
涉及到的统计数学
描述分布的特征:expected value , varience , standard deviation , skewness (偏度) , kurtosis (峰度)其他数据集中趋势的的度量:中位数(Median),众数(Mode),均值(Mean)如果两个变量相互独立,联合概率密度函数 = 两个变量边际概率密度函数的乘积。从统计角度(最大化似然)来找,或者从几何角度(让它离点最近)来找。(
概率分布
离散分布的概率质量函数&连续分布的概率密度函数

概率质量函数(离散)
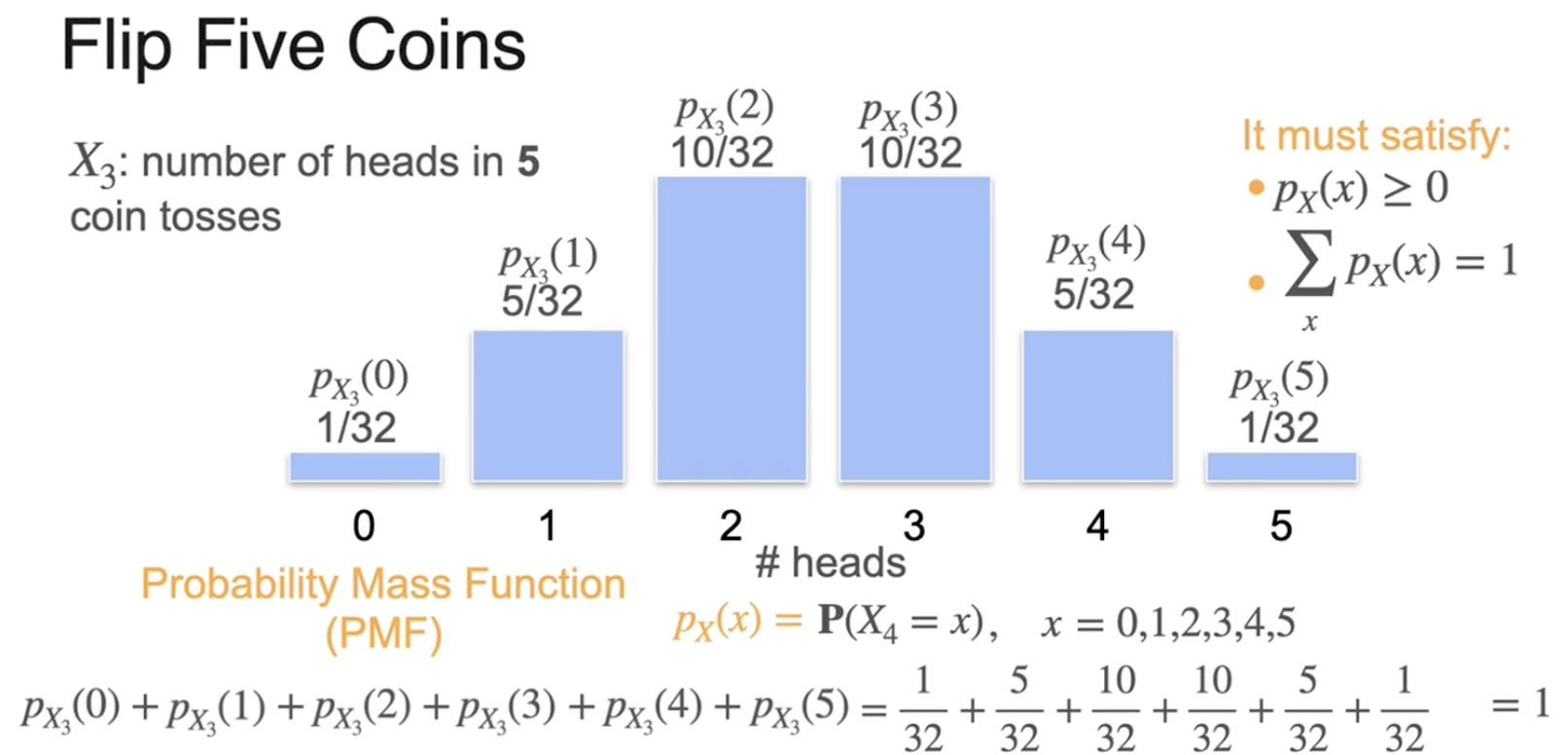
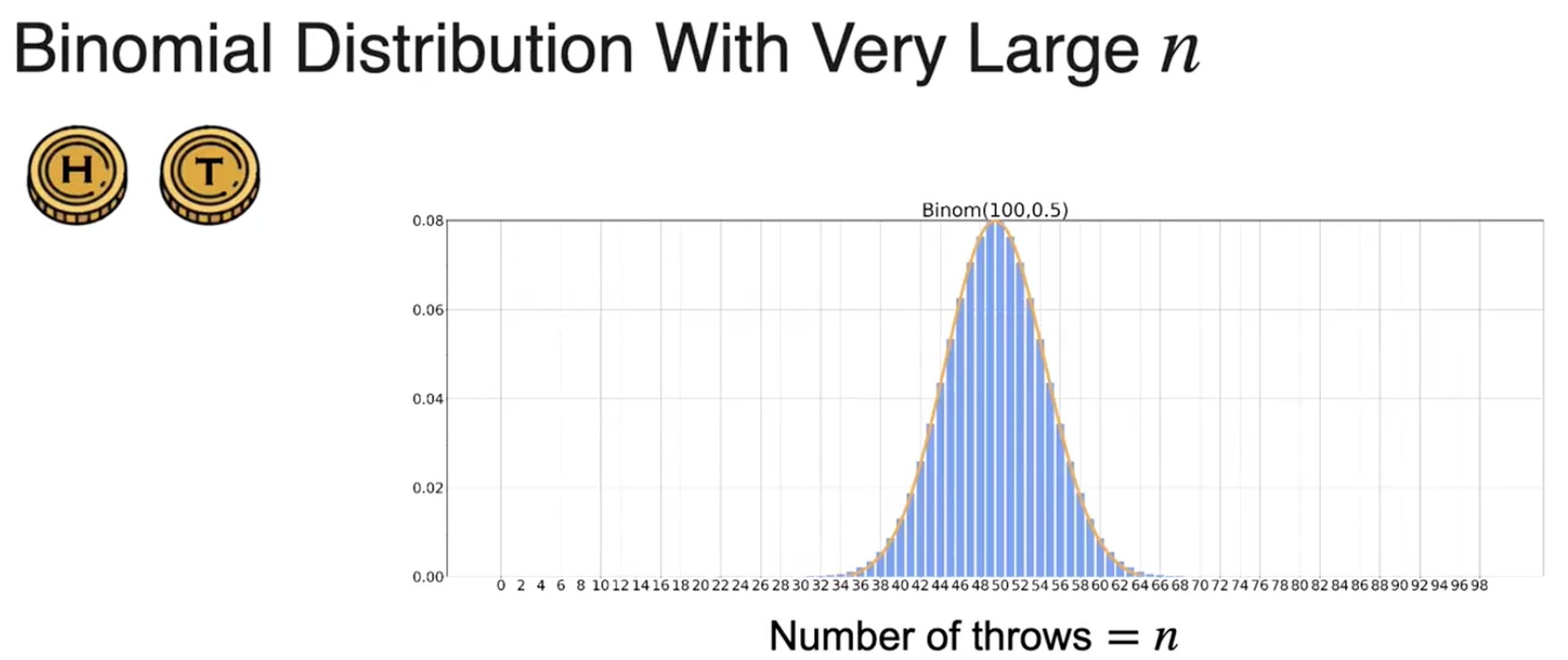
二项分布(离散)

概率密度函数(连续)

伯努利分布
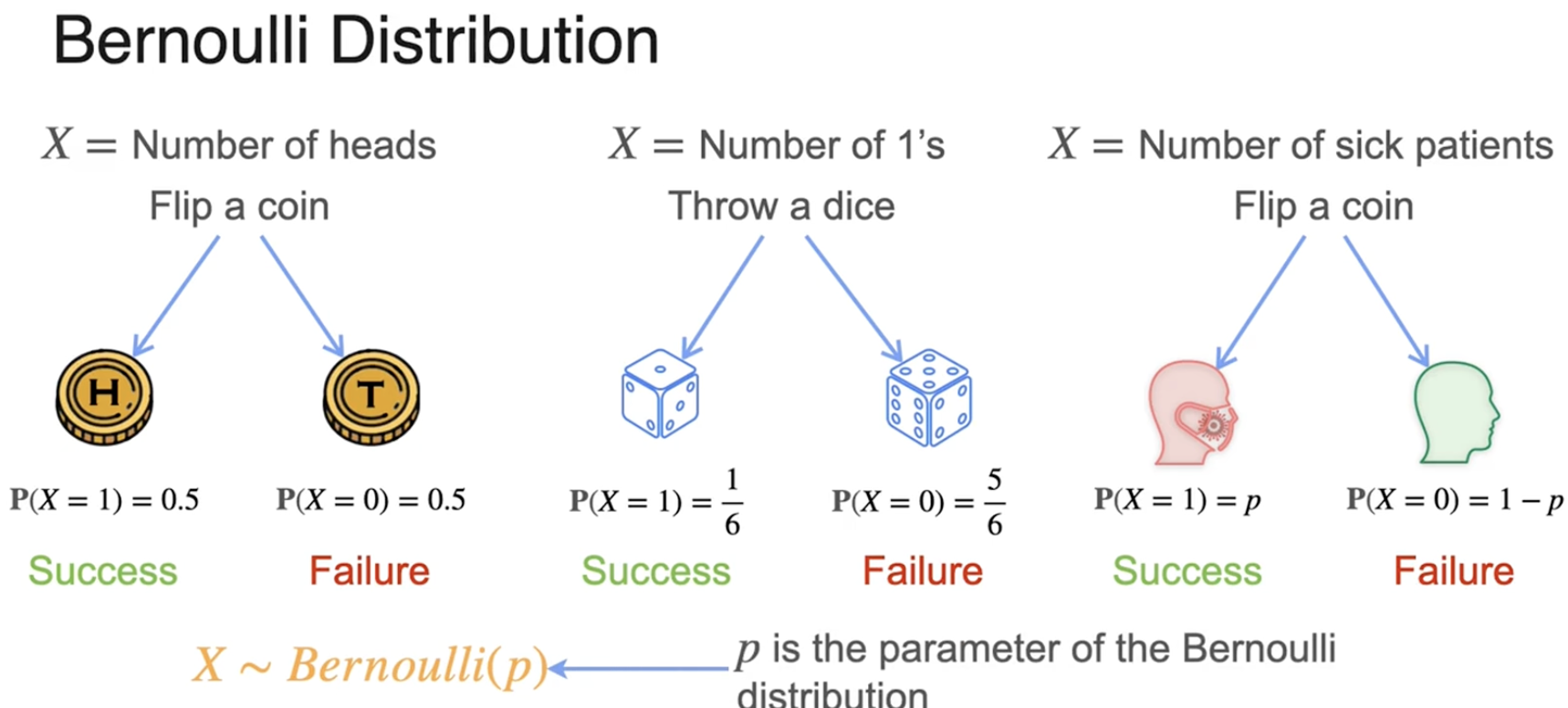
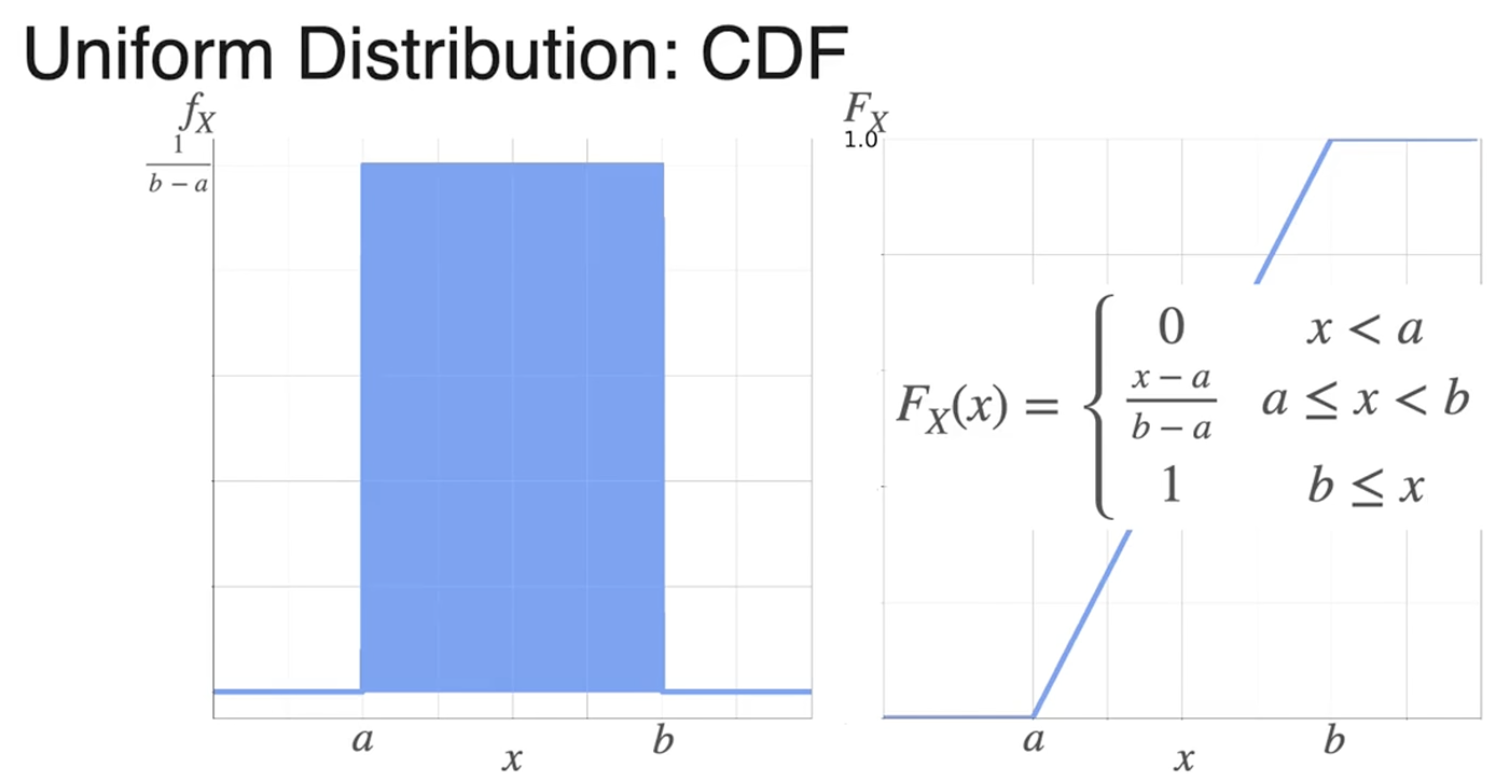
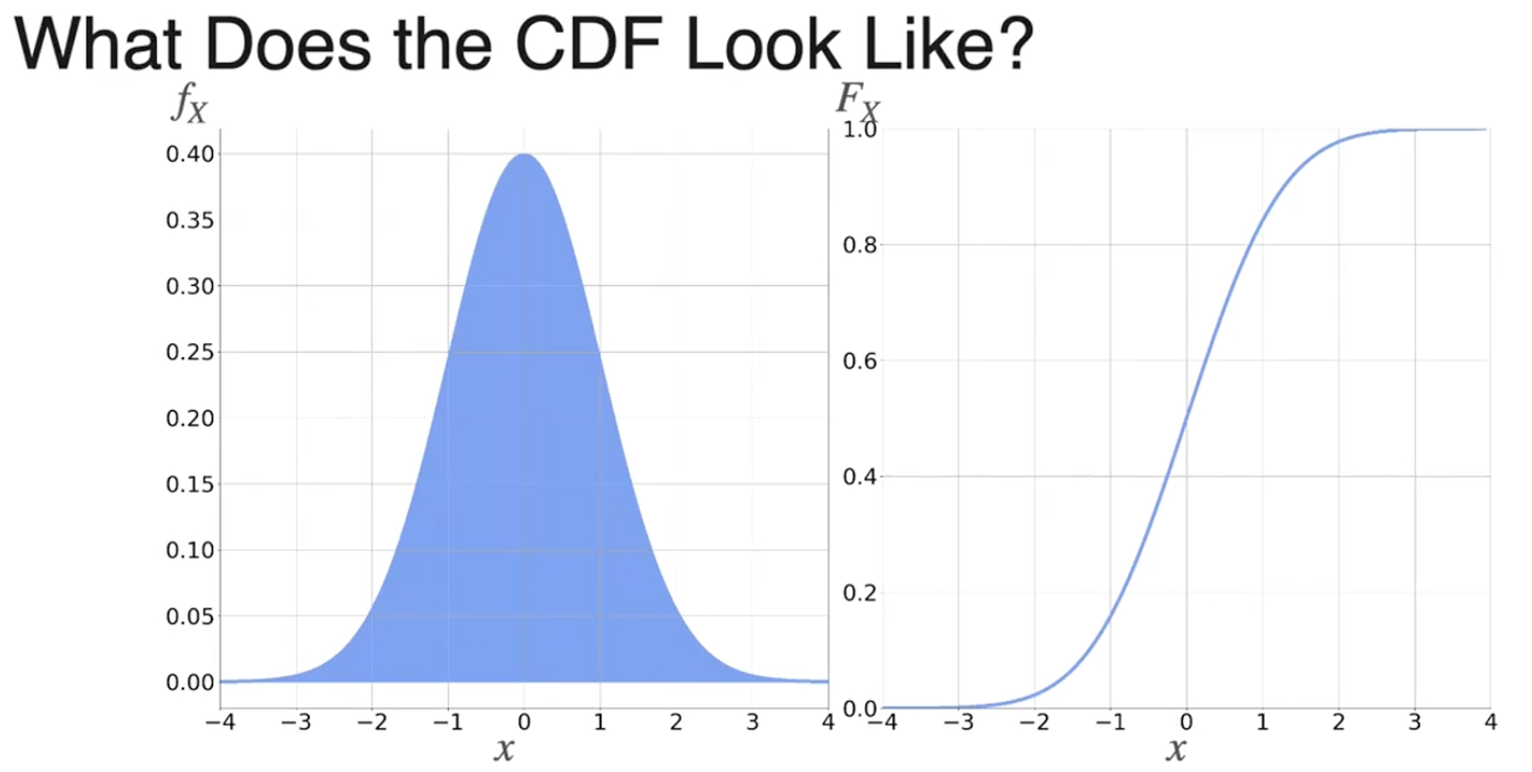
累积分布函数
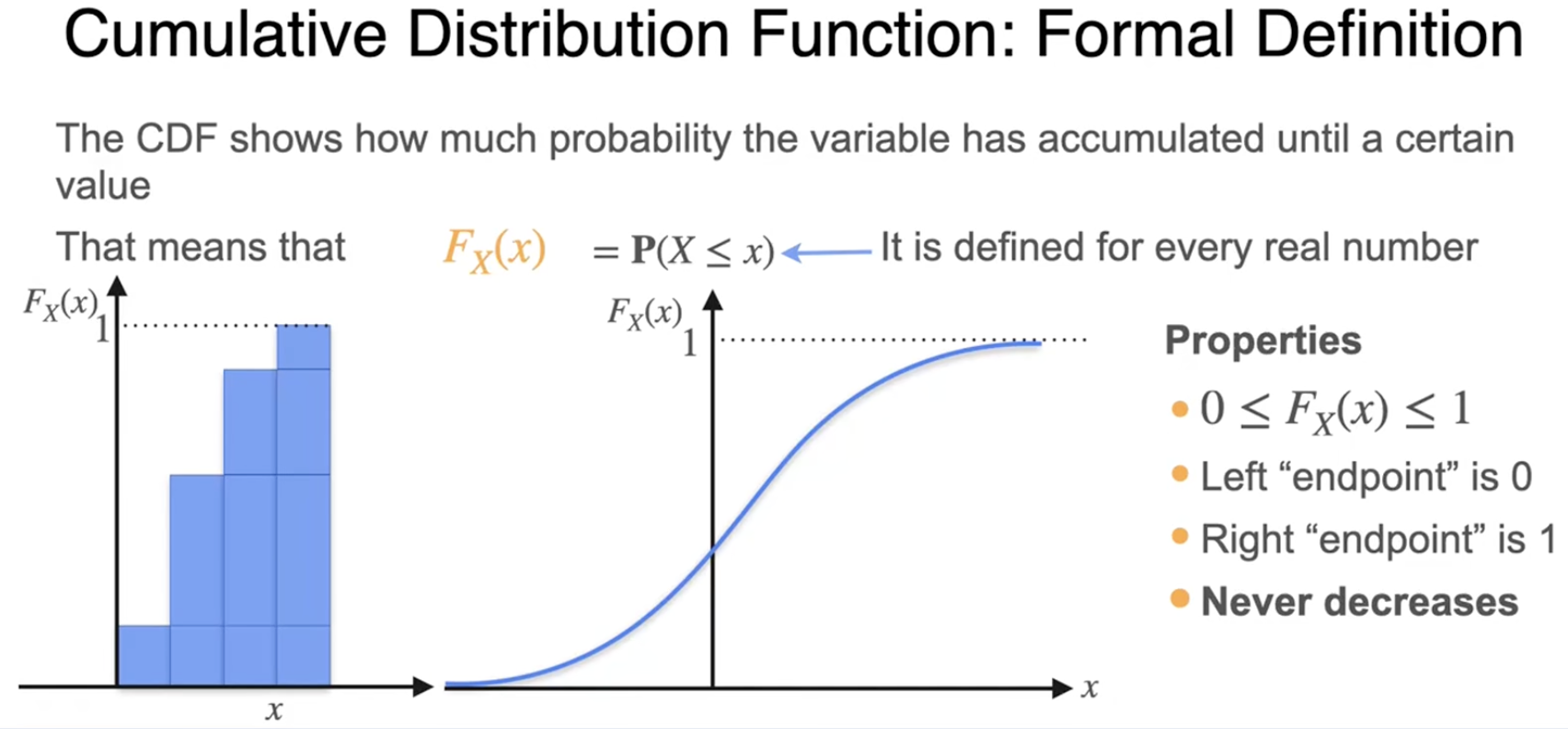
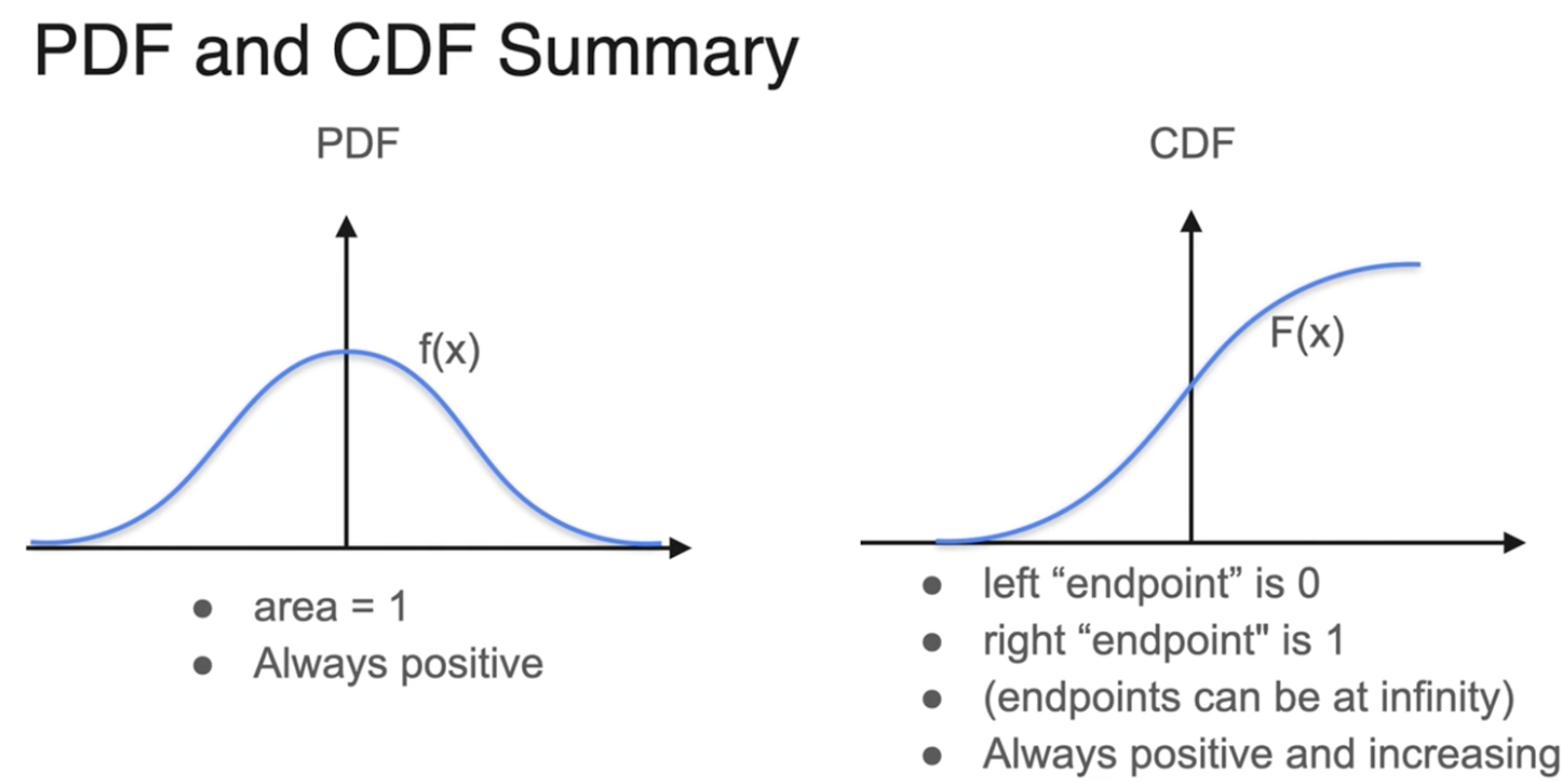
均匀分布(最简单的连续分布)

