
嵌入式面试八股文(十七)·ADC采样、SPI运用、C语言基础知识运用
本文围绕单片机开发中的常见问题展开分析,主要包括以下内容:1. STM32 ADC采样点选择原理;2. SPI协议的工作模式与引脚功能解析;3. 中断嵌套对栈空间和程序效率的影响;4. 栈溢出问题的判断与解决方案;5. 确保中断服务程序原子性的方法;6. 位运算和宏定义的使用技巧;7. 指针与数组的地址运算差异;8. 结构体内存对齐规则及其影响因素。通过具体代码示例和理论分析,详细阐述了嵌入式开发

目录
1.5 在单片机中,以下哪种方式可以确保中断服务程序 (ISR) 的原子性
1.6 宏定义表达式:#define HW_KEY_Y (0x01 << 4)
2.5 在单片机中,以下哪种方式可以确保中断服务程序 (ISR) 的原子性
2.6 宏定义表达式:#define HW_KEY_Y (0x01 << 4)
1. 问题
1.1 AD采样点
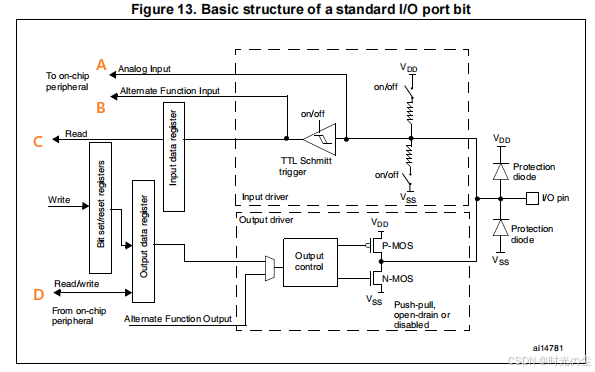
如下 STM32 I/O 内部框图根据图中 A、B、C、D 4 个信号点哪个是 GPIO 作为 AD 采样时输入的信号 ( )?理由是________________________?
1.2 以下有关 SPI 说法正确的是
A. SPI 有 3 中工作模式。
B. MOSI 是主机的通信输入引脚。
C. MISO 是从机通信输入引脚。
D. 在工作方式一中,时钟下降沿数据有效。
1.3 关于中断嵌套,以下说法正确的是
A. 中断嵌套会增加栈空间的使用
B. 中断嵌套不会影响程序执行效率
C. 所有单片机都支持中断嵌套
D. 中断嵌套与优先级无关
1.4 以下的代码在单片机中运行,可能导致什么问题
void func(){
int large_array[1024*1024];
//其他操作
}
A. 栈溢出。
B. 堆溢出。
C. 内存泄漏。
D. 无问题。
1.5 在单片机中,以下哪种方式可以确保中断服务程序 (ISR) 的原子性
A. 使用全局变量
B. 使用 volatile 关键字
C. 禁用中断
D. 使用动态内存分配
1.6 宏定义表达式:#define HW_KEY_Y (0x01 << 4)
HW_KEY_Y 的值用十六进制表示 = ________
十进制表示 = ________
计算 0XC3 & (0X80) = ________
1.7 #define MAX(x,y) x>y?x:y
请问 int a = 3, b=2 时,执行 MAX(a++,++b) 语句后,执行结果和 a、b 分别是 ________
1.8 数组与指针
请问 int *p[10] 中标识符 p 表示 ________;int (*q)[10] 中的标识符 q 表示 ________(例如:int a 中标识符 a 表示一个整型变量)
1.9 如下代码打印输出值是多少
int main()
{
int arr[] = {1,2,3,4,5};
int *p = (int*)(&arr + 1);
printf("arr=%d, %d\n", *(arr+1), *(p-1));
}
输出:arr= ________
1.10 有以下代码片段请根据代码回答一下问题
typedef struct{
char a;
unsigned short b;
}test_t;
int i;
test_t test={0X01,0X02};
char *p = (char*)&test;
