅仅支持 C 语言,它现在已经成为一个 GNU 编译器家族(GNU Compiler Collection),支持:
- C / C++ / Ada / Java / Objective-C / Pascal / COBOL / Mercury 等多种语言
- 多种 操作系统平台与硬件架构(x86、ARM、RISC-V、MIPS…)
一句话总结:
💡 GCC,无所不在。
2. 单个程序的编译
示例代码:
//test.c
#include <stdio.h>
int main(void)
{
printf("Hello World!\n");
return 0;
}
这个程序,一步到位的编译指令是:
gcc test.c -o test
实质上,上述编译过程是分为四个阶段进行的,即预处理(也称预编译,Preprocessing)、编译(Compilation)、汇编 (Assembly)和连接(Linking)。
2.1 预处理
gcc -E test.c -o test.i 或 gcc -E test.c
可以输出 test.i 文件中存放着 test.c 经预处理之后的代码。打开 test.i 文件,看一看,就明白了。后面那条指令,是直接在命令行窗口中输出预处理后的代码。
gcc 的-E 选项,可以让编译器在预处理后停止,并输出预处理结果。在本例中,预处理结果就是将stdio.h 文件中的内容插入到 test.c 中了。
2.2 编译为汇编代码(Compilation)
gcc -S test.i -o test.s
gcc 的-S 选项,表示在程序编译期间,在生成汇编代码后,停止,-o 输出汇编代码文件。
2.3 汇编(Assembly)
gcc -c test.s -o test.o
2.4 连接(Linking)
gcc test.o -o test
gcc 连接器是 gas 提供的,负责将程序的目标文件与所需的所有附加的目标文件连接起来,最终生成可执行文件。附加的目标文件包括静态连接库和动态连接库。
3. 多个程序文件的编译
假设有一个由 test1.c 和 test2.c 两个源文件组成的程序,为了对它们进行编译,并最终生成可执行程序 test,可以使用下面这条命令:
gcc test1.c test2.c -o test
如果同时处理的文件不止一个,GCC 仍然会按照预处理、编译和链接的过程依次进行。如果深究起来,上面这条命令大致相当于依次执行如下三条命令:
gcc -c test1.c -o test1.o
gcc -c test2.c -o test2.o
gcc test1.o test2.o -o test
4. 检错
gcc -pedantic illcode.c -o illcode
-pedantic 编译选项并不能保证被编译程序与 ANSI/ISO C 标准的完全兼容,它仅仅只能用来帮助Linux 程序员离这个目标越来越近。或者换句话说,-pedantic 选项能够帮助程序员发现一些不符合ANSI/ISO C 标准的代码,但不是全部,事实上只有 ANSI/ISO C 语言标准中要求进行编译器诊断的那些情况,才有可能被 GCC 发现并提出警告。
除了-pedantic 之外,GCC 还有一些其它编译选项也能够产生有用的警告信息。这些选项大多以-W开头,其中最有价值的当数-Wall 了,使用它能够使 GCC 产生尽可能多的警告信息。
gcc -Wall illcode.c -o illcode GCC
给出的警告信息虽然从严格意义上说不能算作错误,但却很可能成为错误的栖身之所。一个优秀的 Linux 程序员应该尽量避免产生警告信息,使自己的代码始终保持标准、健壮的特性。所以将警告信息当成编码错误来对待,是一种值得赞扬的行为!所以,在编译程序时带上-Werror 选项,那么 GCC 会在所有产生警告的地方停止编译,迫使程序员对自己的代码进行修改,如下:
gcc -Werror test.c -o test
5. 库文件连接
开发软件时,完全不使用第三方函数库的情况是比较少见的,通常来讲都需要借助许多函数库的支持才能够完成相应的功能。从程序员的角度看,函数库实际上就是一些头文件(.h)和库文件(so、或 lib、dll)的集合。虽然 Linux 下的大多数函数都默认将头文件放到/usr/include/目录下,而库文件则放到/usr/lib/目录下;Windows 所使用的库文件主要放在 Visual Stido 的目录下的 include 和 lib,以及系统文件夹下。但也有的时候,我们要用的库不再这些目录下,所以 GCC 在编译时必须用自己的办法来查找所需要的头文件和库文件。
