
开源二进制分析工具binwalk实战应用详解
在嵌入式系统、固件镜像和闭源二进制文件的逆向分析领域,binwalk作为一款开源且高度可扩展的二进制分析工具,凭借其强大的签名扫描、递归解包与差分对比能力,已成为研究人员进行固件解析与安全审计的首选工具之一。该工具不仅支持对多种常见文件格式(如gzip、SquashFS、U-Boot、PNG等)的快速识别,还能通过模块化架构实现自定义规则扩展,适用于从初级漏洞挖掘到高级数字取证的广泛场景。本章将深

简介:binwalk是一款功能强大的开源二进制分析工具,广泛应用于固件逆向、恶意软件分析、数字取证和开源合规性检查等领域。该工具通过签名匹配、自动解压、简单解密和模块块分析等功能,帮助用户识别并提取嵌入在二进制文件中的隐藏数据,如文件系统、压缩包和图像等。支持与反汇编工具集成,并可通过自定义签名扩展功能。本项目基于binwalk-master源码,提供完整的安装指南与使用实践,适合安全研究人员和开发人员深入掌握二进制分析核心技术。 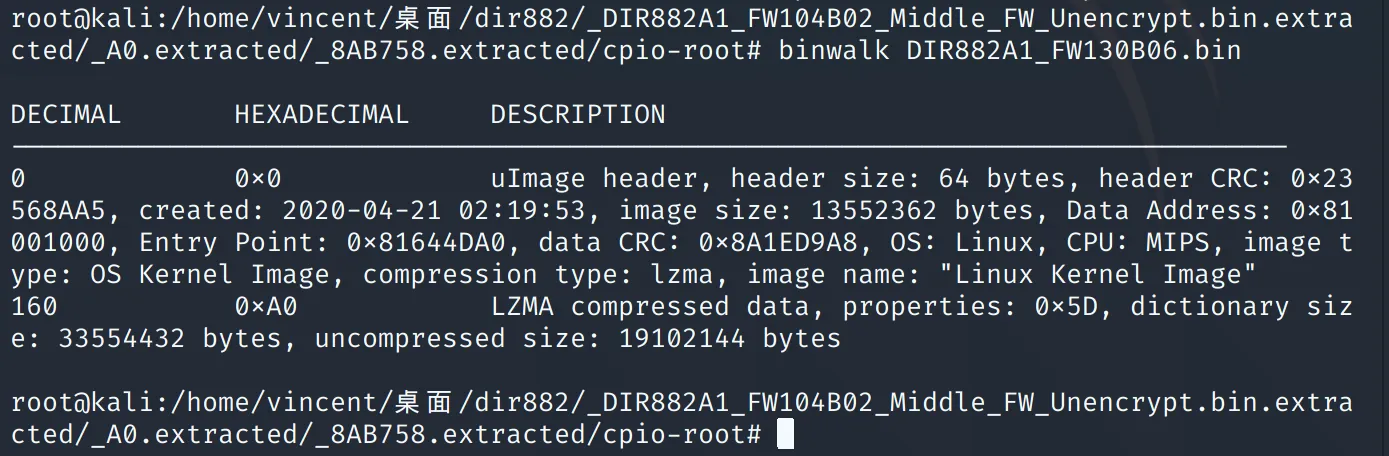
1. 二进制分析与逆向工程基础
在现代信息安全领域,二进制分析是深入理解闭源系统行为的核心技术。本章系统介绍其基本原理与应用场景,涵盖静态与动态分析的差异、ELF/PE/Mach-O等主流文件格式的结构特征,以及嵌入式固件中常见的复合镜像组织方式。重点讲解熵值分析、字符串提取和节区识别等基础方法,结合以下典型操作示例:
$ strings firmware.bin | grep -i "boot"
$ hexdump -C firmware.bin | head -20
通过这些手段,可初步判断二进制文件的构成逻辑,为后续使用 binwalk 进行深度解析奠定基础。读者将掌握从原始字节流中提炼结构信息的思维模式,明确分析目标与技术路径的映射关系。
2. binwalk核心功能概述
在嵌入式系统、固件镜像和闭源二进制文件的逆向分析领域, binwalk 作为一款开源且高度可扩展的二进制分析工具,凭借其强大的签名扫描、递归解包与差分对比能力,已成为研究人员进行固件解析与安全审计的首选工具之一。该工具不仅支持对多种常见文件格式(如gzip、SquashFS、U-Boot、PNG等)的快速识别,还能通过模块化架构实现自定义规则扩展,适用于从初级漏洞挖掘到高级数字取证的广泛场景。本章将深入剖析 binwalk 的整体架构设计与工作流程,详细解读其三大核心分析模式——签名扫描、递归解包与差分分析的技术实现机制,并结合典型固件实例演示如何高效执行初步解析任务。同时,还将介绍关键命令行参数的组合策略及其在自动化分析流水线中的集成方法,为后续章节中更深层次的功能开发与定制化应用打下坚实基础。
2.1 binwalk架构设计与工作流程
binwalk 并非一个单一功能的“黑盒”工具,而是基于清晰的模块化设计理念构建而成的一个灵活、可扩展的二进制分析框架。其内部结构采用分层处理机制,将输入数据流依次经过预处理、特征匹配、结果生成与输出控制等多个阶段,形成一条完整的分析流水线。这种设计不仅提升了运行效率,也使得开发者能够轻松地添加新的文件类型识别规则或替换底层提取引擎,极大增强了工具的适应性与长期可维护性。
2.1.1 模块化架构解析:扫描器、提取器与插件机制
binwalk 的核心架构由三大组件构成: 扫描器(Scanner) 、 提取器(Extractor) 和 插件系统(Plugin System) 。这三者协同工作,构成了从原始字节流中识别结构化信息并还原嵌套内容的技术闭环。
- 扫描器(Scanner) 负责遍历目标文件的每一个字节偏移位置,使用预定义的“签名数据库”进行模式匹配。这些签名通常以十六进制序列或正则表达式形式存在,用于标识特定文件格式的头部特征。例如,GZIP 文件以
1F 8B开头,PNG 文件以89 50 4E 47 0D 0A 1A 0A为魔数。扫描器会逐段比对,一旦发现匹配项,则记录其偏移地址、描述信息及置信度。 -
提取器(Extractor) 在扫描结果的基础上,调用相应的外部解压程序(如
gzip、unsquashfs)或内置逻辑对识别出的数据块进行实际解包操作。提取过程可以是单层的,也可以是递归的(配合-M参数),从而应对多层嵌套的复杂固件结构。 -
插件系统(Plugin System) 提供了高度开放的接口,允许用户编写 Python 脚本来自定义分析行为。例如,可通过插件实现特定厂商私有分区表的解析、加密数据流的自动检测,甚至集成熵值计算模块辅助判断压缩/加密区域。
以下是一个简化的 binwalk 架构流程图,展示了各组件之间的交互关系:
graph TD
A[输入文件] --> B(输入处理器)
B --> C{是否启用插件?}
C -->|是| D[加载用户插件]
C -->|否| E[标准签名数据库]
D --> F[扩展签名集]
F --> G[扫描器模块]
E --> G
G --> H[匹配结果列表]
H --> I{是否启用提取?}
I -->|是| J[提取器模块]
J --> K[调用外部工具或内置解码]
K --> L[输出解压后文件]
I -->|否| M[仅输出扫描报告]
M --> N[终端/JSON/CSV]
上述流程体现了 binwalk 的灵活性:无论是否启用插件或提取功能,系统都能根据配置动态调整处理路径,确保资源消耗与分析深度之间的平衡。
此外, binwalk 使用 Python 的面向对象设计模式组织代码,主要类包括:
- BinWalk() :主控制器,协调扫描与提取流程;
- Signature() :表示单个签名条目,包含偏移量、魔数、描述等字段;
- Extractor() :封装解压命令调用逻辑;
- PluginManager() :负责插件的发现、加载与执行。
示例代码:自定义插件注册机制
以下是一段典型的 binwalk 插件示例代码,展示如何通过装饰器注册一个新插件:
from binwalk.plugins import Plugin
@Plugin("my_custom_analyzer")
class MyCustomAnalyzer:
def __init__(self, binwalk):
self.binwalk = binwalk
def scan(self, result):
if "special_header" in result.description.lower():
print(f"[+] Detected special header at offset {hex(result.offset)}")
# 可在此处触发额外分析动作
代码逻辑逐行解读:
- 第1行:从binwalk.plugins导入Plugin装饰器,这是binwalk提供的插件注册接口。
- 第3–4行:使用@Plugin("my_custom_analyzer")将当前类标记为一个可用插件,名称为my_custom_analyzer,可在运行时通过-B参数调用。
- 第5–6行:构造函数接收一个binwalk实例,用于访问扫描上下文和共享状态。
- 第8–10行:scan()方法会在每次扫描命中后被调用;若结果描述中包含"special_header",则打印提示信息,可用于触发日志记录、网络告警或其他自动化响应。
该机制允许研究人员在不修改核心代码的前提下,快速部署针对特定设备或协议的专用分析逻辑,显著提升研究效率。
2.1.2 输入处理与输出控制流程
binwalk 支持多种输入源类型,包括本地文件、标准输入(stdin)、内存映像以及通过网络获取的原始二进制流。输入处理模块首先会对文件大小进行评估,决定是否启用内存映射(mmap)技术以提高大文件读取性能。对于超过数百MB的固件镜像, binwalk 默认采用分块读取策略,避免一次性加载导致内存溢出。
