
嵌入式共享资源管理技术:从优先级反转到协议解决方案
本文深入探讨嵌入式实时系统中的共享资源管理问题,重点分析优先级反转现象及其解决方案。
在嵌入式实时系统中,多个任务往往需要共享有限的系统资源,如处理器、内存和外设等。当高优先级任务因低优先级任务占用共享资源而被阻塞时,就会发生优先级反转问题,严重影响系统的实时性和可靠性。本文深入探讨共享资源管理中的关键问题,重点分析优先级反转现象及其解决方案,并通过树莓派实战演示优先级继承协议(PIP)和优先级上限协议(PCP)的实现。
一、共享资源管理基础
1.1 实时系统的时间约束分类
根据时间约束的严格程度,实时系统可分为三类:
-
软实时约束:即使在时间限制D之后,结果仍然对应用程序有一定效用,但会遭受服务质量下降
-
固定时间约束:结果在时间限制D之后对应用程序失去任何有用性
-
硬实时约束:不满足时间限制可能导致灾难性失败
1.2 抢占与不可抢占调度
-
可抢占调度:操作系统以时间片为单位进行任务调度,时间片耗尽时强制暂停当前任务
-
不可抢占调度:任务一直运行直到自行放弃CPU或发生系统调用
1.3 共享资源分类
-
处理器资源管理:物理CPU和虚拟CPU的分配与调度
-
临界区资源管理:一次仅允许一个进程使用的共享资源
二、固定优先级调度算法
2.1 速率单调调度(RM)
RM调度算法采用抢占式静态优先级策略,适用于周期性任务调度。其核心思想是:周期越短的任务优先级越高。
算法特点:
-
优先级与周期成反比
-
较低优先级进程运行时,较高优先级进程可抢占
-
适合周期性任务调度
实例分析:
假设三个进程P1、P2、P3,周期分别为6、8、12,处理时间分别为1、2、4。
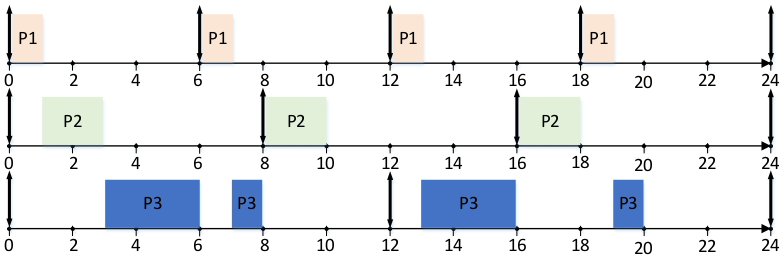
2.2 时限单调调度(DM)
DM是对RM的优化,优先级与时限(截止时间)成反比。
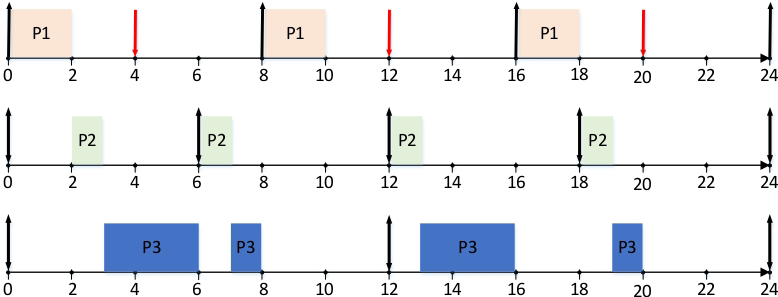
实例分析:
进程P1=(2,8,4), P2=(1,6,6), P3=(4,12,12),其中参数为(处理时间,周期,截止时间)。
三、动态优先级调度算法
3.1 最早截止时间优先(EDF)
EDF根据任务截止时间确定优先级,截止时间越早优先级越高。
实例分析:
五个进程的到达时间、处理时间和截止时间如下:
|
进程 |
到达时间 |
处理时间 |
截止时间 |
|---|---|---|---|
|
P1 |
0 |
5 |
6 |
|
P2 |
2 |
2 |
8 |
|
P3 |
8 |
6 |
20 |
|
P4 |
10 |
3 |
14 |
|
P5 |
15 |
4 |
22 |
3.2 最低松弛度优先(LLF)
LLF根据任务的紧急(松弛)程度确定优先级。松弛度计算公式为:松弛度 = 必须完成时间 - 剩余运行时间 - 当前时间
实例分析:
两个周期性任务A和B,任务A每20ms执行一次,执行时间10ms;任务B每50ms执行一次,执行时间25ms。
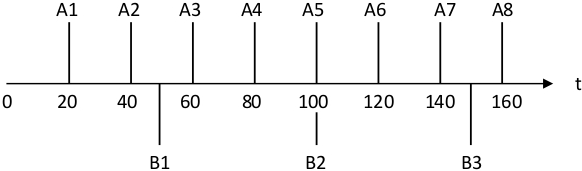
调度过程详细计算:
-
t=0s时,A1松弛度=20-10-0=10ms,B1松弛度=50-25-0=25ms,执行A1
-
A1执行后t=10ms,B1松弛度=50-25-10=15ms,A2松弛度=40-10-10=20ms,执行B1
-
t=30ms时,B1剩余5ms,松弛度=50-5-30=15ms,A2松弛度=40-10-30=0ms,执行A2
-
t=40ms时,A3松弛度=60-10-40=10ms,B1松弛度=50-5-40=5ms,执行B1
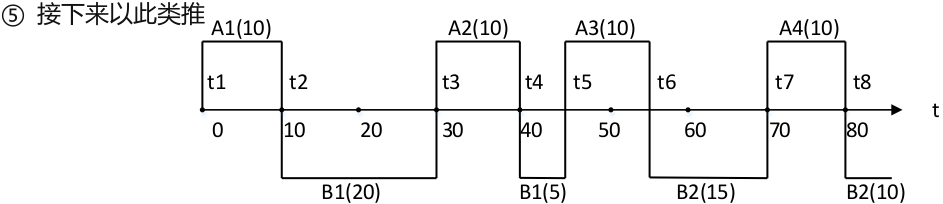
图:利用LLF算法进行调度的情况
四、优先级反转问题深度解析
4.1 优先级反转定义与成因
当一个高优先级任务被迫等待低优先级任务执行时,就会发生优先级反转。这种情况在共享临界资源时尤为常见。
典型场景:
三个任务τ₁(高优先级)、τ₂(中优先级)、τ₃(低优先级),τ₁和τ₃共享临界资源。
-
τ₃先锁定临界资源S
-
τ₁到达并请求S,被阻塞
-
τ₂到达并抢占τ₃,延长了τ₁的等待时间
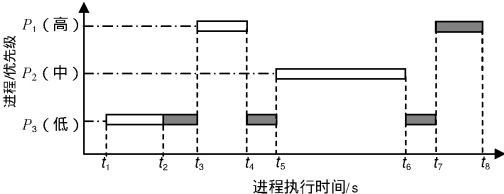
图:优先级反转
4.2 无上限优先级反转
