
Xiaomi MiMo-V2-Omni 发布:看得清,听得懂,能动手的全模态 Agent 基座
你说"帮我看看小米17怎么选,去小红书做做功课,选好了去京东下单,顺便砍砍价",模型就会自己打开小红书,翻十几篇帖子,提取配置对比、拍照评测、真实用户体验,给你整理出一份购买建议。一周前,MiMo-V2-Omni 以 Healer Alpha 为代号,匿名上线了全球最大的 API 聚合平台 OpenRouter,上线期间调用量持续上涨,广受用户好评。理解是基础,交付是关键。经过一周的持续迭代和优化

今天,我们发布小米面向 Agent 时代的全模态基座模型 Xiaomi MiMo-V2-Omni。
MiMo-V2-Omni 专为现实世界中复杂的多模态交互与执行场景而生。我们从底层构建了融合文本、视觉、语音的全模态基座,并以统一架构将“感知”与“行动”深度绑定。这不仅打破了传统模型“重理解、轻执行”的局限,更让模型原生具备了多模态感知、工具调用、函数执行及 GUI 操作能力。MiMo-V2-Omni 可无缝接入各种 Agent 框架,实现了从理解到操控的跨越,大幅降低了全模态 Agent 的落地门槛。
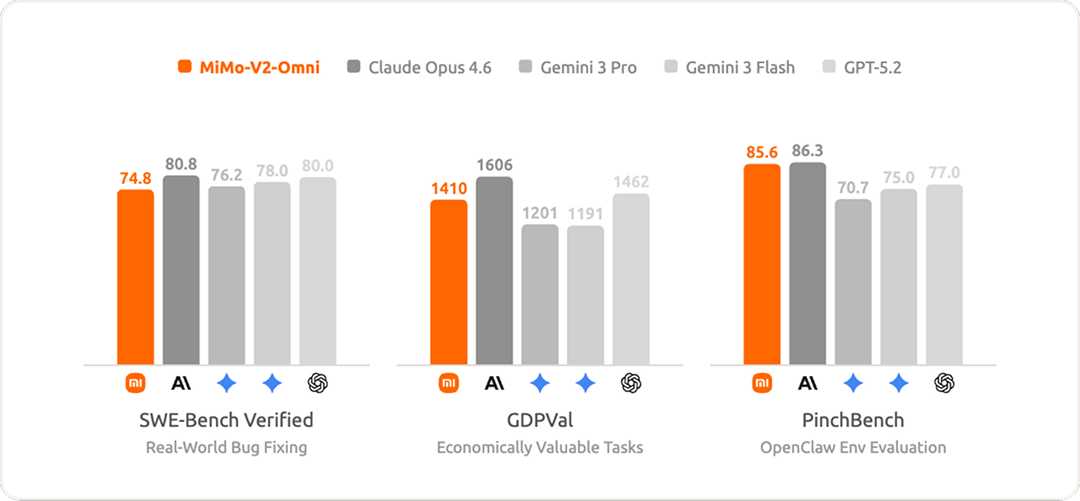
在正式发布之前,我们将一个早期测试版本以「Healer Alpha」为代号匿名上架 OpenRouter,没有任何宣传,纯粹让模型能力说话。结果调用量自然攀升至平台前列,并在 OpenClaw 测评榜单 PinchBench 上拿下均分第一,用户和基准双双给出了同一个答案。
感知能力:图像、视频、音频,全面对标前沿