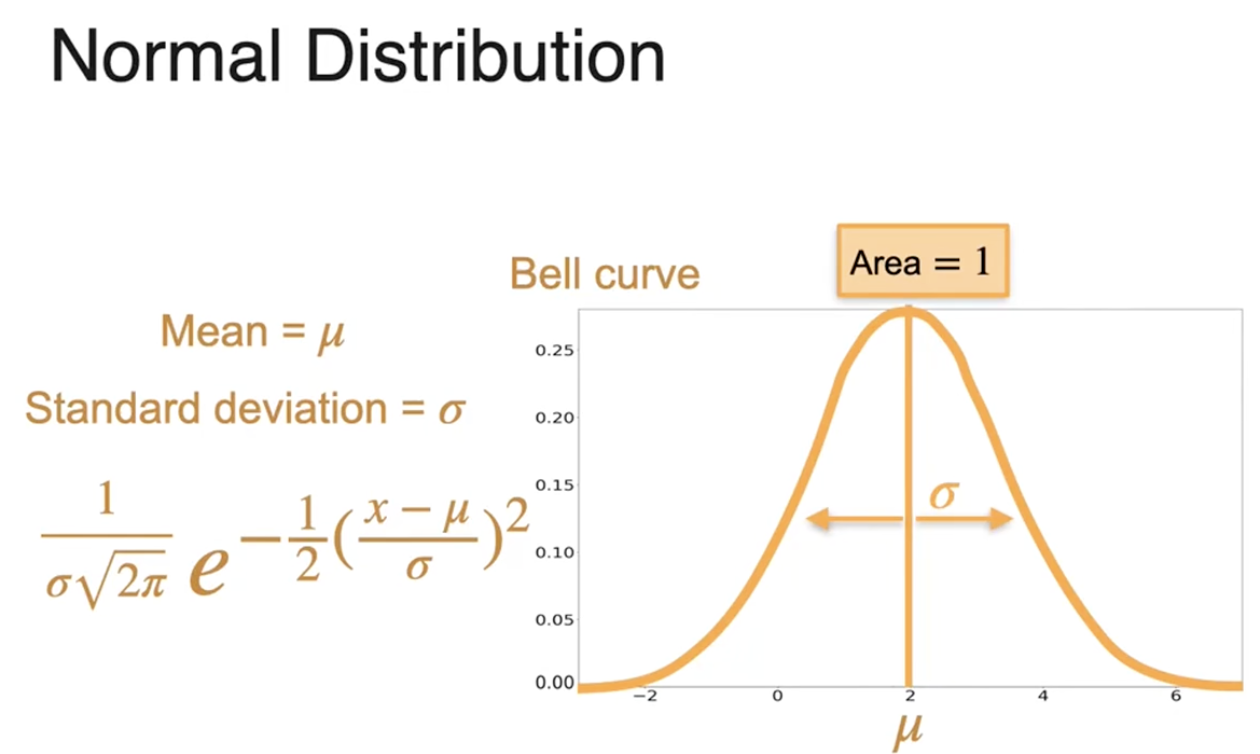
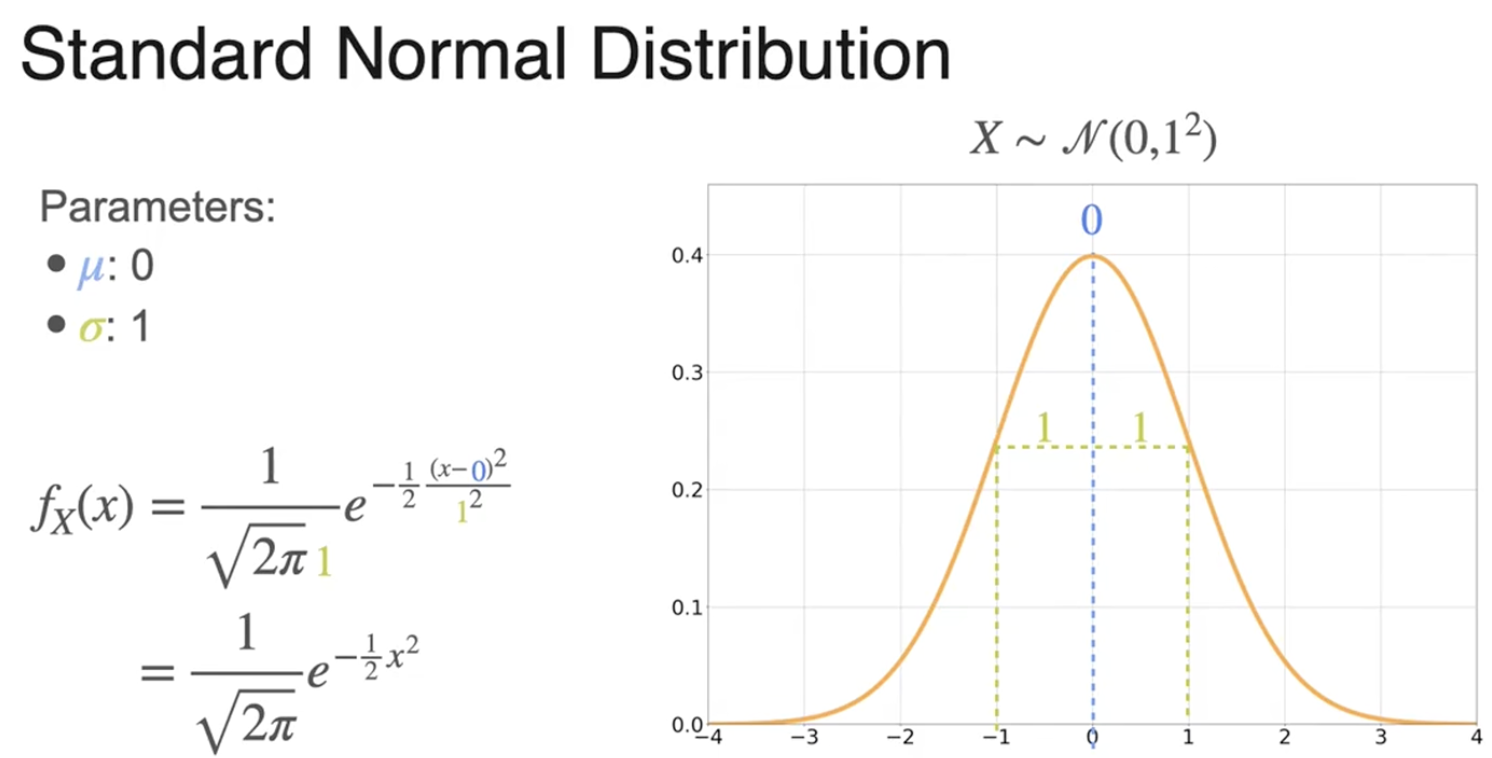
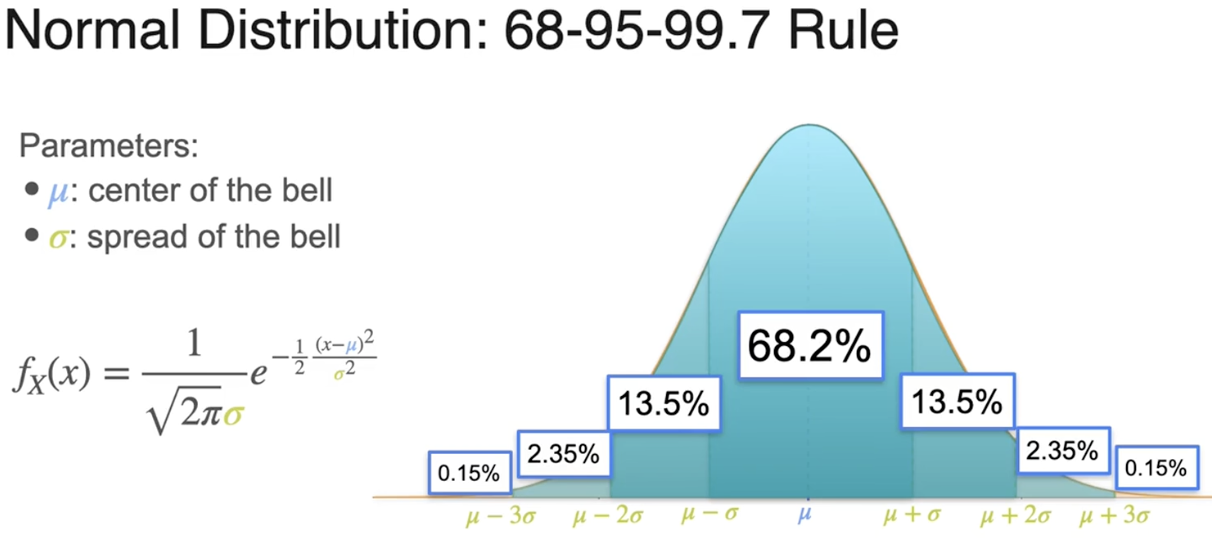
正态分布(高斯分布)
当n很大时,二项分布可以很好地近似为 Gaussian distribution
曲线宽度的度量
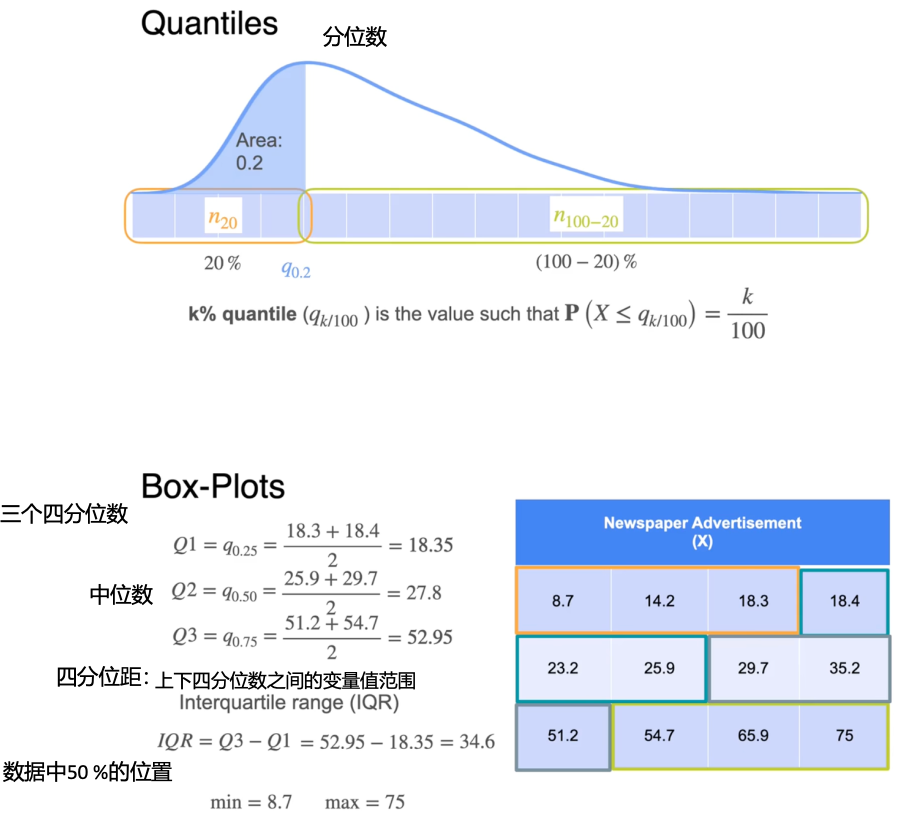
数据中心的位置
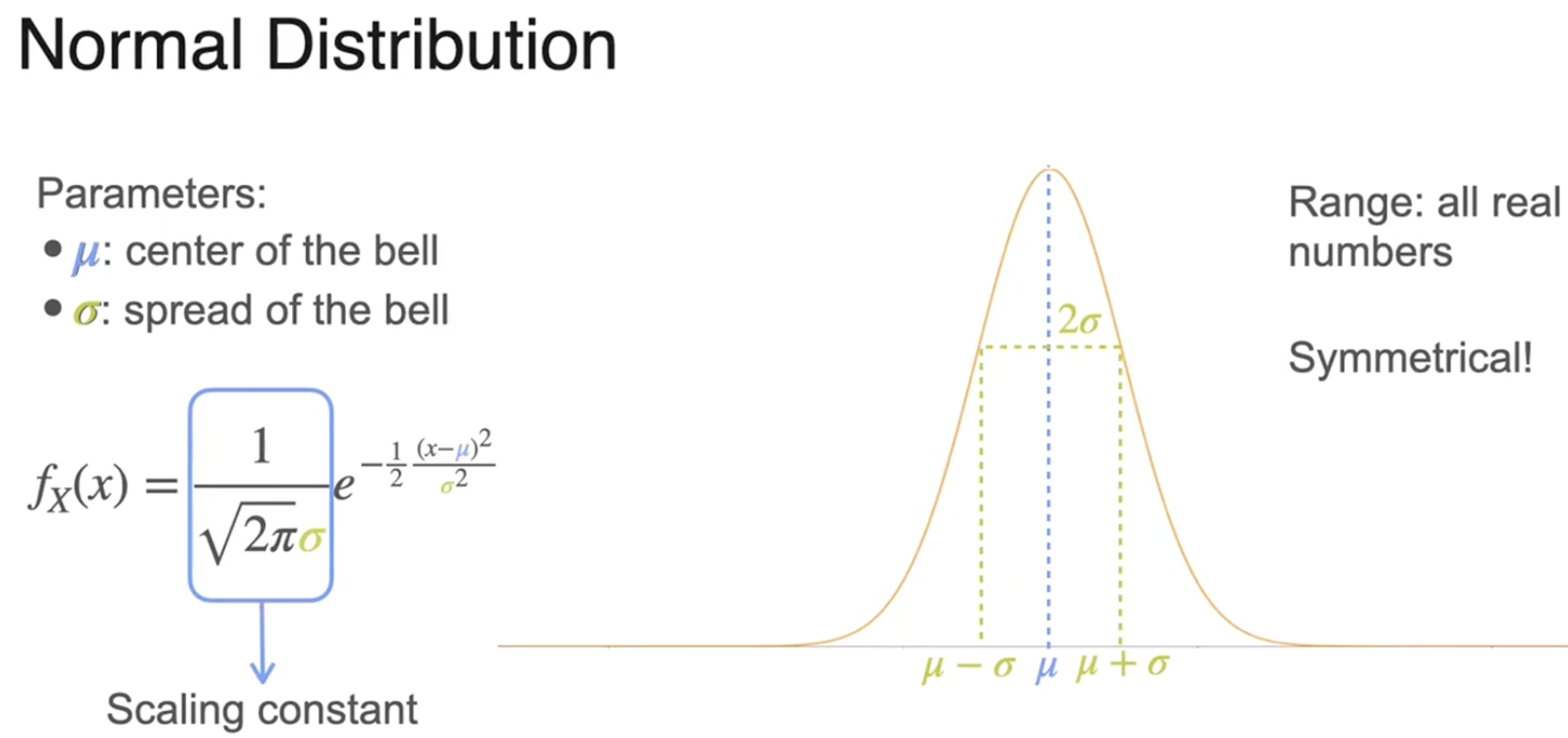
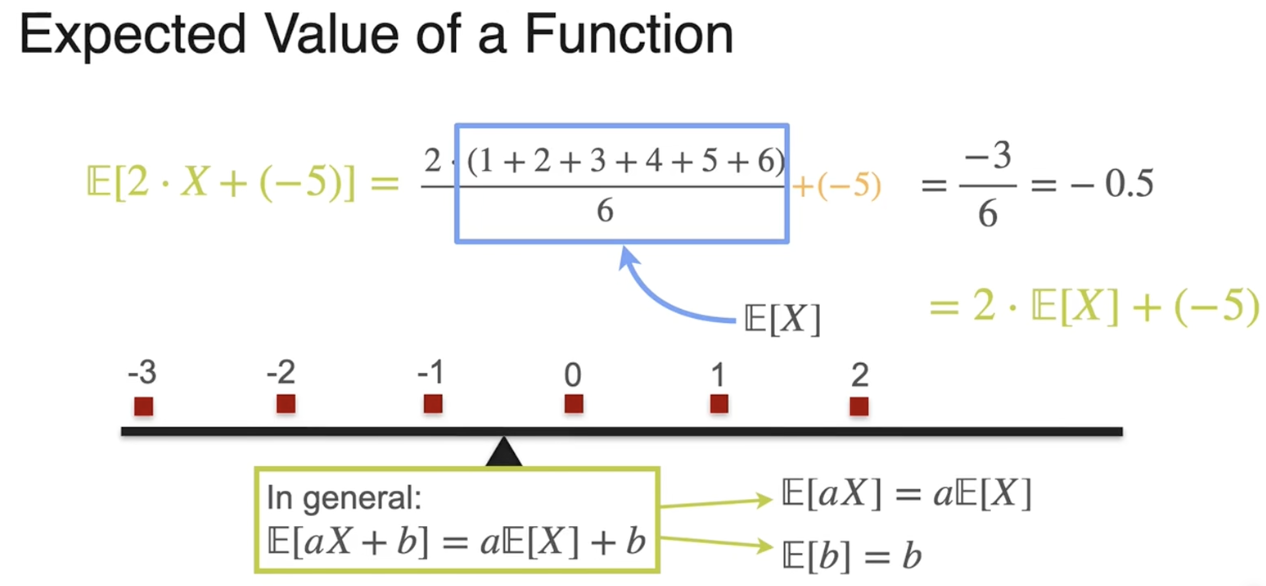
比例常数
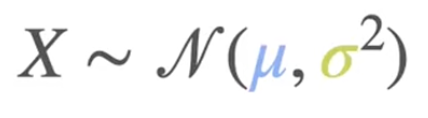
N 代表正态分布
标准正态分布
标准化(正态分布--->标准正态分布)
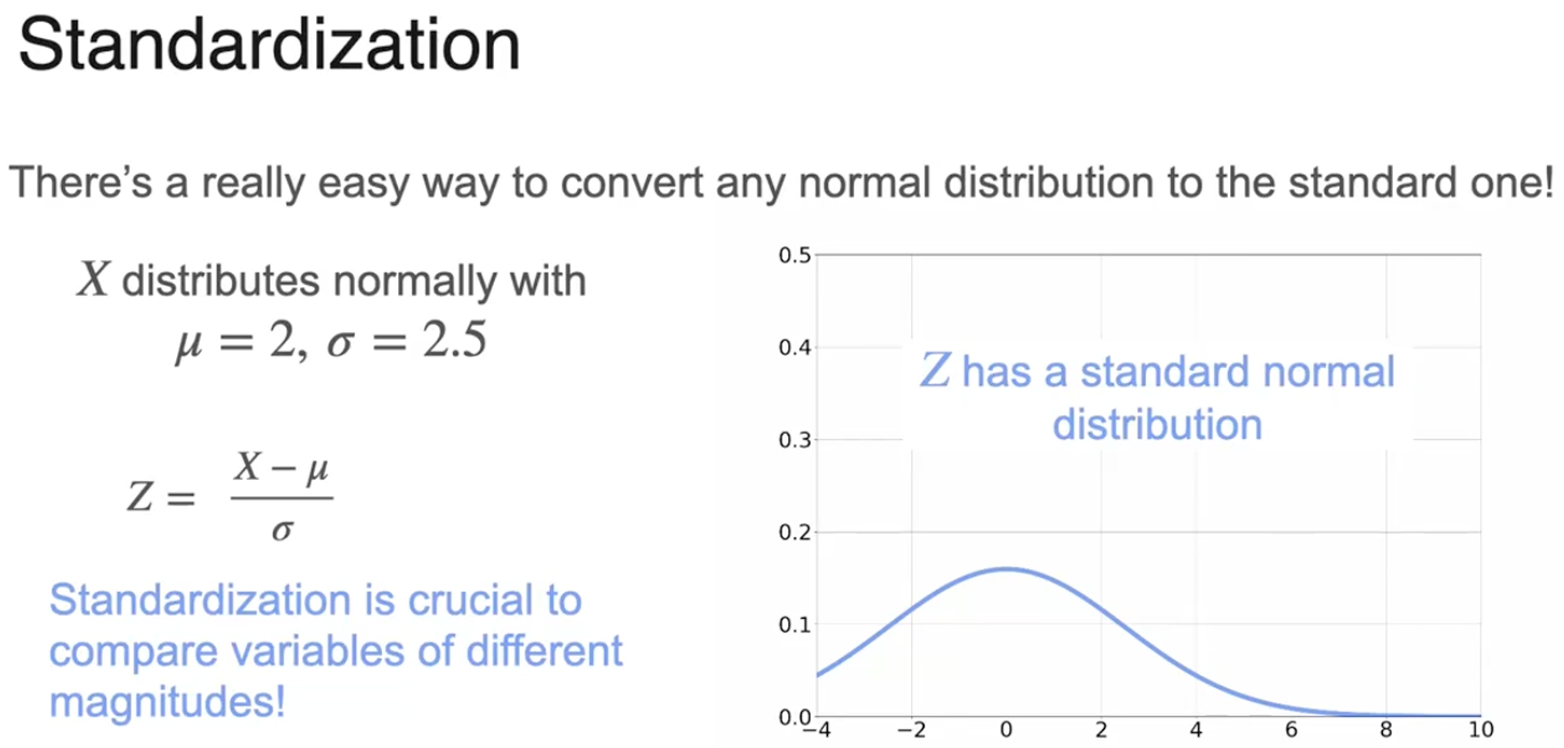
通过标准化,可以比较在不同的值范围内的不同变量
卡方分布
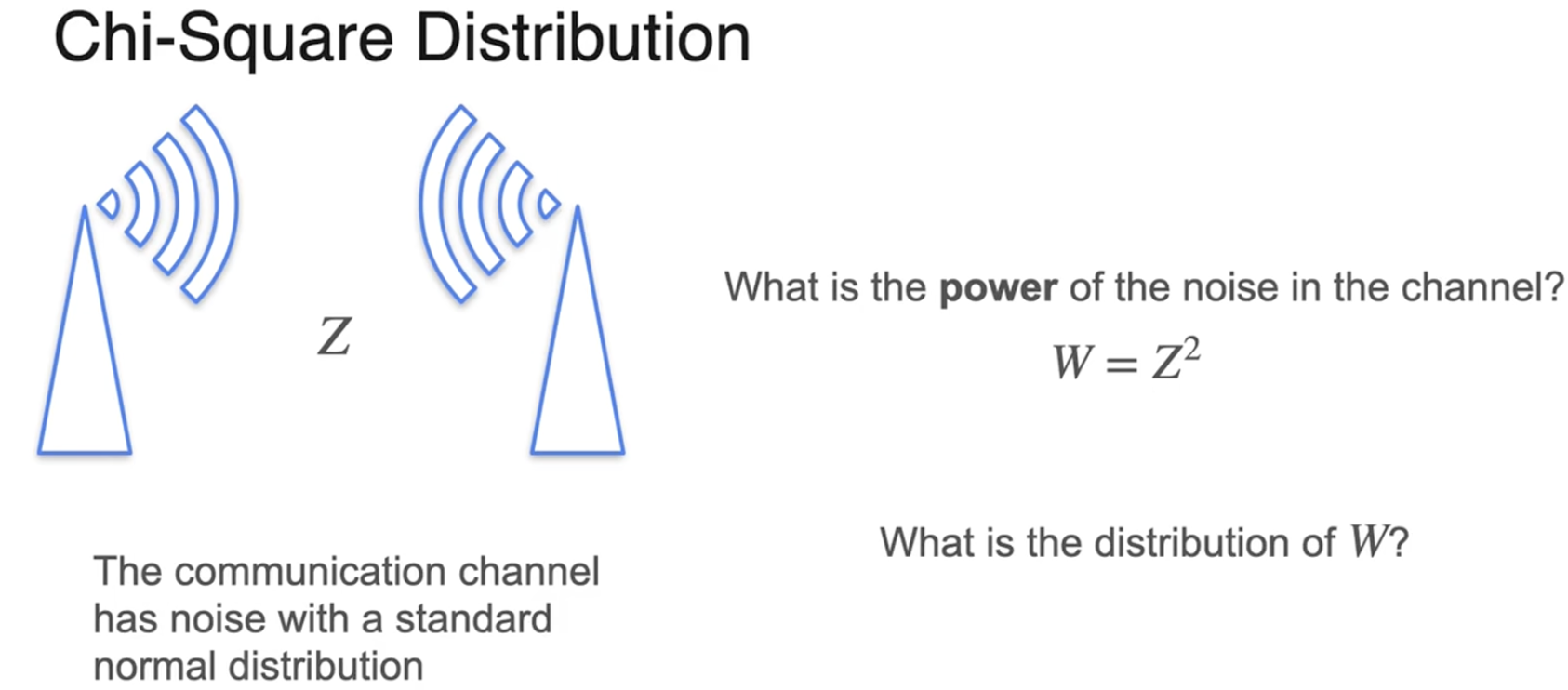
噪声功率 = 噪声的平方
假设 Z 服从标准正态分布
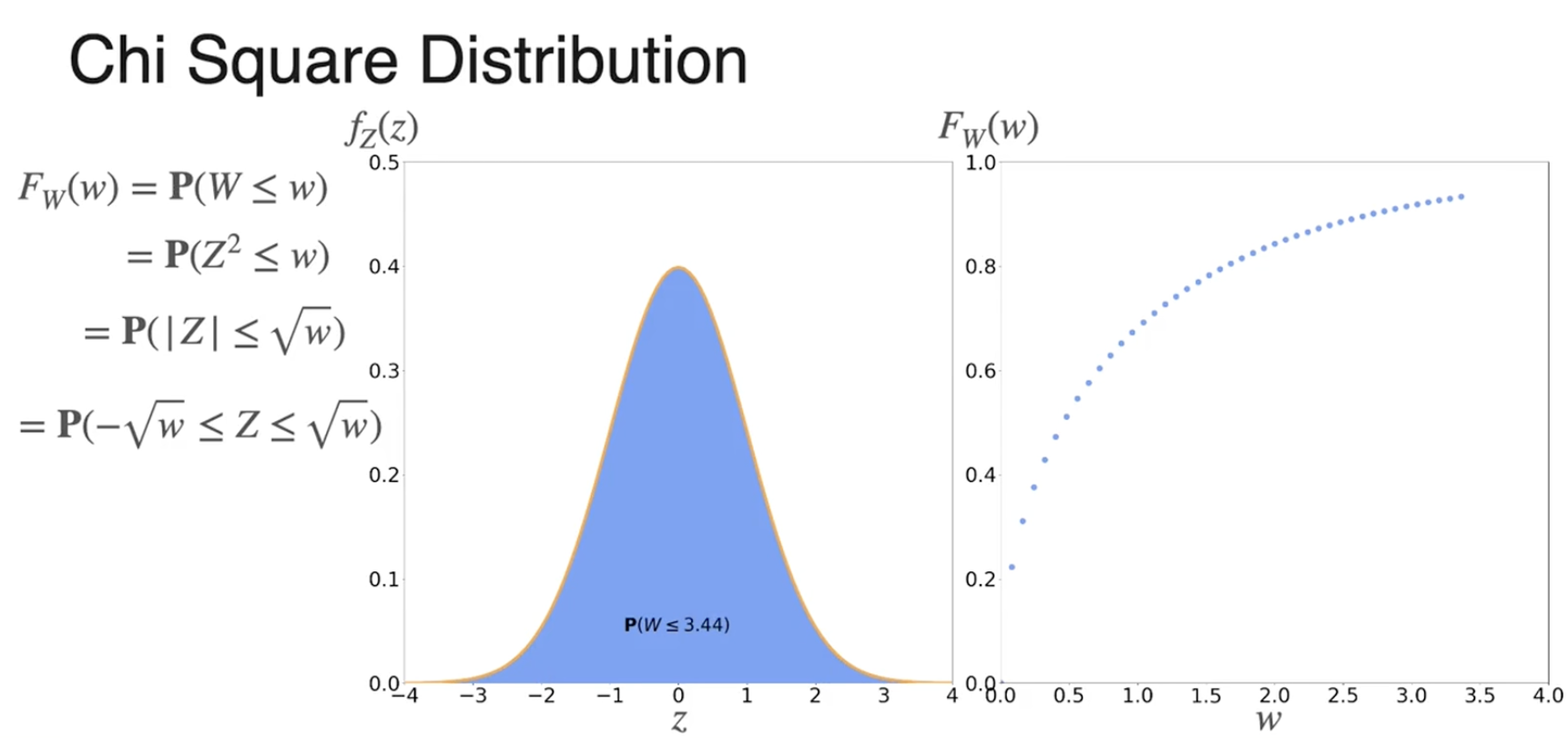
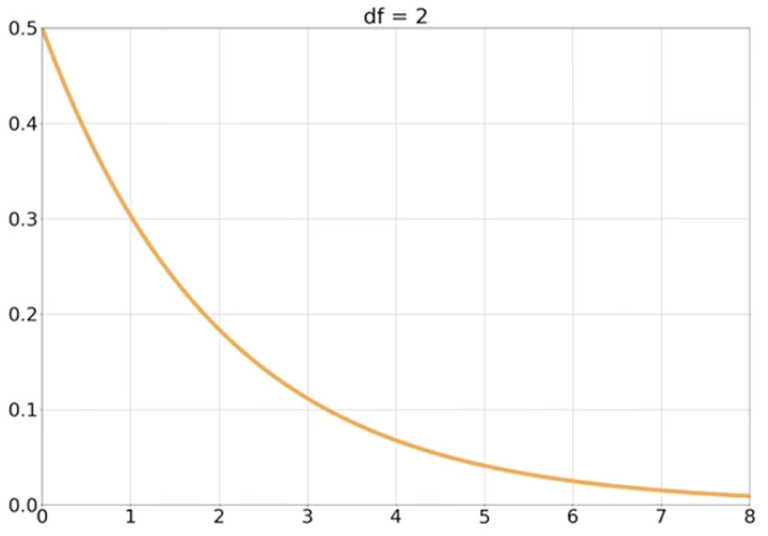
自由度为1的卡方分布
Degree of free
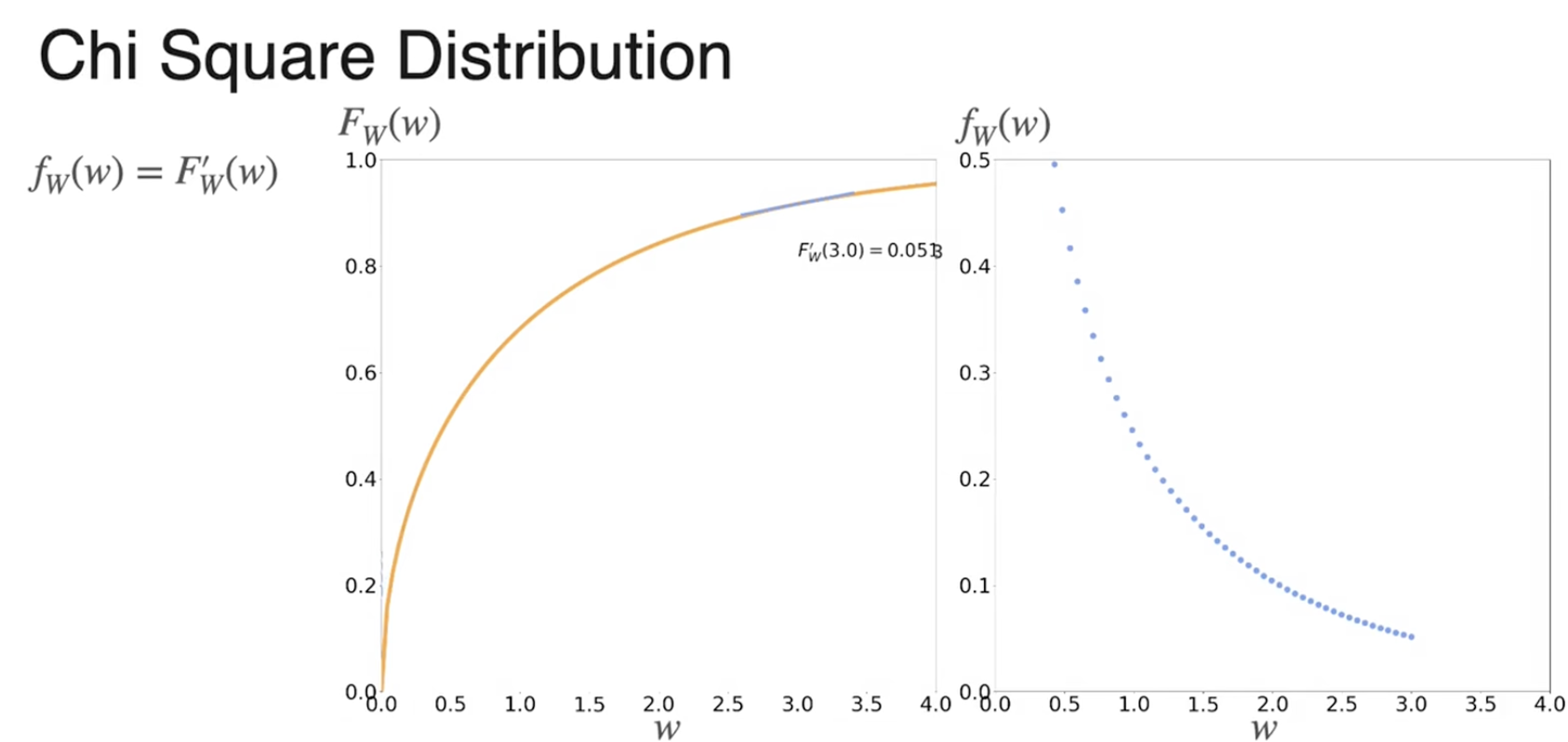
CDF是PDF的积分
可以通过CDF进行导数运算,得到PDF
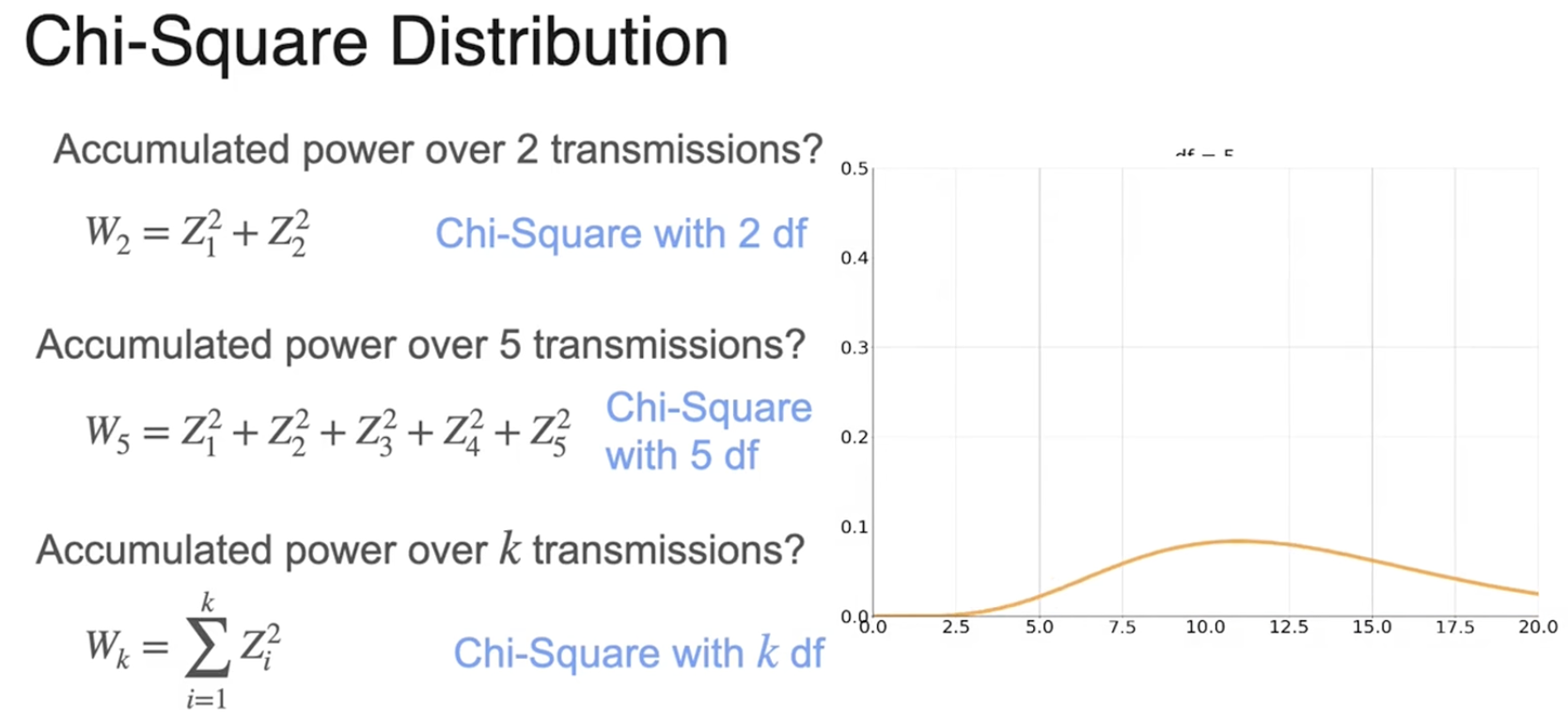
在两次传输中累积噪声功率
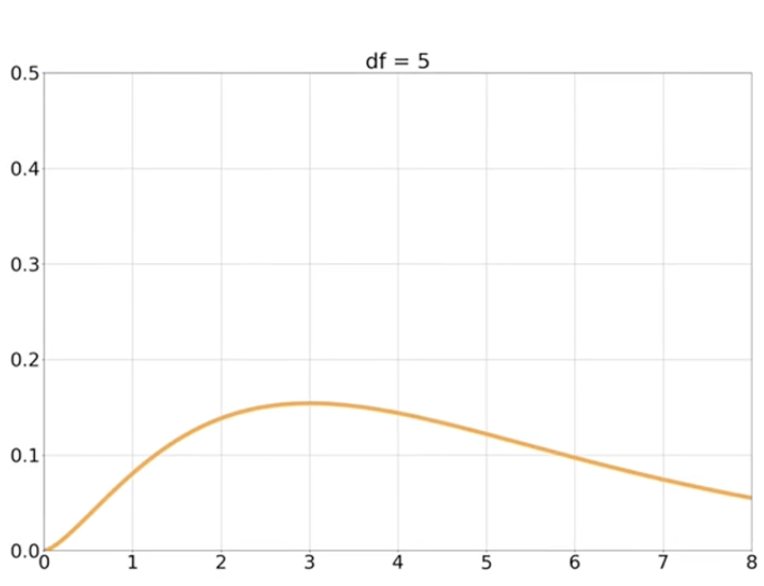
自由度为 k 的卡方分布
随着 k 增加,PDF更加分散,变得越来越对称
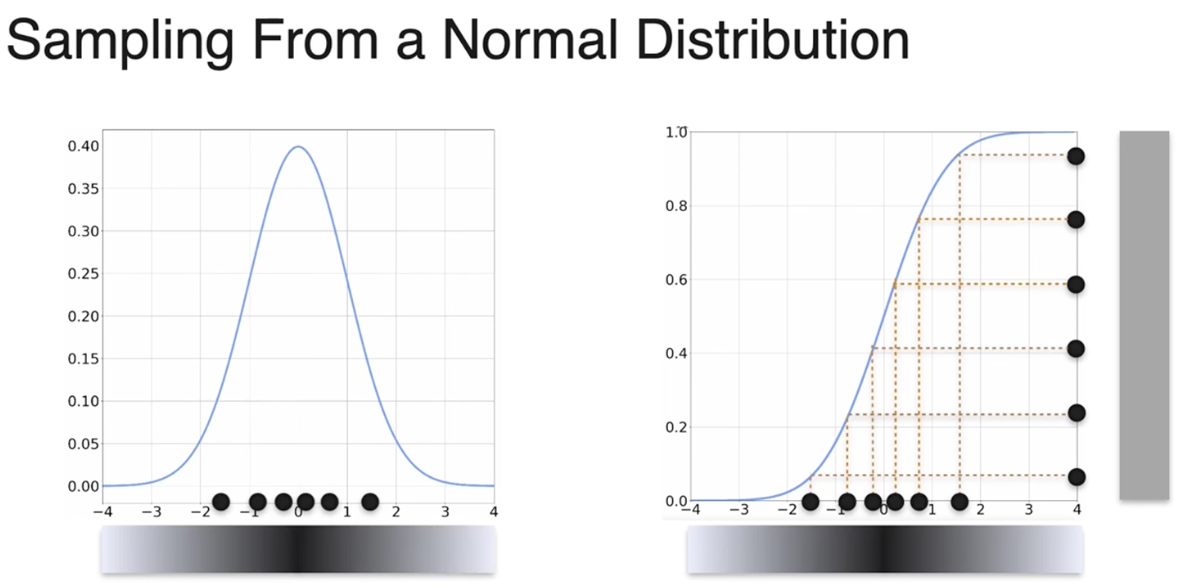
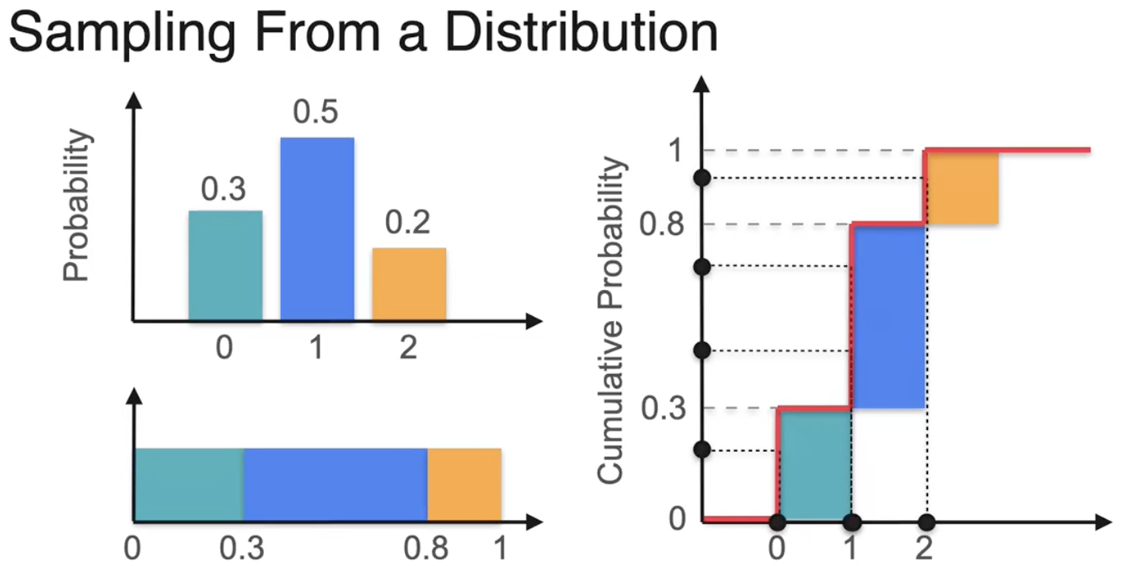
采样概率分布
(需要更大的数据集,可以创建一些很像原始数据的合成数据)
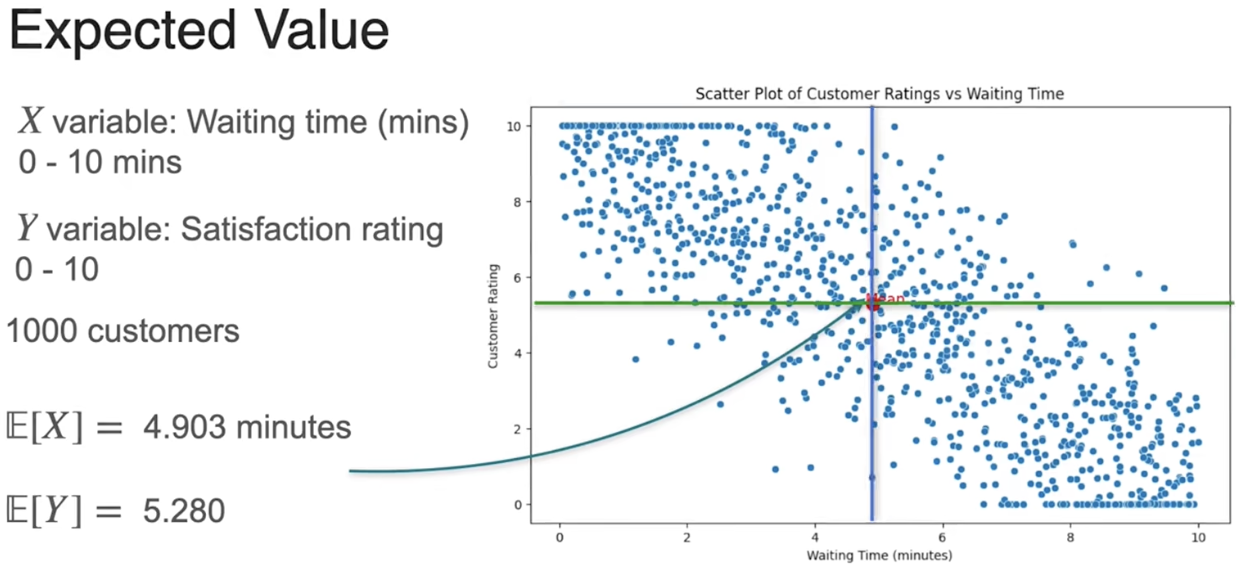
期望值

