
SPI接口协议以及性能演进案例
为,是一种的通信协议,由摩托罗拉(Motorola)在 1980 年代中期提出,最初用于其微控制器(MCU)与外设之间的短距离通信。在 SPI 协议出现之前,微控制器与外设的通信多采用方式。并行通信需要多根数据线(如 8 位、16 位),硬件布线复杂,占用大量的 GPIO 引脚,不适合小型化、低成本的嵌入式系统。此外,当时的串行通信方案(如早期 UART)多为异步通信,速率较低且不支持全双工,无法
目录
一、SPI协议
1、SPI协议的起源
SPI (Serial Peripheral Interface)为串行外设接口,是一种高速、全双工的同步串行通信协议,由摩托罗拉(Motorola)在 1980 年代中期提出,最初用于其微控制器(MCU)与外设之间的短距离通信。
在 SPI 协议出现之前,微控制器与外设的通信多采用并行通信方式。并行通信需要多根数据线(如 8 位、16 位),硬件布线复杂,占用大量的 GPIO 引脚,不适合小型化、低成本的嵌入式系统。此外,当时的串行通信方案(如早期 UART)多为异步通信,速率较低且不支持全双工,无法满足高速外设(如 SPI Flash、ADC/DAC)的通信需求。
为解决上述痛点,摩托罗拉设计了 SPI 协议:以极少的引脚数量实现高速同步全双工通信,简化硬件设计的同时提升数据传输效率,很快成为嵌入式领域的主流串行通信标准之一。
2、SPI协议通信应用场景
SPI 协议的特点是高速、全双工、主从架构灵活,因此广泛应用于短距离、板级的芯片间通信,典型场景包括:
1)与外部存储设备通信:例如与SPI 接口的Flash或者RAM通信,读写存储程序固件、配置数据等(后续为了提升访问Flash的速率,诞生了Quad SPI,通过并行通信方式提升访问速度)。
2)传感器数据读取:与高精度传感器(主要应用于车载领域,例如加速度、转角、温湿度、Air Bag等类型传感器)通信,传感器将采集的数据通过 SPI 接口传给 MCU。
3)显示设备驱动:驱动小型显示屏,MCU 通过 SPI 向显示屏控制器传输图像数据和控制指令。一般图像数据的存储以及传输接口是在外部ASIC芯片处理完成,转化为LED控制指令。指令通过通过SPI接口传输给OLED屏\TFT屏显示图像(显示屏图像刷新频率最高只有几百hz)。
4)ADC/DAC数模转化:连接高速模数转换器(ADC)或数模转换器(DAC),实现模拟信号与数字信号的转换,适用于工业测控、音频设备等场景。
5)多从机扩展:支持一主多从的拓扑结构,可在一个 MCU 下挂载多个外设(如同时连接 SPI Flash、传感器和 OLED 屏),节省引脚资源。
