
AT45DB041D闪存芯片驱动程序开发与应用
AT45DB041D是一款由Atmel(现为Microchip技术公司的一部分)生产的4M位串行接口数据闪存芯片,具有业界领先的性能和可靠性。它使用SPI协议与微控制器通信,适用于需要非易失性存储的嵌入式系统。容量与性能:拥有高达4兆比特的存储容量,同时提供2.3至3.6V的工作电压,以及20MHz的时钟频率。接口协议:支持标准SPI模式(0,0),允许在SPI总线上与多个设备共享,提高了系统的灵

简介:AT45DB041D是由Atmel公司推出的串行闪存芯片,适用于嵌入式系统和微控制器应用。本驱动程序专为ATMEL64单片机设计,以实现高效的数据读写。该芯片具有4MB存储空间,支持最高10MHz的SPI通信速率,并具备低功耗、硬件错误校验和高耐用性等特性。驱动开发涉及SPI接口编程、AT45DB041D命令集、数据缓冲管理、错误处理和状态检测、驱动程序设计和软件优化等方面。附带的压缩包文件包含驱动源码、示例应用、库文件和数据手册,帮助开发者在项目中集成和使用AT45DB041D。 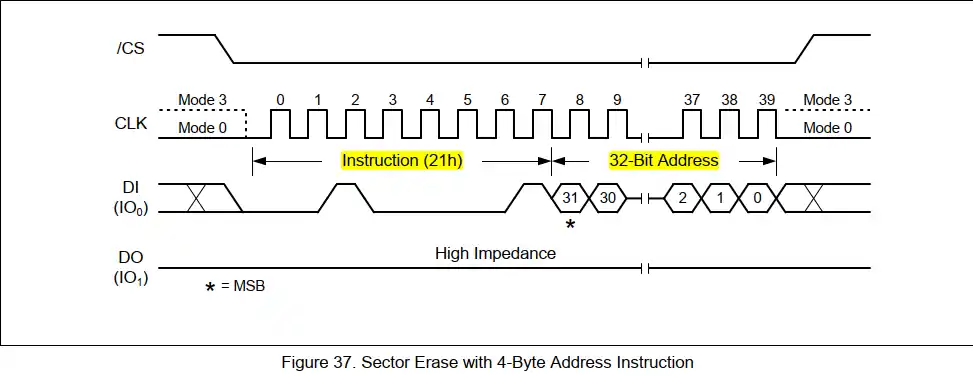
1. AT45DB041D芯片特性
在存储解决方案领域,AT45DB041D以其独特的串行外设接口(SPI)和数据闪存存储能力而受到青睐。本章将介绍该芯片的基本特性,为后续章节中关于编程与应用打下坚实的基础。
1.1 AT45DB041D的概述
AT45DB041D是一款由Atmel(现为Microchip技术公司的一部分)生产的4M位串行接口数据闪存芯片,具有业界领先的性能和可靠性。它使用SPI协议与微控制器通信,适用于需要非易失性存储的嵌入式系统。
1.2 核心特性介绍
- 容量与性能 :拥有高达4兆比特的存储容量,同时提供2.3至3.6V的工作电压,以及20MHz的时钟频率。
- 接口协议 :支持标准SPI模式(0,0),允许在SPI总线上与多个设备共享,提高了系统的灵活性。
- 页面编程与扇区擦除 :提供了页面编程能力和扇区擦除功能,适合频繁读写操作的场景。
通过本章,读者将获得AT45DB041D芯片基础特性的全面理解,并为深入探讨其编程和应用做好准备。接下来的章节将会围绕SPI接口编程和芯片命令集展开,揭示更多技术细节。
2. SPI接口编程
2.1 SPI通信原理及特性
2.1.1 SPI接口的硬件连接和信号线
SPI(Serial Peripheral Interface)是一种常用的串行通信协议,它支持全双工通信,允许微控制器与各种外围设备进行高速数据交换。SPI接口包含四条基本信号线:MISO(主设备输入,从设备输出)、MOSI(主设备输出,从设备输入)、SCK(串行时钟)和CS(片选)。
硬件连接通常如下:
- 主设备的MOSI连接到所有从设备的MOSI。
- 主设备的MISO连接到所有从设备的MISO。
- 主设备的SCK连接到所有从设备的SCK。
- 每个从设备有自己的CS引脚,由主设备控制。
当主设备想要与特定的从设备通信时,它会将对应的CS信号线置低,以此选中该从设备进行数据交换。
flowchart LR
Master[主设备] -->|MOSI|MISO[从设备]
Master -->|MISO|MOSI[从设备]
Master -->|SCK|SCK[从设备]
Master -->|CS|CS[从设备]
信号线的作用如下:
- MOSI:数据从主设备发送到从设备。
- MISO:数据从从设备发送到主设备。
- SCK:同步时钟信号,由主设备产生,用于同步数据的发送和接收。
- CS:片选信号,由主设备控制,用于选择当前通信的从设备。
2.1.2 SPI的工作模式和时序分析
SPI通信支持四种不同的工作模式,这些模式主要由时钟极性和相位来定义。模式0到模式3的区别如下:
- 模式0(CPOL=0, CPHA=0):时钟空闲时为低电平,数据采样在时钟的第一个边沿。
- 模式1(CPOL=0, CPHA=1):时钟空闲时为低电平,数据采样在时钟的第二个边沿。
- 模式2(CPOL=1, CPHA=0):时钟空闲时为高电平,数据采样在时钟的第一个边沿。
- 模式3(CPOL=1, CPHA=1):时钟空闲时为高电平,数据采样在时钟的第二个边沿。
gantt
title SPI时序分析
dateFormat YYYY-MM-DD
section 时钟极性(CPOL)
