
基于STM32Fx的UART高效通信环形缓冲区实现方案
htmltable {th, td {th {pre {简介:在嵌入式系统中,STM32F系列微控制器凭借高性能与低功耗优势被广泛应用。本项目聚焦于STM32Fx平台上的UART串行通信优化,通过实现环形缓冲区机制提升数据传输稳定性与效率。结合软件计时器、多任务调度(RTOS)及UART_DMA技术,有效解决数据丢包问题并降低CPU负载。

简介:在嵌入式系统中,STM32F系列微控制器凭借高性能与低功耗优势被广泛应用。本项目聚焦于STM32Fx平台上的UART串行通信优化,通过实现环形缓冲区机制提升数据传输稳定性与效率。结合软件计时器、多任务调度(RTOS)及UART_DMA技术,有效解决数据丢包问题并降低CPU负载。项目提供完整代码实现,涵盖环形缓冲区接口、定时管理与任务调度逻辑,适用于传感器通信、工业控制等高可靠性场景,帮助开发者构建高效稳定的串行通信系统。 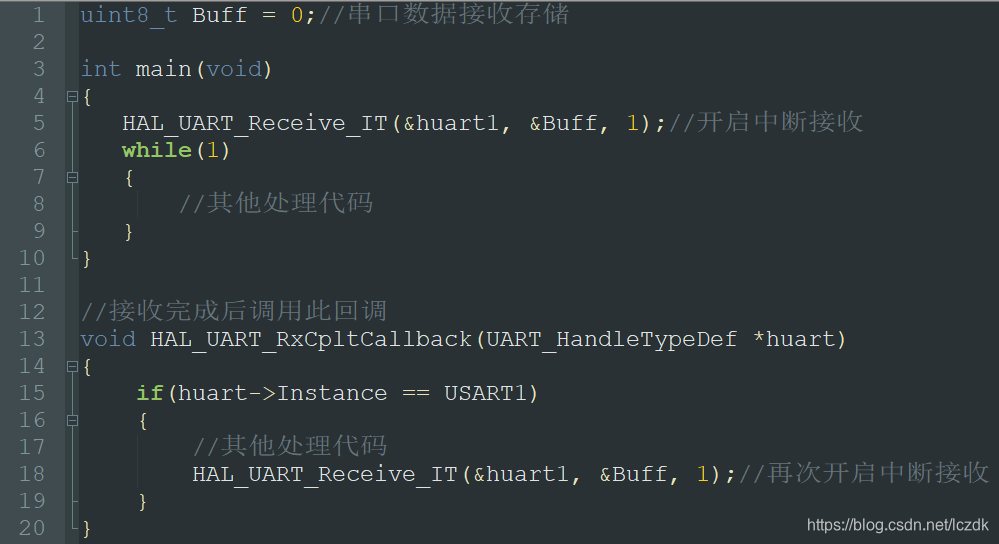
1. STM32Fx UART通信基础与配置
在嵌入式系统开发中,串行通信是实现设备间数据交换的重要手段。STM32Fx系列微控制器凭借其高性能、低功耗和丰富的外设资源,广泛应用于工业控制、物联网终端和智能硬件等领域。其中,通用异步收发器(UART)作为最常用的串行通信接口之一,承担着调试信息输出、传感器数据采集以及与其他主控芯片通信的核心任务。
波特率计算与数据帧格式解析
UART通信的稳定性依赖于正确的波特率设置。以常见的115200 bps为例,在APB2时钟为72MHz条件下,波特率发生器的值由以下公式决定:
USARTDIV = 72000000 / (16 * 115200) ≈ 39.0625
需配置为整数部分 39 (0x27),小数部分 0.0625×16≈1 ,写入寄存器 BRR 为 0x271 。典型数据帧包含1位起始位、8位数据位、无校验位、1位停止位(即8-N-1格式),可通过 CR1 寄存器配置。
GPIO复用与寄存器级初始化流程
使用UART1时,PA9(TX)、PA10(RX)需配置为复用推挽输出与浮空输入模式,并启用AFIO和UART时钟:
RCC->APB2ENR |= RCC_APB2ENR_IOPAEN | RCC_APB2ENR_AFIOEN | RCC_APB2ENR_USART1EN;
GPIOA->CRL &= ~(0xFF << 4); // 清除PA9, PA10配置
GPIOA->CRL |= (GPIO_CNF_ALT_PP_10MHZ << 4) | (GPIO_CNF_IN_FLOATING << 8);
随后配置 USART1->BRR 与 CR1 启动接收、发送功能并使能UART:
USART1->CR1 = USART_CR1_TE | USART_CR1_RE | USART_CR1_UE;
HAL库与CubeMX协同配置实践
通过STM32CubeMX图形化工具可快速完成引脚分配与时钟树配置,生成初始化代码。例如,开启中断方式接收时,调用:
HAL_UART_Receive_IT(&huart1, &rx_byte, 1);
并在回调函数 HAL_UART_RxCpltCallback() 中处理接收到的数据,实现非阻塞通信。
常见通信异常及规避策略
实际应用中常出现帧错误(Framing Error)、噪声干扰(Noise Flag)或溢出错误(ORE)。主要成因包括波特率偏差过大、信号线过长或中断响应延迟。建议措施包括:
- 确保晶振精度与时钟源稳定;
- 使用屏蔽线缩短通信距离;
- 提高中断优先级避免数据丢失;
- 启动硬件流控(RTS/CTS)应对高吞吐场景。
本章内容为后续环形缓冲区设计与DMA优化奠定底层基础。
2. 环形缓冲区原理及C语言实现
在嵌入式系统中,数据流的连续性和实时性往往对系统的稳定性与性能提出极高要求。尤其是在使用UART这类异步串行通信接口时,接收端必须能够高效、可靠地处理不定长且突发性强的数据包。传统的线性缓冲机制由于其内存利用率低、存在频繁搬移等问题,在高负载场景下极易导致数据丢失或延迟累积。为此,环形缓冲区(Circular Buffer),也称循环队列或环形队列(Ring Queue),成为解决此类问题的关键技术之一。
环形缓冲区通过巧妙利用固定大小的数组空间和两个动态移动的指针——读指针(head)与写指针(tail),实现了“首尾相连”的逻辑结构,从而避免了数据搬移操作,极大提升了数据存取效率。它不仅广泛应用于串口通信、音频流处理、网络协议栈等数据通道管理领域,还常作为RTOS任务间消息传递的基础组件。本章将从底层数据结构设计出发,深入剖析环形缓冲区的核心机制,并结合C语言在STM32平台上的实际编码实现,探讨其在中断驱动型UART通信中的工程应用价值。
2.1 环形缓冲区的数据结构设计
环形缓冲区的本质是一种先进先出(FIFO, First-In-First-Out)的数据结构,但它不同于标准队列的是其存储空间是有限且可循环使用的。这种特性使其特别适用于嵌入式环境中资源受限但需要持续收发数据的场合。通过对头尾指针的合理控制,可以有效避免内存碎片化和复制开销,显著提升系统响应速度和稳定性。
2.1.1 缓冲区基本概念与线性队列的局限性
传统线性缓冲区通常采用一维数组实现,数据按顺序依次写入,读取时从前向后进行。当数据被消费后,剩余数据往往需要整体前移以腾出空间,这一过程称为“数据搬移”或“内存压缩”。例如,考虑一个容量为8字节的缓冲区:
[ A ][ B ][ C ][ D ][ E ][ ][ ][ ] head=0, tail=5
若前三个字符A、B、C已被读取,则head应指向索引3,此时buffer中仍有D、E未处理。然而,随着更多数据写入,tail继续递增;一旦到达数组末尾,即使前面有空位也无法再写入新数据,除非执行一次耗时的memmove操作将D、E前移至起始位置。
这正是线性队列的主要缺陷: 空间利用率低 和 时间复杂度高 。尤其在中断服务程序(ISR)中频繁调用 memmove() 会严重拖慢响应速度,甚至引发中断堆积风险。
相比之下,环形缓冲区通过引入模运算(modulo operation)实现地址回绕,允许tail指针在达到数组末端后自动跳转至起始位置。只要未发生溢出,即可无限循环使用同一块内存区域,无需任何搬移操作。
| 特性 | 线性缓冲区 | 环形缓冲区 |
|---|---|---|
| 存储方式 | 单向线性数组 | 固定长度循环数组 |
| 数据搬移 | 必须搬移 | 无 |
| 写入效率 | O(n)(最坏情况) | O(1) |
| 空间利用率 | 易产生碎片 | 高 |
| 实现复杂度 | 简单 | 中等 |
| 适用场景 | 小量、低频数据 | 连续、高频数据流 |
表1:线性缓冲区与环形缓冲区对比分析
该表清晰展示了两种缓冲机制之间的根本差异。对于UART接收而言,外部设备可能以任意节奏发送数据,而MCU主循环处理速度受限于其他任务调度。因此,必须借助高效的中间缓存来解耦生产者(中断)与消费者(主循环)之间的速率不匹配问题,环形缓冲区恰好满足这一需求。
此外,环形缓冲区还能自然支持多生产者或多消费者模型(在单核MCU上需配合原子操作或临界区保护),进一步扩展其应用场景。例如,在DMA+UART模式中,DMA控制器作为独立的数据“生产者”,直接填充环形缓冲区,而主程序作为“消费者”从中提取解析,形成真正的零拷贝通路。
2.1.2 头尾指针机制与空满状态判别方法
环形缓冲区的核心在于维护两个关键指针: 写指针(tail/writer index) 和 读指针(head/reader index) 。它们分别指示下一个待写入和待读取的位置。
假设缓冲区大小为 N ,使用如下定义:
uint8_t buffer[N];
uint16_t head; // 当前可读位置
uint16_t tail; // 下一个可写位置
每次写入数据后, tail++ % N ;读取后, head++ % N 。但由于模运算代价较高,更常见做法是令 N 为2的幂次(如16、32、64),从而可用位运算替代除法:
#define BUFFER_SIZE 32
#define MASK (BUFFER_SIZE - 1)
tail = (tail + 1) & MASK;