例如我们的程序 test.c 是在 linux 上使用 c 连接 mysql,这个时候我们需要去 mysql 官网下载 MySQLConnectors 的 C 库,下载下来解压之后,有一个 include 文件夹,里面包含 mysql connectors 的头文件,还有一个 lib 文件夹,里面包含二进制 so 文件 libmysqlclient.so
其中 inclulde 文件夹的路径是/usr/dev/mysql/include,lib 文件夹是/usr/dev/mysql/lib
5.1 编译成可执行文件
首先我们要进行编译 test.c 为目标文件,这个时候需要执行:
gcc –c –I /usr/dev/mysql/include test.c –o test.o
5.2 链接
最后我们把所有目标文件链接成可执行文件:
gcc –L /usr/dev/mysql/lib –lmysqlclient test.o –o test
Linux 下的库文件分为两大类分别是动态链接库(通常以.so 结尾)和静态链接库(通常以.a 结尾),二者的区别仅在于程序执行时所需的代码是在运行时动态加载的,还是在编译时静态加载的。
5.3 强制链接时使用静态链接库
默认情况下, GCC 在链接时优先使用动态链接库,只有当动态链接库不存在时才考虑使用静态链接库,如果需要的话可以在编译时加上-static 选项,强制使用静态链接库。
在/usr/dev/mysql/lib 目录下有链接时所需要的库文件 libmysqlclient.so 和 libmysqlclient.a,为了让GCC 在链接时只用到静态链接库,可以使用下面的命令:
gcc –L /usr/dev/mysql/lib –static –lmysqlclient test.o –o test
二、GCC背后的“战友”
1. GCC
GCC(GNU C Compiler)是编译工具。本文所要介绍的将 C/C++语言编写的程序转换成为处理器能够执行的二进制代码的过程即由编译器完成。
2. Binutils
一组二进制程序处理工具,包括:addr2line、ar、objcopy、objdump、as、ld、ldd、readelf、 size 等。这 一组工具 是开发和 调试不可 缺少的工具 ,分别简 介如下:
(1) addr2line:用 来将程序 地址转 换成其所 对应的程 序源文 件及所对 应的代 码行,也可以得到所对应的函数。该工具将帮助调试器在调试的过程中定位对应的源代码位置。
(2) as:主要用于汇编,有关汇编的详细介绍请参见后文。
(3) ld:主要用于链接,有关链接的详细介绍请参见后文。
(4) ar:主要用于创建静态库。
(5) ldd:可以用于查看一个可执行程序依赖的共享库。
(6) objcopy:将一种对象文件翻译成另一种格式,譬如将.bin 转换成.elf、或者将.elf 转换成.bin 等。
(7) objdump:主要的作用是反汇编。有关反汇编的详细介绍,请参见后文。
(8) readelf:显示有关 ELF 文件的信息,请参见后文了解更多信息。
(9) size:列出可执行文件每个部分的尺寸和总尺寸,代码段、数据段、总大小等,请参见后文了解使用 size 的具体使用实例。
3. C 运行库
C 语言标准主要由两部分组成:一部分描述 C 的语法,另一部分描述 C 标准库。C 标准库定义了一组标准头文件,每个头文件中包含一些相关的函数、变量、类型声明和宏定义,譬如常见的 printf 函数便是一个 C 标准库函数,其原型定义在 stdio 头文件中。
C 语言标准仅仅定义了 C 标准库函数原型,并没有提供实现。因此,C 语言编译器通常需要一个 C 运行时库(C Run Time Libray,CRT)的支持。C 运行时库又常简称为 C 运行库。与 C 语言类似,C++也定义了自己的标准,同时提供相关支持库,称为 C++运行时库。
4. ELF 文件
ELF 文件格式如下图所示,位于 ELF Header 和 Section Header Table 之间的都是段(Section)。一个典型的 ELF 文件包含下面几个段:
.text:已编译程序的指令代码段。
.rodata:ro 代表 read only,即只读数据(譬如常数 const)。
.data:已初始化的 C 程序全局变量和静态局部变量。
.bss:未初始化的 C 程序全局变量和静态局部变量。
.debug:调试符号表,调试器用此段的信息帮助调试。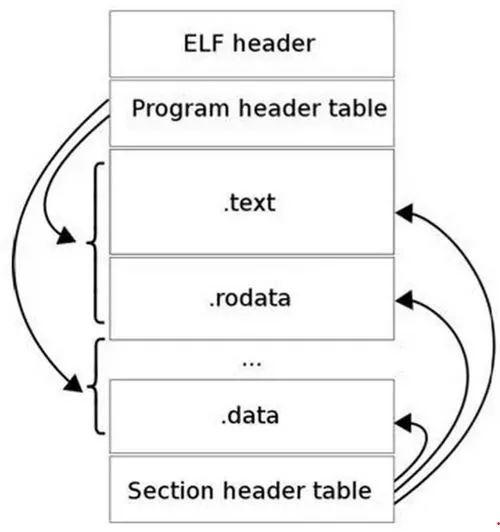
三、用 gcc 生成 .a 静态库和 .so 动态库
什么是静态库和动态库?