CPOL_0 [Active Low] :a, 2023-04-01, 2d
CPOL_1 [Active High] :after a, 2d
section 时钟相位(CPHA)
CPHA_0 [Sample at First Edge] :a, 4d
CPHA_1 [Sample at Second Edge] :after a, 2d
时序分析是对时钟周期和数据位的采样与保持时间的分析。这在设计SPI通信时至关重要,以确保数据的正确同步和传输。SPI的时序通常遵循以下规则:
- 在数据传输前,主设备将CS置为有效状态(通常为低电平)。
- 主设备在SCK的第一个有效边沿之前准备好数据位到MOSI。
- 在SCK的每一个有效边沿,数据被从MOSI传输到从设备,或从从设备接收至主设备。
- 数据传输完成之后,主设备将CS置为无效状态(通常为高电平)。
2.2 SPI接口编程基础
2.2.1 SPI驱动的加载与配置
在嵌入式系统中,SPI驱动的加载和配置是通信前的必要步骤。这个过程涉及到内核中SPI驱动模块的加载、SPI设备的注册以及SPI总线的配置。
加载驱动通常通过如下指令完成:
modprobe spi_bcm2835
配置SPI设备一般包含设置设备的速率、模式和位宽等参数。这通常通过编写SPI设备的设备树(Device Tree)或通过sysfs接口进行。
下面是一个简单的设备树配置示例:
spi0@7E204000 {
compatible = "brcm,bcm2835-spi";
reg = <0x7e204000 0x100>;
interrupts = <1 14>;
#address-cells = <1>;
#size-cells = <0>;
cs-gpios = <&gpio 8 0>;
spi-max-frequency = <500000>;
num-chipselect = <1>;
status = "okay";
};
2.2.2 SPI数据传输的基本流程
SPI数据传输流程主要分为几个步骤:
1. 初始化SPI设备。
2. 设置SPI通信的参数,比如速率、模式等。
3. 通过SPI总线发送数据或命令。
4. 数据传输结束后,关闭或释放SPI设备。
数据传输的代码示例如下:
#include <linux/spi/spi.h>
struct spi_device *spi_device;
struct spi_transfer transfer = {
.tx_buf = (void *)data_to_send,
.len = sizeof(data_to_send)
};
int ret;
// 初始化SPI设备
spi_device = spi_setup_device();
// 设置SPI通信参数
spi_device->max_speed_hz = 1000000;
spi_device->bits_per_word = 8;
spi_device_setup_mode(spi_device);
// 发送数据
ret = spi_sync_transfer(spi_device, &transfer, 1);
// 关闭SPI设备
spi_unregister_device(spi_device);
2.3 SPI高级编程技术
2.3.1 主从模式下的数据交换
在SPI通信中,主从模式允许一个主设备与多个从设备进行通信。主设备通过控制CS信号来选择特定的从设备。每个从设备都拥有自己的CS信号,通过这个信号,主设备可以实现对不同从设备的独立寻址。
CS信号的控制是通过GPIO(通用输入输出)引脚实现的。在编程中,可以使用诸如 gpio_request 和 gpio_direction_output 函数来申请和配置GPIO引脚。
下面是如何配置和使用GPIO的示例:
int gpio = ...; // 某个GPIO引脚
int cs_active_value = ...; // CS有效值,通常为0
// 申请GPIO引脚
ret = gpio_request(gpio, "spi-cs");
if (ret) {
printk(KERN_ERR "Failed to request GPIO pin %d\n", gpio);
return ret;
}
// 设置GPIO为输出模式
