
Freertos前置知识学习
使用STM32CubeMX 创建的FreeRTOS工程中,FreeRTOS相关的源码如下:主要涉及2个目录:Core Inc目录下的FreeRTOSConfig.h是配置文件 Src目录下的freertos.c是STM32CubeMX创建的默认任务 根目录下是核心文件,这些文件是通用的 portable 目录下是移植时需要实现的文件目录名为:[compiler]/[architecture
1. ARM 架构
1.1 RISC 精简指令集特点
ARM 属于 RISC(精简指令集计算机),核心思想:指令简单、规整、数量少。
RISC 关键特征
- 对内存只有「读 / 写」指令
- 只有
Load(读)、Store(写)能访问内存 - 其他运算不能直接操作内存
- 只有
- 所有数据运算都在 CPU 内部寄存器中完成
- 指令格式统一、长度固定,CPU 设计更简单
1.2 RISC 执行乘法 a = a * b 的过程
以 a = a * b 为例,RISC 必须分 4 步:
- Load:从内存读取变量 a → 存入寄存器
- Load:从内存读取变量 b → 存入寄存器
- 运算:在 CPU 内部做乘法运算
- Store:把运算结果写回内存 a
对比理解(帮助记忆)
- CISC(x86 那种):可以一条指令直接
内存a = 内存a * 内存b - RISC(ARM):必须 先读寄存器 → 运算 → 再写回
这就是 RISC 著名的:Load / Store 架构
CPU内部用寄存器来存数据
寄存器(Register) —— CPU 内部超高速的临时存储单元,是 ARM 运算的「核心操作载体」。
1.3 ARM CPU 内部寄存器
无论 Cortex-M3/M4(微控制器)还是 Cortex-A7(应用处理器),ARM 内核都标配通用寄存器 + 专用寄存器:
1. 通用寄存器
R0、R1、R2、……、R12:用于临时存放运算数据(如上述 a、b、a*b),可自由读写。
2. 专用寄存器(R13/R14/R15)
有固定功能,不可随意用作普通运算:
| 寄存器 | 别名 | 核心作用 |
|---|---|---|
| R13 | SP (Stack Pointer) | 栈指针,指向当前栈顶地址 |
| R14 | LR (Link Register) | 链接寄存器,保存函数调用后的返回地址 |
| R15 | PC (Program Counter) | 程序计数器,指向当前执行的指令地址(修改即跳转) |
后面还有一个PSR(程序状态寄存器)
1.4 ARM 核心汇编指令(必记)
ARM 汇编指令格式:指令 目标寄存器, 源寄存器1, 源寄存器2/立即数
| 指令类型 | 示例 | 解释 |
|---|---|---|
| 读内存:Load | LDR R0, [R1, #4] |
读取地址 R1+4 的 4 字节数据,存入 R0 |
| 写内存:Store | STR R0, [R1, #4] |
把 R0 的 4 字节数据,写入地址 |
| 指令 | 格式 | 解释(以 LDRB 为例) |
| LDRB | LDRB R0, [R1, #1] |
读内存地址R1+1处的 1 字节数据,存入 R0(R0 高位 24 位补 0) |
| STRB | STRB R0, [R1, #1] |
把 R0 的低 8 位数据,写入内存地址R1+1处(仅操作 1 字节,不影响其他位) |
| 适用场景 | char 类型、8 位寄存器、外设 8 位寄存器读写 | |
| 指令 | 格式 | 解释(以 LDRH 为例) |
| LDRH | LDRH R0, [R1, #2] |
读内存地址R1+2处的 2 字节数据,存入 R0(R0 高位 16 位补 0) |
| STRH | STRH R0, [R1, #2] |
把 R0 的低 16 位数据,写入内存地址R1+2处 |
| 适用场景 | short 类型、16 位外设寄存器(如 ADC、UART) | |
| 指令 | 格式 | 解释 |
| LDRD | LDRD R0, R1, [SP, #4] |
从栈地址SP+4处读 8 字节数据:前 4 字节→R0,后 4 字节→R1(批量读两个 int) |
| STRD | STRD R0, R1, [SP, #4] |
把 R0(前 4 字节)、R1(后 4 字节)写入栈地址SP+4处 |
| 适用场景 | 64 位数据、一次性传两个参数(如函数的 a/b 参数) | |
| 加法 | ADD R0, R1, R2 |
R0 = R1 + R2 |
| 加法(立即数) | ADD R0, R0, #1 |
R0 = R0 + 1(自增) |
| 减法 | SUB R0, R1, R2 |
R0 = R1 - R2 |
| 比较 | CMP R0, R1 |
比较 R0 和 R1,结果存入程序状态寄存器(PSR) |
| 跳转:Branch | B main |
直接跳转到 main 函数处执行 |
| 带返回跳转:Branch and Link | BL main |
先把当前返回地址存入 LR,再跳转到 main |
1.5ARM 数据传输三大要素
源、目的、长度
1. 源(Source):数据从哪来
- 内存某个地址
- 寄存器
- 立即数(常数)
2. 目的(Destination):数据到哪去
- 寄存器
- 内存某个地址
ARM 规则:运算只能在寄存器里做,内存不能直接运算。所以数据传输一定是:内存 ↔ 寄存器
3. 长度(Length):传多少字节