一旦输入数据准备就绪,系统即进入扫描阶段。扫描器按照预设步长(默认为1字节)滑动窗口,在每个偏移位置尝试匹配所有已加载的签名规则。为了优化性能, binwalk 对签名进行了索引化处理——将所有签名的首字节作为哈希键存储,只有当当前字节与某个签名首字节相同时,才启动完整匹配流程。这一优化可大幅减少无效比较次数,尤其在处理大型未压缩固件时效果显著。
输出控制方面, binwalk 提供了丰富的格式选项:
- 标准文本输出:适用于人工查看;
- JSON 输出( --json ):便于脚本解析;
- CSV 输出( --csv ):适合导入 Excel 或数据库;
- 安静模式( -q ):仅输出关键信息,抑制冗余日志。
| 输出模式 | 命令参数 | 适用场景 |
|---|---|---|
| 文本输出 | (默认) | 快速查看扫描结果 |
| JSON | --json |
自动化分析流水线 |
| CSV | --csv |
数据统计与可视化 |
| 静音模式 | -q |
批量处理时不干扰终端 |
此外, binwalk 还支持输出重定向至文件,例如:
binwalk firmware.bin --json > results.json
此命令将扫描结果以 JSON 格式写入 results.json ,可用于后续与其他工具(如 jq 、 pandas )联动分析。
2.1.3 支持的文件类型与协议识别范围
binwalk 内置了庞大的签名数据库,涵盖超过百种常见的文件格式、压缩算法、文件系统和引导加载程序。以下是部分典型支持类型的分类汇总表:
| 类别 | 支持格式示例 |
|---|---|
| 压缩格式 | gzip, bzip2, LZMA, XZ, 7-Zip, RAR, ZIP |
| 文件系统 | SquashFS, JFFS2, cramfs, ext2/3/4, YAFFS |
| 引导程序 | U-Boot, MIPS RedBoot, ARM Trusted Firmware |
| 图像格式 | PNG, JPEG, GIF, BMP, TIFF |
| 可执行格式 | ELF, PE (Windows), Mach-O (macOS) |
| 网络协议 | Ethernet frames, IP packets, TCP segments |
| 加密/编码 | Base64, XOR-obfuscated data, ASN.1 DER |
值得注意的是, binwalk 不仅能识别独立文件,还能探测嵌套结构中的复合型封装。例如,在某些 IoT 设备固件中,可能包含如下层级结构:
[Whole Firmware Image]
├── U-Boot Bootloader (binary)
├── Kernel (compressed with LZMA)
│ └── vmlinux (ELF executable)
└── RootFS (SquashFS)
├── /bin/sh (static ELF)
└── /etc/config.xml (plain text)
在这种情况下, binwalk 可通过多轮扫描+提取的方式逐层剥离,最终还原出最内层的应用程序与配置文件。
为了验证某类格式是否被支持,可通过以下命令列出所有已注册的签名:
binwalk -L
输出示例片段:
DECIMAL HEX DESCRIPTION
0 0x0 gzip compressed data, maximum compression
512 0x200 Squashfs filesystem, little endian, version 4.0
1024 0x400 CRC32 polynomial table
2048 0x800 Linux kernel version 4.14.151
该功能有助于快速确认目标固件中是否存在预期组件,是开展逆向工程前的重要准备工作。
2.2 核心分析模式详解
binwalk 的强大之处不仅在于其广泛的格式识别能力,更体现在其多样化的分析模式上。不同的分析需求对应不同的操作策略,合理选择模式可显著提升分析效率与准确性。本节将深入探讨三种最具代表性的分析模式: 签名扫描模式 、 递归解包模式 和 差分分析模式 ,并结合具体案例说明其技术实现原理与实战价值。
2.2.1 签名扫描模式:基于已知头部特征的快速定位
签名扫描是 binwalk 最基础也是最常用的分析方式。其核心思想是利用预先定义的“魔数”(Magic Number)或固定字节序列来识别文件格式。这类特征通常位于文件起始位置,具有唯一性和稳定性,适合作为分类依据。
例如,SquashFS 文件系统的标准头部为 sqsh 四字符标识,对应的十六进制为 73 71 73 68 。 binwalk 在扫描过程中会不断检查当前位置是否满足此类模式匹配条件。
执行签名扫描的基本命令如下:
binwalk firmware.bin
输出示例:
OFFSET TYPE DESCRIPTION
0 HEADER TRX firmware header, size = 4194304 bytes
16 HEADER LZMA compressed data, compressed size = 393216 bytes
264192 FILESYSTEM Squashfs filesystem, big endian, block size: 128 KB
每一行输出包含三个关键字段:
- OFFSET :数据块在原始文件中的起始偏移(十进制和十六进制);
- TYPE :识别出的数据类型;
- DESCRIPTION :详细说明,可能包含压缩方式、endianness、版本号等元信息。
该模式的优势在于速度快、误报率低,特别适合初次接触未知固件时的“侦察”阶段。然而,它也有局限性:无法识别无明确头部的加密封装或经过混淆处理的数据段。为此, binwalk 提供了熵值分析辅助手段(见第五章),通过统计字节分布均匀性来推测潜在加密区域。
2.2.2 递归解包模式:自动展开嵌套结构的能力实现
面对现代固件中普遍存在的多层嵌套结构,仅靠一次扫描往往不足以揭示全部内容。为此, binwalk 引入了 递归解包模式 ,通过 -M 参数启用,能够在发现可提取对象后自动将其解压,并对解压后的子文件再次执行扫描,直至无法继续分解为止。
启用递归解包的命令如下:
binwalk -Me firmware.bin
其中:
- -M 表示启用递归模式;
- -e 表示执行提取操作。
执行过程如下:
1. 扫描原始文件,识别出第一个可提取项(如 SquashFS);
2. 使用 unsquashfs 工具将其解压至 _firmware.bin.extracted/squashfs-root/ ;
3. 对解压出的所有子文件重新调用 binwalk 进行二次扫描;
4. 若子文件中仍存在嵌套结构(如另一个 gzip 包裹的脚本),则继续提取;
5. 循环往复,直到所有层级都被展开。
该模式极大简化了手动逐层解包的工作负担,尤其适用于结构复杂的路由器或摄像头固件。
以下是一个递归解包后的目录结构示例:
_firmware.bin.extracted/
├── squashfs-root/
│ ├── bin/
│ ├── sbin/
│ └── etc/
├── 264192.squashfs
├── 16.lzma
└── _16.lzma.extracted/
└── vmlinux
可以看到, binwalk 不仅完成了提取,还保留了原始偏移命名,便于追溯来源。
2.2.3 差分分析模式:多镜像对比检测隐藏变更
在固件更新分析或恶意代码植入检测中,经常需要比较两个相似但略有差异的镜像文件,以发现微小改动。 binwalk 提供了内置的差分分析功能,可通过 -W 参数实现两文件间的字节级对比。
使用示例:
binwalk -W firmware_v1.bin firmware_v2.bin
输出将仅显示两者不一致的区域:
DIFF OFFSET SIZE DESCRIPTION
0x1A2F00 0x4000 Added new configuration blob
0x2C0000 0x1000 Modified U-Boot environment block
该功能常用于:
- 检测厂商更新中新增的后门组件;
- 分析 OTA 升级包中的变更点;
- 发现固件克隆设备中的篡改痕迹。
差分分析依赖于精确的对齐机制,因此建议在比较前确保两镜像具有相同的起始偏移和分区布局。必要时可结合 dd 截取特定区间后再进行比对。
2.3 实战初探:固件镜像的初步解析
2.3.1 使用默认配置执行基本扫描
以某常见家用路由器固件为例,执行最基本的 binwalk 扫描命令:
binwalk router_firmware.bin
输出如下:
DECIMAL HEX DESCRIPTION
0 0x0 TP-Link firmware header
16 0x10 gzip compressed data, max compression
262160 0x40010 Squashfs filesystem, little endian, 4.0
该结果显示固件由三部分组成:厂商头部、压缩内核和只读文件系统。下一步即可针对性提取关键组件。
2.3.2 输出结果解读:偏移地址、描述信息与概率标识
binwalk 的输出并非绝对确定,某些匹配带有“概率”或“启发式”性质。例如:
1024 0x400 Possibly XOR encoded data (high entropy)
此处 “Possibly” 表明该判断基于熵值统计而非确切签名,需进一步验证。
理解输出中的术语至关重要:
- TRX Header :常见于 Broadcom 芯片设备,指示固件封装格式;
- Squashfs :轻量级只读文件系统,广泛用于嵌入式 Linux;
- CRC32 Table :常出现在固件校验区域,可用于定位完整性校验逻辑。
2.3.3 快速识别常见组件:U-Boot、Linux Kernel、SquashFS
通过观察偏移规律与描述关键词,可快速识别三大核心组件:
- U-Boot :通常位于 0x0~0x40000,描述含 “U-Boot” 或 “bootloader”;
- Kernel :紧跟其后,常标注 “Linux kernel” 或压缩类型;
- RootFS :位于末尾或中间大片连续区域,标明 “Squashfs” 或 “JFFS2”。
识别这些组件后,即可制定提取与逆向计划。
2.4 高级命令行选项配置(深度扫描、输出格式定制)
2.4.1 -D、-M、-C 等关键参数的作用与组合策略
| 参数 | 功能说明 | 典型用途 |
|---|---|---|
-D <type> |
仅扫描指定类型(如 -D png ) |
定向查找图像资源 |
-M |
启用递归解包 | 多层嵌套固件分析 |
-C <dir> |
指定提取目录 | 组织输出结构 |
组合示例:
binwalk -Me -C extracted/ firmware.bin
实现递归提取并存放到 extracted/ 目录。
2.4.2 JSON/CSV格式输出用于自动化分析流水线集成
binwalk --json firmware.bin | jq '.[] | select(.description | contains("Squashfs"))'
利用 jq 工具从 JSON 输出中筛选出文件系统条目,便于脚本化处理。
3. 签名匹配机制与内置数据库使用
在二进制分析领域,识别文件类型和结构是逆向工程的第一步。对于未经文档说明或闭源的固件镜像、嵌入式系统镜像或恶意软件样本而言,传统的文件扩展名已失去意义。此时,基于内容特征的 签名匹配机制 成为核心手段。 binwalk 正是通过其强大的签名匹配引擎,在原始字节流中快速定位已知格式的数据块,从而实现对复合型二进制文件的精准解析。本章将深入剖析 binwalk 的签名匹配原理、内置数据库组织方式,并指导如何创建和加载自定义签名以应对专有或未知数据格式。
3.1 签名文件结构与匹配原理
binwalk 的签名系统是其能够高效识别数百种文件格式的核心支撑。它不依赖于文件后缀或元信息,而是通过对目标文件进行逐字节扫描,查找预定义的“指纹”——即特定的头部字节序列、魔术数字(magic numbers)或结构化模式。这些指纹被组织成可扩展的签名规则集,支持多种匹配逻辑,包括十六进制字面量、正则表达式以及条件判断。
3.1.1 .lzm、.py 等签名脚本语法规范
binwalk 使用两种主要类型的签名文件: .lzm (Legacy Zip Magic)风格的文本签名和基于 Python 的 .py 脚本签名。虽然 .lzm 格式较为古老,但仍广泛用于简单格式;而现代版本更推荐使用 Python 编写的签名脚本,因其具备更强的表达能力和灵活性。
.lzm 文本签名示例:
# gzip compressed data, from RFC 1952
0 string \x1f\x8b gzip compressed data
该行表示:从偏移 0 开始,如果遇到字节序列 \x1f\x8b ,则标记为 “gzip compressed data”。其中字段含义如下:
| 字段 | 含义 |
|---|---|
0 |
匹配起始偏移(相对文件头) |
string |
匹配类型(可为 string , le16 , be32 等) |
\x1f\x8b |
实际要匹配的十六进制字符串 |
gzip compressed data |
描述性标签 |
Python 风格签名示例(gzip.py):
from binwalk.core.module import Module
class GzipSignature(Module):
TITLE = "GZIP Compressed Data"
SIGNATURE = "\x1f\x8b"
def scan(self, result):
if result.file and result.offset == 0:
result.description = "GZIP compressed data, last modified: unknown"
else:
result.description = "GZIP compressed data (embedded)"
上述代码定义了一个名为 GzipSignature 的类,继承自 Module ,并设置了标题与签名常量。 scan() 方法允许在匹配成功时动态生成描述信息,甚至可以调用外部函数进行进一步分析。
参数说明 :
-TITLE: 在输出中显示的模块名称。
-SIGNATURE: 必须为字符串或字节串,表示需匹配的原始字节。
-scan(result): 回调函数,接收一个Result对象,可用于修改结果描述、设置提取标志等。
这种面向对象的设计使得签名不仅能做静态匹配,还能执行上下文感知的智能判断,例如根据后续字节推断压缩时间戳或校验和是否存在。
3.1.2 十六进制模式匹配与正则表达式结合方式
为了应对复杂格式(如 PNG、JPEG), binwalk 支持更高级的匹配语法,允许在签名中嵌入正则表达式或通配符。
示例:PNG 文件签名(png.py)
import re
from binwalk.core.module import Module
class PNGSignature(Module):
TITLE = "PNG Image"
# PNG header + IHDR chunk
PATTERN = re.compile(b'\x89PNG\r\n\x1a\n' +
b'\x00{4}\x49\x48\x44\x52')
