
上海AI实验室介绍(二):OpenXLab等
开源:LMDeploy、实战、MindSearch、XTuner、OpenCompass;OpenXLab:开放项目、应用中心、模型中心、数据集中心、文档中心;OpenMMLab:MMDetection、Amphion、MMSegmentation;OpenXRLab;OpenGVLab:Ask-Anything;OpenDataLab:MinerU、PDF-Extract-Kit;OpenMED
开源
LMDeploy
GitHub,上海AI实验室,MMRazor和MMDeploy团队联合开发推出的大模型推理部署工具,能显著提升大模型的推理性能,支持多种硬件架构,包括英伟达的Hopper和Ampere系列GPU,实现FP8和MXFP4等高效量化技术。提供从模型量化、部署、推理优化、服务的全流程支持,支持多机多卡分布式推理,能满足大规模生产环境的需求。具备良好的兼容性和易用性,方便开发者快速部署和使用大语言模型。
主要功能
- 高效推理:通过优化的推理引擎,能显著提升LLM的推理速度,降低延迟,提高吞吐量。支持多种硬件架构,如NVIDIA的Hopper和Ampere系列GPU,能充分利用硬件资源,实现高效的并行计算;
- 有效量化:提供先进量化技术,如FP8和MXFP4量化,在保持模型精度的同时,大幅减少模型存储和计算资源的需求;
- 易于部署:提供一套完整的部署工具,支持从模型训练到推理的全流程部署。工具支持多机多卡分布式推理,能满足大规模生产环境的需求,提供交互式推理模式,方便开发者进行调试和测试;
- 优秀兼容性:支持多种LLM,如Qwen等,能与现有的深度学习框架(如PyTorch)无缝集成。工具支持多种推理后端,如TensorRT、DeepSpeed等,为开发者提供灵活选择。
提供双引擎(TurboMind/PyTorch)可选项,既追求极致性能,也兼顾易用性;支持海量LLM/VLM,提供OpenAI兼容服务与离线Pipeline,并内置KV Cache INT4/INT8在线量化等特性。近期还加入DeepSeek系列加速组件、PD分离部署生态集成等前沿优化。
- 高效量化:权重与KV Cache在线量化(INT8/INT4),在不显著牺牲质量的前提下降低显存、提升并发。https://lmdeploy.readthedocs.io/en/latest/quantization/kv_quant.html
- 服务形态:OpenAI兼容API Server,以及请求分发(多模型/多机多卡)的代理服务。
TurboMind支持MXFP4(V100+可用),在H800上推理gpt-oss模型性能可达vLLM的1.5×;引入DeepSeek系列优化(FlashMLA、DeepGemm、DeepEP、MicroBatch、eplb等)及PD分离部署生态(DLSlime、Mooncake),便于大规模推理与跨节点缓存流动。
性能
- 显存与并发:KV Cache INT4/INT8 在线量化 + 持续批处理,可显著降低并发单连接的 VRAM 占用、提高同时会话数
- 最新精度/硬件特性:MXFP4 与 FP8 路线在 Hopper/Ampere 代 GPU 上进一步释放吞吐—延迟平衡;与 PD 分离部署生态(MoE/超长上下文/海量并发)结合后,易于做跨节点 KV 远端化 与 Prefill/Decode 解耦。