ARM 最常见三种长度:
- B(Byte):1 字节
- H(Halfword):2 字节
- 无后缀(Word):4 字节(int、指针)
1.6 add 函数反汇编(看到栈操作)
反汇编看栈操作的核心意义
- 验证栈的生长规则:直观看到 SP(栈指针)「减小分配空间、增大释放空间」的向下生长特性;
- 理解 volatile 的影响:如果去掉
volatile,编译器可能优化掉STR r0,[sp,#0](sum 不写回栈),反汇编能直接看到这个差异; - 掌握 ARM 函数调用规范:看到参数 / 返回地址如何通过栈保护、局部变量如何通过栈分配,这是嵌入式开发的核心基础;
- 排查栈相关问题:比如栈溢出、参数传递错误等 bug,反汇编是定位这类问题的关键。
int add(volatile int a, volatile int b)
{
volatile int sum;
sum = a + b;
return sum;
}- ARM 函数调用规则:函数参数
a、b默认通过R0、R1传入;返回值通过R0返回。 - 栈(SP)特性:栈是「向下生长」的(SP 减小 = 分配空间,SP 增大 = 释放空间),
PUSH自动减 SP,POP自动加 SP。 - volatile 作用:禁止编译器优化,变量必须读写内存(而非仅寄存器),所以反汇编会有明确的 Load/Store 操作。
| 地址 | 机器码 | 汇编指令 | 对应 C 代码 | 深度解析(内存 / 寄存器变化) |
|---|---|---|---|---|
| 0x08002f34 | b503 | PUSH {r0,r1,lr} | 函数入口 | 核心作用:保护现场(防止后续操作覆盖关键数据)1. 把R0(a)、R1(b)、LR(返回地址)依次压入栈;2. SP 自动减 3×4=12(3 个寄存器,每个 4 字节);3. 为什么保护?后续会重写 R0/R1,必须先保存原始参数和返回地址。 |
| 0x08002f36 | b081 | SUB sp,sp,#4 | 定义 sum | 核心作用:为局部变量sum分配栈空间1. SP = SP - 4(栈指针下移 4 字节);2. 这 4 字节就是sum的内存地址(栈地址SP+0);3. 此时栈布局:SP+0=sum,SP+4= 之前 PUSH 的 r0/r1/lr。 |
| 0x08002f38 | e9dd0101 | LDRD r0,r1,[sp,#4] | 读取 a、b | 核心作用:从栈中恢复参数 a、b 到寄存器(Load 操作)1. LDRD= 双字传输(8 字节),从栈地址SP+4读 8 字节;2. 前 4 字节→R0(恢复参数 a),后 4 字节→R1(恢复参数 b);3. 为什么从SP+4读?因为SP+0是 sum 的空间,SP+4才是之前 PUSH 的 r0/r1。 |
| 0x08002f3c | 4408 | ADD r0,r0,r1 | sum = a + b | 核心作用:执行加法运算(寄存器内操作)1. R0 = R0 (a) + R1 (b)(运算结果存在 R0);2. 符合 RISC 规则:所有运算仅在寄存器执行,无内存直接运算。 |
| 0x08002f3e | 9000 | STR r0,[sp,#0] | sum = a + b | 核心作用:把运算结果写入 sum(Store 操作)1. 把 R0 中的加法结果,写入栈地址SP+0(即 sum 的内存地址);2. 因为 sum 是volatile,必须写回内存,不能只存在寄存器。 |
| 0x08002f40 | bd0e | POP {r1-r3,pc} | return sum | 核心作用:释放栈 + 返回函数1. 从栈顶弹出数据,依次写入 R1、R2、R3、PC;2. 关键:把之前保存在 LR 的返回地址写入 PC(CPU 跳回调用 add 的地方);3. SP 自动加 4×4=16(释放所有栈空间);4. 返回值:加法结果已在 R0,符合 ARM 函数返回规则(R0 传返回值)。 |
1.6.1实例操作:
添加程序代码Add测试代码(上述)进入工程,修改cnt

编译程序;为例方便复制,制作反汇编的指令如下
fromelf --text -a -c --output=xxx.dis xxx.axf配置工程-User-After Bulid/ReBuild-Run#1-User Command-输入反汇编指令
XXX.axf改为目录地址方便后续找到(Linker里面找到地址)
点击编译即可生成test.dis
打开dis文件查找add函数进行分析即可
堆和栈
堆:一块内存空间,可以从中分配出一个小buffer,用完再把它放回去
定义一个数组,进行内存的分配和释放就是堆
小例子:
这段代码实现了一个极简的内存分配器(简易版 malloc),它基于一个预先定义的静态字符数组 heap_buf 作为「内存池」,通过维护一个全局位置指针 pos 来分配内存,本质是模拟堆内存的线性分配(也叫「栈式分配」/「线性分配」)。
// 1. 定义一个1024字节的静态字符数组作为内存池(模拟堆空间)
char heap_buf[1024];
// 2. 全局变量pos,记录内存池的下一个可分配位置,初始为0(表示从数组起始位置开始分配)
int pos=0;
// 3. 自定义内存分配函数,参数size是要分配的字节数,返回分配内存的起始地址
void *my_malloc(int size)
{
// 4. 保存当前的pos值(分配前的位置,即本次分配的起始地址)
int old_pos=pos;