6)芯片间互联:部分 MCU 之间也可通过 SPI 实现通信,完成数据交互或协同工作(在车载通信网络上,各CAN节点的收发器可基于SPI接口进行通信;车载领域中,作为电机控制系统接口,灯光系统控制器接口,BMS控制系统接口等)。
3、SPI接口时序
SPI 总线采用4 根信号线(部分简化场景可省略部分引脚),基于主从(Master-Slave)架构,一个主设备可控制多个从设备,4根信号线如下所示,。
| 信号名称 | 英文全称 | 功能描述 |
|---|---|---|
| SCK | Serial Clock | 串行时钟,由主设备产生,用于同步数据传输的时序 |
| MOSI | Master Out, Slave In | 主发从收,主设备向从设备发送数据的通道 |
| MISO | Master In, Slave Out | 主收从发,从设备向主设备发送数据的通道 |
| CS | Chip Select | 片选信号,由主设备控制,低电平有效时选中对应的从设备,只有被选中的从设备才会响应 SPI 通信 |
3.1 SPI协议时序:
SPI 是全双工通信,主设备和从设备在同一个 SCK 时钟周期内,同时通过 MOSI 和 MISO 传输数据,传输过程如下:
-
主设备拉低目标从设备的 CS 引脚,选中该从设备;
-
主设备产生 SCK 时钟信号,同时在 MOSI 引脚上逐位输出数据;
-
从设备在 SCK 的指定采样沿,读取 MOSI 引脚上的数据;
-
与此同时,从设备在 MISO 引脚上逐位输出反馈数据;
-
主设备在 SCK 的对应采样沿,读取 MISO 引脚上的数据;
-
数据传输完成后,主设备拉高 CS 引脚,结束本次通信。

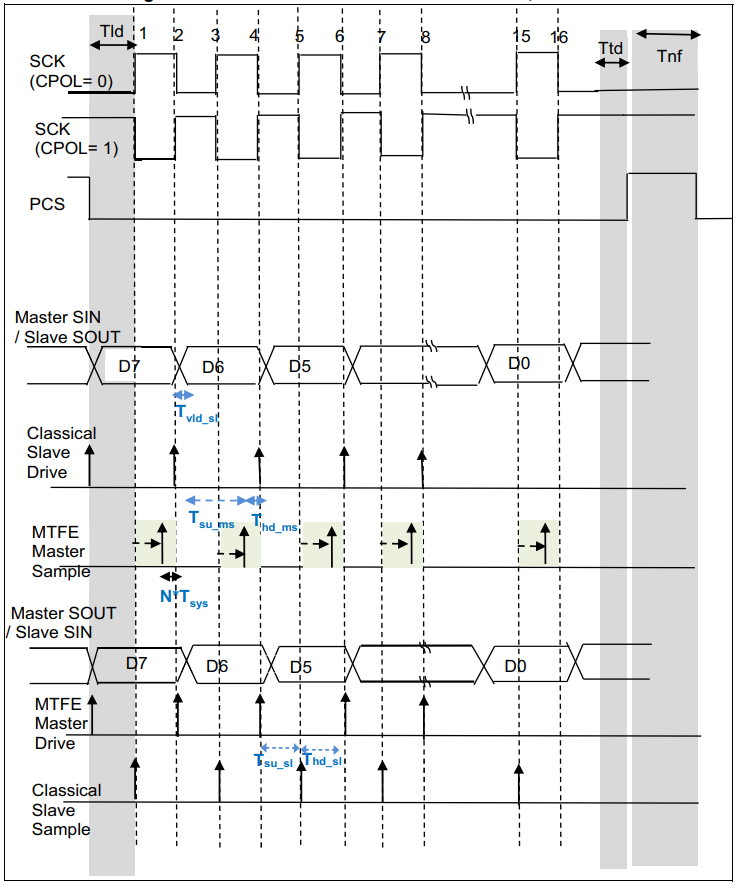
上述是理想的时序结果图,实际SCK到达Slave需要一定的时间,Slave反馈MISO到达Master的引脚也需要一定的时间。如下图所示:T1是SCK到达Slave的时间延迟,T2是Master输出SCK后收到MISO的时间延迟。Master是T3时刻(半个SCK cycle之后)采样MISO的数据。因此SPI同步时序上,T2的延迟不能超过半个SCK cycle的采样余量。波特率SCK频率低时是十分容易满足的,而SCK频率高时,要满足该条件就很困难。

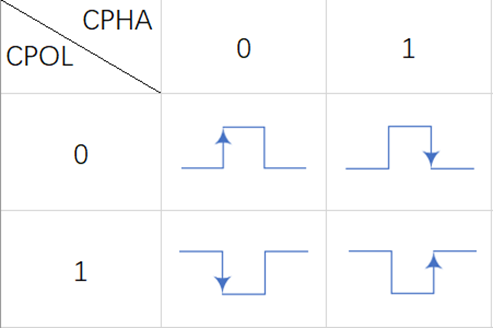
SPI 是同步通信协议,数据传输的节奏由Master产生的 SCK 时钟控制,时钟的极性(CPOL)和相位(CPHA)决定了 SPI 的4 种工作模式,这是 SPI 协议的核心参数。
- 关键时序参数定义
> CPOL(时钟极性):决定空闲状态下 SCK 的电平。
CPOL=0:空闲时 SCK 为低电平;
