
“CLIPer:分层改进CLIP空间表示以实现开放词汇语义分割”【学习笔记】
对比"语言-图像"预训练(ContrastiveLanguage-ImageP,CLIP)在各种图像级任务上表现出很强的zero-shot分类能力,因此引出了一系列研究:如何在不进行额外训练的情况下将CLIP应用于像素级开放词汇语义分割。关键是改进图像级CLIP的空间表示,如用self-self注意图或基于VFM的注意图代替最后一层的自我注意图。本文提出了一个新的分层框架CLIPer,它对CLIP
文章来自:Computer Vision and Pattern Recognition 2024
[2411.13836] CLIPer: Hierarchically Improving Spatial Representation of CLIP for Open-Vocabulary Semantic Segmentation https://arxiv.org/abs/2411.13836
https://arxiv.org/abs/2411.13836
Abstract
对比"语言-图像"预训练(Contrastive Language-Image Pre-training ,CLIP)在各种图像级任务上表现出很强的zero-shot分类能力,因此引出了一系列研究:如何在不进行额外训练的情况下将CLIP应用于像素级开放词汇语义分割。关键是改进图像级CLIP的空间表示,如用self-self注意图或基于VFM的注意图代替最后一层的自我注意图。
本文提出了一个新的分层框架CLIPer,它对CLIP的空间表示进行了分层改进。CLIPer包括一个早期层融合模块和一个细粒度补偿模块。
可以观察到,早期层的嵌入和注意力图可以保留空间结构信息。受此启发,设计了前层融合模块,生成具有较好空间一致性的分割图.
然后,我们使用一个细粒度的补偿模块,使用扩散模型的自注意映射来补偿局部细节。
源代码和模型 :https://linsun449.github.io/cliper
Introduction
开放词汇语义分割(Open-vocabulary semantic segmentation)旨在将图像划分为不同的组,并为每组分配属于任意语义类别的标签。相对于传统的语义切分,开放词汇语义切分是一个更具挑战性的切分任务。
CLIP由于对大规模图文配对数据进行了预训练,因此在图像级分割任务中显示出强大的zero-shot能力。在此基础上,提出了几种方法来适应CLIP的无训练开放词汇语义分割。关键的挑战是改进图像级监督模型的空间表示以实现像素级分割。
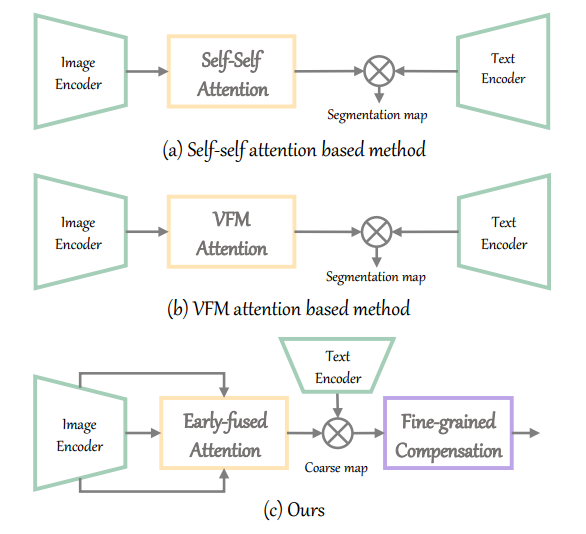
如图1(a)所示,一些方法在最后一层用self-self attention map修改原始self attention map,更好地保持局部空间信息。
图1(b),ProxyCLIP 没有使用原始的或自我的注意力地图,而是从VFM中提取自我注意力图作为最后一层的自我注意力图。
这些方法在不需要额外训练的情况下提高了CLIP在开放词汇环境下的切分性能,但是这些方法主要考虑CLIP最后一层的自注意图的改进。
而本文专注于两个因素,来分层提高空间表示:
(i)一是改进patch级的空间相关性。可以观察到,在早期层的块嵌入和注意图包含丰富的空间结构信息,因此,本文的目标是利用CLIP的早期层信息,而不是在最后一层使用self-self或基于VFM的注意。
(ii)二是细粒度的补偿。图像与文本之间的patch级相似度图在局部细节上比较粗糙,需要进一步改善局部细节以实现改进的分割。
基于这两个因素,本文提出了一种新的开放式词汇语义切分的层次化方法CLIPer,如图1(c)所示,CLIPer由一个早期层融合模块(an earlylayer fusion module)和一个细粒度补偿模块(a fine-grained compensation module)组成。
早期层融合模块将前几层的patch嵌入和注意力图进行融合,以提高输出的patch嵌入的空间一致性。基于输出的任意类别的文本和patch嵌入,我们可以生成corse分割图。然后,细粒度补偿模块结合稳定扩散的精细空间信息来补偿局部细节。
Methodology
Overview
图4展示了CLIPer的总体架构。
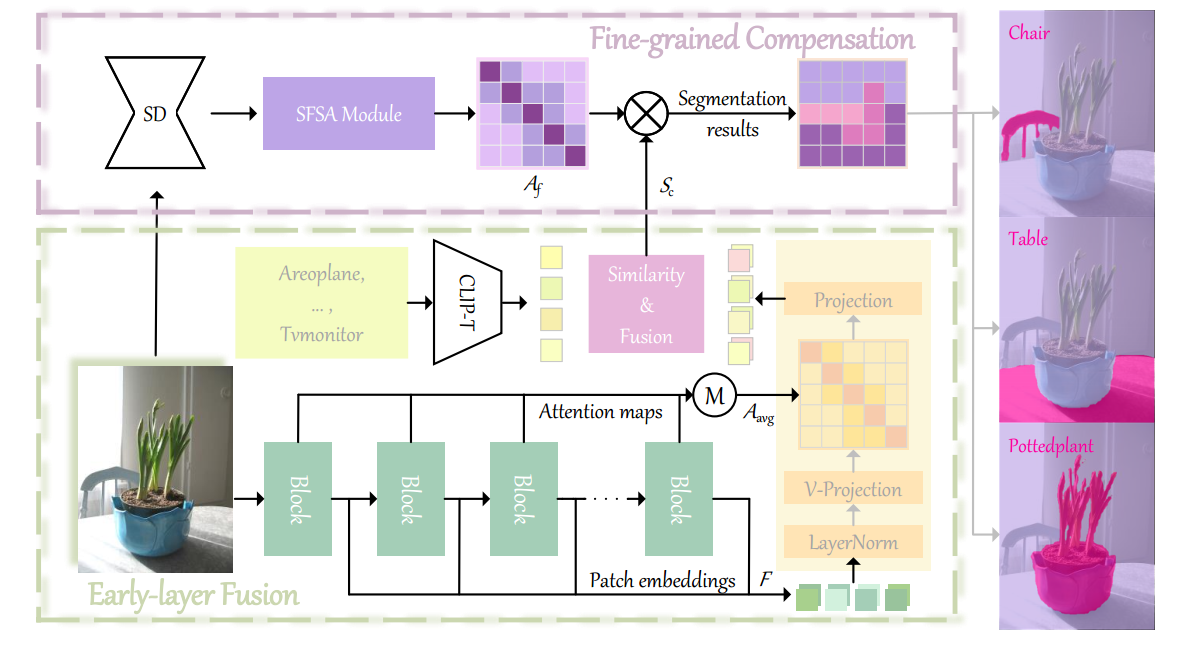
Early-layer fusion
给定一个图像,我们首先将图像划分为块嵌入F,然后将这些嵌入馈送到一系列Transformer块。对于第n个Transformer块,我们生成查询Q、键K和值V。整个Transformer块的计算过程如下:
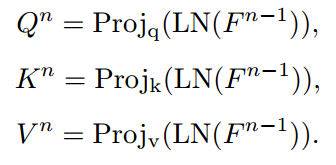
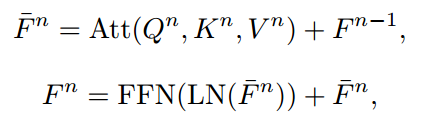
类似地,模型可以生成直到倒数第二层的所有Transformer块的嵌入和注意力图表示为两个集合F和A,用来生成一个平均的注意力图:
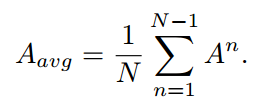
然后,将最后一层的原始自注意力图替换为平均注意力图Aavg,然后将所有嵌入送到最后一层。类似于ClearCLIP,省略了最后一个Transformer块中的前馈网络和剩余连接,这可以简化表示,同时更好地对齐文本嵌入。因此,我们为不同的层生成多个输出嵌入。
Fine-grained compensation
CLIP生成的patch级分割仍然相对粗糙,限制了分割精度。为了更好地补偿粗糙图的局部细节,利用了稳定扩散的自注意图,研究发现它在捕获细粒度局部信息方面特别有效。这种局部保持特性非常有利于细化块级分割的空间细节,提高区分边界的能力。
具体来说,首先将带有空文本提示的图像送入稳定扩散,获得相应的最高空间分辨率的多头自注意图;再将此注意图表示为Am;然后,通过跨注意力头部的矩阵链乘法来融合这些注意力图Am,其公式化为:
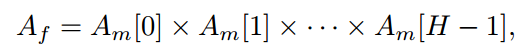
其中Am[i]表示第i个头部自注意图。然后,利用融合的注意图Af来细化放大的粗分割图Sc:
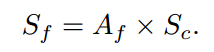
最后,将Sf提升到输入图像的分辨率,得到细粒度的像素级分割图。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)