其他数据集中趋势的的度量:中位数(Median),众数(Mode),均值(Mean)
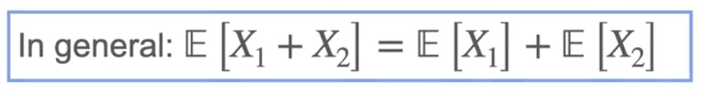
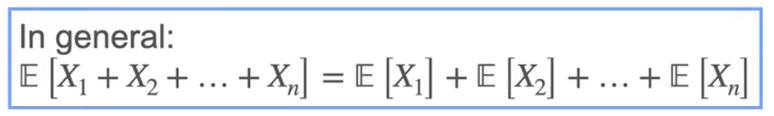
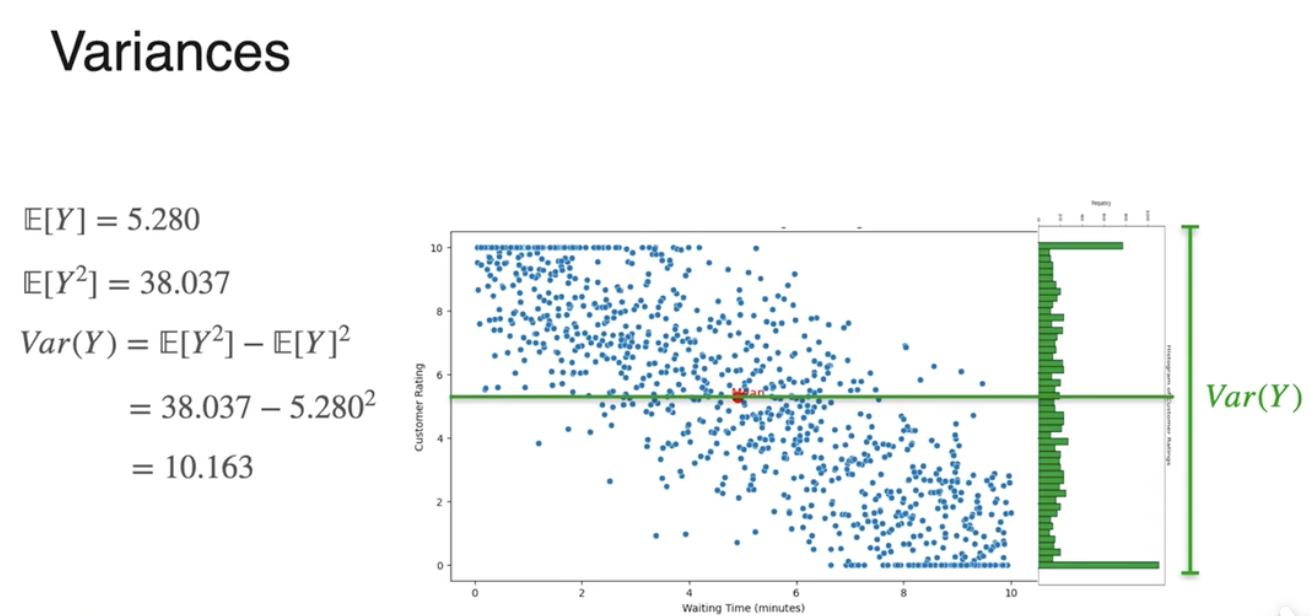
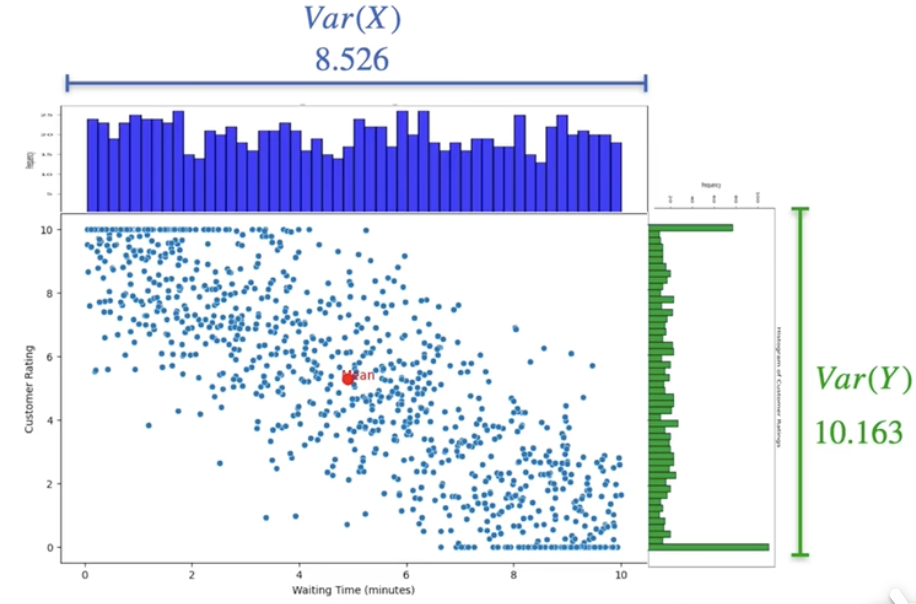
方差(单位不一致)
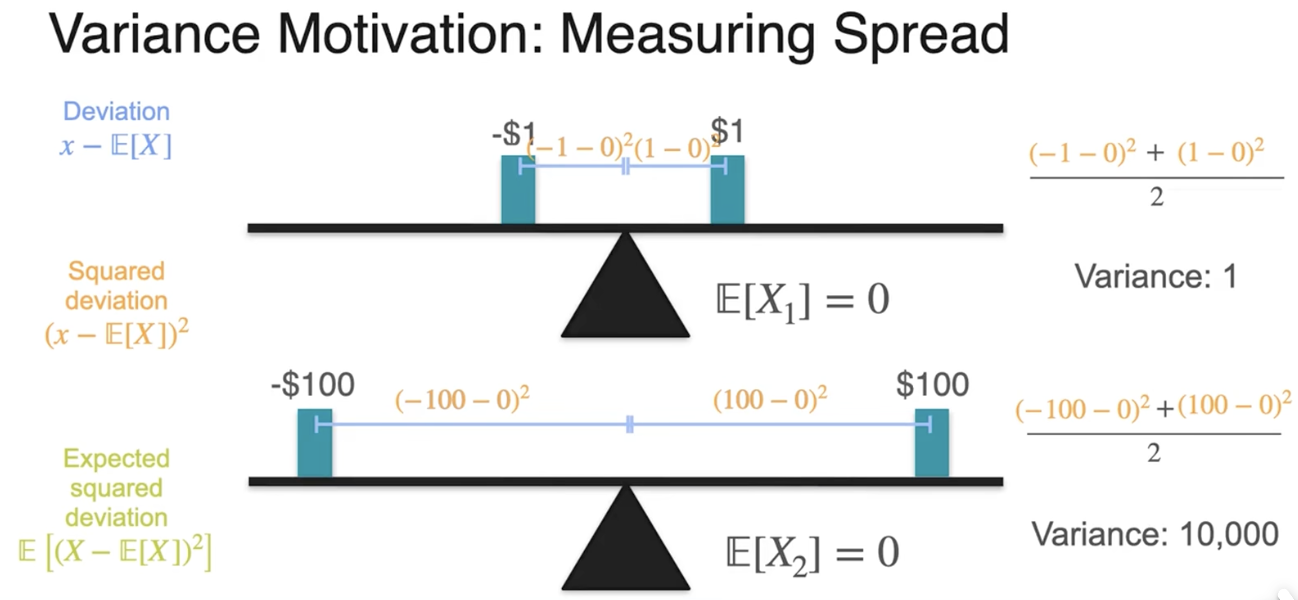
偏差
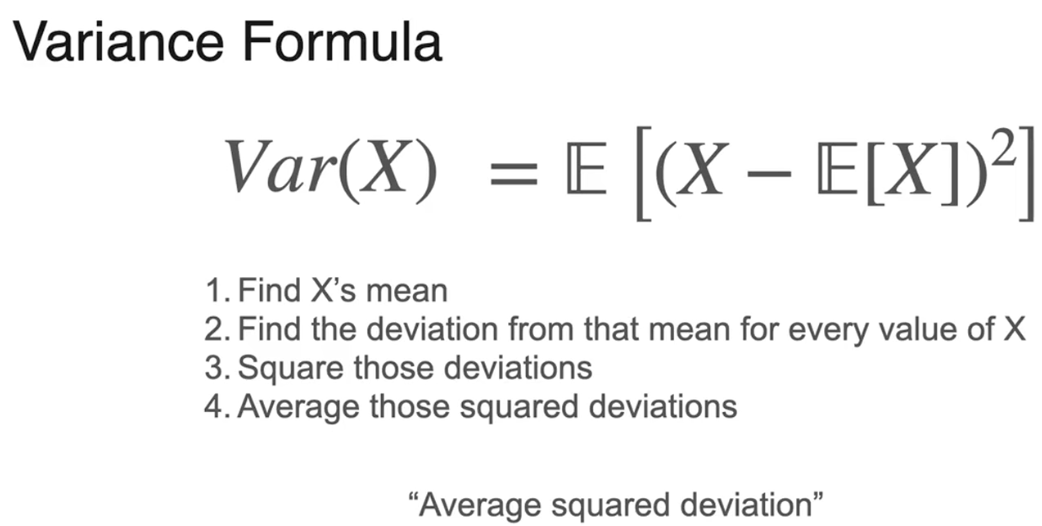