当存在多个中等优先级任务时,每个中等优先级任务都可以重复出现并抢占临界区的最低优先级任务,导致高优先级任务遭受更严重的阻塞。
五、优先级继承协议(PIP)
5.1 PIP原理与实现
优先级继承协议的核心思想是:当低优先级任务阻塞高优先级任务时,临时继承被阻塞的最高优先级任务的优先级。
协议定义:
-
任务以其原始优先级运行,除非阻塞一个或多个高优先级任务
-
当阻塞发生时,继承被阻塞的最高优先级任务的优先级
-
退出临界区后恢复原始优先级
实例分析:
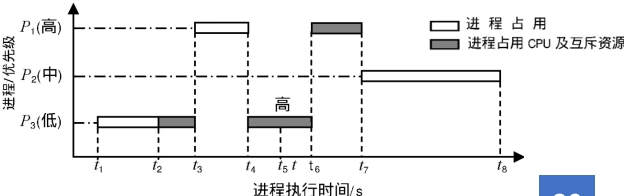
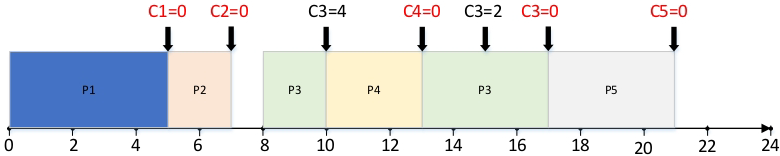
5.2 优先级反转时间上界计算
计算任务τᵢ因优先级反转导致的阻塞时间上界Bᵢ的步骤:
-
识别所有能直接或间接导致τᵢ优先级反转的(任务,临界区)二元组
-
应用约束:一个低优先级任务只能阻塞高优先级任务一次;一个任务只能被一种资源阻塞一次
-
选择导致最大阻塞时间的二元组组合
计算示例:
四个任务对三个临界区的占用时长矩阵:
|
任务 |
S1 |
S2 |
S3 |
|---|---|---|---|
|
T1 |
1 |
2 |
0 |
|
T2 |
0 |
9 |
3 |
|
T3 |
8 |
7 |
0 |
|
T4 |
6 |
5 |
4 |
阻塞时间上界计算结果:
-
T4:B₄ = 0(优先级最低)
-
T3:B₃ = max(6,5,4) = 6(选择τ₄占用S1)
-
T2:B₂ = max(8+5, 6+7) = 13
-
T1:B₁ = 9+8 = 17
5.3 PIP的局限性
-
连续阻塞问题:高优先级任务可能因多个临界区被连续阻塞
-
死锁问题:不能解决循环等待导致的死锁
六、优先级上限协议(PCP)
6.1 PCP基本原理
PCP通过引入优先级上限概念,限制并量化优先级反转的影响。
关键定义:
-
临界资源优先级上限Ⅱ(S):可以访问该资源的最高优先级任务的优先级
-
系统当前优先级上限Ⅱ'(t):时刻t正在被使用资源的优先级上限最大值
协议规则:
任务τ请求共享资源S时,如果π(τ) > Ⅱ'(t),则可以锁定资源;否则必须阻塞,此时资源占用者继承τ的优先级。
6.2 PCP优势分析
PCP保证高优先级任务所需的临界资源能且仅能被一个低优先级任务占用,从而:
-
解决连续阻塞问题
-
防止死锁发生
-
限制优先级反转时间上界为一个临界区执行时长
6.3 PIP与PCP对比
|
特性 |
PIP |
PCP |
|---|---|---|
|
优先级反转时间上界 |
大 |
小 |
|
实现难度 |
小 |
大 |
|
死锁避免 |
不支持 |
支持 |
|
最大等待临界区数 |
多个 |
一个 |
七、树莓派实战:优先级反转与解决方案
7.1 实验环境搭建
# 创建实验目录
cd /usr/local/develop && mkdir task4 && cd task4
# 编译演示程序
gcc demo_6.c -o demo_6 -lpthread7.2 优先级反转演示代码
// demo_6.c - 优先级反转演示
#define _GNU_SOURCE
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
#include <sched.h>
#define LOOP 999999999
pthread_mutex_t mutex;
void nop(void* arg) {
int i = 0; float prod = 1;
while(i < LOOP) { prod /= i; i++; }
}
// 低优先级任务
void* task_1(void* arg) {
printf("task_1 starts execution.\n");
while(pthread_mutex_trylock(&mutex) != 0) {
sleep(1);
printf("task_1 lock fail.\n");
}
printf("task_1 enters critical section.\n");
nop(arg);
printf("task_1 exits critical section.\n");
pthread_mutex_unlock(&mutex);
nop(arg);
printf("task_1 completes execution.\n");