def init(self):
self.result.description = "PNG image data"
self.regex = self.PATTERN
这里使用了 re.compile() 构造一个正则表达式模式,精确匹配 PNG 文件头( \x89PNG\r\n\x1a\n )后紧跟一个长度为4字节的块大小字段( \x00{4} )和 IHDR 标志。
混合匹配语法支持:
| 语法形式 | 示例 | 用途 |
|---|---|---|
\xNN |
\x1f\x8b |
匹配固定字节 |
. |
.\x48\x65\x6c\x6c\x6f |
任意单字节占位符 |
{n} |
\x00{4} |
重复前一字符 n 次 |
(?:...) |
(?:\x47\x49\x46|\x89\x50\x4e\x47) |
分组非捕获匹配 |
此外, binwalk 还支持“跳转匹配”,即先匹配一个头部,再跳转到指定偏移处验证另一特征。这在分析分层协议或容器格式时尤为有用。
# 示例:检查 ELF 文件是否包含 .rodata 节区
def scan(self, result):
if result.data.startswith(b'\x7fELF'):
# 计算程序头表位置(e_phoff)
phoff = struct.unpack_from('<I', result.data, 0x1c)[0]
phentsize = struct.unpack_from('<H', result.data, 0x20)[0]
num_ph = struct.unpack_from('<H', result.data, 0x22)[0]
for i in range(num_ph):
p_type = struct.unpack_from('<I', result.data, phoff + i*phentsize)[0]
if p_type == 1: # PT_LOAD
result.add_description("Contains loadable segment")
逻辑分析 :此代码不仅检测 ELF 头部,还解析其程序头表(Program Header Table),确认是否存在可加载段。这是典型的“深度签名”应用,超越了简单的魔术字节匹配。
3.1.3 匹配优先级与冲突解决机制
当多个签名同时命中同一偏移时, binwalk 必须决定哪一个应被报告。为此,系统引入了一套 优先级排序机制 。
匹配优先级规则如下:
- 精确度优先 :匹配长度越长、约束越多的签名优先级越高。
- 偏移限定性 :仅在固定偏移(如 offset=0)有效的签名优于通配偏移。
- 显式权重设置 :可通过
PRIORITY属性手动设定优先级值。 - 排他性声明 :某些签名可声明“独占”某区域(如整个文件),阻止其他匹配。
class BootloaderSignature(Module):
TITLE = "U-Boot Image"
SIGNATURE = b'#$%&'
PRIORITY = 100 # 高优先级
EXCLUSIVE = True # 排他性匹配
在此例中,即使其他签名也在相同位置匹配成功,只要 BootloaderSignature 命中,其余结果将被抑制。
冲突处理流程图(Mermaid)
graph TD
A[开始扫描] --> B{找到匹配?}
B -- 是 --> C[加入候选列表]
B -- 否 --> D[继续扫描下一字节]
C --> E{是否已有同偏移匹配?}
E -- 否 --> F[直接添加]
E -- 是 --> G[比较优先级]
G --> H{新匹配优先级更高?}
H -- 是 --> I[替换旧匹配]
H -- 否 --> J[保留原匹配]
I --> K[更新结果]
J --> L[丢弃新匹配]
K --> M[继续扫描]
L --> M
该流程确保最终输出的结果是最具代表性和准确性的识别结论,避免冗余或错误信息干扰分析者判断。
3.2 内置数据库管理与维护
binwalk 的强大之处不仅在于其算法设计,更在于其庞大的内置签名数据库。这个数据库由社区长期积累而成,覆盖了从通用压缩格式到嵌入式专用分区的广泛范围。理解其组织结构有助于高效利用现有资源,并为后续自定义扩展提供基础。
3.2.1 signatures 目录结构与分类组织原则
安装 binwalk 后,其签名文件通常位于 /usr/share/binwalk/signatures/ 或 Python 安装路径下的 site-packages/binwalk/signatures/ 。目录采用清晰的层级划分:
signatures/
├── archive/ # 归档格式(tar, zip, rar)
├── audio/ # 音频文件(mp3, wav)
├── compressed/ # 压缩数据(gzip, lzma)
├── firmware/ # 固件相关(uimage, trx)
├── image/ # 图像格式(png, jpg, bmp)
├── video/ # 视频格式(avi, mp4)
└── filesystem/ # 文件系统(squashfs, ext2, jffs2)
每个子目录下存放对应类型的 .py 或 .lzm 文件。例如:
compressed/gzip.pyfilesystem/squashfs.lzmfirmware/uimage.py
这种分类策略便于维护和检索,也方便用户按需加载特定类别签名(通过 -y 参数过滤)。
加载过程简析:
binwalk -B firmware.bin
执行时, binwalk 默认会遍历所有签名文件,构建一个全局匹配引擎。若使用 -y "gzip|png" ,则只加载匹配关键词的签名,提升效率。
3.2.2 常见文件格式签名条目剖析:gzip、PNG、JPEG、RAR
下面选取四种典型格式,解析其签名实现细节。
1. gzip 签名(compressed/gzip.py)
SIGNATURE = b"\x1f\x8b"
METHOD_DEFLATE = 8
def scan(self, result):
if len(result.file.bytes) < 10:
return
method = result.file.bytes[2]
if method != METHOD_DEFLATE:
result.valid = False
return
flags = result.file.bytes[3]
mtime = struct.unpack("<I", result.file.bytes[4:8])[0]
description = f"gzip compressed data, method={method}, time={mtime}"
result.description = description
逻辑分析 :
- 第2字节为压缩方法,标准 deflate 应为8;
- 第3字节为标志位(如是否有文件名);
- 第4~7字节为 Unix 时间戳;
- 若方法非 deflate,则判定为误报,设valid=False抑制输出。
2. PNG 签名(image/png.py)
PATTERN = re.compile(
b'\x89PNG\r\n\x1a\n' # PNG header
b'\x00{4}' # Chunk length
b'IHDR' # First chunk
)
PNG 文件必须以 IHDR 作为首个数据块,因此该签名极具辨识度。
3. JPEG 签名(image/jpeg.py)
START_MARKER = b'\xff\xd8'
END_MARKER = b'\xff\xd9'
def scan(self, result):
if result.data.startswith(START_MARKER):