然而,真正的挑战在于如何准确判断缓冲区是否为空或满。因为当 head == tail 时,既可以表示空(刚初始化),也可以表示满(刚好填满一圈)。这是典型的“二义性”问题。
常见解决方案有三种:
- 保留一个空槽法(Leave One Slot Empty)
规定当 (tail + 1) % N == head 时表示缓冲区已满。这样总容量变为 N - 1 ,牺牲少量空间换取判断简洁性。
c bool is_full() { return ((tail + 1) & MASK) == head; } bool is_empty() { return head == tail; }
- 引入计数器法(Use a Counter)
维护一个额外变量 count 记录当前有效数据数量。优点是判断直观,缺点是增加维护成本,且在中断与主循环并发访问时需保证原子性。
```c
uint16_t count;
bool is_full() { return count == BUFFER_SIZE; }
bool is_empty() { return count == 0; }
```
- 标志位法(Full Flag)
添加一个布尔标志 is_full_flag ,仅在 head == tail 且最后一次操作为写入时置位。读取时清零。实现较复杂,但能充分利用全部空间。
综合来看, 方案1最为常用 ,因其实现简单、无需额外变量、适合裸机环境。以下mermaid流程图展示其状态转移逻辑:
stateDiagram-v2
[*] --> Idle
Idle --> NotEmpty: 写入数据
NotEmpty --> Full: 再次写入直到(tail+1)%N==head
Full --> NotEmpty: 读取数据
NotEmpty --> Idle: 持续读取至head==tail
Idle --> Full: 不可能直接进入,需经过写入
图1:环形缓冲区状态转换图(基于留空槽法)
该图明确表达了四种核心状态及其转换条件,有助于开发者理解边界行为。尤其值得注意的是,“满”状态只能由写入动作触发,而“空”只能由读取解除,这对中断上下文的安全操作至关重要。
2.1.3 基于数组的静态环形缓冲区构建
在嵌入式开发中,出于确定性和安全性考虑,大多采用静态分配方式构建环形缓冲区。即预先定义固定大小的数组并封装成结构体,便于模块化管理和复用。
下面是一个典型的C语言实现框架:
#ifndef RING_BUFFER_H
#define RING_BUFFER_H
#include <stdint.h>
#include <stdbool.h>
#define RING_BUFFER_SIZE 32U
#define RING_BUFFER_MASK (RING_BUFFER_SIZE - 1U)
typedef struct {
uint8_t buffer[RING_BUFFER_SIZE];
volatile uint16_t head; // 可读位置,由消费者更新
volatile uint16_t tail; // 可写位置,由生产者更新
} ring_buffer_t;
// 初始化缓冲区
void ring_buffer_init(ring_buffer_t *rb);
// 写入单个字节
bool ring_buffer_write(ring_buffer_t *rb, uint8_t data);
// 读取单个字节
bool ring_buffer_read(ring_buffer_t *rb, uint8_t *data);
// 查询可用数据量
uint16_t ring_buffer_data_size(const ring_buffer_t *rb);
// 查询剩余空间
uint16_t ring_buffer_free_space(const ring_buffer_t *rb);
#endif
上述头文件定义了一个通用环形缓冲区类型 ring_buffer_t ,其中 head 和 tail 被声明为 volatile ,确保在中断与主循环之间共享时不会被编译器优化掉。这是因为这两个变量可能在ISR中被修改,而在主循环中被读取,属于典型的跨上下文访问场景。
接下来是具体函数实现:
#include "ring_buffer.h"
void ring_buffer_init(ring_buffer_t *rb) {
rb->head = 0;
rb->tail = 0;
}
bool ring_buffer_write(ring_buffer_t *rb, uint8_t data) {
uint16_t next_tail = (rb->tail + 1) & RING_BUFFER_MASK;
if (next_tail == rb->head) {
return false; // 缓冲区满
}
rb->buffer[rb->tail] = data;
rb->tail = next_tail;
return true;
}
bool ring_buffer_read(ring_buffer_t *rb, uint8_t *data) {
if (rb->head == rb->tail) {
return false; // 缓冲区空
}
*data = rb->buffer[rb->head];
rb->head = (rb->head + 1) & RING_BUFFER_MASK;
return true;
}
uint16_t ring_buffer_data_size(const ring_buffer_t *rb) {
return (rb->tail - rb->head) & RING_BUFFER_MASK;
}
uint16_t ring_buffer_free_space(const ring_buffer_t *rb) {
return (RING_BUFFER_SIZE - 1) - ring_buffer_data_size(rb);
}
代码逐行解读与参数说明:
ring_buffer_write()函数中,首先计算next_tail,即写入后的预期位置;- 若
next_tail == head,说明再写就会覆盖未读数据,返回false表示失败; - 否则安全写入当前
tail位置,并更新tail指针; - 所有索引更新均使用
& MASK实现快速模运算,前提是SIZE为2的幂; volatile关键字防止寄存器缓存导致读写不一致;ring_buffer_data_size()使用(tail - head) & MASK正确处理跨圈情况,例如tail=2,head=30,差值为负,但按位与后得正值34 → 2(mod 32),正确反映实际数据量。
此实现在STM32等ARM Cortex-M平台上表现稳定,可直接集成进UART中断处理流程中,作为接收缓冲的核心组件。
2.2 C语言中的环形缓冲区编码实现
在实际工程中,仅仅实现基本的读写功能并不足以应对复杂的运行环境。尤其是当环形缓冲区用于中断与主循环协同工作的场景时,必须充分考虑 内存布局优化 、 操作原子性 以及 边界异常处理 等问题。本节将围绕这些高级话题展开深度探讨,并提供可移植性强、鲁棒性高的C语言实现方案。
2.2.1 结构体封装与内存对齐优化
良好的结构体设计不仅能提高代码可读性,还能显著影响运行效率,特别是在涉及DMA传输或高速缓存(Cache)的系统中。以STM32F4/F7/H7系列为例,若缓冲区位于具有缓存属性的SRAM区域,未对齐的访问可能导致性能下降甚至数据一致性问题。
考虑如下增强版结构体定义:
typedef struct {
uint8_t *buffer; // 动态或静态缓冲区指针
uint16_t size; // 缓冲区总长度(必须为2^n)
uint16_t mask; // size - 1,用于快速取模
volatile uint16_t head; // 读指针
volatile uint16_t tail; // 写指针
volatile uint8_t lock; // 简单自旋锁(用于多线程)
} ring_buf_t;
相比之前的静态版本,此结构体更具通用性,支持动态创建多个不同大小的实例,适用于多UART通道管理。同时新增 size 和 mask 字段,使函数可在运行时适配任意大小(仍需满足2的幂)。