}
// 中优先级任务
void* task_2(void* arg) {
printf("task_2 starts execution.\n");
nop(arg);
printf("task_2 completes execution.\n");
}
// 高优先级任务
void* task_3(void* arg) {
printf("task_3 starts execution.\n");
nop(arg);
while(pthread_mutex_trylock(&mutex) != 0) {
sleep(1);
printf("task_3 lock fail.\n");
}
printf("task_3 enters critical section.\n");
nop(arg);
printf("task_3 exits critical section.\n");
pthread_mutex_unlock(&mutex);
nop(arg);
printf("task_3 completes execution.\n");
}7.3 采用PIP解决优先级反转
// 设置互斥锁属性为优先级继承
pthread_mutexattr_t mattr;
pthread_mutexattr_setprotocol(&mattr, PTHREAD_PRIO_INHERIT);
pthread_mutex_init(&mutex, &mattr);运行结果对比:
-
未使用PIP:高优先级任务被中优先级任务长时间阻塞
-
使用PIP后:低优先级任务继承高优先级,尽快退出临界区
八、高级主题:自旋锁与互斥锁性能对比
8.1 自旋锁实现
// spin_lock.cpp
#include <iostream>
#include <thread>
#include <pthread.h>
#include <sys/time.h>
int num = 0;
pthread_spinlock_t spin_lock;
int64_t get_current_timestamp() {
struct timeval now = {0,0};
gettimeofday(&now, NULL);
return now.tv_sec * 1000 * 1000 + now.tv_usec;
}
void thread_proc() {
for(int i = 0; i < 1000000; ++i) {
pthread_spin_lock(&spin_lock);
++num;
pthread_spin_unlock(&spin_lock);
}
}8.2 互斥锁实现
// mutex_lock.cpp
#include <iostream>
#include <thread>
#include <pthread.h>
#include <sys/time.h>
int num = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void thread_proc() {
for(int i = 0; i < 1000000; ++i) {
pthread_mutex_lock(&mutex);
++num;
pthread_mutex_unlock(&mutex);
}
}8.3 性能对比分析
运行结果:
-
自旋锁:适合锁持有时间短的场景,避免上下文切换开销
-
互斥锁:适合锁持有时间长的场景,避免CPU资源浪费
两种锁的区别:
-
自旋锁:忙等待,持续占用CPU,无上下文切换
-
互斥锁:阻塞等待,让出CPU,有上下文切换开销
九、实际应用与最佳实践
9.1 嵌入式系统中的资源管理策略
-
临界区设计原则:
-
保持临界区尽可能短
-
避免在临界区内进行耗时操作
-
使用层次锁避免死锁
-
-
优先级配置建议:
-
根据任务关键性设置优先级
-
考虑资源依赖关系避免优先级反转
-
使用优先级天花板协议预防死锁
-
9.2 openEuler中的实时性优化
openEuler Embedded通过以下技术提升实时性能:
-
中断线程化:减少关中断时间,提高可抢占性
-
优先级继承:解决优先级反转问题
-
自旋锁优化:采用Qspinlock减少CPU资源浪费

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)