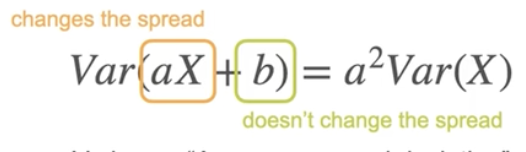
标准差
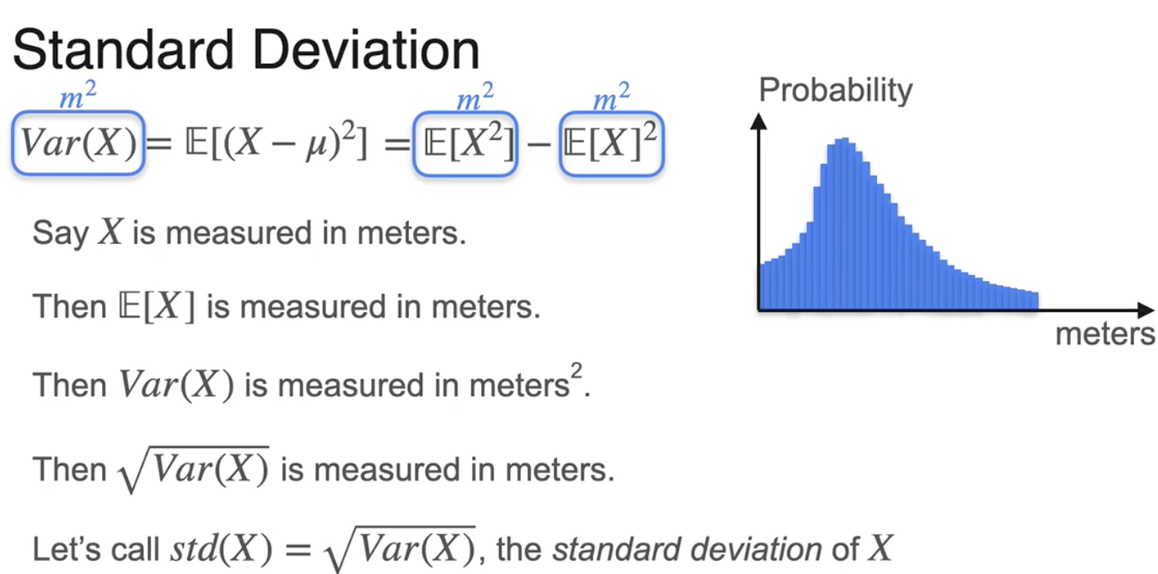
均值加减1,2,3个标准差

高斯分布
高斯分布
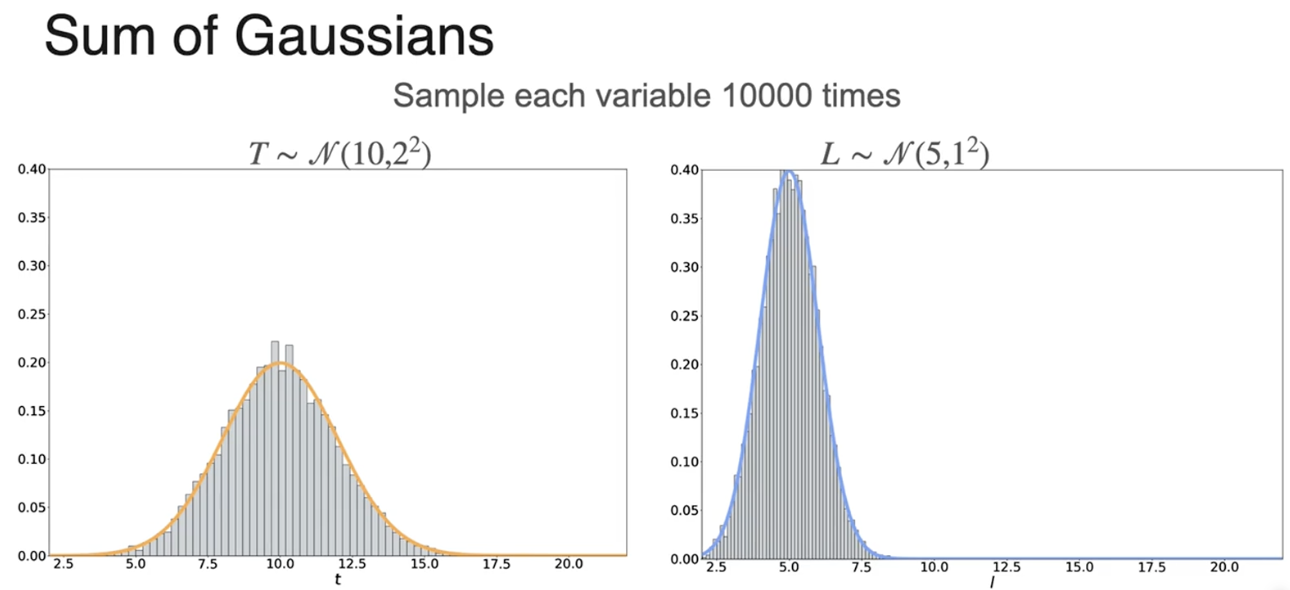
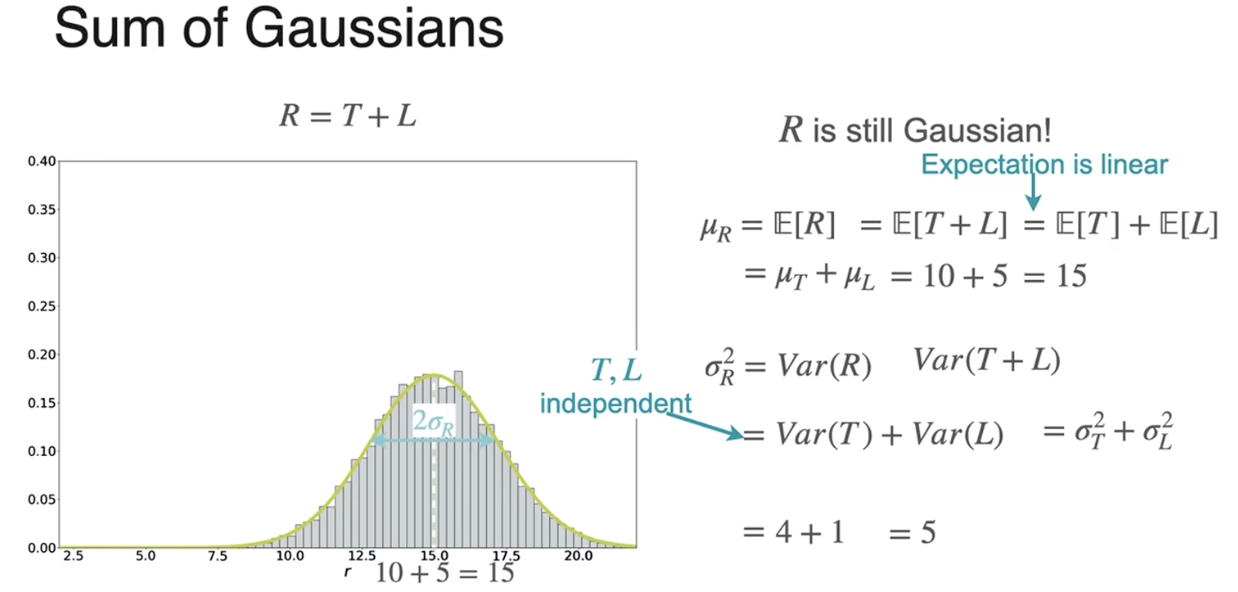
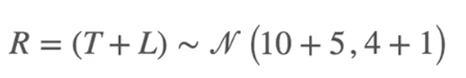
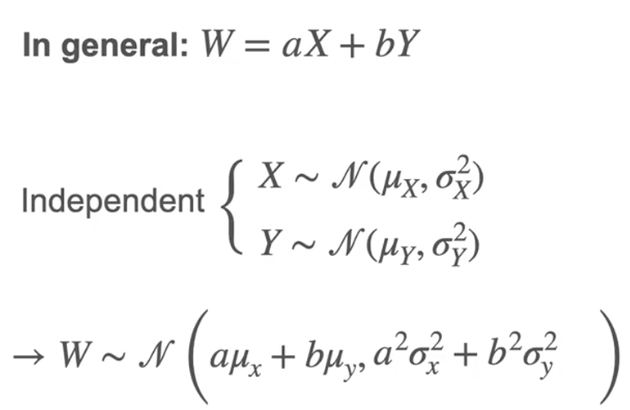
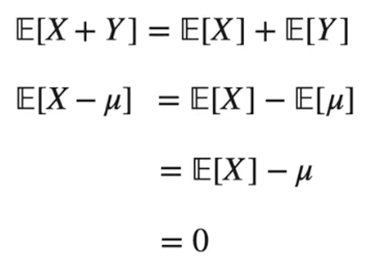
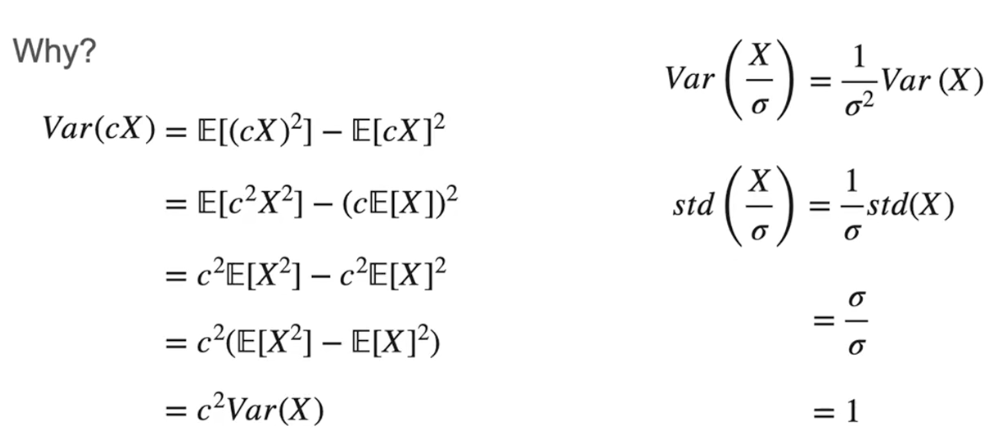
使标准差为1
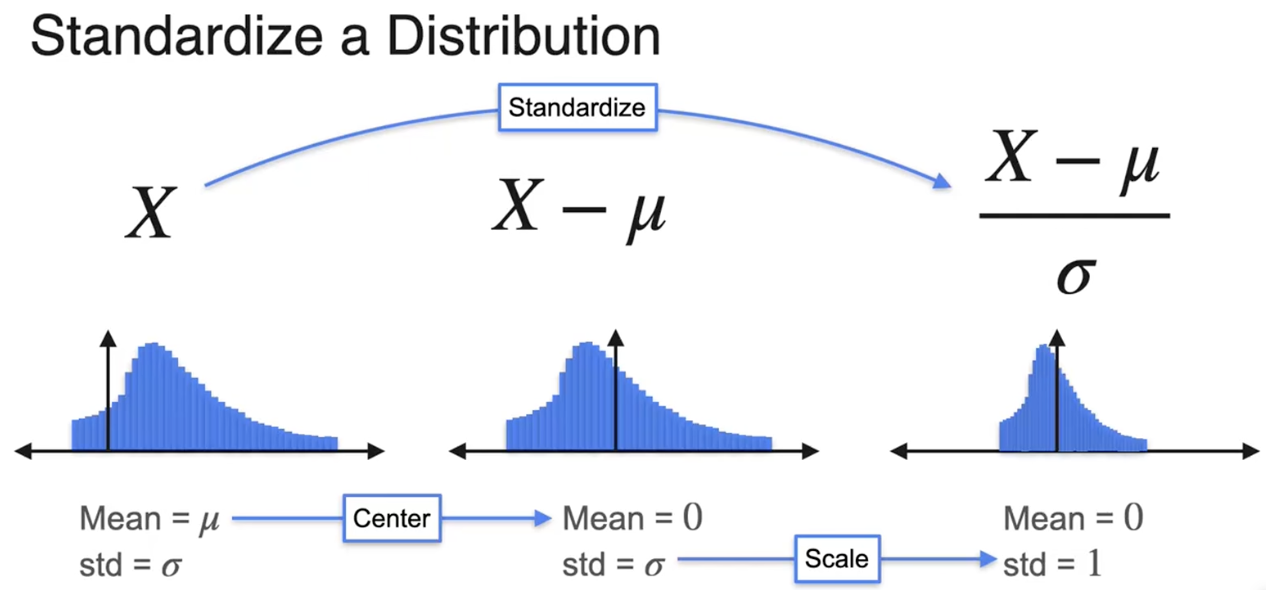
中心化
+
=
缩放
标准化
描述分布的特征:expected value , varience , standard deviation , skewness (偏度) , kurtosis (峰度)
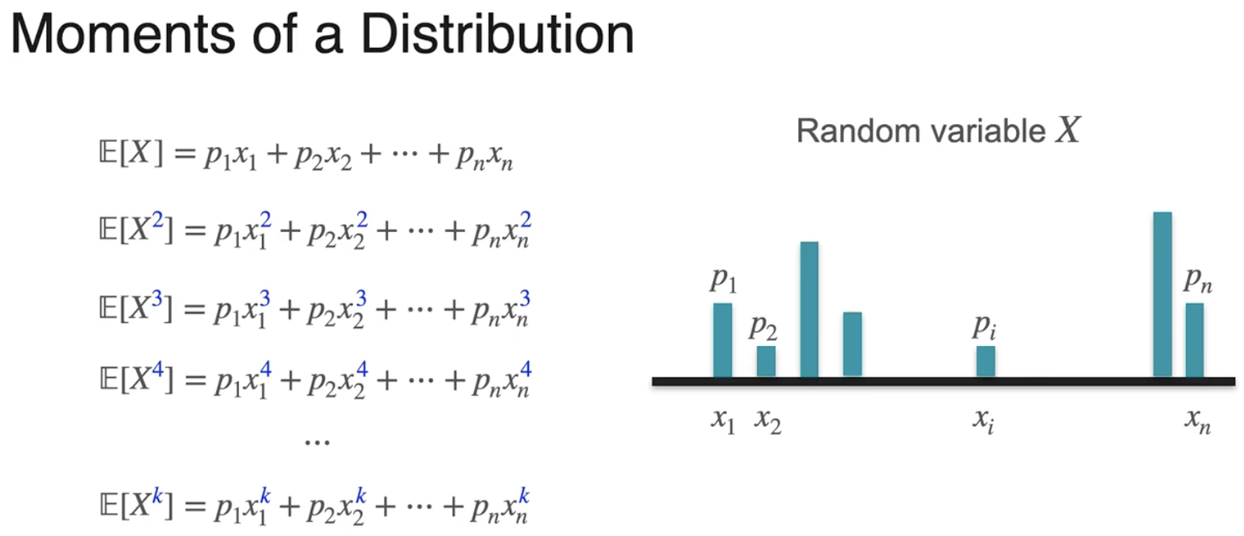
The first moment 第一矩
The second moment
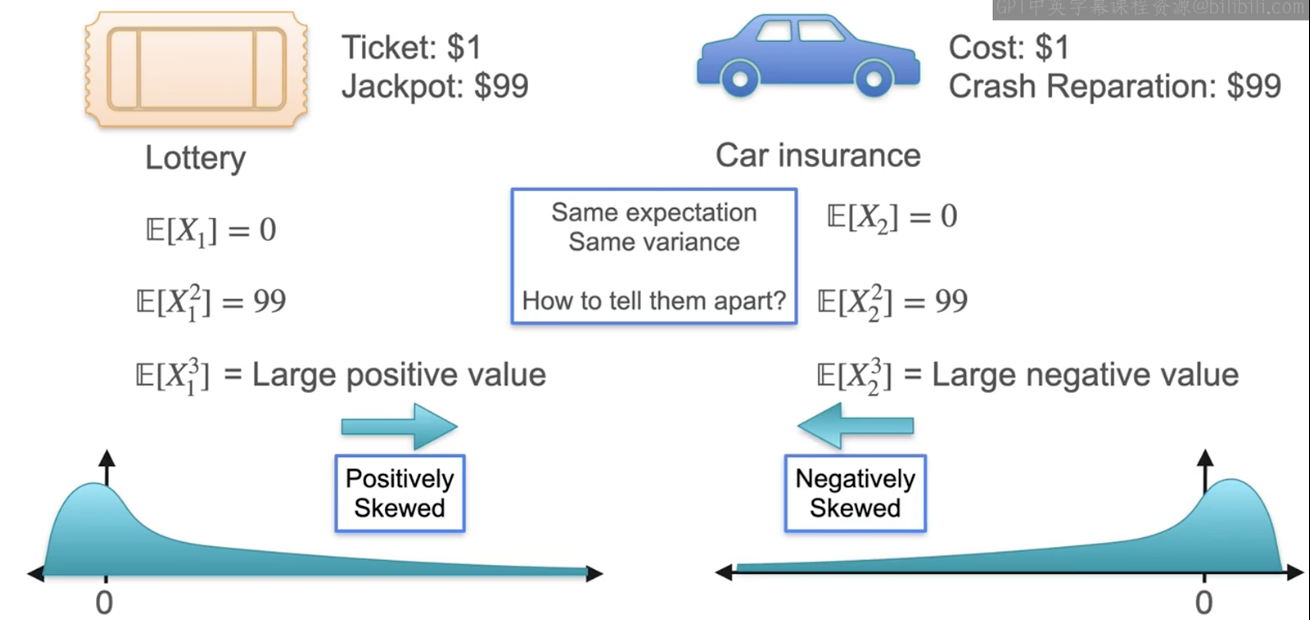
负偏
数值更多的分布在左侧
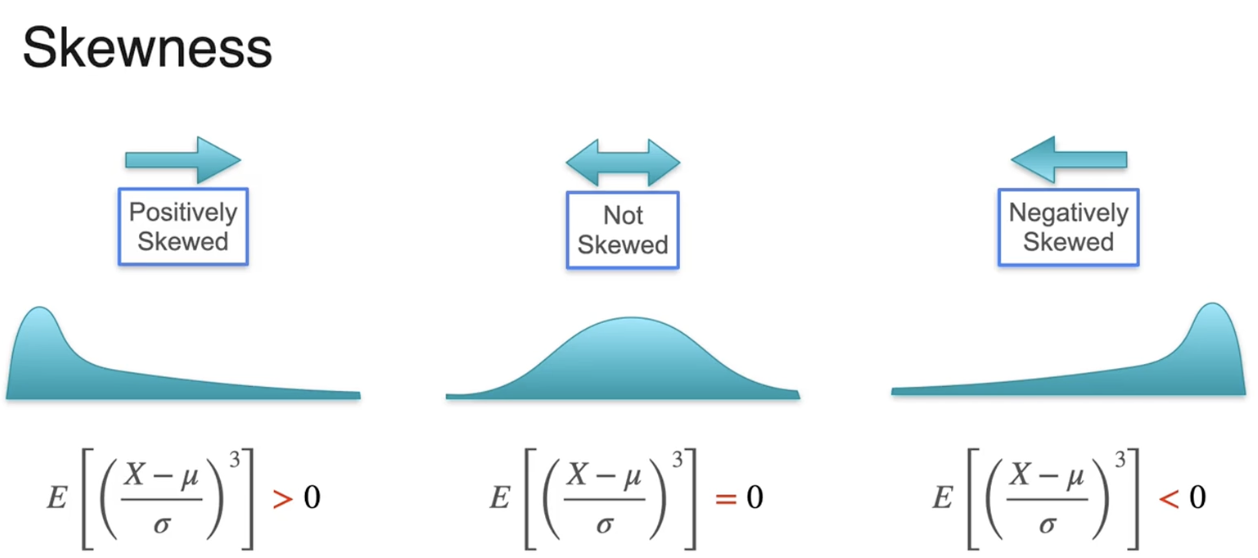
正偏
数值更多的分布在右侧
分布的偏斜程度
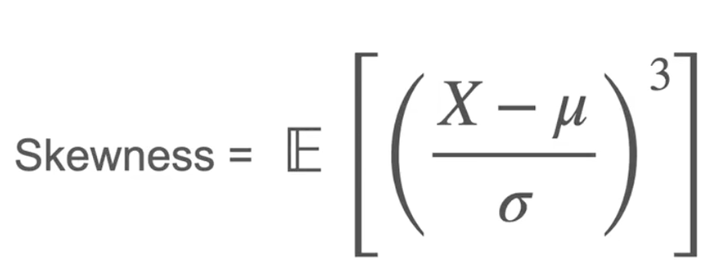
偏度
中心化和标准化的期望值
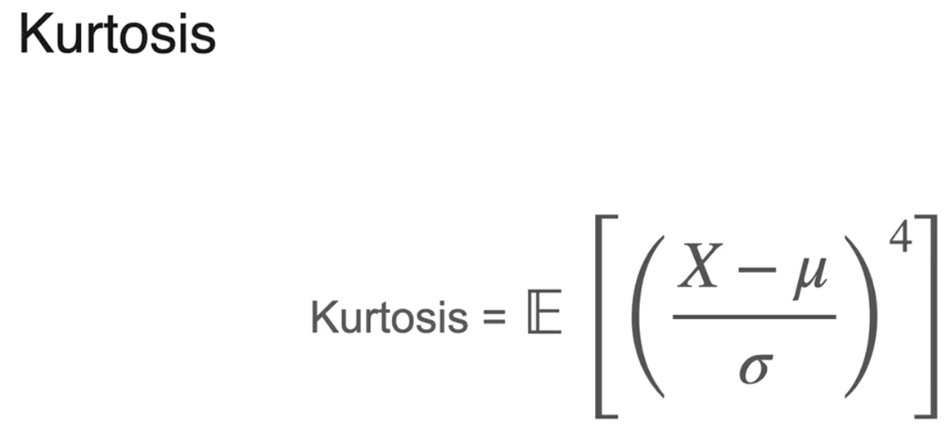
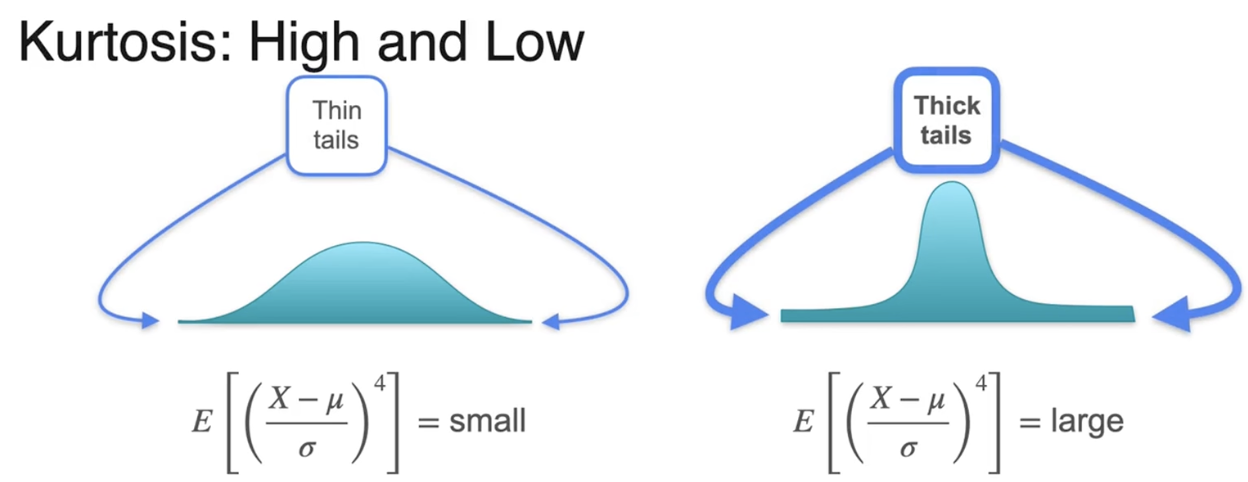
尾部较细,峰度较小
尾部较厚,峰度较大
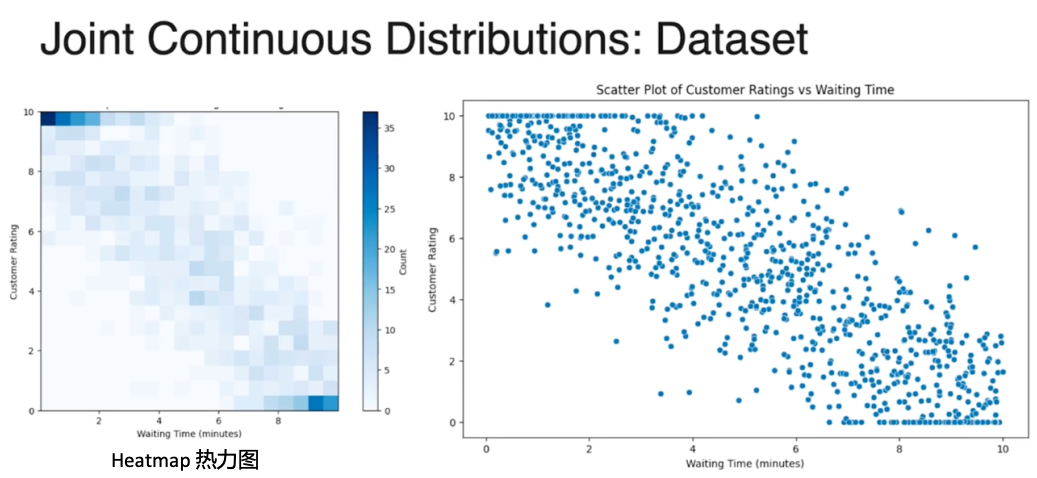
数据可视化的方式