// 5. 将pos向后移动size字节,为下一次分配预留空间
pos+=size;
// 6. 返回本次分配的内存起始地址(heap_buf数组中old_pos位置的地址)
return &heap_buf[old_pos];
}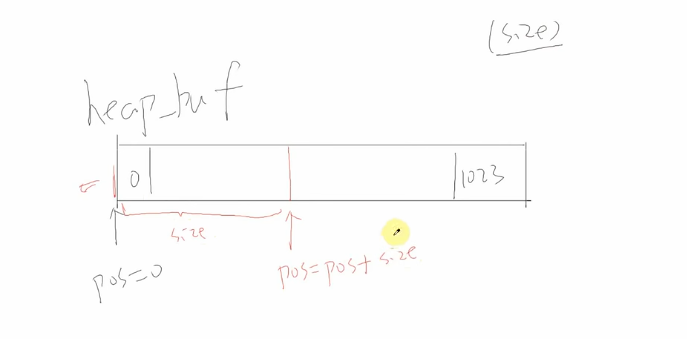
在这个buf来分配一个小块的内存,下标从0-1023;开始时pos=0,想要分配size大小的空间如何分配?pos=pos+size;返回首地址
在空闲的内存上实现malloc函数,这块空闲的内存就被称为堆(malloc需要配合free函数使用,对于简单的malloc函数无法实现free函数)
主函数代码
char ch=65;
int i;
char *buf=my_malloc(100);
unsigned char uch=200;
for (i=0;i<26;i++)
buf[i]='A'+i;- ①
char ch=65:ch是栈内存中的 char 类型变量,65 是 ASCII 码值,等价于ch='A';- 注意:char 类型通常是 1 字节,有符号(范围 - 128~127),但 65 在范围内,无溢出。
- 栈内存特点:系统自动管理,main 函数执行完后销毁。
- ②
int i:i是栈内存中的 int 类型变量,仅定义未初始化(值为随机垃圾值),后续循环会赋值。
- ③
char *buf=my_malloc(100):- 核心步骤:调用自定义
my_malloc(100)分配内存: - 调用
my_malloc(100),函数内先保存当前pos=0到old_pos; pos += 100→pos从 0 变为 100(无对齐、无边界检查);- 返回
&heap_buf[0](内存池起始地址),栈中的指针变量buf存储这个地址; - 内存关系:
buf在栈,指向的 100 字节空间在全局数组 heap_buf(模拟堆) 中。
- 核心步骤:调用自定义
- ④
unsigned char uch=200:uch是栈内存中的无符号 char 变量,1 字节,200 在 unsigned char 范围(0~255)内,正常存储。
buf 是指针(仅存地址),size 字节在内存池里;buf 存在栈里,它指向内存池起始地址

实际的堆管理
heap_buf是 1024 字节的内存池(模拟堆)- 第一次调用
my_malloc(100)→ 分配 0~99 字节,buf指向起始地址&heap_buf[0],pos变为 100 - 第二次调用
my_malloc(50)→ 分配 100~149 字节,buf2指向&heap_buf[100],pos变为 150 - 第三次调用
my_malloc(100)→ 分配 150~249 字节,buf3指向&heap_buf[150],pos变为 250
问题是:这种线性分配无法释放单个块,用完就只能重置整个内存池。要解决「分配 + 释放 + 复用」,就需要用链表来管理空闲块和已分配块。
我们把内存池拆成一个个「内存块」,用双向 / 单向链表把这些块串起来:
- 每个块包含:块头(元数据)+ 有效数据区
- 块头里存:当前块大小、是否空闲、下一个块的指针
- 两种链表:
- 空闲链表:只串起所有「空闲可用」的块
- 已分配链表:串起所有「正在使用」的块(也可以只在块头里用标志位区分)
分配流程(my_malloc 用链表实现)
- 遍历空闲链表,找到第一个足够大的空闲块(首次适配 / 最佳适配)
- 如果块大小刚好等于需求:直接标记为「已分配」
- 如果块更大:拆分成「已分配块 + 新空闲块」,并更新链表
- 返回「数据区起始地址」(块头地址 + 块头大小)
释放流程(my_free 用链表实现)
- 根据指针找到对应的块头
- 标记块为「空闲」
- 合并相邻空闲块(避免内存碎片):
- 向前合并:如果前一个块是空闲,就和当前块合并
- 向后合并:如果后一个块是空闲,就和当前块合并
核心是:块头存管理信息,链表串起所有块,分配找空闲,释放后合并碎片。
栈:也是一块内存空间,CPU的SP寄存器指向它,它可以用于函数调用、局部变量、多任务系统里保存现场
char heap_buf[1024];
int pos=0;
int g_cnt=0;
void *my_malloc(int size)
{
int old_pos=pos;
pos+=size;
return &heap_buf[old_pos];
}
int b_func(volatile int a)
{
a+=2;
return a;
}
int c_func(volatile int a)
{
a+=3;
return a;
}
void a_func(volatile int a)
{
g_cnt=b_func(a);
g_cnt=c_func(g_cnt);
}
int main(void)
{
char ch=65;
volatile int i=99;
char *buf=my_malloc(100);
unsigned char uch=200;
for (i=0;i<26;i++)
buf[i]='A'+i;
a_func(i);
}步骤 1:定义局部变量(栈内存)
| 变量 | 类型 | 存储区域 | 初始值 | 说明 |
|---|---|---|---|---|
ch |
char | 栈 | 65('A') | 1 字节,ASCII 65 对应字符 'A' |
i |
volatile int | 栈 | 99 | 4 字节,volatile禁止编译器优化 |
buf |