for(i=0; i<sizeof(test_t); i++){
print("%x,",p[i]);
}上面代码中结构体 test_t 的大小是________;
请填出上面代码 print 打印输出的值:________;
请找出上面出题中存在哪些条件不足:________。
2. 解答
2.1 AD采样点
在该 STM32 I/O 端口位结构中,模拟输入路径是 GPIO 作为 AD 采样时的输入信号通道。也就是问题当中的A。
理由:AD 采样需要直接采集引脚的模拟电压信号,而 STM32 的 GPIO 引脚若要作为 ADC 输入,需将 I/O 配置为 “模拟输入” 模式 —— 此时引脚会直接连接到 “模拟输入” 路径(跳过数字输入的 TTL 肖特基触发器等数字电路),避免数字电路对模拟信号的干扰,确保 ADC 能准确采集引脚的模拟电压。
拓展一些东西:
| 功能 | 核心用途 | 典型应用场景 | 注意要点 |
|---|---|---|---|
| 模拟输入 | 给模拟外设提供无干扰的模拟信号,是 GPIO 作为模拟引脚的核心路径 | ADC 采样、DAC 输出校准、模拟比较器输入 | 需关闭数字电路,避免干扰 |
| 复用功能输入 | 为串口、SPI、I2C、定时器等复用外设提供数字输入信号,是 GPIO “借” 给外设使用的输入路径 | UART_RX、SPI_MISO、定时器捕获 | 需配置对应复用功能映射 |
| 读出 | 获取引脚 / 寄存器的实时状态 | 读取按键、传感器状态 | 读引脚≠读寄存器(寄存器有锁存) |
| 写入 | 向 GPIO 数据输出寄存器(ODR)或置位 / 复位寄存器(BSRR/BRR)写入数据,控制引脚输出电平 | 驱动 LED、继电器 | 优先用 BSRR/BRR 实现原子操作 |
| 读写 | 组合 “读” 和 “写” 的操作,先读取 GPIO 当前状态,再基于该状态修改输出(或配置) | 翻转引脚电平、批量配置 | 非原子操作需防中断干扰 |
2.2 以下有关 SPI 说法正确的是
A. SPI 有 3 中工作模式。
B. MOSI 是主机的通信输入引脚。
C. MISO 是从机通信输入引脚。
D. 在工作方式一中,时钟下降沿数据有效。
正确答案为:D,原因如下。
针对上面问题我们可以看出,本题主要是对SPI一些了解,其中对于SPI的引脚:
| 引脚名称 | 英文全称 | 核心功能 | 方向(主机视角) |
|---|---|---|---|
| SCK | Serial Clock | 同步时钟信号,控制数据传输时序 | 输出 |
| MOSI | Master Output Slave Input | 主机向从机发送数据 | 输出 |
| MISO | Master Input Slave Output | 从机向主机返回数据 | 输入 |
| SS/CS | Slave Select/Chip Select | 从机选择,低电平激活对应从机 | 输出 |
由此可以判断B和C是错误的,然后对于SPI的工作模式,这里需要引申出来一个概念时钟极性(CPOL)和时钟相位(CPHA):
时钟极性(CPOL):是指SPI设备处于空闲状态时,SCK信号线的电平信号(即SPI通讯开始前,NSS线为高电平的SCK的状态)。CPOL=0时,SCK在空闲状态为低电平;CPOL=1时,SCK在空闲状态为高电平。
时钟相位(CPHA):是指数据的采样的时刻,当CPHA=0时,MOSI或者MISO数据线上的信号将会在SCK时钟线的“奇数边沿”被采样,也就是SCK第一个边沿移入数据,第二个边沿移出数据;当CPHA=1时,数据线将会在SCK的“偶数边沿”采样,也就是SCK第一个边沿移出数据,第二个边沿移入数据。
