
帝国理工VLA综述:从世界模型到VLA,如何重构自动驾驶(T-ITS)
我们希望这篇发表在 T-ITS 上的顶刊综述,能为正在探索 DriveLaW、Gaia-1 等前沿技术的开发者们,提供一份扎实且前瞻的理论指南。这些模型不仅能生成逼真的驾驶视频,还能保持长时间的物理一致性(Physical Consistency),是实现“数据飞轮”的关键技术。本综述不仅是对过去两年技术爆发的总结,更是一份面向未来的路线图。的崛起——不再是简单的多模态融合,而是将视觉与语言作为协
点击下方卡片,关注“自动驾驶之心”公众号
论文作者 | Hanlin Tian, Kethan Reddy, Yuxiang Feng, Mohammed Quddus, Yiannis Demiris, Panagiotis Angeloudis
单位 | 帝国理工学院 (Imperial College London)
最近,DriveLaW、OpenDriveVLA 等架构的提出,标志着自动驾驶正在从“感知-规划”分离走向 VLA (Vision-Language-Action) 的端到端时代。与此同时,蔚来等头部玩家对世界模型 (World Models) 的押注,更是将“生成式仿真”推向了风口浪尖。
在这些 SOTA 模型层出不穷的背后,学术界如何定义这一轮技术范式的转移?如何解决大模型上车面临的 推理延迟 与 幻觉 难题?
近日,帝国理工学院(Imperial College London)智能交通系统实验室 的最新综述文章:《Large (Vision) Language Models for Autonomous Vehicles: Current Trends and Future Directions》,被智能交通领域 国际顶级期刊 IEEE T-ITS 正式录用!
该工作系统性地复盘了截止 2025年9月 的 77篇 前沿论文,从 端到端 VLA、世界模型、模块化集成 三大维度,为开发者提供了一份详尽的“大模型上车”学习路线图。
🚀 核心看点:读懂世界模型与VLA的演进
本综述精准切中了当前自动驾驶社区最关心的三大技术命题,构建了清晰的技术象限。
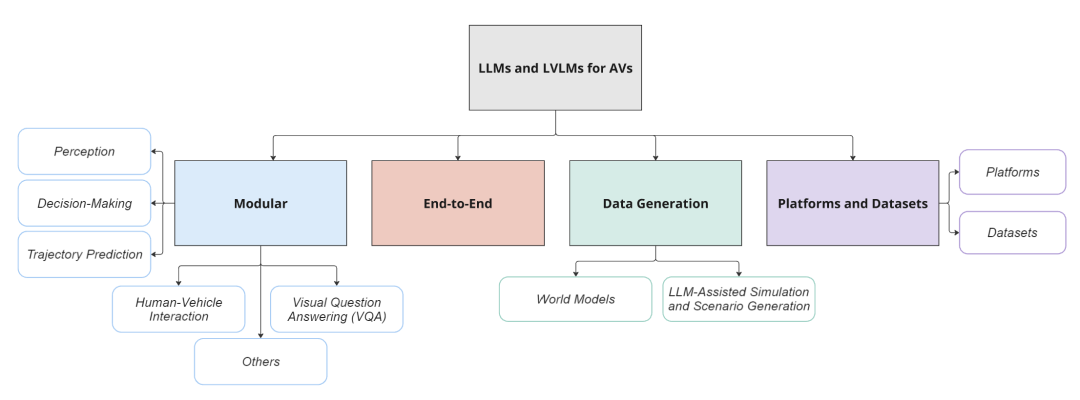
1. 端到端集成的终局:VLA (Vision-Language-Action)
当我们在讨论 DriveLaW 或 OpenDriveVLA 时,我们究竟在讨论什么?