char* | 栈 | 指向 heap_buf [0] | 指针变量,存储 my_malloc 返回的地址 |
uch |
unsigned char | 栈 | 200 | 1 字节,无符号 char,值在 0~255 范围内 |
步骤 1:调用 a_func(i),参数传递
main中的i=99(volatile int),作为参数传入a_func;- 因为是值传递,
a_func内部会创建一个int类型的临时变量a,并把99赋值给这个临时变量; - 注意:
a是volatile修饰的,所以编译器不会把a缓存到寄存器,读写a都直接操作内存(但单线程下这个修饰仅为示例,无实质影响)。
步骤 2:执行第一行 g_cnt = b_func(a)
- 先调用
b_func(a):把a_func中的临时变量a=99传入b_func; b_func内部逻辑:a += 2→99+2=101,然后返回101;- 把
b_func的返回值101赋值给全局变量g_cnt→ 此时g_cnt=101。
步骤 3:执行第二行 g_cnt = c_func(g_cnt)
- 先调用
c_func(g_cnt):把当前的g_cnt=101传入c_func; c_func内部逻辑:a += 3→101+3=104,然后返回104;- 把
c_func的返回值104重新赋值给g_cnt→ 此时g_cnt=104(覆盖之前的 101)。
步骤 4:a_func 执行结束
a_func是void类型,无返回值;- 唯一的副作用是修改了全局变量
g_cnt,使其最终值为104; - 函数执行完后,
a_func内部的临时变量a(值为 99)会被销毁(栈帧回收)
为了看清楚栈的具体操作,采用反汇编指令
i.a_func
a_func
0x08000734: b501 .. PUSH {r0,lr}
0x08000736: 9800 .. LDR r0,[sp,#0]
0x08000738: f000f808 .... BL b_func ; 0x800074c
0x0800073c: 4902 .I LDR r1,[pc,#8] ; [0x8000748] = 0x20000000
0x0800073e: 6048 H` STR r0,[r1,#4]
0x08000740: f000f809 .... BL c_func ; 0x8000756
0x08000744: 6048 H` STR r0,[r1,#4]
0x08000746: bd08 .. POP {r3,pc}
$d
0x08000748: 20000000 ... DCD 536870912
$t
i.b_func
b_func
0x0800074c: b501 .. PUSH {r0,lr}
0x0800074e: 9800 .. LDR r0,[sp,#0]
0x08000750: 1c80 .. ADDS r0,r0,#2
0x08000752: 9000 .. STR r0,[sp,#0]
0x08000754: bd08 .. POP {r3,pc}
i.c_func
c_func
0x08000756: b501 .. PUSH {r0,lr}
0x08000758: 9800 .. LDR r0,[sp,#0]
0x0800075a: 1cc0 .. ADDS r0,r0,#3
0x0800075c: 9000 .. STR r0,[sp,#0]
0x0800075e: bd08 .. POP {r3,pc}
i.main
main
0x08000760: b508 .. PUSH {r3,lr}
0x08000762: 2063 c MOVS r0,#0x63
0x08000764: 9000 .. STR r0,[sp,#0]
0x08000766: 2064 d MOVS r0,#0x64
0x08000768: f000f812 .... BL my_malloc ; 0x8000790
0x0800076c: 9800 .. LDR r0,[sp,#0]
0x0800076e: f7ffffe1 .... BL a_func ; 0x8000734// LR=0x08000772 返回地址,执行完a后返回下一条指令(回家地址)
// PC=a_func 0x08000734(跳转地址)
0x08000772: 2000 . MOVS r0,#0
0x08000774: bd08 .. POP {r3,pc}
如果函数嵌套调用(比如 a_func 调用 b_func,b_func 又调用其他函数),LR 的值确实会被新的 BL 指令覆盖—— 但会通过「栈」来保护 LR 的值,避免返回地址丢失。
在C入口,保存LR进栈
LR 的值会被新的 BL 指令覆盖,但因为每次调用函数前,都会把 LR(和其他寄存器)压入栈保存,所以不会丢失;函数执行完后,再从栈里恢复 LR 的值,就能正确返回。
代码调用链:main → a_func → b_func,我们跟踪每一步 LR 的变化:
步骤 1:main 调用 a_func(BL a_func)
main: 0x0800076e: f7ffffe1 BL a_func ; 0x8000734
- 动作 1:计算下一条指令地址 =
0x08000772(BL 的下一句);- 动作 2:把
0x08000772存入 LR;- 动作 3:PC 跳转到 a_func 入口
0x08000734;- 此时:
LR = 0x08000772(main 的返回地址)。
步骤 2:a_func 开头先保存 LR 到栈(关键!)