CPOL=1:空闲时 SCK 为高电平。
> CPHA(时钟相位):决定数据采样的时刻。
CPHA=0:在 SCK 的第一个跳变沿(上升沿或下降沿,由 CPOL 决定)采样数据;
CPHA=1:在 SCK 的第二个跳变沿采样数据。
- 工作模式
| 模式编号 | CPOL | CPHA | 空闲时钟电平 | 数据采样时刻 |
|---|---|---|---|---|
| 0 | 0 | 0 | 低电平 | SCK 上升沿采样 |
| 1 | 0 | 1 | 低电平 | SCK 下降沿采样 |
| 2 | 1 | 0 | 高电平 | SCK 下降沿采样 |
| 3 | 1 | 1 | 高电平 | SCK 上升沿采样 |
图示如下:箭头代表采样时刻,另一个时钟边沿是更新发送数据时刻。模式0/1时,没有第一个数据发送沿,移位数据提前放到MOSI/MISO引脚上。
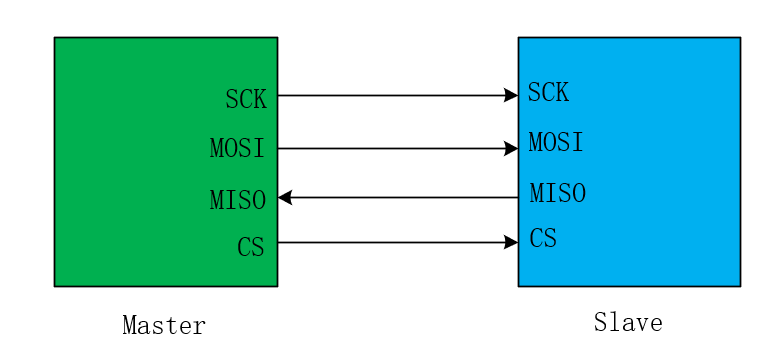
3.2 SPI硬件连接方式:
- 一主一从(点对点通信)的硬件连接方式如下:
- 一主多从的第一类硬件连接方式如下:
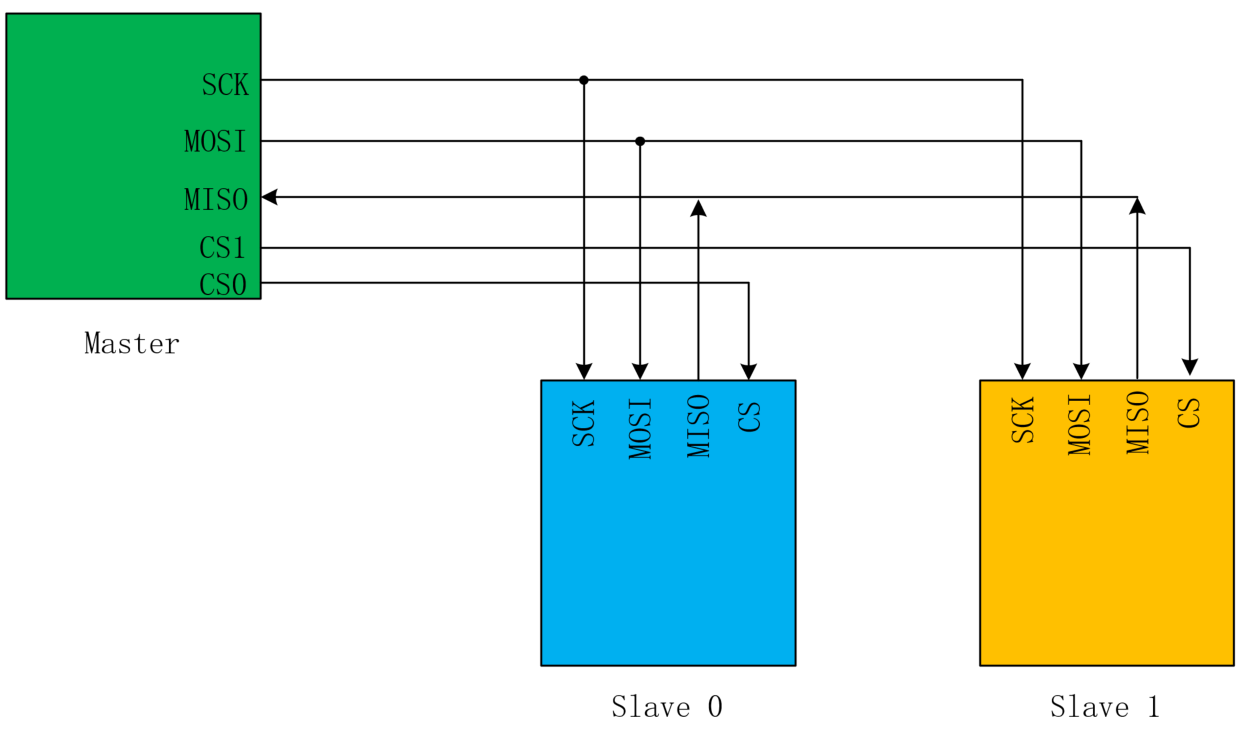
Note:需要Master使用多根片选信号完成Slave分时选通,从而进行通信。因此需要Master存在多CS IO(Input/Output)输出。对于Slave而言,只有CS选通时才能进行通信:CS无效时,MISO IO输出必须高阻,不能输出高电压或者低电压,否则其他Slave通信异常。CS无效时,不进行MOSI的数据采集。
- 一主多从的第二类硬件连接方式如下:
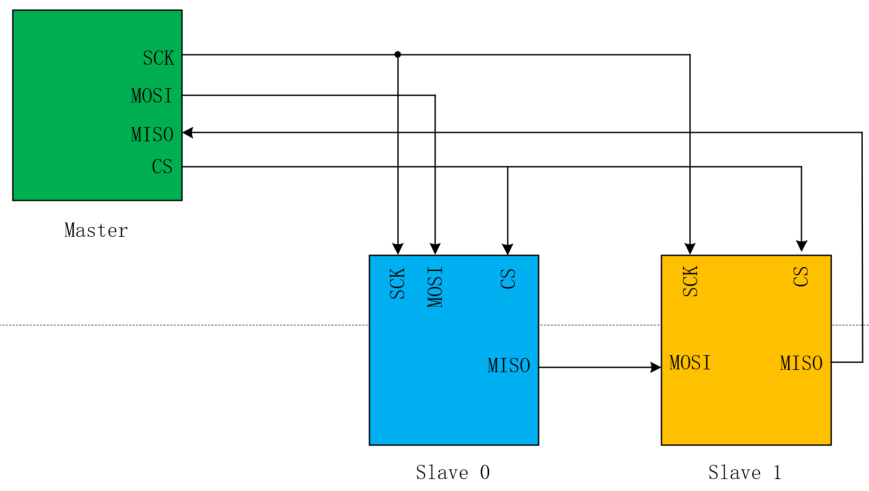
Note:菊花链通信相比普通一主多从通信连接方式,可以节省Master的CS IO数量。但CS有效期间,要完成Master->Slave 0->Slave 1->Master的传输顺序。此类连接方式,无法支持SCK波特率较高的场景下进行通信,波特率性能瓶颈在距离Master最远的Slave上,其反馈MISO数据的延迟不能大于SCK的半Cycle余量。
4、SPI接口面临的新难题
从前面几个小节的介绍,SPI接口协议基本已经清晰。但随着SPI在各个领域应用场景普及后,开始面临了一些问题:
- 当前SPI主要使用的波特率时钟SCK频率为1/2/4/5/8/10/16Mhz等。如何支持波特率时钟SCK的更高通信场景?
- 一主多从的拓扑结构通信场景下,主机切换通信的从机需要软件重新配置,引入额外的操作以及开销,如何缩减此类操作的软件开销?
- SPI接口广泛使用于当前车载领域的热点场景,引入使用者对该接口的安全等级需求思考。如何保证SPI的传输是安全可靠的?