- 量化覆盖全链路:权重+KV Cache在线量化,同时提供长上下文的Prefix Caching等配套能力
技术原理
- 双引擎架构:
- TurboMind:C++/CUDA实现,追求极致吞吐与时延,技术包括:连续批处理、Blocked KV、CUDA Graph、动态split&fuse、并行切分、自研高性能Kernel等。对标vLLM,在多项测试中达到1.3到1.8倍左右RPS(Requests Per Second)吞吐领先;
- PyTorch Engine:纯Python,更易于二开和实验(已支持Ascend/图模式、CUDA Graph等)。
- 量化技术:基于先进量化技术,如FP8和MXFP4量化。通过将模型的权重和激活值从浮点数转换为低精度的量化值,减少模型的存储和计算资源需求。通过优化量化算法,确保量化后的模型精度损失最小化。4比特推理相对FP16/BF16可达2.4倍Token/s提升(小Batch更明显)
- 稀疏化技术:支持稀疏化技术,通过将模型的权重矩阵稀疏化,进一步减少模型的存储和计算资源需求。稀疏化技术能显著提高模型的推理速度,同时保持模型的精度;
- 推理优化:对推理过程进行深度优化,包括指令融合、内存优化等。通过将多个操作合并为一个操作,减少操作的开销。同时,通过优化内存分配和访问,提高内存的利用效率,进一步提升推理速度;
- 分布式推理:支持多机多卡分布式推理,通过将模型分割成多个片段,分布在不同的设备上进行计算,实现高效的并行计算。分布式推理能显著提高模型的吞吐量,满足大规模生产环境的需求。
实战
部署
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy
零样本推理(离线Pipeline)
import lmdeploy
with lmdeploy.pipeline("internlm/internlm3-8b-instruct") as pipe:
res = pipe(["Hi, pls intro yourself", "Shanghai is"])
print(res)
默认从HuggingFace拉取模型;如需ModelScope或OpenMind Hub,安装对应SDK并设置环境变量:
pip install modelscope && export LMDEPLOY_USE_MODELSCOPE=True
pip install openmind_hub && export LMDEPLOY_USE_OPENMIND_HUB=True
注意不同平台的chat template兼容,通过lmdeploy list查看。
一键部署OpenAI兼容API服务
# 单机多卡
lmdeploy serve api_server --model internlm/internlm3-8b-instruct --tp 2 --session-len 8192 --cache-max-size-mb 55000
- API用法与OpenAI SDK基本一致;多模型/多机多卡请用Request Distributor(代理服务)。开启KV Cache在线量化(降显存/提并发)