我们通常把一些公用函数制作成函数库,供其它程序使用。函数库分为静态库和动态库两种。静态库在程序编译时会被连接到目标代码中,程序运行时将不再需要该静态库。动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入,因此在程序运行时还需要动态库存在。
1. 生成示例程序
(1)先创建一个作业目录,保存本次练习的文件。
(2)用vim、nano 或 gedit 等文本编辑器编辑生成所需要的 3 个文件。
hello.h
#ifndef HELLO_H
#define HELLO_H
void hello(const char *name);
#endif //HELLO_H
hello.c
#include <stdio.h>
void hello(const char *name)
{
printf("Hello %s!\n", name);
}
main.c
#include "hello.h"
int main()
{
hello("everyone");
return 0;
}
2. gcc编译得到.o文件
gcc -c hello.c

前面的报错表示hello.c有语法错误,读者自己编写时细心一点即可避免。
3. 创建静态库
静态库文件名的命名规范是以 lib 为前缀,紧接着跟静态库名,扩展名为.a。
ar -crv libmyhello.a hello.o

4.使用静态库
静态库制作完了,如何使用它内部的函数呢?只需要在使用到这些公用函数的源程序中包含这些公用函数的原型声明,然后在用 gcc 命令生成目标文件时指明静态库名,gcc 将会从静态库中将公用函数连接到目标文件中。注意,gcc 会在静态库名前加上前缀 lib,然后追加扩展名.a 得到的静态库文件名来查找静态库文件。
在程序 3:main.c 中,我们包含了静态库的头文件 hello.h,然后在主程序 main 中直接调用公用函数 hello。下面先生成目标程序 hello,然后运行 hello 程序看看结果如何。
方法一:
gcc -o hello main.c -L. –lmyhello
方法二:
gcc main.c libmyhello.a -o hello
方法三:
先生成 main.o:
gcc -c main.c
再生成可执行文件:
gcc -o hello main.o libmyhello.a
动态库连接时也可以这样做。
运行 hello 程序:
./hello

5. 验证静态库的特点
先删除静态库文件:
rm libmyhello.a
再试试公用函数 hello 是否真的连接到目标文件 hello 中了:
./hello

在删掉静态库的情况下,运行可执行文件,发现程序仍旧正常运行,表明静态库跟程序执行没有联系。同时,也表明静态库是在程序编译的时候被连接到代码中的。
6. 创建动态库文件
动态库文件名命名规范和静态库文件名命名规范类似,也是在动态库名增加前缀 lib,但其文件扩展名为.so。例如:我们将创建的动态库名为 myhello,则动态库文件名就是 libmyhello.so。用 gcc 来创建动态库。
gcc -shared -fPIC -o libmyhello.so hello.o #(-o 不可少)
shared:表示指定生成动态链接库,不可省略
-fPIC:表示编译为位置独立的代码,不可省略
命令中的-o一定不能够被省略

7. 使用动态库
gcc -o hello main.c -L. -lmyhello
或
gcc main.c libmyhello.so -o hello

直接使用可能会报错,原因是找不到动态库文件libmyhello.so。程序在运行时,会在/usr/lib 和/lib 等目录中查找需要的动态库文件。若找到,则载入动态库,否则将提示类似上述错误而终止程序运行。
我们将文件 libmyhello.so 复制到目录/usr/lib 中,再试
试:
sudo mv libmyhello.so /usr/lib

直接使用
mv libmyhello.so /usr/lib
可能会提示权限不够,加上sudo即可解决
8. 静态库与动态库比较
gcc编译得到.o文件 :
gcc -c hello.c
创建静态库 :
ar -crv libmyhello.a hello.o
创建动态库 :
gcc -shared -fPIC -o libmyhello.so hello.o
使用库生成可执行文件 :
gcc -o hello main.c -L. -lmyhello
执行可执行文件:
./hello

从程序 hello 运行的结果中很容易知道,当静态库和动态库同名时,gcc 命令将优先使用动态库,默认去连/usr/lib 和/lib 等目录中的动态库,将文件 libmyhello.so 复制到目录/usr/lib中即可。
四、静态库与动态库的使用实例
1. 实例1
1.1 创建示例文件
先创建一个作业目录,保存本次练习的文件:
mkdir test2
cd test2
然后用 vim、nano 或 gedit 等文本编辑器编辑生成所需要的四个文件 A1.c 、 A2.c、 A.h、test.c :
A1.c:
#include <stdio.h>
void print1(int arg){
printf("A1 print arg:%d\n",arg);
}
A2.c:
#include <stdio.h>
void print2(char *arg){
printf("A2 printf arg:%s\n", arg);
}
A.h:
#ifndef A_H
#define A_H
void print1(int);
void print2(char *);
#endif
test.c:
#include <stdlib.h>
#include "A.h"
int main(){
print1(1);
print2("test");
return 0;
}
1.2 静态库.a 文件的生成与使用
生成目标文件(xxx.o):
gcc -c A1.c A2.c
详细操作步骤:
这里的报错仍然是代码有语法错误,所以再次告诫读者编写时要认真一点哦!