ret = gpio_direction_output(gpio, !cs_active_value);
if (ret) {
printk(KERN_ERR "Failed to set GPIO pin %d as output\n", gpio);
gpio_free(gpio);
return ret;
}
// 激活从设备
gpio_set_value(gpio, cs_active_value);
// 执行数据传输...
// 停用从设备
gpio_set_value(gpio, !cs_active_value);
// 释放GPIO引脚
gpio_free(gpio);
2.3.2 多个SPI设备的管理策略
当系统中有多个SPI设备时,管理这些设备的关键在于合理规划它们的地址和资源,以及有效地处理并发访问和数据交换。合理分配片选信号,确保主设备能够准确地与目标从设备通信。
管理策略包括:
- 使用不同的片选信号管理不同的从设备。
- 避免片选信号之间的冲突,例如,确保在任何时候只有一个片选信号有效。
- 如果使用硬件CS,通过配置不同的GPIO引脚来控制不同的从设备。
一个简单的从设备管理示例代码如下:
for (int i = 0; i < num_slaves; i++) {
struct spi_device *spi_dev;
int gpio_cs = ...; // 第i个从设备的CS引脚
int cs_active_value = ...; // CS有效值
// 获取GPIO
if (gpio_request(gpio_cs, "spi-cs")) {
printk(KERN_ERR "Failed to request GPIO pin %d\n", gpio_cs);
continue;
}
// 设置GPIO为输出
if (gpio_direction_output(gpio_cs, !cs_active_value)) {
printk(KERN_ERR "Failed to set GPIO pin %d as output\n", gpio_cs);
gpio_free(gpio_cs);
continue;
}
// 创建SPI设备实例并添加到系统
spi_dev = spi_register_board_info(...);
if (!spi_dev) {
printk(KERN_ERR "Failed to register SPI device\n");
continue;
}
}
以上章节对SPI接口通信的原理与特性、基础编程方法以及高级管理策略进行了详细介绍。从硬件连接到信号线的设置,再到驱动程序的加载与配置,每个环节都有详细的解释和示例代码,确保了读者对SPI通信有一个系统而深入的理解。
3. AT45DB041D命令集应用
3.1 AT45DB041D基本命令介绍
3.1.1 常用读写操作命令
AT45DB041D是Atmel公司推出的一款串行Flash存储器,广泛应用于嵌入式系统中。它提供了一套完整的命令集来执行基本的读写操作。执行读写操作前,需要发送适当的命令序列到AT45DB041D的SPI接口。例如,向Flash写入数据的基本步骤如下:
// 写使能
void write_enable() {
spi_transfer(CMD_WRITE_ENABLE); // 发送写使能命令0x06
}
// 写入数据到主缓冲区1或2
void write_to_main_buffer(uint8_t buf_num, uint16_t addr, uint8_t *data, uint16_t size) {
uint8_t cmd[4];
cmd[0] = buf_num ? CMD_WRITE_MAIN_BUFFER2 : CMD_WRITE_MAIN_BUFFER1; // 选择主缓冲区1或2
cmd[1] = (uint8_t)(addr >> 8); // 地址高8位
cmd[2] = (uint8_t)addr; // 地址低8位
cmd[3] = size - 1; // 写入字节数
write_enable(); // 发送写使能
spi_transfer(cmd, 4); // 发送写命令和地址信息
spi_transfer(data, size); // 写入数据
}
// 从主缓冲区写数据到存储器数组
void main_buffer_to_memory(uint8_t buf_num) {