# INT4/INT8 KV Cache示例(按引擎参数名设置)
lmdeploy serve api_server --model internlm/internlm3-8b-instruct --kv-int4 true --cache-max-size-mb 55000
KV Cache在线量化自v0.4.0起提供,采用非对称per-head、per-token策略;官方已移除旧的离线kv量化方案。
如果不想搭服务,可直接使用离线Pipeline在本机做批量推理;或在Colab/Notebook里跑起来,不涉及长期常驻进程与端口暴露:
- 官方文档提供离线推理代码段与Colab入口;
- 若需要临时对外提供API,可在本地短时启动API Server,或考虑云上即开即用,如Vast.ai社区教程;
- 对于只做评测与离线处理的场景(如生成数据集、跑对齐脚本、做大规模文本生成),只用lmdeploy.pipeline即可,既无需额外网关/负载均衡,也避免服务面暴露带来的安全面与成本。
实战建议与排坑清单
- 在生产环境里,优先结合连续批处理+KV量化+长上下文优化(如Automatic Prefix Caching)与合理的并行策略(TP/PP/EP/MoE),可在稳定性、成本与QPS之间拿到更优折中。
- 优先选TurboMind(对性能敏感):开启连续批处理、KV在线量化、CUDA Graph(在PyTorch引擎亦可见收益),并结合
session-len、cache-max-size-mb进行容量规划。 - 多模型/多卡/多机:
- 单机:api_server+
--tp/--pp等并行参数; - 多模型/多机:Request Distributor(代理服务)按路由/负载均衡转发。
- 单机:api_server+
- MoE/DeepSeek系列:若追求极致成本/吞吐,关注PD分离与KV远端化实践,并结合微批(MicroBatch)取平衡,参考。
MindSearch
GitHub,6.7K Star,667 Fork。技术报告。
一个AI深度搜索引擎,致力于像人类一样思考、分解问题,搜索信息,从而得出最终结论。
对深度研究(DeepResearch)感兴趣的,可继续阅读DeepResearch(上)。
XTuner
另起一篇,参考XTuner。
OpenCompass
另起一篇,参考OpenCompass。
OpenXLab
一个AI开源开放平台,由上海AI实验室推出。
主页:
功能:
- 提供AI模型的托管、部署、演示和协作开发服务;
- 类似于AI版的GitHub+Colab,支持一键启动模型、在线体验、训练和推理;
- 支持多种硬件环境(包括云端和本地)。
开放项目
开源项目:
- OpenMMLab:浦视,视觉智能开源平台。深度学习时代全球最具影响力的视觉算法开源项目,目前已开放2500多算法模型,被全球110多个国家和地区的百万开发者应用。GitHub主页,国际版官网,国内版
- OpenXRLab:浦实,扩展现实开源平台。一站式解决扩展现实领域算法需求的开源平台。包含基础底层、空间计算、多模态人机交互和生成渲染的一站式扩展现实平台,提供服务于XR应用的一套全面的工具链、算法库和基准测试,致力于打造XR生态,加速算法验证,助力业务落地。GitHub主页,官网。