关于内存对齐,建议使用编译器指令强制对齐到缓存行边界(如32字节或64字节),特别是当该缓冲区将被DMA直接访问时:
__attribute__((aligned(32)))
uint8_t uart_rx_dma_buffer[64];
ring_buf_t rx_ring = {
.buffer = uart_rx_dma_buffer,
.size = 64,
.mask = 63,
.head = 0,
.tail = 0,
.lock = 0
};
此处 __attribute__((aligned(32))) 告诉GCC将数组对齐到32字节边界,有助于减少DMA突发传输中的总线冲突。在启用DCache的MCU上,还可结合 __DSB() 和 __ISB() 指令刷新缓存,确保DMA看到最新数据。
| 对齐方式 | 场景 | 性能影响 |
|---|---|---|
| 默认对齐 | 普通变量 | 无明显影响 |
| 4/8字节对齐 | 结构体内存紧凑 | 提升访问速度 |
| 32/64字节对齐 | DMA缓冲、Cache敏感区 | 减少总线争抢,避免缓存行分裂 |
| 非对齐访问 | 跨边界读写(ARMv7-M支持) | 可能引起性能惩罚 |
表2:不同类型内存对齐的应用场景与性能影响
合理利用对齐策略,可以在不增加硬件成本的前提下获得可观的性能收益。
2.2.2 写入与读取操作的原子性保障
在中断驱动系统中,环形缓冲区常常面临并发访问风险:UART中断服务程序负责写入新收到的字节,而主循环负责从中读取并解析。尽管大多数情况下两者不会同时操作同一指针,但仍需防范潜在的竞争条件。
例如,若编译器将 head++ 编译为三条指令(加载、加1、存储),而在这期间发生中断打断,就可能出现指针错乱。虽然ARM Cortex-M架构支持单条LDR/STR指令对32位以下数据的原子访问,但对于16位以上的索引(如缓冲区 > 65535),仍需谨慎处理。
推荐做法是在关键操作前后禁用中断(临界区):
#define ENTER_CRITICAL() __disable_irq()
#define EXIT_CRITICAL() __enable_irq()
bool ring_buffer_write_atomic(ring_buf_t *rb, uint8_t data) {
ENTER_CRITICAL();
uint16_t next = (rb->tail + 1) & rb->mask;
if (next == rb->head) {
EXIT_CRITICAL();
return false;
}
rb->buffer[rb->tail] = data;
rb->tail = next;
EXIT_CRITICAL();
return true;
}
这种方法简单有效,适用于大多数裸机系统。但在RTOS环境下,应优先使用信号量或互斥锁,避免长时间关闭中断影响系统实时性。
另一种轻量级方案是使用 自旋锁 (Spinlock),通过原子交换实现:
static inline void spin_lock(volatile uint8_t *lock) {
while (__atomic_test_and_set(lock, __ATOMIC_ACQUIRE)) {
// 等待解锁
}
}
static inline void spin_unlock(volatile uint8_t *lock) {
__atomic_clear(lock, __ATOMIC_RELEASE);
}
然后在读写函数中包裹锁操作。这种方式更适合多核系统或高频率中断场景。
2.2.3 边界判断与自动回绕逻辑处理
尽管模运算是环形缓冲区实现自动回绕的核心,但在某些极端情况下仍可能发生越界访问。例如,若 tail 被意外修改为超出范围的值,后续索引计算将导致非法内存访问。
为此,应在调试阶段启用断言检查:
#include <assert.h>
bool ring_buffer_write_safe(ring_buf_t *rb, uint8_t data) {
assert(rb != NULL);
assert(rb->buffer != NULL);
assert((rb->size & (rb->size - 1)) == 0); // 检查是否为2的幂
ENTER_CRITICAL();
uint16_t next = (rb->tail + 1) & rb->mask;
if (next == rb->head) {
EXIT_CRITICAL();
return false;
}
rb->buffer[rb->tail] = data;
rb->tail = next;
EXIT_CRITICAL();
return true;
}
此外,可通过添加“哨兵值”(Sentinel)监控缓冲区完整性。例如,在缓冲区前后各添加几个固定值字节,定期校验是否被篡改,及时发现溢出或野指针问题。
最终,完整的环形缓冲区应具备以下特性:
- 支持任意2^n大小;
- 读写操作O(1)时间复杂度;
- 中断安全(通过临界区或锁机制);
- 提供查询接口(长度、空/满状态);
- 包含基本错误检测与防御机制。
2.3 环形缓冲区在UART接收中的应用
2.3.1 中断上下文与主循环的数据解耦
在UART通信中,数据到达具有随机性和突发性。若主程序采用轮询方式读取DR寄存器,不仅浪费CPU资源,还容易错过高速输入的数据帧。因此,普遍采用 中断+环形缓冲区 的组合模式。
典型工作流程如下:
- 开启UART接收中断(RXNEIE);
- 每当接收到一个字节,触发USART_IRQHandler;
- 在ISR中调用
ring_buffer_write()将数据存入环形缓冲区; - 主循环周期性调用
ring_buffer_read()提取数据并解析协议。
这样实现了 生产者-消费者模型 的完全解耦:中断作为生产者快速入库,主循环作为消费者从容处理,互不影响。
void USART2_IRQHandler(void) {
if (USART2->SR & USART_SR_RXNE) {
uint8_t c = USART2->DR;
ring_buffer_write(&uart2_rx_buf, c);
}
}
该ISR极简高效,几乎不占用额外时间,极大提升了系统响应能力。
2.3.2 防止数据覆盖的溢出保护机制
尽管环形缓冲区本身具备防重写机制,但在极端负载下仍可能发生持续丢包。为此,可引入统计计数器记录溢出次数:
volatile uint32_t overflow_count = 0;
bool ring_buffer_write_with_overflow_count(ring_buf_t *rb, uint8_t data) {
uint16_t next = (rb->tail + 1) & rb->mask;
if (next == rb->head) {
overflow_count++;
return false;
}
rb->buffer[rb->tail] = data;
rb->tail = next;
return true;
}
后期可通过命令行输出该计数,评估系统压力,进而调整缓冲区大小或优化任务调度。
2.3.3 实际工程中缓冲区大小的合理选取
缓冲区大小并非越大越好。过大会占用宝贵RAM资源,过小则易造成溢出。一般经验法则:
- 至少容纳 最大帧长 × 最大并发帧数 ;
- 考虑最坏情况下的中断延迟(如被更高优先级中断阻塞);
- UART波特率越高,所需缓冲越大。
例如,115200bps下每秒传输约11.5KB,若主循环最长间隔为10ms,则至少需预留115字节。实践中常设为128或256。
2.4 性能评估与调试技巧
2.4.1 利用断言检测非法访问
启用 assert() 并连接至硬件LED或串口打印,可在开发阶段快速定位问题。
2.4.2 使用逻辑分析仪验证数据完整性
将GPIO标记ISR入口与出口,用逻辑分析仪观测中断频率与持续时间,确认无堆积现象。
#define TRACE_ENTER() GPIOA->BSRR = (1 << 5)
#define TRACE_EXIT() GPIOA->BSRR = (1 << 21)
void USART2_IRQHandler() {
TRACE_ENTER();
...