| 工作模式 | 时钟极性(CPOL) | 时钟相位(CPHA) | 空闲时SCK时钟 | 数据有效边沿(采样边沿) | 核心特点 | 引用场景 | |
|---|---|---|---|---|---|---|---|
| 模式 0 | 0 | 0 | 低电平 | 时钟上升沿 | 奇数边沿 | 时钟空闲为低电平,上升沿采样数据 | EEPROM(如 AT25 系列)、SD 卡(SPI 模式)、普通 ADC/DAC 芯片、多数传感器模块(温湿度、加速度传感器等) |
| 模式 1 | 0 | 1 | 低电平 | 时钟下降沿 | 偶数边沿 | 时钟空闲为低电平,下降沿采样数据 | 部分射频芯片(如 nRF24L01 早期版本)、特定型号的 SPI 接口 LCD 驱动、部分工业控制模块 |
| 模式 2 | 1 | 0 | 高电平 | 时钟下降沿 | 奇数边沿 | 时钟空闲为高电平,下降沿采样数据 | 部分高速 ADC 芯片(如 ADS 系列部分型号)、工业总线扩展芯片、特定通信模块(如 CAN 转 SPI 芯片) |
| 模式 3 | 1 | 1 | 高电平 | 时钟上升沿 | 偶数边沿 | 时钟空闲为高电平,上升沿采样数据 | 高速 SPI Flash(如 W25Q 系列高速模式)、部分 FPGA/CPLD 的 SPI 接口、高端传感器(如高精度惯性测量单元 IMU) |
对于空闲时钟我们好理解0代表低电平,1代表高电平,但是对于采样时刻,为什么有的0代表上升沿,有的代表下降沿,这里其实我们先不要关注上升沿还是下降沿,我们来看奇偶边沿,以模式0为例:
模式0:CPOL=0,CPHA=0,时钟空闲为低电平,奇数边沿采样,也就是上升沿采样数据。
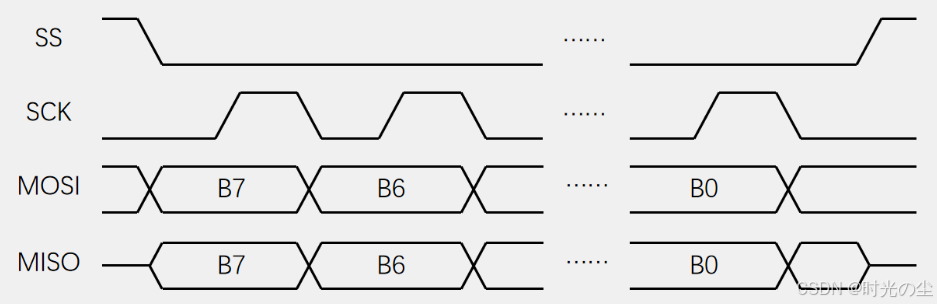
这个我们要怎么理解呢?首先对于起始状态,SS拉低开始,SCK处于空闲状态(CPOL=0),则为低电平:
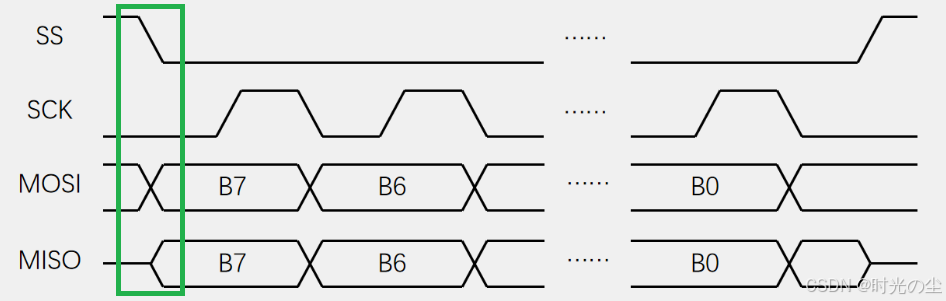
模式0的CPHA=0,则是奇数边沿采样,可以看出此时是上升沿采样数据:
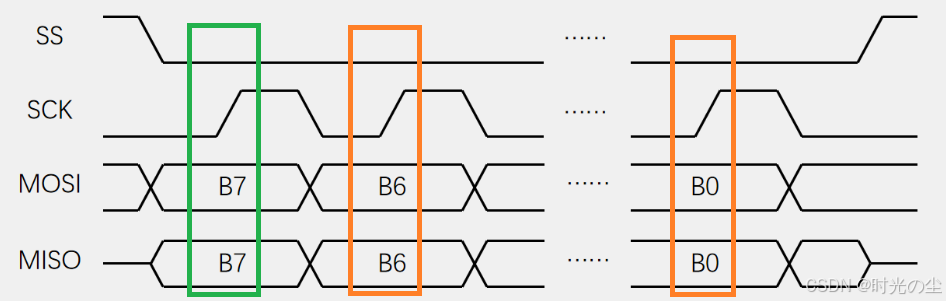
对于其数据的具体流向我们可以进行一个拆分,一个数据的收发,先SS下降,再移出数据,在SCK上升沿,在移入数据(采样),在SCK下降沿,再移出数据,依次类推:
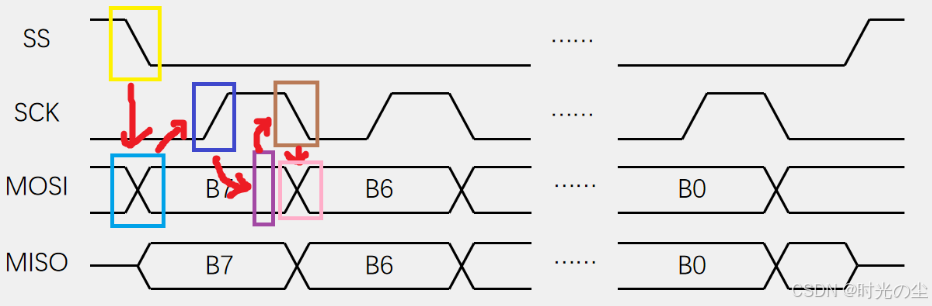
这里我们还要在了解一个概念,对于SPI来说,数据的收发实际上是数据的交互过程:
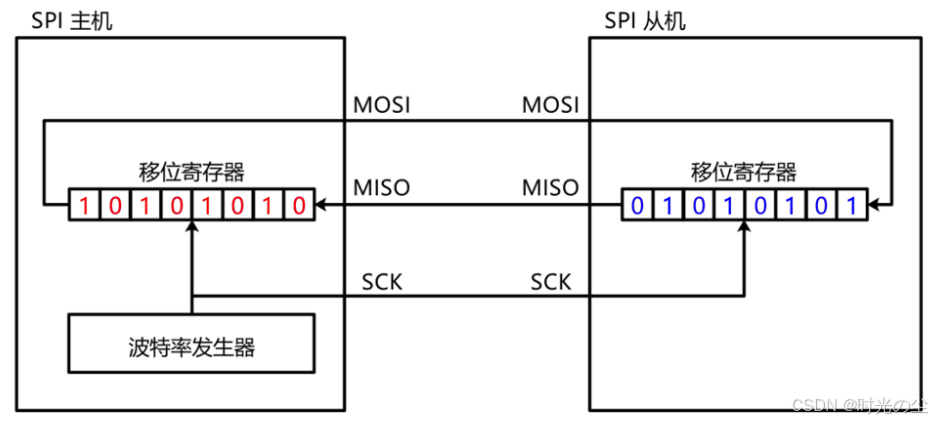
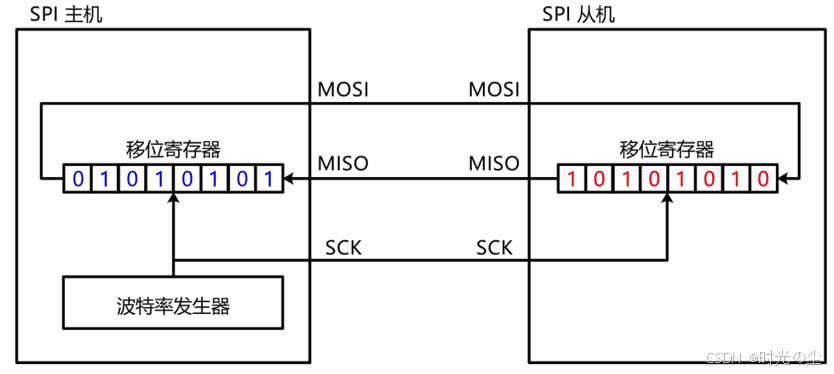
这一点怎么理解呢?例如,我们想要主机去读取从机数据,那么我们就需要将主机的数据移出到从机,然后在将从机的数据移入到主机,将二者的数据交互,实现数据的读取:
模式1:CPOL=0,CPHA=1,时钟空闲为低电平,偶数边沿采样,也就是下降沿采样数据。
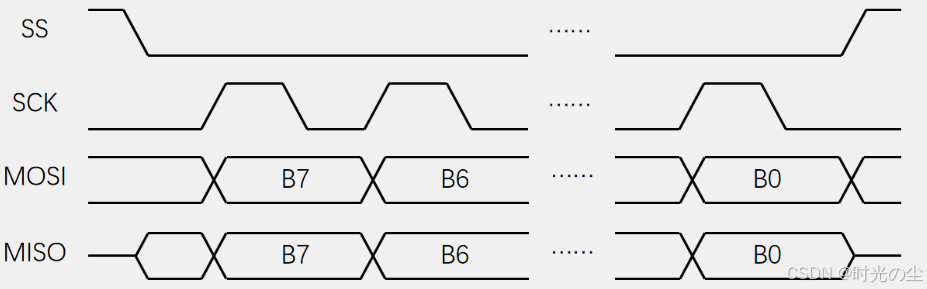
对于起始状态,SS拉低开始,SCK处于空闲状态(CPOL=0),则为低电平,模式1的CPHA=1,则是偶数边沿采样,可以看出此时是下降沿采样数据:
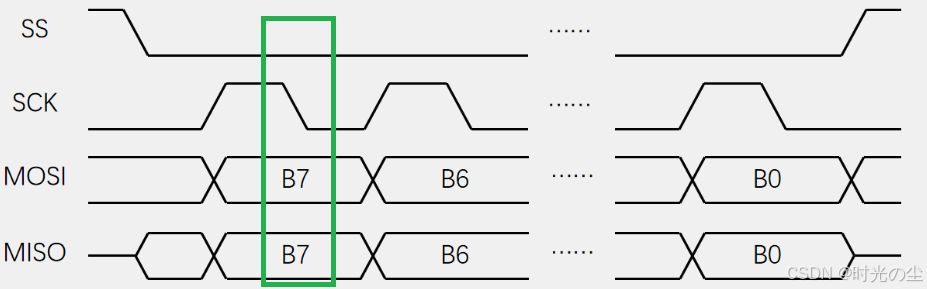
模式2和模式3可以根据上述介绍自己了解一下:
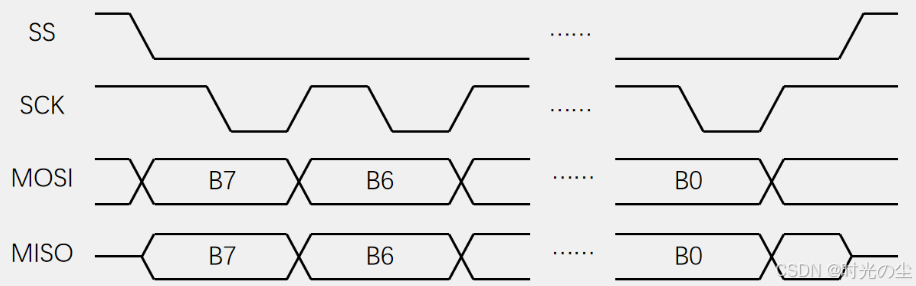
模式2:
模式3:
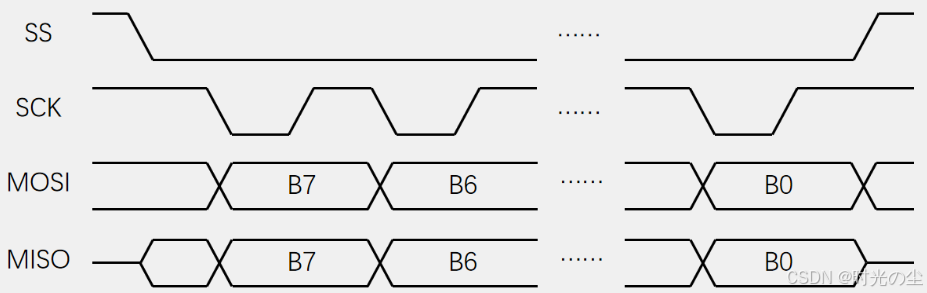
对于SPI的一些运用:
2.3 关于中断嵌套,以下说法正确的是
A. 中断嵌套会增加栈空间的使用
B. 中断嵌套不会影响程序执行效率
C. 所有单片机都支持中断嵌套
D. 中断嵌套与优先级无关
答案:A
选项 A 正确:每次进入中断都会保存程序断点、寄存器等信息到栈中。中断嵌套时,多个中断的上下文会依次压栈,必然增加栈空间的占用。
选项 B 错误:中断嵌套需要切换多个中断的上下文,还可能出现优先级判断、断点保存恢复等额外操作,会降低程序整体执行效率。
选项 C 错误:并非所有单片机都支持中断嵌套,部分低端或简化版单片机仅支持单级中断,不具备优先级配置和嵌套机制。
选项 D 错误:中断嵌套的核心前提是优先级差异,只有高优先级中断才能打断正在执行的低优先级中断,完全依赖优先级配置。
我们先来了解一下,中断的概念:
中断:在主程序运行过程中,出现了特定的中断触发条件(中断源),使得CPU暂停当前正在运行的程序,转而去处理中断程序,处理完成后又返回原来被暂停的位置继续运行。
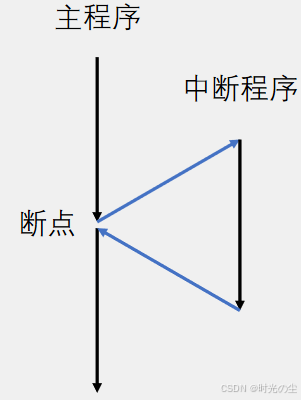
中断优先级:当有多个中断源同时申请中断时,CPU会根据中断源的轻重缓急进行裁决,优先响应更加紧急的中断源。
中断嵌套:当一个中断程序正在运行时,又有新的更高优先级的中断源申请中断,CPU再次暂停当前中断程序,转而去处理新的中断程序,处理完成后依次进行返回。
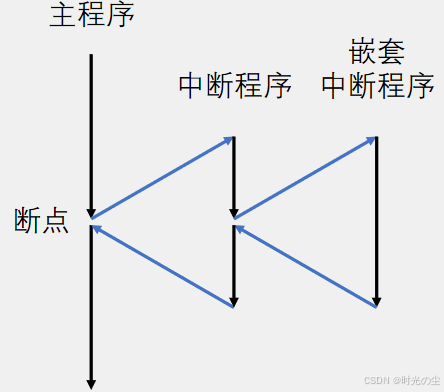
这里来讲一下中断嵌套占用栈空间的底层原理,首先我们需要先了解到,栈的核心作用是保存程序执行上下文,中断嵌套时栈空间的占用是 “逐层叠加” 的过程:
首先,主程序被低优先级中断打断,触发低优先级中断,CPU 自动将当前主程序的执行断点(PC 寄存器)、程序状态字(PSW)、通用寄存器(如 R0~R7)等压入栈中,栈指针(SP)向上移动(多数 MCU 栈向高地址增长),占用第一部分栈空间。
接着,低优先级中断被高优先级中断嵌套,高优先级中断触发,CPU 暂停当前低优先级中断服务函数(ISR)的执行,再次将低优先级 ISR 的当前断点、寄存器状态压入栈中,SP 继续上移,占用第二部分栈空间,嵌套层级越多(如高优先级中断又被更高优先级中断打断),栈中保存的上下文越多,占用空间呈 “层级式增长”。
最后,中断嵌套退出时的栈释放,高优先级 ISR 执行完成后,CPU 将栈中保存的低优先级 ISR 上下文弹出,SP 下移,释放对应空间,低优先级 ISR 执行完成后,再弹出主程序上下文,栈恢复到初始状态。
对于这里可以参考一些官方的数据手册:
STM32F10xxx/20xxx/21xxx/L1xxxx Cortex®-M3 programming manual
2.4 以下的代码在单片机中运行,可能导致什么问题
void func(){ int large_array[1024*1024]; //其他操作 }A. 栈溢出。
B. 堆溢出。
C. 内存泄漏。
D. 无问题。
答案:A
我们明确几个概念:
对于堆和栈的详细概念可以查看:
嵌入式面试八股文(五)·一文带你详细了解程序内存分区中的堆与栈的区别_嵌入式堆栈区别-CSDN博客
下面只是简述一下。