a_func: 0x08000734: b501 PUSH {r0,lr} ; 把r0(参数99)和LR(0x08000772)压入栈
栈里现在的内容(栈是向下生长的,sp 是栈指针)
栈地址(sp + 偏移) 内容 说明 sp+0 r0=99 a_func 的参数 sp+4 LR=0x08000772 main 的返回地址 此时:LR 的值被保存到栈,就算后续被覆盖也没关系。
步骤 3:a_func 调用 b_func(BL b_func)
0x08000738: f000f808 BL b_func ; 0x800074c
- 动作 1:计算下一条指令地址 =
0x0800073C;- 动作 2:把
0x0800073C存入 LR(覆盖了原来的 0x08000772);- 动作 3:PC 跳转到 b_func 入口
0x0800074c;- 此时:
LR = 0x0800073C(a_func 的返回地址)。
步骤 4:b_func 开头保存新的 LR 到栈
b_func: 0x0800074c: b501 PUSH {r0,lr} ; 把r0=99、LR=0x0800073C压入栈
栈里新增内容:
栈地址(sp + 偏移) 内容 说明 sp+0 r0=99 b_func 的参数 sp+4 LR=0x0800073C a_func 的返回地址
步骤 5:b_func 执行完,恢复 LR 并返回
0x08000754: bd08 POP {r3,pc}
- 动作 1:从栈里弹出值到 PC(弹出的是 LR=0x0800073C);
- 动作 2:PC 跳回 a_func 的
0x0800073C;- 此时:b_func 执行完毕,回到 a_func 继续执行。
步骤 6:a_func 执行完,恢复最初的 LR
0x08000746: bd08 POP {r3,pc}
- 动作 1:从栈里弹出最初保存的 LR=0x08000772 到 PC;
- 动作 2:PC 跳回 main 的
0x08000772;- 此时:a_func 执行完毕,回到 main 继续执行。
| 调用阶段 | LR 值 | 栈里保存的 LR | 是否被覆盖 | 结果 |
|---|---|---|---|---|
| main→a_func 前 | 无 | 无 | - | - |
| main→a_func 后 | 0x08000772 | 无 | 未覆盖 | LR 存 main 返回地址 |
| a_func 保存 LR 后 | 0x08000772 | 0x08000772 | - | 栈保护 LR |
| a_func→b_func 后 | 0x0800073C | 0x08000772(栈里) | 已覆盖 | 新 LR 存 a_func 返回地址 |
| b_func 返回后 | 0x0800073C | 0x08000772(栈里) | - | 回到 a_func |
| a_func 返回后 | 0x08000772 | 无 | - | 回到 main |
- LR 会被覆盖:每次执行 BL 指令,都会把新的返回地址写入 LR,覆盖旧值;
- 栈是解决方案:编译器会在函数开头自动插入
PUSH {..., lr},把 LR 压栈保存; - 核心保障:函数执行完通过
POP {..., pc}从栈恢复 LR 到 PC,实现正确返回;
局部变量在栈中分配,如何分配
int main(void) {
char ch=65; // 1字节
volatile int i=99; // 4字节
char *buf=my_malloc(100); // 4字节(指针,32位系统)
unsigned char uch=200; // 1字节
// ... 函数逻辑
}i.main
main
0x08000760: b508 .. PUSH {r3,lr}