- OpenInnoLab:浦育,青少年人工智能开放创新平台。专为青少年打造的AI开放学习平台,提供一站式AI学习服务,包括前沿、多元的AI创作工具和丰富的课程、体验、实践案例、科创活动,鼓励青少年应用AI工具进行科学探究与应用创新。官网。
- OpenGVLab:通用视觉开源平台。研发国内首个广泛覆盖多种视觉任务的通用大模型书生INTERN,在分类、目标检测、语义分割、深度估计四大视觉领域,均以小数据、低能耗实现最优准确度,是中国原创视觉大模型的典范。GitHub主页,官网
- OpenDataLab:浦数,人工智能数据开源开放平台。面向人工智能开发者的新一代超大规模、高质量、多模态公开数据集开放平台,致力于引领AI大模型时代开放共享,让数据集触手可及。GitHub主页,官网
- OpenMEDLab:浦医,医疗多模态基础模型开源平台。全球首个开源医疗多模态基础模型群。作为医疗多模态基础模型的开源平台,覆盖医学图像、医学文本和生物蛋白质等多种数据模态。致力于有效解决医疗长尾问题和AI模型研发的高成本、低效率、泛化差等问题,使得基于医疗基础模型的跨领域、跨疾病、跨模态、高效率的研发创新变为可能。GitHub主页。
- OpenDlLab:浦策,开源决策智能平台。演化即无限。国际上首个覆盖最全学术算法及工业规模的开源决策AI平台。打通产学研需求闭环,打破决策AI研究与产业需求之间无形的壁垒,加速决策AI行业应用创新,构建一系列到手即用的工业应用生态,引领AI迈向更高阶的通用智能。
- DeepLink:浦算,人工智能开放计算体系,一套针对深度学习领域的开放软硬件接口体系,作为硬件与深度学习框架适配的桥梁,厂商一次适配即可支持主流算法生态,根本性实现软硬件解耦,释放国产算力。GitHub主页,官网。
- OpenDriveLab:浦驾,自动驾驶开放平台,致力于探索前沿自动驾驶技术,涵盖自动驾驶大模型、端到端自动驾驶、BEV感知、通用人工智能等多个研究方向。致力于探索前沿自动驾驶技术,推出标杆性工作,开源服务社区,推动国际化交流,推动行业共同发展,让未来的出行更加安全、便捷和智能。GitHub主页,官网
- OpenXDLab:浦画,高质量数字内容平台。作为现实世界数字化的三维空间、四维时空数据的生产工厂,覆盖人脸、人体与物体高质量标注的全面多视角、高分辨率3D/4D数据集,致力于为高维人工智能发展注入无穷动力。
- OpenEGLab:蒲公英,人工智能治理开放平台。规则-技术-场景-评测一体协同的AI治理体系与平台。致力于打造系统、实用的人工智能伦理与治理基础设施,促进AI以人为本理念落地实践,支撑AI可信、可持续发展。
- OpenRobotLab:浦器,具身智能开放平台。致力于构建软硬虚实一体化的通用机器人算法体系,探索多模态感知与自主行为关键技术,驱动智能体在真实世界交互与学习。
探索项目:
- V3Det:超大类别检测数据集,包括多达13,029个类别,组成了一棵完善的类别关系树,是目前世界上类别最多的检测数据集。GitHub,官网,论文。
- CONE:一个中文为核心的轻量级多语言翻译模型,由300+语言数据训练得到的单个翻译模型。GitHub。