栈(Stack):是自动分配、自动释放的内存区域,遵循「后进先出(LIFO)」原则,由编译器 / 操作系统直接管理,无需程序员手动干预。主要存放函数的局部变量、函数参数、返回地址、临时值等。
举个例子:你去餐厅吃饭,餐盘叠成一摞:最后放上去的餐盘(最新调用的函数)必须最先拿走(函数执行完释放),这就是栈的 LIFO;餐厅的餐盘架大小固定(栈空间有限),叠太多就会倒(栈溢出)。
堆(Heap):是手动分配、手动释放(高级语言如 Java/Python 由 GC 自动回收)的内存区域,无固定顺序,由程序员(或垃圾回收器)管理,用于存储生命周期较长、大小不固定的数据。主要存放对象实例、动态数组、大型数据结构(如链表、哈希表)等。
举个例子:你去仓库租货架放东西:货架空间很大(堆空间大),你可以随便选位置放(不连续),但需要自己登记(手动分配)、自己清理(手动释放),忘了清理就会占着位置(内存泄露)。
栈溢出(Stack Overflow):栈的空间被耗尽,无法再为新的变量 / 函数调用分配内存,导致程序崩溃。
常见原因:
- 递归调用过深:无终止条件的递归,每次递归都会在栈中保存函数上下文,最终撑爆栈;
- 局部变量 / 数组过大:在栈中定义超大数组(如char arr[1024*1024*10];),直接超出栈的容量;
- 栈帧过多:多层嵌套函数调用(如无限循环调用函数)。
堆溢出(Heap Overflow):堆的可用空间被耗尽,无法再分配新的内存,导致程序无法创建新对象 / 数据结构。
常见原因:
- 无限制分配堆内存:循环创建大对象 / 数组,且不释放(如 Java 中对象长期被引用,GC 无法回收);
- 内存泄露累积:频繁分配堆内存但忘记释放,最终耗尽堆空间;
- 堆初始配置过小:虚拟机 / 程序配置的堆内存远小于实际需求。
内存泄露(Memory Leak):程序已分配的堆内存不再使用,但未被释放,导致这部分内存被永久占用,最终可能引发堆溢出。
注意:栈内存由系统自动释放,不存在 “栈内存泄露”;内存泄露仅针对堆内存。
| 概念 | 核心一句话总结 |
|---|---|
| 栈 | 小而快的自动内存,存局部变量 / 函数上下文,LIFO |
| 堆 | 大而灵活的手动 / GC 内存,存对象 / 动态数据 |
| 栈溢出 | 栈空间被耗尽(递归 / 大局部变量) |
| 堆溢出 | 堆空间被耗尽(无限分配 / 泄露) |
| 内存泄露 | 堆内存不用但未释放,累积导致堆溢出 |
而题目中给出的是局部变量:
int large_array[1024*1024];因此不存在堆溢出和内存泄露的问题,所以不选BC,然后题目告诉我们该变量是申请在单片机当中,单片机的 RAM 资源通常极其有限,我们以STM32为例,去看一下其数据手册:
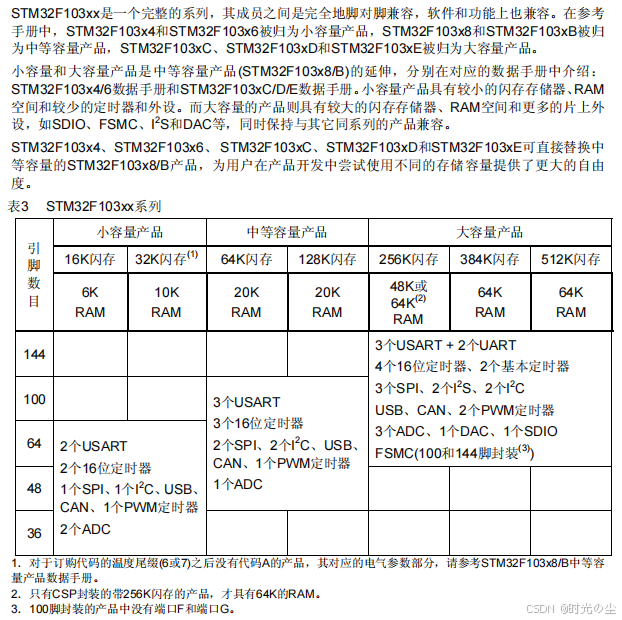
可以发现其RAM多为几十KB,而我们申请的内存为,int 类型通常占 4 字节(32 位 MCU)或 2 字节(16 位 MCU),按 4 字节计算,数组总大小 = 1024×1024×4 = 4MB;按 2 字节计算也达 2MB,远超单片机常规的栈空间大小(一般栈配置为几百字节~几 KB),函数调用时该数组会直接耗尽栈空间,触发栈溢出,因此选A。
2.5 在单片机中,以下哪种方式可以确保中断服务程序 (ISR) 的原子性
A. 使用全局变量
B. 使用 volatile 关键字
C. 禁用中断
D. 使用动态内存分配
答案:C
明确一个概念,什么是原子性?