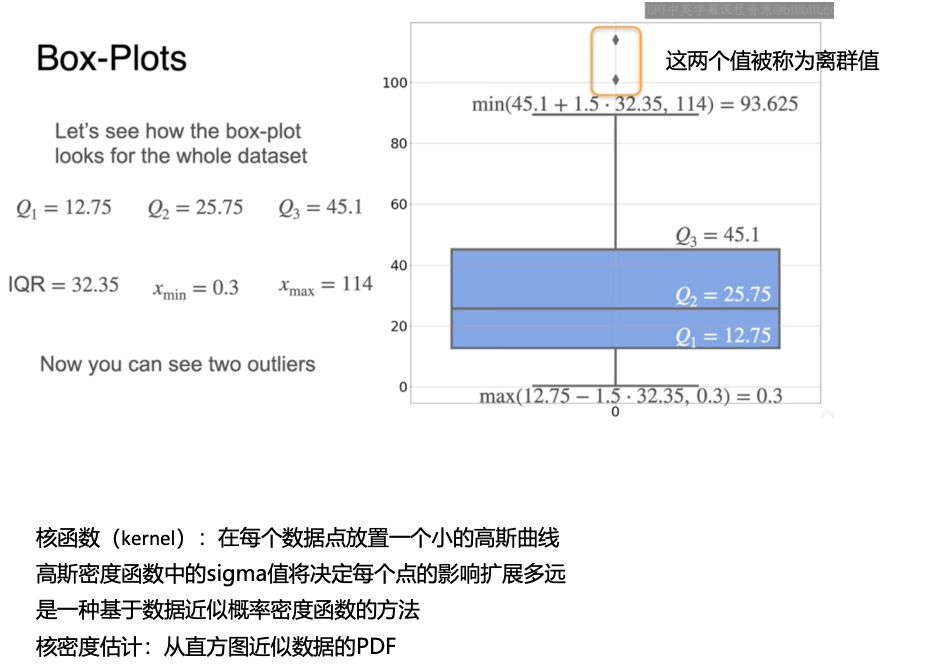
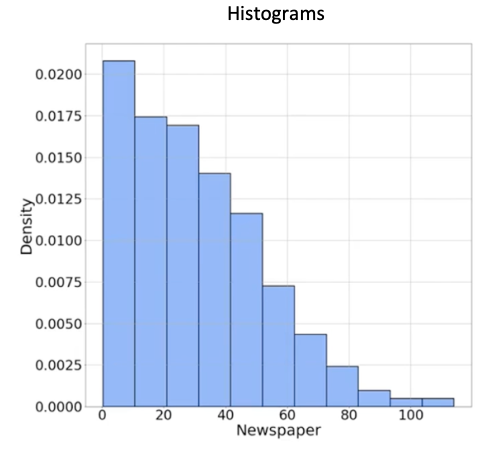
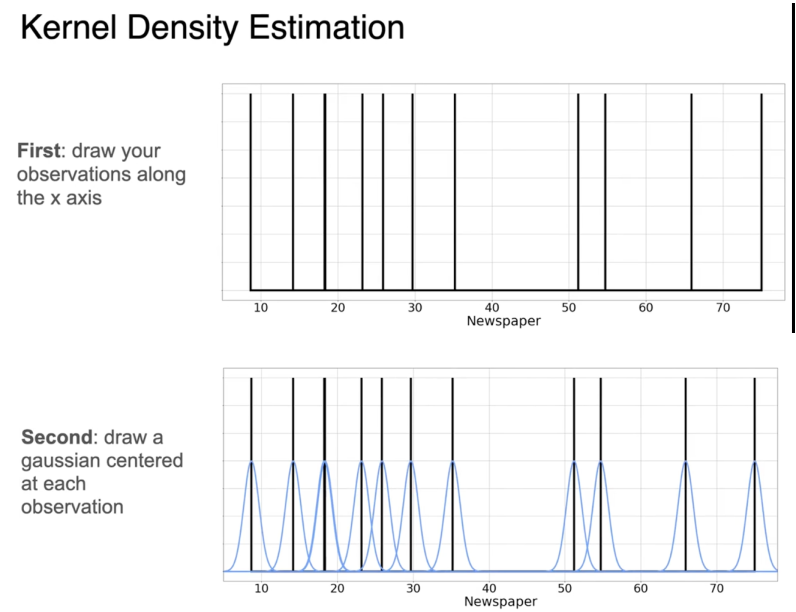
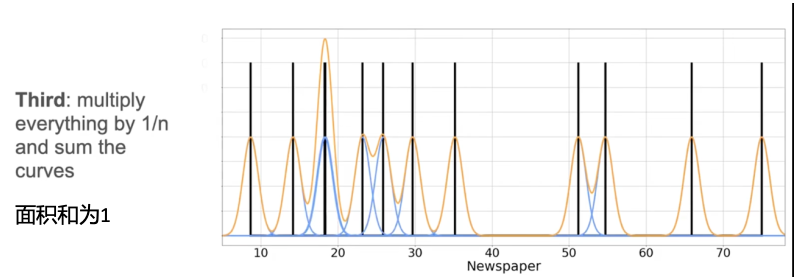
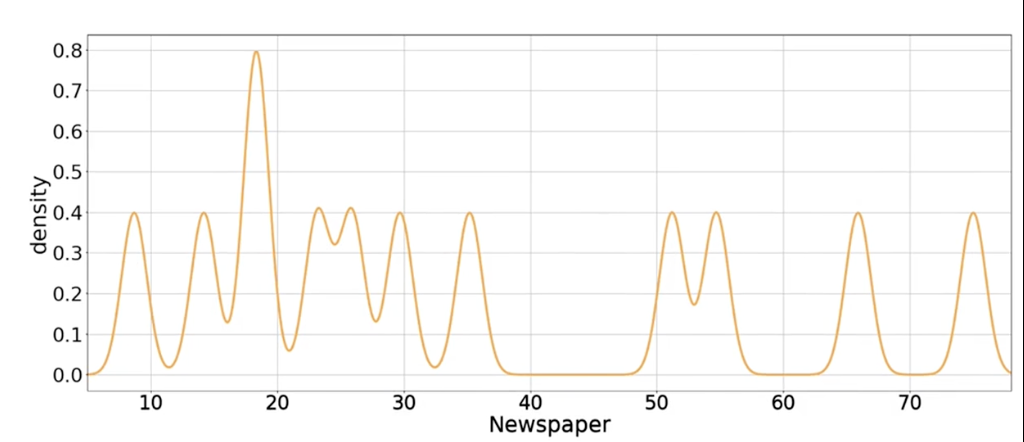
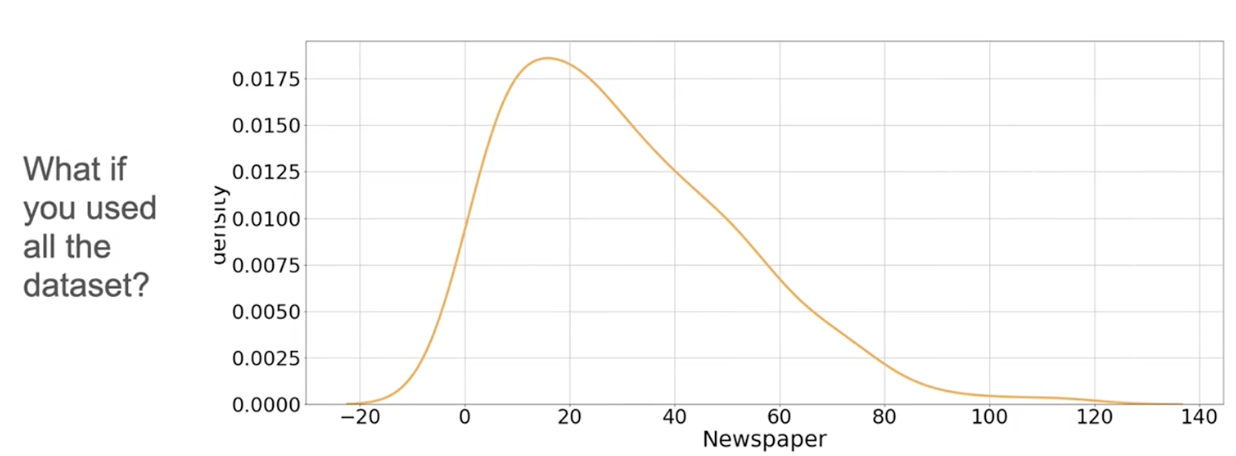
近似PDF
小提琴图:包含了核密度估计和箱线图的信息
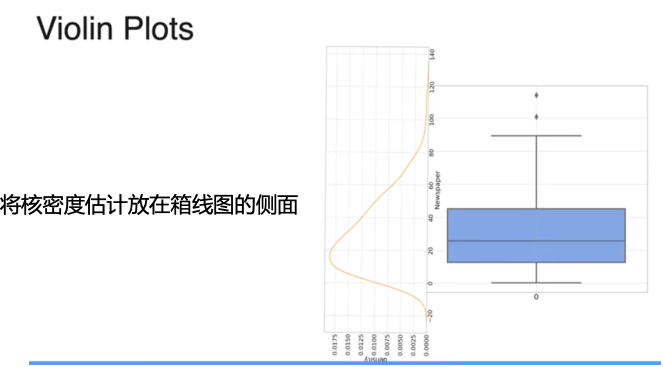
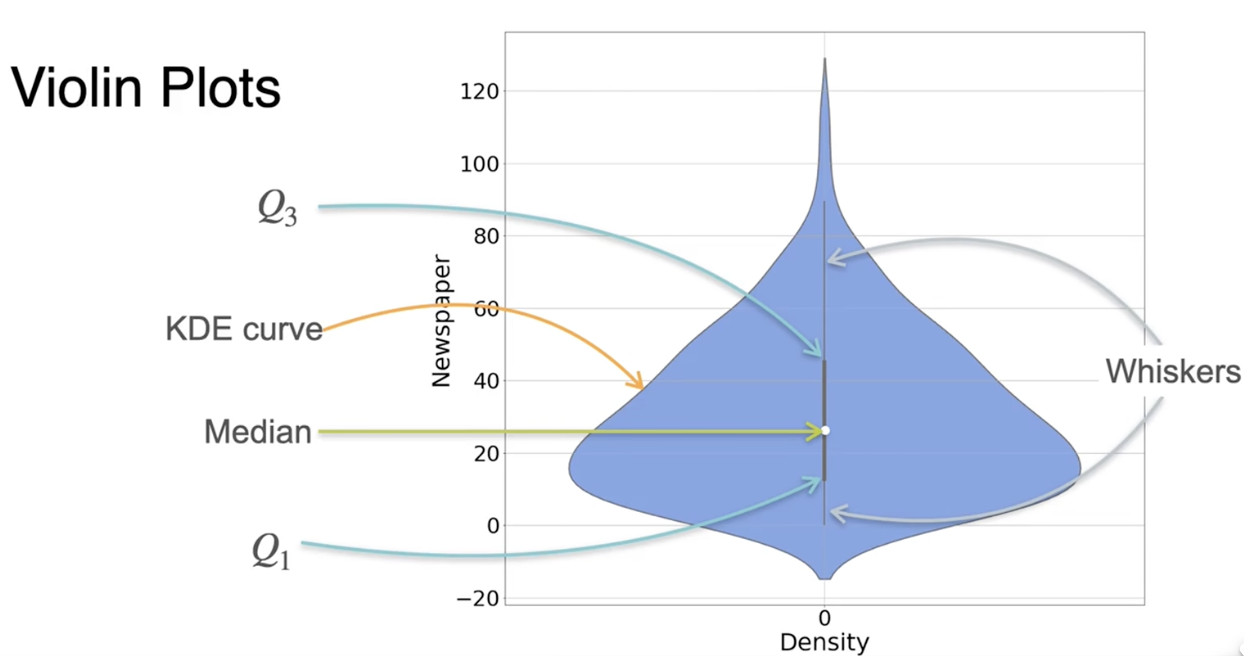