应用中心
功能一目了然,和ModelScope的社区有点类似: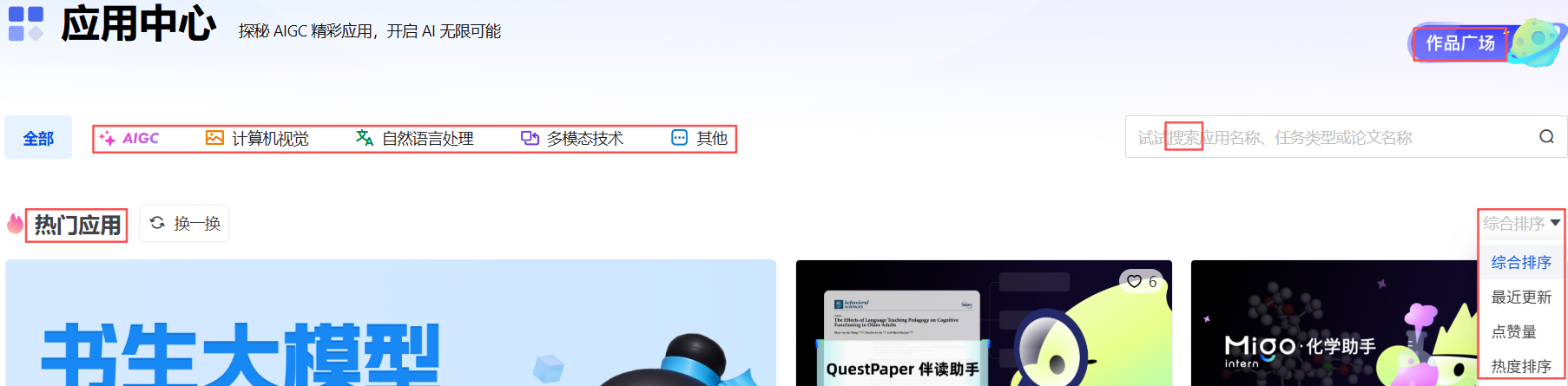
当前应用个数636,不算多,目测还在运营推广阶段: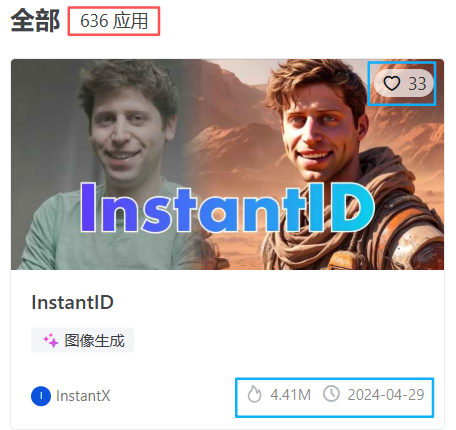
模型中心
提供模型上传、下载、构建自定义推理服务、应用集成使用以及SD模型微调等诸多功能。当前已经托管1822种模型,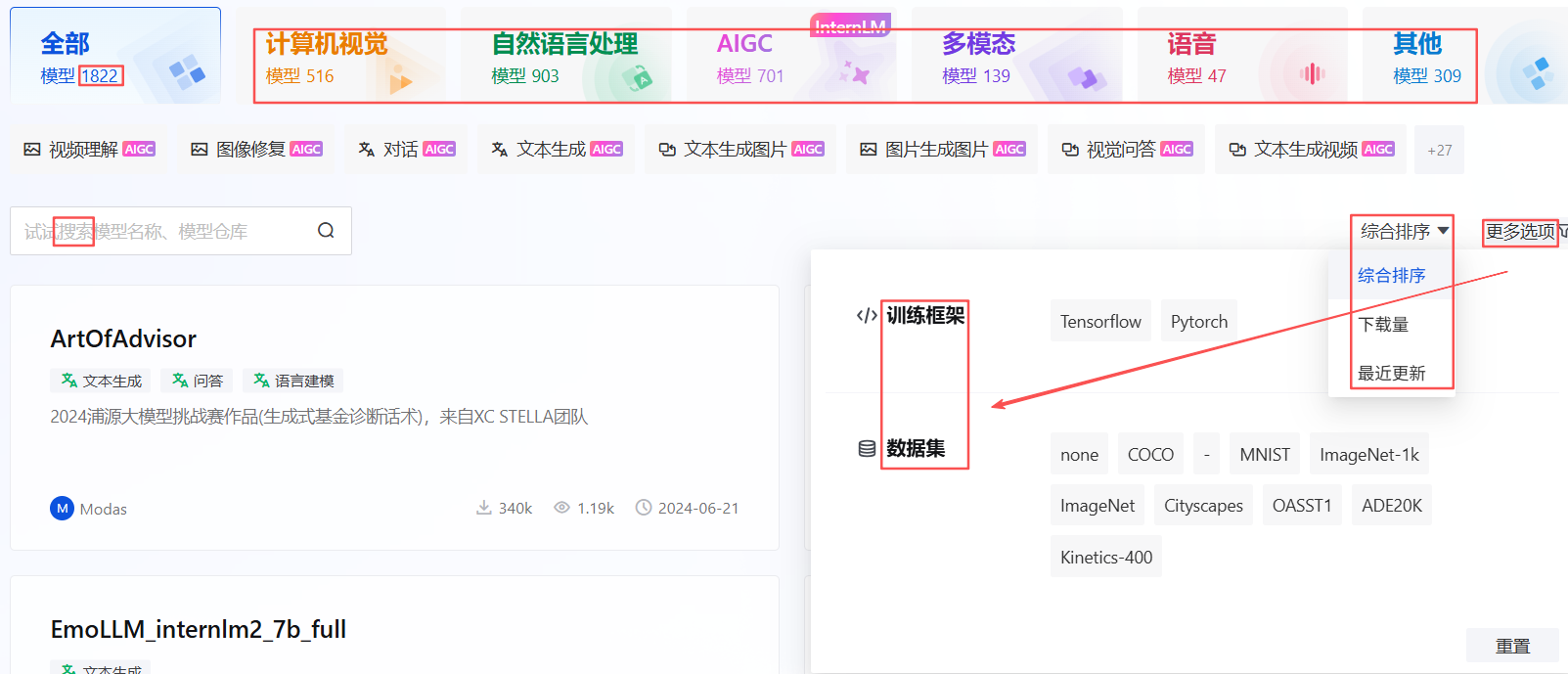
数据集中心
当前托管有7588个数据集,搜索方式包括:数据类型、数据集大小、任务类型。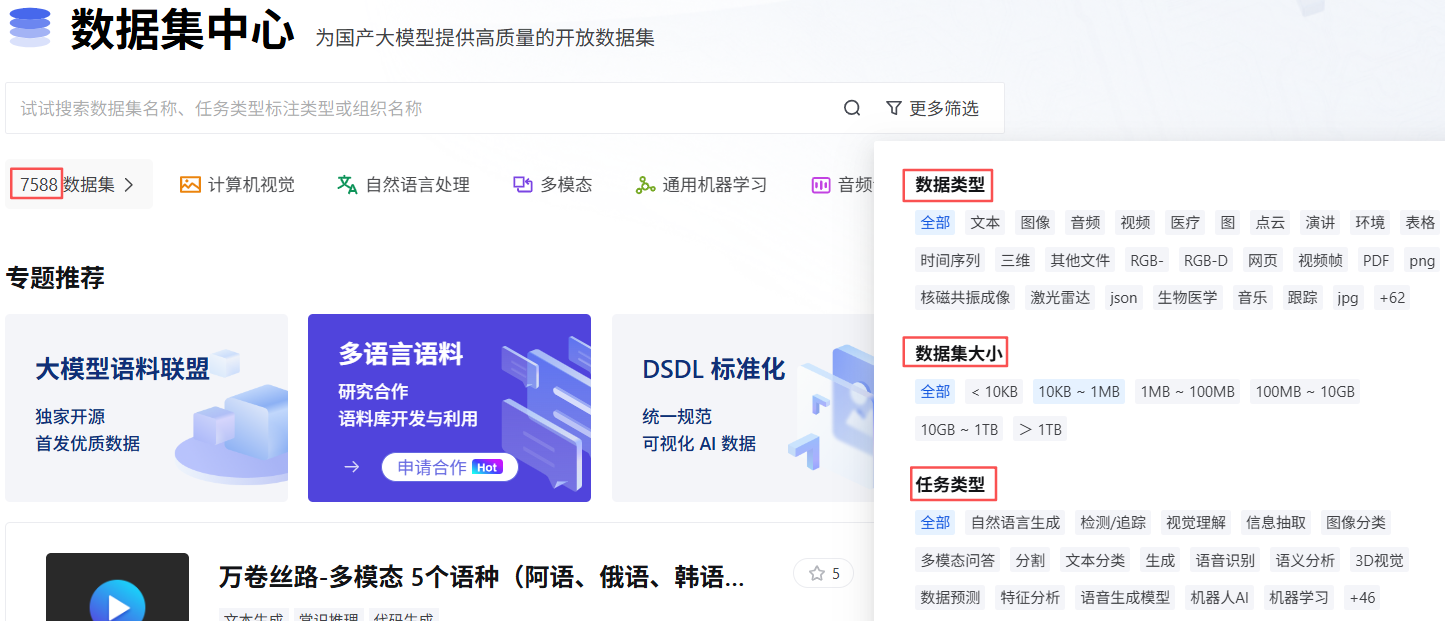
文档中心
非常齐全,超链跳转,业界良心。
OpenMMLab
开放平台。很可惜,不少项目GitHub代码已长达一年半未维护,Issues非常多。
MMDetection
技术报告,官方文档,基于PyTorch的目标检测开源(GitHub,31.8K Star,9.8K Fork)工具箱。
主要特性
- 模块化设计:将检测框架解耦成不同的模块组件,通过组合不同的模块组件,用户可便捷地构建自定义的检测模型;
- 支持多种检测任务:支持各种不同的检测任务,包括目标检测,实例分割,全景分割,以及半监督目标检测;
- 速度快:基本的框和mask操作都实现GPU版本,训练速度比其他代码库更快或相当,包括Detectron2,maskrcnn-benchmark和SimpleDet;
- 性能高:算法库源自于COCO2018目标检测竞赛的冠军团队MMDet团队开发的代码,持续进行改进和提升。新发布的RTMDet还在实时实例分割和旋转目标检测任务中取得最先进的成果,同时也在目标检测模型中取得最佳的的参数量和精度平衡。
依赖于深度学习训练库MMEngine和计算机视觉基础库MMCV。
Amphion
开源(GitHub,9.4K Star,762 Fork)音频、音乐和语音生成工具包,旨在为音频研究成果的复现提供支持,并帮助研究人员和工程师快速入门音频、音乐和语音生成领域的研究与开发。
核心目标是提供一个用于研究把任意输入转化为音频的平台,能支持各类音频生成任务,包括:TTS文本转语音,SVS歌声合成,VC语音转换,AC口音转换,SVC歌声转换,TTA文本转音频,TTM文本转音乐等。
还提供多种声码器和评估指标,声码器是生成高质量音频信号的重要模块,而评估指标对于确保生成任务中指标的一致性至关重要。
支持模型或架构:FastSpeech2、VITS、VALL-E、NaturalSpeech2、Jets、MaskGCT。
安装:
# 通过Docker
docker run --runtime=nvidia --gpus all -it -v .:/app realamphion/amphion
# 源码
git clone https://github.com/open-mmlab/Amphion.git
cd Amphion
conda create --name amphion python=3.12
conda activate amphion
sh env.sh
示例:
from models.tts.valle.valle_inference import ValleInference
import librosa
import torch
from IPython.display import Audio
wav, _ = librosa.load('./egs/tts/VALLE_V2/example.wav', sr=16000)
wav = torch.tensor(wav, dtype=torch.float32)
Audio(wav, rate=16000)
MMSegmentation
简称MMSeg,官方文档,基于PyTorch的开源(GitHub,9.3K Star,2.8K Fork)语义分割工具箱。
主要特性
- 统一的基准平台:将各种各样的语义分割算法集成到了一个统一的工具箱,进行基准测试;
- 模块化设计:将分割框架解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的分割模型;
- 丰富的即插即用的算法和模型:支持众多主流的和最新的检测算法,如PSPNet,DeepLabV3,PSANet,DeepLabV3+等;
- 速度快:训练速度比其他语义分割代码库更快或相当。
OpenXRLab
OpenGVLab
Ask-Anything
技术报告,
用于视频理解的视频聊天工具(机器人),
OpenDataLab
MinerU
有待另起一篇,参考MinerU理论与实战。
PDF-Extract-Kit
基础算法模块:
- 布局检测算法
- 公式检测算法
- 公式识别算法
- OCR算法
- 表格识别算法
- 阅读顺序算法
布局检测:文档内容提取的基础任务,目标是对页面中不同类型的区域进行定位:如图像、表格、文本、标题等,方便后续高质量内容提取。对于文本或标题等区域,可基于OCR模型进行文字识别,其他类推。
支持以下模型:
| 模型 | 简述 | 特点 | 模型权重 | 配置文件 |
|---|---|---|---|---|
| DocLayout-YOLO | 基于YOLO-v10改进: 1.生成多样性预训练数据,提升对多种类型文档泛化性 2.模型结构改进,提升对多尺度目标感知能力 详见DocLayout-YOLO |
速度快、精度高 | doclayout_yolo_ft.pt | layout_detection.yaml |
| YOLO-v10 | 基础YOLO-v10模型 | 速度快,精度一般 | yolov10l_ft.pt | layout_detection_yolo.yaml |
| LayoutLMv3 | 基础LayoutLMv3模型 | 速度慢,精度较好 | layoutlmv3_ft | layout_detection_layoutlmv3.yaml |
执行布局检测程序python scripts/layout_detection.py --config configs/layout_detection.yaml
公式检测:针对给定的输入图像,检测出图像中所有包含公式的位置(包含行内公式和行间公式)。
python scripts/formula_detection.py --config configs/formula_detection.yaml