基于上述待解决的问题,以及摩托拉提出SPI协议后未再继续演进,因此相关MCU Vender在解决上述问题时,基于原始SPI协议各自独立演进,形成接口时序一致但使用风格以及性能不一的SPI解决方案,例如IFX TC3XX系列的QSPI,IFX TC4XX系列的xSPI,Renesas U2B系列的MSPI,ST的Stellar系列的 SPIQ/Octol SPI等。
二、SPI的演进
为了更好支持当前热点领域场景,SPI演进目的不外乎是解决上述新难题。现在各MCU vender都做出了一些改进设计。例如IFX QSPI是队列SPI能支持最高50Mhz(LVDS)的波特率时钟通信场景,使用队列缓存帧命令和数据的方式能实现硬件自动切换通信从机,很好的缩减软件开销。而Renesas MSPI和ST SPIQ则实现了多队列的硬件架构,更好的缩减软件开销,同时也支持当前车规安全需求的Safe SPI传输帧格式。
1、Safe SPI
为满足车规级产品的SPI接口安全需求,也是为各Vender的不同变种SPI协议提供一个统一车规场景下软件应用接口,博世和大陆汽车于2016年一起推出汽车领域的SPI接口工业标准SafeSPI协议。SafeSPI主要是应用于不同设备间的传感器数据的SPI传输协议。当前SafeSPI已经发展到V2.0版本,于2021年推出。
SafeSPI和传统的SPI协议的硬件输出引脚没有变化,只是在硬件拓扑架构以及传输数据格式上进行新规定,旨在更好应用车规领域。
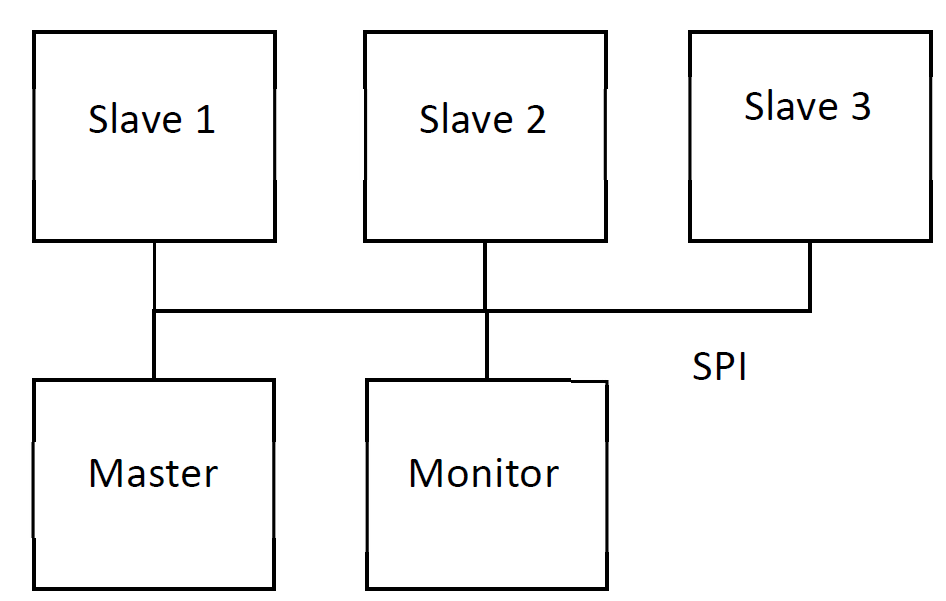
可以看到SafeSPI和SPI一主多从硬件拓扑结构很类似。差异点在于,硬件连接上多一个Monitor器件。Monitor是一个专用的ASIC设备,主要是监测系统上各个节点传输是否异常。SafeSPI系统上各个节点的数据是SafeSPI协议中规定的特定SPI帧格式。
Safe帧格式主要分为两大类:In-frame 和Out-of-frame。具体的帧结构定义,可以去查看SafeSPI协议规范(官网地址是Specifications | SafeSPI.org)。
两类帧格式所应用的传输场景是不同的。In-frame帧格式传输场景下,要求从机响应主机的请求是同一个帧时隙内。On-frame帧格式传输场景下,要求从机响应主机的请求是在下一个帧时隙内。
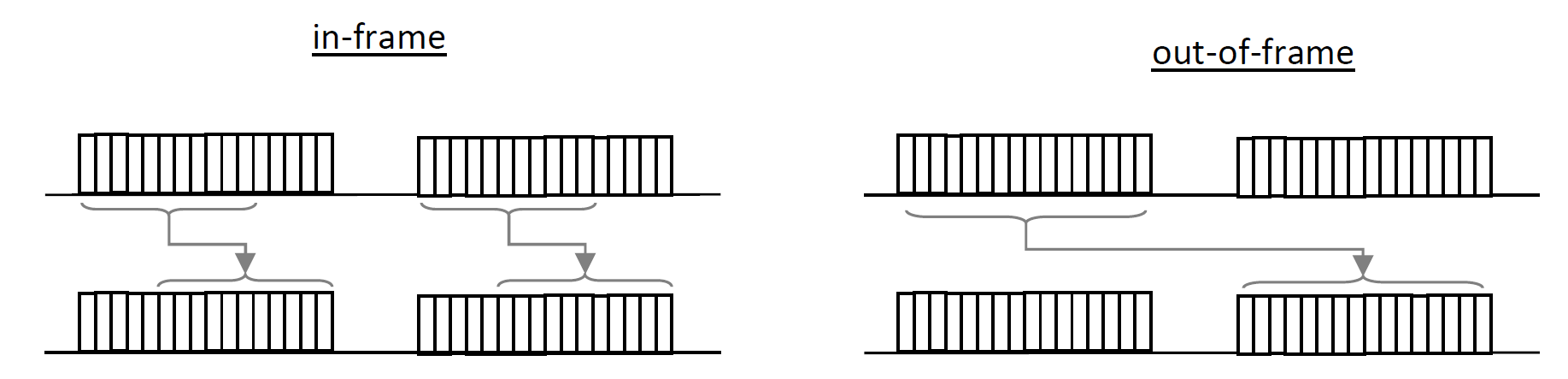
看到这里,大家若查阅SafeSPI协议内容,知晓了帧格式以及传输场景,是不是有这样的疑问:SafeSPI似乎只是传输数据内容按照特定帧格式封装的SPI传输。是不是在传统SPI的基础上让软件按照SafeSPI帧格式完成组帧然后进行通信就可以?