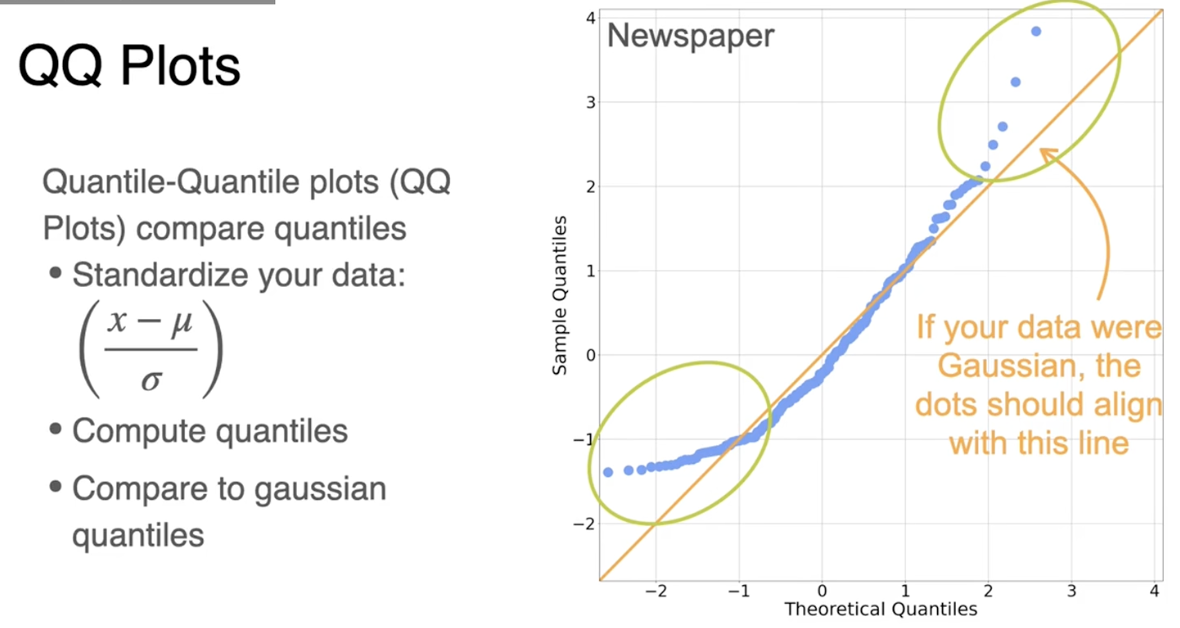

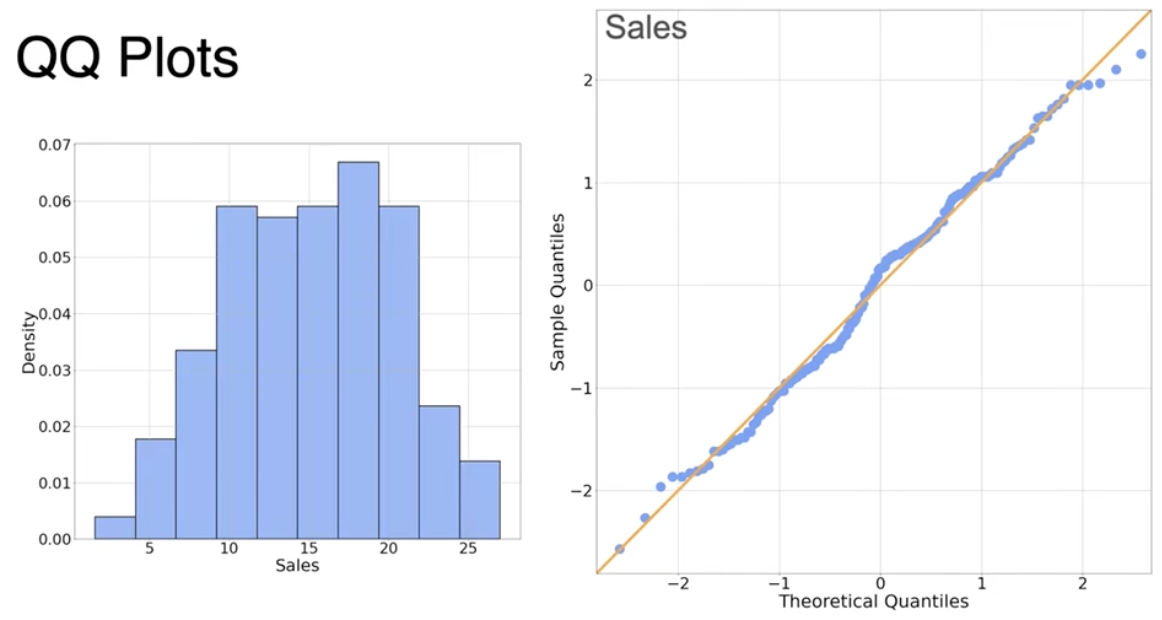
数据呈现高斯分布
联合分布:两个特征的结合
Joint distributions
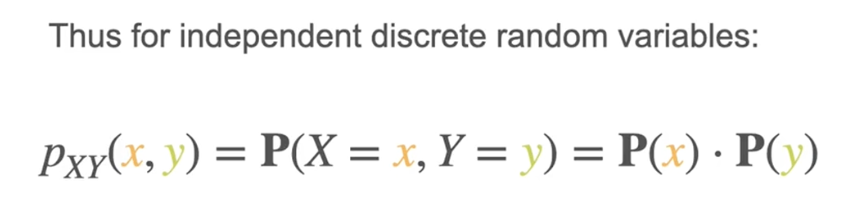
两个离散变量的联合分布
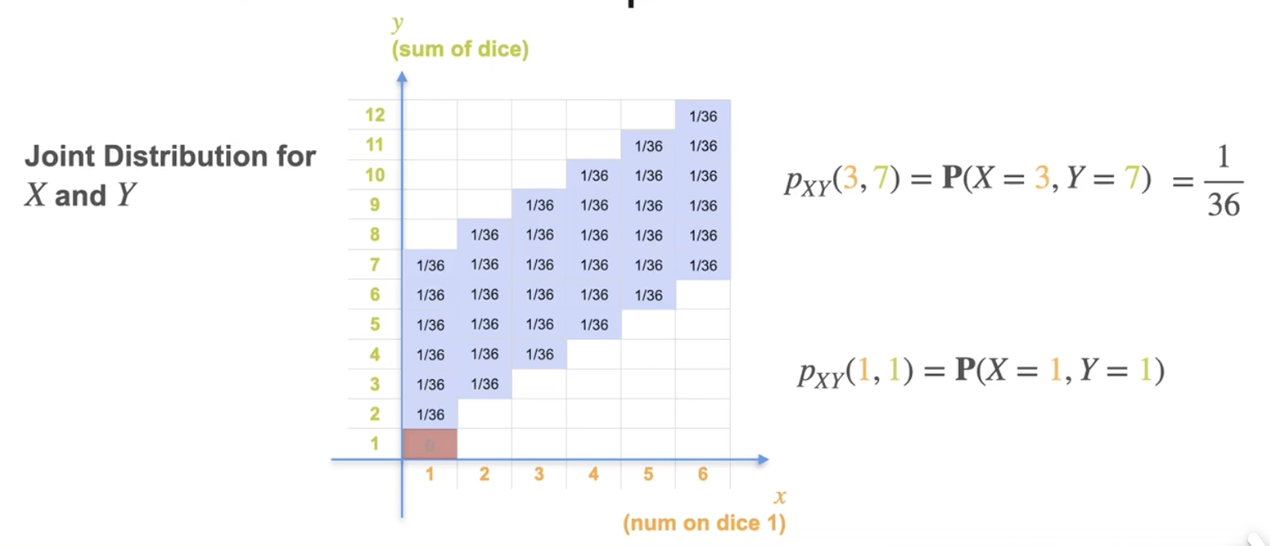
连续变量的联合分布
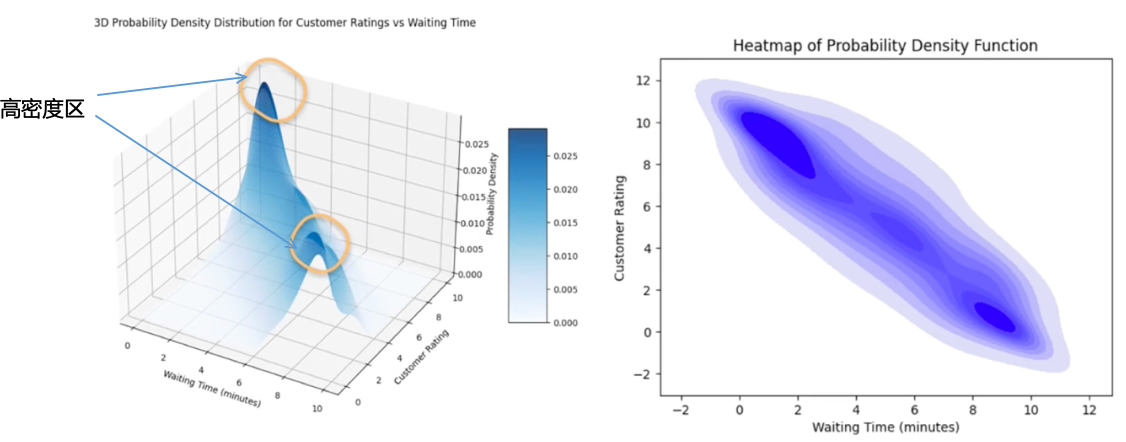

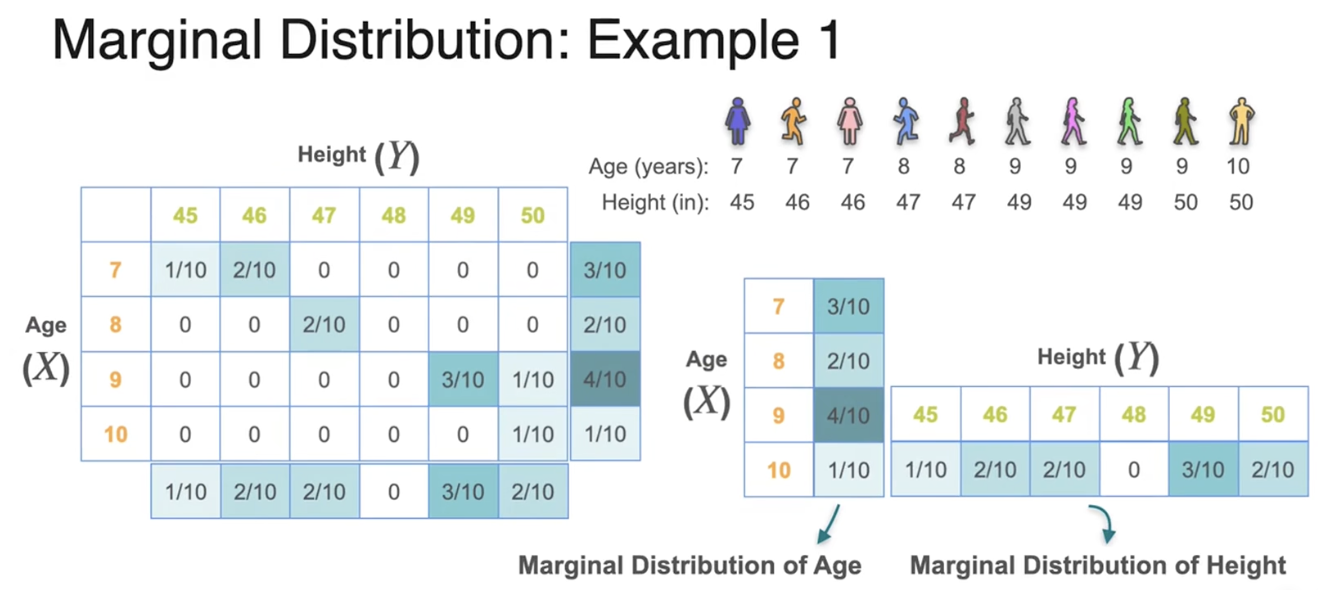
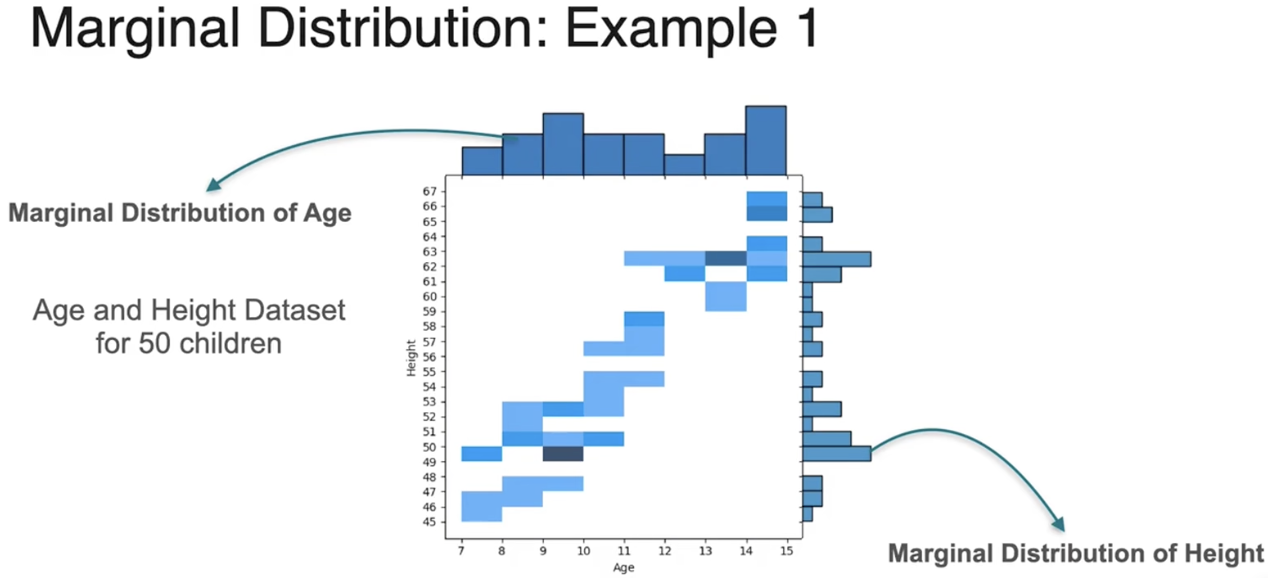
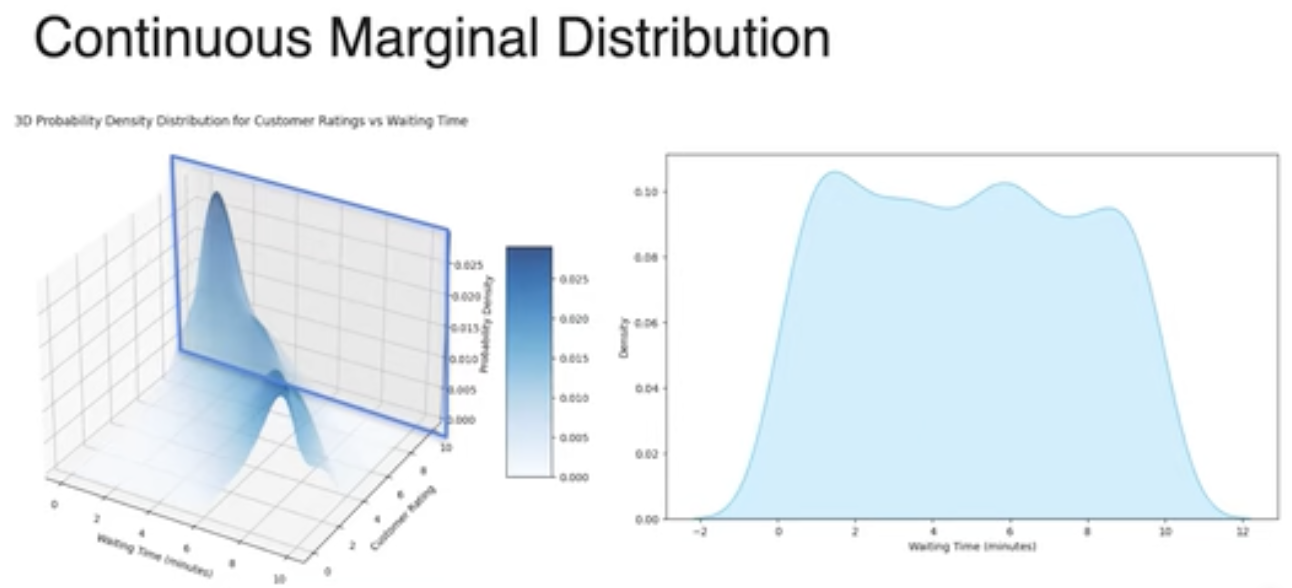
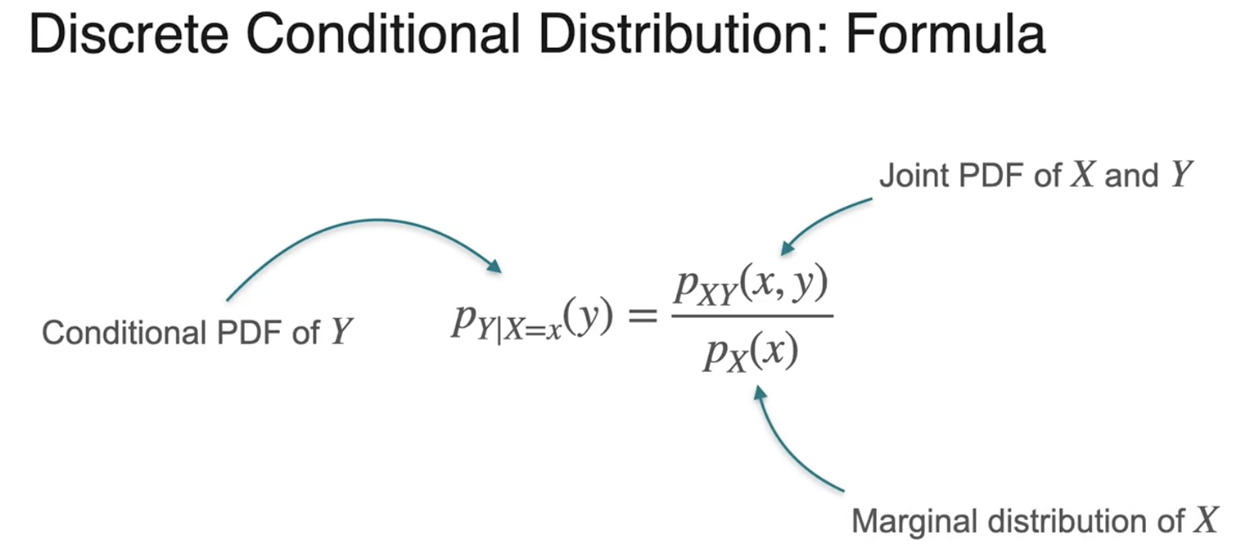
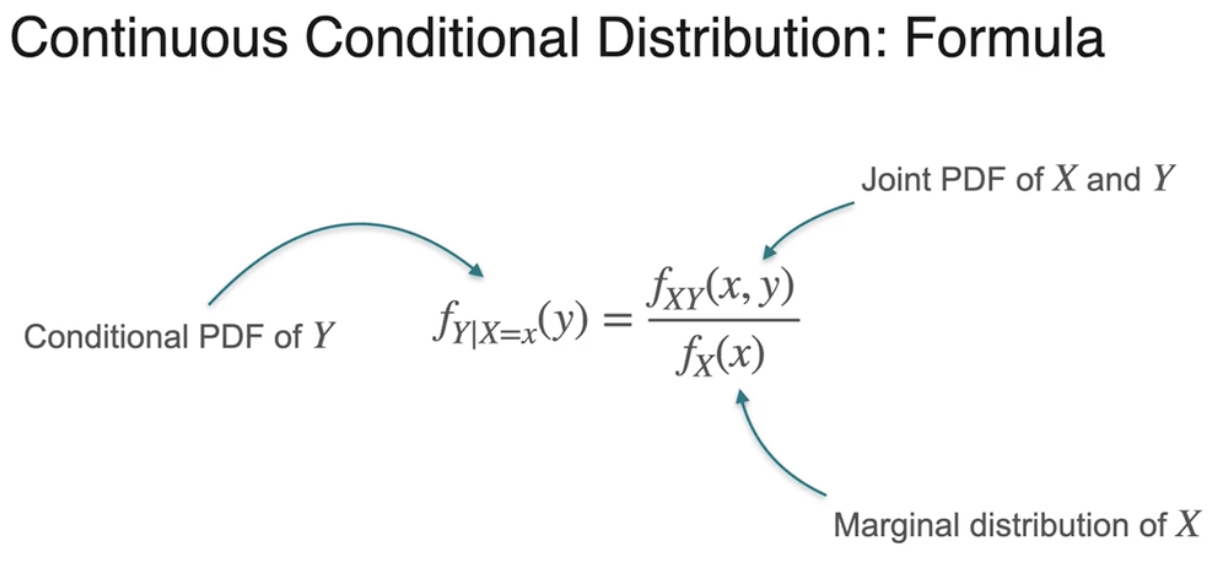
条件分布:固定一个变量,观测另一个变量

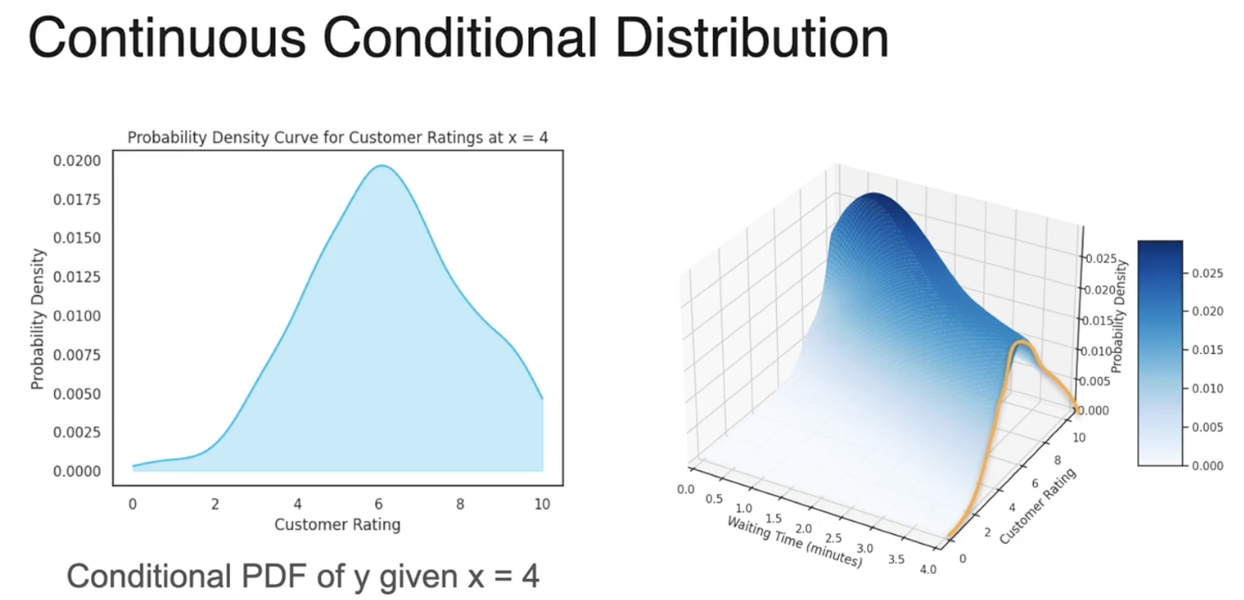
条件概率密度分布
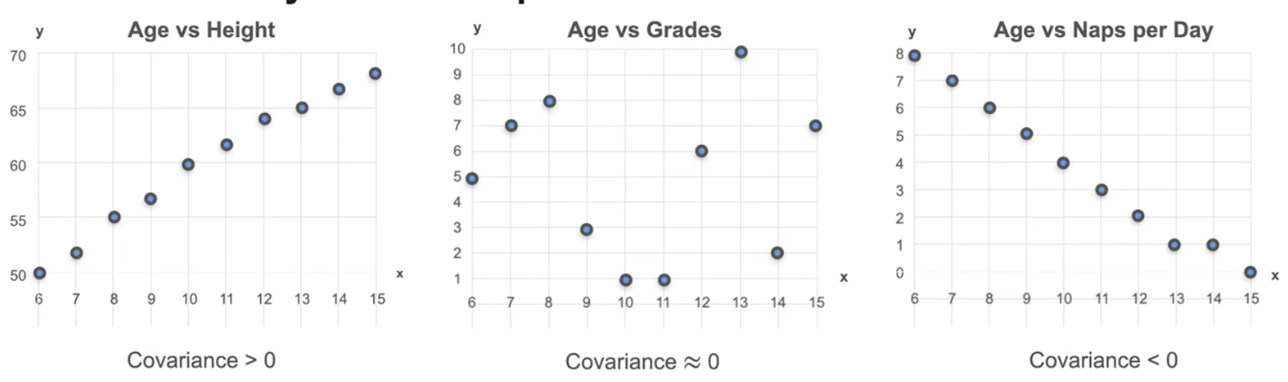
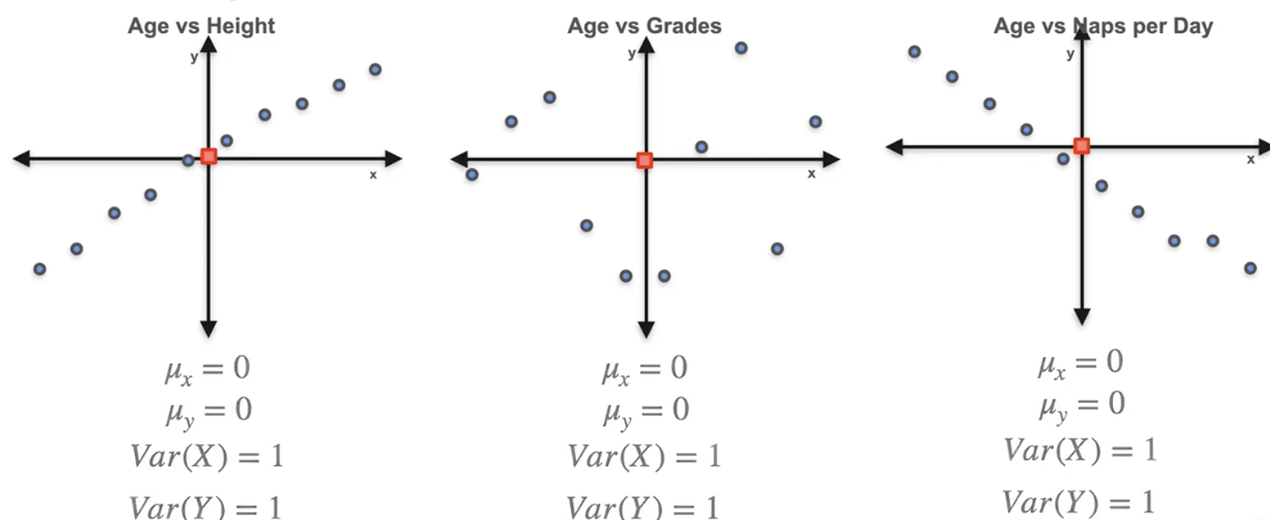
协方差:两个变量之间的关系

Covariance Formula
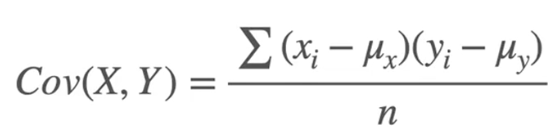
概率分布的协方差

协方差矩阵
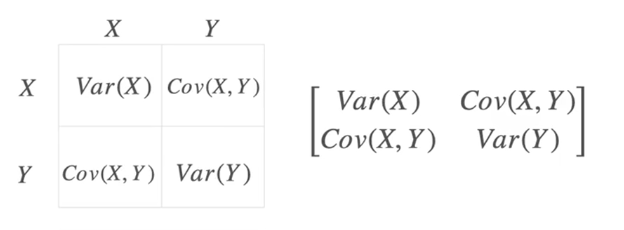
对角线上是方差

Correlation Coefficient 相关系数:协方差的标准化
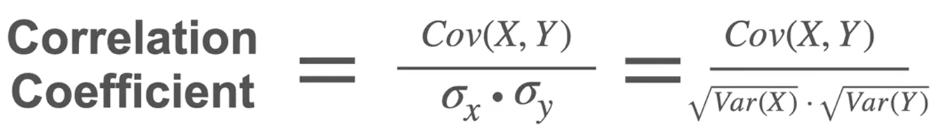
多元高斯分布:多个变量的高斯分布
如果两个变量相互独立,联合概率密度函数 = 两个变量边际概率密度函数的乘积
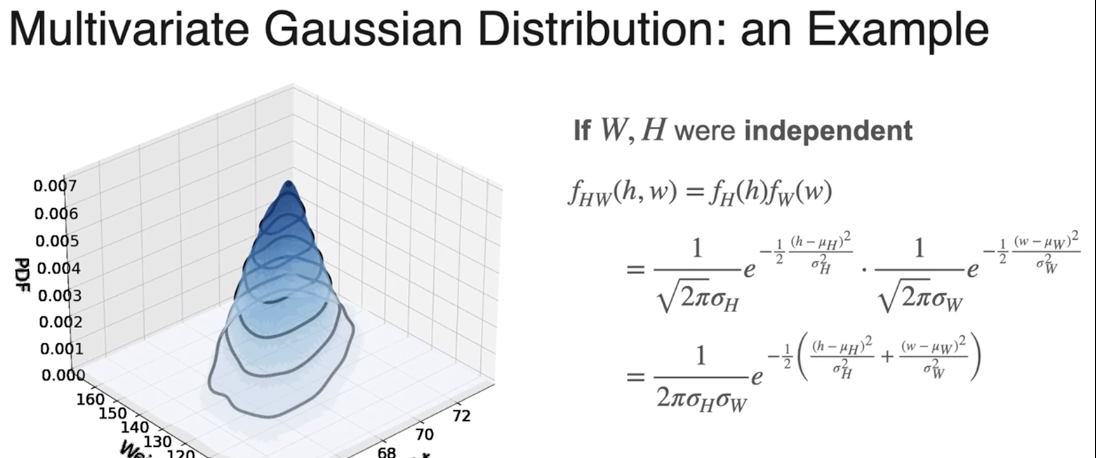

