
毕业设计 将博客文章数据从mysql放到mongodb里面 设想 (完)
文章摘要: 本文探讨了MySQL与MongoDB混合使用的解决方案。针对MySQL强关联性问题,提出了嵌入式文档、引用式及混合方案三种处理方式。通过工厂模式实现DAO层动态切换,配置驱动选择MySQL或MongoDB服务。采用继承方式实现无侵入式修改,保持原有Service逻辑。详细介绍了MongoDB查询(Criteria/Query类)和更新(Update类)的实现方法,包括条件构建、分页处理
目录
思考 2 如何实现 dao 层 mysql 和 mongodb 的动态切换
思考 3 如何设计实现对原来的 service 无侵入式修改
事前准备
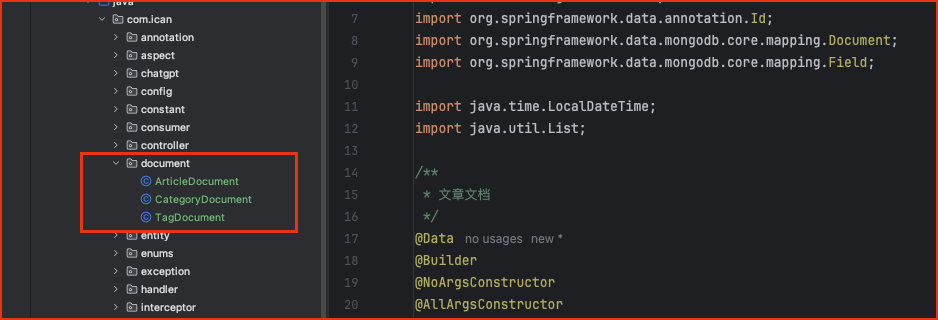
- 实体类单独封装
封装的是涉及到的三张表
- 二次封装 MongdbTemple
这仅仅是个人的习惯单纯不喜欢直接在 service 里面调用MongdbTemple
思考 1 如何解决 mysql 强关联性问题
MongDB 数据是弱关联的
没有外键这个概念
MongoDB 这种 NoSQL 数据库在处理多表关联(article、category、tag)时没有 MySQL 那么方便。
我明白你的意思,你是担心 MongoDB 这种 NoSQL 数据库在处理多表关联(article、category、tag)时没有 MySQL 那么方便。
其实 MongoDB 处理关联数据有两种主要思路,你可以根据查询需求来选择:
1. 嵌入式文档(最终采用)
适合场景:
分类(Category)数据量不大,每个分类信息基本不变
文章详情页经常需要显示分类名
标签(Tag)数量不多,且常用
实现方式:
@Document(collection = "articles")
public class Article {
@Id
private String id;
private String title;
private String content;
@Field("category")
private Category category; // 直接内嵌分类对象
@Field("tags")
private List<Tag> tags; // 内嵌标签对象列表
// ...其他字段
}优点:
一次查询就能获取文章+分类+标签,无需多次查询 œ
读性能高,减少 join
无需维护外键关系
缺点:
如果分类或标签信息更新,需要更新所有引用它们的文章
标签或分类数据量大时,会造成文章文档过大
2. 引用式(类似外键,适合“多”的一方数据量大)
适合场景:
标签数量非常多,且经常被复用
分类信息经常变更
需要独立管理标签和分类
实现方式:
@Document(collection = "articles")
public class Article {
@Id
private String id;
private String title;
private String content;
@Field("category_id")
private ObjectId categoryId; // 只存分类ID
@Field("tag_ids")
private List<ObjectId> tagIds; // 存标签ID列表
// ...其他字段
}优点:
数据冗余少
分类/标签更新只需改一处
适合大数据量的关联
缺点:
查询文章详情时需要多次查询(或用 MongoDB 的 $lookup 聚合)
代码中需要手动处理关联数据组装
3. 混合方案(推荐)
结合两种方式的优点:
文章中内嵌分类信息(因为分类变动少,且查询频繁)
文章中引用标签ID(因为标签可能频繁变更,且复用率高)
@Document(collection = "articles")
public class Article {
@Id
private String id;
private String title;
@Field("category")
private Category category; // 内嵌分类
@Field("tag_ids")
private List<ObjectId> tagIds; // 引用标签
// ...