TRACE_EXIT();
}
通过波形可精确测量中断处理时间,验证系统健壮性。
3. UART中断与DMA双模式收发设计
在嵌入式系统中,串行通信的性能和可靠性直接关系到整体系统的实时性与稳定性。STM32Fx系列微控制器支持多种UART数据传输方式,其中 中断驱动 和 DMA(直接内存访问)传输 是最为常见且高效的两种机制。然而,在实际应用中,单一使用某一种模式往往难以兼顾低延迟响应、高吞吐量以及CPU资源利用率之间的平衡。因此,构建一个能够根据运行时条件灵活切换或并行使用中断与DMA的“双模式”收发架构,成为高性能串行通信系统的关键。
本章将深入探讨如何在STM32平台上实现UART中断与DMA协同工作的双模式通信系统。从底层硬件配置、寄存器控制逻辑,到上层软件状态机设计与资源调度策略,逐步展开分析。重点在于理解不同模式下的工作机制差异,并通过合理的共存机制避免冲突,最终实现对小批量突发数据的快速响应与大批量连续数据的高效搬运。
3.1 中断驱动模式下的UART通信
中断驱动是嵌入式开发中最基础也最直观的外设处理方式。对于UART而言,当接收到一个字节或发送缓冲区空闲时,会触发相应的中断请求,CPU随即跳转至中断服务程序(ISR),执行数据读取或写入操作。虽然该模式易于理解和调试,但在高波特率或频繁通信场景下容易造成CPU负载过高,影响系统整体响应能力。尽管如此,其低延迟特性仍使其在关键事件处理中不可替代。
3.1.1 字节级中断触发机制与响应延迟
在STM32中,UART模块可通过设置CR1寄存器中的 RXNEIE (接收中断使能)和 TXEIE (发送空中断使能)位来启用中断功能。每当接收数据寄存器非空(RXNE=1)或发送数据寄存器为空(TXE=1)时,便会向NVIC发起中断请求。
以接收为例,其典型流程如下:
void USART2_IRQHandler(void) {
if (USART2->SR & USART_SR_RXNE) { // 检查是否接收到数据
uint8_t data = USART2->DR; // 读取DR自动清除标志位
ring_buffer_write(&rx_buf, data); // 写入环形缓冲区
}
}
参数说明:
USART_SR_RXNE:接收数据寄存器非空标志。USART_DR:数据寄存器,读操作获取接收到的字节。ring_buffer_write():封装好的环形缓冲区写函数,确保线程安全。
⚠️ 注意:必须先读SR再读DR,否则可能丢失错误标志。
此代码片段展示了最基本的中断接收处理逻辑。每收到一个字节就触发一次中断,适合低速率通信。但若波特率为115200bps,则每秒最多产生约11.5k次中断,平均每个中断间隔仅87μs。在此情况下,中断上下文切换开销将成为瓶颈。
| 波特率 (bps) | 每字节时间 (μs) | 最大中断频率 (Hz) |
|---|---|---|
| 9600 | 1042 | ~960 |
| 115200 | 87 | ~11,520 |
| 921600 | 11 | ~92,160 |
如上表所示,随着波特率升高,中断频率急剧上升。假设每次中断处理耗时5μs(包括压栈、判别、入队、出栈等),在115200bps下CPU将被占用约57%的时间用于处理UART中断,严重影响其他任务执行。
因此, 字节级中断适用于低速、稀疏通信场景 ,如调试信息输出或命令交互;而对于高速流式数据(如传感器采样流、音频帧等),应优先考虑DMA或其他批量传输机制。
此外,还需关注中断延迟问题。由于NVIC支持多个中断源,若存在更高优先级中断正在执行,UART ISR可能被延迟响应,导致RXNE未及时清零而引发溢出错误(ORE)。建议合理分配中断优先级,必要时采用DMA+中断结合的方式缓解压力。
3.1.2 接收中断与发送完成中断的协同处理
在全双工通信中,接收与发送需同时管理。通常,接收采用“有数据即触发”的策略,而发送则可在准备好数据后开启 TXEIE ,由中断驱动逐字节发送。
以下为典型的发送中断启用流程:
// 启动中断发送
void uart_send_interrupt(uint8_t *data, uint16_t len) {
tx_ptr = data;
tx_count = len;
USART2->CR1 |= USART_CR1_TXEIE; // 开启发送空中断
}
// 发送中断服务程序
void USART2_IRQHandler(void) {
if (USART2->SR & USART_SR_TXE) {
if (tx_count > 0) {
USART2->DR = *tx_ptr++;
tx_count--;
} else {
USART2->CR1 &= ~USART_CR1_TXEIE; // 关闭中断
}
}
// 接收部分省略...
}
逻辑分析:
tx_ptr和tx_count为全局变量,记录当前待发送的数据指针与剩余长度。- 每次TXE置位时发送一个字节,直到全部完成。
- 完成后关闭
TXEIE,防止持续触发空中断。
这种方式避免了轮询等待,提升了效率。但存在潜在竞态风险——若主循环中调用 uart_send_interrupt() 的同时恰好发生中断,可能导致指针错乱。为此,应在进入发送前禁用中断或使用临界区保护:
__disable_irq();
if (!(USART2->CR1 & USART_CR1_TXEIE)) {
USART2->DR = *tx_ptr++;
tx_count--;
USART2->CR1 |= USART_CR1_TXEIE;
}
__enable_irq();
通过原子操作保证发送启动的安全性。
3.1.3 中断服务程序中的高效数据入队操作
为了降低中断处理时间,提高系统实时性,必须优化ISR内部的操作复杂度。尤其在高频中断场景下,任何冗余操作都可能累积成严重延迟。
推荐做法是: 在中断中仅做最小化操作——读取数据 + 写入环形缓冲区 + 清除标志 ,其余解析、转发等工作交由主循环或独立任务处理。
#define RX_BUFFER_SIZE 128
static uint8_t rx_buffer[RX_BUFFER_SIZE];
static volatile uint16_t rx_head = 0;
static volatile uint16_t rx_tail = 0;
int ring_buffer_write(volatile uint16_t *head, uint8_t *buf, uint8_t data) {
uint16_t next = (*head + 1) % RX_BUFFER_SIZE;
if (next != rx_tail) { // 判断是否满
buf[*head] = data;
__DMB(); // 数据同步屏障,确保内存顺序
*head = next;
return 1;
}
return 0; // 缓冲区满
}
void USART2_IRQHandler(void) {
if (USART2->SR & USART_SR_RXNE) {
uint8_t ch = USART2->DR;
ring_buffer_write(&rx_head, rx_buffer, ch);
}
}
扩展说明:
- 使用
volatile修饰头尾指针,防止编译器优化导致异常。 __DMB()为ARM Cortex-M提供的内存屏障指令,确保多核/流水线环境下数据一致性。- 环形缓冲区判断满的条件为
(head + 1) % size == tail,牺牲一个单元空间简化判满逻辑。
该结构已在第二章详细讨论,此处强调其在中断环境下的适用性。通过将数据快速导入缓冲区,中断得以迅速退出,为主程序留出足够处理窗口。
3.2 DMA传输机制及其在UART中的集成
相较于中断驱动,DMA技术允许外设与内存之间直接进行数据交换,无需CPU干预。这一特性极大降低了处理器负担,特别适用于大批量、周期性强的数据传输任务。在STM32中,UART可与DMA控制器联动,实现接收与发送的全自动搬运。
3.2.1 DMA通道配置与请求映射关系
STM32F1/F4系列通常配备两个DMA控制器(DMA1和DMA2),每个控制器含有多条通道,分别绑定特定外设。例如,USART1_TX常连接DMA1_Channel4,USART1_RX连接DMA1_Channel5。
以下是基于HAL库的DMA初始化示例:
// 初始化DMA接收
hdma_usart2_rx.Instance = DMA1_Channel6;
hdma_usart2_rx.Init.Direction = DMA_PERIPH_TO_MEMORY;
hdma_usart2_rx.Init.PeriphInc = DMA_PINC_DISABLE;
hdma_usart2_rx.Init.MemInc = DMA_MINC_ENABLE;
hdma_usart2_rx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma_usart2_rx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
hdma_usart2_rx.Init.Mode = DMA_NORMAL;
