
RAG进阶:Embedding Models嵌入式模型原理和示例
一、概念与核心原理
1. 嵌入模型的本质
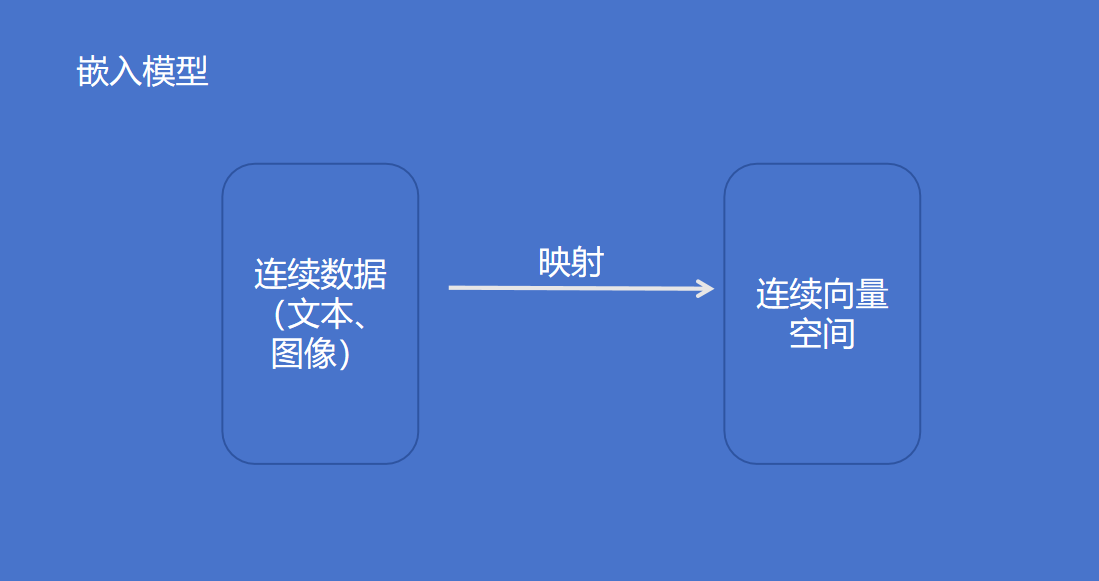
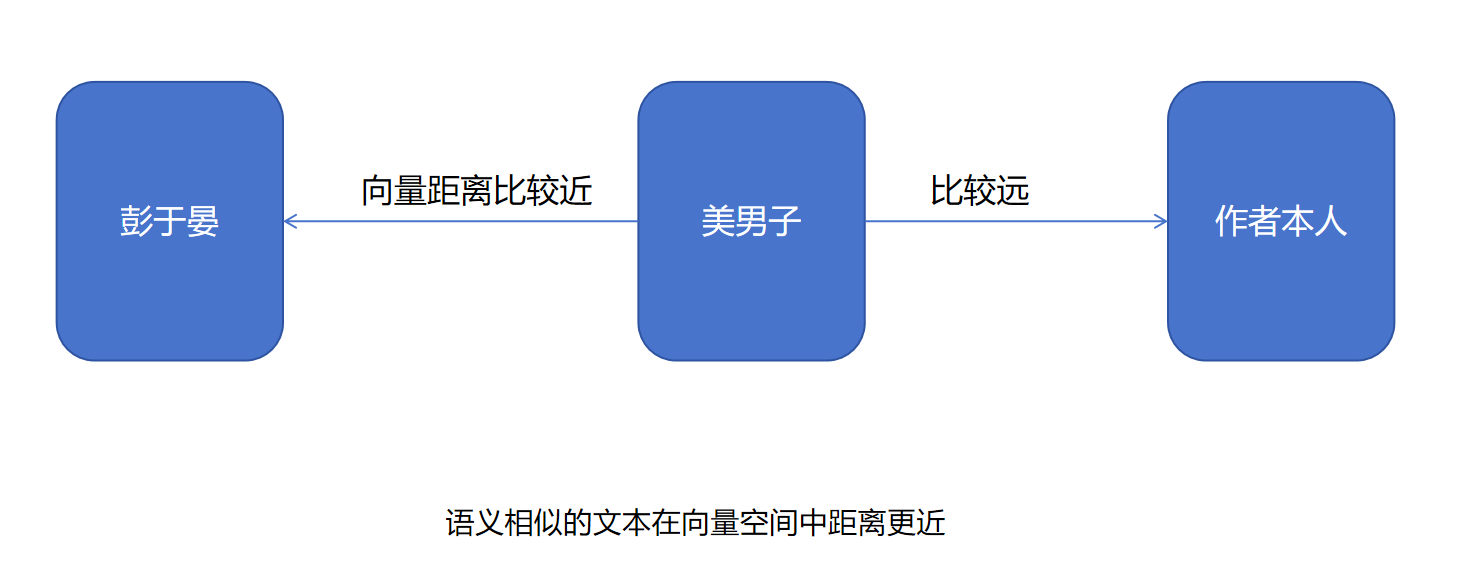
向量(嵌入)模型(Embedding Model)是一种将离散数据(如文本、图像)映射到连续向量空间的技术。通过高维向量表示(如 768 维或 3072 维),模型可捕捉数据的语义信息,使得语义相似的文本在向量空间中距离更近。例如,“忘记密码”和“账号锁定”会被编码为相近的向量,从而支持语义检索而非仅关键词匹配。
2. 核心作用
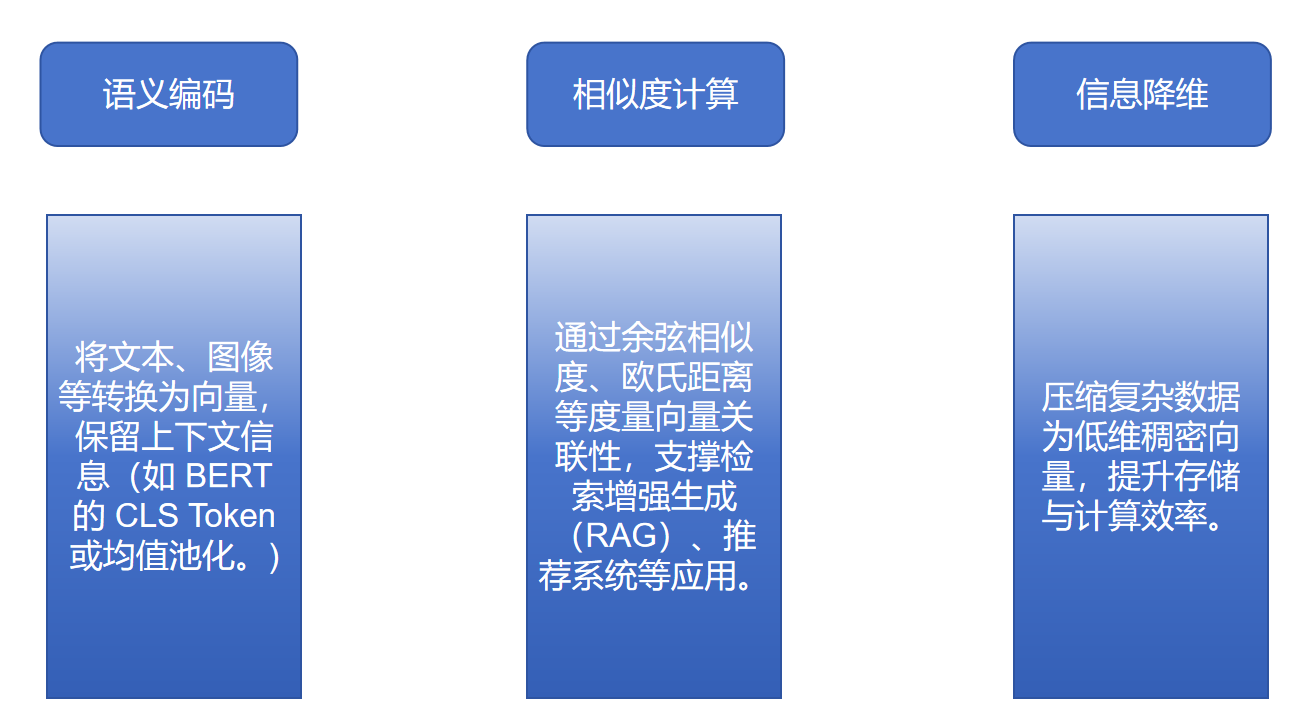
语义编码:将文本、图像等转换为向量,保留上下文信息(如 BERT 的 CLS Token 或均值池化。)
相似度计算:通过余弦相似度、欧氏距离等度量向量关联性,支撑检索增强生成(RAG)、推荐系统等应用。
信息降维:压缩复杂数据为低维稠密向量,提升存储与计算效率。
3. 关键技术原理
上下文依赖:现代模型(如 BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义。
训练方法:对比学习(如 Word2Vec 的 Skip-gram/CBOW)、预训练+微调(如 BERT)。
二、选型指南
Embedding模型将文本转换为数值向量,捕捉语义信息,使计算机能够理解和比较内容的"意义"。 选择Embedding模型的考虑因素:
|
因素 |
说明 |
|
任务性质 |
匹配任务需求(问答、搜索、聚类等) |
|
领域特性 |
通用vs专业领域(医学、法律等) |
|
多语言支持 |
需处理多语言内容时考虑 |
|
维度 |
权衡信息丰富度与计算成本 |
|
许可条款 |
开源vs专有服务 |
|
最大tokens |
适合的上下文窗口大小 |
最佳实践:为特定应用测试多个embedding模型,评估在实际数据上的性能而非仅依赖通用基准。