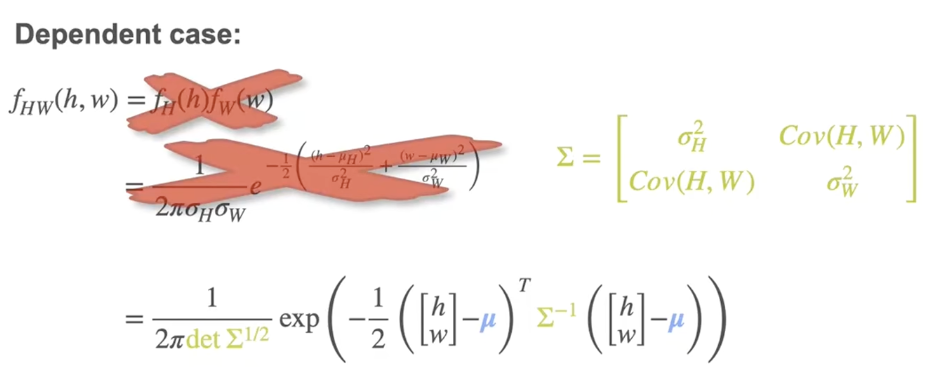
处理多变量分布,所有标量值都被向量取代。标量方差被协方差矩阵取代

 |
|||||
|
总体符号 |
|||||
|
样本大小 |
|||||

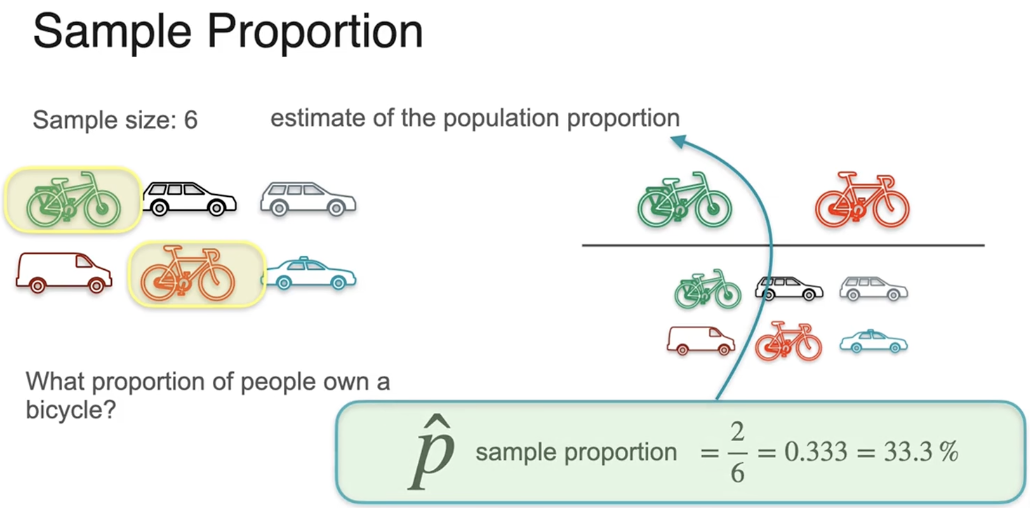
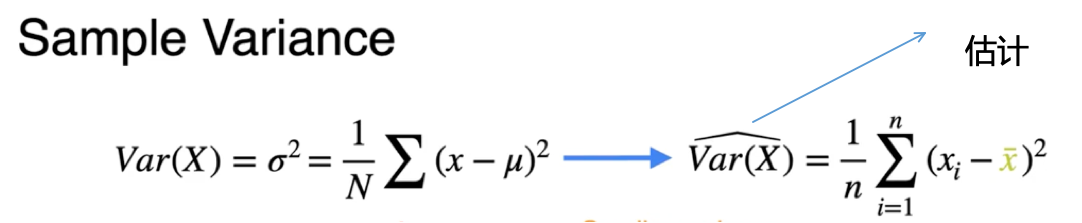
方差估计

 |
|||
|
可以纠正使用样本均值而不是总体均值引入的误差 |
|||
大数据定律

中心极限定理
离散随机变量

连续随机变量
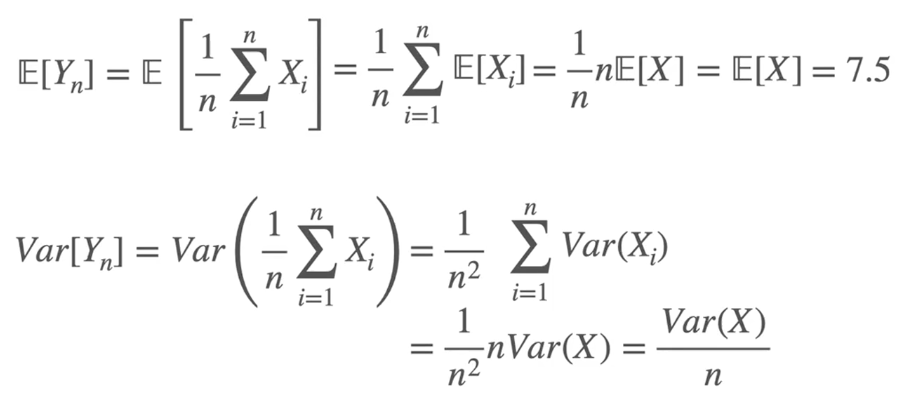
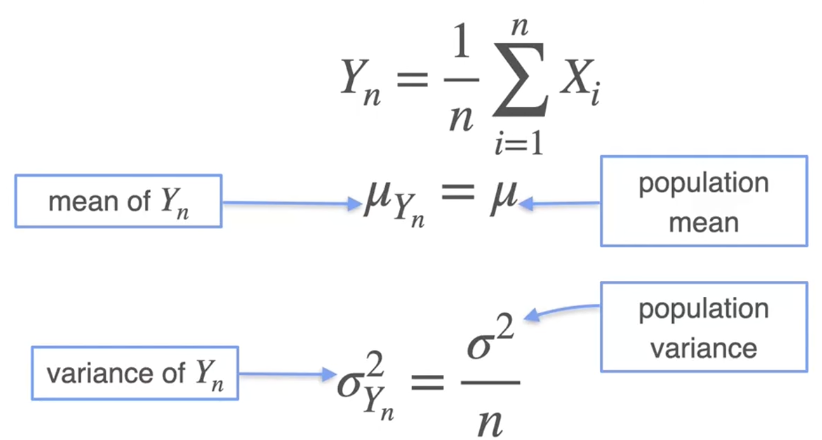

点估计 point estimation:最大似然估计(MLE)
MLE:最大化给定模型的数据的概率
似然是基于模型看到这些数据的概率
取对数:是乘积变成加和的标准方式
MLE:伯努利示例

求导:
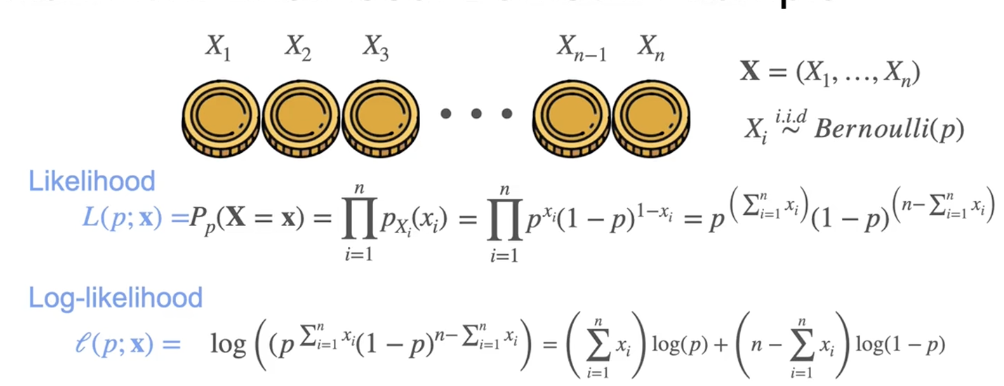
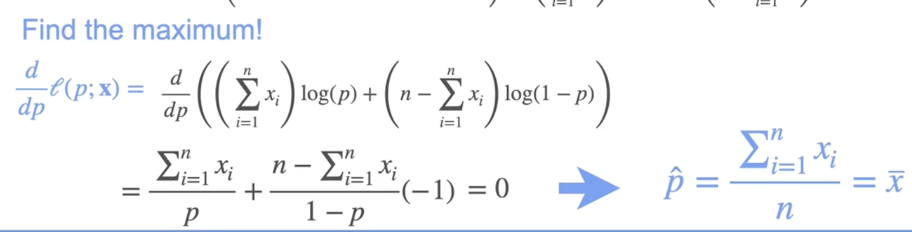
MLE:高斯示例
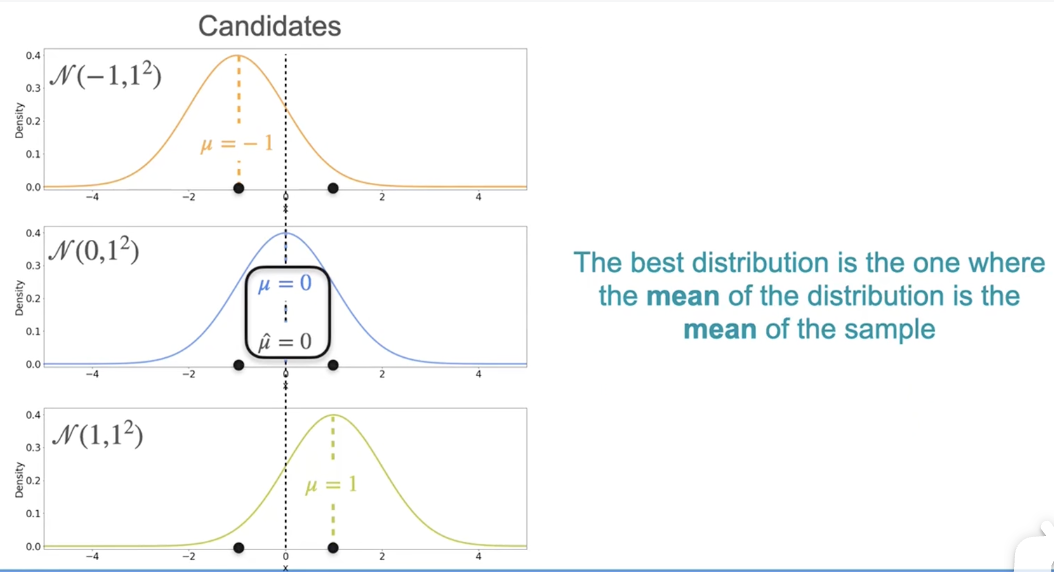
最佳分布是分布的均值 = 样本的均值
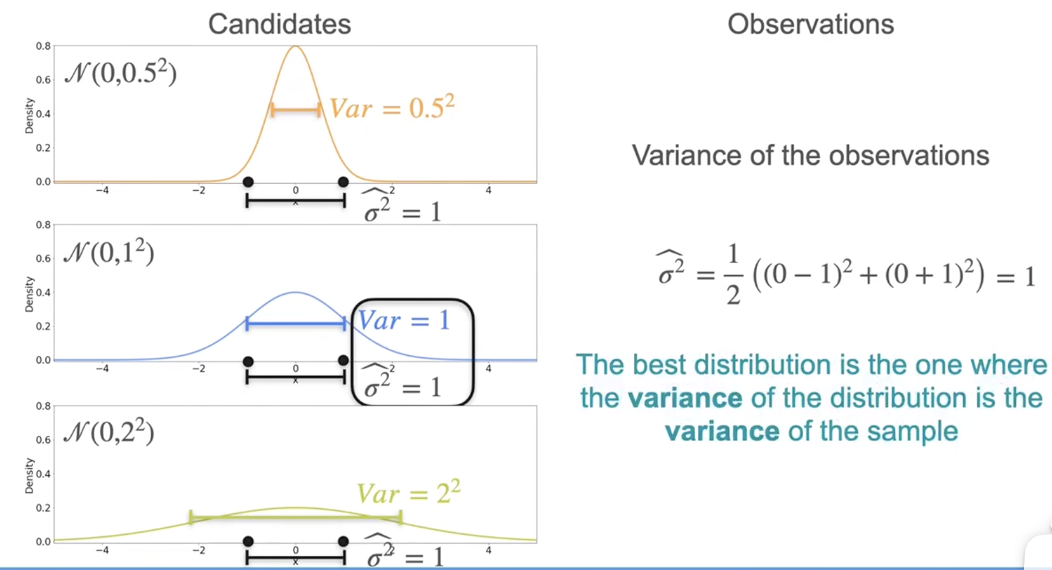
最佳分布是分布的方差 = 样本的方差
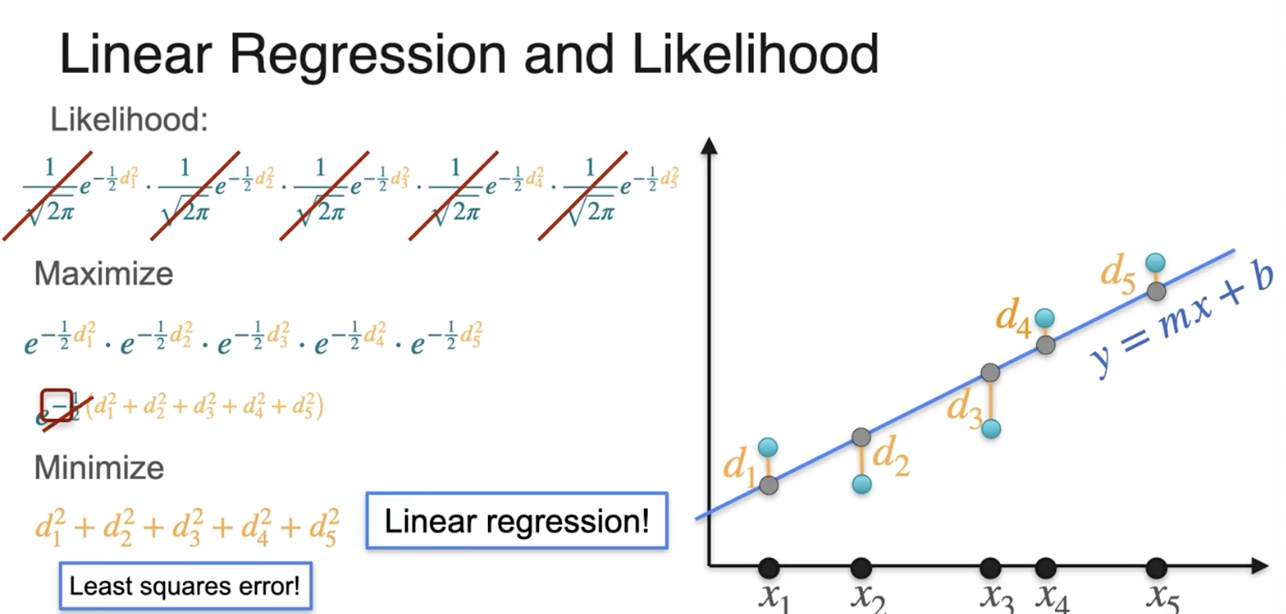
最大似然估计:线性回归
使用最大似然找到最有可能产生点的线 = 使用线性回归最小化二乘误差
找一条“最可能”生成这些点的直线。
最可能 = 最大似然
基于线抽样点:从每个高斯分布中,抽样出点
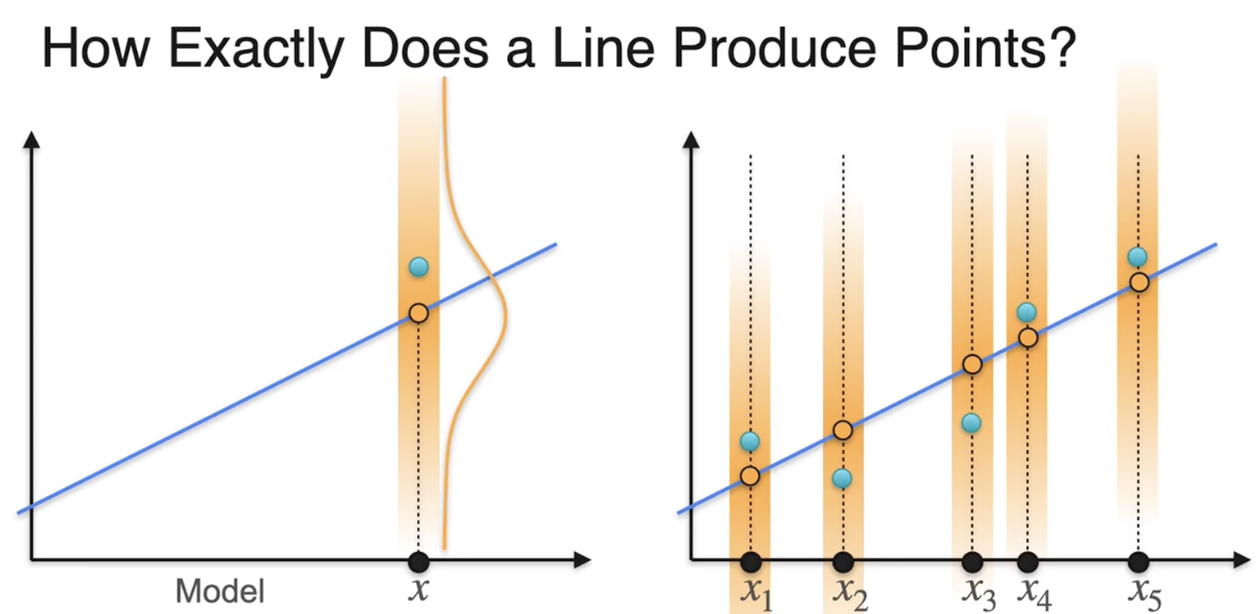
从统计角度(最大化似然)来找,或者从几何角度(让它离点最近)来找
正则化:防止过拟合
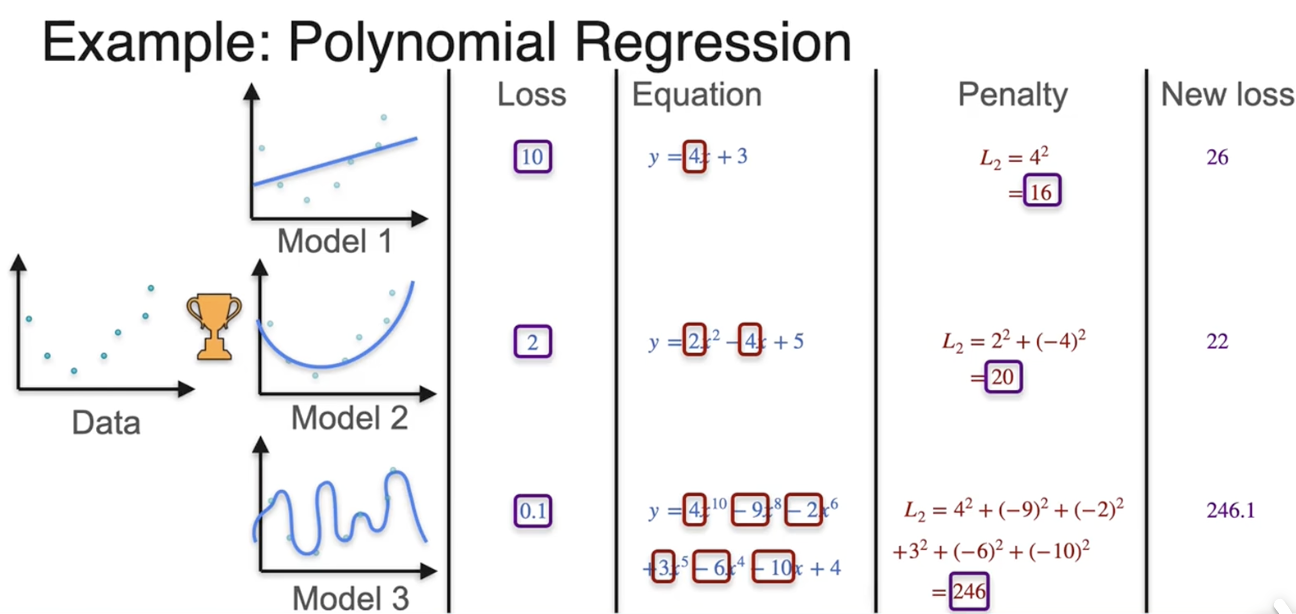
修改损失函数并对过于复杂的模型进行惩罚