公式识别:指给定输入公式图像,识别公式图像内容并转为LaTeX格式。python scripts/formula_recognition.py --config configs/formula_recognition.yaml
运行OCR算法脚本:python scripts/ocr.py --config configs/ocr.yaml
表格识别是指输入表格图像,识别表格结构和内容,并将其转换为LaTeX或HTML等格式。python scripts/table_parsing.py --config configs/table_parsing.yaml
安装
conda create -n pdf-extract-kit-1.0 python=3.12 -y
conda activate pdf-extract-kit-1.0
pip install -r requirements.txt
# 或CPU设备
pip install -r requirements-cpu.txt
目前包含
- 布局检测:YOLO系列,YOLOv10、DocLayout-YOLO
- 公式检测:YOLO系列,YOLOv8
- 公式识别:UniMERNet
- OCR:PaddleOCR
LabelU
一款综合性的数据标注平台,专为处理多模态数据而设计。旨在通过提供丰富的标注工具和高效的工作流程,帮助用户更轻松地处理图像、视频和音频数据的标注任务,满足各种复杂的数据分析和模型训练需求。在线体验
功能
- 多功能图像标注工具:为图像标注提供全面的工具集,包括2D框、语义分割、多段线、关键点等多种标注方式。能灵活应对诸如目标检测、场景分析、图像识别、机器翻译等各种图像处理任务,帮助用户高效完成图像的标识、注释和分析;
- 强大的视频标注功能:支持视频分割、视频分类以及视频信息提取等功能。非常适合应用于视频检索、视频摘要、行为识别等任务,使用户能够轻松处理长时段视频,精准提取关键信息,支持复杂场景分析,为后续的模型训练提供高质量的标注数据;
- 高效的音频标注工具:具备高效、精准的音频分析能力,支持音频分割、音频分类和音频信息提取。通过将复杂的声音信息直观化展示,简化音频数据的处理流程,助力更准确的模型开发;
- 人工智能辅助标注:支持预标注数据的一键载入,用户可根据实际需要对其进行细化和调整,提高标注的效率和准确性。
特性
- 简易,提供多种图像标注工具,通过简单可视化配置即可标注;
- 灵活,多种工具可自由组合使用,满足大部分图像,视频,音频的标注需求;
- 通用,支持导出多种数据格式,包括JSON,COCO,MASK。
部署:
conda create -n labelu python=3.11
conda activate labelu
pip install labelu
# 或安装带mysqlclient的版本
pip install labelu[mysql]
# 启动
labelu
OpenMEDLab
Awesome-Medical-Dataset
GitHub收录医学数据集。
DeepLink
OpenDriveLab
UniAD
参考

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)