0x08000762: 2063 c MOVS r0,#0x63
0x08000764: 9000 .. STR r0,[sp,#0]
0x08000766: 2064 d MOVS r0,#0x64
0x08000768: f000f812 .... BL my_malloc ; 0x8000790
0x0800076c: 9800 .. LDR r0,[sp,#0]
0x0800076e: f7ffffe1 .... BL a_func ; 0x8000734// LR=0x08000772 返回地址,执行完a后返回下一条指令(回家地址)
// PC=a_func 0x08000734(跳转地址)
0x08000772: 2000 . MOVS r0,#0
0x08000774: bd08 .. POP {r3,pc}
加上volatile的局部变量必须写进栈中,不能只存在寄存器中;当寄存器写满时,也会用栈来分配
为什么每个Rtos任务都有自己的栈

无 RTOS 时,只有 1 个栈(主线程栈)
在裸机程序中,整个程序只有一个栈(通常是 MSP,主栈指针):
- 所有函数调用、局部变量、寄存器保存都在这一个栈里;
- 程序执行是 “串行的”:一个函数执行完,栈帧销毁,下一个函数再用这个栈;
- 不存在 “切换”,所以一个栈足够用。
RTOS 的核心需求:任务切换,必须隔离运行状态
RTOS 的核心是多任务抢占式调度 —— 比如:
- 任务 A 正在执行
a_func,局部变量i=99存在栈里,寄存器r0=99、lr=0x08000772; - 调度器触发(比如定时器中断),暂停任务 A,切换到任务 B 执行;
- 任务 B 执行自己的函数,局部变量
j=100、寄存器r0=100; - 稍后调度器切回任务 A,要求任务 A 能 “无缝继续执行”(就像没被暂停过)。
如果所有任务共用一个栈,会发生什么?
- 任务 B 的局部变量会覆盖任务 A 的栈数据(比如任务 A 的
i=99被改成j=100); - 任务 B 的函数调用会覆盖
lr、pc等寄存器值,切回任务 A 时,返回地址丢失,程序直接跑飞。
👉 结论 1:每个任务必须有独立栈,用来存储「专属的局部变量、函数调用栈帧、寄存器状态」,切换时互不干扰。
1. 存储任务的局部变量和函数栈帧
每个任务执行自己的函数时,局部变量(如i、buf)、函数调用的PUSH/POP操作,都在自己的栈里完成:
- 任务 A 的
i=99存在任务 A 的栈,任务 B 的j=100存在任务 B 的栈; - 即使两个任务调用同一个函数(比如
a_func),各自的栈帧也是独立的,参数 / 返回值互不影响。
2. 保存任务切换时的 “上下文”
RTOS 切换任务的本质是「保存当前任务上下文 → 恢复目标任务上下文」,而上下文(寄存器、PC、LR 等)会被保存到任务自己的栈里;
- 如果没有独立栈,保存 / 恢复上下文时会覆盖其他任务的数据,切换后任务无法正常执行。
3. 避免栈溢出影响其他任务
每个任务的栈大小是独立配置的(比如 FreeRTOS 中xTaskCreate的usStackDepth参数):
- 即使任务 A 发生栈溢出,也只会破坏自己的栈空间,不会影响任务 B/C 的运行;
- 如果共用栈,一个任务栈溢出会直接导致整个系统崩溃。
FreeRtos源码概述
FreeRTOS 目录结构
使用STM32CubeMX 创建的FreeRTOS工程中,FreeRTOS相关的源码如下:

主要涉及2个目录:
Core
Inc目录下的FreeRTOSConfig.h是配置文件
Src目录下的freertos.c是STM32CubeMX创建的默认任务
Middlewares\Third_Party\FreeRTOS\Source
根目录下是核心文件,这些文件是通用的