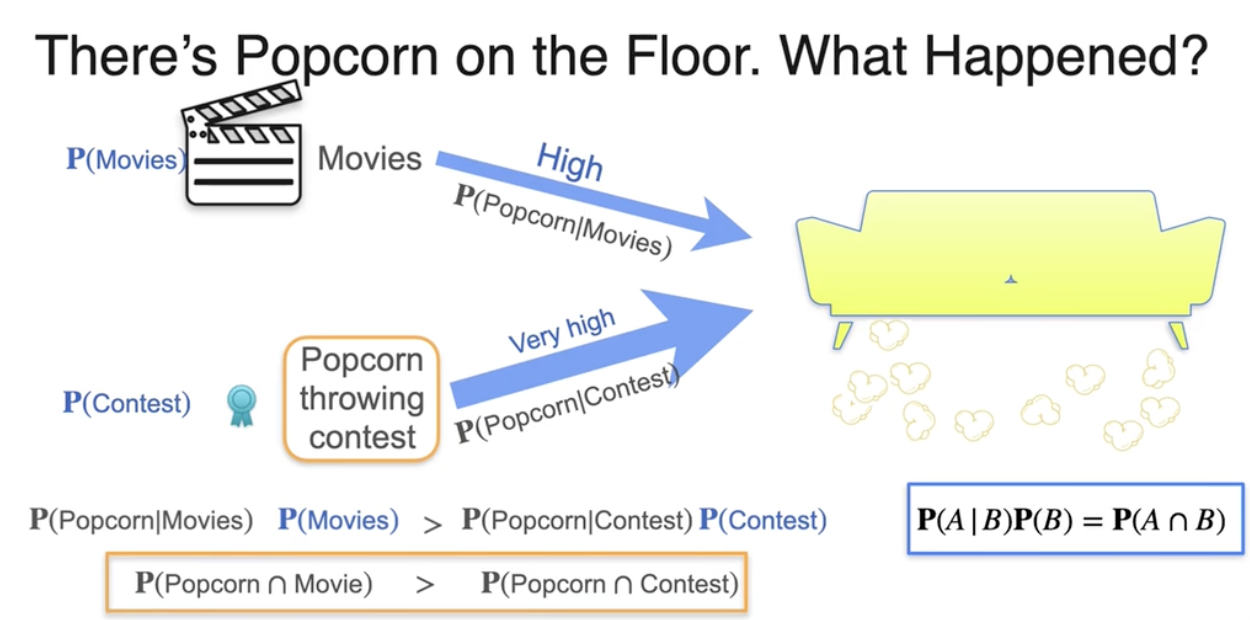

贝叶斯统计:最大后验概率
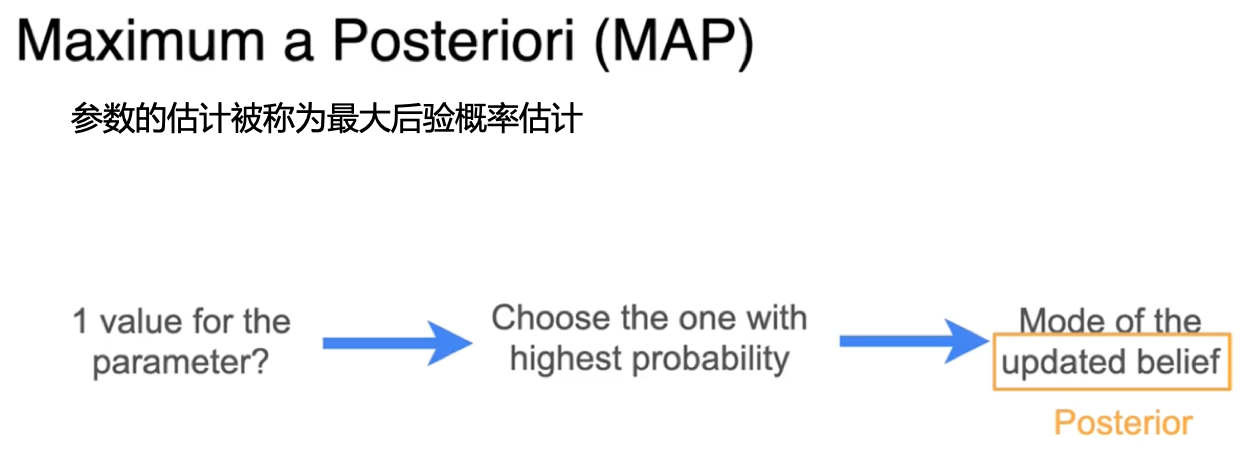
更新后的信念被称为后验
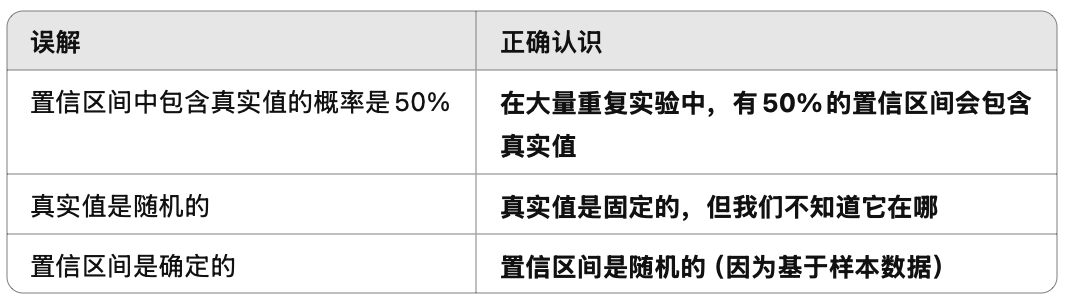
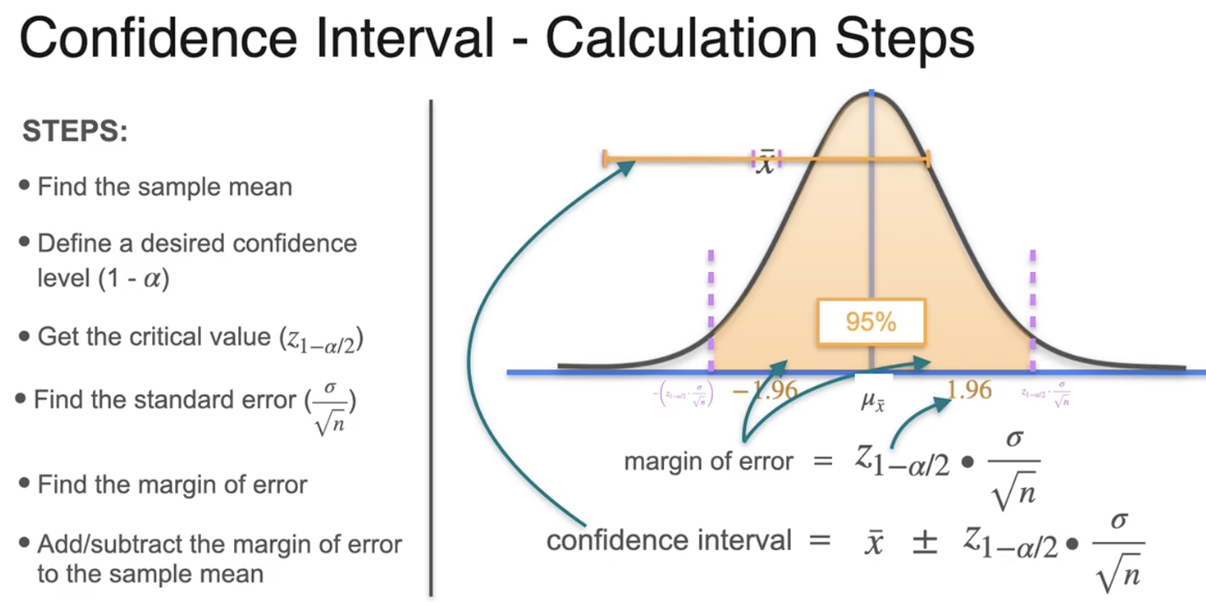
置信区间:以某种程度的确信使用样本均值
置信区间是一个包含总体参数的上限和下限值区间
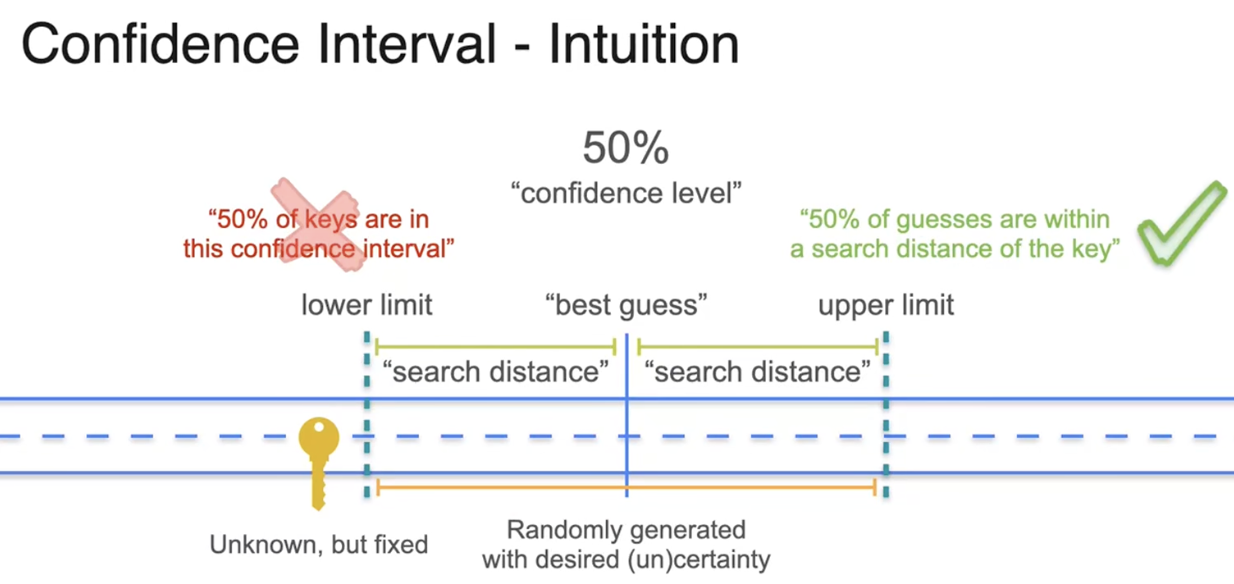
随机生成的样本均值落在误差边界内的概率
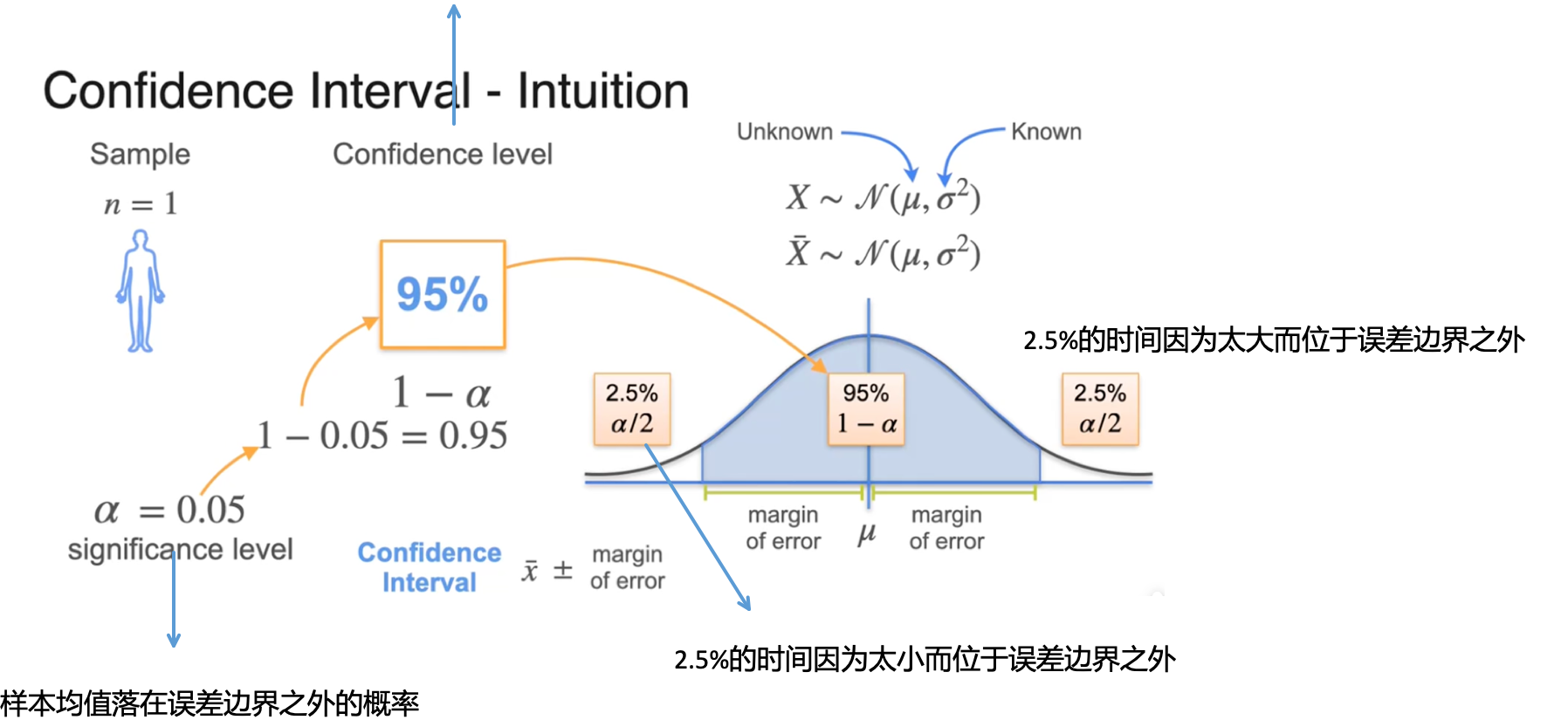
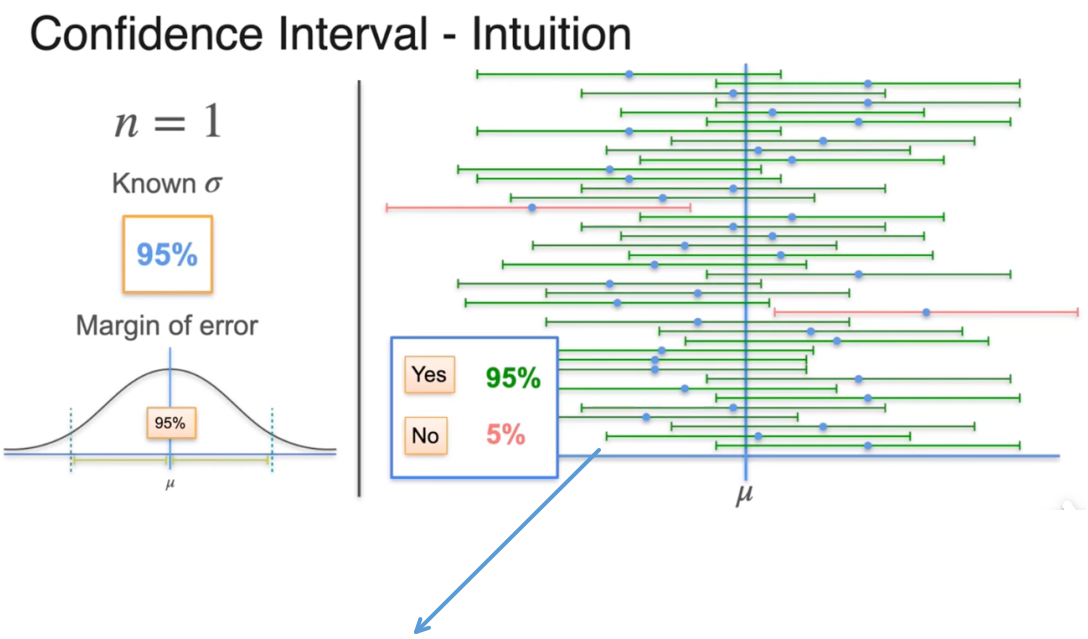
随机生成的置信区间有95%的情况包含总体均值
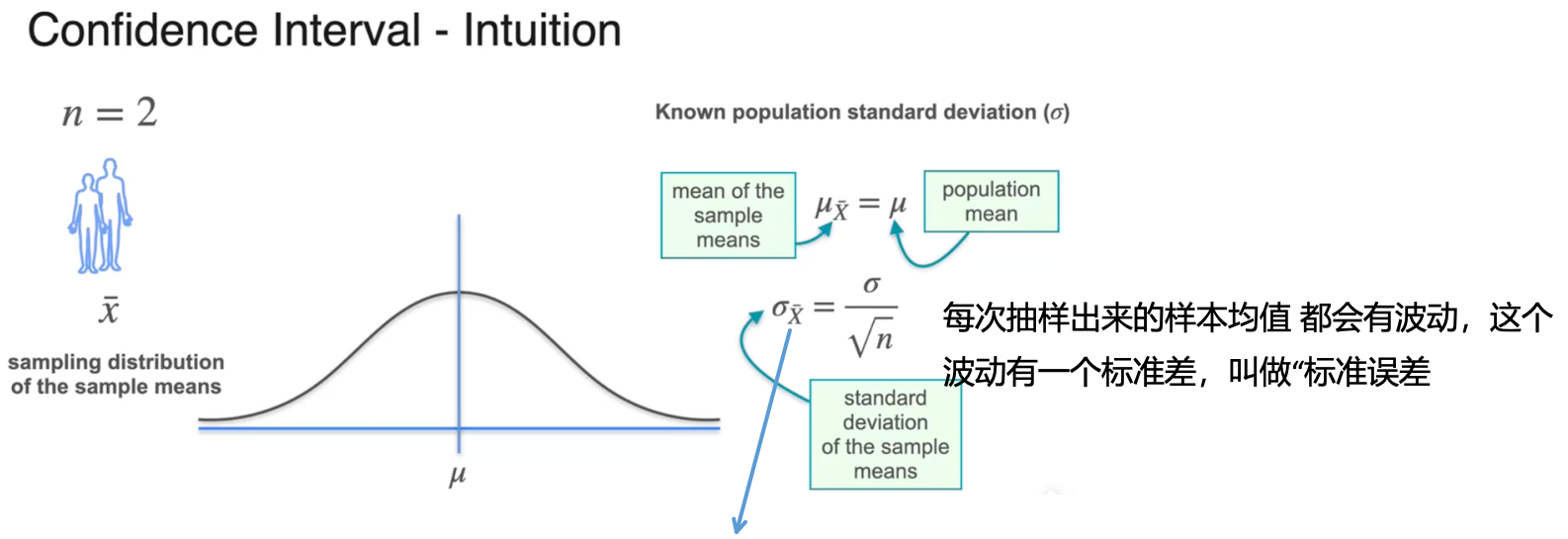

标准差取决于样本大小
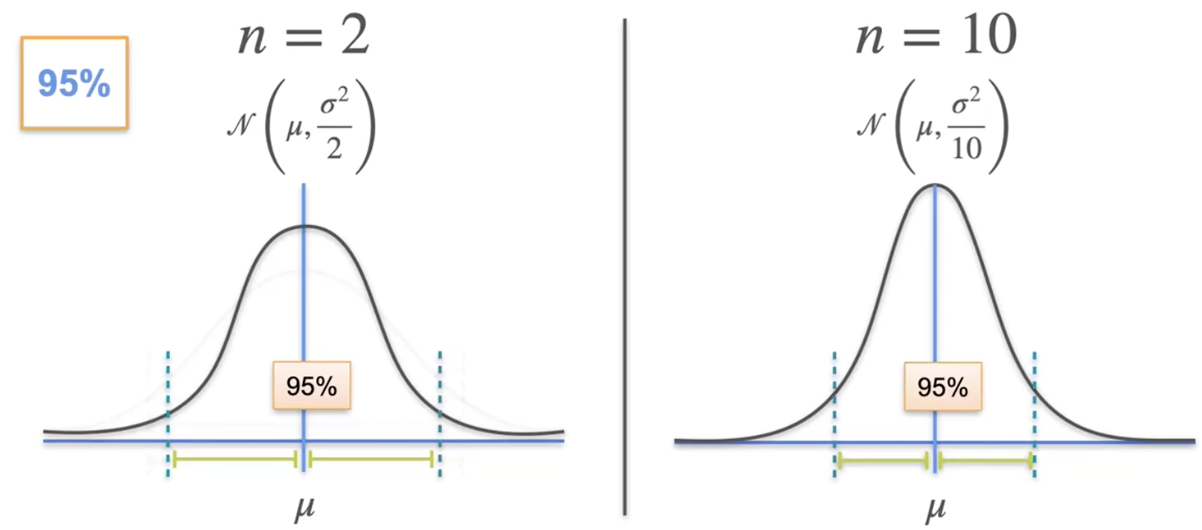
当样本增加,误差边界及其置信区间也会变得更小
随着数据量的增加,在保持相同置信水平的前提下,置信区间会变得更窄,从而可以更精确地估计均值。

Z-score :一个值在它所属分布中距离均值有多少个标准差
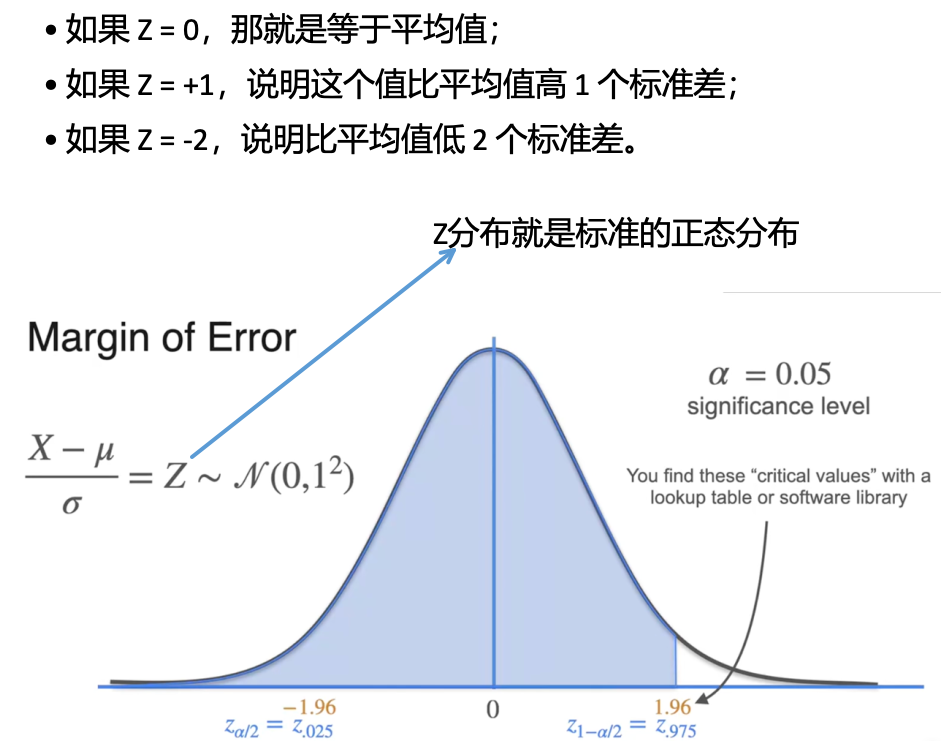
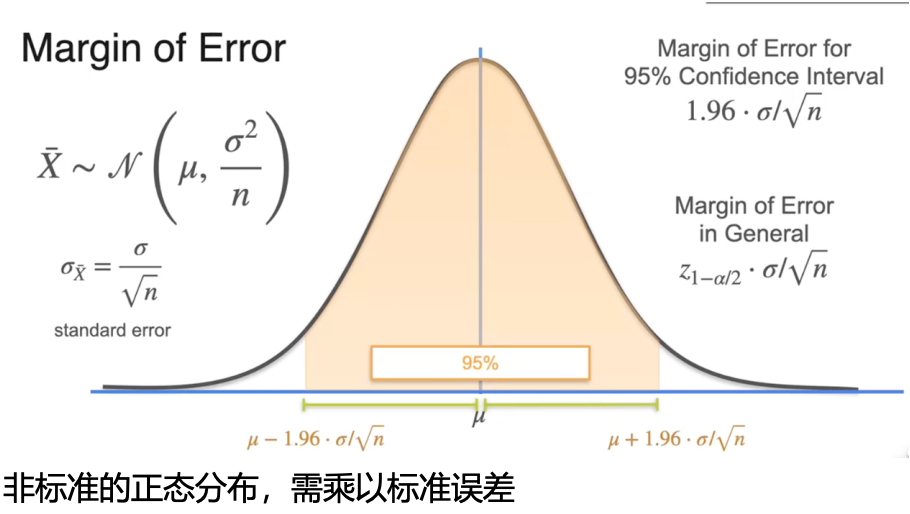
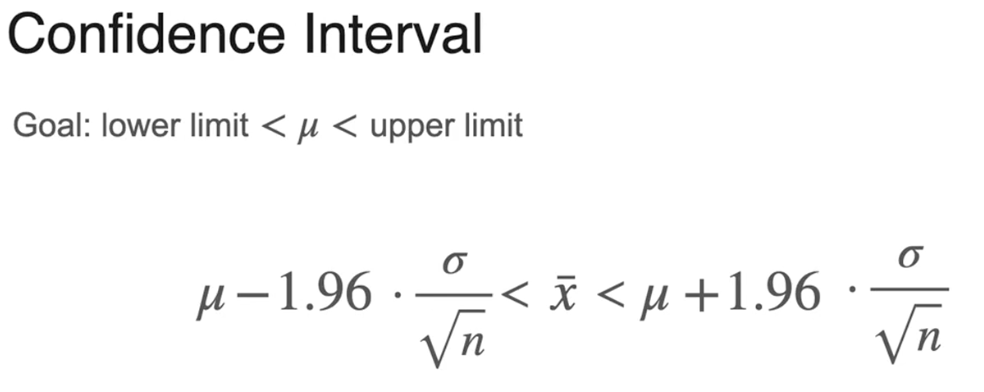
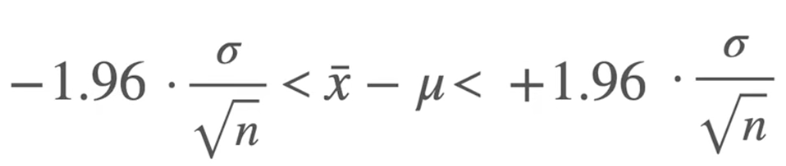
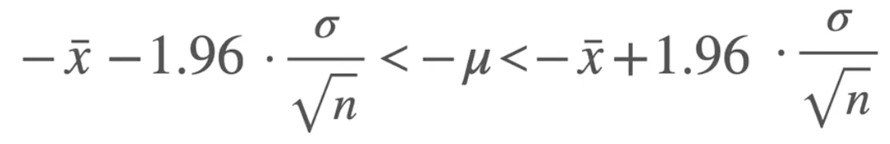
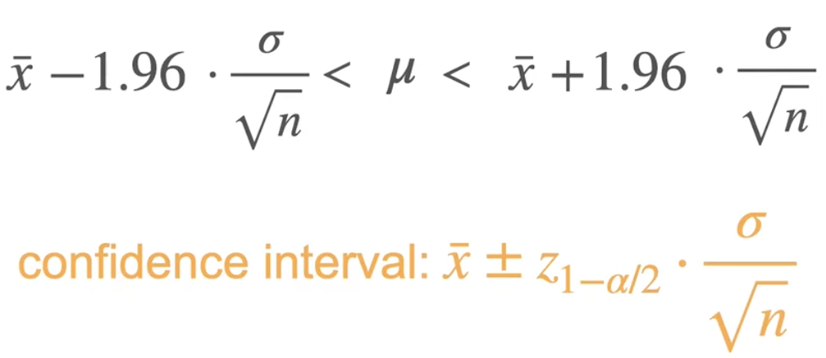
置信区间:计算步骤
应用置信区间时,请确保遵循这些假设条件


openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)