三者是 自动驾驶与计算机视觉领域的核心学术开源力量,形成 " 基础视觉研究 + 自动驾驶专用研究 + 通用视觉工具链" 的协同生态,同属上海人工智能实验室大框架下,共享技术理念与生态底座,在 BEV 感知等前沿方向深度协作 Hongyang Li 。
- 联合研究团队:BEVFormer 等核心项目由三机构共同完成,作者团队包含代季峰(FundamentalVision)、李弘扬(OpenDriveLab)、虞乔(上海 AI Lab)等核心成员fundamentalvision.github.io
- 技术传承:FundamentalVision 的 Deformable ConvNets 系列被 OpenMMLab 广泛集成,成为 3D 检测与 BEV 感知的核心组件
- 生态共享:三者均依托上海人工智能实验室,在 OpenXLab 浦源平台共享预训练模型与技术成果
- FundamentalVision 提供 "核心算法创新":如 BEVFormer 中的时空 Transformer 架构、可变形注意力机制
- OpenDriveLab 提供 "自动驾驶场景落地":将通用视觉算法适配驾驶场景,解决时序一致性、多模态融合等领域难题OpenDriveLab
- OpenMMLab 提供 "工程化工具链":将学术创新封装为模块化组件,提供训练 / 评估 / 部署全流程支持,降低落地门槛
- 合作深度:三机构联合开发,代码由 FundamentalVision 维护(https://github.com/fundamentalvision/BEVFormer)
- 核心创新:通过时空 Transformer 学习多摄像机图像的鸟瞰图表示,首次实现纯视觉 BEV 感知性能媲美激光雷达方案
- OpenMMLab 集成:被深度整合到 MMDetection3D 中,成为 OpenMMLab 生态的核心 BEV 感知模块,支持 nuScenes/KITTI 等主流自动驾驶数据集
- 行业影响:被英伟达 CEO 黄仁勋等高度评价,成为特斯拉 Autopilot 等工业界系统的参考方案
- 合作机构:FundamentalVision + OpenDriveLab + 上海人工智能实验室fundamentalvision.github.io
- 核心目标:将多模态大语言模型与驾驶行为规划状态对齐,提升复杂场景下的决策可解释性fundamentalvision.github.io
- 技术路径:基于 BEVFormer 的视觉表征,融合驾驶场景图与自然语言理解,实现 "感知 - 预测 - 规划 - 语言" 的统一建模fundamentalvision.github.io
- 数据处理接口统一:三机构共同维护 nuScenes/KITTI 等自动驾驶数据集的 BEV 格式处理流程,推动基准统一
- 模型优化协同:OpenDriveLab 基于 MMDetection3D 的 BEVFormer 模块开发端到端驾驶方案;FundamentalVision 提供可变形注意力优化;OpenMMLab 负责工程化与性能调优
- 部署工具共享:均通过 MMDeploy 实现模型到 ONNX/TensorRT 的转换,适配车载边缘设备(如 Jetson Orin)
三者形成了 **"基础研究→场景适配→工程化落地" 的完整技术闭环 **:
- FundamentalVision 探索视觉感知的 "根技术",为上层应用提供理论支撑
- OpenDriveLab 将基础技术转化为自动驾驶场景的解决方案,验证技术实用性
- OpenMMLab 提供通用工具链,让技术成果快速普及到全行业
对自动驾驶开发者而言,三者是 不可或缺的组合:用 MMDetection3D 快速搭建基线模型,用 OpenDriveLab 的 UniAD 探索前沿方向,参考 FundamentalVision 的 BEVFormer 核心代码优化性能,实现效率与创新的平衡。
需要我整理一份基于三者协同的自动驾驶 BEV 感知开发流程(从环境搭建→模型选择→训练→部署)的极简教程吗?


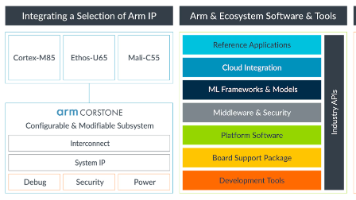
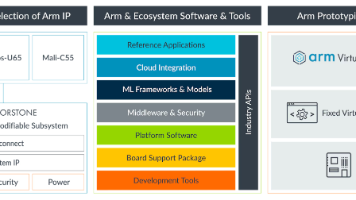
 5
5 0
0


 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)