portable 目录下是移植时需要实现的文件
目录名为:[compiler]/[architecture] 比如:RVDS/ARM_CM3,这表示cortexM3架构在RVDS工具上的移植文件
核心文件
FreeRTOS的最核心文件只有2个:
FreeRTOS/Source/tasks.c FreeRTOS/Source/list.c 其他文件的作用也一起列表如下:
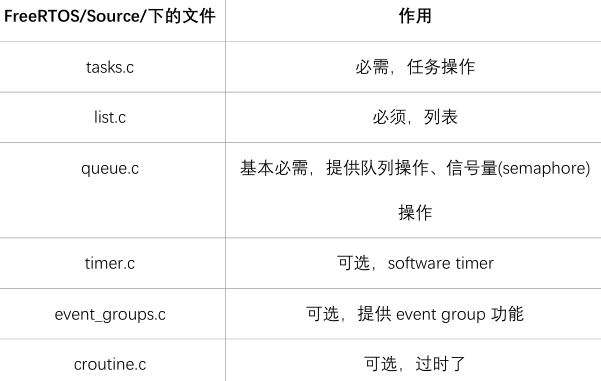
移植时涉及的文件
移植FreeRTOS时涉及的文件放在
FreeRTOS/Source/portable/[compiler]/[architecture]目录下, 比如:RVDS/ARM_CM3,这表示cortexM3架构在RVDS或Keil工具上的移植文件。 里面有2个文件:
port.c portmacro.h
头文件相关
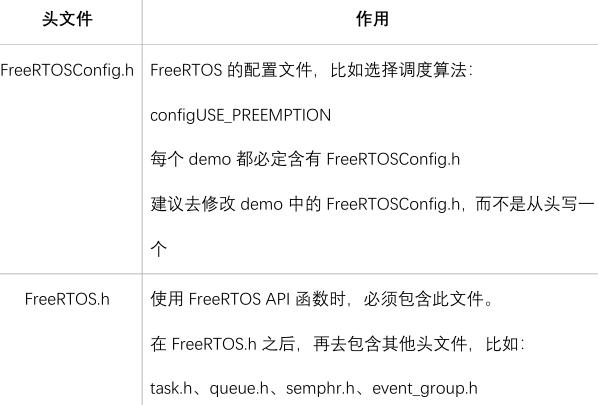
头文件目录
FreeRTOS需要3个头文件目录:
FreeRTOS本身的头文件: Middlewares\Third_Party\FreeRTOS\Source\include
移植时用到的头文件: Middlewares\Third_Party\FreeRTOS\Source\portable\[compiler]\[architecture]
含有配置文件FreeRTOSConfig.h的目录:Core\Inc
头文件
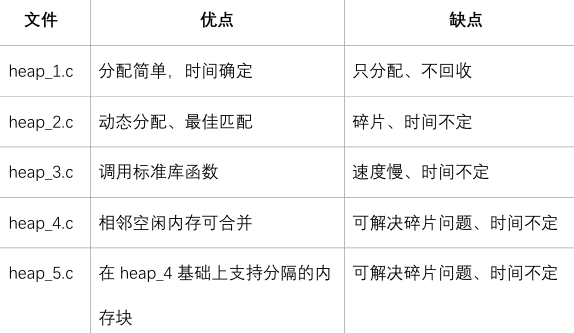
内存管理
文件在Middlewares\Third_Party\FreeRTOS\Source\portable\MemMang 下,它也是放在“portable”目录下,表示你可以提供自己的函数。 源码中默认提供了5个文件,对应内存管理的5种方法。 (堆)
如何去使用freertos中的堆
入口函数
在Core\Src\main.c 的 main 函数里,初始化了FreeRTOS环境、创建了任务,然后启动调度器。源码如下:
/* Init scheduler */
osKernelInitialize(); /* 初始化FreeRTOS运行环境 */
MX_FREERTOS_Init();
/* 创建任务 */
/* Start scheduler */
osKernelStart();
/* 启动调度器 */数据类型和编程规范
数据类型
每个移植的版本都含有自己的portmacro.h头文件,里面定义了2个数据类型:
TickType_t:
FreeRTOS配置了一个周期性的时钟中断:TickInterrupt
每发生一次中断,中断次数累加,这被称为tickcount
tickcount这个变量的类型就是TickType_t
TickType_t 可以是16位的,也可以是32位的
FreeRTOSConfig.h 中定义configUSE_16_BIT_TICKS 时,TickType_t 就是 uint16_t 否则TickType_t就是uint32_t
对于32位架构,建议把TickType_t配置为uint32_t
BaseType_t:
这是该架构最高效的数据类型
32位架构中,它就是uint32_t 16位架构中,它就是uint16_t 8位架构中,它就是uint8_t
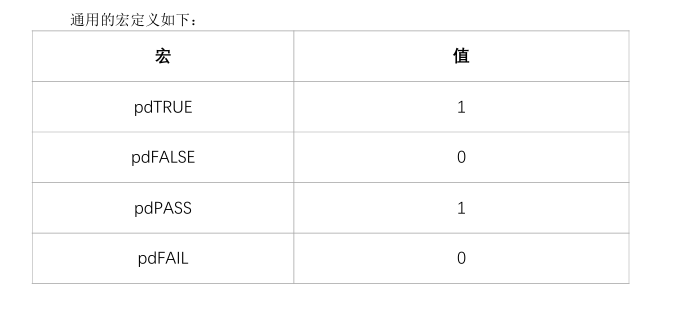
BaseType_t 通常用作简单的返回值的类型,还有逻辑值,比如pdTRUE/pdFALSE
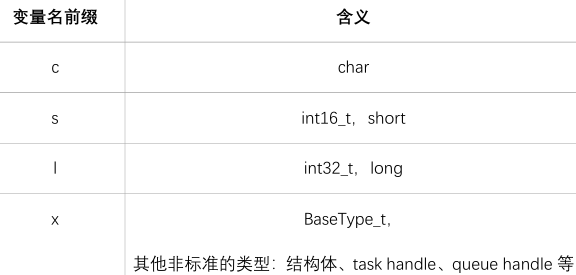
变量名
变量名有前缀

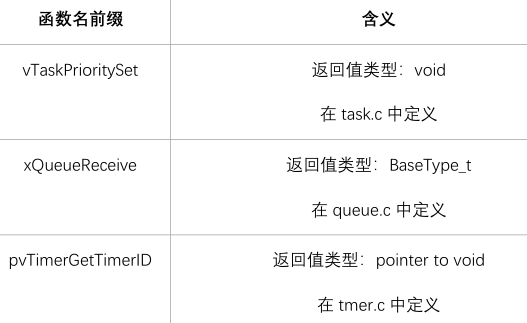
函数名