result.description = "JPEG image data"
# 可选:搜索结束标记以估算大小
end_pos = result.data.find(END_MARKER)
if end_pos != -1:
result.size = end_pos + 2
JPEG 是变长格式,故签名常尝试估算完整图像尺寸,便于后续提取。
4. RAR 签名(archive/rar.py)
RAR_ID = b'Rar!\x1a\x07\x00'
NEW_RAR_ID = b'Rar!\x1a\x07\x01\x00'
def scan(self, result):
data = result.file.bytes
if data.startswith(RAR_ID) or data.startswith(NEW_RAR_ID):
version = 1 if data[5] == 0 else 2
result.description = f"RAR archive, v{version}"
RAR 有两种版本标识,分别对应旧版与新版格式,签名需兼容两者。
3.2.3 版本更新与社区贡献机制
binwalk 的签名库托管于 GitHub(https://github.com/ReFirmLabs/binwalk),采用开源协作模式。任何开发者均可提交 Pull Request 添加新签名或修复错误。
贡献流程:
- Fork 仓库;
- 在对应目录新建
.py文件; - 编写签名逻辑并测试;
- 提交 PR 并附带样本哈希(建议脱敏);
- 维护者审核合并。
社区最佳实践:
- 不要硬编码敏感样本;
- 尽量使用
PATTERN或SIGNATURE显式声明; - 提供
scan()方法增强描述能力; - 避免过度匹配(如仅凭几个常见字节就断言格式);
定期运行 binwalk --update 可同步最新签名数据库,确保对新型固件格式的支持。
3.3 自定义签名文件创建与加载
面对厂商私有格式或加密封装结构,标准签名往往无法识别。此时,编写 自定义签名 成为必要技能。这不仅能提升分析效率,还可用于自动化检测特定设备固件。
3.3.1 编写针对专有格式的新签名规则
假设某 IoT 设备使用一种名为 MyFS 的私有文件系统,其头部结构如下:
| 偏移 | 长度 | 内容 |
|---|---|---|
| 0x00 | 4 | 魔术字: MYSF (ASCII) |
| 0x04 | 4 | 版本号(小端) |
| 0x08 | 4 | 总块数 |
| 0x0c | 4 | 块大小 |
我们可编写如下签名文件 myfs.py :
from binwalk.core.module import Module
import struct
class MyFSSignature(Module):
TITLE = "MyFS File System"
SIGNATURE = "MYSF"
def scan(self, result):
if not result.file or len(result.file.bytes) < 16:
return
version = struct.unpack('<I', result.file.bytes[4:8])[0]
block_count = struct.unpack('<I', result.file.bytes[8:12])[0]
block_size = struct.unpack('<I', result.file.bytes[12:16])[0]
total_size = block_count * block_size
result.description = (
f"MyFS v{version}, {block_count} blocks "
f"of {block_size} bytes each (total ~{total_size} B)"
)
result.size = total_size # 用于提取
参数说明 :
-struct.unpack('<I', ...):从小端序解包无符号整数;
-result.size:告知binwalk此数据块的实际长度,以便正确提取;
-result.description:动态生成人性化描述。
保存至本地目录后,即可通过 -A 参数加载:
binwalk -A ./myfs.py firmware.bin
3.3.2 动态加载外部签名进行定向探测
有时只需临时测试某个签名,无需永久安装。 binwalk 支持运行时加载:
binwalk --signature=./custom_signatures/ proprietary_device.bin
或批量加载整个目录:
binwalk -A ./signatures/ -y "MyFS|CustomBoot" target.bin
配合 -y (include)和 -x (exclude)可实现精细化控制。
3.3.3 实例:识别私有加密头或厂商特有分区表
考虑某路由器固件中的加密分区,其头部包含:
- 魔术字:
ENC\0(\x45\x4E\x43\x00) - 密钥ID:1字节(0x01~0x0A 表示不同密钥)
- 加密算法标识:
AES-CBC或XOR-128
编写签名如下:
class EncryptedPartition(Module):
TITLE = "Encrypted Partition"
SIGNATURE = b'\x45\x4E\x43\x00'
ALGO_MAP = {
0x01: 'AES-CBC with Key #1',
0x02: 'AES-CBC with Key #2',
0x03: 'XOR-128 Stream Cipher'
}
def scan(self, result):
if len(result.file.bytes) < 6:
return
key_id = result.file.bytes[4]
algo_desc = self.ALGO_MAP.get(key_id, 'Unknown algorithm')
result.description = f"Encrypted partition, {algo_desc}"
result.encrypted = True # 标记为加密内容
逻辑分析 :
- 利用key_id推断可能使用的解密方式;
- 设置result.encrypted = True可触发后续 XOR 分析模块;
- 输出信息可直接指导下一步解密操作。
该签名可在未授权固件审计中快速定位加密区域,提高漏洞挖掘效率。
3.4 模板块分析与固件结构探测
签名不仅是识别工具,更是理解固件整体架构的钥匙。通过观察签名出现的 顺序、间距与依赖关系 ,可逆向推导出固件的布局规划。
3.4.1 利用签名序列推断固件整体布局
典型嵌入式固件结构如下:
Offset Content
0x000000 Bootloader (U-Boot)
0x010000 Environment Variables
0x020000 Linux Kernel (zImage, compressed)
0x200000 RootFS (SquashFS)
0x700000 Configuration Partition
执行 binwalk firmware.bin 得到输出:
DECIMAL HEX DESCRIPTION
0 0x0 uImage header, header size: 64 ...
64 0x40 U-Boot boot loader, ...
131072 0x20000 Linux kernel ARM32 4.x ...
2097152 0x200000 Squashfs filesystem, little endian ...