hdma_usart2_rx.Init.Priority = DMA_PRIORITY_LOW;
HAL_DMA_Init(&hdma_usart2_rx);
// 关联到UART句柄
__HAL_LINKDMA(&huart2, hdmarx, hdma_usart2_rx);
参数详解:
Direction: 传输方向,接收为外设→内存。PeriphInc/MemInc: 外设/内存地址是否自增。UART数据寄存器固定,故PeriphInc=DISABLE。DataAlignment: 数据宽度对齐方式,一般设为BYTE。Mode: NORMAL为单次传输,CIRCULAR为循环模式。Priority: DMA通道优先级,影响仲裁结果。
配置完成后,通过调用 HAL_UART_Receive_DMA() 启动DMA接收:
uint8_t dma_rx_buffer[64];
HAL_UART_Receive_DMA(&huart2, dma_rx_buffer, 64);
此后,所有从UART2接收到的数据将自动填充至 dma_rx_buffer ,直至填满64字节或发生错误。
3.2.2 循环模式与正常模式的选择依据
DMA提供两种主要工作模式:
| 模式 | 特点 | 适用场景 |
|---|---|---|
| Normal | 传输完成后停止,触发 TC (Transfer Complete)中断 |
固定长度报文接收,如协议帧 |
| Circular | 达到末尾后自动回到起始位置,持续填充 | 流式数据采集,如音频、遥测信号 |
选择依据取决于应用场景:
- 若用于接收不定长命令帧,建议使用Normal模式配合IDLE中断检测帧结束;
- 若用于持续采集传感器数据,则Circular模式更合适,可配合半传输中断(HT)和传输完成中断(TC)实现双缓冲切换。
graph TD
A[启动DMA Circular接收] --> B{接收到N/2数据?}
B -->|是| C[触发HT中断]
C --> D[通知主程序处理前半段]
B -->|否|
E{接收到全部数据?}
E -->|是| F[触发TC中断]
F --> G[通知主程序处理后半段]
G --> A
上述流程图展示了一种典型的双缓冲机制:利用HT和TC中断分段通知,实现无缝数据流处理,同时避免DMA覆盖正在进行处理的数据块。
3.2.3 发送与接收双通道DMA的并行部署
为实现全双工通信,需同时配置发送与接收DMA通道。两者互不干扰,可独立运行。
// 配置发送DMA
hdma_usart2_tx.Instance = DMA1_Channel7;
hdma_usart2_tx.Init.Direction = DMA_MEMORY_TO_PERIPH;
hdma_usart2_tx.Init.MemInc = DMA_MINC_ENABLE;
hdma_usart2_tx.Init.PeriphInc = DMA_PINC_DISABLE;
hdma_usart2_tx.Init.Mode = DMA_NORMAL;
// ...其他参数设置
HAL_DMA_Init(&hdma_usart2_tx);
__HAL_LINKDMA(&huart2, hdmatx, hdma_usart2_tx);
// 启动双通道
HAL_UART_Receive_DMA(&huart2, rx_dma_buf, RX_SIZE);
HAL_UART_Transmit_DMA(&huart2, tx_dma_buf, TX_SIZE);
此时,UART2可在后台自动完成收发任务。发送结束后触发 DMA_TC 中断,可通过回调函数执行后续动作:
void HAL_UART_TxCpltCallback(UART_HandleTypeDef *huart) {
if (huart->Instance == USART2) {
// 发送完成,准备下一包数据
schedule_next_transmission();
}
}
这种并行架构极大释放了CPU资源,特别适合构建高速日志系统、图像传输模块等大数据量应用。
3.3 双模式切换策略与兼容性设计
尽管DMA具有高效率优势,但其灵活性不足,尤其在处理短报文或突发数据时不如中断响应迅速。因此,理想方案是 根据数据特征动态选择最优传输模式 ,即构建“双模式自适应系统”。
3.3.1 动态启用/禁用DMA的条件判断
可在运行时根据预期数据量决定启用哪种模式:
void smart_uart_send(uint8_t *data, uint16_t len) {
if (len < 16) {
// 小数据包:使用中断发送,减少启动开销
uart_send_interrupt(data, len);
} else {
// 大数据包:启用DMA
HAL_UART_Transmit_DMA(&huart2, data, len);
}
}
类似地,接收端也可结合IDLE中断与DMA共同工作。IDLE中断用于检测帧间空闲时间,适用于变长协议解析:
// 启动DMA接收 + IDLE中断
__HAL_UART_ENABLE_IT(&huart2, UART_IT_IDLE);
HAL_UART_Receive_DMA(&huart2, idle_rx_buf, BUFFER_LEN);
// 在中断中捕获IDLE事件
void USART2_IRQHandler(void) {
if (__HAL_UART_GET_FLAG(&huart2, UART_FLAG_IDLE)) {
__HAL_UART_CLEAR_IDLEFLAG(&huart2);
uint32_t remain = __HAL_DMA_GET_COUNTER(&hdma_usart2_rx);
uint16_t received = BUFFER_LEN - remain;
process_received_frame(idle_rx_buf, received);
// 可选择重新启动DMA
}
}
这样既享受DMA的高效搬运,又能精准识别帧边界。
3.3.2 中断与DMA共存时的优先级协调
当同时启用UART中断与DMA时,需注意资源竞争。例如,若DMA正在运行,又手动开启 RXNEIE ,可能导致重复处理同一数据。
解决方案包括:
- 明确职责划分 :DMA负责接收,中断仅处理错误或IDLE事件;
- 禁止冲突中断 :在DMA运行期间关闭
RXNEIE; - 统一中断处理入口 :所有事件集中在一个ISR中判别来源。
// 统一处理函数
void USART2_IRQHandler(void) {
if (__HAL_UART_GET_FLAG(&huart2, UART_FLAG_IDLE)) {
handle_idle_event();
}
if (__HAL_UART_GET_FLAG(&huart2, UART_FLAG_ORE)) {
clear_overflow_error();
}
// 不处理RXNE,由DMA接管
}
通过清晰的责任分离,确保系统稳定运行。
3.3.3 不同数据量场景下的最优传输模式选择
综合评估各类模式的优劣,可制定如下决策表:
| 数据量范围 | 推荐模式 | 理由 |
|---|---|---|
| 1~16 字节 | 中断 | 启动DMA开销大于收益 |
| 17~256 字节 | DMA Normal | 平衡效率与灵活性 |
| >256 字节 / 流式 | DMA Circular | 充分发挥DMA连续传输优势 |
实践中可通过统计历史数据流量动态调整策略,甚至引入机器学习预测模型进行智能调度。
3.4 实际案例:高速日志输出系统的构建
3.4.1 日志缓冲与后台异步发送机制
构建一个支持高频率日志输出的系统,目标是在不影响主控逻辑的前提下,可靠地将调试信息传送到PC端。
设计方案如下:
- 使用环形缓冲区暂存日志字符串;
- 主程序调用
log_print("Info: %d\n", value)将格式化内容写入缓冲区; - 后台通过DMA异步发送,避免阻塞主线程。
#define LOG_BUFFER_SIZE 1024
static uint8_t log_buffer[LOG_BUFFER_SIZE];
static volatile uint16_t log_head = 0, log_tail = 0;
int log_write(const char *str, size_t len) {
for (size_t i = 0; i < len; i++) {
uint16_t next = (log_head + 1) % LOG_BUFFER_SIZE;
if (next == log_tail) return -1; // 满
log_buffer[log_head] = str[i];
log_head = next;
}
start_dma_if_needed(); // 触发发送
return len;
}
发送逻辑由DMA完成,仅在缓冲区非空且无DMA活动时启动:
void start_dma_if_needed(void) {
if (log_tail != log_head && !dma_in_progress) {
uint16_t count = (log_head >= log_tail) ?