原子性:指一段操作不可被中断、完整执行完毕,不会被其他程序(尤其是中断)打断。中断服务程序(ISR)的原子性,核心是保证 ISR 执行过程中,自身的关键操作不被更高优先级中断嵌套打断,或 ISR 对共享资源的操作不被其他程序干扰。
对于A我们需要知道:
全局变量:作用域覆盖整个程序(或编译单元),无需通过函数参数传递、返回值传递等方式,就能让不同函数、不同模块访问 / 修改同一数据,简化多上下文的数据交互。
全局变量本身无法保证原子性,例如主程序正在读写全局变量时,ISR 触发并修改该变量,会导致数据错乱;反之 ISR 操作全局变量时,更高优先级中断也可能打断并修改,破坏操作的完整性。
对于B:
volatile :禁止编译器优化,确保每次访问变量都直接读取内存(而非寄存器缓存)。
volatile 不保证操作的原子性,比如 ISR 中执行count++(非原子操作,拆分为 “读 - 加 - 写” 三步),即使count加了volatile,高优先级中断仍可能在三步之间打断,导致count值异常。
对于D:
动态内存分配(malloc/free)是非原子操作,内部包含复杂的内存块管理逻辑,执行过程中被中断打断会导致堆结构破坏。
并且上面也提到过,单片机 RAM 资源有限,ISR 中使用动态内存易引发堆溢出、内存泄漏,且完全无法保证原子性,行业规范中严禁在 ISR 中使用动态内存。
2.6 宏定义表达式:#define HW_KEY_Y (0x01 << 4)
HW_KEY_Y 的值用十六进制表示 = 0x10,十进制表示 = 16;
计算 0XC3 & (0X80) = 0x80;
宏定义 #define HW_KEY_Y (0x01 << 4) 的核心是十六进制数 0x01 左移 4 位,我们先对 0x10,进行拆分成二进制:0000 0001,让其左移4位为:0001 0000,转换为十六进制也就是:0x10,转换为十进制:16。
& 是按位与运算,规则:对应二进制位都为 1 时结果为 1,否则为 0。我们首先将0xC3转成二进制表示:1100 0011,然后将0x80转成二进制表示:1000 0000,运算:
1100 0011
& 1000 0000
————————————
1000 0000最终结果为:1000 0000,转为十六进制:0x80。
2.7 #define MAX(x,y) x>y?x:y
请问 int a = 3, b=2 时,执行 MAX(a++,++b) 语句后,执行结果和 a、b 分别是:
MAX执行结果:4
执行后a的值:4
执行后b的值:4
该问题的核心是:理解宏定义的 “文本替换” 特性(而非函数调用),以及自增运算符++的执行时机。我们先编写一个代码:
#include <stdio.h>
#define MAX(x,y) x>y?x:y
int main() {
int a = 3, b = 2;
// 执行MAX(a++, ++b),并接收返回值
int result = MAX(a++, ++b);
// 打印结果
printf("MAX执行结果:%d\n", result);
printf("执行后a的值:%d\n", a);
printf("执行后b的值:%d\n", b);
return 0;
} 实际运行一下:
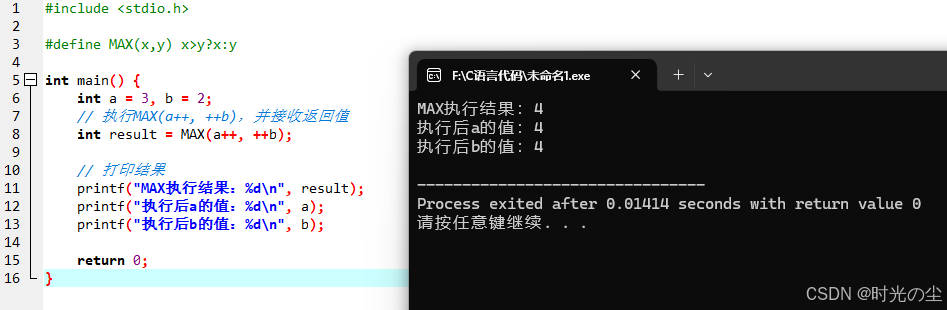
宏 #define MAX(x,y) x>y?x:y 是简单的字符串替换,而非函数传参,当我们调用MAX(a++, ++b)的时候,实际上此时的result等价于:
int result = MAX(a++, ++b);
//等价于
int result = a++ > ++b ? a++ : ++b;此时我们运行三目运算符,首先先对比:a++ > ++b,对于二者:
a++:后置自增,先参与运算(也就是此时的大小比较),先把a的当前值3参与比较,再把a加 1(此时a变为4);
++b:前置自增,后参与运算(也就是先进行自己的+1操作),先把b的值加 1,b变为3,参与比较的是3;
此时a++参与比较的值为3,++b参与比较的值为3,3>3不满足条件,因此执行++b,前置自增,b从3变为4,该分支的结果是4(即整个MAX表达式的执行结果)。
| 项 | 结果 |
|---|---|
| MAX (a++,++b) 的执行结果 | 4 |
| 执行后 a 的值 | 4 |
| 执行后 b 的值 | 4 |
这里我们做一个延伸,下面这个函数最终输出结果为多少呢?