通过分析各组件偏移,可绘制出如下结构图:
graph LR
A[0x000000] -->|U-Boot| B[0x20000]
B -->|Kernel| C[0x200000]
C -->|RootFS| D[End of Image]
此图揭示了启动流程:先加载 bootloader,再跳转至内核入口,最后挂载根文件系统。
3.4.2 关键模块边界确定与依赖关系分析
进一步地,可借助签名长度估算各模块占用空间:
| 模块 | 起始偏移 | 结束偏移(估算) | 大小 |
|---|---|---|---|
| U-Boot | 0x0 | 0x1FFFF | ~128KB |
| Kernel | 0x20000 | 0x1FFFFF | ~1.8MB |
| RootFS | 0x200000 | 0x6FFFFF | ~5MB |
这些信息可用于:
- 精确提取某一模块( dd if=firmware.bin of=kernel.bin skip=131072 count=1966080 );
- 判断是否存在冗余填充或隐藏分区;
- 分析升级包差异(结合差分模式);
此外,若发现 SquashFS 出现在 Kernel 之前,可能意味着 dual-bank flash 设计或 recovery 分区存在。
综上所述,签名匹配不仅是“找文件”,更是“读设计”。掌握这一能力,意味着掌握了打开闭源世界的万能钥匙。
4. 多格式解压功能(gzip/bzip2/lzma/7z等)实战
在嵌入式系统与固件逆向工程领域,压缩数据的识别与还原是实现深层次分析的关键前置步骤。大多数现代设备固件为了节省存储空间和加快传输效率,通常会将内核、根文件系统、配置分区等关键组件进行不同程度的压缩处理,常见的包括 gzip 、 bzip2 、 LZMA 、 7-Zip 等算法。这些压缩单元往往以非标准封装形式嵌入二进制镜像中,无法通过常规解压工具直接打开。binwalk 的核心优势之一便是其强大的多格式自动识别与递归解压能力,能够在不依赖文件扩展名的前提下,基于签名特征精准定位并提取出隐藏的压缩内容。
本章将深入剖析 binwalk 内建提取引擎的工作机制,结合真实固件样本,展示如何高效地对多种压缩格式进行识别、剥离与验证,并探讨在面对复杂嵌套结构时的应对策略。此外,还将演示如何将 binwalk 与其他底层分析工具如 strings 、 hexdump 和 objdump 联动使用,构建完整的自动化解析流水线,提升逆向效率与准确性。整个过程不仅涉及命令行操作细节,还包括底层逻辑推理与异常调试技巧,适合具备一定逆向基础的技术人员深入掌握。
4.1 内建提取引擎工作机制
binwalk 的提取功能并非简单调用外部解压程序,而是通过一个高度模块化的“提取器”(extractor)架构,实现了对多种压缩格式的安全、可控、可扩展的支持。该机制建立在签名扫描的基础之上,当 binwalk 检测到某段数据符合特定压缩格式的头部特征后,便会触发相应的提取动作,尝试将其解包为原始数据。
4.1.1 基于签名触发的自动解压流程
binwalk 使用一组预定义的签名规则来识别压缩数据。每条规则包含格式名称、起始字节模式(十六进制)、是否支持提取以及对应的提取命令。例如,gzip 格式的签名如下所示:
# signatures/compression/gzip.lzm
"gz": {
"header": b"\x1f\x8b\x08",
"offset": 0,
"extract": "gunzip -c %e > %f"
}
上述代码定义了一个名为 "gz" 的签名条目:
- "header" 表示该格式的前三个固定字节;
- "offset" 指明从匹配位置开始读取数据的偏移量;
- "extract" 字段指定了执行提取时所使用的 shell 命令模板。
当 binwalk 扫描到 \x1f\x8b\x08 字节序列时,即认为发现 gzip 数据流。随后,它会根据当前上下文构造实际命令,比如:
gunzip -c /tmp/tmp_binwalk_abcde.gz > _firmware.extracted/squashfs-root/bin/sh
这里的 %e 替换为临时压缩文件路径, %f 替换为目标输出路径。整个过程由 binwalk 自动调度完成,无需用户手动干预。
逻辑分析说明 :这种基于模板的提取方式极大增强了灵活性。开发者可以自定义任意格式的提取逻辑,甚至集成 Python 脚本或专用工具链。同时,由于所有提取操作均运行在隔离环境中(默认使用临时目录),有效避免了潜在的安全风险,防止恶意构造的压缩包执行任意代码。
4.1.2 解压后数据的临时存储与命名规则
binwalk 在执行 -e 或 --extract 选项时,会创建一个名为 _firmware.extracted 的输出目录(可通过 -C 指定自定义路径)。在此目录下,所有成功提取的内容将按照原始偏移地址命名子目录或文件,结构清晰且便于追溯。
例如,若在偏移 0x100000 处发现一个 SquashFS 文件系统,则可能生成如下路径:
_firmware.extracted/
└── 100000.squashfs/
├── etc/
├── bin/
└── proc/
对于嵌套压缩结构(如 .tar.gz 再打包进固件),binwalk 支持递归展开,默认最多 8 层深度。每一层都会被赋予唯一的路径标识,确保不会发生覆盖冲突。
| 提取层级 | 默认最大限制 | 是否可配置 | 典型用途 |
|---|---|---|---|
| Level 1 | 8 | 是 ( -M ) |
固件 → Kernel + RootFS |
| Level 2 | 8 | 是 | RootFS 中嵌套 tar.gz |
| Level 3+ | 依配置而定 | 是 | 深度混淆样本 |
此外,binwalk 还提供 -J 参数用于跳过已知不可提取的条目(如 JPEG 图像头误判为压缩包),减少冗余操作。
4.1.3 支持的压缩算法列表及兼容性说明
binwalk 内置支持超过 30 种压缩与归档格式,涵盖主流嵌入式平台常用类型。以下是部分关键格式及其依赖工具:
graph TD
A[输入固件镜像] --> B{检测头部签名}
B --> C[gzip]
B --> D[bzip2]
B --> E[LZMA]
B --> F[7-Zip]
B --> G[Tar]
B --> H[CramFS]
C --> I[调用 gunzip]
D --> J[调用 bunzip2]
E --> K[调用 unlzma / xz]
F --> L[调用 7z x]
G --> M[调用 tar xf]
H --> N[调用 unsquashfs 或 cramfsswap]
style C fill:#e6f3ff,stroke:#0066cc
style D fill:#e6f3ff,stroke:#0066cc
style E fill:#e6f3ff,stroke:#0066cc
图表说明 :上图为 binwalk 提取流程的状态转换图,展示了从输入镜像到最终解压完成的主要分支路径。每个节点代表一种压缩格式,边表示调用的外部工具。颜色高亮部分为最常见于嵌入式系统的三大压缩算法。
| 压缩格式 | 头部签名(Hex) | 所需工具 | 可提取性 | 应用场景 |
|---|---|---|---|---|
| gzip | 1F 8B 08 |
gunzip | ✅ | Linux 内核、initramfs |
| bzip2 | 42 5A 68 (BZh) |
bunzip2 | ✅ | 大型根文件系统 |
| LZMA | 5D 00 00 80 00 |
xz / unlzma | ✅ | OpenWRT 固件 |
| 7z | 37 7A BC AF 27 1C |
7z | ✅ | 私有打包方案 |
| XZ | FD 37 7A 58 5A |
xz | ✅ | 新型嵌入式系统 |
| Zlib | 78 9C or 78 DA |
Python zlib | ⚠️ 需脚本 | 协议载荷、内存转储 |