三、示例代码
知识库:
documents=[ "联合国安理会上,俄罗斯与美国,伊朗与以色列“吵”起来了", "土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判", "日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤", "孙志刚被判死缓 减为无期徒刑后终身监禁 不得减刑、假释", "以色列立法禁联合国机构,美表态担忧,中东局势再生波澜", ]
query = "国际争端"
需求:求query与知识库中的每个内容的相似度。
代码实现如下:
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
import os
key = os.getenv("qwq_key")
base_url=os.getenv("qwq_base_url")
client = OpenAI(api_key=key, base_url=base_url) #调用向量化模型的对象
"""
NumPy是Python中用于科学计算的核心库。
NumPy提供了高性能的多维数组对象(称为ndarray)和用于处理这些数组的各种函数,
广泛应用于数组和矩阵的运算、线性代数、傅里叶变换、随机数生成等领域
"""
import numpy as np
"""
dot函数用于计算两个向量的点积,
它是一种数学运算,用于计算两个向量的数量积
"""
from numpy import dot
"""
norm函数用于计算向量的范数(长度)
"""
from numpy.linalg import norm
"""
计算两个向量的余弦相似度
@param vec1: 向量1
@param vec2: 向量2
"""
def cosine_similarity(vec1, vec2):
return dot(vec1, vec2) / (norm(vec1) * norm(vec2))
"""
计算两个向量的欧氏距离
@param vec1: 向量1