}4. 实际操作示例
假设用引用式存储标签:
// 保存文章时
public void addArticle(ArticleReq article) {
// 保存分类(单独集合)
ObjectId categoryId = saveCategory(article.getCategoryName());
// 保存标签(单独集合)
List<ObjectId> tagIds = saveTags(article.getTagNameList());
// 保存文章
Article newArticle = new Article();
newArticle.setTitle(article.getTitle());
newArticle.setContent(article.getContent());
newArticle.setCategoryId(categoryId);
newArticle.setTagIds(tagIds);
articleRepository.save(newArticle);
}
// 查询文章详情时组装标签
public ArticleResp getArticleById(String id) {
Article article = articleRepository.findById(id).orElse(null);
if (article == null) return null;
ArticleResp resp = BeanCopyUtils.copyBean(article, ArticleResp.class);
// 查询分类
Category category = categoryRepository.findById(article.getCategoryId()).orElse(null);
resp.setCategoryName(category.getCategoryName());
// 查询标签
List<Tag> tags = tagRepository.findAllById(article.getTagIds());
resp.setTags(tags.stream().map(Tag::getTagName).collect(Collectors.toList()));
return resp;
}5. MongoDB 聚合查询(替代 SQL Join)
如果用引用式存储,可以用聚合管道一次性查询:
Aggregation agg = Aggregation.newAggregation(