spi_transfer(buf_num ? CMD_MAIN_BUFFER2_TO_MEMORY : CMD_MAIN_BUFFER1_TO_MEMORY); // 发送传输命令
}
在上述示例代码中, spi_transfer 函数用于通过SPI接口发送数据。 write_enable 函数用于发送写使能命令,该命令需要在写操作前执行以允许写入。 write_to_main_buffer 函数用于向选定的主缓冲区写入数据。最后, main_buffer_to_memory 函数用于将缓冲区中的数据传输到存储器数组中。
3.1.2 状态寄存器的操作命令
状态寄存器提供了关于AT45DB041D内部状态的信息,如写操作是否完成、是否处于忙碌状态等。读取状态寄存器的命令是:
// 读取状态寄存器
uint8_t read_status_register() {
uint8_t command = CMD_READ_STATUS_REGISTER;
uint8_t status;
spi_transfer(&command, 1); // 发送读状态寄存器命令
spi_transfer(NULL, 0); // 发送空字节,准备读取数据
status = spi_transfer(NULL, 1); // 读取状态寄存器数据
return status;
}
在上述代码中,通过发送读取状态寄存器命令 CMD_READ_STATUS_REGISTER ,然后读取一个字节,即可得到状态寄存器的值。通过分析这个值,可以判断Flash芯片是否准备就绪,是否处于写保护状态等重要信息。
接下来,我们将探讨如何将这些命令集在不同模式下应用,以及如何进行命令集与数据操作的优化策略。
4. 数据缓冲管理
4.1 数据缓冲的重要性
4.1.1 缓冲区的概念与作用
缓冲区是计算机系统中的一个临时存储区域,其主要目的是缓和生产者和消费者之间的速度差异,即提高系统效率和稳定性。缓冲区可以存在于硬件、操作系统内核、文件系统以及应用程序等多个层面。在硬件层面,如RAM中的缓存,可以减少对硬盘的直接读写次数;在软件层面,数据缓冲可以用于网络通信、文件处理、多线程应用等场景,以平衡操作速率或数据吞吐量。
在嵌入式系统或微控制器中,比如AT45DB041D芯片的SPI通信,数据缓冲同样至关重要。它允许我们在传输大量数据前暂存数据,之后再通过SPI接口以控制的方式进行数据交换。这不仅可以减少通信过程中的错误率,还能够提高数据传输的效率和可靠性。
4.1.2 缓冲管理的策略
有效的缓冲管理策略是优化系统性能的关键。一个好的缓冲管理策略通常需要考虑以下几个方面:
- 缓冲区大小 :缓冲区应该足够大以适应数据的突发传输,但又不能过大以至于浪费系统资源。
- 缓冲区分配机制 :采用先进先出(FIFO)、循环缓冲区等机制,确保数据处理的公平性和及时性。
- 缓冲区同步 :确保生产者和消费者之间对缓冲区的操作不会发生冲突,可能涉及锁机制或原子操作。
- 异常处理 :对缓冲区溢出、数据丢失等问题进行及时的检测和处理。
在设计缓冲管理策略时,也需要对应用场景进行深入分析。例如,在多线程环境下,缓冲区的线程安全是一个必须重视的问题;在实时系统中,延迟和吞吐量要求对缓冲区设计有直接影响;在存储系统中,IO性能和缓存策略对整体性能至关重要。
4.2 缓冲区的管理实践
4.2.1 缓冲区分配与释放
缓冲区的分配通常是通过堆内存分配函数完成的,如C语言中的malloc和free,或者C++中的new和delete。在嵌入式系统中,资源相对有限,因此动态分配和释放内存必须谨慎处理。为提高效率和降低复杂度,可以预先分配一个固定大小的缓冲池,然后根据需要从这个池中获取和释放缓冲区。
以下是一个简单的C语言例子,演示如何实现一个基于栈的缓冲区分配器:
#include <stdlib.h>
#include <stdio.h>
#define MAX_BUFFERS 10
#define BUFFER_SIZE 128
char buffer_pool[MAX_BUFFERS][BUFFER_SIZE];
void* get_buffer() {
for (int i = 0; i < MAX_BUFFERS; ++i) {
if (!buffer_pool[i][0]) {
buffer_pool[i][0] = 1; // Mark as in use
