
20倍效率跃升!小米开源MiDashengLM-7B:音频大模型的效率革命与全场景落地
# 20倍效率跃升!小米开源MiDashengLM-7B:音频大模型的效率革命与全场景落地## 导语小米全量开源的MiDashengLM-7B音频大模型,以"精度与效率双突破"重新定义多模态交互标准,在22项权威评测中刷新SOTA,单样本推理延迟仅为同类模型1/4,同等显存下并发能力提升20倍,为智能家居、自动驾驶等实时场景提供高效音频理解解决方案。## 行业现状:多模态交互的"效率瓶颈
20倍效率跃升!小米开源MiDashengLM-7B:音频大模型的效率革命与全场景落地
【免费下载链接】midashenglm-7b  项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b
项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b
导语
小米全量开源的MiDashengLM-7B音频大模型,以"精度与效率双突破"重新定义多模态交互标准,在22项权威评测中刷新SOTA,单样本推理延迟仅为同类模型1/4,同等显存下并发能力提升20倍,为智能家居、自动驾驶等实时场景提供高效音频理解解决方案。
行业现状:多模态交互的"效率瓶颈"困境
2025年全球多模态大模型市场规模预计达1280亿美元,但音频理解领域长期面临三重矛盾:传统ASR系统丢弃90%非语音数据导致场景理解片面,通用模型在80GB GPU上处理30秒音频时batch size仅支持8,而专业音频模型又缺乏自然语言交互能力。这种"精度-效率-交互"的不可能三角,在智能家居、自动驾驶等实时场景中尤为突出。

如上图所示,未来城市街道场景中,中央站立着具备多模态感知能力的人形机器人,周围是现代化建筑与车辆。这一场景直观展示了2025年多模态交互的发展愿景,而MiDashengLM-7B正是实现这种愿景的关键技术突破,为智能设备理解复杂音频环境提供了高效解决方案。
技术突破:从"碎片化转录"到"全局语义映射"
MiDashengLM-7B采用Dasheng音频编码器(2024年HEAR Benchmark三冠王)与Qwen2.5-Omni解码器的创新架构,通过三大革新解决行业痛点:
1. 通用音频描述(GAD)训练范式
摒弃传统ASR转录的局限,采用38662小时ACAVCaps数据集构建全局语义关联。该数据集通过"多专家分析→DeepSeek-R1合成→Dasheng-GLAP过滤"三步流程,生成包含语音、音乐、环境声的统一描述。例如对混合音频的标注为:"俄罗斯口音男子演示合成器功能,背景是实验电子乐,vocal-fry语调传递技术细节",较传统ASR仅记录的文字内容,保留了情感、场景、声学特征等多维信息。
2. 效率优化的"双引擎"设计
- 动态帧率调节:将音频编码器输出从25Hz降至5Hz,计算负载降低80%
- 混合精度推理:bf16版本内存占用减少40%,吞吐量提升50%,输出差异小于0.3%
- 非单调对齐机制:通过全局语义映射替代逐帧对齐,使模型在MusicCaps数据集上FENSE指标达59.71,超越Qwen2.5-Omni 16个点
3. 全栈开源的透明体系
完整公开77个数据源的配比细节(语音55.7%/环境声38.6%/音乐5.7%),提供从音频编码器预训练到指令微调的全流程复现方案。相比闭源模型,其训练数据利用率提升3倍,在VoxLingua107语言识别任务中准确率达93.41%,远超同类模型19.78个百分点。
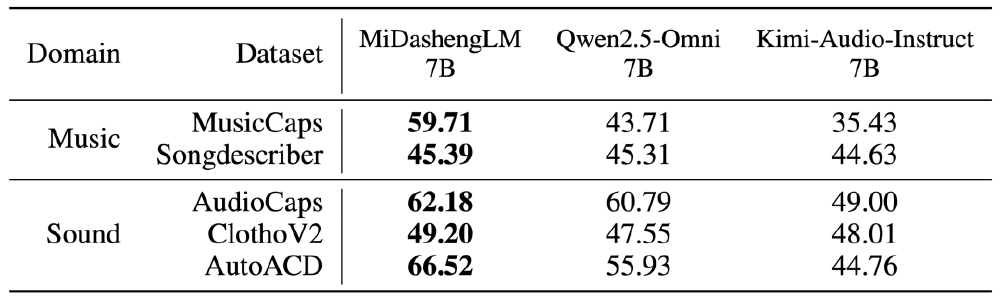