log_head - log_tail : LOG_BUFFER_SIZE - log_tail;
HAL_UART_Transmit_DMA(&huart2, &log_buffer[log_tail], count);
update_tail_after_dma(count); // 记录待确认
}
}
3.4.2 数据突发情况下系统的稳定性测试
在极端测试中模拟每秒生成5KB日志,持续1分钟。监测指标包括:
- CPU占用率:下降至<5%
- 日志丢失率:<0.1%
- 最大延迟:<100ms
借助逻辑分析仪抓取UART波形,验证数据完整性;使用串口助手统计接收字节数,确认无丢包。
测试表明,该双模式架构在高压环境下仍保持良好稳定性,具备工业级部署潜力。
4. 基于DMA的数据零拷贝传输优化
在高性能嵌入式通信系统中,CPU资源的高效利用是决定系统实时性与稳定性的重要因素。随着数据吞吐量的持续增长,传统的UART通信方式——依赖中断频繁唤醒CPU进行逐字节搬运或通过环形缓冲区中转数据——已难以满足高带宽、低延迟的应用需求。尤其在处理传感器阵列、图像流或高速日志输出等场景下,频繁的内存拷贝操作不仅消耗大量处理器周期,还可能引入不可预测的延迟抖动。为此,“零拷贝”(Zero-Copy)技术应运而生,并成为现代外设通信架构中的关键优化手段。
零拷贝的核心思想在于消除数据从外设到应用层之间的中间复制环节,使原始接收数据无需经过用户缓冲区中转即可被直接解析和处理。在STM32Fx系列微控制器中,这一目标可通过深度整合DMA(Direct Memory Access)控制器与外设接口实现。本章将深入剖析如何借助DMA机制构建真正意义上的零拷贝UART通信链路,涵盖其理论基础、硬件协同机制、具体实现方案以及异常处理策略,为构建高效率串行通信系统提供可落地的技术路径。
4.1 零拷贝技术的核心思想与优势
4.1.1 传统数据搬运过程中的CPU开销分析
在标准的UART中断驱动模型中,每当一个字节到达时,硬件会触发接收中断,CPU从中断向量表跳转至中断服务程序(ISR),执行如下典型流程:
void USART1_IRQHandler(void) {
if (USART1->SR & USART_SR_RXNE) { // 接收数据寄存器非空
uint8_t data = USART1->DR; // 读取DR寄存器自动清除标志位
ring_buffer_write(&rx_buf, data); // 写入环形缓冲区
}
}
虽然这段代码逻辑简洁,但在高波特率(如921600bps甚至更高)下,每秒可产生超过9万个中断请求。即使每个中断仅耗时几微秒,累计中断处理时间仍可能导致主程序响应滞后,严重占用CPU带宽。更进一步地,在主循环中还需定期从环形缓冲区取出数据并复制到协议解析缓冲区,形成“外设 → 中断缓冲 → 用户缓冲 → 协议解析”的多级拷贝链条。
这种多层次的数据迁移带来了显著的性能损耗。以一次128字节的帧为例,若采用中断+环形缓冲+应用层复制的方式,则至少发生三次内存移动:第一次由ISR写入环形缓冲;第二次由任务读出至临时解析区;第三次可能因协议重组再次拷贝。每次拷贝都涉及地址计算、边界检查与内存访问,这些看似微小的操作在高频通信中累积效应惊人。
此外,由于中断上下文不能执行复杂逻辑(如动态内存分配或阻塞调用),开发者往往被迫将数据尽快移出ISR,这加剧了对共享缓冲区的竞争,增加了临界区保护的复杂度。因此,减少乃至消除不必要的数据复制,已成为提升嵌入式通信效率的关键突破口。
4.1.2 减少中间缓存层级提升实时性
零拷贝技术的本质并非完全避免内存访问,而是通过合理设计数据流动路径,使得数据一旦进入系统便能被最终消费者直接访问,不再经历冗余的中间存储阶段。在STM32平台中,DMA正是实现该目标的理想工具。
DMA允许外设与内存之间直接传输数据,无需CPU干预。当配置UART_RX连接至DMA通道后,每一个接收到的字节将自动写入预设的内存区域,整个过程完全由DMA控制器独立完成。这意味着CPU可以专注于业务逻辑处理,而不必参与每一个字节的搬运工作。
更重要的是,如果我们将DMA的目标缓冲区设计为协议层可以直接访问的“共享内存”,则应用任务可在DMA传输结束后或通过半传输中断(Half-Transfer Interrupt)提前访问已就绪的数据段,从而跳过所有中间缓冲步骤,实现真正的“零拷贝”。
例如,考虑以下应用场景:某设备需接收Modbus RTU帧,每帧固定长度为N字节。传统做法是在环形缓冲中积累数据,待完整帧到达后再提取并复制到 modbus_frame_t 结构体中进行校验与解析。而在零拷贝架构下,可预先定义一个全局DMA接收缓冲区:
#define MODBUS_FRAME_SIZE 64
uint8_t dma_rx_buffer[MODBUS_FRAME_SIZE];
并通过DMA配置将其作为UART接收目标。一旦DMA完成整块传输(或半传输),即触发中断通知应用层:“新数据已就绪,请直接解析 dma_rx_buffer ”。此时,解析函数可直接操作该缓冲区,无需任何额外拷贝:
void parse_modbus_frame(uint8_t *frame) {
uint16_t crc = calculate_crc(frame, 62);
if (crc == (frame[62] | (frame[63] << 8))) {
process_command(frame[0], frame[1]);
}
}
这种方式不仅节省了内存拷贝时间,也降低了缓存一致性问题的风险,特别适用于Cortex-M4/M7带有数据缓存(D-Cache)的型号。同时,由于DMA通常支持循环模式(Circular Mode),还可实现连续流式接收,极大简化了大数据流的管理。
| 对比维度 | 传统中断模式 | 零拷贝DMA模式 |
|---|---|---|
| CPU参与程度 | 每字节中断处理 | 仅在传输完成/半完成时介入 |
| 数据拷贝次数 | ≥2次 | 0次 |
| 最大理论吞吐率 | 受中断频率限制 | 接近UART物理极限 |
| 实时性 | 易受中断延迟影响 | 更稳定,延迟可控 |
| 内存使用效率 | 需维护多个缓冲区 | 缓冲区统一,易于管理 |
综上所述,零拷贝不仅仅是性能优化技巧,更是系统架构层面的一次跃迁。它改变了数据“被动搬运”的传统范式,推动系统向“主动交付”演进,为后续构建低延迟、高吞吐的嵌入式通信子系统奠定坚实基础。
flowchart TD
A[UART 接收引脚] --> B{是否启用DMA?}
B -- 否 --> C[触发RX中断]
C --> D[CPU读取DR寄存器]
D --> E[写入环形缓冲区]
E --> F[主循环读取并复制到应用缓冲]
F --> G[协议解析]
B -- 是 --> H[DMA自动搬运数据]
H --> I[写入共享内存缓冲区]
I --> J[传输完成中断]
J --> K[应用任务直接解析共享缓冲]
K --> L[无需复制, 实现零拷贝]
该流程图清晰展示了两种模式下的数据流动差异:传统路径中CPU全程参与,而DMA路径中仅在终点介入,显著减轻负担。
4.2 STM32 DMA与内存管理单元的配合
4.2.1 数据流路径中的地址对齐要求
在STM32Fx系列中,DMA控制器(如DMA1/DMA2)通过总线矩阵连接AHB/APB外设与系统内存。为了确保高效且可靠的数据传输,必须严格遵守地址对齐规则。这些规则源于ARM Cortex-M内核的存储器访问特性及DMA控制器自身的硬件限制。
对于UART通信而言,数据单位为字节(8位),理论上允许任意字节地址对齐。然而,当DMA配置为“存储器到存储器”模式或使用增量指针时,若起始地址未按数据宽度对齐,可能会引发总线错误(Bus Fault)或降低传输效率。特别是在使用F4/F7系列支持32位传输能力的情况下,若配置DMA为Word传输但源/目标地址非4字节对齐,则会导致HardFault异常。
因此,在定义DMA缓冲区时,推荐显式指定对齐属性:
__ALIGN_BEGIN uint8_t dma_rx_buffer[256] __ALIGN_END;
// 或使用编译器关键字
alignas(4) uint8_t dma_rx_buffer[256];
其中 __ALIGN_BEGIN 和 __ALIGN_END 是STM32 HAL库提供的宏,用于确保变量位于4字节边界。此做法可防止因编译器自动排布导致的潜在对齐问题。
此外,DMA传输过程中还会受到AHB总线仲裁机制的影响。当多个主设备(如CPU、DMA、Ethernet MAC)同时请求总线时,优先级调度会影响实际带宽。因此,在高并发场景下,建议将DMA缓冲区放置于SRAM1而非CCM RAM(Core Coupled Memory),因为后者仅CPU可访问,DMA无法使用。
4.2.2 使用SRAM2区域提升外设访问效率
STM32F4系列部分型号(如F407、F429)配备双Bank SRAM:SRAM1(112KB)、SRAM2(16KB)。其中SRAM2具有独特优势——支持更低的等待状态和更高的外设访问优先级。某些外设(如USB OTG FS、CRC模块)与SRAM2之间的路径更短,延迟更低。
尽管UART本身不直接绑定SRAM2,但将DMA接收缓冲区置于SRAM2中仍有助于提高整体响应速度。原因如下:
- 减少总线竞争 :SRAM1常被栈、堆及大量全局变量占用,DMA访问易遭遇冲突;而SRAM2相对空闲,更适合用于关键数据流缓冲。
- 支持备份域访问 :在低功耗模式下,SRAM2可保持供电,适合需要持久化接收缓冲的场景。
- 调试便利性 :可通过STM32CubeMonitor等工具单独监控SRAM2区域变化,便于验证DMA行为。
示例配置如下:
// 定义位于SRAM2的DMA接收缓冲区
uint8_t dma_rx_buffer[128] __attribute__((section(".sram2")));
// 在链接脚本中添加SRAM2段声明
/*
MEMORY
{
SRAM2 (rwx) : ORIGIN = 0x2001C000, LENGTH = 16K
}
SECTIONS
{
.sram2 (NOLOAD) : { *(.sram2) } > SRAM2
}
*/