Aggregation.match(Criteria.where("_id").is(new ObjectId(articleId))),
Aggregation.lookup("categories", "category_id", "_id", "category"),
Aggregation.unwind("category"),
Aggregation.lookup("tags", "tag_ids", "_id", "tags")
);
AggregationResults<ArticleDetailDTO> results = mongoTemplate.aggregate(
agg, "articles", ArticleDetailDTO.class);
ArticleDetailDTO article = results.getUniqueMappedResult();思考 2 如何实现 dao 层 mysql 和 mongodb 的动态切换
这个问题的关键在于我们要尽可能减少 原来 service 层代码的书写
我们可以在添加博客文章的时候在 mongodb 里面也存一份
可以先将代码改造成双写,再逐步迁移到 MongDB
开关在配置文件里面
我们采用的是工厂方法的设计模式
通过加载配置来引导 controller 加载不同的 service
具体代码逻辑
我们将配置写在 application.yml 配置文件里面
# 数据源, 可选值: mysql, mongodb
datatype:
# type: mysql
type: mongodb
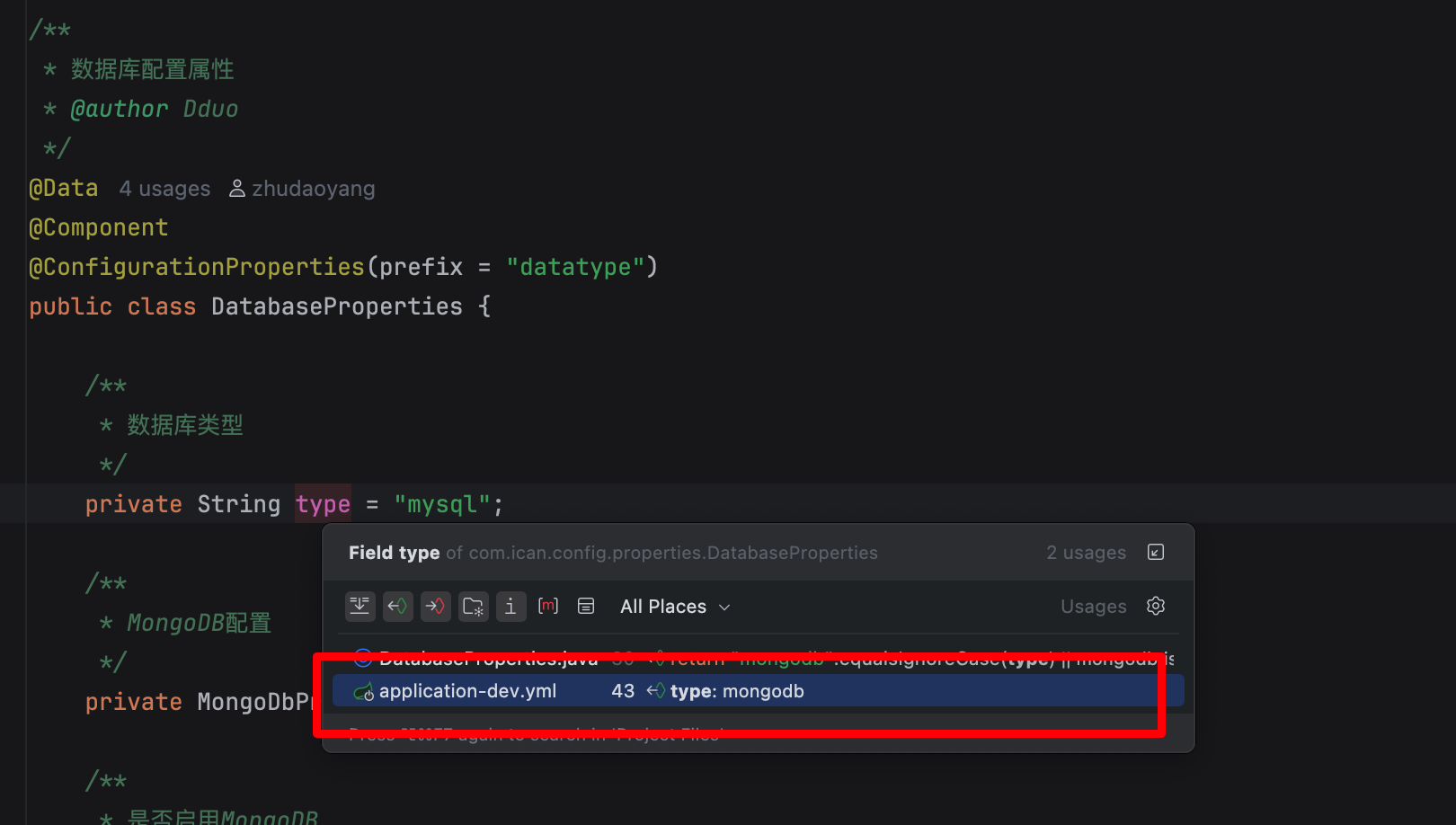
DatabaseProperties 类 用于加载挂载 yml 文件里的配置
@ ConfigurationProperties 注解
package com.ican.config.properties;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
/**
* 数据库配置属性
* @author Dduo
*/
@Data
@Component
@ConfigurationProperties(prefix = "datatype")
public class DatabaseProperties {
/**
* 数据库类型
*/
private String type = "mysql";
/**
* MongoDB配置
*/