@param vec2: 向量2
"""
def osd_similarity(vec1, vec2):
x = np.asarray(vec1) - np.asarray(vec2)
return norm(x)
"""
对内容进行向量化。
"""
def get_embeddings(texts, model="text-embedding-v3"):
# texts 是一个包含要获取嵌入表示的文本的列表,
# model 则是用来指定要使用的模型的名称
# 生成文本的嵌入表示。结果存储在data中。
completion = client.embeddings.create(input=texts, model=model)
# 返回了一个包含所有嵌入表示的列表
return [x.embedding for x in completion.data]
"""
知识库
"""
documents=[
"联合国安理会上,俄罗斯与美国,伊朗与以色列“吵”起来了",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"孙志刚被判死缓 减为无期徒刑后终身监禁 不得减刑、假释",
"以色列立法禁联合国机构,美表态担忧,中东局势再生波澜",
]
"""
用户的问题,需要匹配的内容
"""
query = "国际争端"
query_vec= get_embeddings([query])[0]
documents_vecs = get_embeddings(documents) # 5个向量
for vec in documents_vecs:
print(cosine_similarity(vec, query_vec)) # 计算相似度
print("==="*20)
for vec in documents_vecs:
print(osd_similarity(vec, query_vec)) # 计算欧氏距离

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)