生成静态库.a 文件:
ar crv libafile.a A1.o A2.o
1.3 共享库.so 文件的生成与使用
生成目标文件((xxx.o) 此处生成.o 文件必须添加"-fpic"(小模式,代码少),否则在生成.so文件时会出错):
gcc -c -fpic A1.c A2.c
生成共享库.so 文件:
gcc -shared *.o -o libsofile.so
使用.so 库文件,创建可执行程序:
gcc -o test test.c libsofile.so
运行test.c:
./test
这时就会报错,这是由于 linux 自身系统设定的相应的设置的原因,即其只在/lib and /usr/lib 下搜索对应的.so 文件,故需将对应 so 文件拷贝到对应路径:
sudo cp libsofile.so /usr/lib
再次执行./test,即可成功运行。
详细操作步骤:
2. 实例2
2.1 代码:
sub1.c
float x2x(int a,int b)
{
float result = a + b;
return result;
}
x2y.c
int x2y(int a, int b)
{
return a*b;
}
sub.h
#ifndef SUB_H
#define SUB_H
float x2x(int a,int b);
int x2y(int a,int b);
#endif
main1.c
#include<stdio.h>
#include"sub.h"
void main()
{
int a = 10,b = 20;
printf("Please input the value of a:");
scanf("%d",&a);
printf("Please input the value of b:");
scanf("%d",&b);
printf("a+b=%.2f\n",x2x(a,b));
printf("a/b=%.2f\n",x2y(a,b));
}
gcc -c sub1.c
gcc -c x2y.c
gcc -c main1.c

2.2 生成静态库并链接
ar crv libxyfile.a sub1.o x2y.o
gcc -o main1 main1.c libxyfile.a

2.3 生成动态库并链接
gcc -c -fpic sub1.c x2y.c
gcc -shared *.o -o libxysofile.so
gcc -o main1 main1.c libxysofile.so
sudo cp libxysofile.so /sur/lib

五、Linux 与 STM32 的内存分布对比
1. Linux (Ubuntu x86_64) — 演示程序、编译与运行
将下列程序保存为 mem_demo_linux.c:
// mem_demo_linux.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
/* 全局已初始化 */
int global_init = 0x11111111;
/* 全局未初始化 (BSS) */
int global_bss;
static int static_global_init = 0x22222222;
/* 一个普通函数(用来查看代码段地址)*/
void func_dummy(void) { }
int main(void) {
/* 局部变量 */
int local_var = 0x33333333;
static int static_local = 0x44444444;
/* 堆分配 */
void *p1 = malloc(64);
void *p2 = malloc(1024);
/* 当前程序 break (heap top) */
void *brk = sbrk(0);
/* 打印指针大小 */
printf("pointer size = %zu bytes\n\n", sizeof(void*));
printf("==== sections & objects ====\n");
printf("address of func_dummy (code/text) : %p\n", (void*)func_dummy);
printf("address of global_init (data) : %p\n", (void*)&global_init);
printf("address of static_global_init (data) : %p\n", (void*)&static_global_init);
printf("address of global_bss (bss) : %p\n", (void*)&global_bss);
printf("address of static_local (bss/data?) : %p\n", (void*)&static_local);