private MongoDbProperties mongodb = new MongoDbProperties();
/**
* 是否启用MongoDB
*/
public boolean isMongoDbEnabled() {
return "mongodb".equalsIgnoreCase(type) || mongodb.isEnabled();
}
@Data
public static class MongoDbProperties {
/**
* 是否启用MongoDB
*/
private boolean enabled = false;
/**
* MongoDB集合前缀
*/
private String collectionPrefix = "blog_";
/**
* 是否启用自动同步
*/
private boolean autoSync = true;
/**
* 同步批次大小
*/
private int syncBatchSize = 100;
}
}绑定的是具体配置内的内容
简单工厂模式
DatabaseServiceFactory 类
从 DatabaseProperties 加载配置,来决定注入的是哪个 servcie 类
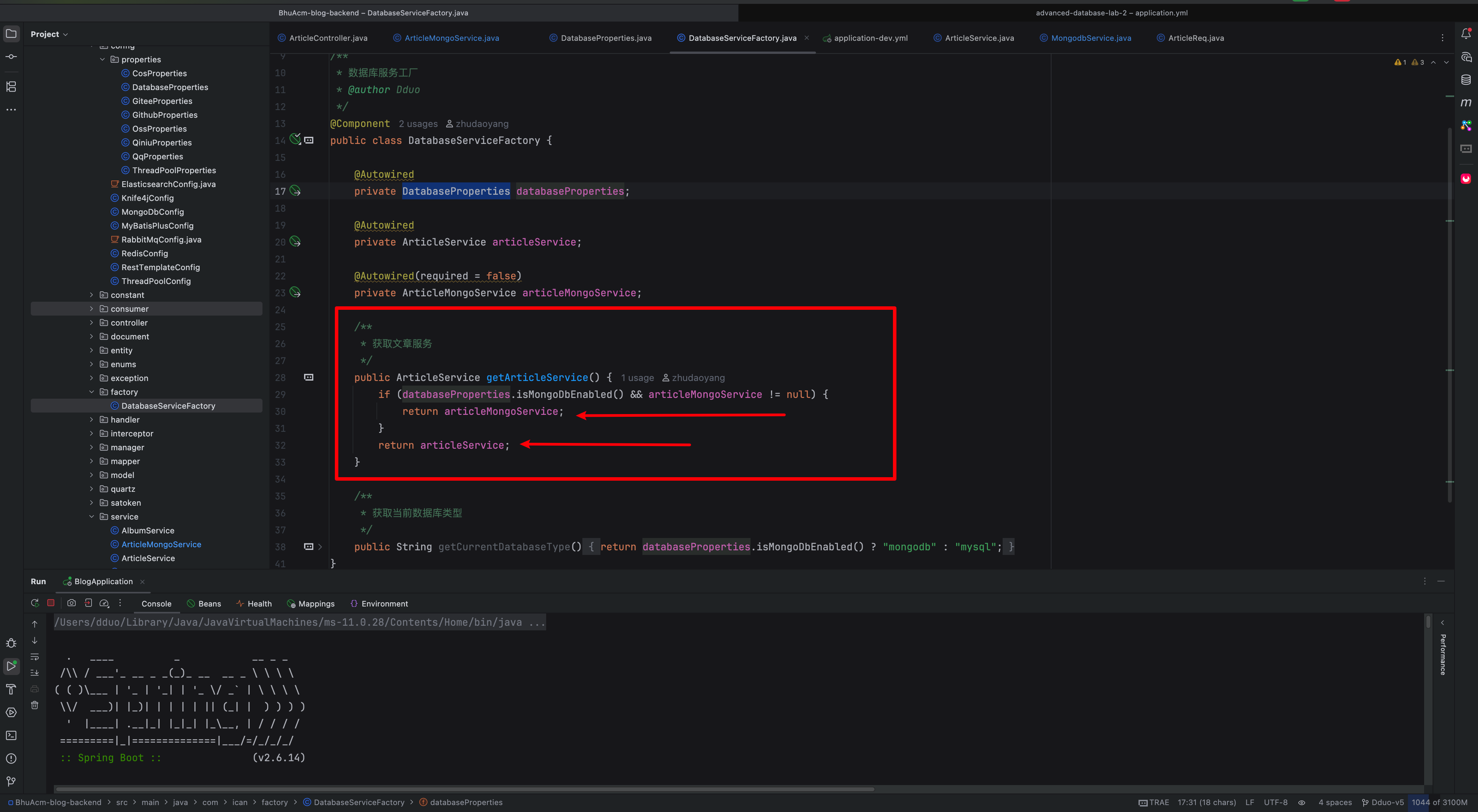
package com.ican.factory;
import com.ican.config.properties.DatabaseProperties;
import com.ican.service.ArticleMongoService;
import com.ican.service.ArticleService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* 数据库服务工厂
* @author Dduo
*/
@Component
public class DatabaseServiceFactory {
@Autowired
private DatabaseProperties databaseProperties;
@Autowired
private ArticleService articleService;
@Autowired(required = false)
private ArticleMongoService articleMongoService;
/**
* 获取文章服务
*/