#include <stdio.h>
int MAX(int x, int y) {
return x > y ? x : y;
}
int main() {
int a = 3, b = 2;
int result = MAX(a++, ++b);
printf("MAX执行结果:%d\n", result);
printf("执行后a的值:%d\n", a);
printf("执行后b的值:%d\n", b);
return 0;
}
答案:
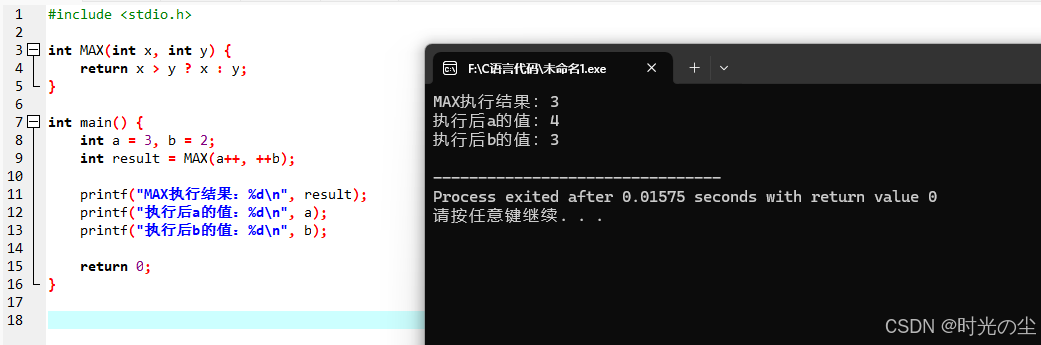
这里我们需要了解一个规则,函数调用的规则是:先计算所有参数的值,再将值传入函数体执行逻辑(和宏的 “文本替换” 完全不同)。
简单来说此时我们在调用MAX的时候,其实是将参数传递过去,也就是a++后置自增,先传递3再自增,++b前置自增,先自加在进行参数传递,此时的MAX可以看做:
int result = MAX(a++, ++b);
int result = MAX(3, 3);| 项 | 结果 |
|---|---|
| MAX (a++,++b) 的执行结果 | 3 |
| 执行后 a 的值 | 4 |
| 执行后 b 的值 | 3 |
在延伸几个可以自行测试一下结果:
#include <stdio.h>
#define MAX(y,x) x>y?x:y
int main() {
int a = 3, b = 2;
// 执行MAX(a++, ++b),并接收返回值
int result = MAX(a++, ++b);
// 打印结果
printf("MAX执行结果:%d\n", result);
printf("执行后a的值:%d\n", a);
printf("执行后b的值:%d\n", b);
return 0;
}#include <stdio.h>
#define MAX(x,y) x>x?x:y
int main() {
int a = 3, b = 2;
int result = MAX(a++, ++b);
// 打印结果
printf("MAX执行结果:%d\n", result);
printf("执行后a的值:%d\n", a);
printf("执行后b的值:%d\n", b);
return 0;
}#include <stdio.h>
#define MAX(x,y) x<x?x:y
int main() {
int a = 3, b = 2;
int result = MAX(a++, ++b);
// 打印结果
printf("MAX执行结果:%d\n", result);
printf("执行后a的值:%d\n", a);
printf("执行后b的值:%d\n", b);
return 0;
}2.8 数组与指针
请问:
int *p[10] 中标识符 p 表示:一个包含 10 个元素的数组,每个元素都是指向整型变量的指针(简称 “指针数组”);
int (*q)[10] 中的标识符 q 表示:一个指向包含 10 个整型元素的数组的指针(简称 “数组指针”)
对于数组指针和指针数组的具体介绍可以参考:
C语言菜鸟入门·一文带你从浅入深了解指针_c语言指针-CSDN博客
2.9 如下代码打印输出值是多少
int main()
{
int arr[] = {1,2,3,4,5};
int *p = (int*)(&arr + 1);
printf("arr=%d, %d\n", *(arr+1), *(p-1));
}
输出:arr=2,5
这题主要需要了解一下数组地址运算和指针偏移。我们对于数组分配内存:
int arr[] = {1,2,3,4,5};| 地址(示例) | 0xXXX0 | 0xXXX4 | 0xXXX8 | 0xXXXC | 0xXXX10 |
|---|---|---|---|---|---|
| 元素 | arr[0] | arr[1] | arr[2] | arr[3] | arr[4] |
| 值 | 1 | 2 | 3 | 4 | 5 |
arr:本身是数组首元素地址(&arr[0]),类型为 int*;
arr + 1:对数组首元素地址加 1,偏移量是数组单个元素的大小(4字节),因此 arr + 1 指向 arr[0]的下一位也就是arr[1];
&arr:是整个数组的地址,类型为 int (*)[5](指向 “包含 5 个 int 的数组” 的指针);
&arr + 1:对 “数组地址” 加 1,偏移量是整个数组的大小(5*4=20字节),因此 &arr + 1 指向数组末尾的下一个位置。
| 表达式 | 本质含义 | 类型 | 数值(地址) | 加 1 偏移量 | 指向位置(对应 arr={1,2,3,4,5}) |
|---|---|---|---|---|---|
| arr | 数组首元素的地址 | int*(int 型指针) |
&arr[0] |
4 字节 | arr [0](值 1) |
arr + 1 |
首元素地址偏移 1 个 int | int* |
&arr[1] |
- | arr [1](值 2) |
| &arr | 整个数组的地址 | int (*)[5](数组指针) |
&arr[0] |
20 字节 | 整个数组(首地址和 arr 相同) |