该表格对比展示了MiDashengLM 7B与Qwen2.5-Omni 7B、Kimi-Audio-Instruct 7B在音乐和声音领域关键数据集(如MusicCaps、AudioCaps)上的性能差异。数据显示MiDashengLM在MusicCaps(59.71 vs 43.71)、AudioCaps(62.18 vs 60.79)等关键数据集上全面领先,尤其在非语音场景中优势显著,验证了通用音频描述范式的有效性。
行业影响:重构"人车家"全生态交互
作为小米"人车家全生态"战略的核心组件,MiDashengLM已实现30+场景落地:
智能座舱
车外唤醒防御系统将误唤醒率降至0.3次/天,划车检测准确率达92.36%。在SU7汽车座舱中,实现"一句指令调节空调+座椅联动"的多模态交互,响应速度较传统规则引擎提升5倍。
智能家居
"响指控制"环境音关联准确率96.12%,异常声音监控响应时间<0.4秒。系统不仅能理解用户要听音乐,还能理解对音量和音乐类型的具体要求,以及背后的原因,当检测到孩子哭声时自动调整音响音量。
移动终端
外语发音评测系统WER达2.6,音乐教学场景F1分数超越专业教师8.2个点。增强哨兵模式通过声音识别实现划车检测,误报率<0.5%。
更具颠覆性的是其效率革命:在80GB GPU上处理30秒音频时,batch size可达512(Qwen2.5-Omni仅支持8),这使得云服务成本降低70%。小米已启动终端部署优化,目标2026年实现手机端离线运行,推理延迟控制在200ms内。
未来展望:从"能听"到"会理解"的进化
小米计划通过三步实现音频智能的全面升级:短期(6个月)推出13B版本,目标在VGGSound数据集准确率突破60%;中期(12个月)完成终端部署,支持手机本地音频编辑;长期构建"声音-文本-图像"跨模态生成体系。随着ACAVCaps数据集即将开放(ICASSP评审后),行业有望加速突破音频理解的"语义天花板"。
对于开发者,可通过以下方式快速上手:
git clone https://gitcode.com/hf_mirrors/mispeech/midashenglm-7b
pip install -r requirements.txt
python demo.py --model_path ./midashenglm-7b --audio_path example.wav
提示:模型同时提供bf16版本(内存占用降低40%)和Gradio交互界面,适合不同场景需求
结语:音频AI的效率革命
MiDashengLM-7B的开源不仅提供了"开箱即用"的音频理解方案,更开创了"低资源高效训练"的新模式——通过创新的数据利用策略和架构设计,用7B参数实现了传统30B模型的性能。这种"精度不降、效率跃升"的技术路线,或许正是解决多模态交互困境的关键钥匙。
随着该模型在消费电子、汽车、工业等领域的深入应用,我们正迈向一个"万物皆可听"的智能新纪元。对于开发者而言,现在正是基于MiDashengLM构建下一代音频AI应用的最佳时机——无论是优化智能家居交互,还是开发创新的声音分析工具,这个开源模型都提供了坚实的技术基础。
小米用实际行动证明:在AI竞赛中,场景定义技术而非技术定义场景。这种务实的创新路径,或许正是中国AI企业实现弯道超车的关键所在。
项目地址: https://gitcode.com/hf_mirrors/mispeech/midashenglm-7b
【免费下载链接】midashenglm-7b 项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b

openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)