printf("address of local_var (stack) : %p\n", (void*)&local_var);
printf("address of p1 (heap) malloc 64 : %p\n", p1);
printf("address of p2 (heap) malloc 1024 : %p\n", p2);
printf("program break (sbrk(0)) : %p\n", brk);
/* 通过取局部变量地址观察栈方向 */
int another_local;
printf("address of another_local (stack) : %p\n", (void*)&another_local);
/* 观察环境地址(可选)*/
char *env = getenv("PATH");
printf("address of env PATH (in env area) : %p\n", (void*)env);
/* 防止立即退出(便于观察)*/
printf("\nPID=%d. Press Enter to exit...", getpid());
getchar();
free(p1);
free(p2);
return 0;
}
注意/提示
在现代 Linux 下,默认启用了 ASLR(地址随机化),每次运行会看到不同的虚拟地址。要做稳定对比可以临时关闭 ASLR(需要 root)或使用 setarch $(uname -m) -R ./mem_demo_linux 来在当前进程禁用随机化。
32-bit 与 64-bit 的典型布局不同(指针宽度、地址空间不同),上面示例在 x86_64 上运行。
分析要点(Linux):
func_dummy 在代码段/text(可执行映像);
global_init、static_global_init 与 global_bss 在数据段/ BSS 段(通常位于较低虚拟地址,比如 0x600000 区域,这与可执行文件加载地址及 ABI 有关);
malloc 返回的地址位于堆区(在 data 段后面的增长区域,sbrk(0) 可看到当前程序 break);
局部变量地址位于栈区(高地址,向低增长 —— 在 x86_64 Linux 上栈地址通常以 0x7fff… 开头,且栈向低地址增长,两个局部变量地址靠得很近且后一个地址小于前一个表示向低增长);
环境变量/argv/堆栈/共享库(libc)都会被映射在用户进程虚拟空间的不同区域;共享库 (.so) 映射地址通常在 0x7f…(高位)或随机位置。
2. STM32 (Cortex-M,示例以 STM32F103 / Keil/STM32CubeMX HAL 为例)
下图是一个Cortex-M4的存储器地址映射示意图(与Cortex-M3/stm32F10x基本相同,只存在微小差异)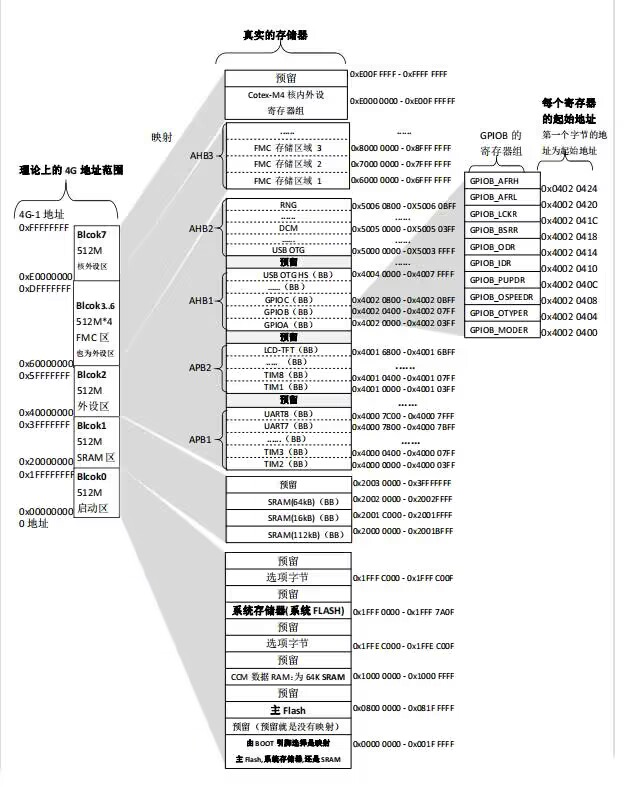
保存实例程序为 main.c(Keil/STM32Cube HAL 或 GCC 环境皆可):
/* main.c - STM32F1 示例(打印地址到 UART via printf) */
#include "stm32f1xx_hal.h"
#include <stdio.h>
#include <stdint.h>
/* 声明全局/静态变量 */
int g_init = 0x1111;
int g_bss; /* BSS */
static int g_static = 0x2222;
static int g_static_bss; /* 未初始化 static */
/* 局部 static */
void dummy_func(void) { }
/* 声明从链接脚本导出的符号(常见符号名,按你的链接脚本确认) */
extern uint32_t _estack; /* 堆栈初始值(由链接脚本提供) */
extern uint32_t _sdata; /* 数据段起始(flash->ram拷贝目标) */
extern uint32_t _edata; /* 数据段结束 */
extern uint32_t _sbss; /* bss 起始 */
extern uint32_t _ebss; /* bss 结束 */
extern uint32_t _etext; /* 文本段结束,data 源(flash)结束 */
/* UART handle (根据你的配置) */
UART_HandleTypeDef huart1;
/* 简单的 retarget printf 到 HAL UART */
int _write(int file, char *ptr, int len) {
HAL_UART_Transmit(&huart1, (uint8_t*)ptr, len, HAL_MAX_DELAY);