&arr + 1 |
数组地址偏移 1 个数组大小 | int (*)[5] |
&arr[0]+20 |
- | 数组末尾的下一个位置(arr [5],越界但合法) |
编写一个代码验证一下:
#include <stdio.h>
int main() {
int arr[] = {1,2,3,4,5};
printf("arr 的地址值:%p\n", arr);
printf("&arr 的地址值:%p\n", &arr);
printf("arr + 1 的地址:%p\n", arr + 1);
printf("&arr + 1 的地址:%p\n", &arr + 1);
return 0;
}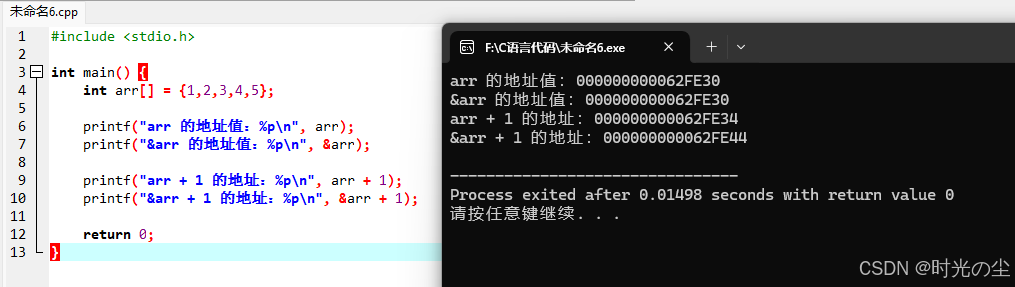
为什么arr和&arr地址数值相同,但类型不同?
举个例子:你家的门牌号是100(对应arr,指向 “第一个房间”),而 “你家整套房子” 的地址也是100(对应&arr,指向 “整套 5 室的房子”)。
- 数值相同是因为 “第一个房间” 和 “整套房子” 的起始位置一致;
- 类型不同导致 “加 1” 的行为完全不同:
- arr+1:走到 “下一个房间”(偏移 4 字节,对应 arr [1]);
- &arr+1:走出 “整套房子”,走到隔壁栋(偏移 20 字节,数组外)。
2.10 有以下代码片段请根据代码回答一下问题
typedef struct{
char a;
unsigned short b;
}test_t;
int i;
test_t test={0X01,0X02};
char *p = (char*)&test;
for(i=0; i<sizeof(test_t); i++){
print("%x,",p[i]);
}上面代码中结构体 test_t 的大小是:4 字节;
请填出上面代码 print 打印输出的值:1,0,2,0;
请找出上面出题中存在哪些条件不足:
- 未明确编译器的内存对齐规则(是否默认对齐 / 手动设置pack);
- 未说明系统的字节序(小端 / 大端);
- 未明确char的符号属性(虽无实质影响,但属于规范缺失);
- 代码中print是语法错误,应为printf。
首先对于结构体 test_t 的大小,我们先来了解一下内存对齐,内存对齐是编译器的 “优化策略”,核心目的是提升 CPU 访问内存的效率,CPU 读取内存时并非逐字节读取,而是按 “固定步长”(如 2/4/8 字节,即 “对齐单位”)读取。如果数据跨步长存储,CPU 需要读两次再拼接,效率极低;对齐后只需读一次。C 语言默认对齐规则就是为了适配 CPU 的这种读取特性,因此结构体的内存布局不是简单的 “成员大小相加”,而是要满足对齐要求。
内存对齐的两个规则:
规则 1:成员的偏移量必须是自身大小的整数倍
- 偏移量:成员在结构体中的起始地址相对于结构体首地址的字节数(结构体首地址偏移量为 0);
- 自身大小:char占 1 字节、short占 2 字节、int占 4 字节、long占 8 字节(64 位)等;
- 通俗说:每个成员必须 “落在自己大小的整数倍地址上”,否则编译器会在前面补空字节(填充)。
规则 2:结构体总大小必须是 “最大基本成员大小” 的整数倍
- 最大基本成员大小:结构体中所有基本数据类型成员的大小最大值(忽略嵌套结构体 / 指针等,本题只有char和short,最大值是 2);
- 通俗说:就算成员按规则 1 排完了,若总大小不是最大值的整数倍,要在结构体末尾补填充字节。
以题目为例:
typedef struct{
char a; // 成员1:char类型,大小1字节
unsigned short b;// 成员2:unsigned short类型,大小2字节
}test_t;| 偏移地址(相对于结构体首地址) | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 存储内容 | a=0x01 | 填充(0x00) | b 低字节 = 0x02 | b 高字节 = 0x00 |
| 归属 | 成员 a | 对齐填充 | 成员 b | 成员 b |
我们做个延伸:
typedef struct{
char a; // 成员1:char,大小1字节
unsigned short b;// 成员2:unsigned short,大小2字节
int c; // 成员3:int,大小4字节
}test_t;| 偏移地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 存储内容 | a | 填充(0) | b | b | c | c | c | c |
| 归属 | 成员 a | 对齐填充 | 成员 b | 成员 b | 成员 c | 成员 c | 成员 c | 成员 c |



openvela 操作系统专为 AIoT 领域量身定制,以轻量化、标准兼容、安全性和高度可扩展性为核心特点。openvela 以其卓越的技术优势,已成为众多物联网设备和 AI 硬件的技术首选,涵盖了智能手表、运动手环、智能音箱、耳机、智能家居设备以及机器人等多个领域。
更多推荐
 31
31 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)