-
趋势洞察: 论文详细分析了 VLA 设计 的崛起——不再是简单的多模态融合,而是将视觉与语言作为协同推理流,直接输出规划轨迹。
-
代表工作: 深入复盘了 LMDrive、AlphaDrive、OpenDriveVLA 等工作。这些模型展示了如何通过语言指令实现闭环控制,并利用 CoT(思维链) 解决长尾场景中的因果推理难题(例如:为什么要减速?因为前方有行人在犹豫是否过马路)。
2. 数据引擎的核心:世界模型 (World Models)
工业界押注世界模型的背后,是利用生成式 AI 解决 Corner Case 的野心。
-
高保真生成: 论文专门开辟章节探讨了基于 潜在扩散模型(Latent Diffusion Models) 的世界模型。
-
前沿案例: 重点拆解了 Gaia-1、DriveDreamer-2 以及 GenAD。这些模型不仅能生成逼真的驾驶视频,还能保持长时间的物理一致性(Physical Consistency),是实现“数据飞轮”的关键技术。
3. 模块化感知的重塑 (Modular Integration)
即便在端到端架构备受推崇的当下,模块化方案 依然在大模型加持下焕发新生:
-
语义异常检测: 论文展示了 Talk2BEV、ChatBEV 等利用 VLM 进行语义异常检测和长尾目标识别的潜力,证明了大模型在传统感知栈中同样大有可为。

⚠️ 落地挑战:直面工程痛点
不同于纯理论探讨,这篇 T-ITS 综述以工程落地的视角,冷静地指出了当前 VLM 上车面临的“三座大山”,这对于致力于量产的工程师尤为重要:
1. 推理延迟 (Latency) —— 秒级 vs 毫秒级
-
痛点: 像 DriVLMe 这样的模型推理可能需要数秒,无法满足高频控制需求。
-
解法: 论文探讨了 视觉 Token 压缩(如 Senna-VLM 的 Driving Vision Adapter)、CoT 剪枝 以及针对 NVIDIA OrinX 芯片的量化优化策略(PEFT/LoRA)。
2. 幻觉问题 (Hallucinations) —— 安全的阿喀琉斯之踵
-
痛点: VLM 可能会生成不存在的车辆,或者错误理解交通规则。
-
解法: 引入 Nullu 等“幻觉子空间投影”技术,以及基于规则的 安全过滤器(Safety Filter)。
3. 计算权衡 (Computational Trade-offs)
-
架构设计: 探讨了 “快慢系统” (Fast-Slow Architecture) —— 利用云端大模型进行长时序推理与 Corner Case 处理,配合车端小模型(或传统 Planner)进行实时高频控制。
📚 资源盘点:9大汇总表与主流数据集
为了助力社区研究,论文内含 **9 个详细的分类汇总表 (Table I-IX)**,并详细梳理了关键基础设施:
-
数据集 (Datasets): 重点分析了 NuScenes-QA、DriveLM 等专注于驾驶推理与问答的数据集,以及它们如何弥补传统感知数据集在逻辑推理上的短板。
-
仿真平台 (Platforms): 探讨了 CARLA、NuPlan 等模拟器在 VLM 闭环评测 (Closed-loop Evaluation) 中的应用,强调了从开环指标向闭环实战迁移的必要性。
🔭 未来风向:四大未解难题
论文最后指出了该领域亟待攻克的四个方向,为后续研究提供了选题参考:
-
标准化评测 (Standardized Evaluation): 建立统一的 VLA 安全性与幻觉率评分体系。
-
端侧轻量化 (Edge Deployment): 如何在有限算力(如 OrinX)上运行 7B+ 参数的大模型。
-
多模态对齐 (Multi-modal Alignment): 提升 LiDAR 点云、视觉与语言在复杂长尾场景下的语义一致性。
-
法律与伦理 (Ethics & Law): 当 VLM 做出决策时,如何进行归因与定责?
📊 结论与展望
从 模块化 到 端到端,再到 VLA 与 世界模型,大模型正在以惊人的速度重构自动驾驶的技术栈。
本综述不仅是对过去两年技术爆发的总结,更是一份面向未来的路线图。它揭示了自动驾驶正从单纯的“感知-规划”范式,向着 具备认知、推理与生成能力的通用智能体 演进。我们希望这篇发表在 T-ITS 上的顶刊综述,能为正在探索 DriveLaW、Gaia-1 等前沿技术的开发者们,提供一份扎实且前瞻的理论指南。
🔗 论文信息
论文链接:https://ieeexplore.ieee.org/document/11264491
引用格式 (BibTeX):
@ARTICLE{11264491,
author={Tian, Hanlin and Reddy, Kethan and Feng, Yuxiang and Quddus, Mohammed and Demiris, Yiannis and Angeloudis, Panagiotis},
journal={IEEE Transactions on Intelligent Transportation Systems},
title={Large (Vision) Language Models for Autonomous Vehicles: Current Trends and Future Directions},
year={2026},
volume={27},
number={1},
pages={187-210},
doi={10.1109/TITS.2025.3628969}
}
openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)