return buffer_pool[i];
}
}
return NULL; // No buffer available
}
void release_buffer(void* buffer) {
int i = (int)buffer - (int)buffer_pool[0];
if (i >= 0 && i < MAX_BUFFERS) {
buffer_pool[i][0] = 0; // Mark as free
}
}
int main() {
char* buf = (char*)get_buffer();
if (buf) {
printf("Got a buffer, now release it: %p\n", buf);
} else {
printf("No buffers available\n");
}
release_buffer(buf);
return 0;
}
在上述代码中,我们定义了一个缓冲池 buffer_pool ,包含固定数量和大小的缓冲区。 get_buffer 函数遍历缓冲池,查找一个未被使用的缓冲区并标记为在使用状态。 release_buffer 函数则负责释放该缓冲区,将其标记为可再次使用。
4.2.2 缓冲区溢出与异常处理
缓冲区溢出是一种常见的错误,发生在试图写入的数据超出了缓冲区的容量。这会导致数据覆盖相邻内存区域,可能导致程序崩溃、安全漏洞等问题。因此,管理缓冲区时,必须包括对缓冲区溢出的检测和处理。
缓冲区溢出的处理方法通常包括:
- 边界检查 :在每次数据写入前,检查是否超出缓冲区界限。
- 安全函数 :使用不会产生溢出的安全函数(如strncpy代替strcpy)。
- 动态检查 :利用诸如Valgrind的工具在运行时检测内存溢出。
异常处理策略可以分为以下几种:
- 预防策略 :通过边界检查和安全编程实践,预防缓冲区溢出的发生。
- 检测策略 :运行时监控,对可能的溢出进行检测。
- 恢复策略 :当检测到缓冲区溢出时,采取措施(如程序重启)以恢复系统正常运行。
在实际应用中,缓冲区溢出的处理往往需要结合以上多种策略。下面是一个使用边界检查防止溢出的示例:
void write_data(char* buffer, size_t buffer_size, const char* data, size_t data_size) {
if (data_size >= buffer_size) {
// Data is too large to fit in the buffer, handle error or resize buffer
fprintf(stderr, "Error: Data too large for the buffer\n");
} else {
// Copy only the amount of data that will fit in the buffer
memcpy(buffer, data, data_size);
buffer[data_size] = '\0'; // Ensure null-termination for strings
}
}
在这个函数中,我们首先比较要写入的数据大小与缓冲区大小。如果数据大小超过了缓冲区大小,则不会执行写入操作,并返回错误信息;如果数据可以放入缓冲区,我们使用 memcpy 函数安全地复制数据,并确保字符串正确地以空字符结尾。这样,就可以有效预防数据溢出的风险。
5. 错误处理与状态检测
5.1 错误处理机制
5.1.1 错误检测的方法
在嵌入式系统中,错误检测是保证设备稳定运行的关键环节。错误检测机制能够及时发现并响应硬件或软件的异常状态,防止错误积累导致系统崩溃或数据损坏。错误检测方法通常分为两类:主动检测和被动检测。
主动检测是通过周期性地检查硬件组件和软件系统的工作状态来实现的。例如,周期性地执行自检程序,或者使用看门狗定时器(Watchdog)来监控系统响应。如果系统在预定时间内未完成特定的操作,看门狗定时器将重置系统。
被动检测则是在运行中对异常行为的实时监测,这包括硬件中断、软件异常、通信超时等。当发生这些事件时,系统会立即采取错误处理措施,如记录日志、触发错误处理流程,甚至通知用户。
5.1.2 错误处理与恢复流程
一旦检测到错误,系统需要有一套标准化的错误处理流程来最小化错误带来的影响。错误处理流程通常包含以下步骤:
- 错误记录: 发生错误时,首先应将错误信息记录下来,这对于后续的故障诊断非常关键。
- 错误响应: 根据错误的类型和严重程度,采取相应的响应措施。对于可恢复的错误,可以尝试重试或回滚到稳定状态。
- 错误恢复: 尝试恢复到一个安全状态,可以包括重启服务、重置硬件设备或切换到备用系统。
- 通知用户: 在某些情况下,需要将错误信息通知给最终用户,以便采取外部干预措施。
错误处理的代码示例如下:
// 错误处理函数示例
void handleError(int errorCode) {
// 记录错误信息
recordError(errorCode);
// 根据错误类型进行不同的处理
switch(errorCode) {
case ERROR_TIMEOUT:
// 处理超时错误
break;
case ERROR_HARDWARE_FAIL:
// 处理硬件故障
break;
// ... 其它错误类型
default:
// 未知错误处理
break;
}
// 尝试恢复操作
if (isRecoverable(errorCode)) {
recoverFromError(errorCode);
}
// 必要时通知用户
notifyUser(errorCode);
}
5.2 状态检测与诊断
5.2.1 状态寄存器的作用与读取
状态寄存器是微控制器和外设中一种用来指示设备状态的寄存器。AT45DB041D这类存储器芯片通常具有几个状态寄存器,用于报告芯片的工作状态,例如是否正忙于执行某些操作、是否处于待机模式等。
正确读取状态寄存器对于实现有效的错误处理和状态检测至关重要。状态寄存器的读取通常通过发送特定的命令到芯片来完成,芯片随后将状态字节返回给请求方。在AT45DB041D中,例如,通过发送读取状态寄存器的命令 57h ,可以得到当前的设备状态。
示例代码如下:
// 读取AT45DB041D状态寄存器的代码片段
uint8_t readStatusRegister() {
uint8_t status;
// 发送读取状态寄存器命令
sendCommand(AT45DB041D_READ_STATUS_COMMAND);
// 等待数据准备就绪
waitForDataReady();
// 读取状态字节
status = readByte();
return status;
}
5.2.2 常见故障的诊断与处理
对于AT45DB041D这类存储器芯片,常见的故障可能包括但不限于:
- 写入保护(WP)状态: 如果芯片被意外地设置为写入保护状态,则需要检查硬件连接或软件控制指令,确保WP引脚未被拉低。
- 通信错误: 如果通信过程中发生了错误,应检查SPI总线连接是否正确,以及是否遵守了正确的时序规范。
- 读写故障: 这通常与存储器损坏或设备处于非预期状态有关。在故障发生时,首先读取状态寄存器,查看是否报告了忙状态或出错状态。
故障诊断的一般步骤如下:
- 初始化检查: 确保所有硬件连接正确,设备被正确初始化。
- 状态寄存器检查: 利用上面提到的
readStatusRegister函数检查状态寄存器,识别潜在的问题。 - 故障排除测试: 尝试执行最基本的读写操作,看是否能复现错误。
- 硬件诊断: 如果怀疑硬件问题,可以尝试替换芯片或使用新的硬件组件。
在所有故障处理步骤中,记录详细的错误日志至关重要,它可以帮助快速定位问题所在,并在将来预防类似问题的发生。
graph TD;
A[开始诊断] --> B[初始化检查]
B --> C[状态寄存器检查]
C --> D[故障排除测试]
D --> |问题解决| E[故障处理成功]
D --> |问题未解决| F[硬件诊断]
F --> |硬件问题| G[更换硬件]
F --> |硬件无问题| H[更深入的诊断]
G --> E
H --> E
以上内容为第五章《错误处理与状态检测》的详细描述,涵盖了错误检测方法、错误处理流程、状态寄存器作用及其读取方法,以及常见的故障诊断和处理步骤。在接下来的章节中,我们继续深入探讨驱动程序的设计和API封装。
6. 驱动程序设计与API封装
6.1 驱动程序架构设计
6.1.1 驱动程序的模块划分
一个高效、可维护的驱动程序通常需要良好的模块划分。这种划分有利于代码的组织与后续的维护工作。在设计驱动程序时,我们通常会按照功能或硬件的抽象层次来划分模块。以下是AT45DB041D驱动程序模块划分的一个基本框架:
- 初始化与配置模块 :负责在系统启动或驱动加载时对芯片进行初始化,设置必要的工作模式。
- 命令处理模块 :响应来自上层的命令,将它们转化为SPI操作,执行相应的读写操作。
- 数据缓冲管理模块 :负责管理数据的临时存储,包括读写缓冲区的分配和释放。
- 状态检测与错误处理模块 :负责监控设备状态,并处理可能出现的错误情况。
- 数据传输模块 :实现与SPI接口的实际通信,控制数据在设备与内存之间的流动。
- 接口与API封装模块 :提供简洁、一致的接口给上层应用程序调用,隐藏驱动实现细节。
6.1.2 驱动程序的代码结构
代码结构设计是驱动程序设计的关键部分,它不仅关系到代码的可读性和可维护性,也影响性能和扩展性。驱动程序的代码结构应清晰地反映出其功能模块的划分。通常,每个模块会有相应的代码文件,或者在同一个文件中会有明确的代码块进行区分。以下是驱动程序代码结构的一个示例:
// SPI_driver.c
#include "SPI_driver.h"
// 初始化与配置模块
void SPI_Init() {
// 初始化代码
}
// 命令处理模块
void SPI_ProcessCommand(command_t cmd) {
// 命令处理代码
}
// 数据缓冲管理模块
buffer_t* SPI_AllocateBuffer() {
// 分配缓冲区代码
}
void SPI_FreeBuffer(buffer_t* buf) {
// 释放缓冲区代码
}
// 状态检测与错误处理模块
void SPI_CheckStatus() {
// 状态检测代码
}
void SPI_ErrorHandling(error_t err) {
// 错误处理代码
}
// 数据传输模块
void SPI_PerformTransfer(data_t* data, size_t size) {
// 数据传输代码
}
// 接口与API封装模块
// 函数声明位于SPI_driver.h
void AT45DB041D_Write(data_t* data, size_t size);
data_t* AT45DB041D_Read(size_t size);
以上代码仅为示例,并非真实驱动程序代码。驱动程序的实现细节需要根据具体的硬件特性及应用场景进行设计。代码结构的划分应根据实际需要调整,以达到最佳的维护性和性能。
6.2 API接口设计与封装
6.2.1 API的功能划分与设计原则
API(Application Programming Interface)是驱动程序与上层应用交互的界面,其设计质量直接影响上层软件的可用性和驱动的稳定性。在设计API时,应遵循以下原则:
- 简洁性 :API应提供简洁明了的操作接口,减少上层程序的负担。
- 一致性 :所有API应遵循统一的设计风格和命名规则,便于理解和使用。
- 健壮性 :API应具备错误处理能力,对输入参数进行检查,确保调用安全。
- 性能 :API应尽量减少上层与驱动程序之间的交互次数,提高执行效率。
对于AT45DB041D驱动程序,可以设计如下的API:
int AT45DB041D_Init():初始化驱动程序和设备。int AT45DB041D_Write(uint8_t* data, size_t length):写入数据到Flash。int AT45DB041D_Read(uint8_t* buffer, size_t length):从Flash读取数据。int AT45DB041D_EraseSector(int sector):擦除Flash中的一个扇区。int AT45DB041D_Status():获取设备状态。
6.2.2 API的封装与文档编写
API的封装不仅包括代码实现,还应该提供详细的文档说明,以帮助开发者了解如何正确使用这些API。文档至少应该包括以下内容:
- 函数原型 :列出每个API的函数签名和返回值。
- 参数说明 :对每个参数的类型、意义和使用范围进行说明。
- 功能描述 :详细描述API实现的具体功能。
- 返回值 :列出所有可能的返回值以及对应的错误解释。
- 使用示例 :提供简洁的代码示例,展示如何调用API。
此外,良好的代码注释也是API封装的重要部分。注释应该直接写在相应的函数内部,对关键的实现步骤、逻辑决策和可能的异常情况进行解释。
/**