我的结论是不可行,软件无法实现SafeSPI的场景需求。这个问题就不回答了,大家感兴趣可以一起讨论。
2、改进型SPI
为了解决第一章的SPI新难题,各MCU Vender都推出有自己特色的SPI接口,我统称为改进型的SPI。
如IFX TC3XX系列的QSPI,Renesas U2B系列的MSPI,ST的Stellar系列的 SPIQ等改进型SPI接口和传统SPI的架构差异是使用了队列缓存结构,因此可以统称为队列SPI,将在2.1章节进行重点介绍。
除了队列SPI外,还有一种是专门针对对片外Flash/SRAM进行高速访问场景的并行传输SPI,即4线或8线传输SPI,例如IFX xSPI和ST的Qctol SPI等,将在2.2章节进行重点介绍。
2.1 队列SPI
如前文所述,使用了队列缓存结构的SPI即为队列SPI。只有一个缓存队列的SPI是IFX TC3XX系列的QSPI。存在多个缓存队列的SPI是Renesas U2B系列的MSPI,ST的Stellar系列的 SPIQ。队列SPI典型结构如Renesas U2B系列的MSPI:
Renesas MSPI存在8个队列,共用一个RAM作为缓存空间。需用户指定每个队列Region区域大小和RAM存储区域映射关系。但SPI总线接口只有一套,意味各队列是分时通信,只有仲裁模块授权的队列才能进行通信。
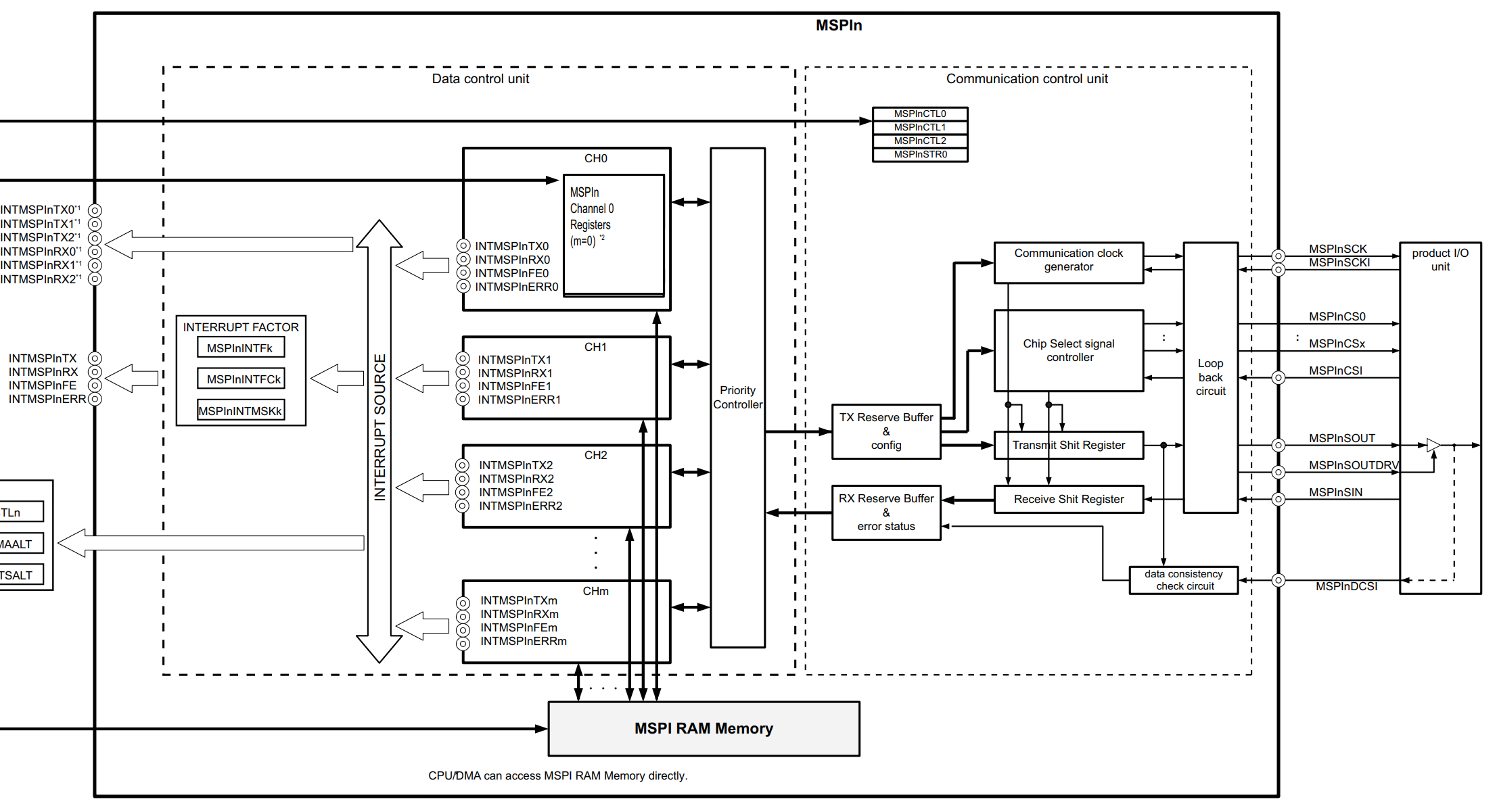
那么队列SPI是如何解决SPI接口面临的三大难题的呢?