public ArticleService getArticleService() {
if (databaseProperties.isMongoDbEnabled() && articleMongoService != null) {
return articleMongoService;
}
return articleService;
}
/**
* 获取当前数据库类型
*/
public String getCurrentDatabaseType() {
return databaseProperties.isMongoDbEnabled() ? "mongodb" : "mysql";
}
}思考 3 如何设计实现对原来的 service 无侵入式修改
在启动 nosql 后,我们无非是用于进行数据双写
先写入 mysql 再写入 mongodb
原来我们在 controller 调用的是 ArticleService 类
我们现在创建他的子类
这样可以无侵入式 进行代码修改
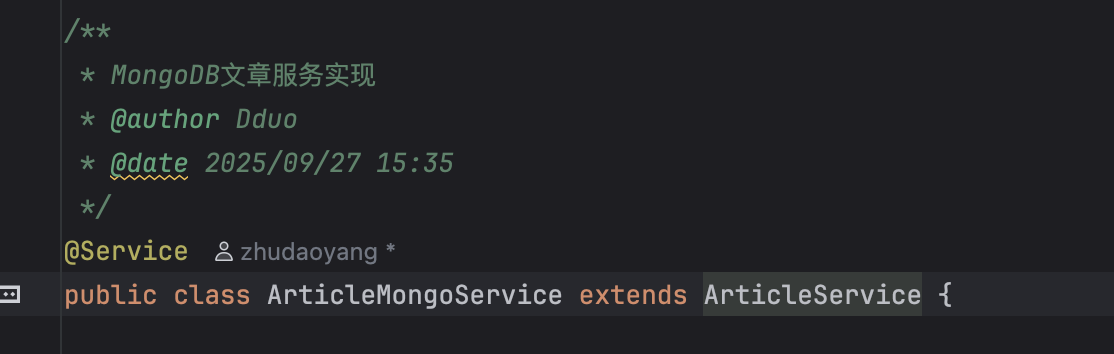
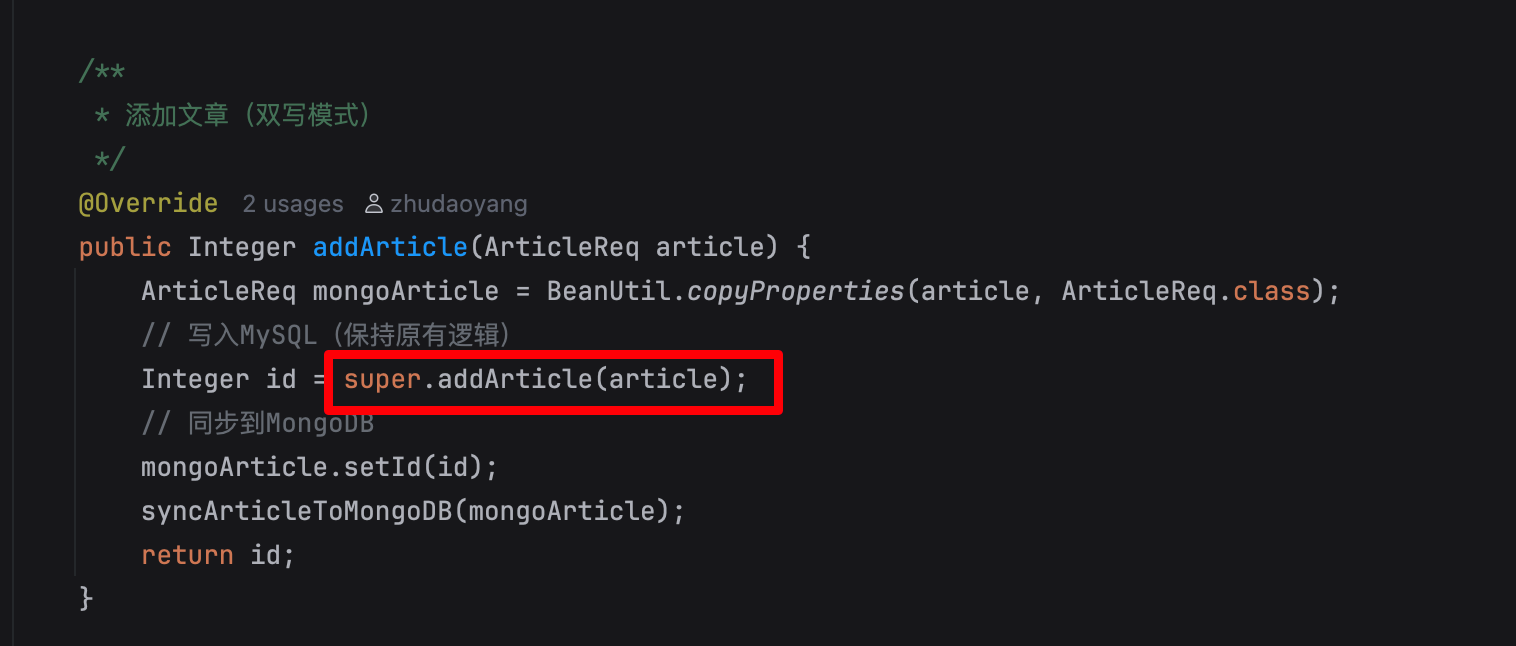
比如说这个 添加博客
我们子类的这个方法是继承父类而来
所以我先调用 super 里面的方法
然后在进行自己的逻辑
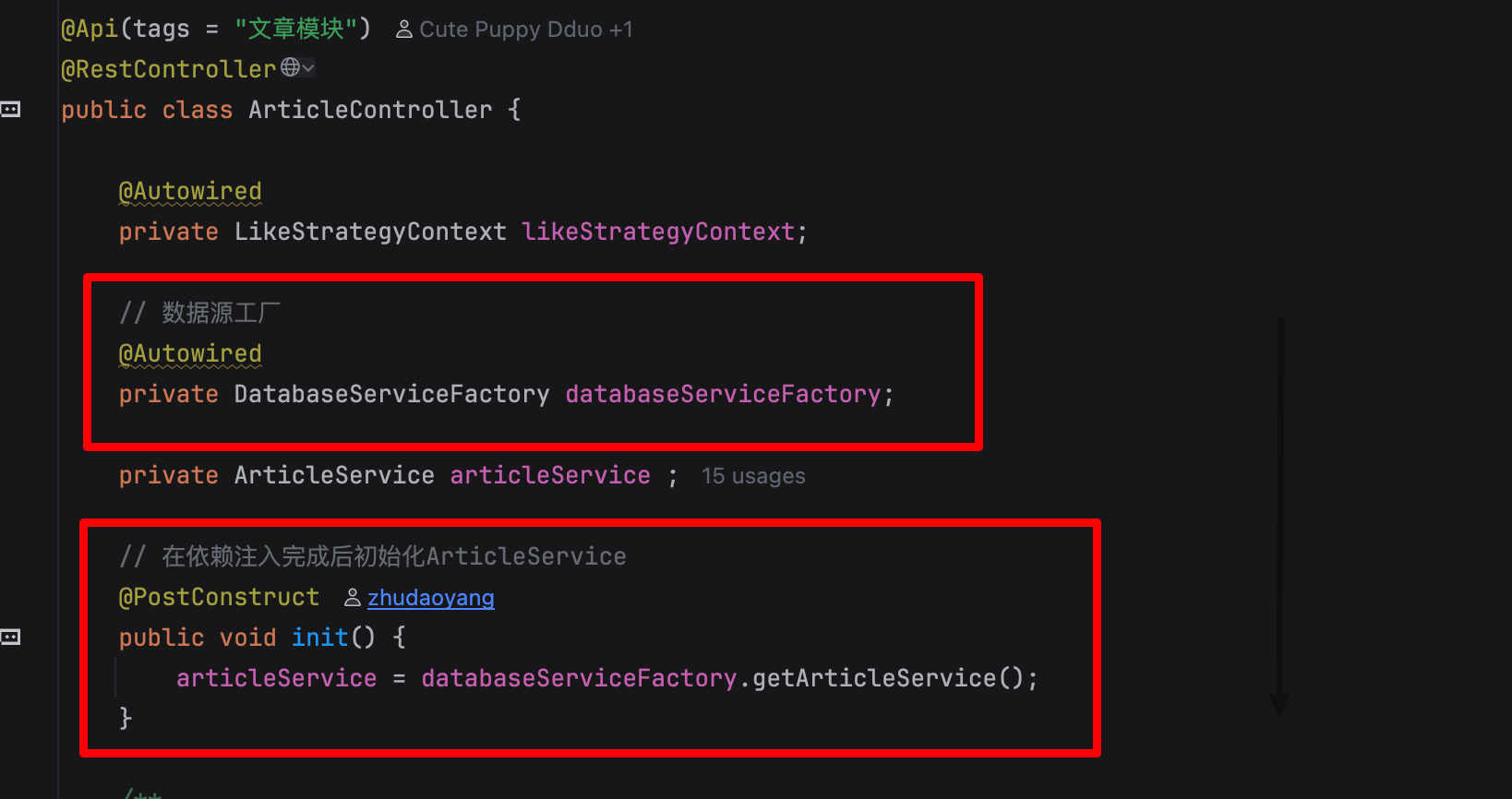
在 controller 里面
我们使用数据源工厂 (DatabaseServiceFactory) 在 依赖注入完成后初始化 ArticleService
思考 4 如何高效实现条件查询和数据更新
这个是全新的知识点
查询我们 使用的是一个 Criteria 类 和 Query 类
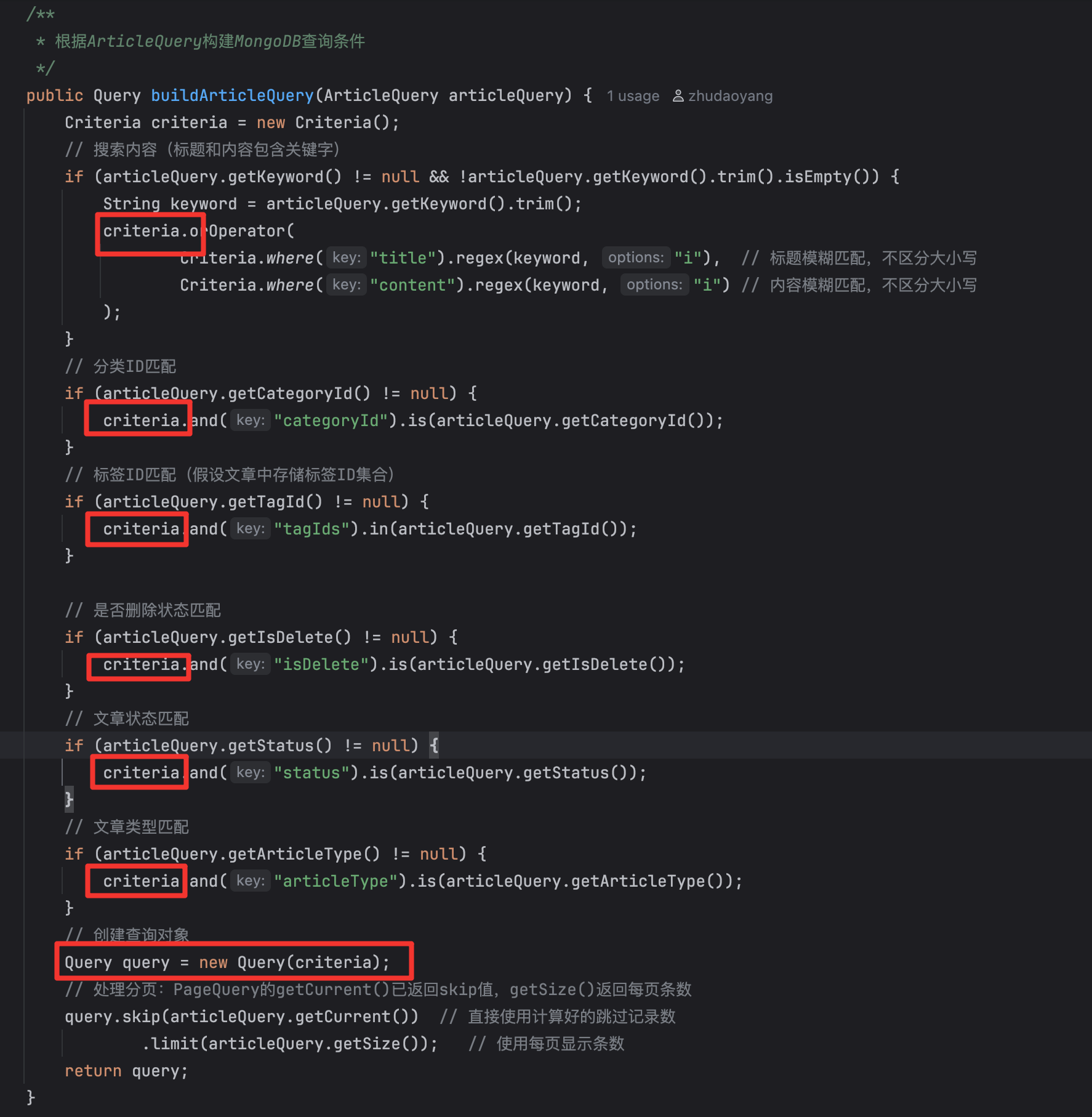
/**
* 根据ArticleQuery构建MongoDB查询条件
*/
public Query buildArticleQuery(ArticleQuery articleQuery) {
Criteria criteria = new Criteria();
// 搜索内容(标题和内容包含关键字)
if (articleQuery.getKeyword() != null && !articleQuery.getKeyword().trim().isEmpty()) {
String keyword = articleQuery.getKeyword().trim();