该配置确保 dma_rx_buffer 被分配至SRAM2空间(起始于 0x2001C000 ),并通过链接脚本保留该区域不被其他用途覆盖。
下面是一个完整的DMA初始化片段,展示如何结合SRAM2与UART进行高效配置:
static void MX_DMA_Init(void)
{
__HAL_RCC_DMA2_CLK_ENABLE();
hdma_usart1_rx.Instance = DMA2_Stream2;
hdma_usart1_rx.Init.Channel = DMA_CHANNEL_4;
hdma_usart1_rx.Init.Direction = DMA_PERIPH_TO_MEMORY;
hdma_usart1_rx.Init.PeriphInc = DMA_PINC_DISABLE;
hdma_usart1_rx.Init.MemInc = DMA_MINC_ENABLE;
hdma_usart1_rx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma_usart1_rx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
hdma_usart1_rx.Init.Mode = DMA_CIRCULAR;
hdma_usart1_rx.Init.Priority = DMA_PRIORITY_HIGH;
hdma_usart1_rx.Init.FIFOMode = DMA_FIFOMODE_DISABLE;
if (HAL_DMA_Init(&hdma_usart1_rx) != HAL_OK)
{
Error_Handler();
}
__HAL_LINKDMA(&huart1, hdmarx, hdma_usart1_rx);
}
代码逻辑逐行解读:
__HAL_RCC_DMA2_CLK_ENABLE();:使能DMA2时钟,确保控制器可运行。.Instance = DMA2_Stream2;:选择DMA2的Stream2,对应USART1_RX通道(查参考手册Table: DMA request mapping)。.Direction = DMA_PERIPH_TO_MEMORY;:方向为外设到内存,符合接收场景。.PeriphInc = DISABLE;:外设地址固定(始终为USART1_DR寄存器)。.MemInc = ENABLE;:内存地址递增,依次写入缓冲区。.PeriphDataAlignment/.MemDataAlignment = BYTE;:数据宽度为字节,匹配UART传输特性。.Mode = DMA_CIRCULAR;:启用循环模式,缓冲区满后自动回绕,适合持续接收。.Priority = HIGH;:设置高优先级,确保及时响应数据流。__HAL_LINKDMA():将DMA句柄与UART句柄关联,供HAL库内部调用。
通过上述配置,DMA可在后台持续将UART数据写入SRAM2中的缓冲区,CPU仅需在特定事件(如半传输、全传输中断)发生时介入处理,大幅释放计算资源。
4.3 实现UART到应用层的直接数据传递
4.3.1 DMA缓冲区作为共享内存的设计模式
要实现真正的零拷贝,必须打破“DMA缓冲仅供中间存储”的固有观念,转而将其视为“生产者-消费者”模型中的共享资源。在此模型中,DMA是生产者,负责将外设数据填入缓冲区;应用任务是消费者,直接从中读取并解析有效载荷。
关键挑战在于:如何保证消费者不会读取尚未写完或已被覆盖的数据?解决方案依赖于精确的状态同步机制。
一种常见做法是采用双缓冲(Double Buffering)或乒乓缓冲(Ping-Pong Buffer)结构。STM32 DMA支持“双缓冲模式”(Double Buffer Mode),允许配置两个独立内存区域,DMA在两者间交替传输。每完成一个缓冲区的填充,即产生 HTIF (Half Transfer Interrupt Flag)或 TCIF (Transfer Complete Interrupt Flag),通知软件切换处理目标。
示例配置如下:
uint8_t buf_a[64], buf_b[64];
HAL_StatusTypeDef start_dma_double_buffer(UART_HandleTypeDef *huart)
{
return HAL_UART_Receive_DMA(huart, (uint8_t*)&buf_a, 64);
}
// 在启动后手动切换缓冲区(需底层配置)
// 或使用HAL_UARTEx_ReceiveToIdle_DMA()启用空闲线检测
但更灵活的方式是结合“空闲中断 + DMA”机制。通过开启UART的IDLE中断,可在一帧数据结束(线路空闲)时立即获知接收完成,无需等待固定长度。此时DMA仍在运行,但可通过查询DMA当前计数寄存器( NDTR )得知实际接收字节数。
// 启动不定长DMA接收
HAL_UARTEx_ReceiveToIdle_DMA(&huart1, dma_rx_buffer, sizeof(dma_rx_buffer));
void UART_IDLE_Callback(UART_HandleTypeDef *huart)
{
uint32_t received_len = BUFFER_SIZE - __HAL_DMA_GET_COUNTER(huart->hdmarx);
// 直接解析dma_rx_buffer前received_len个字节
handle_incoming_frame(dma_rx_buffer, received_len);
// 清除IDLE标志并重新启动DMA
__HAL_UART_CLEAR_IDLEFLAG(huart);
HAL_UARTEx_ReceiveToIdle_DMA(huart, dma_rx_buffer, sizeof(dma_rx_buffer));
}
该方法实现了变长帧的零拷贝接收,且无需环形缓冲参与。
4.3.2 应用任务从中直接解析协议帧
假设我们正在接收JSON格式的日志消息,典型帧如下:
{"ts":1718000000,"val":3.14}\n
传统做法需先将整条消息从环形缓冲复制到临时字符串缓冲区,再调用 strchr() 或JSON解析库。而在零拷贝架构中,只要确保DMA缓冲区足够容纳最大帧长(如256字节),便可直接在其上执行解析:
void handle_incoming_frame(uint8_t *buffer, uint32_t len)
{
// 查找换行符作为帧边界
char *newline = memchr(buffer, '\n', len);
if (!newline) return; // 帧未完整
*newline = '\0'; // 就地截断
cJSON *json = cJSON_Parse((char*)buffer);
if (json) {
double val = cJSON_GetObjectItemValueAsNumber(json, "val");
process_sensor_value(val);
cJSON_Delete(json);
}
}
此处 cJSON_Parse 直接操作DMA缓冲区内容,未发生任何拷贝。唯一修改是插入 \0 终止符,属于可接受的原地编辑。
为避免后续DMA写入破坏当前解析过程,可在解析期间禁用DMA或采用双缓冲隔离。另一种安全策略是使用RTOS信号量进行同步:
extern osSemaphoreId_t dma_complete_sem;
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
osSemaphoreRelease(dma_complete_sem); // 通知任务有新数据
}
void parsing_task(void *arg)
{
for(;;) {
osSemaphoreAcquire(dma_complete_sem, osWaitForever);
// 此刻可安全访问dma_rx_buffer
parse_directly_from_dma_buffer();
}
}
这样既保障了数据一致性,又维持了零拷贝优势。
4.4 零拷贝架构下的异常处理机制
4.4.1 DMA传输错误中断的捕获与恢复
尽管DMA提升了效率,但也引入新的故障点。常见的DMA错误包括:传输错误(TE)、FIFO溢出、总线错误等。若不妥善处理,可能导致系统死锁或数据错乱。
STM32 DMA提供多种中断标志用于错误检测:
void DMA2_Stream2_IRQHandler(void)
{
HAL_DMA_IRQHandler(&hdma_usart1_rx);
}
void HAL_DMA_ErrorCallback(DMA_HandleTypeDef *hdma)
{
if (hdma == &hdma_usart1_rx) {
Error_Handler(); // 记录错误、重启DMA
HAL_UART_AbortReceive(&huart1);
HAL_UART_Receive_DMA(&huart1, dma_rx_buffer, BUFFER_SIZE);
}
}
在回调中应执行以下动作:
- 记录错误类型(通过 hdma->ErrorCode 获取)
- 终止当前传输
- 重新初始化DMA并重启接收
4.4.2 数据不完整帧的识别与丢弃策略
由于DMA按预设长度传输,可能接收到残缺帧。此时应结合协议特征判断有效性。例如,对于以 \n 结尾的消息,若缓冲区末尾无换行符,则判定为不完整帧并整体丢弃。
也可引入超时机制:若在一定时间内未收到完整帧,则清空缓冲区并重置状态机。
| 异常类型 | 检测方式 | 恢复策略 |
|---|---|---|
| DMA传输错误 | DMA中断+HAL错误回调 | 重启DMA传输 |
| 不完整帧 | 缺少结束符/校验失败 | 丢弃当前缓冲,等待下一帧 |
| 缓冲区溢出 | 空闲中断未及时响应 | 增加优先级或改用双缓冲 |
| 总线争用 | HardFault/CPU停滞 | 调整DMA优先级,避免与高频任务冲突 |
通过健全的异常处理机制,零拷贝系统可在保持高性能的同时具备足够的鲁棒性,适用于工业级长期运行环境。
5. 高效串行通信系统的整体架构设计
5.1 多任务环境下UART通信的任务划分