return len;
}
/* 初始化 UART1 (按你的板子修改波特率/引脚) */
void MX_USART1_UART_Init(void) {
huart1.Instance = USART1;
huart1.Init.BaudRate = 115200;
huart1.Init.WordLength = UART_WORDLENGTH_8B;
huart1.Init.StopBits = UART_STOPBITS_1;
huart1.Init.Parity = UART_PARITY_NONE;
huart1.Init.Mode = UART_MODE_TX_RX;
huart1.Init.HwFlowCtl = UART_HWCONTROL_NONE;
huart1.Init.OverSampling = UART_OVERSAMPLING_16;
HAL_UART_Init(&huart1);
}
int main(void) {
HAL_Init();
SystemClock_Config(); /* 由 CubeMX 生成,或自己实现 */
MX_USART1_UART_Init();
printf("STM32 memory demo start\r\n");
/* 本地/静态/全局/堆/栈 */
int local = 0x3333;
static int static_local = 0x4444;
void *p = malloc(128);
void *p2 = malloc(1024);
/* 获取主栈指针(CMSIS 提供)*/
uint32_t msp = __get_MSP(); /* 需要包含 cmsis core header */
printf("=== symbols from linker ===\r\n");
printf("_estack : %p\r\n", (void*)&_estack);
printf("_etext : %p\r\n", (void*)&_etext);
printf("_sdata : %p\r\n", (void*)&_sdata);
printf("_edata : %p\r\n", (void*)&_edata);
printf("_sbss : %p\r\n", (void*)&_sbss);
printf("_ebss : %p\r\n", (void*)&_ebss);
printf("\r\n=== variables & memory ===\r\n");
printf("func dummy (text) : %p\r\n", (void*)dummy_func);
printf("g_init (data) : %p\r\n", (void*)&g_init);
printf("g_static (data) : %p\r\n", (void*)&g_static);
printf("g_bss (bss) : %p\r\n", (void*)&g_bss);
printf("static_local (bss/data) : %p\r\n", (void*)&static_local);
printf("local (stack) : %p\r\n", (void*)&local);
printf("malloc p (heap) : %p\r\n", p);
printf("malloc p2 (heap) : %p\r\n", p2);
printf("MSP (stack pointer) : 0x%08lX\r\n", (unsigned long)msp);
while (1) {
HAL_Delay(1000);
printf("."); fflush(stdout);
}
}
Keil/GCC/链接符号说明
链接脚本(或 Keil 的 scatter 文件/ Linker script)通常会定义 _estack、_sdata、_edata、_sbss、_ebss、_etext 等符号。如果你使用的是 MDK-ARM (ARMCC) 或 Keil 默认模板,符号名可能略有差异(如 __initial_sp 等),请以你工程的链接脚本/MDK scatterfile 为准并在代码中 extern 对应符号名。
__get_MSP() 属于 CMSIS(core_cm3.h / core_cm4.h),确保项目包含 CMSIS core 头文件或直接用 __asm volatile(“MRS %0, MSP”:“=r”(msp)); 读取 MSP。
STM32 典型内存地址(以 STM32F103C8T6 为例)
Flash: 0x0800 0000 起(128 KiB → 0x0801FFFF)
SRAM: 0x2000 0000 起(20 KiB → 0x20004FFF)