criteria.orOperator(
Criteria.where("title").regex(keyword, "i"), // 标题模糊匹配,不区分大小写
Criteria.where("content").regex(keyword, "i") // 内容模糊匹配,不区分大小写
);
}
// 分类ID匹配
if (articleQuery.getCategoryId() != null) {
criteria.and("categoryId").is(articleQuery.getCategoryId());
}
// 标签ID匹配(假设文章中存储标签ID集合)
if (articleQuery.getTagId() != null) {
criteria.and("tagIds").in(articleQuery.getTagId());
}
// 是否删除状态匹配
if (articleQuery.getIsDelete() != null) {
criteria.and("isDelete").is(articleQuery.getIsDelete());
}
// 文章状态匹配
if (articleQuery.getStatus() != null) {
criteria.and("status").is(articleQuery.getStatus());
}
// 文章类型匹配
if (articleQuery.getArticleType() != null) {
criteria.and("articleType").is(articleQuery.getArticleType());
}
// 创建查询对象
Query query = new Query(criteria);
// 处理分页:PageQuery的getCurrent()已返回skip值,getSize()返回每页条数
query.skip(articleQuery.getCurrent()) // 直接使用计算好的跳过记录数
.limit(articleQuery.getSize()); // 使用每页显示条数
return query;
}数据更新是一个 Updata 类
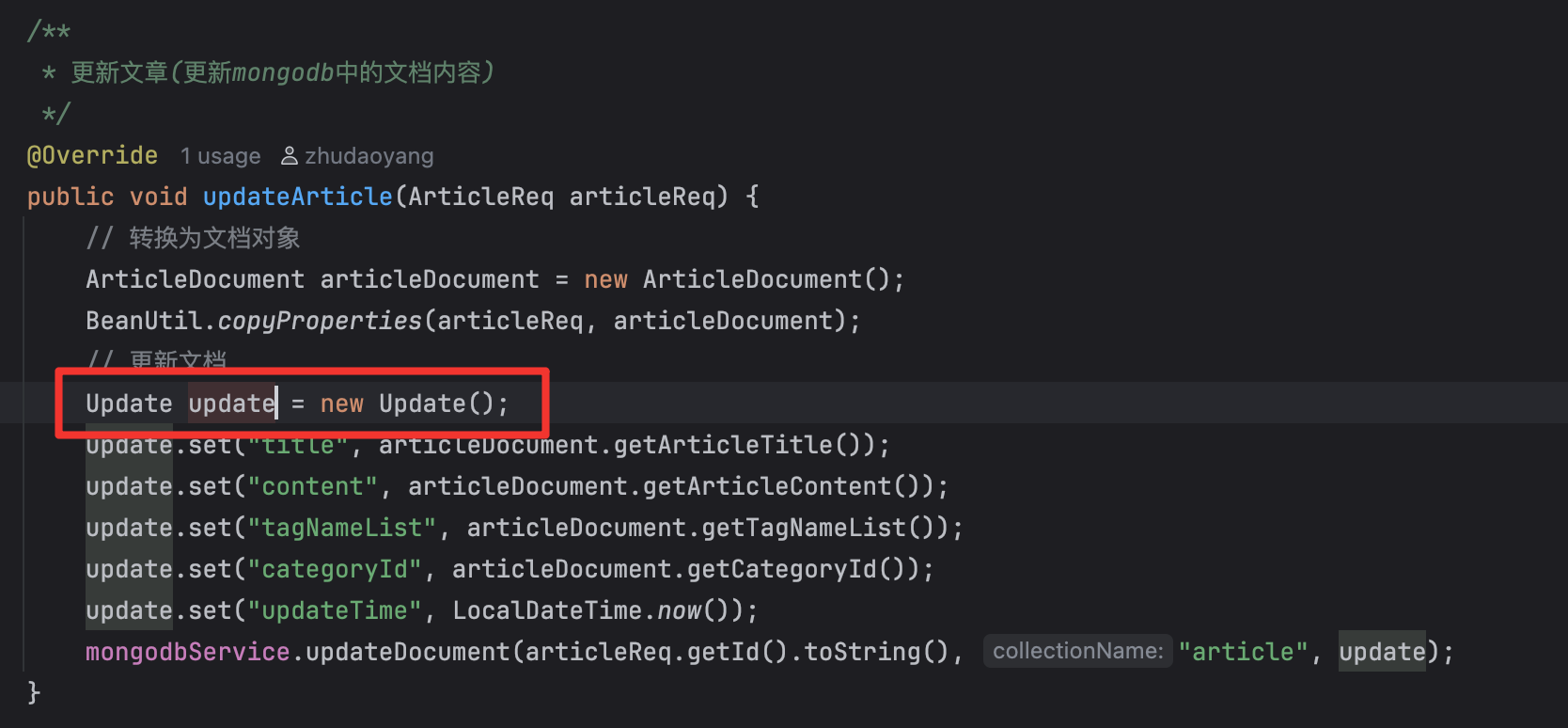
/**
* 更新文章(更新mongodb中的文档内容)
*/
@Override
public void updateArticle(ArticleReq articleReq) {
// 转换为文档对象