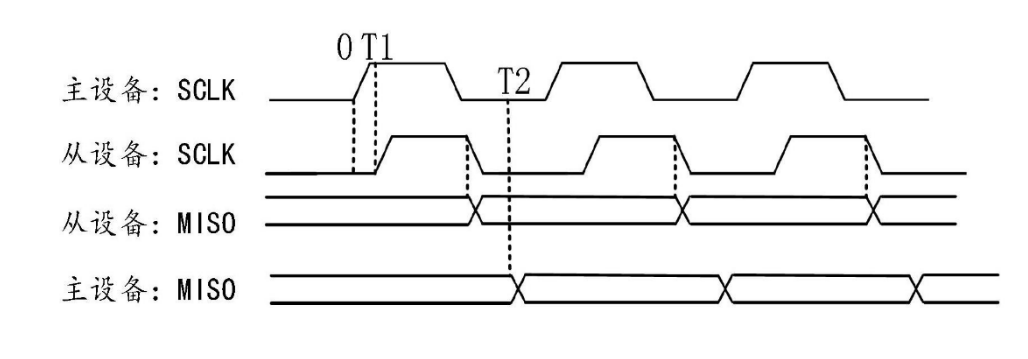
支持更高的波特率时钟通信场景:一旦波特率时钟SCK频率增大,那么SCK周期T宽度就会缩小,引用第一章 3.1小节分析结论 0.5T > T2 master才可以正确接收MISO数据。而T2随着两个MCU板上物理位置和MCU内SPI位置实现,基本不可能更改。因此在T变小情况下要满足上述公式,只能从0.5T采样余量是考虑,即如果SPI的采样余量不是0.5个Cycle而是0.8个,或者1个是不是可以?
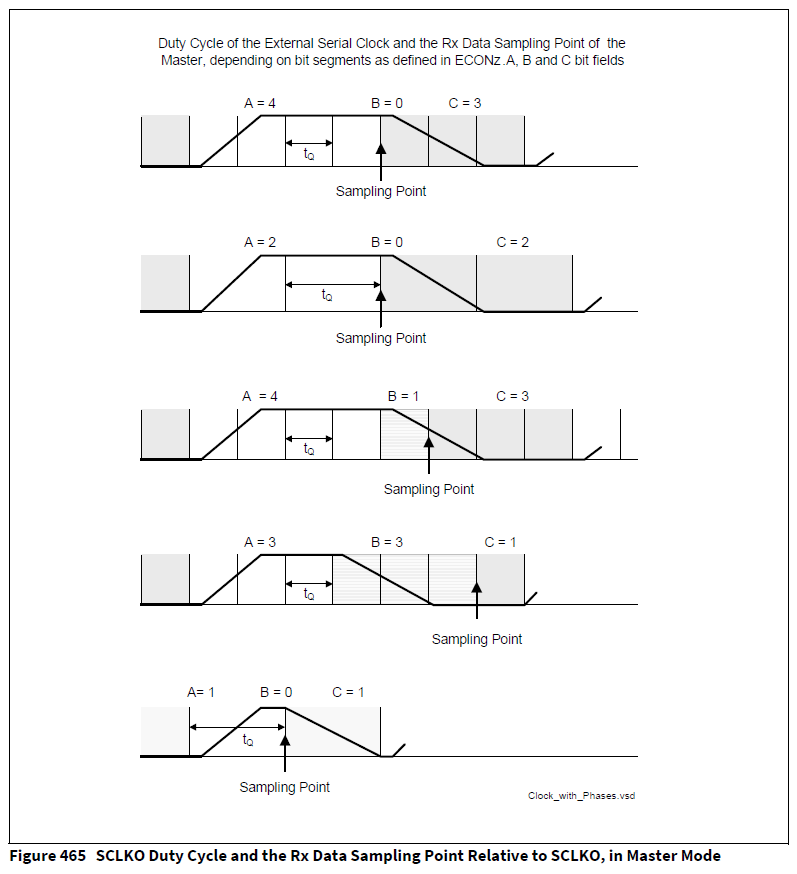
因此,MCU Vender另辟蹊径,改变Master提供的SCK波特率时钟的占空比,使得留给Master采样MISO余量大于0.5T,同时也会改变slave的MOSI真实采样时刻。而这样的变化会改变SPI接口的时序且SCK采样余量只能趋近于0.8T无法达到1个T(大于0.8T时,高频率的SCK采样沿->下一个发送沿间隔太小,IO引脚模拟器件无法输出采样沿,SCK引脚输出电平经过滤波后可能一直为高)。典型例子如IFX QSPI 波特率时钟生成方案:
图示中A配置决定波特率时钟SCK发送沿到采样沿的间隔宽度。B配置决定波特率时钟SCK真实采样时刻,C配置决定波特率时钟SCK采样时刻到新发送沿的间隔宽度。
为了达到能支持Master 采样余量达到1T,MCU Vender又想出另一个很有创意的解决方案:不改变Master 输出SCK的占空比,而是改变Master内部实际采样点的位置。这样的好处是Slave仍然是在0.5T时刻采样MOSI,而Master内部采样时,在延迟时刻采样MISO。典型案例如ST Stellar系列SPIQ接口的Capture Delay方案:
图示中主机原本MISO的采样时刻和从机采样MOSI的时刻应是SCK第一个沿,但主机开启MTFE功能后,可往后推迟MISO的采样时刻,最大可推迟到图中绿色区域的边沿,即下一个SCK的发送沿上,达到Master获得1个T的采样余量,能很好的应对从机MISO发送延迟。
主机除了修改波特率时钟SCK占空比,以及监测到SCK采样时刻后再按固定步进去推迟采样点时刻,还有一种方案是将输出的SCK再环回,也能有效补充T2延迟,引入的性能问题。此类方案不在进行详细展开,有兴趣再行讨论。
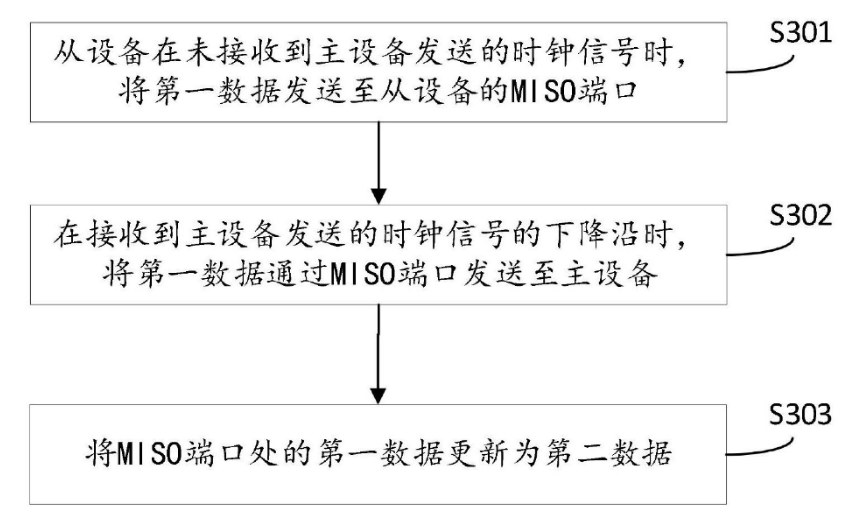
除了上述主机提供采样余量方案外,也可以在从机端进行考虑,例如编号为CN117493254A的《一种数据传输方法及装置》专利中所描述:
从机没收到SCK,提前将第一笔数据放到MISO引脚上。在SCK的第一个周期的采样沿时刻更新第二笔数据到MISO引脚上,达到从机提前半周期发送MISO的效果,补偿主机发出时钟再收到MISO的T2延迟。因此使用此类设计方案,可以支持更高波特率时钟SCK的通信场景。