外设/寄存器: 0x4000 0000 起
向量表默认在 0x0800 0000(也可以重定位到 0x2000 0000)
因此你会看到:
func_dummy 地址在 0x0800xxxx(text)
数据段(已初始化数据)在 0x2000xxxx
BSS 变量也在 0x2000xxxx
堆 / malloc 分配通常也在 0x2000xxxx(SRAM 内)
MSP(栈指针)也会在 0x2000xxxx 的高地址(接近 SRAM 上端)
串口助手接收
在上位机使用串口工具(115200 8N1)接收 Keil 运行时 printf 输出,观察地址。
3. 对比分析(Ubuntu vs STM32)
3.1 地址空间 & 虚拟/物理差别
Linux 用户进程:虚拟地址空间,由操作系统管理(每个进程独立、并受 ASLR 影响)。地址值会是 64 位(在 x86_64),显示出 text、data、heap、stack、mmap(共享库)等映射区,且地址分布依赖于 ELF 加载基址与内核的随机化策略。
STM32(裸机/RTOS):没有 MMU,使用物理地址(线性地址),地址是固定的硬件映射(Flash、SRAM、外设固定地址),无 ASLR。变量地址直接映射到实际内存硬件(例如 0x20000000 起)。
3.2 堆与栈的增长方向
两者通常都采用:堆向高地址增长(sbrk / malloc 管理),栈向低地址增长(从高地址向低压缩)。在 Linux 可以利用指针打印连续两次局部变量或比较局部变量与函数调用层级验证栈增长方向;在 STM32 同理,MSP 的值会比局部变量地址大(或小,取决于栈初始化),但通常栈在 SRAM 的高端,向低增长。
3.3 全局/静态变量位置
Linux:在可执行文件加载的 data / bss 区(虚拟地址通常集中在某个中段,例如 ELF 的 0x600000 区域,取决于链接器与 PIE/ASLR)。
STM32:在 SRAM 的固定地址区(由链接脚本决定),例如 0x20000xxx。
3.4 代码段(text)
Linux:映射到进程虚拟地址空间,可能在低中高地址(取决于 ELF)。
STM32:位于 0x0800 0000(Flash),固定且可见于十六进制查看器 / map 文件。
3.5 验证方法 & 建议
在 Linux 上:为了可重复结果,临时关闭 ASLR:sudo sh -c ‘echo 0 > /proc/sys/kernel/randomize_va_space’(运行后记得恢复为 2)。或者使用 setarch -R 来禁用随机化只对当前进程有效:setarch $(uname -m) -R ./mem_demo_linux。
在 STM32:看 map 文件(链接后生成 .map),可精确看到每个符号在 Flash/SRAM 的地址;使用串口打印 &symbol 与 _sdata/_edata/_sbss/_ebss,并对照 map 文件。
六、总结
通过本次实验,我们在 Ubuntu 平台与 STM32 平台 上分别完成了 C 程序的编译、运行与内存结构分析,获得了以下主要认识与结论:
一、存储分区的共性与差异
- 两个平台的 C 程序都遵循 代码段(text)、已初始化数据段(data)、未初始化数据段(bss)、堆(heap)、栈(stack) 的通用分区规则;
- 但 Linux 程序运行于 虚拟地址空间(受 ASLR 影响),而 STM32 直接使用 物理地址映射,地址固定且与硬件结构直接对应。
二、堆与栈的行为特征
- 在两种平台中,堆区从低地址向高地址增长,栈区从高地址向低地址增长;
- Linux 使用
malloc由操作系统动态分配堆内存,STM32 则由运行库(newlib或microlib)通过_sbrk()简单管理 SRAM。
三、链接与加载机制的差异
- GCC 在 Linux 下生成的 ELF 文件包含详细的节区信息与符号表,由 操作系统加载器 负责重定位;
- STM32 的 链接脚本(linker script) 直接决定各段的物理地址,数据段从 Flash 拷贝至 SRAM,BSS 区清零后开始执行。
四、Cortex-M 架构内存映射理解
- Flash (
0x0800_0000)、SRAM (0x2000_0000)、外设 (0x4000_0000)、系统控制区 (0xE000_0000) 的分布遵循 ARM 官方规范; - 通过对比地址输出与
.map文件验证,我们能清楚地看到变量存储区与硬件物理空间的一一对应关系。
五、理论与实践的融合
- 实验不仅验证了 C 语言变量的生命周期与存储类别,还深化了对 编译器、链接器、装载器、内存管理机制 的理解;
- 在嵌入式开发中,掌握这些底层细节能显著提高调试与优化能力,避免常见的内存溢出、堆栈冲突等问题。
七、参考资料

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)