参数说明与扩展讨论 :
- 对于 zlib 流,虽然没有标准容器封装,但 binwalk 可通过自定义插件调用 Python 的zlib.decompress()函数进行尝试性还原。
- 若目标环境中缺少必要工具(如无7z命令),提取将失败。此时应提前安装p7zip-full包以确保完整性。
- 所有提取行为均可通过--list查看支持格式清单,或查阅magic/目录下的 MIME 类型定义。
综上所述,binwalk 的提取引擎本质上是一个“智能分发系统”,它将签名识别结果映射到具体的解压命令,借助外部工具链完成实质性还原工作。这一设计既保证了广泛兼容性,又保持了轻量化特性,是嵌入式逆向工程不可或缺的一环。
4.2 典型压缩格式识别与处理实例
在真实固件分析过程中,不同厂商采用的压缩策略差异较大。以下通过三个典型场景,详细演示 binwalk 如何识别并提取 gzip、bzip2 和 LZMA/7z 格式的数据。
4.2.1 gzip 压缩内核镜像的提取与验证
许多 MIPS 架构路由器固件中的 Linux 内核采用 gzip 压缩,位于镜像开头附近。假设我们有一个名为 firmware.bin 的样本:
binwalk firmware.bin
输出片段如下:
DECIMAL HEXADECIMAL DESCRIPTION
0 0x0 TRX firmware header, size = 4194304
16 0x10 gzip compressed data, last modified: 2020-05-10 12:34:56 UTC
此处显示在偏移 0x10 处存在 gzip 数据。为进一步提取,执行:
binwalk -e firmware.bin
binwalk 将自动调用 gunzip 解压该区域,生成 _firmware.extracted/10.zlib 文件(注意:有时误标为 zlib,实为 gzip 流)。接着可用 file 命令验证:
file _firmware.extracted/10.zlib
# 输出:Linux kernel ARM boot executable zImage
逐行代码解读 :
-binwalk -e启用提取模式;
- 工具查找匹配签名并调用注册的提取命令;
- 输出文件保留原始偏移命名,便于追踪来源;
- 最终产物为未压缩的可启动内核镜像,可用于后续反汇编分析。
4.2.2 bzip2 压缩根文件系统的恢复操作
某些高端设备使用 bzip2 压缩整个根文件系统以获得更高压缩率。检测方法相同:
binwalk -y bzip2 firmware.bin
其中 -y bzip2 表示仅扫描 bzip2 类型。若发现结果:
1048576 0x100000 bzip2 compressed data, block size = 900k
则可通过递归提取获取完整文件树:
binwalk -Me firmware.bin
参数说明 :
--M表示启用递归解包;
--e触发提取;
- 组合使用可穿透多层包装。
完成后查看 _firmware.extracted/100000.bz2 目录,通常包含 /etc/passwd 、 /bin/sh 等标准 Unix 文件,确认提取成功。
4.2.3 lzma 与 7z 在私有固件中的应用案例
一些工业控制设备使用 LZMA 或 7z 封装升级包。这类格式具有较强的抗分析能力,常用于保护专有逻辑。
示例命令:
binwalk --signature --extract private_update.dat
若输出包含:
512 0x200 LZMA compressed data
且提取失败,可能是缺少 xz 工具。安装后重试:
sudo apt install xz-utils
binwalk -e private_update.dat
成功后可在提取目录中看到 XML 配置文件或 Lua 脚本,揭示内部通信协议。
逻辑延伸 :此类格式常伴随加密层。建议结合 entropy 分析判断是否存在 XOR 或 AES 加密前缀,进一步使用
--xor模块破解。
4.3 复合嵌套结构的逐层剥离
现实世界中的固件往往层层包裹,形成“俄罗斯套娃”式结构。正确拆解需策略性运用递归与人工干预相结合的方法。
4.3.1 多重压缩包裹下的数据还原策略
典型结构示例:
[Outer TRX]
→ [Inner gzip]
→ [SquashFS]
→ [tar.gz in /opt/app]
→ [binary encrypted with XOR]
应对策略:
1. 使用 binwalk -Mre 一次性展开前四层;
2. 对剩余加密段进行熵值分析;
3. 编写脚本批量测试单字节 XOR 密钥;
4. 成功解密后再运行 binwalk 二次扫描。
4.3.2 使用-M 参数实现递归解包
binwalk -M -d 8 -e firmware.bin
-M: 启用递归模式;-d 8: 设置最大递归深度为 8;-e: 执行提取。
此命令将自动探测并解压所有可识别的嵌套内容,直到无法继续为止。
4.3.3 提取失败时的调试技巧与补救措施
常见问题及解决方案:
| 问题现象 | 可能原因 | 解决方法 |
|---|---|---|
| “Failed to extract” | 缺少外部工具 | 安装对应软件包(如 p7zip) |
| 解压后文件为空 | 头部损坏或非完整流 | 手动截取数据段并用 dd + gunzip 测试 |
| 误识别导致错误提取 | 签名冲突 | 使用 -I 忽略特定类型 |
| 提取卡死或内存溢出 | 深度过大或无限循环 | 降低 -d 值,逐步排查 |
推荐调试流程:
# 1. 先仅扫描
binwalk firmware.bin
# 2. 手动提取可疑段
dd if=firmware.bin bs=1 skip=$((0x100000)) count=1048576 | gunzip > test_kernel
# 3. 验证是否成功
file test_kernel
4.4 binwalk与hexdump、strings、objdump等工具联动分析
单一工具难以覆盖全部分析需求。结合其他经典命令行工具可显著增强洞察力。
4.4.1 结合strings提取潜在敏感信息
strings _firmware.extracted/100000.squashfs/etc/config/system.cfg
常能发现硬编码密码、API 密钥、调试接口 URL 等敏感内容。
4.4.2 利用objdump反汇编可执行段代码
对提取出的二进制程序进行反汇编:
arm-linux-gnueabi-objdump -D -m arm _firmware.extracted/bin/httpd > httpd.asm
有助于理解服务启动逻辑、认证绕过点等漏洞线索。
4.4.3 hexdump辅助手工验证binwalk输出准确性
当怀疑 binwalk 错误识别时,可用 hexdump 手动检查:
hexdump -C firmware.bin | grep "1f 8b"
定位 gzip 头部是否存在,排除伪匹配。
综合来看,binwalk 的多格式解压功能不仅是自动化逆向的起点,更是连接静态分析与动态调试的桥梁。熟练掌握其工作机制与协作生态,是从事高级固件安全研究的必备技能。
5. XOR及简单加密数据的识别与解密
5.1 加密数据的特征分析与检测方法
在嵌入式系统、固件镜像以及恶意软件样本中,开发者或攻击者常使用简单的加密手段(如XOR加密)对关键数据进行混淆,以规避静态扫描和自动化分析。这类加密虽不具备现代密码学强度,但足以干扰常规工具的识别能力。因此,掌握其识别与破译技术是逆向工程中的重要一环。
5.1.1 高熵区域识别与加密内容推测
加密或高度压缩的数据通常表现出接近随机的字节分布,这可通过 信息熵 (Shannon Entropy)量化。binwalk内置熵分析模块,可生成可视化熵图谱:
binwalk -E firmware.bin
该命令输出如下格式的熵值数据表(每行代表一个固定大小块的熵值):