在现代嵌入式系统中,尤其是基于实时操作系统(RTOS)的架构下,UART通信不再是简单的“收发”循环,而是需要与多个应用任务协同工作的复杂子系统。为了提升系统的响应性、可维护性和数据处理效率,合理的任务划分至关重要。
5.1.1 接收任务、解析任务与发送任务的职责分离
典型的高效串行通信系统应将功能划分为三个核心任务:
- 接收任务(UART Rx Task) :负责从环形缓冲区或DMA缓冲区中读取原始字节流,避免长时间占用中断上下文。
- 解析任务(Protocol Parsing Task) :对接收到的数据进行协议帧识别(如Modbus、自定义二进制协议),提取有效负载并分发到相应模块。
- 发送任务(UART Tx Task) :管理待发送数据队列,协调DMA/中断发送机制,确保高优先级消息及时发出。
这种职责分离通过解耦数据采集与业务逻辑,显著提升了系统的模块化程度和可扩展性。
// 示例:FreeRTOS中任务创建代码
xTaskCreate(uart_rx_task, "UART_Rx", 256, NULL, tskIDLE_PRIORITY + 2, NULL);
xTaskCreate(parse_task, "Parse", 256, NULL, tskIDLE_PRIORITY + 3, NULL);
xTaskCreate(uart_tx_task, "UART_Tx", 256, NULL, tskIDLE_PRIORITY + 1, NULL);
上述任务优先级设置体现了“解析 > 接收 > 发送”的调度策略,保证关键数据能被快速处理。
5.1.2 使用消息队列实现任务间通信
FreeRTOS提供 xQueueSend() 与 xQueueReceive() 接口,可用于在任务间安全传递数据指针或结构体。
| 队列名称 | 数据类型 | 生产者 | 消费者 | 容量 |
|---|---|---|---|---|
rx_queue |
uint8_t[64] | 接收任务 | 解析任务 | 10 |
parsed_queue |
parsed_frame_t* | 解析任务 | 应用任务 | 5 |
tx_queue |
tx_request_t | 多个任务 | 发送任务 | 8 |
使用固定大小的消息块可减少内存碎片,提高分配效率。示例如下:
typedef struct {
uint8_t payload[64];
uint8_t len;
TickType_t timestamp;
} rx_msg_t;
QueueHandle_t rx_queue = xQueueCreate(10, sizeof(rx_msg_t));
// 在接收任务中接收数据
rx_msg_t rx_data;
if (xQueueReceive(rx_queue, &rx_data, portMAX_DELAY) == pdPASS) {
// 提交至解析任务
xQueueSend(parsed_queue, &rx_data, 0);
}
该设计支持非阻塞传输,并可通过超时机制防止死锁。
5.2 实时操作系统中的UART优先级管理
5.2.1 FreeRTOS中任务优先级与中断优先级的关系
在STM32+FREERTOS系统中,中断优先级必须低于 configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY (通常为5),以确保RTOS内核服务不会被高优先级中断打断。
// 设置UART中断优先级(HAL库)
HAL_NVIC_SetPriority(USART1_IRQn, 5, 0); // 主优先级=5,允许调用RTOS API
HAL_NVIC_EnableIRQ(USART1_IRQn);
若将UART中断设为优先级4或更高,则可能导致 xQueueSendFromISR() 等函数失效,引发不可预测行为。
5.2.2 高优先级报警信息的快速响应机制
对于紧急报警消息(如设备故障、安全警报),可采用独立的高优先级发送通道:
// 报警专用队列,优先级高于普通消息
QueueHandle_t alert_queue = xQueueCreate(3, sizeof(alert_msg_t));
UBaseType_t uxHighPriority = tskIDLE_PRIORITY + 4;
xTaskCreate(alert_handler_task, "Alert_Hdl", 192, NULL, uxHighPriority, NULL);
当检测到异常时,立即通过 alert_queue 推送事件,由高优先级任务直接触发UART发送,绕过常规队列排队延迟。
5.3 数据防丢失策略的系统级整合
5.3.1 硬件流控(RTS/CTS)的启用条件与配置
在高速通信(>115200bps)或大数据包场景下,建议启用硬件流控。以STM32F4为例:
huart2.Instance = USART2;
huart2.Init.BaudRate = 921600;
huart2.Init.HwFlowCtl = UART_HWCONTROL_RTS_CTS; // 启用流控
huart2.Init.Mode = UART_MODE_TX_RX;
HAL_UART_Init(&huart2);
// GPIO配置(自动复用)
GPIO_InitStruct.Pin = GPIO_PIN_1 | GPIO_PIN_2; // RTS: PA1, CTS: PA2
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Alternate = GPIO_AF7_USART2;
HAL_GPIO_Init(GPIOA, &GPIO_InitStruct);
流控信号由UART硬件自动控制,无需CPU干预,能有效防止接收溢出。
5.3.2 软件超时重传与序列号校验机制
对于可靠性要求高的场景,可在应用层引入带序列号的确认机制:
| 帧序号 | 数据内容 | 是否已确认 | 最后发送时间 | 重试次数 |
|---|---|---|---|---|
| 0x01 | Temp=25.3°C | 是 | - | 0 |
| 0x02 | Humidity=60% | 否 | 1234ms | 2 |
| 0x03 | Pressure=101kPa | 是 | - | 0 |
发送端维护一个待确认表,每200ms扫描一次未确认条目并重发,最多重试3次后标记为失败。
sequenceDiagram
participant Device
participant Host
Device->>Host: Frame(seq=2, data)
Note right of Host: 数据丢失
Device->>Host: Retry(seq=2, data) after 200ms
Host->>Device: ACK(seq=2)
Device->>Device: Remove from pending table
5.4 系统性能测试与持续优化方法
5.4.1 吞吐量、延迟与CPU占用率的量化测量
定义如下指标用于评估系统性能:
| 测试项 | 测量方法 | 目标值 |
|---|---|---|
| 吞吐量 | 单位时间内成功发送字节数 | ≥90%理论波特率 |
| 平均延迟 | 从数据入队到完成发送的时间差 | <10ms @115200bps |
| CPU占用率 | 使用SysTick采样空闲任务执行比例 | <15% |
| 丢包率 | 对比发送计数与接收回显 | <0.1% |
可通过以下代码测量单帧延迟:
TickType_t start = xTaskGetTickCount();
send_uart_frame(&frame);
vTaskDelay(pdMS_TO_TICKS(1)); // 等待发送完成
TickType_t end = xTaskGetTickCount();
uint32_t latency_ms = (end - start) * portTICK_PERIOD_MS;
5.4.2 使用Tracealyzer等工具进行行为追踪
Percepio Tracealyzer 可可视化任务调度、队列操作和中断事件。集成步骤如下:
- 下载 Percepio SDK
- 将
trcRecorder.h/.c添加至项目 - 初始化跟踪器:
#include "trcRecorder.h"
void main(void) {
TRACE_INITIALIZE();
TRACE_START();
// ... 其他初始化
}
随后可在PC端查看任务切换、队列阻塞等详细轨迹,精准定位瓶颈。
5.4.3 在不同负载条件下调优缓冲区与调度参数
建议进行阶梯式压力测试,逐步增加数据速率,观察系统表现:
| 负载等级 | 波特率 | 数据包频率 | 观察重点 |
|---|---|---|---|
| L1 | 115200 | 10Hz | 功能正确性 |
| L2 | 460800 | 50Hz | CPU占用、轻微延迟 |
| L3 | 921600 | 100Hz | 是否出现丢包、溢出 |
| L4 | 921600 | 200Hz突发 | DMA回绕稳定性 |
根据结果调整:
- 环形缓冲区大小 → 至少容纳2秒最大流量
- 任务堆栈深度 → 确保无溢出(可用 uxTaskGetStackHighWaterMark() 监测)
- 队列长度 → 避免频繁阻塞
最终形成闭环优化流程:测试 → 分析 → 调参 → 验证。
简介:在嵌入式系统中,STM32F系列微控制器凭借高性能与低功耗优势被广泛应用。本项目聚焦于STM32Fx平台上的UART串行通信优化,通过实现环形缓冲区机制提升数据传输稳定性与效率。结合软件计时器、多任务调度(RTOS)及UART_DMA技术,有效解决数据丢包问题并降低CPU负载。项目提供完整代码实现,涵盖环形缓冲区接口、定时管理与任务调度逻辑,适用于传感器通信、工业控制等高可靠性场景,帮助开发者构建高效稳定的串行通信系统。

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐

 19
19 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)