ArticleDocument articleDocument = new ArticleDocument();
BeanUtil.copyProperties(articleReq, articleDocument);
// 更新文档
Update update = new Update();
update.set("title", articleDocument.getArticleTitle());
update.set("content", articleDocument.getArticleContent());
update.set("tagNameList", articleDocument.getTagNameList());
update.set("categoryId", articleDocument.getCategoryId());
update.set("updateTime", LocalDateTime.now());
mongodbService.updateDocument(articleReq.getId().toString(), "article", update);
}参考文档
在 Java 操作 MongoDB 的过程中,Criteria、Query 和 Update 是三个核心类,分别用于构建查询条件、组装查询操作和定义数据更新操作。下面分别介绍它们的作用和使用方式:
1. Criteria 类:构建查询条件
Criteria 类用于定义具体的查询条件(如等于、大于、模糊匹配等),是构建查询的基础。它提供了一系列静态方法和实例方法来生成各种条件。
常用方法示例:
- 等于:
Criteria.where("字段名").is(值) - 不等于:
Criteria.where("字段名").ne(值) - 大于/小于:
gt(值)/lt(值) - 模糊匹配:
regex(正则表达式) - 包含:
in(数组) - 逻辑组合:
and()、or()
示例:
// 查询 age 大于 18 且 status 为 "active" 的文档
Criteria criteria = Criteria.where("age").gt(18)
.and("status").is("active");2. Query 类:组装查询操作
Query 类用于封装查询条件(通过 Criteria),并可以设置查询的附加参数(如分页、排序、字段过滤等)。它是执行查询的载体。
常用方法:
- 绑定条件:
Query.query(Criteria criteria) - 分页:
skip(跳过条数).limit(查询条数) - 排序:
with(Sort sort) - 字段过滤:
fields().include("字段").exclude("字段")
示例:
// 基于上面的 criteria 构建查询,并设置分页和排序
Query query = Query.query(criteria)
.skip(0) // 跳过 0 条
.limit(10) // 最多返回 10 条
.with(Sort.by(Sort.Direction.DESC, "age")); // 按 age 降序执行查询时,将 Query 对象传入 MongoDB 模板的方法(如 find()):
List<User> users = mongoTemplate.find(query, User.class, "collectionName");3. Update 类:定义数据更新操作
Update 类用于描述对文档的更新动作(如修改字段值、新增字段、删除字段等)。
常用方法:
- 设置字段值:
set("字段名", 值) - 递增/递减:
inc("字段名", 数值) - 移除字段:
unset("字段名") - 数组操作:
push("数组字段", 元素)(添加元素)、pull("数组字段", 条件)(删除元素)
示例:
// 将 status 改为 "inactive",并将 loginCount 递增 1
Update update = new Update()
.set("status", "inactive")
.inc("loginCount", 1);执行更新时,结合查询条件和更新操作:
// 更新满足 query 条件的文档
UpdateResult result = mongoTemplate.updateMulti(query, update, "collectionName");三者关系总结
Criteria负责定义查询条件(如“age > 18”);Query负责封装查询条件和附加参数(如分页、排序),作为查询的“载体”;Update负责定义更新动作(如“set status = 'inactive'”);- 实际操作时,通过 MongoDB 模板(
MongoTemplate)将Query和Update结合,执行查询或更新操作。
这种设计让查询和更新的逻辑更清晰,便于构建复杂的数据库操作。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)