| Offset (hex) | Entropy |
|---|---|
| 0x000000 | 0.23 |
| 0x001000 | 0.89 |
| 0x002000 | 0.94 |
| 0x003000 | 0.96 |
| 0x004000 | 0.12 |
| 0x005000 | 0.95 |
| 0x006000 | 0.93 |
| 0x007000 | 0.97 |
| 0x008000 | 0.05 |
| 0x009000 | 0.96 |
| 0x00A000 | 0.94 |
高熵段(>0.9)往往对应加密或压缩数据。结合签名扫描结果,若某高熵区无任何已知文件头匹配,则极可能是异或加密内容。
5.1.2 固定密钥XOR模式的统计学破译思路
单字节XOR是最常见的轻量级混淆方式:每个明文字节与同一密钥字节异或。由于ASCII文本具有明显分布特征(如空格0x20高频出现),可通过 频率分析 推断密钥。
假设一段加密数据中最多频字节为 0x7B ,而预期最常见字符为空格 0x20 ,则候选密钥为:
key = 0x7B ^ 0x20 = 0x5B ('[')
尝试用此密钥解密后查看是否生成可读字符串。
5.1.3 连续异或流的周期性检测算法
多字节XOR(如4字节密钥循环使用)会产生周期性模式。binwalk通过 差分分析 探测此类结构:
def detect_xor_period(data, max_keylen=16):
for keylen in range(1, max_keylen+1):
matches = 0
for i in range(keylen, len(data)-keylen, keylen):
if data[i:i+keylen] == data[i+keylen:i+2*keylen]:
matches += 1
if matches > threshold:
return keylen
return None
该逻辑已被集成进 binwalk 的 --signature 扫描模式中,能自动标记疑似 XOR 加密区。
5.2 XOR破解模块使用实践
5.2.1 –xor选项启用与密钥空间枚举
binwalk 提供 --xor 参数用于暴力枚举单字节 XOR 密钥:
binwalk --xor firmware.bin
此命令会对所有未识别的高熵区域尝试 0x00–0xFF 共 256 种密钥,并输出可能生成有效文件头的结果。
5.2.2 自动化尝试单字节密钥并生成候选输出
执行上述命令后,binwalk 将创建 firmware.bin-xor-* 目录,存放各密钥解密后的候选文件。例如:
firmware.bin-xor-4A/
├── 0x00001000.gz
├── 0x00002000.squashfs
└── ...
随后可用 -B (启用二进制签名扫描)进一步验证输出质量:
binwalk -B firmware.bin-xor-4A/0x00001000.gz
若发现 gzip 头 1F 8B 或 SquashFS 标志 hsqs ,说明解密成功。
5.2.3 结合entropy图谱判断解密成功可能性
利用以下流程图辅助决策:
graph TD
A[原始镜像] --> B{执行 binwalk -E}
B --> C[绘制熵图]
C --> D[定位高熵低签名区]
D --> E[运行 --xor 枚举]
E --> F[生成候选解密文件]
F --> G[对输出再扫描签名]
G --> H{是否有有效结构?}
H -->|是| I[记录密钥并深入分析]
H -->|否| J[尝试多字节XOR或其它编码]
此闭环流程显著提升了解密效率。
5.3 恶意软件二进制样本分析方法
5.3.1 利用binwalk发现加壳或混淆层
许多IoT恶意软件(如Mirai变种)使用XOR保护配置字符串或C2地址。通过以下步骤提取:
# 先扫描熵值异常区
binwalk -E sample.malware
# 对可疑段尝试XOR爆破
binwalk --xor -o 0x80000 sample.malware
若在 xor-CC 输出中发现大量 URL 或 IP 地址字符串,则表明成功脱壳。
5.3.2 提取植入载荷并重建C2通信结构
解密后使用 strings 提取明文:
strings firmware.bin-xor-A3/* | grep -i "http\|port\|cmd"
典型输出示例:
http://c2.botnet.cc:8080/update
GET /task?id=%d HTTP/1.1
AES_KEY: x9fG!kL2@pQw$
CMD_PORT: 4444
这些信息可用于构建威胁情报图谱。
5.3.3 与IDA Pro、Ghidra协同完成完整逆向链条
将解密后的二进制导入 Ghidra,在 Symbol Tree 中搜索函数调用:
connect(sockfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
结合字符串引用视图(Strings Reference),快速定位 C2 连接逻辑,实现从底层解密到行为建模的全链路逆向。
5.4 binwalk在物联网设备安全审计中的综合应用
5.4.1 固件逆向工程实战流程:从镜像获取到漏洞挖掘
典型审计流程如下表所示:
| 阶段 | 工具 | 输出 |
|---|---|---|
| 镜像提取 | binwalk -D | 分离内核、文件系统 |
| 解压处理 | binwalk -e | 获得 rootfs |
| 异常检测 | binwalk -E | 发现加密配置区 |
| XOR破解 | binwalk –xor | 恢复隐藏参数 |
| 漏洞挖掘 | strings + grep | 找到硬编码凭证 |
| 权限提升 | checksec.sh | 识别不安全服务 |
例如,在某摄像头固件中通过 XOR 破解恢复出调试账户:
username: service_debug
password: Dbg@2023!_hidden
5.4.2 数字取证中隐藏数据提取技术:隐写术与冗余填充探测
某些厂商在固件末尾附加认证信息或日志,形式为:
[Padding...] XOR(Key=0x35) → {"sn":"SN12345","date":"2024-03-15"}
使用以下脚本辅助探测:
with open("firmware.bin", "rb") as f:
data = f.read()
tail = data[-512:]
for k in range(256):
decrypted = bytes(b ^ k for b in tail)
if b"sn" in decrypted and b"date" in decrypted:
print(f"Found potential JSON at key 0x{k:02X}: {decrypted.decode('latin1', errors='ignore')}")
break
5.4.3 开源组件合规性检测应用:识别未授权第三方库引用
解密后的文件系统可通过 licensescan 工具(如 FOSSology)分析许可证合规性。同时,使用 binwalk 扫描是否存在 GPL 组件(如 busybox)却未提供源码的情况,为企业安全合规提供依据。
简介:binwalk是一款功能强大的开源二进制分析工具,广泛应用于固件逆向、恶意软件分析、数字取证和开源合规性检查等领域。该工具通过签名匹配、自动解压、简单解密和模块块分析等功能,帮助用户识别并提取嵌入在二进制文件中的隐藏数据,如文件系统、压缩包和图像等。支持与反汇编工具集成,并可通过自定义签名扩展功能。本项目基于binwalk-master源码,提供完整的安装指南与使用实践,适合安全研究人员和开发人员深入掌握二进制分析核心技术。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 30
30 0
0- 0



 已为社区贡献153条内容
已为社区贡献153条内容

所有评论(0)