缩减主从切换的软件开销:传统的SPI在一主多从结构中,切换通信SPI从机时,软件需先行关闭当前通信从机的CS片选,接着配置SPI通信的配置,开启新从机的CS片选,再进行通信。这样的操作流程需要软件频繁的介入,CPU流程面临被频繁打断的风险,软件时间开销是巨大的。为了解决此类问题,改进型SPI进行两类的硬件创新:
- 时序由硬件根据配置控制,一帧间隔内,CS自动有效和无效由硬件控制:硬件内部存在IDLE/LEAD/TRAIL这三类时序控制间隙。
IDLE间隙:SCK时钟输出电平由默认电平变为CPOL电平时刻,相比CS有效时刻的提前时序量。
LEAD间隙:CS片选有效时刻,相比SCK和DATA有效时刻的提前时序量。
TRAIL间隙:CS片选无效时刻,相比SCK无效时刻的延迟时序量。
典型案例如IFX TC3XX系列的QSPI:
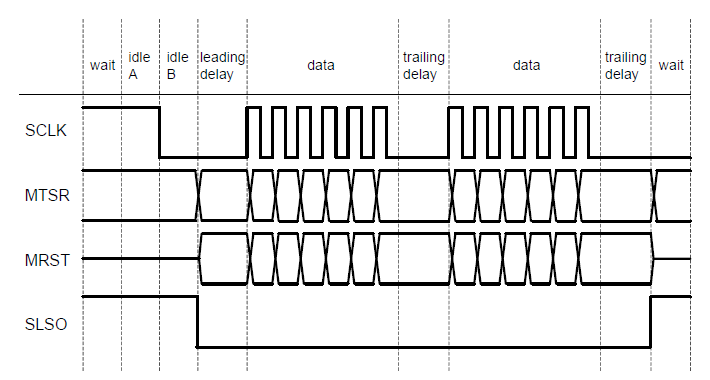
用户开启通信前配置IDLE/LEAD/TRAIL的延迟间隙,配置完成后开启SPI传输。SPI硬件根据配置,DILE间隙开始时将SCK(图中信号名称为SCLK)电平变为CPOL配置电平,IDLE间隙结束后开启LEAD间隙。LEAD间隙开始时刻,片选CS(图中信号名称为SLSO)变为有效,LEAD间隙结束后开始DATA阶段,输出SCK波特率时钟和数据。DATA阶段结束开始TRAIL间隙,TRAIL间隙是两个DATA阶段的间隔,也是一帧最后数据输出结束,延迟CS片选无效时刻的间隔。
通过上述硬件间隙设计,SPI通信开启后,软件切换从机时无需再对CS进行实时配置,避免过多打断CPU进程,引入额外开销。
- 切换控制由硬件自动进行,硬件使用队列缓存结构,队列中缓存对从机的通信配置和数据。
典型案例如IFX TC3XX QSPI,将一帧的命令BACON和帧数据都存入FIFO(First In First Output)中,BACON命令中定义帧的传输格式,波特率时钟配置,时序IDLE/LEAD/TRIAL间隙长度,帧通信有效的CS。SPI传输开始时,Shift Register从FIFO读取BACON和帧数据,生成对应SCK/CS/DATA时序,与对应从机进行通信,帧结束时SPI硬件无效CS。下一帧传输时,读取新的BACON和帧数据,生成新的SCK/CS/DATA,与新从机进行通信。
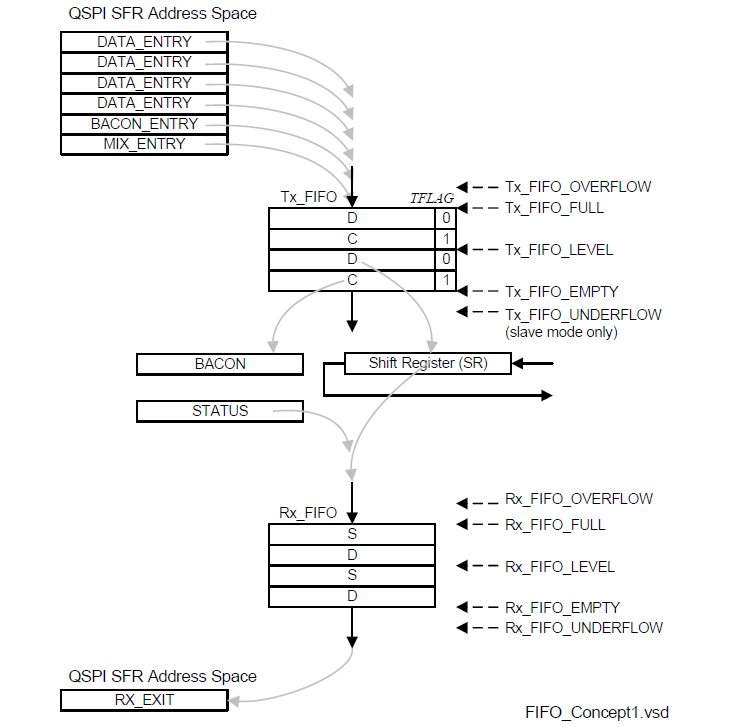
满足车规的安全使用需求:支持车规的安全使用需求,满足ISO 26262的安全要求等级,需要SPI支持Safe SPI协议,详细描述见Safe SPI章节。为支持这个Safe SPI协议,队列SPI要支持CRC编码以及校验功能,例如Renesas U2B系列的MSPI,ST的Stellar系列的 SPIQ等。