精准感知和准确推理是高效执行的基石。我们在所有模态上将 MiMo-V2-Omni 与国际领先模型进行对比,充分验证了其作为新一代智能体基座的坚实感知与推理能力。
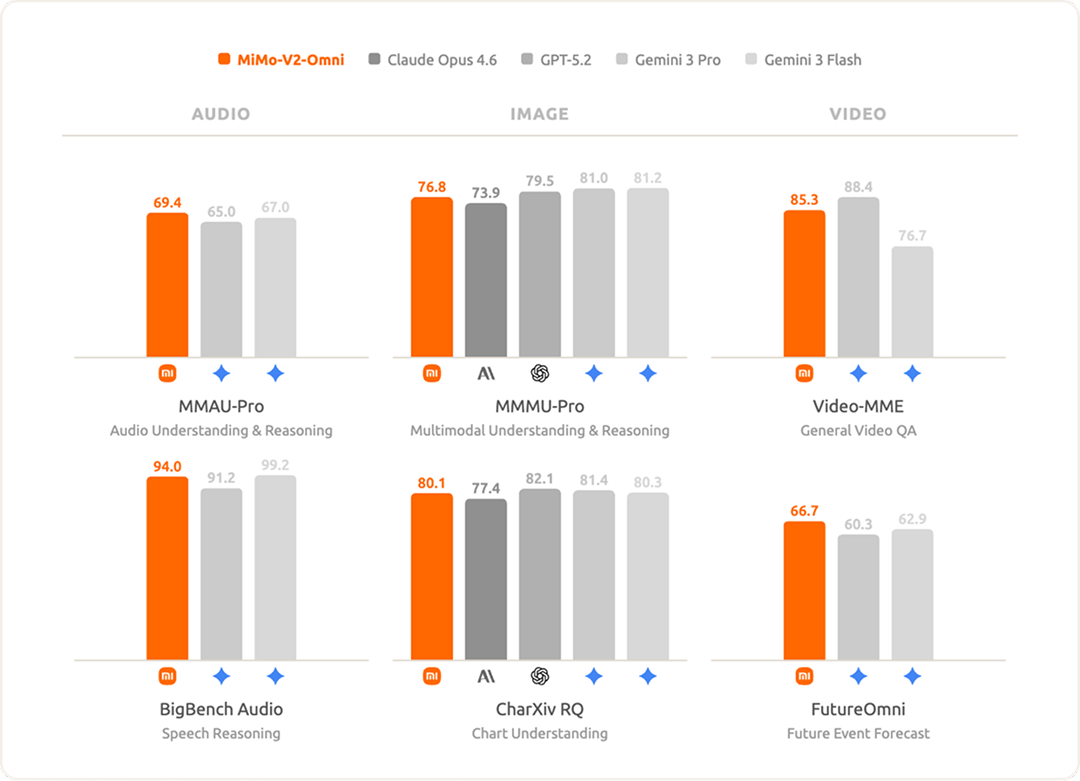
音频理解方面,支持从环境声分类、多说话人分离、音频-视觉联合推理,到超过 10 小时连续长音频的深度理解。综合表现超越 Gemini 3 Pro,是当前最强的音频理解基座模型之一。
图像理解方面,MiMo-V2-Omni 展现出强大的多学科视觉推理与复杂图表分析能力,超越 Claude Opus 4.6,逼近 Gemini 3 Pro 等顶尖闭源模型水平。
视频理解方面,支持原生音视频联合输入,实现真正的多模态视频理解。通过创新的视频预训练,模型具备强大的情境感知与未来推理能力。
智能体能力:从理解到完成任务
理解是基础,交付是关键。MiMo-V2-Omni 能够跨模态理解复杂环境、自主制定并执行计划、在遇到异常时实时修正策略,最终端到端地交付完整结果。
全模态智能体任务
在与真实数字环境交互的评测基准上,MiMo-V2-Omni 表现优异,比肩 Gemini 3 Pro。前沿的感知能力与原生训练的行动能力形成了复合优势:感知越准确,行动越有效。
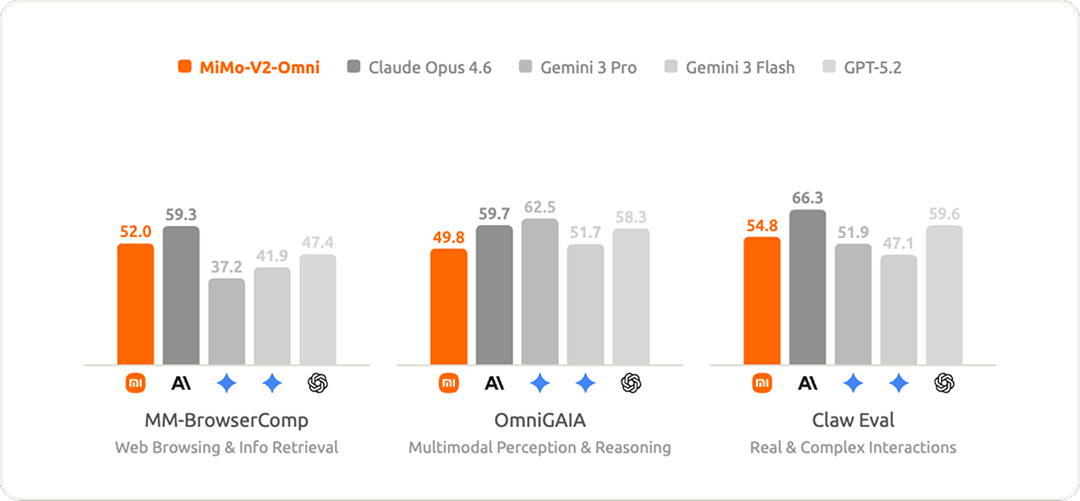
与此同时,MiMo-V2-Omni 在纯文本智能体任务上也保持了高度的竞争力。
Healer Alpha 匿名内测
一周前,MiMo-V2-Omni 以 Healer Alpha 为代号,匿名上线了全球最大的 API 聚合平台 OpenRouter,上线期间调用量持续上涨,广受用户好评。