* @brief 写入数据到AT45DB041D Flash
* @param data 指向要写入数据的指针
* @param length 要写入的数据长度
* @return int 成功返回0,失败返回错误代码
*
* 该函数将数据从主机内存写入到Flash的指定位置。如果写入成功,
* 返回0。如果写入过程中出现错误,返回相应的错误代码。
*/
int AT45DB041D_Write(uint8_t* data, size_t length) {
// 实现写入操作的代码
}
以上内容仅为展示,实际的API实现需要根据具体的驱动程序和硬件设备进行编写和测试。
7. 软件优化策略与驱动集成应用
在现代软件开发中,软件优化与驱动集成是两个关键环节,它们直接关系到系统的运行效率和稳定性。本章将详细讨论软件优化的基本方法和驱动程序的集成与应用策略。
7.1 软件优化的基本方法
软件优化可以分为代码层面和系统资源层面的优化。在代码层面,我们需要关注算法效率、数据结构优化以及代码可读性;在系统资源层面,主要关注的是资源分配、负载平衡以及内存管理。
7.1.1 代码优化技巧
高效的代码可以减少CPU和内存的使用,提高程序的运行速度。一个常见的代码优化技巧是减少循环中的计算量。例如,将计算量大的操作尽可能地移到循环外部。
// 优化前的代码示例
for(int i = 0; i < n; i++) {
result += expensive_function(i);
}
// 优化后的代码示例
int exp_result = 0;
for(int i = 0; i < n; i++) {
exp_result += i;
}
for(int i = 0; i < n; i++) {
result += exp_result;
}
另一个优化技巧是使用合适的数据结构。对于频繁的查找操作,使用哈希表可以大大提高效率,而堆(Heap)结构适合优先级队列等场景。
7.1.2 系统资源优化
系统资源优化涉及对CPU、内存、磁盘I/O等资源的高效管理。使用多线程编程可以提高CPU利用率,但也需要避免线程间的竞争和死锁。内存优化方面,应尽量减少内存泄漏和碎片化,合理使用内存池和对象池。
7.2 驱动程序的集成与应用
驱动程序是硬件设备与操作系统间的桥梁,它的集成和应用对系统的稳定性和性能至关重要。
7.2.1 驱动程序在不同系统中的集成方法
不同操作系统有不同的驱动程序集成方法。在Linux系统中,通常需要编写内核模块,并通过makefile编译集成。而在Windows系统中,则可能需要编写INF安装脚本,并通过设备管理器安装驱动。
7.2.2 驱动程序的应用案例分析
以AT45DB041D闪存驱动程序为例,我们可以看到驱动集成的重要步骤。首先,驱动程序需要注册为SPI设备,然后通过定义的SPI接口进行数据交换。在应用层,我们可以封装API来简化编程模型,使得调用驱动程序就像操作普通文件一样简单。
// 示例代码:注册SPI设备
struct spi_device *spi_device_register(struct spi_board_info *info);
在软件优化和驱动程序集成中,我们需要注意性能和稳定性的平衡,避免过度优化导致代码的复杂度增加,同时也要确保驱动程序的兼容性和可维护性。通过上述优化策略和集成应用,我们可以提升整个系统的性能,并确保硬件设备能够在各种复杂环境中稳定工作。
在下一章中,我们将继续深入探讨AT45DB041D芯片的高级应用场景,例如如何实现故障容错和数据恢复策略等。
简介:AT45DB041D是由Atmel公司推出的串行闪存芯片,适用于嵌入式系统和微控制器应用。本驱动程序专为ATMEL64单片机设计,以实现高效的数据读写。该芯片具有4MB存储空间,支持最高10MHz的SPI通信速率,并具备低功耗、硬件错误校验和高耐用性等特性。驱动开发涉及SPI接口编程、AT45DB041D命令集、数据缓冲管理、错误处理和状态检测、驱动程序设计和软件优化等方面。附带的压缩包文件包含驱动源码、示例应用、库文件和数据手册,帮助开发者在项目中集成和使用AT45DB041D。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 8
8 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)