2.2 并行SPI
并行SPI一般我们称之为Quad SPI或者Octo SPI,主要是为了解决高速访问片外存储系统的通信场景,提高存储传输带宽,主要应用于车规领域中和片外Flash通信,以及BMS中高速AFE芯片通信。
Quad SPI相比传统SPI数据线增加了2根,Octo SPI则是增加6根,通过并行传输方式提升访问带宽,例如单线MISO使用SCK(50Mhz)传输数据,带宽为50Mbps。而Quad SPI则有4根SIN数据线进行传输,则传输带宽为4*50=200Mbps,而Octo SPI则为8*50=400Mbps。
| 协议类型 | 时钟线 | 片选线 | 数据通道(收发) | 传输速率(同 SCK 频率) | 核心引脚 |
|---|---|---|---|---|---|
| 标准 SPI | SCK | CS |
MOSI MISO |
1× |
SCK/SS/MOSI/MISO (4线) |
| Quad SPI | SCK | CS |
4XSIO (双向) |
4× |
SCK/CS/SIO0~3 (6线) |
| Octo SPI | SCK | CS |
8XSIO (双向) |
8× |
SCK/CS/SIO0~7 (8线) |
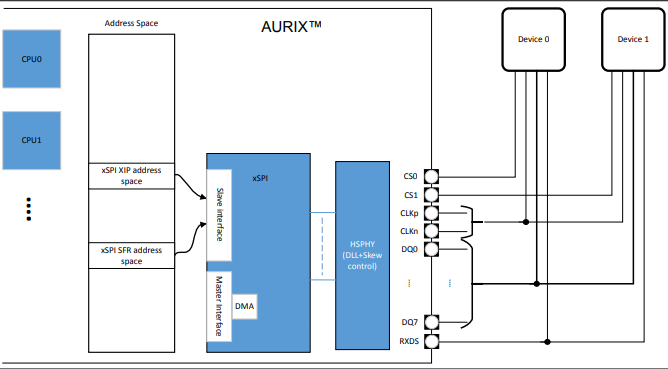
典型案例如IFX TC4XX系列的xSPI:图中DQ0-7为8根数据线。
标准SPI和xSPI访问片外Flash的时序差异:标准SPI发送8bit CMD和32bit addr一共需要40个SCK Cycle,Flash读数据也是每个SCK周期反馈1个bit,图中反馈n Byte需要8n个SCK周期。而xSPI使用DDR(Dual Data Rate,双倍数据速率)模式后,SCK半周期就可以传输CMD的1bit,因此一个SCK周期就可以传输2个8bit CMD,2个SCK就可以传输32bit addr。Flash反馈n Byte读数据只需要n/2个SCK周期,速率提升16倍。若SCK波特率时钟为50Mhz,则理论xSPI速率为800Mb/s。可见并行传输SPI针对片外Flash访问速率提升是巨大。
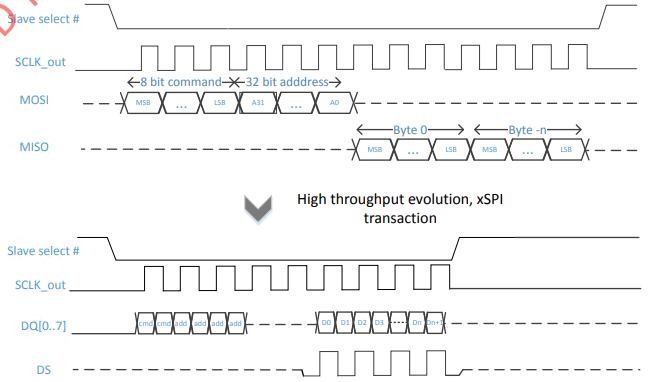
基于此,是否可以说并行传输SPI比队列SPI更先进,性能更强?此问题,我无法进行解答,或许随着工作经历变多,我才能有特定条件的结论。这里只列举两者的应用差异:
| 队列SPI | 并行SPI | |
| 差异项 |
|
|

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)