函数名的前缀有2部分:返回值类型、在哪个文件定义。
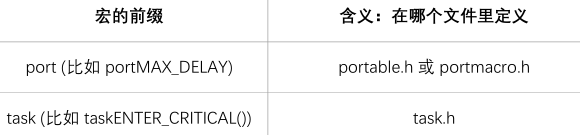
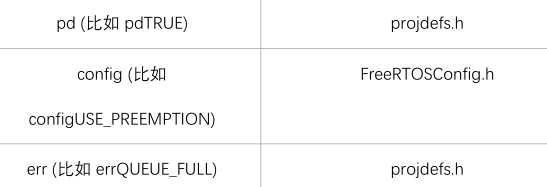
宏的名
宏的名字是大小,可以添加小写的前缀。前缀是用来表示:宏在哪个文件中定义。
内存管理
- FreeRTOS 内核对象的管理方式:task、queue、信号量、事件组等内核对象通常采用动态分配(用时分配、不用释放),能简化程序设计,无需提前规划对象、简化 API 设计,还可减少内存占用;
- 标准 C 内存管理函数(malloc/free)不适用 FreeRTOS 的原因:适配性差(嵌入式资源紧缺、代码体积大)、线程不安全、执行时间不确定、易产生内存碎片、编译器配置复杂且调试困难;
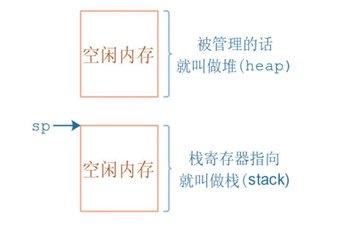
- 堆与栈的核心区别:堆是需管理函数(malloc/free)的空闲内存块,用于动态分配空间;栈用于存储函数局部变量和程序运行环境,也可从堆中分配空间作为栈使用,二者并非同一概念。
FreeRTOS中内存管理的接口函数为:pvPortMalloc、vPortFree,对应于C库的malloc、 free。
文件在FreeRTOS/Source/portable/MemMang下,它也是放在portable目录下,表示你可以提供自己的函数。 源码中默认提供了5个文件,对应内存管理的5种方法。
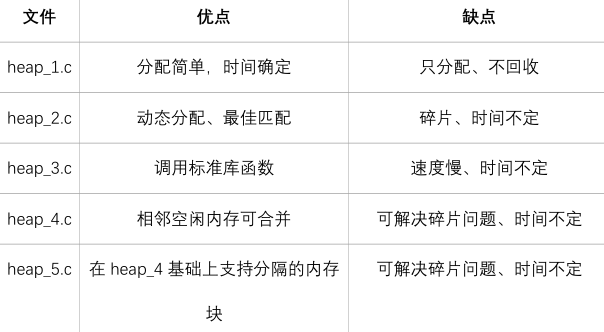
常使用heap_4,多个内存使用heap_5;
heap相关函数
pvPortMalloc/vPortFree
函数原型:
void * pvPortMalloc( size_t xWantedSize );
void vPortFree( void * pv );
作用:分配内存、释放内存。 如果分配内存不成功,则返回值为NULL。
xPortGetFreeHeapSize
函数原型:
size_t xPortGetFreeHeapSize( void );
当前还有多少空闲内存,这函数可以用来优化内存的使用情况。比如当所有内核对象都分配好后,执行此函数返回2000,那么configTOTAL_HEAP_SIZE就可减小2000。 注意:在heap_3中无法使用。
xPortGetMinimumEverFreeHeapSize
函数原型: size_t xPortGetMinimumEverFreeHeapSize( void );
返回:程序运行过程中,空闲内存容量的最小值。
注意:只有heap_4、heap_5支持此函数。
malloc 失败的钩子函数
在pvPortMalloc 函数内部:
void * pvPortMalloc( size_t xWantedSize )vPortDefineHeapRegions
{ ...... #if ( configUSE_MALLOC_FAILED_HOOK == 1 )
{
if( pvReturn == NULL )
{ extern void vApplicationMallocFailedHook( void );
vApplicationMallocFailedHook(); }
} #endif
return pvReturn;
}
所以,如果想使用这个钩子函数:
- 在FreeRTOSConfig.h 中,把configUSE_MALLOC_FAILED_HOOK定义为1
- 提供vApplicationMallocFailedHook 函数
- pvPortMalloc 失败时,才会调用此函数

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)