左右滑动,查看更多
经过一周的持续迭代和优化,MiMo-V2-Omni 具备了更强更稳定的全模态感知和智能体行动能力,在日常生产力场景中表现出巨大的潜力。
开放 API
MiMo-V2-Omni 模型现已正式开放 API 服务,支持 256K 上下文长度,输入 $0.4 / 百万 tokens,输出 $2 / 百万 tokens。
访问 https://platform.xiaomimimo.com,即刻接入API。
此外,MiMo-V2-Omni 联合 OpenClaw、OpenCode、KiloCode、Blackbox 及 Cline 等五大 Agent 开发框架团队,为全球开发者提供为期一周的限时免费接口支持,欢迎广大开发者接入体验。
能力展示
来一起看看,MiMo-V2-Omni 能为我们做点什么?
🎭 跨模态共鸣:理解生活的蒙太奇
当我们将电影《好东西》中经典的“猜声音”片段输入 MiMo-V2-Omni 时,让它以资深电影分析师的视角进行拉片,MiMo-V2-Omni 展现出了令人惊叹的跨模态隐喻与情感推理能力:

🎧 长音频理解:7 小时访谈,一次听完
当我们将张小珺对谢赛宁长达7小时的完整访谈音频一次性输入 MiMo-V2-Omni 时,它准确提炼出了跨越数小时的核心论点与逻辑脉络,展现出超长音频的深度理解能力。

💻 Browser Use 场景
Browser Use 是衡量模型 Agentic 能力的试金石。结合 OpenClaw 框架,MiMo-V2-Omni 可以像真人一样操控浏览器,帮你把事情办完:
-
帮你挑手机、砍价、下单:你说"帮我看看小米17怎么选,去小红书做做功课,选好了去京东下单,顺便砍砍价",模型就会自己打开小红书,翻十几篇帖子,提取配置对比、拍照评测、真实用户体验,给你整理出一份购买建议。切到京东,跨店比价,找到最优渠道。转接人工客服砍价,和客服实时交互,试探优惠空间。聊完价,直接加购下单。遇到复杂网页结构、多标签页切换、实时交互要求,都能见招拆招。
-
帮你做短视频、发 TikTok:你只需要说一句“做一个 MiMo-V2-Omni 介绍短视频,配上科技感音效,发到 TikTok 上”,模型就会自己设计四组画面、现场合成全部音效,不依赖任何外部素材。渲染过程中碰到中文字体报错?自动修复,继续干。做完之后打开 TikTok 上传页面,填好文案,点击发布,还会顺手点赞、评论,最后检查确认视频审核通过、成功上线。
🗒️ 智能办公场景
我们还与金山办公合作,将 MiMo-V2-Omni 接入 WPS Office,探索全模态智能体模型在日常生产力场景中的表现。
只需几句话,MiMo-V2-Omni 能够直接生成高质量的 Word、结构化 Excel、排版规范的 PDF 与完整的 PPT。
这是智能体 AI 在真实生产力工具中的落地形态,它跳出了对话机器人的限制,能够走入现实生活,切实提升日常工作效率。
下一步
MiMo-V2-Omni 是我们第一个在基座层面统一感知与行动的全模态模型,但这只是起点。
接下来,我们将持续推进长周期智能体规划、实时流式感知、多智能体协同,以及与物理世界更深层的整合。
欢迎加入我们,一起探索 AGI 的下一程。

END


openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 0
0 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)